| Hadoop�ǶԴ����ݼ����зֲ�ʽ����ı����ߣ���Ҳ��Ϊʲô���㴩������ʱ�ܿ�����������(Big
Data)������ԭ�����Ѿ���Ϊ�����ݵIJ���ϵͳ���ṩ�˰������ߺͼ������ڵķḻ��̬ϵͳ������ʹ����Ա��˵���ҵӲ����Ⱥ���г������������ļ��㡣2003��2004�꣬��������Google�Ĺ۵�ʹHadoop��Ϊ���ܣ�һ���ֲ�ʽ�洢���(Google�ļ�ϵͳ)����Hadoop�б�ʵ��ΪHDFS��һ���ֲ�ʽ������(MapReduce)��
�������۵��Ϊ��ȥʮ���ģ������scaling analytics�������ģ����ѧϰ��machine
learning�����Լ�����������Ӧ�ó��ֵ���Ҫ�ƶ��������ǣ��Ӽ����Ƕ��Ͻ���ʮ����һ�ηdz�����ʱ�䣬����Hadoop�����ںܶ���֪���ƣ�������MapReduce����MapReduce������������ѵġ��Դ�����������㶼�����úܶಽ�轫Map��Reduce�����������������SQL�ļ�������ѧϰ��Ҫר�ŵ�ϵͳ�����С�������ǣ�MapReduceҪ��ÿ������������Ҫ���л������̣�����ζ��MapReduce��ҵ��I/O�ɱ��ܸߣ����½��������͵����㷨��iterative
algorithms�������ܴ���ʵ�ǣ��������е����Ż��ͻ���ѧϰ���ǵ����ġ�
Ϊ�˽����Щ���⣬Hadoopһֱ����һ�ָ�Ϊͨ�õ���Դ�������ת�䣬��YARN��Yet Another
Resource Negotiator, ��һ����ԴЭ���ߣ���YARNʵ������һ����MapReduce����ͬʱҲ����Ӧ�����÷ֲ�ʽ��Դ�����ز���MapReduce���м��㡣ͨ������Ⱥ����һ�㻯���о�ת���ֲ�ʽ�����һ�㻯�ϣ�����չ��MapReduce�ij��ԡ�
Spark�ǵ�һ����̥�ڸ�ת��Ŀ��١�ͨ�÷ֲ�ʽ���㷶ʽ�����Һܿ�����������Sparkʹ�ú���ʽ��̷�ʽ��չ��MapReduceģ����֧�ָ���������ͣ����Ժ��ǹ㷺�Ĺ���������Щ������֮ǰ��ʵ��ΪHadoop֮�ϵ�����ϵͳ��Sparkʹ���ڴ滺�����������ܣ���˽��н���ʽ����Ҳ�㹻����(����ͬʹ��Python���������뼯Ⱥ���н���һ��)������ͬʱ�����˵����㷨�����ܣ���ʹ��Spark�dz��ʺ��������������ر��ǻ���ѧϰ��
�����У����ǽ�������������ڱ��ػ����ϻ���EC2�ļ�Ⱥ������Spark���м�����Ȼ�����������ż�ˮƽ̽��Spark���˽�Spark��ʲô�Լ�����ι�����ϣ�����Լ�������̽����������������ǿ�ʼͨ����������Spark���н�����Ȼ����ʾ�����PythonдSparkӦ�ã�����ΪSpark��ҵ�ύ����Ⱥ�ϡ�
����Spark
�ڱ������ú�����Spark�dz�����ֻ��Ҫ����һ��Ԥ�����İ���ֻҪ�㰲װ��Java 6+��Python
2.6+���Ϳ�����Windows��Mac OS X��Linux������Spark��ȷ��java������PATH���������У�����������JAVA_HOME�������������Ƶģ�pythonҲҪ��PATH�С�
�������Ѿ���װ��Java��Python��
1.����Spark����ҳ
2.ѡ��Spark���·�����(����д��ʱ��1.2.0)��һ��Ԥ������Hadoop
2.4����ֱ�����ء�
���ڣ���μ�����������IJ���ϵͳ�������Լ�ȥ̽���ˡ�Windows�û���������������������õ���ʾ�������ۡ�
һ�㣬�ҵĽ����ǰ�������IJ���(��POSIX����ϵͳ��)��
1.��ѹSpark
~$ tar -xzf spark-1.2.0-bin-hadoop2.4.tgz |
2.����ѹĿ¼�ƶ�����ЧӦ�ó���Ŀ¼��(��Windows�ϵ�
~$ mv spark-1.2.0-bin-hadoop2.4 /srv/spark-1.2.0 |
3.����ָ���Spark�汾�ķ������ӵ�<sparkĿ¼����������Լ�������/�ɰ汾��Spark��Ȼ��������������Spark�汾�������ø���·����������
~$ ln -s /srv/spark-1.2.0 /srv/spark |
4.��BASH���ã���Spark���ӵ�PATH�У�����SPARK_HOME������������ЩС�������������ϻ�ﵽ�㡣��Ubuntu�ϣ�ֻҪ�༭~/.bash_profile��~/.profile�ļ���������������ӵ��ļ��У�
