| Binder��ʵ���DZȽϸ��ӵģ���Ҫ��ȫŪ��������ôһ���£�������һ���������顣
������ǣ�浽�ü�����Σ�ÿһ�㶼��һЩģ��ͻ�����Ҫ���⡣�ⲿ������Ԥ�ƻ��Ϊ��ƪ���������⡣�����ǵ�һƪ�����Ȼ������Binder������һ���ܹ��ԵĽ��⣬Ȼ��Ὣ�־�����������Binder����������ĵIJ��֣�Binder������ʵ�֡�
Binder���Ƽ��
BinderԴ��Be Inc��˾������OpenBinder��ܣ������ÿ��ת�Ƶ�Palm Inc����Dianne
Hackborn����������OpenBinder���ں˲����Ѿ�����Linux Kernel 3.19��
Android Binder����OpneBinder�ϵĶ���ʵ�֡�ԭ�ȵ�OpenBinder��������Ѿ����ټ�������������˵Android�ϵ�Binder��ԭ�ȵ�OpneBinder�õ���������
Binder��Androidϵͳ�д���ʹ�õ�IPC��Inter-process communication�����̼�ͨѶ�����ơ�������Ӧ�ó����ϵͳ�����������Ӧ�ó��������ṩ���������Ҫʹ�õ�Binder��
��ˣ�Binder������Androidϵͳ�еĵ�λ�dz���Ҫ������˵������Binder������Androidϵͳ�ľ��Ա�Ҫǰ�ᡣ
��Unix/Linux�����£���ͳ��IPC���ư�����
1.�ܵ�
2.��Ϣ����
3.�����ڴ�
4.�ź���
5.Socket
����ƪ�����ޣ����IJ������ЩIPC���������⣬����Ȥ�Ķ��߿��Բ��ġ�UNIX������ ��2�����̼�ͨ�š���
Androidϵͳ�ж��ڴ�ͳ��IPCʹ�ý��٣���Ҳ��ʹ�ã����磺������Zygote fork���̵�ʱ��ʹ�õ���Socket
IPC�����ֳ�����ʹ�õ�IPC����Binder��
Binder����ڴ�ͳIPC��˵���ʺ���Androidϵͳ������ԭ��İ����������㣺
1.Binder������C/S�ܹ��ģ���һ�������Androidϵͳ�ļܹ�
2.�����ϸ������ƣ��ܵ�����Ϣ���У�Socket��ͨѶ����Ҫ�������ݿ�������Binderֻ��Ҫһ�Ρ�Ҫ֪��������ϵͳ�ײ��IPC��ʽ����һ�����ݿ��������������ܵ�Ӱ���Ƿdz�֮���
3.��ȫ�Ը��ã���ͳIPC��ʽ�����õ��Է������ݱ�ʶ��UID/GID)������ʹ��Binder
IPCʱ����Щ���ݱ�ʾ�Ǹ�����ù��̶��Զ����ݵġ�Server�˺����Ϳ���֪��Client�˵����ݣ��dz���������ȫ���
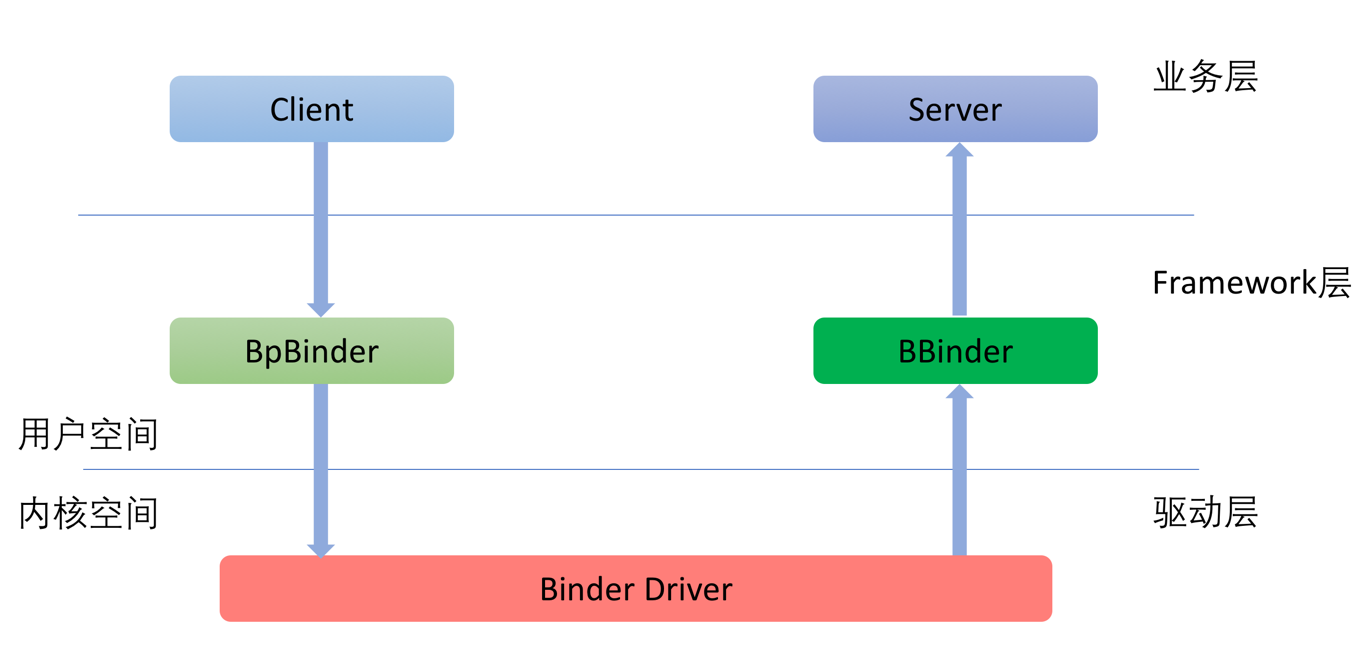
����ܹ�
Binder����ܹ�������ʾ��

��ͼ�п��Կ�����Binder��ʵ�ַ�Ϊ��ô���㣺
1.Framework��
2.Java����
3.JNI����
4.C++����
5.������
������λ��Linux�ں��У����ṩ����ײ�����ݴ��ݣ������ʶ���̹߳��������ù��̿��Ƶȹ��ܡ�������������Binder���Ƶĺ��ġ�
Framework����������Ϊ�������ṩ��Ӧ�ÿ����Ļ�����ʩ��
Framework��Ȱ�����C++���ֵ�ʵ�֣�Ҳ������Java���ֵ�ʵ�֡�Ϊ���ܽ�C++��ʵ�ָ��õ�Java�ˣ��м�ͨ��JNI�����νӡ�
�����߿�����Framework֮������Binder�ṩ�Ļ��������о����ҵ������������ʵ�������ǵ����������ߣ�Androidϵͳ�б���Ҳ�����˺ܶ�ϵͳ�����ǻ���Binder��ܿ����ġ�
��Ȼ�ǡ����̼䡱ͨѶ������ǣ�浽�������̣�Binder����ǵ��͵�C/S�ܹ����������У����ǰѷ��������֮ΪClient�������ʵ�ַ���֮ΪServer��
Client����Server������ᾭ��Binder����������´��ݵ��ں˵�Binder�����У������а�����Client��Ҫ���õ�����Ͳ�����������Binder����֮����ȷ���˷�����ṩ��֮���ٴ������Ͻ����ݸ�����ķ����������ù�������ͼ��ʾ��
������Э�������˽�Ķ��ᷢ�֣�������ݵĴ��ݹ��̺�����Э������˵����ơ�
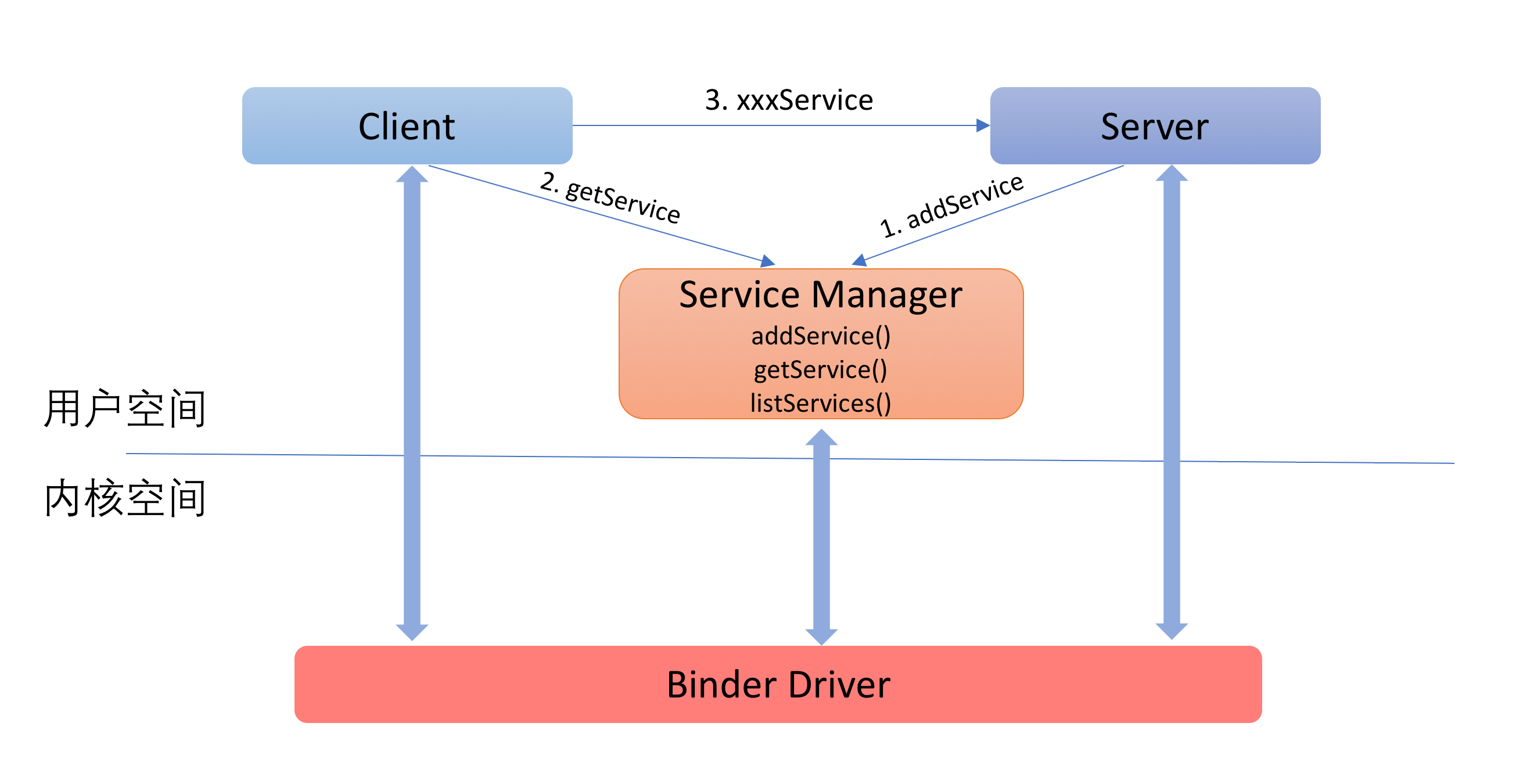
