| 编辑推荐: |
| 本文来自于个人博客,本文讲述美团外卖Android客户端团队在将App的Crash率从千分之三做到万分之二过程中所做的大量实践工作,希望能够为其他团队提供一些经验和启发。 |
|
Crash率是衡量一个App好坏的重要指标之一。如果你忽略了它的存在,它就会得寸进尺,愈演愈烈,最后造成大量用户的流失,进而给公司带来无法估量的损失。本文讲述美团外卖Android客户端团队在将App的Crash率从千分之三做到万分之二过程中所做的大量实践工作,抛砖引玉,希望能够为其他团队提供一些经验和启发。
面临的挑战和成果
面对用户使用频率高,外卖业务增长快,Android碎片化严重这些问题,美团外卖Android
App如何持续的降低Crash率,是一项极具挑战的事情。通过团队的全力全策,美团外卖Android
App的平均Crash率从千分之三降到了万分之二,最优值万一左右(Crash率统计方式:Crash次数/DAU)。
美团外卖自2013年创建以来,业务就以指数级的速度发展。美团外卖承载的业务,从单一的餐饮业务,发展到餐饮、超市、生鲜、果蔬、药品、鲜花、蛋糕、跑腿等十多个大品类业务。目前美团外卖日完成订单量已突破2000万,成为美团点评最重要的业务之一。美团外卖客户端所承载的业务模块越来越多,产品复杂度越来越高,团队开发人员日益增加,这些都给App降低Crash率带来了巨大的挑战。
Crash的治理实践
对于Crash的治理,我们尽量遵守以下三点原则:
由点到面。一个Crash发生了,我们不能只针对这个Crash的去解决,而要去考虑这一类Crash怎么去解决和预防。只有这样才能使得这一类Crash真正被解决。
异常不能随便吃掉。随意的使用try-catch,只会增加业务的分支和隐蔽真正的问题,要了解Crash的本质原因,根据本质原因去解决。catch的分支,更要根据业务场景去兜底,保证后续的流程正常。
预防胜于治理。当Crash发生的时候,损失已经造成了,我们再怎么治理也只是减少损失。尽可能的提前预防Crash的发生,可以将Crash消灭在萌芽阶段。
常规的Crash治理
常规Crash发生的原因主要是由于开发人员编写代码不小心导致的。解决这类Crash需要由点到面,根据Crash引发的原因和业务本身,统一集中解决。常见的Crash类型包括:空节点、角标越界、类型转换异常、实体对象没有序列化、数字转换异常、Activity或Service找不到等。这类Crash是App中最为常见的Crash,也是最容易反复出现的。在获取Crash堆栈信息后,解决这类Crash一般比较简单,更多考虑的应该是如何避免。下面介绍两个我们治理的量比较大的Crash。
NullPointerException
NullPointerException是我们遇到最频繁的,造成这种Crash一般有两种情况:
对象本身没有进行初始化就进行操作。
对象已经初始化过,但是被回收或者手动置为null,然后对其进行操作。
针对第一种情况导致的原因有很多,可能是开发人员的失误、API返回数据解析异常、进程被杀死后静态变量没初始化导致,我们可以做的有:
对可能为空的对象做判空处理。
养成使用@NonNull和@Nullable注解的习惯。
尽量不使用静态变量,万不得已使用SharedPreferences来存储。
考虑使用Kotlin语言。
针对第二种情况大部分是由于Activity/Fragment销毁或被移除后,在Message、Runnable、网络等回调中执行了一些代码导致的,我们可以做的有:
Message、Runnable回调时,判断Activity/Fragment是否销毁或被移除;加try-catch保护;Activity/Fragment销毁时移除所有已发送的Runnable。