export SPARK_HOME=/srv/spark
export PATH=$SPARK_HOME/bin:$PATH |
5.source��Щ���ã����������նˣ�֮����Ϳ����ڱ�������һ��pyspark��������ִ��pyspark�����ῴ�����½����
~$ pyspark
Python 2.7.8 (default, Dec 2 2014, 12:45:58)
[GCC 4.2.1 Compatible Apple LLVM 6.0 (clang-600.0.54)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
Spark assembly has been built with Hive, including Datanucleus jars on classpath
Using Sparks default log4j profile: org/apache/spark/log4j-defaults.properties
[�� snip ��]
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ `_/
/__ / .__/\_,_/_/ /_/\_\ version 1.2.0
/_/
Using Python version 2.7.8 (default, Dec 2 2014 12:45:58)
SparkContext available as sc.
>>> |
����Spark�Ѿ���װ��ϣ������ڱ����ԡ�����ģʽ����standalone mode��ʹ�á�������ڱ�������Ӧ�ò��ύSpark��ҵ����Щ��ҵ���Զ����/���߳�ģʽ���еģ����ߣ����øû�����Ϊһ����Ⱥ�Ŀͻ��ˣ����Ƽ�����������Ϊ��Spark��ҵ�У���������(driver)�Ǹ�����Ҫ�Ľ�ɫ������Ӧ���뼯Ⱥ���������ִ�����ͬ���磩�����ܳ��˿��������ڱ���ʹ��Spark�������ľ�������spark-ec2�ű�������Amazon���ϵ�һ��EC2
Spark��Ⱥ�ˡ�
����Spark���
Spark����PySpark����ִ�п����ر���ϸ���ܶ�INFO��־��Ϣ�����ӡ����Ļ�����������У���Щ�dz����ˣ���Ϊ���ܶ�ʧPythonջ���ٻ���print�������Ϊ�˼���Spark���
�C ���������$SPARK_HOME/conf�µ�log4j�����ȣ�����һ��$SPARK_HOME/conf/log4j.properties.template�ļ���ȥ����.template����չ����
~$ cp $SPARK_HOME/conf/log4j.properties.template $SPARK_HOME/conf/log4j.properties |
�༭���ļ�����WARN�滻�����г��ֵ�INFO�����log4j.properties�ļ����ƣ�
# Set everything to be logged to the console
log4j.rootCategory=WARN, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Settings to quiet third party logs that are too verbose
log4j.logger.org.eclipse.jetty=WARN
log4j.logger.org.eclipse.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=WARN
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=WARN |
��������PySpark�������Ϣ��������ԣ���л@genomegeek��һ��District Data
Labs�����ֻ���ָ����һ�㡣
��Spark��ʹ��IPython Notebook
���������õ�SparkС����ʱ���ҷ�����һЩ�����ᵽ��PySpark������IPython notebook��IPython
notebook�����ݿ�ѧ����˵�Ǹ������س��ֿ�ѧ�����۹����ıر����ߣ����������ı���Python���롣�Ժܶ����ݿ�ѧ�ң�IPython
notebook�����ǵ�Python���ţ�����ʹ�÷dz��㷺����������ֵ���ڱ������ἰ��
����Ĵ�˵�������ı���IPython notebook: ��PySpark������IPython�����ǣ����ǽ��۽��ڱ����Ե���ģʽ��IPtyon
shell���ӵ�PySpark����������EC2��Ⱥ�����������һ����Ⱥ��ʹ��PySpark/IPython���鿴���������ĵ�˵���ɣ�
1.ΪSpark����һ��iPython notebook����
~$ ipython profile create spark
[ProfileCreate] Generating default config file: u'$HOME/.ipython/profile_spark/ipython_config.py'
[ProfileCreate] Generating default config file: u'$HOME/.ipython/profile_spark/ipython_notebook_config.py'
[ProfileCreate] Generating default config file: u'$HOME/.ipython/profile_spark/ipython_nbconvert_config.py' |
��ס�����ļ���λ�ã��滻���ĸ�������Ӧ��·����
2.�����ļ�$HOME/.ipython/profile_spark/startup/00-pyspark-setup.py�����������´��룺
import os
import sys
# Configure the environment
if 'SPARK_HOME' not in os.environ:
os.environ['SPARK_HOME'] = '/srv/spark'
# Create a variable for our root path
SPARK_HOME = os.environ['SPARK_HOME']
# Add the PySpark/py4j to the Python Path
sys.path.insert(0, os.path.join(SPARK_HOME, "python", "build"))
sys.path.insert(0, os.path.join(SPARK_HOME, "python")) |
3.ʹ�����Ǹոմ���������������IPython notebook��
~$ ipython notebook --profile spark |
4.��notebook�У���Ӧ���ܿ������Ǹոմ����ı�����
5.��IPython notebook�����棬ȷ����������Spark context��
from pyspark import SparkContext
sc = SparkContext( 'local', 'pyspark') |
6.ʹ��IPython�����ļ���������Spark context��
def isprime(n):
"""
check if integer n is a prime
"""
# make sure n is a positive integer
n = abs(int(n))
# 0 and 1 are not primes
if n < 2:
return False
# 2 is the only even prime number
if n == 2:
return True
# all other even numbers are not primes
if not n & 1:
return False
# range starts with 3 and only needs to go up the square root of n
# for all odd numbers
for x in range(3, int(n**0.5)+1, 2):
if n % x == 0:
return False
return True
# Create an RDD of numbers from 0 to 1,000,000
nums = sc.parallelize(xrange(1000000))
# Compute the number of primes in the RDD
print nums.filter(isprime).count() |
������ܵõ�һ�����ֶ���û�д���������ô���context��ȷ�����ˣ�
�༭��ʾ������������һ��ʹ��PySparkֱ�ӵ���IPython notebook��IPython context�����ǣ���Ҳ����ʹ��PySpark�����·�ʽֱ������һ��notebook��
$ IPYTHON_OPTS=��notebook �Cpylab inline�� pyspark
�ĸ���������ȡ������ʹ��PySpark��IPython�ľ����龰��ǰһ�������������ʹ��IPython
notebook���ӵ�һ����Ⱥ���������ϲ���ķ�����
��EC2��ʹ��Spark
�ڽ���ʹ��Hadoop���зֲ�ʽ����ʱ���ҷ��ֺܶ����ͨ���ڱ���α�ֲ�ʽ�ڵ㣨pseudo-distributed
node�����Ե��ڵ�ģʽ��single-node mode�����ڡ�����Ϊ���˽�����������ʲô������Ҫһ����Ⱥ�������ݱ���Ӵ���Щ���潲�ڵļ��ܺ���ʵ��������侭�����ָ�Ĥ����������ѧϰ��ϸʹ��Spark�ϻ�Ǯ���ҽ���������һ������Spark��Ⱥ����ʵ�顣
