| Android�������ǻ���Linux�ں˵�ϵͳ��Ҳ����˵Android����һ��Linux����ϵͳ��ֻ���������ʱ��������ARM�ܹ����豸�ϣ����磬Android�ֻ���ƽ��ȡ�Android����ʵ���Ͼ���Linux������ֻ������ʹ��Android���̽������1������װC/C++������뻷��
���ܵĽ����������Linux�����������ARM�ܹ��ģ�������������װ��Androidģ������Android�ֻ�����Ҫroot����ƽ���ϣ���Щ�豸��Ҫʹ�ø���ARM�ܹ���CPU������Ȼ��ʹ�ô�ͳ��GCCҲ���Ա����X86�ܹ���������������Ҫ�Ĵ��룩������Ҳ������Ubuntu
Linux�ϰ�װLinux������
���ļ����漸ƪ������Ҫ�����������Androidģ������S3C6410�����忪������ARM�ܹ���Linux��������Ȼ�����ԵĻ�����Android������������ͨ��ʹ�õ�Ubuntu
Linux��X86�ܹ���ϵͳ���������ͨ�����ַ�ʽ����������������Է������������С�NDK��Android����Java���룩�ȣ���Ȼ���������������������Ƕ�뵽LInux�ں��У�����Android�������Ǿ��Զ�ӵ�������������
��ѧϰAndroid�ײ㿪����ͯЬ����ͨ��������ȫ���տ�������Android��LInux�������������衣�ڡ�Android���̽������1����HAL�����������������������������ʵ�黷����VMWare
Ubuntu Linux12.04LTS����������Լ������鷳�����Դӹ����и��Ƹ�������������ļ�̫��3.6G����������ȥ��ֻ�ܷ������ˣ�
һ��Linux���������Ǹ�ʲô����
���ڴ�δ�Ӵ������������ij���Ա���ܻ�о�Linux���������ء��о�����������ܸ��ӡ���ʵ����ȫ����⡣ʵ����Linux��������ͨ��LinuxAPIû�б��ʵ�����ֻ��ʹ��Linux�����ķ�ʽ��ʹ��Linux
API�ķ�ʽ��ͬ����
��ѧϰLinux����֮ǰ������������һ��Linux�����Ĺ�����ʽ�����������ǰ�Ӵ���Windows��������Unix��ϵ�IJ���ϵͳ����ý����ǵĹ�����ʽ��ʱ��������Ϊ��Щ����������������Linux�ײ��һЩϸ�ڡ�
Linux�����Ĺ����ͷ��ʷ�ʽ��Linux������֮һ��ͬʱ�ܵ���ҵ��Ĺ㷺������Linuxϵͳ��ÿһ��������ӳ���һ���ļ�����Щ�ļ���Ϊ�豸�ļ��������ļ�����������/devĿ¼�С������������ʹ����Linux�������н�����������ͨ�ļ����н���һ�����ס���Ȼ��Ҳ�ȷ���LinuxAPI�����ס����ڴ����Linux�������������Ӧ���豸�ļ��������Linux�����������ݾͱ�������豸�ļ��������ݡ����磬��Linux��ӡ����������һ����ӡ�������ֱ��ʹ��C���Ժ���open���豸�ļ�����ʹ��C���Ժ���ioctl����������豸�ļ����ʹ�ӡ���
��Ȼ��Ҫ��дLinux����������Ҫ�����Ĺ��ܡ������ӡ������д������ʱ�����ڴ�ӡ��������˵����Ҫ������Щ��д������ݣ���������ͨ��PC�IJ��ڡ�USB�ȶ˿ڷ�����ӡ����Ҫʵ����һ���̾���ҪLinux����������ӦӦ�ó��ݹ��������ݡ������Linux�������¼�����Ȼ��C������û���¼��ĸ����ȴ�����¼����Ƶĸ������ǻص���callback����������ˣ���дLinux��������Ҫ��һ�����DZ�д�ص��������������豸�ļ����������ݽ����õ�������ͼ6-1��Ӧ���������豸�ļ�����������Ӳ��֮��Ĺ�ϵ
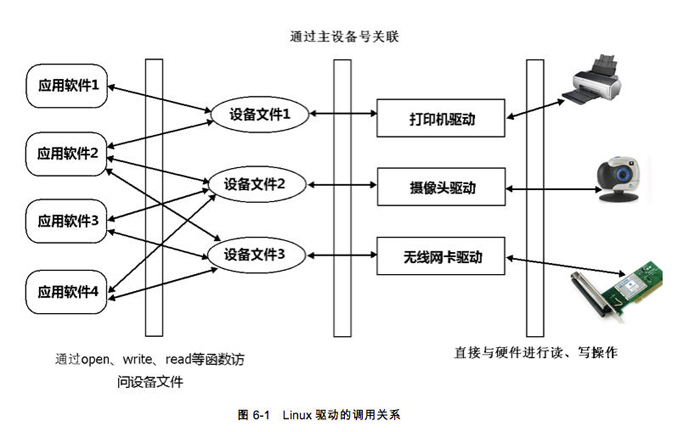
������дLinux��������IJ���
Linux�����������������͵�Linux����һ����Ҳ���Լ��Ĺ����ڸտ�ʼ�Ӵ�Linux���������Ķ��߿��ܶ���ο���һ��LInux����������̫�˽⡣Ϊ�˽���ⲿ�ֶ��ߵ������ڸ����˱�дһ��������Linux������һ�㲽�衣���߿�������Щ����ѭ����ѧϰLinux����������
��1��������Linux�����Ǽܣ�װ�غ�ж��Linux������
�κ����͵ij�����һ�������Ľṹ�����磬C������Ҫ��һ����ں���main��Linux��������Ҳ�����⡣Linux�ں���ʹ������ʱ������Ҫװ����������װ�ع�������Ҫ����һЩ��ʼ�����������磬�����豸�ļ��������ڴ��ַ�ռ�ȡ���Linuxϵͳ�˳�ʱ��Ҫж��Linux��������ж�صĹ�������Ҫ�ͷ���Linux����ռ�õ���Դ�����磬ɾ���豸�ļ����ͷ��ڴ��ַ�ռ�ȡ���Linux������������Ҫ�ṩ�����������ֱ���������ʼ�����˳��Ĺ����������������ֱ���module_init��module_exit��ָ����Linux��������һ�㶼����Ҫָ����������������˰��������������Լ�ָ���������������������C�����ļ�Ҳ�ɿ�����Linux�����ĹǼܡ�
��2����ע���ע���豸�ļ�
�κ�һ��Linux��������Ҫ��һ���豸�ļ�������Ӧ�ó����������������������豸�ļ��Ĺ���һ���ڵ�1����д�Ĵ���Linux��ʼ�������ĺ�������ɡ�ɾ���豸�ļ�һ���ڵ�1����д�Ĵ���Linux�˳������ĺ�������ɡ����Էֱ�ʹ��misc_register��misc_deregister�����������Ƴ��豸�ļ���
��3����ָ����������ص���Ϣ
�����������������ġ����磬����ͨ��modinfo�����ȡ�������������������ʹ�õĿ�ԴЭ�顢������������������Ϣ����Щ��Ϣ����Ҫ������Դ������ָ����ͨ��MODULE_AUTHOR��MODULE_LICENSE
��MODULE_ALIAS ��MODULE_DESCRIPTION�Ⱥ����ָ����������ص���Ϣ��
��4����ָ���ص�����
Linux���������˶��ֶ�����Ҳ�ɳ�Ϊ�¼������磬���豸�ļ�д������ʱ�ᴥ����д���¼���Linuxϵͳ����ö�Ӧ���������write�ص����������豸�ļ�������ʱ�ᴥ���������¼���Linuxϵͳ����ö�Ӧ���������read�ص�������һ����������һ��Ҫָ�����еĻص��������ص�������ͨ����ػ��ƽ���ע�ᡣ���磬���豸�ļ���صĻص�������ͨ��misc_register��������ע�ᡣ
��5������дҵ����
��һ����Linux�����ĺ��IJ��֡����йǼܺͻص�������Linux������û���κ�����ġ��κ�һ��������Linux����������һЩ���书����صĹ��������ӡ�����������ӡ�����ʹ�ӡָ�COM��������ݴ������ʽ������ݽ����������ҵ�����������Ĺ����йء�ҵ���������ж������������ļ������Ƕ��Linux����ģ����ɡ������ʵ�ֶ��߿��Ը���ʵ�����������
��6������дMakefile�ļ�
Linux�ں�Դ����ı��������ͨ��Makefile�ļ�����ġ���˱�дһ���µ�Linux�����������Ҫ��һ��Makefile�ļ���
��7��������Linux��������
Linux�����������ֱ�ӱ�����ںˣ�Ҳ������Ϊģ�鵥�����롣
��8������װ��ж��Linux����
�����Linux����������ںˣ�ֻҪLinuxʹ�ø��ںˣ���������ͻ��Զ�װ�ء����Linux����������ģ�鵥�����ڣ���Ҫʹ��insmod��modprobe����װ��Linux����ģ�飬ʹ��rmmod����ж��Linux����ģ�顣
����8���е�ǰ5���ǹ�����α�дLinux��������ģ�ͨ����3������ʹLinux��������������
������дLinux��������ǰ��������
������Linux����Դ���벢δ��linux�ں�Դ�������һ�𣬶��ǵ�������һ��Ŀ¼������ʹ���������������Linux���������Ŀ¼��
# mkdir �Cp /root/drivers/ch06/word_count
# cd /root/drivers/ch06/word_count
Ȼ��ʹ����������������Դ�����ļ���word_count.c��
# echo '' > word_count.c
����дһ��Makefile�ļ���ʵ��������6.2�ڽ��ܵı�дLinux��������ĵ�6��������Ϥ��дLinux��������IJ������Բ���6.2�ڽ��ܵ�˳������дLinux������
# echo 'obj-m := word_count.o' > Makefile
����obj-m��ʾ��Linux������Ϊģ�飨.ko�ļ������롣���ʹ��obj-y����Linux���������Linux�ںˡ�obj-m��obj-y��Ҫʹ�á�:=����ֵ�����obj-m��obj-y��ֵΪword_count.o����ʾmake������Linux����Դ����Ŀ¼�е�word_count.c��word_count.s�ļ������word_count.o�ļ������ʹ��obj-m��word_count.o�ᱻ���ӽ�word_count.ko�ļ���Ȼ��ʹ��insmod��modprobe����װ��word_count.ko�����ʹ��obj-y��word_count.o�ᱻ���ӽ�built-in.o�ļ������ջᱻ���ӽ��ںˡ�����built-in.o�ļ�������ͬһ������.o�ļ����ɵ��м�Ŀ���ļ������磬���е��ַ��豸�����������������һ��built-in.o�ļ������߿�����<Linux�ں�Դ����Ŀ¼>/drivers/charĿ¼�ҵ�һ��built-in.o�ļ�����Ŀ���ļ����������п����ӽ�Linux�ں˵��ַ�������ͨ��make
menuconfig�����������ÿһ�������������ں˳����Ƿ�����������ںˣ���������Linux�ں˵ļ������4.2.4�ڽ��ܣ���
���Linux������������������process.c��data.c����Ҫ�����·�ʽ��дMakefile�ļ���
obj-m := word_count.o
word_count-y := process.o data.o
���������ļ�Ҫʹ��module-y��module-objsָ����module��ʾģ��������word_count��
�ġ���дLinux��������ĹǼ�
���ڱ�дLinux��������ĹǼܲ��֣�Ҳ����ǰ����ܵĵ�1�����Ǽܲ�����Ҫ��Linux�����ij�ʼ�����˳��������������£�
#include
#include
#include
#include
#include
#include
// ��ʼ��Linux����
static int word_count_init(void)
{
// �����־��Ϣ
printk("word_count_init_success\n");
return 0;
}
// �˳�Linux����
static void word_count_exit(void)
{
// �����־��Ϣ
printk("word_count_init_exit_success\n");
}
// ע���ʼ��Linux�����ĺ���
module_init(word_count_init);
// ע���˳�Linux�����ĺ���
module_exit(word_count_exit);
|
������Ĵ�����ʹ����printk�������ú������������־��Ϣ������printk��������ϸ�÷�����10.1����ϸ���ܣ���printk������printf�������÷����ơ��еĶ��߿��ܻ������ʣ�Ϊʲô����printf�����أ�������漰��һ��Linux�ں˳�����Ե���ʲô�������Ե���ʲô�����⡣Linuxϵͳ���ڴ��Ϊ���û��ռ���ں˿ռ䣬�������ռ�ij�����ֱ�ӷ��ʡ�printf�����������û��ռ䣬printk�����������ں˿ռ䡣��ˣ������ں˳����Linux�����Dz���ֱ�ӷ���printf�����ġ����������stdio.hͷ�ļ����ڱ���Linux����ʱҲ���׳�stdio.h�ļ�û�ҵ��Ĵ���Ȼ���������û��ռ�ij���Ҳ����ֱ�ӵ���printk��������ô�Dz����û��ռ���ں˿ռ�ij�������������أ����Ƿġ������������ڴ治�ͳ��˹µ������������������ڴ��еij���֮�佻���ķ����ܶࡣ�����豸�ļ�����һ����Ҫ�Ľ�����ʽ���ں�����½ڻ������/proc�����ļ��Ľ�����ʽ��������û��ռ�ij���Ҫ�����ں˿ռ䣬ֻҪ��һ�����Է����ں˿ռ����������Ȼ���û��ռ�ij���ͨ���豸�ļ�������������н������ɡ�
����������еĶ������ʸ����ˡ�Linux����������ֱ�ӷ����������û��ռ�ij�����ô�ܶ�ܾͶ����Լ�ʵ���ˡ����磬��C�����лᾭ��ʹ��malloc������̬�����ڴ�ռ䣬�ú�����Linux��������������ʹ�õġ���ô�����Linux���������ж�̬�����ڴ�ռ��أ�������Ƶ�����Ҳ�ܼ���ȻLinux������ֱ�ӵ����������û��ռ�ĺ�������ô��Linux�ں��оͱ���Ҫ�ṩ���Ʒ�����߿��Խ���<Linux�ں�Դ����>/includeĿ¼����Ŀ¼�ĸ�����Ŀ¼�а����˴�����C����ͷ�ļ�����Щͷ�ļ��ж���ĺ����������Դ�����������û��ռ�ij�������Ʒ���������û��ռ�ĺ������Ӧ��ͷ�ļ���/usr/includeĿ¼�С��ղ��ᵽ��malloc�������ں˿ռ�����Ʒ��kmalloc����Ҫ����slab.hͷ�ļ���#include
<linux/slab.h>����
ע�⣺�û��ռ����ں˿ռ����ͬ�������ƹ��ܵĺ����������Դ�����Ʋ���һ����ͬ���е��������ƣ���malloc��kmalloc���е���ȫ��������ͬ�����֣���atoi���û��ռ䣩��simple_strtol���ں˿ռ䣩��itoa���û��ռ䣩��snprintf���ں˿ռ䣩��������ʹ���ں������ԴʱҪע����һ�㡣
��������뿴��ǰ���д�ij����Ч��������ʹ��������������Linux����Դ���루X86�ܹ�����
# make -C /usr/src/linux-headers-3.0.0-15-generic M=/root/drivers/ch06/word_count
�ڲ���Linux����δ��һ����Android�豸����ɡ���ΪAndroidϵͳ��Ubuntu Linux�Լ�����Linux���а汾���ǻ���Linux�ں˵ģ������Linux�������������Ubuntu
Linux������Linux���а��ϲ������������ý������������ɻ���ARM�ܹ���Ŀ���ļ���Ȼ���ٰ�װ��Android�ϼ����������С����ڱ���Linux�ں�Դ������Ҫʹ��Linux�ں˵�ͷ�ļ���Ϊ����Ubuntu
Linux�ϲ�������������Ҫʹ��-C�����в���ָ��Linux�ں�ͷ�ļ���Ŀ¼��/usr/src/linux-headers-3.0.0-15-generic��������linux-headers-3.0.0-15-genericĿ¼��Linux�ں�Դ����Ŀ¼���ڸ�Ŀ¼��ֻ��include��Ŀ¼��ʵ�ʵ�ͷ�ļ�������Ŀ¼ֻ��Makefile������һЩ�����ļ�����������Linux�ں�Դ���롣��Ŀ¼����Ϊ�˿�����ǰLinux�ں˰汾�������������ں˳�����ṩ�ģ���Ϊ�ڱ���Linux����ʱ����Ŀ���ļ�ֻ��Ҫͷ�ļ����ڽ���Ŀ���ļ�����ʱֻҪ����ص�Ŀ���ļ����ɣ�������ҪԴ�����ļ����������ģ�鷽ʽ����Linux����������Ҫʹ��Mָ�������������ڵ�Ŀ¼��M=
root/drivers/ch06/word_count����
ע�⣺�������ʹ�õ�Linux���а����������Linux�ںˣ���ҪΪ-C�����в���������ȷ��·����
ִ�����������������ͼ6-2��ʾ��Ϣ������Щ��Ϣ���Կ������Ѿ���word_count.c�ļ��������Linux����ģ���ļ�word_count.ko��
ʹ��ls�����г�/root/drivers/ch06/word_countĿ¼�е��ļ����֣����˶��˼���.o��.ko�ļ���������һЩ�������ļ�����ͼ6-3��ʾ����Щ�ļ����б������Զ����ɵģ�һ�㲢����Ҫ����Щ�ļ������ݡ�
���ı�д��Linux����������Ȼʲôʵ�ʵĹ��ܶ�û�У����Ѿ�������Ϊ��������װ��Linux�ں˿ռ��ˡ����߿���ʹ����������װ���鿴��ж��Linux������Ҳ���Բ鿴�����������������־��Ϣ��ִ����������ʱ��Ҫ�Ƚ���word_countĿ¼����
��װLinux����
# insmod word_count.ko
�鿴word_count�Ƿ�ɹ���װ
# lsmod | grep word_count
�Linux����
# rmmod word_count
�鿴��Linux�����������־��Ϣ
# dmesg | grep word_count | tail �Cn 2
ִ��������������������ͼ6-4��ʾ����Ϣ˵�������ѳɹ���ɱ��ڵ�ѧϰ�����Լ�������һ���ˡ�
dmesg����ʵ�����Ǵ�/var/log/messages��Ubuntu Linux 10.04����/var/log/syslog��Ubuntu
Linux11.10���ļ��ж�ȡ����־��Ϣ�����Ҳ����ִ������������ȡ��Linux�����������־��Ϣ��
# cat /var/log/syslog | grep word_count | tail �Cn 2
ִ�����������������������Ϣ����ͼ6-5��ʾ��
�塢ָ����������ص���Ϣ
��Ȼָ����Щ��Ϣ���DZ���ģ���һ��������Linux��������ָ����Щ��������ص���Ϣ��һ����ҪΪLinux��������ָ��������Ϣ��
1. ģ�����ߣ�ʹ��MODULE_AUTHOR��ָ����
2. ģ��������ʹ��MODULE_DESCRIPTION��ָ����
3. ģ�������ʹ��MODULE_ALIAS��ָ����
4. ��ԴЭ�飺ʹ��MODULE_LICENSE��ָ����
������Щ��Ϣ�⣬Linux����ģ���Լ��������һЩ��Ϣ�����߿���ִ�����������鿴word_count.ko����Ϣ��
# modinfo word_count.ko
ִ�����������������ͼ6-6��ʾ����Ϣ������depends��ʾ��ǰ����ģ���������word_count��û������ʲô����˸���Ϊ�ա�vermagic��ʾ��ǰLinux����ģ�����Ǹ�Linux�ں˰汾�±���ġ�
����ʹ������Ĵ���ָ������4����Ϣ��һ��Ὣ��Щ�������word_count.c�ļ������
MODULE_AUTHOR("lining");
MODULE_DESCRIPTION("statistics of wordcount.");
MODULE_ALIAS("word count module.");
MODULE_LICENSE("GPL");
����ʹ����һ�ڵķ������±���word_count.c�ļ���Ȼ����ִ��modinfo����ͻ���ʾ��ͼ6-7��ʾ����Ϣ����ͼ6-7���Կ���������Ĵ������õ���Ϣ����������word_count.ko�ļ��С�
������ԴЭ��
��Ȼ�ܶ���˿�����С��˾����̫���ǿ�ԴЭ������ƣ������ڽϴ�Ĺ�˾���Υ����ԴЭ�飬���ܻ��б����ߵķ��ա����Զ���һ����ģ��Ӱ�����Ĺ�˾ʹ�ÿ�Դ����ʱһ��Ҫע����Щ����ʹ�õĿ�ԴЭ�顣
Ϊ�˽��ͷ���Linux�������ѶȺͰ�װ���ߴ磬�ܶ�Linux�������ǿ���Դ����ġ���Linux����Դ������ʹ��MODULE_LICENSE��ָ����ԴЭ�顣���磬word_count����ʹ����GPLЭ�顣��ô����Ҫ��дLinux'��������Ӧ��ȡʲôЭ���أ�Ŀǰ��ԴЭ��Ƚ϶ࡣ���߿��Ե������ҳ��鿴���еĿ�ԴЭ�顣
http://www.opensource.org/licenses/alphabetical
���潫������õ�5�ֿ�ԴЭ��Ļ����������5�ֿ�ԴЭ���Լ������Ŀ�ԴЭ�����ϸ��������Open
SourceInitiative��֯�����ҳ�档
GPL��
����ϲ�����м����ij���Ա��˵Ӧ�ú�ϲ��GPLЭ�顣��ΪGPLЭ��ǿ��ʹ�øÿ�ԴЭ���������Դ�����磬Linux�ں˾Ͳ�����GPLЭ�顣GPL�ij�����������/��Դ������������ԴЭ�飨��BSD��Apache
Licence����ͬ����GPLЭ�鿪Դ�ĸ����ס�����Ҫ�����GPLЭ���������Դ/��ѣ���Ҫ�����������뿪Դ/��ѡ����磬A����������GPLЭ�飬B����ʹ����A��������ôB����Ҳ�������/��Դ������B��������Ҳ����GPLЭ�顣C������ʹ����B������C����Ҳ���뿪Դ/��ѣ���Ȼ��C����Ҳ�������GPLЭ�顣�������ν�ġ���Ⱦ�ԡ�����Ҳ��Ŀǰ�кܶ�Linux���а漰����ʹ��GPLЭ���������Դ��ԭ��
����GPLЭ���ϸ�Ҫ��ʹ����GPLЭ���������Ʒ����ʹ��GPLЭ�飬���ұ��뿪Դ/��ѡ�������ҵ�������߶Դ����б���Ҫ��IJ��žͷdz����ʺ�ʹ��GPLЭ�鷢�������������û���GPLЭ�����⡣Ϊ��������ҵ��˾�����ܵ���Ҫ����GPLЭ��Ļ������ֳ�����LGPLЭ�顣
LGPL��
LGPL��Ҫ��Ϊ���ʹ����ƵĿ�ԴЭ�顣��GPLҪ���κ�ʹ��/��/������GPL���ĵ������������GPLЭ�鲻ͬ��LGPL
������ҵ����ͨ���������(link)��ʽʹ��LGPL��������Ҫ��Դ��ҵ�����Ĵ��롣��ʹ�ò���LGPLЭ��Ŀ�Դ������Ա���ҵ������Ϊ������ò����������ۡ�
���������LGPLЭ��Ĵ�������������������ĵĴ��룬�漰�IJ��ֵĶ������������Ĵ��붼�������LGPLЭ�顣���LGPLЭ��Ŀ�Դ������ʺ���Ϊ��������ⱻ��ҵ�������ã������ʺ�ϣ����LGPLЭ�����Ϊ������ͨ���ĺ������ķ�ʽ�����ο�������ҵ�������á�
BSD��
BSD��ԴЭ����һ������ʹ���ߺܴ����ɵ�Э�顣������ʹ���߿��ԡ�Ϊ����Ϊ��,�������ɵ�ʹ�ã���Դ���룬Ҳ���Խ��ĺ�Ĵ�����Ϊ��Դ����ר�������ٷ���������Ϊ����Ϊ����ǰ���ǵ��㷢��ʹ����BSDЭ��Ĵ��룬������BSDЭ�����Ϊ���������ο����Լ��IJ�Ʒʱ����Ҫ��������3��������
1. ����ٷ����IJ�Ʒ�а���Դ���룬����Դ�����б������ԭ�������е�BSDЭ�顣
2. ����ٷ�����ֻ�Ƕ��������/����������Ҫ�����/�������ĵ��Ͱ�Ȩ�����а���ԭ�������е�BSDЭ�顣
3. �������ÿ�Դ���������/�������ֺ�ԭ����Ʒ���������г��ƹ㡣
BSD Э��������빲��������Ҫ����Դ�������ߵ�����Ȩ��BSD��������ʹ�����ĺ����·������룬Ҳ����ʹ�û���BSD�����Ͽ�����ҵ�������������ۣ�����Ƕ���ҵ���ɺ��Ѻõ�Э�顣���ܶ�Ĺ�˾��ҵ��ѡ�ÿ�Դ��Ʒ��ʱ����ѡBSDЭ�飬��Ϊ������ȫ������Щ�������Ĵ��룬�ڱ�Ҫ��ʱ������Ļ��߶��ο�����
Apache Licence 2.0��
Apache Licence�������ķ�ӯ����Դ��֯Apache���õ�Э�顣��Э���BSD���ƣ�ͬ���������빲��������ԭ���ߵ�����Ȩ��ͬ�����������ģ��ٷ�������Ϊ��Դ����ҵ����������Ҫ���������Ҳ��BSD���ơ�
1. ��Ҫ��������û�һ��Apache Licence
2. ��������˴��룬��Ҫ�ڱ��ĵ��ļ���˵����
3. ������Ĵ����У��ĺ���Դ���������Ĵ����У���Ҫ����ԭ�������е�Э�飬�̱꣬ר������������ԭ�����߹涨��Ҫ������˵����
4. ����ٴη����IJ�Ʒ�а���һ��Notice�ļ�������Notice�ļ�����Ҫ����Apache Licence���������Notice�������Լ������ɣ��������Ա���ΪApache
Licence��
Apache LicenceҲ�Ƕ���ҵӦ���Ѻõ����ɡ�ʹ����Ҳ��������Ҫ��ʱ���Ĵ�����������Ҫ����Ϊ��Դ����ҵ��Ʒ����/���ۡ�
MIT��
MIT�Ǻ�BSDһ�����ƿ��ɵ�����Э�飬����ֻ�뱣����Ȩ�������κ�����������.Ҳ����˵�����������ķ��а������ԭ����Э������������������Զ����Ʒ����Ļ�����Դ���뷢���ġ�
�ߡ�ע���ע���豸�ļ�
���ڽ�Ϊword_count��������һ���豸�ļ������豸�ļ���������wordcount��λ��/devĿ¼�С��豸�ļ�����ͨ�ļ���ͬ������ʹ��IO������������Ҫʹ��misc_register���������豸�ļ���ʹ��misc_deregister����ע�����Ƴ����豸�ļ��������������Ķ������£�
extern int misc_register(struct miscdevice * misc);
extern int misc_deregister(struct miscdevice*misc);
|
һ����Ҫ�ڳ�ʼ��Linux����ʱ�����豸�ļ�����ж��Linux����ʱɾ���豸�ļ��������豸�ļ�����Ҫһ���ṹ�壨miscdevice��������������ص���Ϣ��miscdevice�ṹ������һ����Ҫ�ij�Ա����fops�����������豸�ļ��ڸ��ֿɴ����¼��ĺ���ָ�롣�ó�Ա��������������Ҳ��һ���ṹ��file_operations��
������Ҫ��word_count.c�ļ���word_count_init��word_count_exit������������һЩ��ͱ������IJ��ֵĴ������£�
// �����豸�ļ���
#define DEVICE_NAME "wordcount"