封装LifecycleMessage/Runnable基础组件,并自定义Lint检查,提示使用封装好的基础组件。
在BaseActivity、BaseFragment的onDestory()里把当前Activity所发的所有请求取消掉。
IndexOutOfBoundsException
这类Crash常见于对ListView的操作和多线程下对容器的操作。
针对ListView中造成的IndexOutOfBoundsException,经常是因为外部也持有了Adapter里数据的引用(如在Adapter的构造函数里直接赋值),这时如果外部引用对数据更改了,但没有及时调用notifyDataSetChanged(),则有可能造成Crash,对此我们封装了一个BaseAdapter,数据统一由Adapter自己维护通知,
同时也极大的避免了The content of the adapter has changed but
ListView did not receive a notification,这两类Crash目前得到了统一的解决。
另外,很多容器是线程不安全的,所以如果在多线程下对其操作就容易引发IndexOutOfBoundsException。常用的如JDK里的ArrayList和Android里的SparseArray、ArrayMap,同时也要注意有一些类的内部实现也是用的线程不安全的容器,如Bundle里用的就是ArrayMap。
系统级Crash治理
众所周知,Android的机型众多,碎片化严重,各个硬件厂商可能会定制自己的ROM,更改系统方法,导致特定机型的崩溃。发现这类Crash,主要靠云测平台配合自动化测试,以及线上监控,这种情况下的Crash堆栈信息很难直接定位问题。下面是常见的解决思路:
尝试找到造成Crash的可疑代码,看是否有特异的API或者调用方式不当导致的,尝试修改代码逻辑来进行规避。
通过Hook来解决,Hook分为Java Hook和Native
Hook。Java Hook主要靠反射或者动态代理来更改相应API的行为,需要尝试找到可以Hook的点,一般Hook的点多为静态变量,同时需要注意Android不同版本的API,类名、方法名和成员变量名都可能不一样,所以要做好兼容工作;Native
Hook原理上是用更改后方法把旧方法在内存地址上进行替换,需要考虑到Dalvik和ART的差异;相对来说Native
Hook的兼容性更差一点,所以用Native Hook的时候需要配合降级策略。
如果通过前两种方式都无法解决的话,我们只能尝试反编译ROM,寻找解决的办法。
我们举一个定制系统ROM导致Crash的例子,根据Crash平台统计数据发现该Crash只发生在vivo
V3Max这类机型上,Crash堆栈如下:
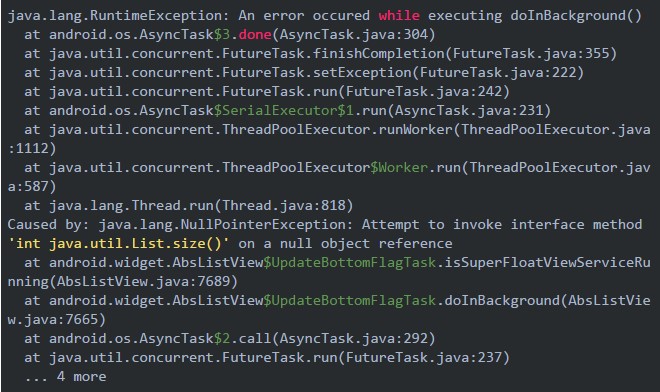
我们发现原生系统上对应系统版本的AbsListView里并没有UpdateBottomFlagTask类,因此可以断定是vivo该版本定制的ROM修改了系统的实现。我们在定位这个Crash的可疑点无果后决定通过Hook的方式解决,通过源码发现AsyncTask$SerialExecutor是静态变量,是一个很好的Hook的点,通过反射添加try-catch解决。因为修改的是final对象所以需要先反射修改accessFlags,需要注意ART和Dalvik下对应的Class不同,代码如下:
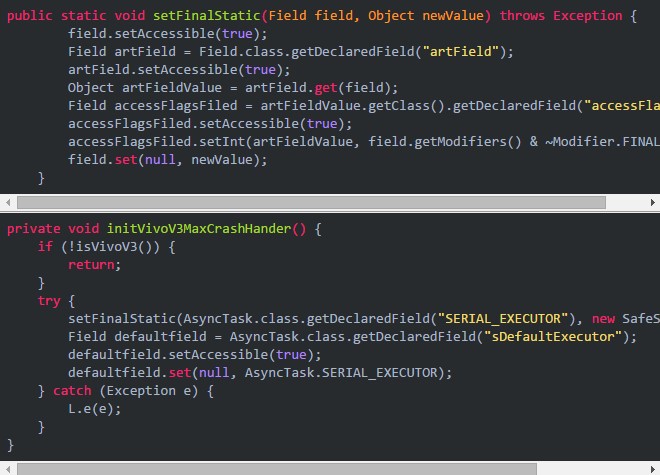