��ʶServiceManager
ǰ���Ѿ��ᵽ��ʹ��Binder��ܵļȰ���ϵͳ����Ҳ����������Ӧ�á���ˣ���ͬһʱ�̣�ϵͳ�л��д�����Serverͬʱ���ڡ���ô��Client������Server��ʱ�������ȷ����������һ��Server���أ�
������⣬�ͺ�������ʵ����������ҵ�һ����˾/�̳������ȷ��һ����/һ����һ��������ķ������ǣ�ÿ��Ŀ�������Ҫһ��Ψһ�ı�ʶ�����ң���Ҫ��һ����֯���������Ψһ�ı�ʶ��
��Binder����и�����������ʶ�ľ���ServiceManager��ServiceManager����Binder
Server�Ĺ����ͺñȳ��������ڳ��ƺ���ĵĹ������ɳ�����������֤����Ĺ�����ÿ�����������ṩ�����Server����Ҫע�ᵽServiceManager�У�ͨ��addService����ע���ʱ����Ҫָ��һ��Ψһ��id�����id��ʵ����һ���ַ�������
ClientҪ��Server�������ͱ���֪������˵�id��Client��Ҫ�ȸ���Server��idͨ��ServerManager�õ�Server�ı�ʾ��ͨ��getService����Ȼ��ͨ�������ʾ��Server����ͨ�š�
������������ͼ��ʾ��
���������Щ�����Ѿ�����һͷ��ˮ���벻Ҫ���ֵ��ģ��������ϸ���������е�ϸ�ڡ�
���Ļ������¶��ϵķ�ʽ������Binder��ܡ����¶���δ������õķ�����ÿ���˵�˼����ʽ��һ����������ϲ�����϶��µ����⣬��Ҳ��������˳�����Ķ���
���ڴ�����˵�����ǿ�����Ҫ�����IJ��IJ�����ȫ���⡣
������
Դ��·�����ⲿ�ִ��벻��AOSP�У�����λ��Linux�ں˴����У���
| /kernel/drivers/android/binder.c /kernel/include/uapi/linux/android/binder.h
|
����
| /kernel/drivers/staging/android/binder.c /kernel/drivers/staging/android/uapi/binder.h
|
Binder���Ƶ�ʵ���У�����ĵľ���Binder������ Binder��һ��miscellaneous���͵���������������Ӧ�κ�Ӳ�������еIJ������������㡣
binder_init��������Binder�����ij�ʼ���������ú����дִ�������ͨ��debugfs_create_dir��debugfs_create_file��������debugfs��Ӧ���ļ���
����ں��ڱ���ʱ����debugfs����ͨ��adb shell�����豸֮�������豸�����·���ҵ�debugfs��Ӧ���ļ���/sys/kernel/debug��Binder�����д�����debug�ļ�������ʾ��
| # ls -l /sys/kernel/debug/binder/ total 0 -r--r--r-- 1 root root 0 1970-01-01 00:00 failed_transaction_log drwxr-xr-x 2 root root 0 1970-05-09 01:19 proc -r--r--r-- 1 root root 0 1970-01-01 00:00 state -r--r--r-- 1 root root 0 1970-01-01 00:00 stats -r--r--r-- 1 root root 0 1970-01-01 00:00 transaction_log -r--r--r-- 1 root root 0 1970-01-01 00:00 transactions
|
��Щ�ļ���ʵ�����ڴ��еģ�ʵʱ�ķ�Ӧ�˵�ǰBinder��ʹ���������ʵ�ʵĿ��������У���Щ��Ϣ����æ�������⡣���磬����ͨ���鿴/sys/kernel/debug/binder/procĿ¼��ȷ����Щ��������ʹ��Binder��ͨ���鿴transaction_log��transactions�ļ���ȷ��Binderͨ�ŵ����ݡ�
binder_init����������Ҫ�Ĺ�����ʵ�������У�
| static struct miscdevice binder_miscdev = { .minor = MISC_DYNAMIC_MINOR, .name = "binder", .fops = &binder_fops };
|