// �������豸�ļ��������¼���Ӧ�Ļص�����ָ��
// owner���豸�¼��ص�����Ӧ������Щ����ģ�飬THIS_MODULE��ʾӦ���ڵ�ǰ����ģ��
static struct file_operations dev_fops =
{ .owner = THIS_MODULE};
// �����豸�ļ�����Ϣ
// minor�����豸�� MISC_DYNAMIC_MINOR,����̬���ɴ��豸�� name���豸�ļ�����
// fops��file_operations�ṹ�����ָ��
static struct miscdevice misc =
{ .minor = MISC_DYNAMIC_MINOR, .name = DEVICE_NAME,.fops = &dev_fops };
// ��ʼ��Linux����
static int word_count_init(void)
{
int ret;
// �����豸�ļ�
ret = misc_register(&misc);
// �����־��Ϣ
printk("word_count_init_success\n");
return ret;
}
// �Linux����
static void word_count_exit(void)
{
// ע�����Ƴ����豸�ļ�
misc_deregister(&misc);
// �����־��Ϣ
printk("word_init_exit_success\n");
}
|
��д���������Ҫע�����¼��㣺
1. �豸�ļ������豸�źʹ��豸����������ʹ��misc_register����ֻ�����ô��豸�š����豸��ͳһ��Ϊ10�����豸��Ϊ10���豸��Linuxϵͳ��ӵ�й�ͬ���Եļ��ַ��豸�������豸��Ϊmisc�豸���������ʵ�ֵ������Ĺ��ܲ������ӣ����Կ���ʹ��10��Ϊ�����豸�ţ������豸�ſ����Լ�ָ����Ҳ���Զ�̬���ɣ���Ҫָ��MISC_DYNAMIC_MINOR����������Ϊ���������ķ�ʽ����ʹ��misc_register��misc_deregister������ע���ע���豸�ļ��IJ��衣�ں�����½ڻ���ϸ�������ʹ��register_chrdev_region��alloc_chrdev_region����ͬʱָ�����豸�źʹ��豸�ŵķ�ʽע���ע���豸�ļ���
2. miscdevice.name������ֵ�����豸�ļ������ơ��ڱ������豸�ļ�����Ϊwordcount��
3. ��Ȼfile_operations�ṹ���ж����˶���ص�����ָ������������ڲ�δ��ʼ���κ�һ���ص�����ָ�������ֻ��ʼ����file_operations.owner����������ñ�����ֵΪmodule�ṹ�壬��ʾfile_operations�ɱ�Ӧ������Щ��moduleָ��������ģ���С����owner������ֵΪTHIS_MODULE����ʾfile_operationsֻӦ���ڵ�ǰ����ģ�顣
4. ����ɹ�ע�����豸�ļ���misc_register�������ط�0�����������ע���豸�ļ�ʧ�ܣ�����0��
5. �����еĶ���ע��ˡ�word_count.c�е����к�������������������static��������Ϊ��C��������static������������������Դ��ϵͳ�Ὣ��Щ�����ͱ������������ڴ��ijһ������ֱ��������ȫ�˳���������Щ��Դ���ᱻ�ͷš�Linux����һ��װ�أ������ֶ�ж�ػ�ػ���������һֱפ���ڴ棬�����Щ�����ͱ�����Դ��һֱ���ڴ��С�Ҳ����˵��ε�����Щ��Դ�����ٽ���ѹջ����ջ�����ˡ��������������������Ч�ʡ�
�������±���word_count.c�ļ���ʹ�����µ����װword_count������
# insmod word_count.ko
���word_count�����Ѿ�����װ��Ӧ��ʹ���������������word_count������Ȼ����ʹ����������װword_count������
# rmmod word_count
��װ��word_count������ʹ�����������鿴/devĿ¼�е��豸��
# ls �Ca /dev
ִ�����������������ͼ6-8��ʾ����Ϣ�����ж���һ��wordcount�ļ����ڰ��У���
�����鿴wordcount�豸�ļ������豸�źʹ��豸�ţ�����ʹ�����µ����
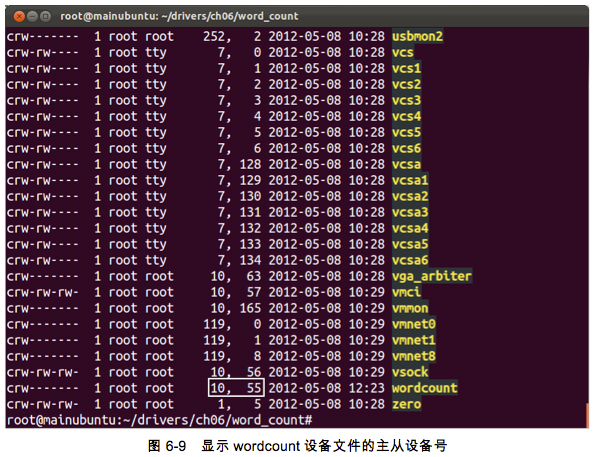
# ls �Cl /dev
ִ�����������������ͼ6-9��ʾ����Ϣ�����еĵ�һ�����������豸�ţ��ڶ��������Ǵ��豸�š�
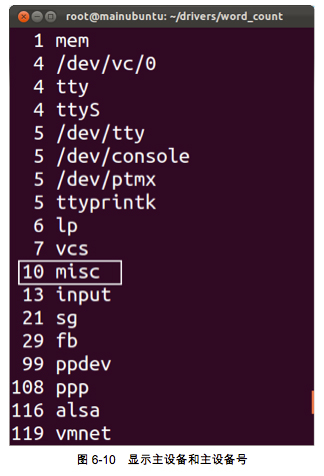
ʹ�����������ɻ���ʾ����ϵͳ������Щ���豸�Լ����豸�š�
# cat /proc/devices
ִ������������������ͼ6-10��ʾ����Ϣ�����п����ҵ�misc�豸�Լ����豸���10��
�ˡ� ָ���ص�����
���ڽ�������ʮ�ֹؼ�������Linux��������Ĺ��ܶ�ô���ӻ��Ƕ�ô���ᡱ�������������û��ռ��Ӧ�ó������ں˿ռ������������н����������塣����õĽ�����ʽ���Ƕ�д�豸�ļ���ͨ��file_operations.read��file_operations.write��Ա�������Էֱ�ָ����д�豸�ļ�Ҫ���õĻص�����ָ�롣
�ڱ��ڽ�Ϊword_count.c��������������word_count_read��word_count_write�������������ֱ������豸�ļ������ݺ����豸�ļ�д���ݵĶ��������ڵ������Ȳ�����word_countҪʵ�ֵ�ͳ�Ƶ������Ĺ��ܣ�����word_count_read��word_count_write������һ����д�豸�ļ����ݵ�ʵ�飬�Ա��ö����˽�������豸�ļ��������ݡ����ڱ�д��word_count.c�ļ���һ����֧�����߿���word_count/read_writeĿ¼�ҵ�word_count.c�ļ��������ø��ļ�����word_countĿ¼�µ�ͬ���ļ����Ա��ڵ����ӡ�
�����Ĺ��������豸�ļ�/dev/wordcountд�����ݺ����Դ�/dev/wordcount�豸�ļ��ж�����Щ���ݣ�ֻ�ܶ�ȡһ�Σ��������ȿ��������������Ĵ��롣
#include
#include
#include
#include
#include
#include
#define DEVICE_NAME "wordcount" // �����豸�ļ���
static unsigned char mem[10000]; // �������豸�ļ�д�������
static char read_flag = 'y'; // y���Ѵ��豸�ļ���ȡ���� n��δ���豸�ļ���ȡ����
static int written_count = 0; // ���豸�ļ�д�����ݵ��ֽ���
// ���豸�ļ���ȡ����ʱ���øú���
// file��ָ���豸�ļ���buf������ɶ�ȡ������ count���ɶ�ȡ���ֽ��� ppos����ȡ���ݵ�ƫ����
static ssize_t word_count_read(struct file *file, char __user *buf, size_t count, loff_t *ppos)
{
// �����û�ж�ȡ�豸�ļ��е����ݣ����Խ��ж�ȡ
if(read_flag == 'n')
{
// ���ں˿ռ�����ݸ��Ƶ��û��ռ䣬buf�е����ݾ��Ǵ��豸�ļ��ж���������
copy_to_user(buf, (void*) mem, written_count);
// ����־����Ѷ�ȡ���ֽ���
printk("read count:%d", (int) written_count);
// ���������Ѷ�״̬
read_flag = 'y';
return written_count;
}
// �Ѿ����豸�ļ���ȡ���ݣ������ٴζ�ȡ����
else
{
return 0;
}
}
// ���豸�ļ�д������ʱ���øú���
// file��ָ���豸�ļ���buf������д������� count��д�����ݵ��ֽ��� ppos��д�����ݵ�ƫ����
static ssize_t word_count_write(struct file *file, const char __user *buf, size_t count, loff_t *ppos)
{
// ���û��ռ�����ݸ��Ƶ��ں˿ռ䣬mem�е����ݾ������豸�ļ�д�������
copy_from_user(mem, buf, count);
// �������ݵ�δ��״̬
read_flag = 'n';
// ����д�����ݵ��ֽ���
written_count = count;
// ����־�����д����ֽ���
printk("written count:%d", (int)count);
return count;
}
// �������豸�ļ��������¼���Ӧ�Ļص�����ָ��
// ��Ҫ����read��write��Ա������ϵͳ���ܵ��ô�����д�豸�ļ������ĺ���
static struct file_operations dev_fops =
{ .owner = THIS_MODULE, .read = word_count_read, .write = word_count_write };
// �����豸�ļ�����Ϣ
static struct miscdevice misc =
{ .minor = MISC_DYNAMIC_MINOR, .name = DEVICE_NAME, .fops = &dev_fops };
// ��ʼ��Linux����
static int word_count_init(void)
{
int ret;
// �����豸�ļ�
ret = misc_register(&misc);
// �����־��Ϣ
printk("word_count_init_success\n");
return ret;
}
// �Linux����
static void word_count_exit(void)
{
// ɾ���豸�ļ�
misc_deregister(&misc);
// �����־��Ϣ
printk("word_init_exit_success\n");
}
// ע���ʼ��Linux�����ĺ���
module_init( word_count_init);
// ע��ж��Linux�����ĺ���
module_exit( word_count_exit);
MODULE_AUTHOR("lining");
MODULE_DESCRIPTION("statistics of word count.");
MODULE_ALIAS("word count module.");
MODULE_LICENSE("GPL");
|
��д���������Ҫ�˽����¼��㡣
1. word_count_read��word_count_write�����IJ���������ͬ��ֻ�е�2������buf��һ����졣word_count_read������buf����������char*����word_count_write������buf����������const
char*�������ζ��word_count_write�����е�buf����ֵ���ġ�word_count_read�����е�buf������ʾ���豸�ļ����������ݣ�Ҳ����˵��buf�е����ݶ��������豸�ļ����������ڿ��Զ����������ݣ�ȡ����word_count_read�����ķ���ֵ�����word_count_read��������n������Դ�buf����n���ַ�����Ȼ�����nΪ0����ʾ�������κε��ַ������nС��0����ʾ������ij�ִ���nΪ������룩��word_count_write�����е�buf��ʾ���û��ռ��Ӧ�ó���д������ݡ�buf����ǰ��һ����__user���꣬��ʾbuf���ڴ�����λ���û��ռ䡣
2. �����ں˿ռ�ij�����ֱ�ӷ����û��ռ��е����ݣ���ˣ���Ҫ��word_count_read��word_count_write�����зֱ�ʹ��copy_to_user��copy_from_user���������ݴ��ں˿ռ临�Ƶ��û��ռ����û��ռ临�Ƶ��ں˿ռ䡣
3. ����ֻ�ܴ��豸�ļ���һ�����ݡ�Ҳ����˵��дһ�����ݣ���һ�����ݺڶ������ٴ��豸�ļ������κ����ݡ������ٴ�д�����ݡ����������ͨ��read_flag�������Ƶġ���read_flag����ֵΪn����ʾ��û�ж����豸�ļ�����word_count_read�����л�������ȡ���ݡ����read_flag����ֵΪy����ʾ�Ѿ������豸�ļ��е����ݣ�word_count_read������ֱ�ӷ���0��Ӧ�ó�������ȡ�κ����ݡ�
4. ʵ����word_count_read������count������ʾ�ľ��Ǵ��豸�ļ���ȡ���ֽ���������Ϊʹ��cat�������word_count����ʱ��ֱ�Ӷ�ȡ��32768���ֽڡ����count������ûʲô���ˣ�ֵ����32768��������Ҫ��word_count_write�����н�д����ֽ������棬��word_count_read������ֱ��ʹ��д����ֽ�����Ҳ����˵��д����ٸ��ֽڣ��Ͷ������ٸ��ֽڡ�
5. ����д������ݶ�������mem�����С������鶨��Ϊ10000���ַ������д��������ֽ������ܳ���10000�����������
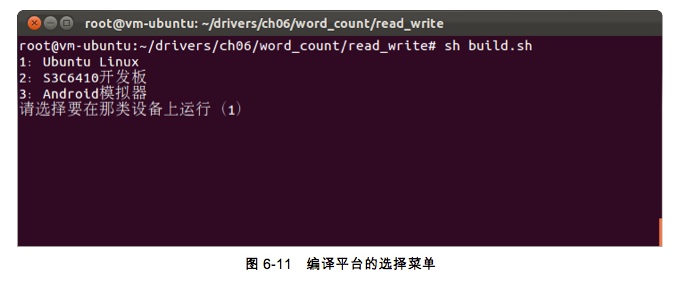