美团外卖App用上述方法解决了对应的Crash,但是美团App里的外卖频道因为平台的限制无法通过这种方式,于是我们尝试反编译ROM。
Android ROM编译时会将framework、app、bin等目录打入system.img中,system.img是Android系统中用来存放系统文件的镜像
(image),文件格式一般为yaffs2或ext。但Android 5.0开始支持dm-verity后,system.img不再提供,而是提供了三个文件system.new.dat,system.patch.dat,system.transfer.list,因此我们首先需要通过上述的三个文件得到system.img。但我们将vivo
ROM解压后发现厂商将system.new.dat进行了分片,如下图所示:
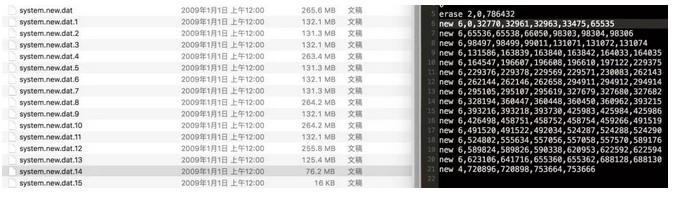
经过对system.transfer.list中的信息和system.new.dat
1 2 3 … 文件大小对比研究,发现一些共同点,system.transfer.list中的每一个block数*4KB
与对应的分片文件的大小大致相同,故大胆猜测,vivo ROM对system.patch.dat分片也只是单纯的按block先后顺序进行了分片处理。所以我们只需要在转化img前将这些分片文件合成一个system.patch.dat文件就可以了。
最后根据system.img的文件系统格式进行解包,拿到framework目录,其中有framework.jar和boot.oat等文件,因为Android4.4之后引入了ART虚拟机,会预先把system/framework中的一些jar包转换为oat格式,所以我们还需要将对应的oat文件通过ota2dex将其解包获得dex文件,之后通过dex2jar和jd-gui查看源码。
OOM
OOM是OutOfMemoryError的简称,在常见的Crash疑难排行榜上,OOM绝对可以名列前茅并且经久不衰。因为它发生时的Crash堆栈信息往往不是导致问题的根本原因,而只是压死骆驼的最后一根稻草。导致OOM的原因大部分如下:
内存泄漏,大量无用对象没有被及时回收导致后续申请内存失败。
大内存对象过多,最常见的大对象就是Bitmap,几个大图同时加载很容易触发OOM。
内存泄漏
内存泄漏指系统未能及时释放已经不再使用的内存对象,一般是由错误的程序代码逻辑引起的。在Android平台上,最常见也是最严重的内存泄漏就是Activity对象泄漏。Activity承载了App的整个界面功能,Activity的泄漏同时也意味着它持有的大量资源对象都无法被回收,极其容易造成OOM。常见的可能会造成Activity泄漏的原因有:
匿名内部类实现Handler处理消息,可能导致隐式持有的Activity对象无法回收。
Activity和Context对象被混淆和滥用,在许多只需要Application
Context而不需要使用Activity对象的地方使用了Activity对象,比如注册各类Receiver、计算屏幕密度等等。
View对象处理不当,使用Activity的LayoutInflater创建的View自身持有的Context对象其实就是Activity,这点经常被忽略,在自己实现View重用等场景下也会导致Activity泄漏。
对于Activity泄漏,目前已经有了一个非常好用的检测工具:LeakCanary,它可以自动检测到所有Activity的泄漏情况,并且在发生泄漏时给出十分友好的界面提示,同时为了防止开发人员的疏漏,我们也会将其上报到服务器,统一检查解决。另外我们可以在debug下使用StrictMode来检查Activity的泄露、Closeable对象没有被关闭等问题。