���д����������ں���ע����Binder�豸��binder_miscdev�Ķ������£�
| static const struct file_operations binder_fops = { .owner = THIS_MODULE, .poll = binder_poll, .unlocked_ioctl = binder_ioctl, .compat_ioctl = binder_ioctl, .mmap = binder_mmap, .open = binder_open, .flush = binder_flush, .release = binder_release, };
|
����ָ����Binder�豸�������ǡ�binder�������������û��ռ�����ͨ����/dev/binder�ļ����в�����ʹ��Binder��
binder_miscdevͬʱҲָ���˸��豸��fops��fops������һ���ṹ�壬����ṹ�а�����һϵ�еĺ���ָ�룬�䶨�����£�
| static int binder_open(struct inode *nodp, struct file *filp) { struct binder_proc *proc;
// �������̶�Ӧ��binder_proc����
proc = kzalloc(sizeof(*proc), GFP_KERNEL);
if (proc == NULL)
return -ENOMEM;
get_task_struct(current);
proc->tsk = current;
// ��ʼ��binder_proc
INIT_LIST_HEAD(&proc->todo);
init_waitqueue_head(&proc->wait);
proc->default_priority = task_nice(current);
// ������
binder_lock(__func__);
binder_stats_created(BINDER_STAT_PROC);
// ���ӵ�ȫ���б�binder_procs��
hlist_add_head(&proc->proc_node, &binder_procs);
proc->pid = current->group_leader->pid;
INIT_LIST_HEAD(&proc->delivered_death);
filp->private_data = proc;
binder_unlock(__func__);
return 0;
} |
�������owner֮�⣬ÿһ���ֶζ���һ������ָ�룬��Щ����ָ���Ӧ���û��ռ���ʹ��Binder�豸ʱ�IJ��������磺binder_poll��Ӧ��pollϵͳ���õĴ�����binder_mmap��Ӧ��mmapϵͳ���õĴ�����������ͬ��
�����У�������������Ϊ��Ҫ�������ǣ�binder_open��binder_mmap��binder_ioctl��
������Ϊ����Ҫʹ��Binder�Ľ��̣�����������ͨ��binder_open��Binder�豸��Ȼ��ͨ��binder_mmap�����ڴ�ӳ�䡣
����֮��ͨ��binder_ioctl������ʵ�ʵIJ�����Client����Server�˵������Լ�Server����Client�������ķ��أ�����ͨ��ioctl��ɵġ�
�����ᵽ����������ͼ��ʾ��
��Ҫ�ṹ
Binder�����а����˺ܶ�Ľṹ�塣Ϊ�˱������Ľ��⣬���������ȶ���Щ�ṹ����һЩ���ܡ�
�����еĽṹ����Է�Ϊ���ࣺ
һ�������û��ռ乲�õģ���Щ�ṹ����Binderͨ��Э������л��õ�����ˣ���Щ�ṹ�嶨����binder.h�У�������
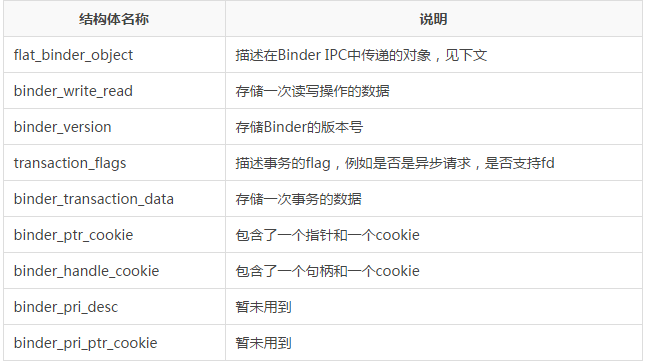
�����У�binder_write_read��binder_transaction_data�������ṹ����Ϊ��Ҫ�����Ǵ洢��IPC���ù����е����ݡ�������һ�㣬�����������лὲ�⡣
Binder�����У�����һ��ṹ���ǽ���Binder�����ڲ�ʵ�ֹ�������Ҫ�ģ����Ƕ�����binder.c�У�������
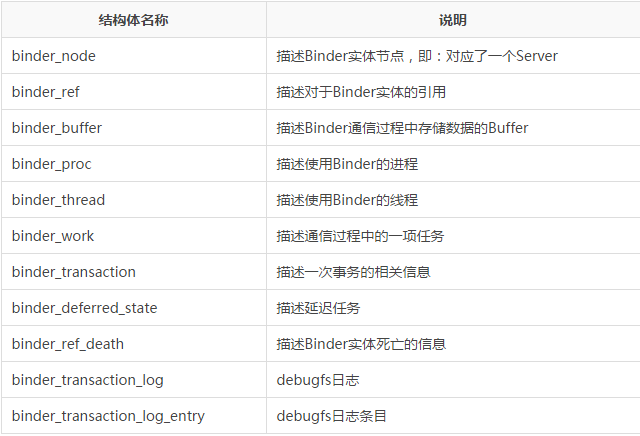
������Ҫ���߹�ע�Ľṹ���Ѿ��üӴ����˱�ע��
Binder��
BinderЭ����Է�Ϊ����Э�������Э�����ࡣ
����Э���ǽ���ͨ��ioctl(��/dev/binder��) ��Binder�豸����ͨѶ��Э�飬��Э��������¼������
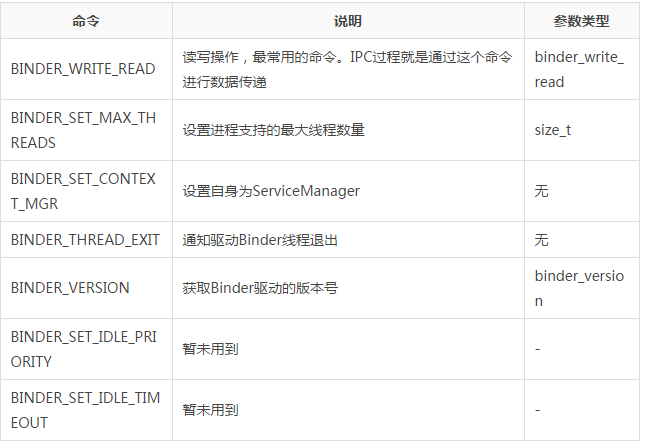
Binder������Э�������˶���Binder�����ľ���ʹ�ù��̡�����Э���ֿ��Է�Ϊ���ࣺ