Ϊ�˷�����߲��Ա��ڵ����ӣ����߱�д�˼���Shell�ű��ļ���������UbuntuLinux��S3C6410�������Androidģ�����ϲ���word_count������������һ��������ȵĽű��ļ�build.sh���������е����Ӷ�����һ��build.sh�ű��ļ���ִ������ű��ļ��ͻ�Ҫ���û�ѡ��Դ������뵽�Ǹ�ƽ̨��ѡ��˵���ͼ6-11��ʾ���û���������1��2��3ѡ�����ƽ̨�����ֱ�Ӱ��س�����Ĭ��ֵ��ѡ���1������ƽ̨��UbuntuLinux����
build.sh�ű��ļ��Ĵ������£�
source /root/drivers/common.sh
# select_target��һ��������������ʾͼ6-11��ʾ��ѡ��˵����������û�������
# �ĺ�����common.sh�ļ��ж���
select_target
if [ $selected_target == 1 ]; then
source ./build_ubuntu.sh # ִ�б����Ubuntu Linuxƽ̨�����Ľű��ļ�
elif [ $selected_target == 2 ]; then
source ./build_s3c6410.sh # ִ�б����s3c6410ƽ̨�����Ľű��ļ�
elif [ $selected_target == 3 ]; then
source ./build_emulator.sh # ִ�б����Androidģ����ƽ̨�����Ľű��ļ�
fi
|
��build.sh�ű��ļ����漰����3���ű��ļ���build_ubuntu.sh��build_s3c6410.sh��build_emulator.sh������3���ű��ļ��Ĵ������ƣ�ֻ��ѡ���Linux�ں˰汾��ͬ������S3C6410��Androidģ����ƽ̨���������Linux���������Զ�������õ�Linux�����ļ���*.so�ļ����ϴ�����Ӧƽ̨��/data/localĿ¼������װLinux���������磬build_s3c6410.sh�ű��ļ��Ĵ������£�
source /root/drivers/common.sh
# S3C6410_KERNEL_PATH����������S3C6410ƽ̨��Linux�ں�Դ�����·����
# �ñ����Լ��������Ʊ�������common.sh�ű��ļ��ж���
make -C $S3C6410_KERNEL_PATH M=${PWD}
find_devices
# ���ʲô��ѡ��ֱ���˳�
if [ "$selected_device" == "" ]; then
exit
else
# �ϴ���������word_count.ko��
adb -s $selected_device push ${PWD}/word_count.ko /data/local
�� �ж�word_count�����Ƿ����
testing=$(adb -s $selected_device shell lsmod | grep "word_count")
if [ "$testing" != "" ]; then
# ɾ���Ѿ����ڵ�word_count����
adb -s $selected_device shell rmmod word_count
fi
# ��S3C6410�������а�װword_count����
adb -s $selected_device shell "insmod /data/local/word_count.ko"
fi
|
ʹ������Ľű��ļ�����Ҫ��read_writeĿ¼����һ��Makefile�ļ����������£�
obj-m := word_count.o
����ִ��build.sh�ű��ļ���ѡ��Ҫ�����ƽ̨����ִ�������������/dev/word_count�豸�ļ�д�����ݡ�
# echo ��hello lining�� > /dev/wordcount
Ȼ��ִ�����µ������/dev/word_count�豸�ļ���ȡ���ݡ�
# cat /dev/wordcount
��������hello lining����˵�����Գɹ���
ע�⣺�����S3C6410�������Androidģ�����ϲ���word_count��������Ҫִ��shell.sh�ű��ļ���adb
shell���������Ӧƽ̨���նˡ�����shell.sh�ű���/root/driversĿ¼�С������ַ�ʽ������������ж��Android�豸��PC����ʱ��shell.sh�ű������һ������ͼ6-11��ʾ��ѡ��˵����û�����ѡ������ĸ�Android�豸���նˣ���adb
shell�������Ҫ��-s�����в���ָ��Android�豸��ID�ſ��Խ�����ӦAndroid�豸���նˡ�
�š�ʵ��ͳ�Ƶ��������㷨
���ڿ�ʼ��дword_count������ҵ������ͳ�Ƶ�����������ʵ�ֵ��㷨���ɿո��Ʊ�����ASCII��9�����س�����ASCII��13���ͻ��з���ASCII��10���ָ����ַ�������һ�����ʣ����㷨ͬʱ�������ж���ָ������ո�����Ʊ������س����ͻ��з����������������word_count���������Ĵ��롣�ڴ����а�����ͳ�Ƶ������ĺ���get_word_count��
#include
#include
#include
#include
#include
#include
#define DEVICE_NAME "wordcount" // �����豸�ļ���
static unsigned char mem[10000]; // �������豸�ļ�д�������
static int word_count = 0; // ������
#define TRUE -1
#define FALSE 0
// �ж�ָ���ַ��Ƿ�Ϊ�ո����ո�����Ʊ������س����ͻ��з���
static char is_spacewhite(char c)
{
if(c == ' ' || c == 9 || c == 13 || c == 10)
return TRUE;
else
return FALSE;
}
// ͳ�Ƶ�����
static int get_word_count(const char *buf)
{
int n = 1;
int i = 0;
char c = ' ';
char flag = 0; // ��������ո�ָ��������0�����������1��������һ���ո�
if(*buf == '\0')
return 0;
// ��1���ַ��ǿո�0��ʼ����
if(is_spacewhite(*buf) == TRUE)
n--;
// ɨ���ַ����е�ÿһ���ַ�
for (; (c = *(buf + i)) != '\0'; i++)
{
// ֻ��һ���ո�ָ����ʵ����
if(flag == 1 && is_spacewhite(c) == FALSE)
{
flag = 0;
}
// �ɶ���ո�ָ����ʵ���������Զ���Ŀո�
else if(flag == 1 && is_spacewhite(c) == TRUE)
{
continue;
}
// ��ǰ�ַ�Ϊ�ո�ʱ��������1
if(is_spacewhite(c) == TRUE)
{
n++;