大对象
在Android平台上,我们分析任一应用的内存信息,几乎都可以得出同样的结论:占用内存最多的对象大都是Bitmap对象。随着手机屏幕尺寸越来越大,屏幕分辨率也越来越高,1080p和更高的2k屏已经占了大半份额,为了达到更好的视觉效果,我们往往需要使用大量高清图片,同时也为OOM埋下了祸根。对于图片内存优化,我们有几个常用的思路:
尽量使用成熟的图片库,比如Glide,图片库会提供很多通用方面的保障,减少不必要的人为失误。
根据实际需要,也就是View尺寸来加载图片,可以在分辨率较低的机型上尽可能少地占用内存。除了常用的BitmapFactory.Options#inSampleSize和Glide提供的BitmapRequestBuilder#override之外,我们的图片CDN服务器也支持图片的实时缩放,可以在服务端进行图片缩放处理,从而减轻客户端的内存压力。分析App内存的详细情况是解决问题的第一步,我们需要对App运行时到底占用了多少内存、哪些类型的对象有多少个有大致了解,并根据实际情况做出预测,这样才能在分析时做到有的放矢。Android
Studio也提供了非常好用的Memory Profiler,堆转储和分配跟踪器功能可以帮我们迅速定位问题。
AOP增强辅助
AOP是面向切面编程的简称,在Android的Gradle插件1.5.0中新增了Transform
API之后,编译时修改字节码来实现AOP也因为有了官方支持而变得非常方便。在一些特定情况下,可以通过AOP的方式自动处理未捕获的异常:
抛异常的方法非常明确,调用方式比较固定。
异常处理方式比较统一。
和业务逻辑无关,即自动处理异常后不会影响正常的业务逻辑。典型的例子有读取Intent
Extras参数、读取SharedPreferences、解析颜色字符串值和显示隐藏Window等等。
这类问题的解决原理大致相同,我们以Intent Extras为例详细介绍一下。读取Intent
Extras的问题在于我们非常常用的方法 Intent#getStringExtra 在代码逻辑出错或者恶意攻击的情况下可能会抛出ClassNotFoundException异常,而我们平时在写代码时又不太可能给所有调用都加上try-catch语句,于是一个更安全的Intent工具类应运而生,理论上只要所有人都使用这个工具类来访问Intent
Extras参数就可以防止此类型的Crash。但是面对庞大的旧代码仓库和诸多的业务部门,修改现有代码需要极大成本,还有更多的外部依赖SDK基本不可能使用我们自己的工具类,此时就需要AOP大展身手了。
我们专门制作了一个Gradle插件,只需要配置一下参数就可以将某个特定方法的调用替换成另一个方法:
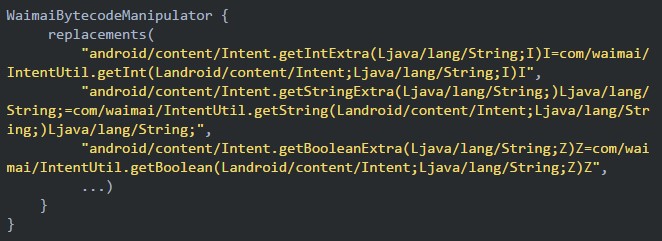
上面的配置就可以将App代码(包括第三方库)里所有的Intent.getXXXExtra调用替换成IntentUtil类中的安全版实现。当然,并不是所有的异常都只需要catch住就万事大吉,如果真的有逻辑错误肯定需要在开发和测试阶段及时暴露出来,所以在IntentUtil中会对App的运行环境做判断,Debug下会将异常直接抛出,开发同学可以根据Crash堆栈分析问题,Release环境下则在捕获到异常时返回对应的默认值然后将异常上报到服务器。
依赖库的问题
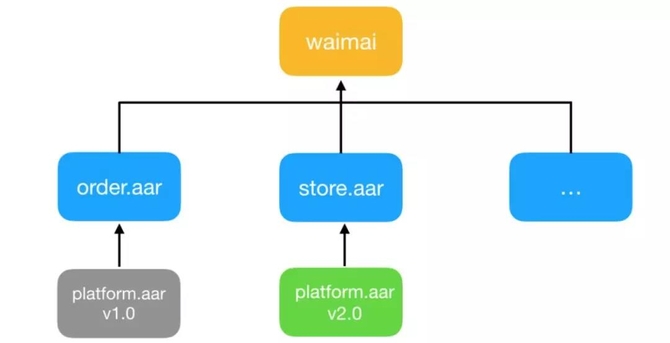
