| 引言
58 同城的搜索功能支撑了近一半的用户流量,所以搜索是一个很重要的模块。众所周知,iPhone 的搜索是通过
Spotlight 来实现的,那么在 App 内部是如何实现搜索呢?首先了解一下 58 同城的搜索需求:
1.58 同城首页,提供搜索功能,称为全站搜。
2.58 同城有二手物品、房产、二手车、招聘、黄页几大业务线,这是粗粒度的业务线。细分一下,二手可以拆分出二手物品、宠物等类别;房产拆分出租房、二手房等类别;招聘拆分出全职招聘、兼职等类别;黄页拆分出家政、本地服务等类别。拆分出的这些较细的类别的页面称之为大类页,这些大类页也提供搜索功能,称为大类搜。
3.大类页提供更细粒度的类别,如进入二手房大类页后会看到二手房、新房、商铺、厂房等入口,再次进入后是列表页,这些列表页也提供搜索功能,称为列表搜。
图 1 是旧的搜索框架,虽然看上去比较清晰,但实际上存在着很多问题,比如代码冗余、耦合度高、不易复用等。这些也是一些大型模块经过多次升级,到了后期经常存在的问题。接下来具体问题具体分析。
存在的问题
从最开始的 1.0 版本,就在首页实现了搜索功能。随着业务的扩展,58 的业务线也在逐渐成型和完善,每个业务线的大类页接入搜索功能也存在先后。业务线内部的列表页,更是多种多样,比如
Native 的类别页、Web 列表页,还有特殊的列表页(如简历库列表页、地图搜房页等),这些列表页后来也都一一实现了搜索功能。不过也正是因为实现的时间有先后,逐渐积累产生了一些历史遗留问题。
代码冗余
不同的业务页面对搜索功能的支持有先后之别,后实现搜索的页面都是先拷贝一份先实现搜索的代码,然后把其中的业务代码删除,加入自己的。旧版的业务入口页面各自实现了一套搜索逻辑(如图
2 所示),重复的代码超过一万行。
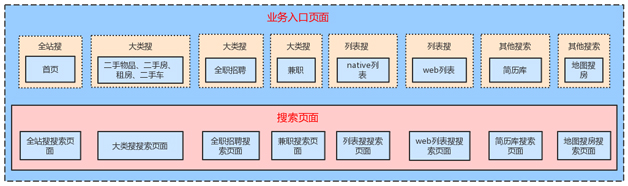
图 2 业务页面各自实现搜索页面
耦合度高
从图 1 可以看出,搜索页面是由业务入口页面管理和加载的。搜索页面要处理数据,包括热词和搜索历史的本地获取、服务器获取;要处理网络请求,包括关键词的联想请求、搜索请求;还要实现视图的协议方法。这些大量的逻辑都是在业务页面文件中实现的。
在代码管理上,尽管已经把搜索相关的代码剥离出来,单独放到了一个 Category
类别文件中,但实际上还是无法避免地跟业务页面逻辑耦合在一起。

1.文件级别。业务页面文件中,既有业务方法,又有搜索相关的方法;
2.方法级别。在同一个方法中,既有业务逻辑,又有搜索逻辑。这是更为严重的耦合。
搜索页面无法复用
因为搜索页面与业务页面耦合度高,所以业务入口页面无法复用以前的搜索页面,只能各自实现。相反的,越来越多的业务入口页面不再考虑搜索页面的复用性,只考虑自己独自实现,导致搜索页面越来越多,比以前更加难以复用和移植。
另一个无法复用的原因来自于搜索页面自身的定制化严重。搜索页面需要清楚地知道是否存在热词、搜索历史、联想结果等,然后定制显示视图,如图
3 所示是两个搜索页面的简化类图。搜索页面的列表协议方法均直接访问了搜索页面的属性,但其属性是与搜索业务直接相关的。全站搜中没有城市业务,而城市选择页搜页面也没有热词等业务,这样的定制导致搜索页面无法复用。