����5��slave����1��master��ÿ�ܴ��ʹ��10Сʱ�ļ�Ⱥÿ�´����Ҫ$45.18��
���������ۿ�����Spark�ĵ����ҵ�����EC2������Spark�����������EC2��Ⱥǰһ��Ҫͨ����ƪ�ĵ������г���һЩ�ؼ��㣺
ͨ��AWS Console��ȡAWS EC2 key�ԣ�����key����Կkey����
��key�Ե�������Ļ����С���shell���ó�����������߽��������ӵ������С�
export AWS_ACCESS_KEY_ID=myaccesskeyid
export AWS_SECRET_ACCESS_KEY=mysecretaccesskey |
ע�ⲻͬ�Ĺ���ʹ�ò�ͬ�Ļ������ƣ�ȷ�����õ���Spark�ű���ʹ�õ����ơ�
3.������Ⱥ��
~$ cd $SPARK_HOME/ec2
ec2$ ./spark-ec2 -k <keypair> -i <key-file> -s <num-slaves> launch <cluster-name> |
4.SSH����Ⱥ������Spark��ҵ��
ec2$ ./spark-ec2 -k <keypair> -i <key-file> login <cluster-name> |
5.���ټ�Ⱥ
ec2$ ./spark-ec2 destroy <cluster-name>. |
��Щ�ű����Զ�����һ�����ص�HDFS��Ⱥ���������ݣ�copy-dir�������ͬ����������ݵ��ü�Ⱥ�����������ʹ��S3���洢���ݣ�����ʹ��s3://URI���������ݵ�RDDs��
Spark��ʲô��
��Ȼ���ú���Spark����������������Spark��ʲô��Spark�Ǹ�ͨ�õļ�Ⱥ�����ܣ�ͨ�����������ݼ�����������䵽��̨������ϣ��ṩ��Ч�ڴ���㡣�������ϤHadoop����ô��֪���ֲ�ʽ������Ҫ����������⣺��ηַ����ݺ���ηַ����㡣Hadoopʹ��HDFS������ֲ�ʽ�������⣬MapReduce���㷶ʽ�ṩ��Ч�ķֲ�ʽ���㡣���Ƶģ�Sparkӵ�ж������Եĺ���ʽ���API���ṩ�˳�map��reduce֮���������������Щ������ͨ��һ���������Էֲ�ʽ���ݼ�(resilient
distributed datasets, RDDs)�ķֲ�ʽ���ݿ�ܽ��еġ�
�����ϣ�RDD���ֱ�̳��������Կ�������зָ��ֻ�����ϡ�RDD���Դ�һ���̳нṹ��lineage���ؽ�����˿����ݴ�����ͨ�����в������ʣ����Զ�дHDFS��S3�����ķֲ�ʽ�洢������Ҫ���ǣ����Ի��浽worker�ڵ���ڴ��н����������á�����RDD���Ա��������ڴ��У�Spark�Ե���Ӧ���ر���Ч����Ϊ��ЩӦ���У��������������㷨��������ж����Ա����á����������ѧϰ�����Ż��㷨���ǵ����ģ�ʹ��Spark�����ݿ�ѧ��˵�Ǹ��dz���Ч�Ĺ��ߡ����⣬����Spark�dz��죬����ͨ������Python
REPL����������ʾ������ʽ���ʡ�
Spark�Ȿ�������ܶ�Ӧ��Ԫ�أ���ЩԪ�ؿ����õ��ִ�����Ӧ���У����а����Դ����ݽ�������SQL��ѯ��֧�֣�����ѧϰ��ͼ�㷨��������ʵʱ�����ݵ�֧�֡�
����������£�
Spark Core������Spark�Ļ������ܣ������Ƕ���RDD��API�������Լ��������ϵĶ���������Spark�Ŀⶼ�ǹ�����RDD��Spark
Core֮�ϵġ�
Spark SQL���ṩͨ��Apache Hive��SQL����Hive��ѯ���ԣ�HiveQL����Spark���н�����API��ÿ�����ݿ��������һ��RDD��Spark
SQL��ѯ��ת��ΪSpark����������ϤHive��HiveQL���ˣ�Spark�����������á�
Spark Streaming��������ʵʱ���������д����Ϳ��ơ��ܶ�ʵʱ���ݿ⣨��Apache
Store�����Դ���ʵʱ���ݡ�Spark Streaming���������ܹ�����ͨRDDһ������ʵʱ���ݡ�
MLlib��һ�����û���ѧϰ�㷨�⣬�㷨��ʵ��Ϊ��RDD��Spark������������������չ��ѧϰ�㷨��������ࡢ�ع����Ҫ�Դ������ݼ����е����IJ�����֮ǰ��ѡ�Ĵ����ݻ���ѧϰ��Mahout������ת��Spark������δ��ʵ�֡�
GraphX������ͼ������ͼ�����ͼ����һ���㷨���ߵļ��ϡ�GraphX��չ��RDD
API����������ͼ��������ͼ������·�������ж���IJ�����
������Щ��������˺ܶ����������Ҳ�����˺ܶ����ݿ�ѧ������㷨�ͼ����ϵ���Ҫ��Spark��������������������ˣ�SparkҲ�ṩ��ʹ��Scala��Java��Python��д��API�������˲�ͬ��������������������ݿ�ѧ�Ҽ��ز���Spark��Ϊ���ǵĴ����ݽ��������
��Spark���
��дSparkӦ����֮ǰʵ����Hadoop�ϵ������������������ơ�����д��һ��������ֵ����������driver
program���У�ͨ��һ��������action�����������뱻�ַ�����Ⱥ�ϣ��ɸ���RDD�����ϵ�worker��ִ�С�Ȼ�����ᱻ���ͻ�����������оۺϻ���롣�����ϣ���������һ������RDD�����ò�����ת��RDD��Ȼ����ö���������ת�����RDD��
��Щ����������£�
����һ������RDD������ͨ����ȡ�洢�ڴ����ϵ����ݣ�HDFS��Cassandra��HBase��Local
Disk�������л��ڴ��е�ijЩ���ϣ�ת����transform��һ���Ѵ��ڵ�RDD�����ߣ�����档
ͨ������һ���հ�����������RDD�ϵ�ÿ��Ԫ��������RDD�ϵIJ�����Spark�ṩ�˳���Map��Reduce��80���ָ�������
ʹ�ý��RDD�Ķ�����action������count��collect��save�ȣ�����������������Ⱥ�ϵļ��㡣
��Spark��һ��worker�����бհ�ʱ���հ����õ������б������ᱻ�������ڵ��ϣ������ɱհ��ľֲ���������ά����Spark�ṩ���������͵Ĺ�����������Щ�������������ķ�ʽ������worker���ʡ��㲥�����ᱻ�ַ�������worker��������ֻ���ġ��ۼ������ֱ�����worker����ʹ�ù������������ӡ���ͨ��������������
SparkӦ�ñ�����ͨ��ת���Ͷ���������RDD���������½����������ۣ��������������������ִ������������ˡ�
Spark��ִ��
����������Spark��ִ�С������ϣ�SparkӦ����Ϊ�����Ľ������У������������е�SparkContextЭ�������context�������ӵ�һЩ��Ⱥ�����ߣ���YARN������Щ�����߷���ϵͳ��Դ����Ⱥ�ϵ�ÿ��worker��ִ���ߣ�executor��������ִ���߷�������SparkContext������ִ���߹������㡢�洢������ÿ̨�����ϵĻ��档
�ص�Ҫ��ס����Ӧ�ô���������������ִ���ߣ�ִ����ָ��context��Ҫ���е�����ִ��������������ͨ�Ž������ݷ������߽���������������Spark��ҵ����Ҫ�����ߣ������Ҫ�뼯Ⱥ������ͬ�����硣����Hadoop���벻ͬ��Hadoop�������������λ���ύ��ҵ��JobTracker��JobTracker������Ⱥ�ϵ�ִ�С�
��Spark����
ʹ��Spark��ķ�ʽ����ʹ�ý���ʽ��������ʾ������PySpark�նˣ����������д��pyspark��
~$ pyspark
[�� snip ��]
>>> |
PySpark�����Զ�ʹ�ñ���Spark���ô���һ��SparkContext�������ͨ��sc��������������������������һ��RDD��
>>> text = sc.textFile("shakespeare.txt")
>>> print text
shakespeare.txt MappedRDD[1] at textFile at NativeMethodAccessorImpl.java:-2 |
textFile������ɯʿ����ȫ����Ʒ���ص�һ��RDD�����ı�������鿴��RDD����Ϳ��Կ������Ǹ�MappedRDD���ļ�·��������ڵ�ǰ����Ŀ¼��һ�����·�����ǵô��ݴ�������ȷ��shakespear.txt�ļ�·����������ת�������RDD�������зֲ�ʽ����ġ�hello
world����������ͳ�ơ���
>>> from operator import add
>>> def tokenize(text):
... return text.split()
...