Android App经常会依赖很多AAR, 每个AAR可能有多个版本,打包时Gradle会根据规则确定使用的最终版本号(默认选择最高版本或者强制指定的版本),而其他版本的AAR将被丢弃。如果互相依赖的AAR中有不兼容的版本,存在的问题在打包时是不能发现的,只有在相关代码执行时才会出现,会造成NoClassDefFoundError、NoSuchFieldError、NoSuchMethodError等异常。
如图所示,order和store两个业务库都依赖了platform.aar,一个是1.0版本,一个是2.0版本,默认最终打进APK的只有platform
2.0版本,这时如果order库里用到的platform库里的某个类或者方法在2.0版本中被删除了,运行时就可能发生异常,虽然SDK在升级时会尽量做到向下兼容,但很多时候尤其是第三方SDK是没法得到保证的,在美团外卖Android
App v6.0版本时因为这个原因导致热修复功能丧失,因此为了提前发现问题,我们接入了依赖检查插件Defensor。
Defensor在编译时通过DexTask获取到所有的输入文件(也就是被编译过的class文件),然后检查每个文件里引用的类、字段、方法等是否存在。
除此之外我们写了一个Gradle插件SVD(strict version
dependencies)来对那些重要的SDK的版本进行统一管理。插件会在编译时检查Gradle最终使用的SDK版本是否和配置中的一致,如果不一致插件会终止编译并报错,并同时会打印出发生冲突的SDK的所有依赖关系。
Crash的预防实践
单纯的靠约定或规范去减少Crash的发生是不现实的。约定和规范受限于组织架构和具体执行的个人,很容易被忽略,只有靠工程架构和工具才能保证Crash的预防长久的执行下去。
工程架构对Crash率的影响
在治理Crash的实践中,我们往往忽略了工程架构对Crash率的影响。Crash的发生大部分原因是源于程序员的不合理的代码,而程序员工作中最直接的接触的就是工程架构。对于一个边界模糊,层级混乱的架构,程序员是更加容易写出引起Crash的代码。在这样的架构里面,即使程序员意识到导致某种写法存在问题,想要去改善这样不合理的代码,也是非常困难的。相反,一个层级清晰,边界明确的架构,是能够大大减少Crash发生的概率,治理和预防Crash也是相对更容易。这里我们可以举几个我们实践过的例子阐述。
业务模块的划分
原来我们的Crash基本上都是由个别同学关注解决的,团队里的每个同学都会提交可能引起Crash的代码,如果负责Crash的同学因为某些事情,暂时没有关注App的Crash率,那么造成Crash的同学也不会知道他的代码引起了Crash。
对于这个问题,我们的做法是App的业务模块化。业务模块化后,每个业务都有都有唯一包名和对应的负责人。当某个模块发生了Crash,可以根据包名提交问题给这个模块的负责人,让他第一时间进行处理。业务模块化本身也是工程架构优先需要考虑的事情之一。
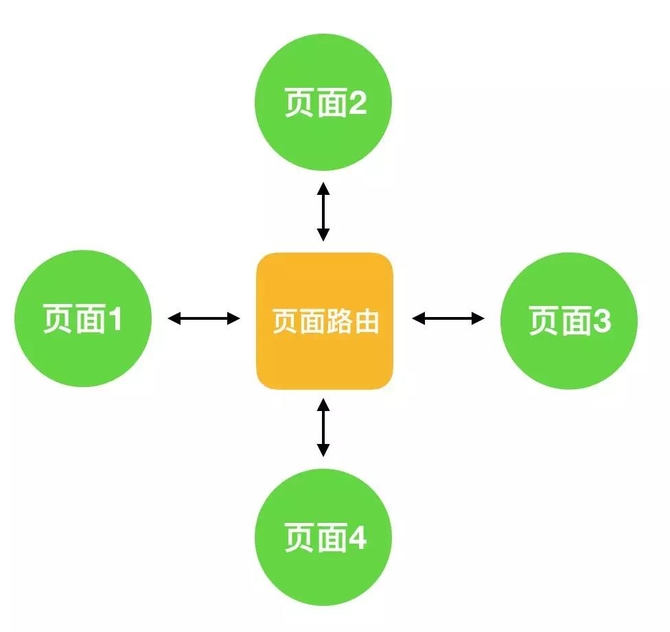
页面跳转路由统一处理页面跳转
对外卖App而言,使用过程中最多的就是页面间的跳转,而页面间跳转经常会造成ActivityNotFoundException,例如我们配了一个scheme,但对方的scheme路径已经发生了变化;又例如,我们调用手机上相册的功能,而相册应用已被用户自己禁用或移除了。解决这一类Crash,其实也很简单,只需要在startActivity增加ActivityNotFoundException异常捕获即可。但一个App里,启动Activity的地方,几乎是随处可见,无法预测哪一处会造成ActivityNotFoundException。