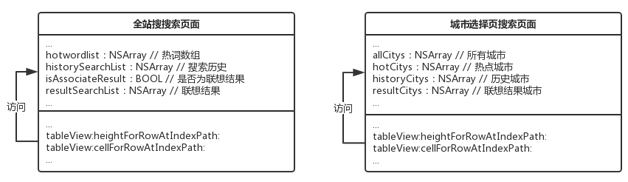
图 3 两个搜索页面的简化类图
业务功能接入成本高
业务功能接入成本高,表现在以下两个方面:
1.代码复用度低,开发成本高:业务页面想实现搜索页面成本高。前面已经介绍过了,搜索页面无法复用,业务页面需要自行实现一套搜索页面。
2.搜索页面与搜索结果页耦合性高:从搜索页面到搜索结果页之间的跳转只处理了固定页面的跳转。如果是列表页面接入搜索页面,只需要基于当前页面刷新即可。而全站搜和大类搜是最灵活的,根据搜索词可以跳转到所有业务线的落地页。但是
JumpManager 模块只处理了固定的页面跳转(如图 1,只有搜索类别页、搜索结果列表页),假如业务线想搜索后跳转到一个自定义的页面(如搜索“拼车”),JumpManager
是无法实现的。
这种只能跳转到固定、有限页面的跳转方式,限制了快速变化的业务需求。如果业务功能要接入一个新的跳转目标页面,需要发版才能实现,成本很高。
新搜索框架设计
针对上面的历史遗留问题,重新设计了搜索框架:
1.把搜索页面从业务入口页面中解耦出来,降低了耦合度;
2.实现了路由中心,让 App 内页面的跳转变得简单,降低了业务线接入成本;
3.实现了搜索页面的组件化,提高了搜索页面的复用性,减少了代码冗余。
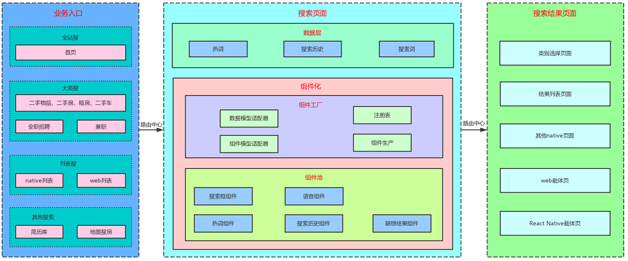
如图 4 所示是新搜索框架图。整体来说是从三个层级实现了搜索模块的组件化。最外层,通过路由中心,业务入口可以跳转到搜索页面,搜索页面可以跳转到更多的结果页面;中间层,搜索页面内部可以配置搜索框组件和语音组件;最内层是
UITableView 内部的组件化实现,列表中的元素根据数据可以灵活、动态地展示任意组合的样式,消去了逻辑判断和业务依赖。下面详细展开说明新框架。
搜索入口解耦
以前的搜索页面是在业务页面的视图控制器内加载的,搜索页面是一个 UIView,是业务页面的一个子视图。业务页面除了处理自身业务逻辑,还需要实现搜索页面的大量逻辑,导致视图控制器动辄几千行,难以维护,代码可读性较差,视图控制器逻辑太多、过于复杂。
新框架中,对搜索入口进行了解耦,方法是使用假搜输入框作为搜索入口,如图 5 所示的视图层级,用户能看到搜索框,也可以点击搜索框,但是无法输入字符,因为搜索框上面覆盖了一层透明的
UIButton 按钮。当用户点击输入框时,其实是触发了 UIButton 的 Target 方法,然后通过路由中心跳转到搜索页面。
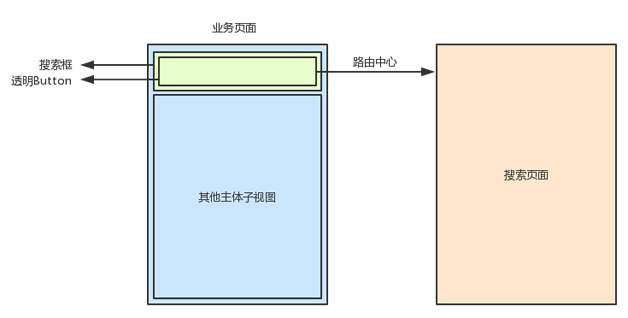
图 5 搜索入口解耦方式
搜索页面解耦
以前的搜索页面,数据和 UI 显示是耦合在一起的。UI 页面直接访问数据属性,因为需要了解显示的是什么数据模型、数据模型的
Class。其他业务页面很难去复用这样的搜索页面。
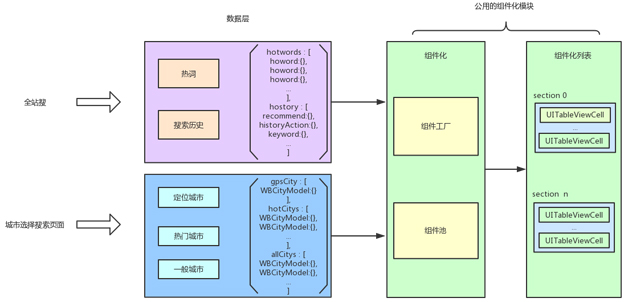
新搜索框架中,把搜索页面划分为两层,上层是数据层,是真正与业务有关的子模块;下层是组件层,与业务无关,是可以复用的模块。
1.数据层。每个业务页面需要的搜索功能是不用的,区别在于 UI 展示的数据不相同。数据层处理与数据有关的搜索业务逻辑,如数据的获取、缓存、网络请求等,除此之外还需要把数据组装到一个数组中。