>>> words = text.flatMap(tokenize)
>>> print words
PythonRDD[2] at RDD at PythonRDD.scala:43 |
�������ȵ�����add�����������Ǹ�����������������Ϊ�ӷ��ıհ���ʹ�á������Ժ���ʹ�������������������Ҫ�����ǰ��ı����Ϊ���ʡ����Ǵ�����һ��tokenize�������������ı�Ƭ�Σ����ظ��ݿո��ֵĵ����б���Ȼ������ͨ����flatMap����������tokenize�հ���textRDD���б任������һ��wordsRDD����ᷢ�֣�words�Ǹ�PythonRDD������ִ�б�Ӧ���������С���Ȼ�����ǻ�û�а�����ɯʿ�������ݼ����Ϊ�����б���
�������ʹ��MapReduce����Hadoop��ġ�����ͳ�ơ�����Ӧ��֪����һ���ǽ�ÿ������ӳ�䵽һ����ֵ�ԣ����м��ǵ��ʣ�ֵ��1��Ȼ��ʹ��reducer����ÿ������1������
���ȣ�����mapһ�¡�
>>> wc = words.map(lambda x: (x,1))
>>> print wc.toDebugString()
(2) PythonRDD[3] at RDD at PythonRDD.scala:43
| shakespeare.txt MappedRDD[1] at textFile at NativeMethodAccessorImpl.java:-2
| shakespeare.txt HadoopRDD[0] at textFile at NativeMethodAccessorImpl.java:-2 |
��ʹ����һ����������������Python�е�lambda�ؼ��֣��������������������д��뽫���lambdaӳ�䵽ÿ�����ʡ���ˣ�ÿ��x����һ�����ʣ�ÿ�����ʶ��ᱻ�����հ�ת��ΪԪ��(word,
1)��Ϊ�˲鿴ת����ϵ������ʹ��toDebugString�������鿴PipelinedRDD����ô��ת���ġ�����ʹ��reduceByKey������������ͳ�ƣ�Ȼ���ͳ�ƽ��д�����̡�
>>> counts = wc.reduceByKey(add)
>>> counts.saveAsTextFile("wc") |
һ���������յ�����saveAsTextFile����������ֲ�ʽ��ҵ�Ϳ�ʼִ���ˣ�����ҵ���缯Ⱥ�ء��������㱾���ĺܶ���̣�����ʱ����Ӧ�ÿ��Կ����ܶ�INFO��䡣����˳�������������Կ�����ǰ����Ŀ¼���и���wc��Ŀ¼��
$ ls wc/
_SUCCESS part-00000 part-00001 |
ÿ��part�ļ��������㱾���ϵĽ��̼���õ��ı����ֵ������ϵ�����RDD�������һ��part�ļ�����head�����Ӧ���ܿ�������ͳ��Ԫ�顣
$ head wc/part-00000
(u'fawn', 14)
(u'Fame.', 1)
(u'Fame,', 2)
(u'kinghenryviii@7731', 1)
(u'othello@36737', 1)
(u'loveslabourslost@51678', 1)
(u'1kinghenryiv@54228', 1)
(u'troilusandcressida@83747', 1)
(u'fleeces', 1)
(u'midsummersnightsdream@71681', 1) |
ע����Щ��û����Hadoopһ����������ΪHadoop��Map��Reduce�������и���Ҫ�Ĵ��Һ�����Σ������ǣ��ܱ�֤ÿ�������������ļ���ֻ����һ�Σ���Ϊ��ʹ����reduceByKey���������㻹����ʹ��sort������ȷ����д�뵽����֮ǰ���еļ������Ź���
��дһ��SparkӦ��
��дSparkӦ����ͨ������ʽ����̨ʹ��Spark���ơ�API����ͬ�ġ����ȣ�����Ҫ����<SparkContext�����Ѿ���<pyspark�Զ����غ��ˡ�
ʹ��Spark��дSparkӦ�õ�һ������ģ�����£�
## Spark Application - execute with spark-submit
## Imports
from pyspark import SparkConf, SparkContext
## Module Constants
APP_NAME = "My Spark Application"
## Closure Functions
## Main functionality
def main(sc):
pass
if __name__ == "__main__":
# Configure Spark
conf = SparkConf().setAppName(APP_NAME)
conf = conf.setMaster("local[*]")
sc = SparkContext(conf=conf)
# Execute Main functionality
main(sc) |
���ģ���г���һ��SparkӦ������Ķ���������Python�⣬ģ�鳣�������ڵ��Ժ�Spark UI�Ŀ�ʶ���Ӧ�����ƣ�������Ϊ�����������е�һЩ��Ҫ��������ѧ����ifmain�У����Ǵ�����SparkContext��ʹ�������úõ�contextִ��main�����ǿ��Լص����������뵽pyspark������ִ�С�ע������Spark����ͨ��setMaster������Ӳ���뵽SparkConf��һ����Ӧ���������ֵͨ�������������ã��������ܿ�����������ռλ��ע�͡�
ʹ��<sc.stop()��<sys.exit(0)���رջ��˳�����
## Spark Application - execute with spark-submit
## Imports
import csv
import matplotlib.pyplot as plt
from StringIO import StringIO
from datetime import datetime
from collections import namedtuple
from operator import add, itemgetter
from pyspark import SparkConf, SparkContext
## Module Constants
APP_NAME = "Flight Delay Analysis"
DATE_FMT = "%Y-%m-%d"
TIME_FMT = "%H%M"
fields = ('date', 'airline', 'flightnum', 'origin', 'dest', 'dep',
'dep_delay', 'arv', 'arv_delay', 'airtime', 'distance')
Flight = namedtuple('Flight', fields)
## Closure Functions
def parse(row):
"""
Parses a row and returns a named tuple.