我们的做法是将页面的跳转,都通过我们封装的scheme路由去分发。这样的好处是,通过scheme路由,在工程架构上所有业务都是解耦,模块间不需要相互依赖就可以实现页面的跳转和基本类型参数的传递;同时,由于所有的页面跳转都会走scheme路由,我们只需要在scheme路由里一处加上ActivityNotFoundException异常捕获即可解决这种类型的Crash。路由设计示意图如下:
网络层统一处理API脏数据
客户端的很大一部分的Crash是因为API返回的脏数据。比如当API返回空值、空数组或返回不是约定类型的数据,App收到这些数据,就极有可能发生空指针、数组越界和类型转换错误等Crash。而且这样的脏数据,特别容易引起线上大面积的崩溃。
最早我们的工程的网络层用法是:页面监听网络成功和失败的回调,网络成功后,将JSON数据传递给页面,页面解析Model,初始化View,如图所示。这样的问题就是,网络虽然请求成功了,但是JSON解析Model这个过程可能存在问题,例如没有返回数据或者返回了类型不对的数据,而这个脏数据导致问题会出现在UI层,直接反应给用户。
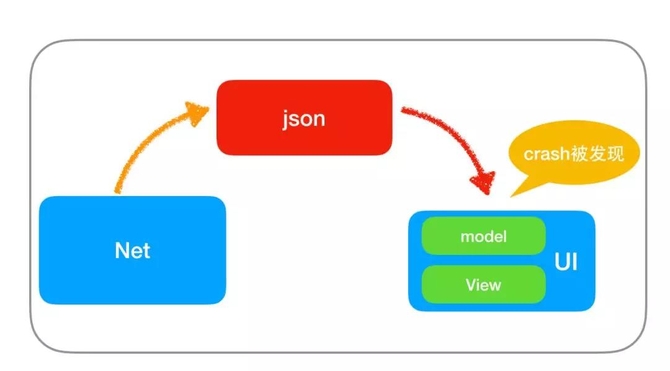
根据上图,我们可以看到由于网络层只承担了请求网络的职责,没有承担数据解析的职责,数据解析的职责交给了页面去处理。这样使得我们一旦发现脏数据导致的Crash,就只能在网络请求的回调里面增加各种判断去兼容脏数据。我们有几百个页面,补漏完全补不过来。通过几个版本的重构,我们重新划分了网络层的职责,如图所示:
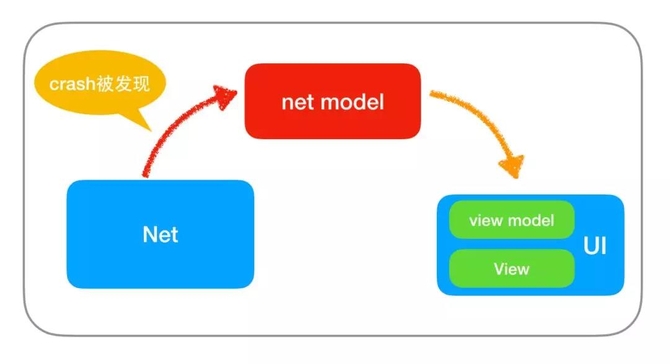
从图上可以看出,重构后的网络层负责请求网络和数据解析,如果存在脏数据的话,在网络层就会发现问题,不会影响到UI层,返回给UI层的都是校验成功的数据。这样改造后,我们发现这类的Crash率有了极大的改善。
大图监控
上面讲到大对象是导致OOM的主要原因之一,而Bitmap是App里最常见的大对象类型,因此对占用内存过大的Bitmap对象的监控就很有必要了。
我们用AOP方式Hook了三种常见图片库的加载图片回调方法,同时监控图片库加载图片时的两个维度:
加载图片使用的URL。外卖App中除静态资源外,所有图片都要求发布到专用的图片CDN服务器上,加载图片时使用正则表达式匹配URL,除了限定CDN域名之外还要求所有图片加载时都要添加对应的动态缩放参数。
最终加载出的图片结果(也就是Bitmap对象)。我们知道Bitmap对象所占内存和其分辨率大小成正比,而一般情况下在ImageView上设置超过自身尺寸的图片是没有意义的,所以我们要求显示在ImageView中的Bitmap分辨率不允许超过View自身的尺寸(为了降低误报率也可以设定一个报警阈值)。
开发过程中,在App里检测到不合规的图片时会立即高亮出错的ImageView所在的位置并弹出对话框提示ImageView所在的Activity、XPath和加载图片使用的URL等信息,如下图,辅助开发同学定位并解决问题。在Release环境下可以将报警信息上报到服务器,实时观察数据,有问题及时处理。

Lint检查
我们发现线上的很多Crash其实可以在开发过程中通过Lint检查来避免。Lint是Google提供的Android静态代码检查工具,可以扫描并发现代码中潜在的问题,提醒开发人员及早修正,提高代码质量。