2.组件层。搜索页面的组件化分为两层,外层是搜索框组件、语音组件的可配置化,内层是
UITableView 内部的组件化。组件化模块不需要了解数据的细节,只需要拿到数据层传来的数据,然后转化成组件来显示。
图 6 是全站搜和城市选择页面的搜索页面,两个页面的数据层处理各自的搜索逻辑,但是公用组件层,当组件显示到列表中的时候,列表不需要知道
Cell 的具体类型,只当作基类类型即可。
路由中心
旧的搜索框架,搜索完成后的跳转通过 JumpManager 实现,且只能跳转到有限的两种页面。虽然页面可以根据接口展现不同内容,但随着业务发展,旧搜索框架已无法满足。
比如,随着 iOS 系统的升级,App 开始支持 WKWebView,但是因为使用 UIWebView
页面的业务线还很多,所以需要长时间保持两者共存的方式。搜索关键词进入 Web 类型的结果页面时,如何控制
App 进入的是 WKWebView 类型的页面还是 UIWebView 类型的页面?
最初可能通过判断参数来实现。Server 返回的结果中有一个参数 webType,当值为 WKWebView
时采用 WKWebView 类型,否则采用 UIWebView 类型。但是当随着业务的增长,将会充斥着大量
if/else 的代码,各种问题接踵而至。
最终我们决定采用更加灵活的方式,即通过路由中心来实现。路由中心不但解决了搜索框架中页面跳转的难题,其他业务需求在页面跳转时遇到的问题也得以解决。
设计目标
1.使用简单。路由中心对使用方而言是一个黑盒子,使用方不需要关心如何实现;
2.支持多种应用场景。以图 7 中的 5 种场景,路由中心都可以处理,而且可以跳转到右侧的四种页面中的任意一个页面;
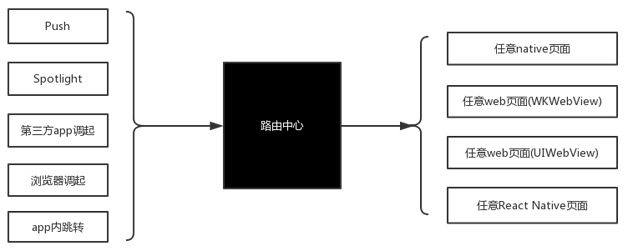
3.稳定、不轻易变化。因为需要支持 App 中所有页面的跳转,如果路由中心不稳定,将会造成很严重的后果;
4.扩展简单,易维护。业务发展很快,增加页面是常见的事,需要路由中心很容易实现对新页面的扩展。
如图 8 所示即是路由中心的设计图。
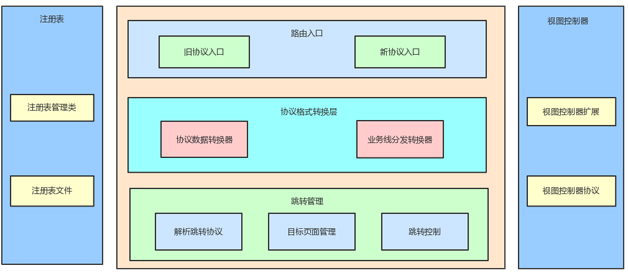
图 8 路由中心框架
路由入口
提供了两类路由入口方法,一类是针对新数据协议的 Scheme URL 路径类型的参数,另一类是针对旧数据协议的参数,如
Server 传送来的数据中还有很多在使用字典类型旧协议数据。
协议数据转换层
不同的路由入口,传入的数据格式不一样,如果不进行统一,后面的处理将会有两套逻辑,出现多个 if/else
的分支代码,代码冗余、升级维护麻烦。根据当前的使用频率和未来的发展方向,最终选择是把旧协议数据转换成新协议数据。
新协议规则
新旧协议中包含的字段是一样的,只是旧的跳转协议中,参数被放在了字典中,而新跳转协议中,参数是在一个长字符串中。为了把旧的跳转协议转换成新协议数据,制定了新跳转协议规则格式:
其中:
1.wbscheme:是 scheme,用于协议区分。外部调起时,区分是不是
58 的交互协议;
2.router:authority,用于业务区分。区分是不是跳起协议;