"""
row[0] = datetime.strptime(row[0], DATE_FMT).date()
row[5] = datetime.strptime(row[5], TIME_FMT).time()
row[6] = float(row[6])
row[7] = datetime.strptime(row[7], TIME_FMT).time()
row[8] = float(row[8])
row[9] = float(row[9])
row[10] = float(row[10])
return Flight(*row[:11])
def split(line):
"""
Operator function for splitting a line with csv module
"""
reader = csv.reader(StringIO(line))
return reader.next()
def plot(delays):
"""
Show a bar chart of the total delay per airline
"""
airlines = [d[0] for d in delays]
minutes = [d[1] for d in delays]
index = list(xrange(len(airlines)))
fig, axe = plt.subplots()
bars = axe.barh(index, minutes)
# Add the total minutes to the right
for idx, air, min in zip(index, airlines, minutes):
if min > 0:
bars[idx].set_color('#d9230f')
axe.annotate(" %0.0f min" % min, xy=(min+1, idx+0.5), va='center')
else:
bars[idx].set_color('#469408')
axe.annotate(" %0.0f min" % min, xy=(10, idx+0.5), va='center')
# Set the ticks
ticks = plt.yticks([idx+ 0.5 for idx in index], airlines)
xt = plt.xticks()[0]
plt.xticks(xt, [' '] * len(xt))
# minimize chart junk
plt.grid(axis = 'x', color ='white', linestyle='-')
plt.title('Total Minutes Delayed per Airline')
plt.show()
## Main functionality
def main(sc):
# Load the airlines lookup dictionary
airlines = dict(sc.textFile("ontime/airlines.csv").map(split).collect())
# Broadcast the lookup dictionary to the cluster
airline_lookup = sc.broadcast(airlines)
# Read the CSV Data into an RDD
flights = sc.textFile("ontime/flights.csv").map(split).map(parse)
# Map the total delay to the airline (joined using the broadcast value)
delays = flights.map(lambda f: (airline_lookup.value[f.airline],
add(f.dep_delay, f.arv_delay)))
# Reduce the total delay for the month to the airline
delays = delays.reduceByKey(add).collect()
delays = sorted(delays, key=itemgetter(1))
# Provide output from the driver
for d in delays:
print "%0.0f minutes delayed\t%s" % (d[1], d[0])
# Show a bar chart of the delays
plot(delays)
if __name__ == "__main__":
# Configure Spark
conf = SparkConf().setMaster("local[*]")