但是Android原生提供的Lint规则(如是否使用了高版本API)远远不够,缺少一些我们认为有必要的检测,也不能检查代码规范。因此我们开始开发自定义Lint,目前我们通过自定义Lint规则已经实现了Crash预防、Bug预防、提升性能/安全和代码规范检查这些功能。如检查实现了Serializable接口的类,其成员变量(包括从父类继承的)所声明的类型都要实现Serializable接口,可以有效的避免NotSerializableException;强制使用封装好的工具类如ColorUtil、WindowUtil等可以有效的避免因为参数不正确产生的IllegalArgumentException和因为Activity已经finish导致的BadTokenException。
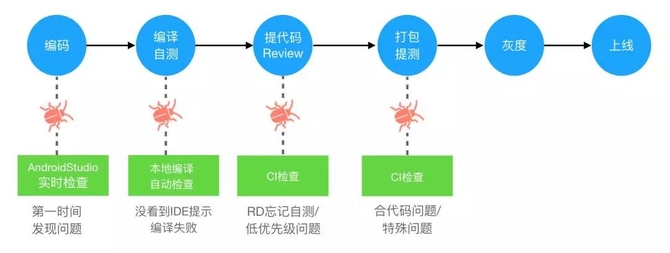
Lint检查可以在多个阶段执行,包括在本地手动检查、编码实时检查、编译时检查、commit时检查,以及在CI系统中提Pull
Request时检查、打包时检查等,如下图所示。更详细的内容可参考《美团外卖Android Lint代码检查实践》。
资源重复检查
在之前的文章《美团外卖Android平台化架构演进实践》中讲述了我们的平台化演进过程,在这个过程中大家很大的一部分工作是下沉,但是下沉不完全就会导致一些类和资源的重复,类因为有包名的限制不会出现问题。但是一些资源文件如layout、drawable等如果同名则下层会被上层覆盖,这时layout里view的id发生了变化就可能导致空指针的问题。
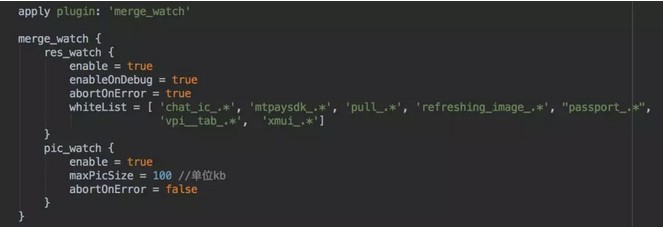
为了避免这种问题,我们写了一个Gradle插件通过hook MergeResource这个Task,拿到所有library和主库的资源文件,如果检查到重复则会中断编译过程,输出重复的资源名及对应的library
name,同时避免有些资源因为样式等原因确实需要覆盖,因此我们设置了白名单。同时在这个过程中我们也拿到了所有的的图片资源,可以顺手做图片大小的本地监控,如下图所示:
Crash的监控&止损的实践
监控
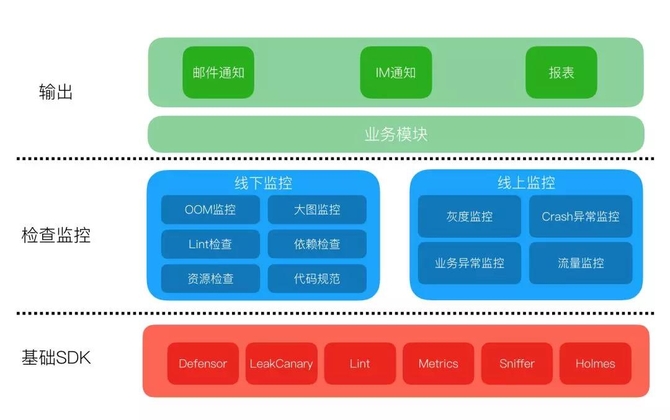
在经过前面提到的各种检查和测试之后,应用便开始发布了。我们建立了如下图的监控流程,来保证异常发生时能够及时得到反馈并处理。首先是灰度监控,灰度阶段是增量Crash最容易暴露的阶段,如果这个阶段没有很好的把握住,会使得增量变存量,从而导致Crash率上升。
如果条件允许的话,可以在灰度期间制定一些灰度策略去提高这个阶段Crash的暴露。例如分渠道灰度、分城市灰度、分业务场景灰度、新装用户的灰度等等,尽量覆盖所有的分支。灰度结束之后便开始全量,在全量的过程中我们还需要一些日常Crash监控和Crash率的异常报警来防止突发情况的发生,例如因为后台上线或者运营配置错误导致的线上Crash。除此之外还需要一些其他的监控,例如,之前提到的大图监控,来避免因为大图导致的OOM。具体的输出形式主要有邮件通知、IM通知、报表。
止损
尽管我们在前面做了那么多,但是Crash还是无法避免的,例如,在灰度阶段因为量级不够,有些Crash没有被暴露出来;又或者某些功能客户端比后台更早上线,而这些功能在灰度阶段没有被覆盖到;这些情况下,如果出现问题就需要考虑如何止损了。
问题发生时首先需要评估重要性,如果问题不是很严重而且修复成本较高可以考虑在下个版本再修复,相反如果问题比较严重,对用户体验或下单有影响时就必须要修复。修复时首先考虑业务降级,主要看该部分异常的业务是否有兜底或者A/B策略,这样是最稳妥也是最有效的方式。
如果业务不能降级就需要考虑热修复了,目前美团外卖Android App接入的热修复框架是自研的Robust,可以修复90%以上的场景,热修成功率也达到了99%以上。如果问题发生在热修复无法覆盖的场景,就只能强制用户升级。强制升级因为覆盖周期长,同时影响用户的体验,只在万不得已的情况下才会使用。