3.pagetype:属于 URL 的 Path,用于区分页面类别,如首页、列表页、详情页等;
4.tradeline:属于 URL 的 Path,用于区分业务线,如二手业务线,房产业务线,招聘业务线等等;
5.otherparams=JsonString:query 参数,表示跳转时需要携带的参数;
可以扩展其他字端,以解决跳转时页面关闭、是否登录等问题。
制定了协议规则之后,就可以把旧协议数据与新协议字段相对应了。数据转换工作是由转换器完成的。
业务线分发转换器
前面已经介绍了新旧跳转协议的参数对应关系,现在需要一个转换器把旧协议数据转换成新跳转协议。但是因为各业务线、主
App 主业务、其他创新业务等在跳转时,Server 传入的参数、需要的参数可能都不一样,所以需要多个转换器,根据业务线(trandline
参数),我们制定了如图 9 所示的多个转换器。
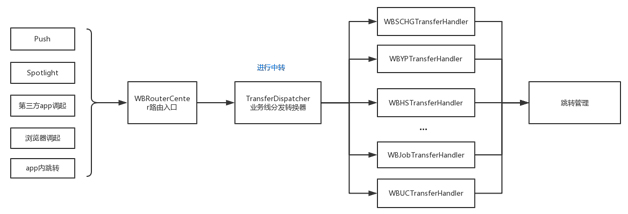
每一个转换器都是一个单例,并且都实现一个 -(NSString *)dispatchActionData:(NSDictionary
*)aJsonDic 方法,作用是把字典类型的旧协议数据转换为字符串类型的新协议数据。
根据 tradeline 参数,就可以在转换器映射表中得到其 ClassName,然后通过转换器调用
dispatchAction:方法,即可完成转换。
注册表
前面已经看到了跳转协议的数据格式,其中两个参数最重要:tradeline 和 pagetype,因为需要两个参数来定位一个视图控制器。
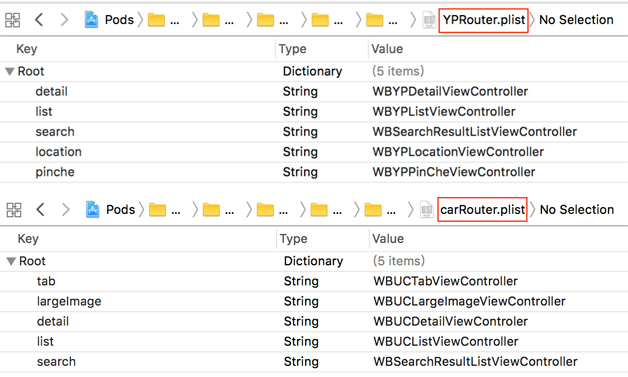
在同一个业务线的注册表中,key 与视图控制器唯一对应。不同的业务线,key
值可以重复。图 10 分别是黄页业务线和二手车业务线的注册表,其中 key 表示 pagetype,value
是视图控制器的 Class Name。
每一个转换器都是一个单例,并且都实现一个 -(NSString *)dispatchActionData:(NSDictionary
*)aJsonDic 方法,作用是把字典类型的旧协议数据转换为字符串类型的新协议数据。
根据 tradeline 参数,就可以在转换器映射表中得到其 ClassName,然后通过转换器调用
dispatchAction:方法,即可完成转换。
跳转管理
解析跳转协议
前面已经统一了跳转协议,所以在这里只需要解析一种格式的数据即可。解析后可以得到 tradeline
参数、pagetype 参数以及 param 字典。
目标页面管理
通过注册表可以基于 tradeline 参数和 pagetype 参数来定位一个唯一的视图控制器。所以在解析完跳转协议后,可以利用得到的
Class Name 通过运行时方法创建目标页面,最后把 param 参数传递给目标页面。
跳转控制
跳转控制可以通过 Native 代码或者 Server 来控制,如果未指定,则采用简单的 Push
方式跳转。路由中心支持以下 6 种方式:
简单的 Push 跳转到目标页:
跳转到目标页之前 pop 到上级页面;