conf = conf.setAppName(APP_NAME)
sc = SparkContext(conf=conf)
# Execute Main functionality
main(sc) |
ʹ��<spark-submit������������δ��루����������ontimeĿ¼��Ŀ¼��������CSV�ļ�����
���Spark��ҵʹ�ñ�����Ϊmaster��������app.pyͬĿ¼�µ�ontimeĿ¼�µ�2��CSV�ļ������ս����ʾ��4�µ�������ʱ�䣨��λ���ӣ����������ģ�������������½���������Ļ��߰���˹�ӣ������Դִ��ͺ��չ�˾��������ġ�ע�⣬������app.py��ʹ��matplotlibֱ�ӽ�������ӻ������ˣ�
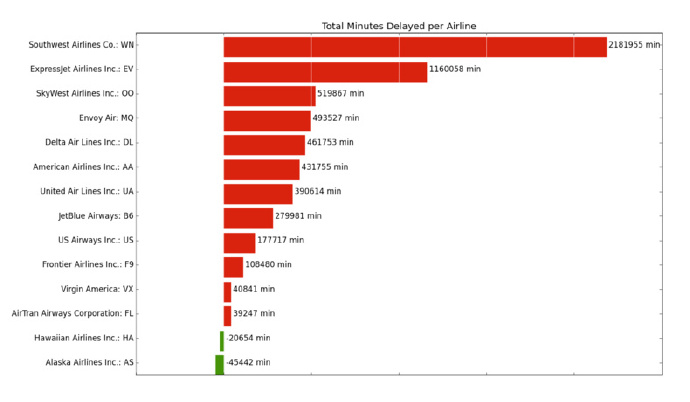
��δ�������ʲô�أ������ر�ע������Spark��ֱ����ص�main���������ȣ����Ǽ���CSV�ļ���RDD��Ȼ���split����ӳ�������split����ʹ��csvģ������ı���ÿһ�У������ش���ÿ�е�Ԫ�顣������ǽ�collect��������RDD�����������������Python�б�����ʽ��RDD���������������У�airlines.csv�Ǹ�С�͵���ת����jump
table�������Խ����չ�˾������ȫ����Ӧ���������ǽ�ת�Ʊ��洢ΪPython�ֵ䣬Ȼ��ʹ��sc.broadcast�㲥����Ⱥ�ϵ�ÿ���ڵ㡣
���ţ�main���������������������flights.csv��[����ע]���߱���д��fights.csv���˴������������CSV�����֮�����ǽ�parse����ӳ���CSV�У��˺���������ں�ʱ��ת��Python�����ں�ʱ�䣬���Ը��������к��ʵ�����ת����ÿ����Ϊһ��NamedTuple���棬��ΪFlight���Ա��Ч����ʹ�á�
����Flight�����RDD������ӳ��һ���������������������RDDת��ΪһЩ�еļ�ֵ�ԣ����м��Ǻ��չ�˾�����֣�ֵ�ǵ���ͳ���������ʱ���ܺ͡�ʹ��reduceByKey������add���������Եõ�ÿ�����չ�˾������ʱ���ܺͣ�Ȼ��RDD�����ݸ��������������к��չ�˾����Ŀ��Խ��٣�����������ʱ�䰴���������У������ӡ���˿���̨������ʹ��matplotlib�����˿��ӻ���
��������Գ�������ϣ������ʾ����Ⱥ����������֮�������ã��������ݽ��з��������ȡ�ظ����������Լ�Python������SparkӦ���еĽ�ɫ��
����
�����㲻��һ��������Spark���ţ�����ϣ�����ܸ��õ��˽�Spark��ʲô�����ʹ�ý��п��١��ڴ�ֲ�ʽ���㡣���٣���Ӧ���ܽ�Spark��������������ʼ�ڱ�����Amazon
EC2��̽�����ݡ���Ӧ�ÿ������ú�iPython notebook������Spark��
Spark���ܽ���ֲ�ʽ�洢���⣨ͨ��Spark��HDFS�л�ȡ���ݣ���������Ϊ�ֲ�ʽ�����ṩ�˷ḻ�ĺ���ʽ���API�������ܽ����������ֲ�ʽ���ݼ���RDD��֮�ϡ�RDD���ֱ�̳������������Ķ��ϣ��������зֲ�ʽ������RDD���ݴ��������������IJ��֣�������Ҫ��ʱ�����Դ洢���ڵ��ϵ�worker�ڴ�������������á��ڴ�洢�ṩ�˿��ٺͼ�ʾ�ĵ����㷨���Լ�ʵʱ����������
����Spark���ṩ��Python��Scale��Java��д��API���Լ��ڽ��Ļ���ѧϰ�������ݡ�ͼ�㷨����SQL��ѯ��ģ�飻SparkѸ�ٳ�Ϊ��������Ҫ�ķֲ�ʽ������֮һ����YARN��ϣ�Spark�ṩ������������������Ѵ��ڵ�Hadoop��Ⱥ��������Ϊδ����������Ҫ��һ���֣�Ϊ���ݿ�ѧ̽��������һ����ׯ�����
|