展望
Crash的自我修复
我们在做新技术选型时除了要考虑是否能满足业务需求、是否比现有技术更优秀和团队学习成本等因素之外,兼容性和稳定性也非常重要。但面对国内非富多彩的Android系统环境,在体量百万级以上的的App中几乎不可能实现毫无瑕疵的技术方案和组件,所以一般情况下如果某个技术实现方案可以达到0.01‰以下的崩溃率,而其他方案也没有更好的表现,我们就认为它是可以接受的。但是哪怕仅仅十万分之一的崩溃率,也代表还有用户受到影响,而我们认为Crash对用户来说是最糟糕的体验,尤其是涉及到交易的场景,所以我们必须本着每一单都很重要的原则,尽最大努力保证用户顺利执行流程。
实际情况中有一些技术方案在兼容性和稳定性上做了一定妥协的场景,往往是因为考虑到性能或扩展性等方面的优势。这种情况下我们其实可以再多做一些,进一步提高App的可用性。就像很多操作系统都有“兼容模式”或者“安全模式”,很多自动化机械机器都配套有手动操作模式一样,App里也可以实现备用的降级方案,然后设置特定条件的触发策略,从而达到自动修复Crash的目的。
举例来讲,Android 3.0中引入了硬件加速机制,虽然可以提高绘制帧率并且降低CPU占用率,但是在某些机型上还是会有绘制错乱甚至Crash的情况,这时我们就可以在App中记录硬件加速相关的Crash问题或者使用检测代码主动检测硬件加速功能是否正常工作,然后主动选择是否开启硬件加速,这样既可以让绝大部分用户享受硬件加速带来的优势,也可以保障硬件加速功能不完善的机型不受影响。还有一些类似的可以做自动降级的场景,比如:
部分使用JNI实现的模块,在SO加载失败或者运行时发生异常则可以降级为Java版实现。
RenderScript实现的图片模糊效果,也可以在失败后降级为普通的Java版高斯模糊算法。
在使用Retrofit网络库时发现OkHttp3或者HttpURLConnection网络通道失败率高,可以主动切换到另一种通道。
这类问题都需要根据具体情况具体分析,如果可以找到准确的判定条件和稳定的修复方案,就可以让App稳定性再上一个台阶。
特定Crash类型日志自动回捞
外卖业务发展迅速,即使我们在开发时使用各种工具、措施来避免Crash的发生,但Crash还是不可避免。线上某些怪异的Crash发生后,我们除了分析Crash堆栈信息之外,还可以使用离线日志回捞、下发动态日志等工具来还原Crash发生时的场景,帮助开发同学定位问题,但是这两种方式都有它们各自的问题。
离线日志顾名思义,它的内容都是预先记录好的,有时候可能会漏掉一些关键信息,因为在代码中加日志一般只是在业务关键点,在大量的普通方法中不可能都加上日志。动态日志(Holmes)存在的问题是每次下发只能针对已知UUID的一个用户的一台设备,对于大量线上Crash的情况这种操作并不合适,因为我们并不能知道哪个发生Crash的用户还会再次复现这次操作,下发配置充满了不确定性。
我们可以改造Holmes使其支持批量甚至全量下发动态日志,记录的日志等到发生特定类型的Crash时才上报,这样一来可以减少日志服务器压力,同时也可以极大提高定位问题的效率,因为我们可以确定上报日志的设备最后都真正发生了该类型Crash,再来分析日志就可以做到事半功倍。
总结
业务的快速发展,往往不可能给团队充足的时间去治理Crash,而Crash又是App最重要的指标之一。团队需要由一个个Crash个例,去探究每一个Crash发生的最本质原因,找到最合理解决这类Crash的方案,建立解决这一类Crash的长效机制,而不能饮鸩止渴。只有这样,随着版本的不断迭代,我们才能在Crash治理之路上离目标越来越近。
|