һ����binder_driver_command_protocol�������˽��̷���Binder����������
һ����binder_driver_return_protocol��������Binder�����������̵�����
binder_driver_command_protocol������17������ֱ��ǣ�
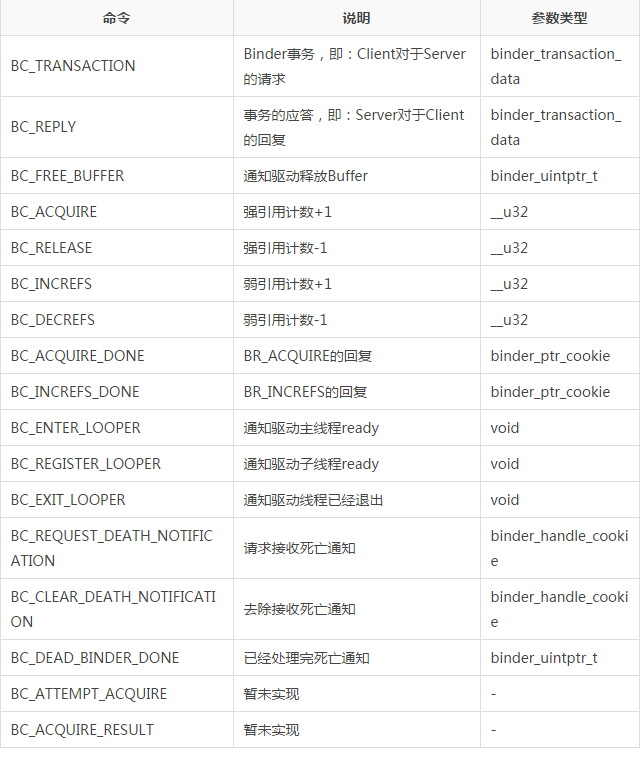
binder_driver_return_protocol������18������ֱ��ǣ�
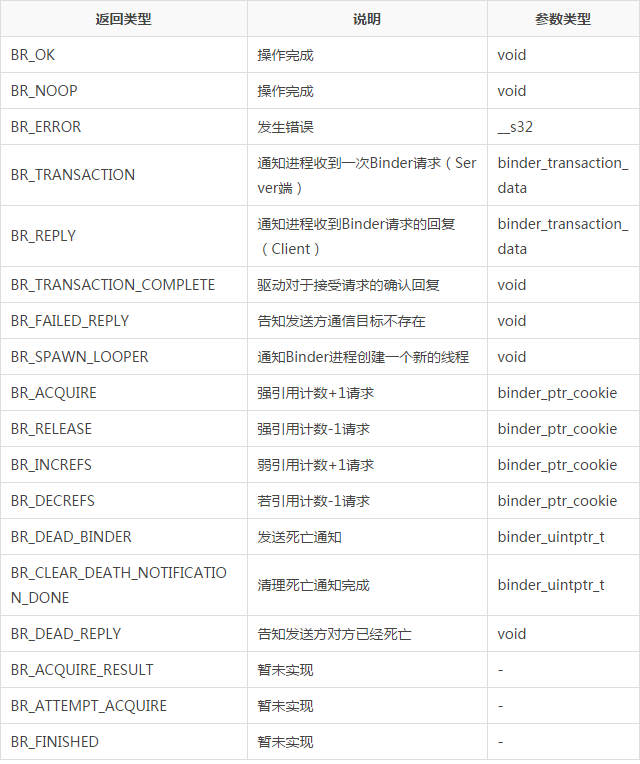
�����������Э����ܺ������⣬����������һ��Binder�����������ϸ��һ��BinderЭ�������ͨ�ŵģ��ͱȽϺ������ˡ�
���ͼ��˵�����£�

Binder��C/S�ܹ��ģ�ͨ�Ź���ǣ�浽��Client��Server�Լ�Binder����������ɫ
Client����Server�������Լ�Server����Client�ظ�����Ҫͨ��Binder��������ת����
BC_XXX�����ǽ��̷�������������
BR_XXX�����������������̵�����
����ͨ�Ź�����Binder��������
�����ٲ���˵��һ�£�ͨ�������BinderЭ���˵�������ǿ�����BinderЭ���ͨ�Ź����У��������Ƿ�������ͽ���������Щ���ͬʱ�����˶������ü����Ĺ����Ͷ�������֪ͨ�Ĺ�������֪һ����ͨѶ������һ���Ѿ��������ȹ��ܡ�
��Щ���ܵ�ͨ�Ź��̺��������ͼ�����Ƶģ�һ������BC_XXX��Ȼ������������ͨ�Ź��̣����ŷ��Ͷ�Ӧ��BR_XXX�����ͨ�ŵ�����һ������Ϊ���������ԣ�������Щ���ݾͲ������ˡ�
������������Щ����֪ʶ����֮�����ǾͿ��Խ��뵽Binder�������ڲ�ʵ������һ̽�����ˡ�
PS��������ܵ���Щ�ṹ���Э�飬��Ϊ���ݽ϶࣬���ο���Dz�ס�Ǻ������ģ���������ϸ�����ʱ�ع�ͷ��������Щ�����������DZȽ��а����ġ�
��Binder�豸
�κν�����ʹ��Binder֮ǰ������Ҫ��ͨ��open("/dev/binder")��Binder�豸�������Ѿ��ᵽ���û��ռ��openϵͳ���ö�Ӧ�������е�binder_open�����������������Binder������Ϊ���õĽ�����һЩ��ʼ��������binder_open��������������ʾ��
| static int binder_open(struct inode *nodp, struct file *filp) { struct binder_proc *proc;
// �������̶�Ӧ��binder_proc����
proc = kzalloc(sizeof(*proc), GFP_KERNEL);
if (proc == NULL)
return -ENOMEM;
get_task_struct(current);
proc->tsk = current;
// ��ʼ��binder_proc
INIT_LIST_HEAD(&proc->todo);
init_waitqueue_head(&proc->wait);
proc->default_priority = task_nice(current);
// ������
binder_lock(__func__);
binder_stats_created(BINDER_STAT_PROC);
// ���ӵ�ȫ���б�binder_procs��
hlist_add_head(&proc->proc_node, &binder_procs);
proc->pid = current->group_leader->pid;
INIT_LIST_HEAD(&proc->delivered_death);
filp->private_data = proc;
binder_unlock(__func__);
return 0;
} |
��Binder�����У�ͨ��binder_procs��¼������ʹ��Binder�Ľ��̡�ÿ�����δ�Binder�豸�Ľ��̶��ᱻ���ӵ�����б��еġ�
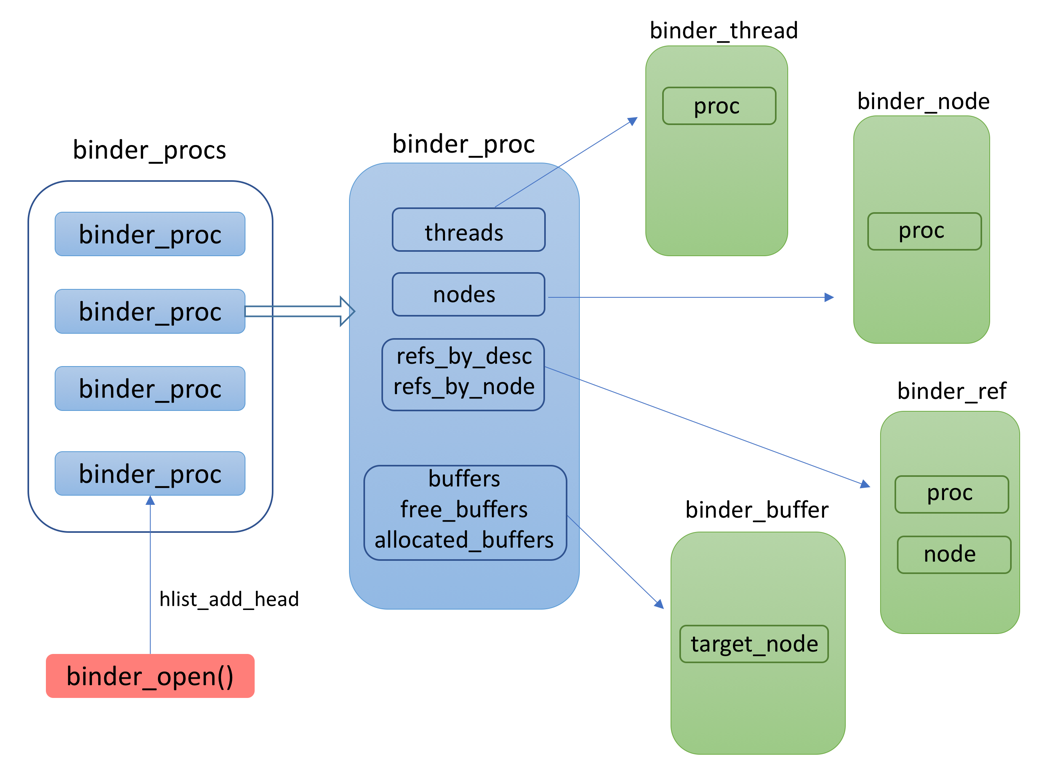
���⣬����ع�һ�����Ľ��ܵ�Binder�����еļ����ؼ��ṹ�壺
1.binder_proc
2.binder_node
3.binder_thread
4.binder_ref
5.binder_buffer