跳转到目标页之前 PopToRootViewController;
通过 Present 的方式呈现目标页;
跳转前先登录,登录成功之后才能跳转;
跳转过程中没有动画。
这 6 种方式的跳转都可以在跳转协议中增加参数来控制,实现了跳转方式的多样性和灵活性。
视图控制器
视图控制器协议
在通过 Class Name 创建对象后,为了更统一地创建视图控制器、给视图控制器对象赋值,声明了一个协议。协议只有一个方法,注册表中的所有视图控制器都需要实现这个方法。
视图控制器扩展
通过注册表可以通过 tradeline 参数和 pagetype 参数来定位一个唯一的视图控制器。也就是说所有的目标页面都有属于自己的
tradeline 参数、pagetype 参数。无法给所有的目标页面增加这两个属性,也不能让所有的目标页面拥有同一个基类,更好的方式是增加一个
UIViewController 的扩展。
扩展中除了动态增加 tradeline、pagetype 两个属性外,还加入了跳转控制的中提及的一些参数作为属性,方便跳转控制。
搜索页面组件化
下面分别说明搜索页面内部组件化的两层。
搜索框组件、语音组件可配置
搜索页面中没有使用系统的导航栏,是为了更好地定制导航栏位置的搜索框视图。搜索页面把搜索框视图组装成一个组件,可以根据需求进行灵活配置。比如
58 同城 App 的 7.12.0 版本,全站搜的搜索框增加了一个前置类别选择框,这是一个新的搜索框组件,只需要在全站搜搜索页面替换搜索框组件即可,而不需要修改搜索页面的其他代码,影响最小。
语音组件也是可以配置的,如果某些业务页面的搜索页面不需要,则可以不显示该组件。
这两个组件的配置都是通过数据层根据业务来实现的。
下面着重说明 UITableView 内部的组件化。
数据模型适配器
数据模型适配器的作用是把原始数据转换成与业务有关的数据模型。原始数据可能来自于 Server,也可能是来自于本地缓存。原始数据一般不外乎
NSDictionary、NSArray,为了更好地操作数据,需要转换成已有的数据模型。
在搜索页面实现组件化,数据就是 Native 拼接的。比如在全站搜、大类搜中,就是把热词、搜索历史拼接为一个数组,然后交给数据模型工厂处理。数据模型工厂解析原始数据,然后输出数据
model 数组。
如图 11 是全站搜的数据模型适配器的输入和输出,输入的是热词和搜索历史数据,而经适配器转换之后,数据被转换为
{key : model} 字典组成的数组。保留 key 值,是为了使用 key 经过视图模型注册表得到对应
cell 的 Class Name,而 model 对象则是用来为 cell 赋值的。下面详细解析说明。
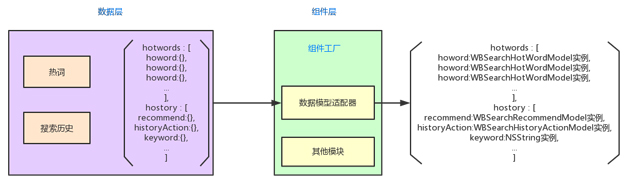
图 11 数据模型适配器的输入和输出
原始数据
传入的原始数据是一个数组,数组中的元素可能是数组,也可能是字典,如图 12 所示,左侧原始数组,都是字典形式,有
10 个字典,那么最后展现在 UITableView 中,section 数目为 1,row 数目为
10;而右侧原始数组中又包含了两个数组,说明 UITableView 中会有 2 个 section。其中第一个子数组只有