flag = 1;
}
}
// ����ַ�����һ�������ո��β������������������1��
if(is_spacewhite(*(buf + i - 1)) == TRUE)
n--;
return n;
}
// ���豸�ļ���ȡ����ʱ���õĺ���
static ssize_t word_count_read(struct file *file, char __user *buf, size_t count, loff_t *ppos)
{
unsigned char temp[4];
// ����������int���ͣ��ֽ��4���ֽڴ洢��buf��
temp[0] = word_count >> 24;
temp[1] = word_count >> 16;
temp[2] = word_count >> 8;
temp[3] = word_count;
copy_to_user(buf, (void*) temp, 4);
printk("read:word count:%d", (int) count);
return count;
}
// ���豸�ļ�д������ʱ���õĺ���
static ssize_t word_count_write(struct file *file, const char __user *buf, size_t count, loff_t *ppos)
{
ssize_t written = count;
copy_from_user(mem, buf, count);
mem[count] = '\0';
// ͳ�Ƶ�����
word_count = get_word_count(mem);
printk("write:word count:%d", (int)word_count);
return written;
}
// �������豸�ļ��������¼���Ӧ�Ļص�����ָ��
static struct file_operations dev_fops =
{ .owner = THIS_MODULE, .read = word_count_read, .write = word_count_write };
// �����豸�ļ�����Ϣ
static struct miscdevice misc =
{ .minor = MISC_DYNAMIC_MINOR, .name = DEVICE_NAME, .fops = &dev_fops };
// ��ʼ��Linux����
static int word_count_init(void)
{
int ret;
// �����豸�ļ�
ret = misc_register(&misc);
// �����־��Ϣ
printk("word_count_init_success\n");
return ret;
}
// �Linux����
static void word_count_exit(void)
{
// ɾ���豸�ļ�
misc_deregister(&misc);
// �����־��Ϣ
printk("word_init_exit_success\n");
}
// ע���ʼ��Linux�����ĺ���
module_init( word_count_init);
// ע��ж��Linux�����ĺ���
module_exit( word_count_exit);
MODULE_AUTHOR("lining");
MODULE_DESCRIPTION("statistics of word count.");
MODULE_ALIAS("word count module.");
MODULE_LICENSE("GPL");
|
��дword_count����������Ҫ�˽����¼��㡣
1. get_word_count������mem�����е�1��Ϊ��\0�����ַ���Ϊ�ַ����Ľ�β���������word_count_write�����н�mem[count]��ֵ��Ϊ��\0��������get_word_count������֪��Ҫͳ�Ƶ��������ַ������������������mem����ij���Ϊ10000�����ַ������һ���ַ�Ϊ��\0������˴�ͳ�Ƶ��ַ������Ϊ9999��
2. ������ʹ��int���ͱ����洢����word_count_write������ͳ�Ƴ��˵�������word_count������ֵ������word_count_read�����н�word_count���ͱ���ֵ�ֽ��4���ֽڴ洢��buf�С���ˣ���Ӧ�ó�������Ҫ�ٽ���4���ֽ���ϳ�int���͵�ֵ��
ʮ�����롢��װ��ж��Linux��������
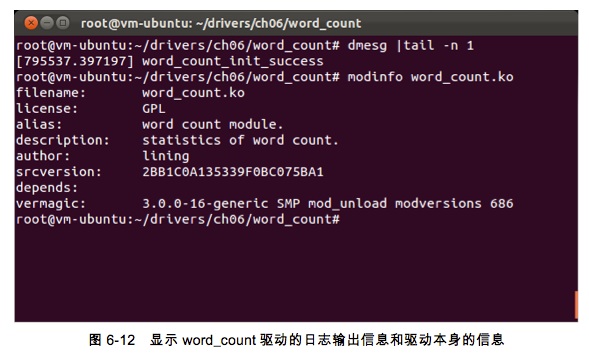
����һ��word_count���������Ѿ�ȫ����д����ˣ����Ҷ�α�����Ը���������װ��ж��word_count����Ҳ������Ρ�word_count������read_writeĿ¼�е�����һ����Ҳ��һ��build.sh��3����ƽ̨��صĽű��ļ�����Щ�ű��ļ���6.3.5�ڵ�ʵ�����ƣ����ﲻ����ϸ���ܡ�����ִ��build.sh�ű��ļ�����ѡ��Ҫ�����ƽ̨��Ȼ��ִ��������������鿴��־�����Ϣ��word_count����ģ�飨word_count.ko������Ϣ��
# dmesg |tail -n 1
# modinfo word_count.ko
�����ʾ��ͼ6-12��ʾ����Ϣ������word_count����������ȫ������
����Ľű��ļ�����ʹ��insmod���װLinux�����ģ����˸������⣬ʹ��modprobe����Ҳ����װLinux������insmod��modprobe��������modprobe������Լ������ģ��������ԡ���Aģ��������Bģ�飨װ��A֮ǰ������װ��B�������ʹ��insmod����װ��Aģ�飬����ִ���ʹ��modprobe����װ��Aģ�飬Bģ�������װ�ء���ʹ��modprobe����װ������ģ��֮ǰ����Ҫ��ʹ��depmod������Linux����ģ���������ϵ��
# depmod /root/drivers/ch06/word_count/word_count.ko
depmod����ʵ���Ͻ�Linux����ģ���ļ���������·�������ӵ����µ��ļ��С�
/lib/modules/3.0.0-16-generic/modules.dep
ʹ��depmod��������������ϵ�Ϳ��Ե���modprobe����װ��Linux������
# modprobe word_count
ʹ��depmod��modprobe������Ҫע�����¼��㣺
1. depmod�������ʹ��Linux����ģ�飨.ko�ļ����ľ���·����
2. depmod����Ὣ�ں�ģ���������Ϣд�뵱ǰ����ʹ�õ��ں˵�modules.dep�ļ������磬���ߵ�Ubuntu
Linuxʹ�õ���Linux3.0.0.16������Ӧ��3.0.0-16-genericĿ¼ȥѰ��modules.dep�ļ����������ʹ��������Linux�ںˣ���Ҫ����Ӧ��Ŀ¼ȥѰ��modules.dep�ļ���
3. modprobe����ֻ��ʹ���������Ƽ��ɣ�����Ҫ��.ko��
|