��ʵ�ֹ����У�Ϊ�˱��ڲ��ң���Щ�ṹ�廥��֮�䶼�����ֶδ洢�����Ľṹ��
�������ͼ����������˵������Щ���ݣ�
�ڴ�ӳ�䣨mmap��
�ڴ�Binder�豸֮���̻���ͨ��mmap�����ڴ�ӳ�䡣mmap������������������
����һ���ڴ�ռ䣬��������Binderͨ�Ź����е�����
������ڴ���е�ַӳ�䣬�Ա㽫������
binder_mmap������Ӧ��mmapϵͳ���õĴ������������Ҳ��Binder�����ľ������ڣ�����˵��binder_mmap����Ҳ�������ڲ����õ�binder_update_page_range�����������ģ���
ǰ������˵����ʹ��Binder���ƣ�����ֻ��Ҫ����һ�ο����Ϳ����ˣ���ԭ��������������С�
binder_mmap��������У�������һ�������ڴ棬Ȼ�����û��ռ���ں˿ռ�ͬʱ��Ӧ������ڴ��ϡ�����֮����ClientҪ�������ݸ�Server��ʱ��ֻ��һ�Σ���Client�����������ݿ�����Server�˵��ں˿ռ�ָ�����ڴ��ַ���ɣ���������ڴ��ַ�ڷ�����Ѿ�ͬʱӳ�䵽�û��ռ䣬�����������һ�θ��ƣ�Server����ֱ�ӷ��ʣ�������������ͼ��ʾ��

���ͼ��˵�����£�
Server������֮���ö�/dev/binder�豸����mmap
�ں��е�binder_mmap�������ж�Ӧ�Ĵ���������һ�������ڴ棬Ȼ�����û��ռ���ں˿ռ�ͬʱ����ӳ��
Clientͨ��BINDER_WRITE_READ�����������������ȵ������У�ͬʱ��Ҫ�����ݴ�Client���̵��û��ռ俽�����ں˿ռ�
����ͨ��BR_TRANSACTION֪ͨServer���˷�������Server���д�������������ڴ�Ҳ���û��ռ������ӳ�䣬���Server���̵Ĵ������ֱ�ӷ���
�˽�ԭ��֮������������һ��Binder���������Դ�롣��δ���������������
binder_mmap������Ӧ��mmap��ϵͳ���õĴ���
binder_update_page_range��������ʵ�����ڴ����͵�ַӳ��
| static int binder_mmap(struct file *filp, struct vm_area_struct *vma) { int ret;
struct vm_struct *area;
struct binder_proc *proc = filp->private_data;
const char *failure_string;
struct binder_buffer *buffer;
...
// ���ں˿ռ��ȡһ���ַ��Χ
area = get_vm_area(vma->vm_end - vma->vm_start,
VM_IOREMAP);
if (area == NULL) {
ret = -ENOMEM;
failure_string = "get_vm_area";
goto err_get_vm_area_failed;
}
proc->buffer = area->addr;
// ��¼�ں˿ռ����û��ռ�ĵ�ַƫ��
proc->user_buffer_offset = vma->vm_start
- (uintptr_t)proc->buffer;
mutex_unlock(&binder_mmap_lock);
...
proc->pages = kzalloc(sizeof(proc->pages[0])
* ((vma->vm_end - vma->vm_start) / PAGE_SIZE),
GFP_KERNEL);
if (proc->pages == NULL) {
ret = -ENOMEM;
failure_string = "alloc page array";
goto err_alloc_pages_failed;
}
proc->buffer_size = vma->vm_end - vma->vm_start;
vma->vm_ops = &binder_vm_ops;
vma->vm_private_data = proc;
/* binder_update_page_range assumes preemption
is disabled */
preempt_disable();
// ͨ���������������������ڴ������͵�ַ��ӳ��
// ����ʹ�ã�������һ��PAGE_SIZE��С���ڴ�
ret = binder_update_page_range(proc, 1, proc->buffer,
proc->buffer + PAGE_SIZE, vma);
...