1 个元素,第二个子数组有 4 个元素,说明 UITableView 的两个 section 分别会有
1 个和 4 个 row。
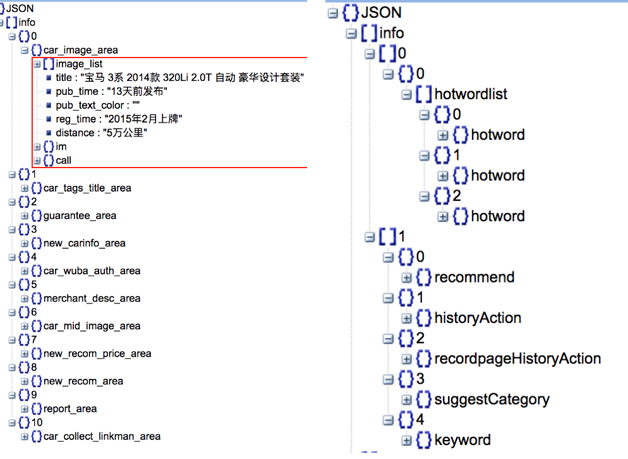
图 12 两个原始数据
原始数组中,还有一个很重要的参数是字典的 key 值,比如右侧原始数组中有一个 key:hotword,在数据模型映射表(如图
13 所示)中会存在对应这个 key 的一个数据 model:WBSearchHotWordModel。
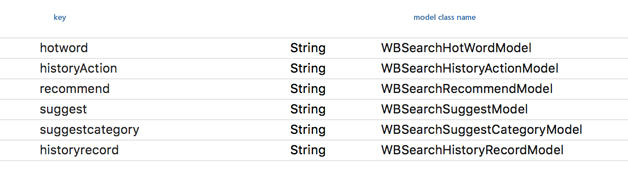
图 13 数据模型注册表
数据模型注册表
数据模型注册表是一个字典,在解析原始数据中,通过 key 值可以找到对应的数据 model 的 Class
Name,图 13 是搜索模块的数据模型注册表。
数据模型池
数据模型池不是一个类、文件、模块,而是多个数据 model 的集合。数据模型池至少包含了数据模型映射表中所需要的数据模型。
数据模型除了声明一些业务需要的属性之外,还需要实现一个解析方法 - (void)generateModelWithOriginalDict:(NSDictionary
*)dict。
数据模型转换
数据模型转换过程如下:
1.遍历原始数据数组,取出字典中的 key 值;
2.通过数据模型映射表,找到 key 对应的 Class Name;
3.创建数据模型 Class Name 的实例对象 model;
4.利用数据模型实现的 generateModelWithOriginalDict:传入数据;
5.把{key : model}这个字段作为元素加入到新的结果数组中;
6.遍历完成,返回新的结果数组。
视图模型适配器
数据是为视图服务的,得到数据模型数组后,就可以在页面展示了。组件是在 UITableView 中展示,所以大部分情况视图都是
UITableViewCell,如果视图工厂得到的视图不是 UITableViewCell,而是 UIView,则工厂会把
UIView 封装到 UITableViewCell 中。
视图模型注册表
视图模型注册表是一个字典,前面已经得到了数据模型数组,数组中每个元素都是一个{key : model}字典,通过
key 值可以找到对应的视图模型的 Class Name,图 14 是搜索模块的视图模型注册表。
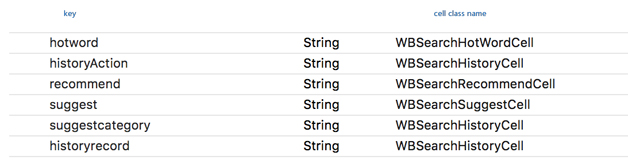
图 14 视图模型注册表
视图模型池
视图模型池不是一个类、文件、模块,而是多个视图的集合。视图模型池至少包含了视图模型映射表中所需要的视图模型。
视图模型除了声明一些业务需要的属性之外,还需要实现一个方法 - (void)configSubViewsWithModel:(id)model。对外暴露的方法只有一个,但实现上会根据
model 的具体数据类型,进行不同的处理。
组件模型转换
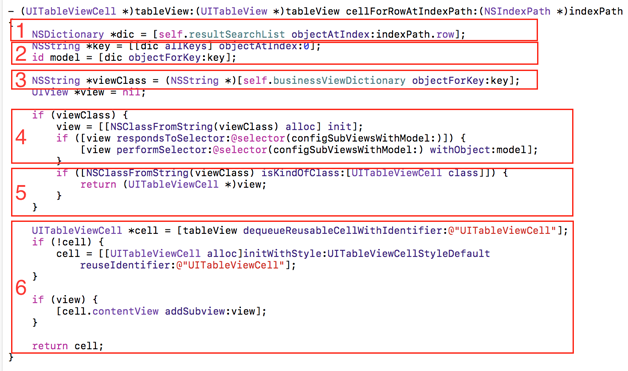
图 15 组件生产全过程
组件模型转换过程就是通过数据 key 值从视图模型池中查询模型 Class Name 的过程。如图
15 中的前 3 个步骤:
1.resultSearchList 是数据模型工厂的输出结果,其中每个元素都是一个{key
: model}字典;
2.获取到 indexPath.row 位置的元素,解析得到 key
和 model 数据;
3.通过 key 值,通过视图模型映射表得到视图的 Class Name。
组件生产
组件的生产过程就是通过数据模型适配器、视图摸适配器,得到视图的过程。
完成数据模型适配器的工作后,在 UITableView 的协议方法 tableView:cellForRowAtIndexPath:方法中实现视图的生成,如图
18 中的后面三个步骤:
1.根据 Class Name,生成视图对象,并且利用视图方法配置数据;
2.假如视图是 UITableViewCell 类型,则直接返回视图对象;
3.否则如果视图只是 UIView 类型,则把 view 加载到
UITableViewCell 中,然后返回 cell 实例。
如此,便生产出配置了数据的组件。
组件池
组件池是按照功能划分的,在搜索框架中,组件池中的组件是所有搜索页面可能使用的组件。其中每一个组件不但包括数据模型、视图模型,还包括注册表和适配器中的处理。如图
16 所示,前面的介绍从按照模块划分的,而每一个红框都是一个组件,如热词组件。
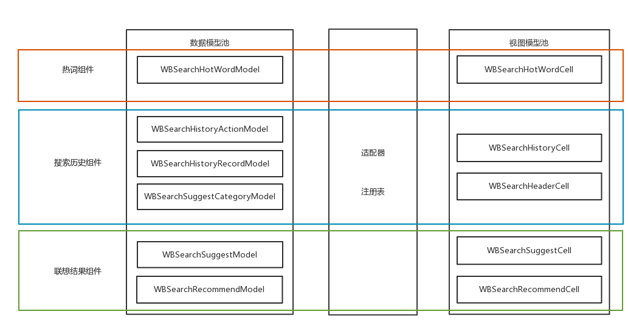
图 16 组件池
增加组件
随着业务发展和需求的增加,不可避免会需要增加一些新的组件。原则是能复用尽量复用,不能复用也不必要把组件做的太耦合。
1.首先按照接口数据,创建一个新的数据 model,包括属性和解析方法generateModelWithOriginalDict:;
2.在数据模型映射表中增加一个新的键值对,key 值不要重复,value
就是 model 的 Class Name;
3.根据 UI 图开发新的视图模型,并且完成对数据的配置方法 configSubViewsWithModel:
4.在视图模型映射表中增加一个新的键值对,key 值与 2 相同,value
就是 3 中新建的视图模型的 Class Name。
如此,便完成了组件的增加。之后可以根据数据的不同配置,让组件可以任意的排列组合。
总结
搜索框架的优化是一个持续的过程。当旧的框架无法满足业务的快速发展时,需要对搜索框架进行大规模的重构,来解决旧代码冗余、不易复用、不易移植、扩展难的问题;大部分情况下,是进行小规模的优化、扩展以满足需求的迭代。由此推广到其他的模块,其经验是通的。
1.模块/框架系统化设计。综合考虑各种可能会接入的业务以及当前业务的扩展。比如搜素模块从刚开始的一个业务线接入及定制化到多个业务线的接入及定制化,所带来系统的复杂性会有根本变化。设计的时候一定不要脱离具体的业务和问题,以解决具体的问题为出发点。
2.善用组件化。页面是一个盒子,组件是盒子里面的摆放的物品,数据指明把哪些物品如何摆放。人操作数据,每个人都可以在盒子里摆出任意排列的物品。所以数据是业务有关的,组件是通用的、可复用的、低耦合的。
3.及时优化和重构。不要把问题拖到最后,否则小范围的修改可能会产生大量的问题,问题会爆炸性地爆发,不得不做大规模重构。
|