}
static int binder_update_page_range(struct binder_proc
*proc, int allocate,
void *start, void *end,
struct vm_area_struct *vma)
{
void *page_addr;
unsigned long user_page_addr;
struct vm_struct tmp_area;
struct page **page;
struct mm_struct *mm;
...
for (page_addr = start; page_addr < end;
page_addr += PAGE_SIZE) {
int ret;
struct page **page_array_ptr;
page = &proc->pages[(page_addr - proc->buffer)
/ PAGE_SIZE];
BUG_ON(*page);
// ���������ڴ�ķ���
*page = alloc_page(GFP_KERNEL | __GFP_HIGHMEM
| __GFP_ZERO);
if (*page == NULL) {
pr_err("%d: binder_alloc_buf failed for page
at %p\n",
proc->pid, page_addr);
goto err_alloc_page_failed;
}
tmp_area.addr = page_addr;
tmp_area.size = PAGE_SIZE + PAGE_SIZE /* guard
page? */;
page_array_ptr = page;
// ���ں˿ռ�����ڴ�ӳ��
ret = map_vm_area(&tmp_area, PAGE_KERNEL,
&page_array_ptr);
if (ret) {
pr_err("%d: binder_alloc_buf failed to map
page at %p in kernel\n",
proc->pid, page_addr);
goto err_map_kernel_failed;
}
user_page_addr =
(uintptr_t)page_addr + proc->user_buffer_offset;
// ���û��ռ�����ڴ�ӳ��
ret = vm_insert_page(vma, user_page_addr, page[0]);
if (ret) {
pr_err("%d: binder_alloc_buf failed to map
page at %lx in userspace\n",
proc->pid, user_page_addr);
goto err_vm_insert_page_failed;
}
/* vm_insert_page does not seem to increment the
refcount */
}
if (mm) {
up_write(&mm->mmap_sem);
mmput(mm);
}
preempt_disable();
return 0;
...
|
�ڿ��������У����ǿ���ͨ��procfs��������ӳ�������ڴ�ռ䣺
��Android�豸���ӵ�������֮��ͨ��adb shell���뵽�ն�
Ȼ��ѡ��һ��ʹ����Binder�Ľ��̣�����system_server������ϵͳ��һ���dz���Ҫ�Ľ��̣���һ�����ǻ�ר�Ž��⣩��ͨ��
ps | grep system_server��ȷ�����̺ţ�������1889
ͨ�� cat /proc/[pid]/maps | grep "/dev/binder"
���˳�����ڴ�ĵ�ַ
���ҵ�Nexus 6P�ϣ�����̨������£�
| angler:/ # ps | grep system_server system 1889 526 2353404 140016 SyS_epoll_ 72972eeaf4 S system_server angler:/ # cat /proc/1889/maps | grep "/dev/binder" 7294761000-729485f000 r--p 00000000 00:0c 12593
|
PS��grep��ͨ��ͨ�������ƥ����˵������|����Unix�ϵĹܵ��������ǰһ��������������һ��������Ϊ���롣����������Dz��ӡ�
| grep xxx������ô������ǰһ����������������
�ڴ�Ĺ���
�����У����ǿ���binder_mmap��ʱ������һ��PAGE_SIZE(ͨ����4K)���ڴ档��ʵ��ʹ�ù����У�һ��PAGE_SIZE�Ĵ�Сͨ���Dz����ġ�
�������У������ʵ�ʵ�ʹ����������ڴ�ķ��䡣���ڴ�ķ��䣬��ȻҲ��Ҫ�ڴ���ͷš��������Ǿ�������Binder����������ν����ڴ�Ĺ����ġ�
���ȣ����ǻ��Ǵ�һ��IPC����˵��
��һ��Client��Ҫ��Server��������ʱ�������Ƚ������͵�Binder�豸�ϣ���Binder���������������Ϣ�ҵ���Ӧ��Ŀ��ڵ㣬Ȼ���������ݴ��ݹ�ȥ��
����ͨ��ioctlϵͳ��������������ioctl(mProcess->mDriverFD, BINDER_WRITE_READ,
&bwr)
PS�����д���������Framework���IPCThreadState�ࡣ�ں����У����ǽ�������IPCThreadState��ר�Ÿ�������������ͨ�š�
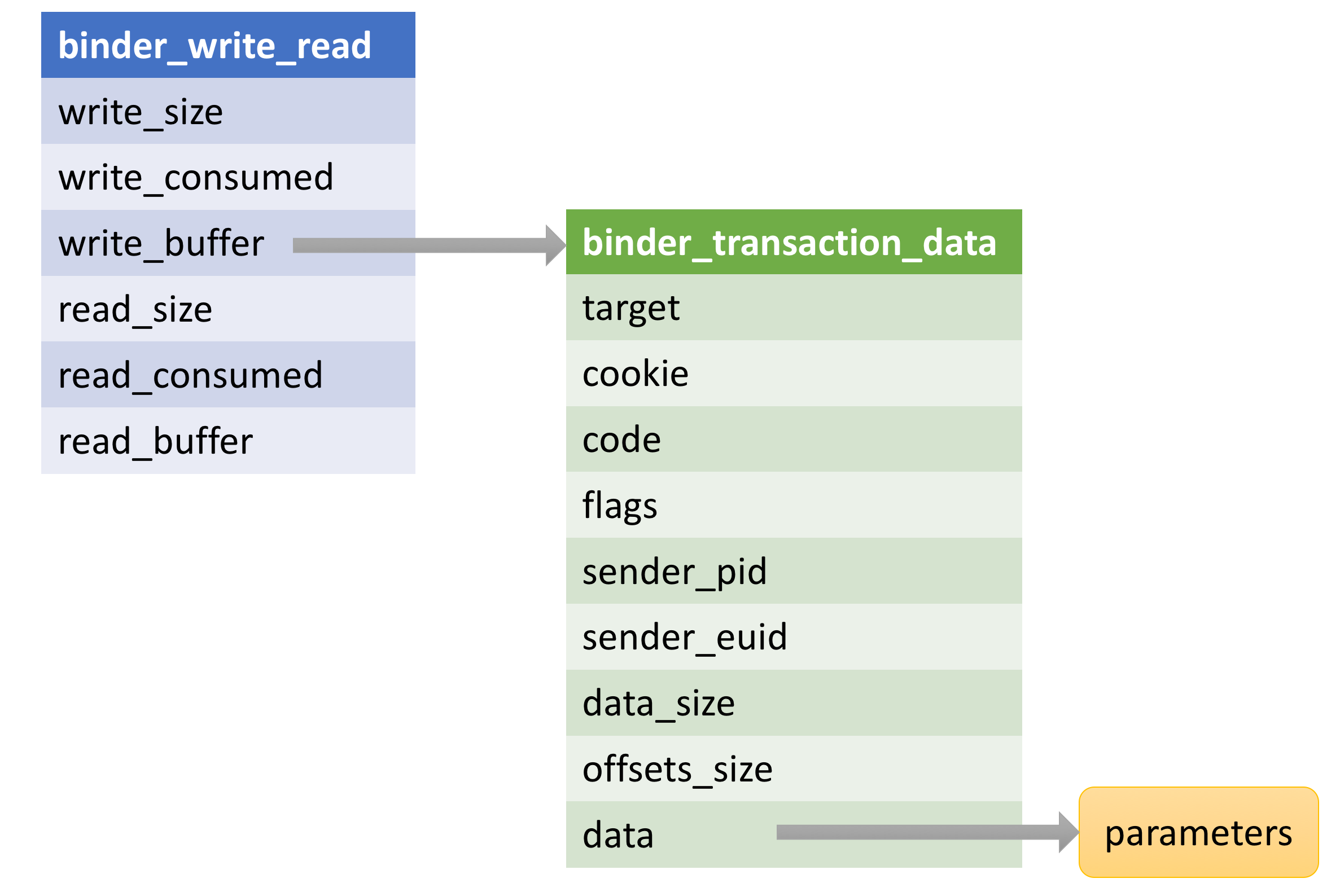
�����mProcess->mDriverFD��Ӧ�˴�Binder�豸ʱ��fd��BINDER_WRITE_READ��Ӧ�˾���Ҫ���IJ����룬��������뽫��Binder����������bwr�洢���������ݣ���������binder_write_read��
binder_write_read��ʵ��һ������������ݽṹ�����ڲ������һ��binder_transaction_data�ṹ�����ݡ�binder_transaction_data�����˷��������ߵı�ʶ�������Ŀ������Լ���������Ҫ�IJ��������ǵĹ�ϵ����ͼ��ʾ��
binder_ioctl������Ӧ��ioctlϵͳ���õĴ�����������������Ƚϼ����Ǹ���ioctl��������ȷ����һ��������������������:
���������BINDER_WRITE_READ������
��� bwr.write_size > 0�������binder_thread_write
��� bwr.read_size > 0�������binder_thread_read
���������BINDER_SET_MAX_THREADS�������ý��̵�max_threads��������֧�ֵ�����߳���
���������BINDER_SET_CONTEXT_MGR�������õ�ǰ����ΪServiceManager��������
���������BINDER_THREAD_EXIT�������binder_free_thread���ͷ�binder_thread
���������BINDER_VERSION���ص�ǰ��Binder�汾��
�����У���ؼ��ľ���binder_thread_write��������Client����Server��ʱ��ᷢ��һ��BINDER_WRITE_READ���ͬʱ��ܻὫ��ʵ�ʵ����ݰ�װ�á���ʱ��binder_transaction_data�е�code����BC_TRANSACTION���ɴ˱����õ�binder_transaction��������������Ƕ�һ��Binder����Ĵ����������л����binder_alloc_buf����Ϊ�˴���������һ�����档�����ᵽ�����ù�ϵ���£�
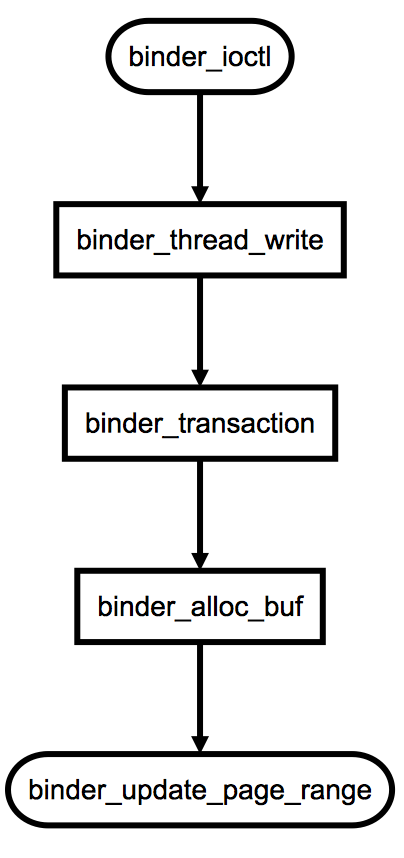
binder_update_page_range��������������У������Ѿ��������ˡ������þ��ǣ������ڴ���䲢������ڴ��ӳ�䡣��binder_alloc_buf���������������������ģ���ɻ���ķ��䡣
�������У�ͨ��binder_buffer�ṹ���������档һ��Binder����ͻ��Ӧһ��binder_buffer����ṹ������ʾ��
| struct binder_buffer { struct list_head entry; struct rb_node rb_node;
unsigned free:1;
unsigned allow_user_free:1;
unsigned async_transaction:1;
unsigned debug_id:29;
struct binder_transaction *transaction;
struct binder_node *target_node;
size_t data_size;
size_t offsets_size;
uint8_t data[0];
}; |
����binder_proc��������ʹ��Binder�Ľ��̣��У������˼����ֶ���������������Binder
IPC�����л��棬���£�
| struct binder_proc { ... struct list_head buffers; // ����ӵ�е�buffer�б� struct rb_root free_buffers; // ����buffer�б� struct rb_root allocated_buffers; // ��ʹ�õ�buffer�б� size_t free_async_space; // ʣ����첽���õĿռ�
size_t buffer_size; // ���������
...
}; |
������mmapʱ�����趨֧�ֵ��ܻ����С�����ޣ����Ļὲ������������ÿ���յ�BC_TRANSACTION���ͻ��ж���ʹ�û���ӱ�������ĺ���û�г������ޡ����û�У��Ϳ��ǽ����ڴ�ķ��䡣
���̵Ŀ��л����¼��binder_proc��free_buffers�У�����һ���Ժ������ʽ�洢�Ľṹ��ÿ�γ��Է��仺���ʱ��������水��С˳����в��ң��ҵ���ӽ���Ҫ��һ�黺�档���ҵ������£�
| while (n) { buffer = rb_entry(n, struct binder_buffer, rb_node); BUG_ON(!buffer->free); buffer_size = binder_buffer_size(proc, buffer);
if (size < buffer_size) {
best_fit = n;
n = n->rb_left;
} else if (size > buffer_size)
n = n->rb_right;
else {
best_fit = n;
break;
}
} |
�ҵ�֮����Ҫ��binder_proc�е��ֶν�����Ӧ�ĸ��£�
| rb_erase(best_fit, &proc->free_buffers); buffer->free = 0; binder_insert_allocated_buffer(proc, buffer); if (buffer_size != size) { struct binder_buffer *new_buffer = (void *)buffer->data + size; list_add(&new_buffer->entry, &buffer->entry); new_buffer->free = 1; binder_insert_free_buffer(proc, new_buffer); } binder_debug(BINDER_DEBUG_BUFFER_ALLOC, "%d: binder_alloc_buf size %zd got %p\n", proc->pid, size, buffer); buffer->data_size = data_size; buffer->offsets_size = offsets_size; buffer->async_transaction = is_async; if (is_async) { proc->free_async_space -= size + sizeof(struct binder_buffer); binder_debug(BINDER_DEBUG_BUFFER_ALLOC_ASYNC, "%d: binder_alloc_buf size %zd async free %zd\n", proc->pid, size, proc->free_async_space); }
|
�����������������ڴ���ͷš�
BC_FREE_BUFFER������֪ͨ���������ڴ���ͷţ�binder_free_buf����������ʵ�ֵ��������������binder_alloc_buf�Ǹպö�Ӧ�ġ�����������У����������������
���¼�����̵Ŀ��л����С
ͨ��binder_update_page_range�ͷ��ڴ�
����binder_proc��buffers��free_buffers��allocated_buffers�ֶ�
Binder�еġ��������
Binder���Ƶ����˽��̵ı߽磬ʹ�ÿ�Խ����Ҳ�ܹ����õ�ָ������ķ�������ԭ������ΪBinder�����ڵײ㴦�����ڽ��̼�ġ������ݡ�
��Binder�����У���������Ľ������ڽ��̼��������л�������ͨ���ض��ı�ʶ�����ж���Ĵ��ݡ�Binder�����У�ͨ��flat_binder_object��������Ҫ��Խ���̴��ݵĶ����䶨�����£�
| struct flat_binder_object { __u32 type; __u32 flags;
union {
binder_uintptr_t binder; /* local object */
__u32 handle; /* remote object */
};
binder_uintptr_t cookie;
}; |
�����У�type������5�����͡�
| enum { BINDER_TYPE_BINDER = B_PACK_CHARS('s', 'b', '*', B_TYPE_LARGE), BINDER_TYPE_WEAK_BINDER = B_PACK_CHARS('w', 'b', '*', B_TYPE_LARGE), BINDER_TYPE_HANDLE = B_PACK_CHARS('s', 'h', '*', B_TYPE_LARGE), BINDER_TYPE_WEAK_HANDLE = B_PACK_CHARS('w', 'h', '*', B_TYPE_LARGE), BINDER_TYPE_FD = B_PACK_CHARS('f', 'd', '*', B_TYPE_LARGE), };
|
�����ݵ�Binder�����е�ʱ�������������з���ͽ��ͣ�Ȼ�ݵ����յĽ��̡�
���統Server��Binderʵ�崫�ݸ�Clientʱ���ڷ����������У�flat_binder_object�е�type��BINDER_TYPE_BINDER��ͬʱbinder�ֶ�ָ��Server�����û��ռ��ַ���������ַ����Client������û������ģ�Linux�У�ÿ�����̵ĵ�ַ�ռ��ǻ������ģ�������������������е�flat_binder_object����Ӧ�ķ��룺��type�ó�BINDER_TYPE_HANDLE��Ϊ���Binder�ڽ��ս����д���λ���ں��е����ò������ú�����handle�С����ڷ������������������͵�BinderҲҪ��ͬ��ת����������������ս��̴���������ȡ�õ�Binder���ò�����Ч�ģ��ſ��Խ����������ݰ�binder_transaction_data��target.handle����Binderʵ�巢������
����ÿ�����������ķ��ض��ᾭ���ں˵ķ��룬���������̴ӽ��̵ĽǶ���������ȫ���ġ�������ȫ���ø�֪������̣��ͺ����������ڽ��̼����ش���һ����
��������̹߳���
���Ķ���ᵽ��Binder������C/S�ܹ�����Server�ṩ����Clientʹ�á���Ȼ��C/S�ܹ����Ϳ��ܴ��ڶ��Client��ͬʱ����Server�������
����������£����Serverֻ��һ���̴߳�����Ӧ���ͻᵼ�¿ͻ��˵����������Ҫ�ŶӶ�������Ӧ������������������������ķ�������������̡߳�
Binder���Ƶ���ƴ���ײ�C�����㣬�Ϳ��ǵ��˶��ڶ��̵߳�֧�֡������������£�
ʹ��Binder�Ľ���������֮��ͨ��BINDER_SET_MAX_THREADS��֪������֧�ֵ�����߳�����
��������߳̽��й�������binder_proc�ṹ�У���Щ�ֶμ�¼�˽������̵߳���Ϣ��max_threads��requested_threads��requested_threads_started��ready_threads
binder_thread�ṹ��Ӧ��Binder�����е��߳�
����ͨ��BR_SPAWN_LOOPER�����֪������Ҫ����һ���µ��߳�
����ͨ��BC_ENTER_LOOPER�����֪���������߳��Ѿ�ready
����ͨ��BC_REGISTER_LOOPER�����֪���������̣߳������̣߳��Ѿ�ready
����ͨ��BC_EXIT_LOOPER�����֪�������߳̽�Ҫ�˳�
���߳��˳�֮��ͨ��BINDER_THREAD_EXIT��֪Binder��������������Ӧ��binder_thread��������
����ServiceManager
�����Ѿ�˵����ÿһ��Binder Server�������л���һ��binder_node���ж�Ӧ��ͬʱ��Binder�����Ḻ���ڽ��̼䴫�ݷ����������ײ��ת�������⣬����Ҳ�ᵽ��ÿһ��Binder������Ҫ��һ��Ψһ�����ơ���ServiceManager��������Щ�����ע��Ͳ��ҡ�
��ʵ���ϣ�Ϊ�˱���ʹ�ã�ServiceManager����Ҳʵ��Ϊһ��Server�����κν�����ʹ��ServiceManager��ʱ����Ҫ���õ�ָ�����ı�ʶ��Ȼ��ͨ�������ʶ��ʹ��ServiceManager��
���ƺ��γ���һ������ì�ܵ�����
ͨ��ServiceManager���Dz����õ�Server�ı�ʶ
ServiceManager����Ҳ��һ��Server
������ì�ܵİ취��ʵҲ�ܼ�Binder����ΪServiceManagerԤ����һ�������λ�á����λ����Ԥ�ȶ��õģ��κ���Ҫʹ��ServiceManager�Ľ���ֻҪͨ������ض���λ�þͿ��Է��ʵ�ServiceManager�ˣ���������ͨ��ServiceManager�Ľӿڣ���
��Binder�����У���һ��ȫ�ֵı�����
static struct binder_node *binder_context_mgr_node;
|
�������ָ��ľ���ServiceManager��
���н���ͨ��ioctl��ָ������ΪBINDER_SET_CONTEXT_MGR��ʱ���������϶����������ServiceManager��binder_ioctl�����ж�Ӧ�Ĵ������£�
case BINDER_SET_CONTEXT_MGR: if (binder_context_mgr_node != NULL) { pr_err("BINDER_SET_CONTEXT_MGR already set\n"); ret = -EBUSY; goto err; } ret = security_binder_set_context_mgr(proc->tsk); if (ret < 0) goto err; if (uid_valid(binder_context_mgr_uid)) { if (!uid_eq(binder_context_mgr_uid, current->cred->euid)) { pr_err("BINDER_SET_CONTEXT_MGR bad uid %d != %d\n", from_kuid(&init_user_ns, current->cred->euid), from_kuid(&init_user_ns, binder_context_mgr_uid)); ret = -EPERM; goto err; } } else binder_context_mgr_uid = current->cred->euid; binder_context_mgr_node = binder_new_node(proc, 0, 0); if (binder_context_mgr_node == NULL) { ret = -ENOMEM; goto err; } binder_context_mgr_node->local_weak_refs++; binder_context_mgr_node->local_strong_refs++; binder_context_mgr_node->has_strong_ref = 1; binder_context_mgr_node->has_weak_ref = 1; break;
|
ServiceManagerӦ��Ҫ��������Binder Server֮ǰ����������������ɲ���֪Binder����֮���������趨��������ض��Ľڵ㡣
����֮��������ģ����Ҫʹ��ServerManager��ʱ��ֻҪ������ָ��ServiceManager���ڵ�λ�ü��ɡ�
��Binder�����У�ͨ��handle = 0���λ��������ServiceManager�����磬binder_transaction�У��ж����target.handlerΪ0������Ϊ��������Ƿ���ServiceManager�ģ���ش������£�
������
��ƪ�����У����Ƕ�Binder������������ܹ��ͷֲ�Ľ��ܣ�Ҳ��ϸ������Binder�����е�����ģ�顣��������֮�ϵ�ģ�飬���ڽ��������н��⡣
|






