| 编辑推荐: |
通过这篇文章,你将了解到Claude Code用于CR的流水线搭建原理和效果,如何在1分钟内接入你的代码项目,并启发你对AI Coding Agent用于CI/CD提效的思考,希望对你的学习有帮助。
本文来自于阿里云开发者公众号,由火龙果软件Alice编辑推荐。 |
|
问题痛点
当前CR流程说明: 目前我们组的CR流程,是研发完成代码开发后,在代码平台上手动开启代码评审单,交由多位同学人工评审,同时触发Aone AI评审。
当前流程的 主要问题 如下:
1. 人工评审耗时较长,员工心力消耗大,可能会拖慢小组整体的研发节奏,同时也不一定保证能发现所有问题;
2. 现有的代码分析、AI评审工具,也都存在一些经常发生的问题:
- 误报较多;
- 分析不够深入,无法联合分析上下游代码,许多业务逻辑问题难发现;
- 纠正意见不太实用。
解决思路
我们尝试利用 Claude Code 的强大AI Coding Agent能力,结合 AONE MCP Server ,来在 代码平台CI流水线 中实现更智能的AI代码评审,为团队提供一个 低成本、高收益 的代码质量检查工具。
Claude Code 官方文档: https://docs.anthropic.com/zh-CN/docs/claude-code/quickstart
当前效果
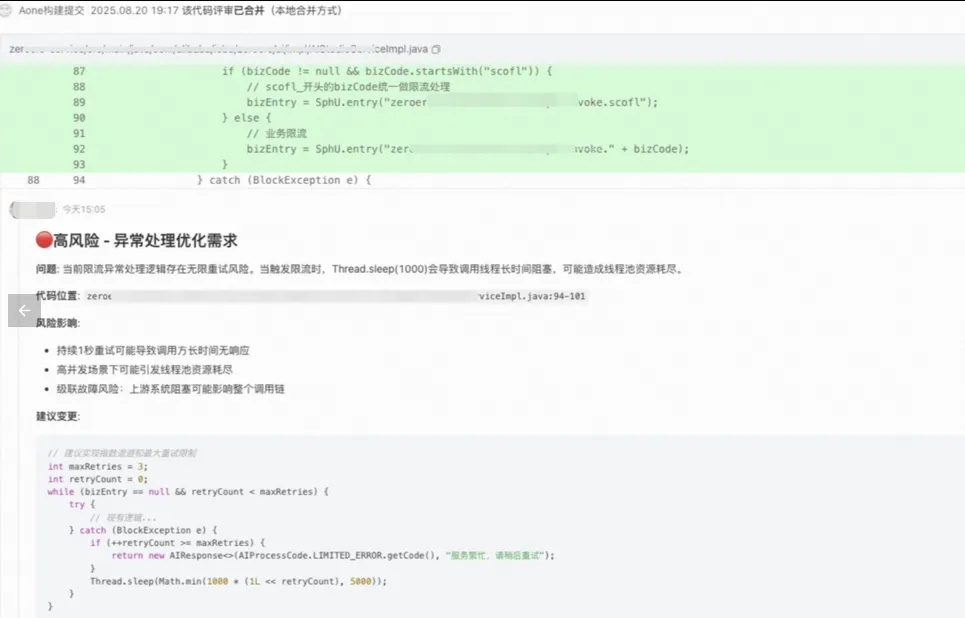
运行效果 当代码评审开启以及后续新增commit时,会触发CR流水线开启AI分析,最终将分析结果同步至CR评论区,如下图(发现了项目里一直存在但没人提出的死循环阻塞获取限流锁的代码)。
提效效果 目前体感来看,许多AI建议是有必要的、能启发人的。其中,人分析到但AI没考虑到的情况比较少。但是,因为还在调试阶段,所以也不是能解决全部问题。因此,估摸给个数字的话,可能是 提效50% 以上。
长期预测来看,如果后续调教优化得好,应该在以下2方面给CR工作带来明显收益:
- 提效:辅助人工,大幅减少发现问题、分析问题、给出建议的时间,80%不是问题;
- 提质:超越人工,发现人工察觉不了的潜在问题,给质量工程满满安全感;
解决方案详细说明
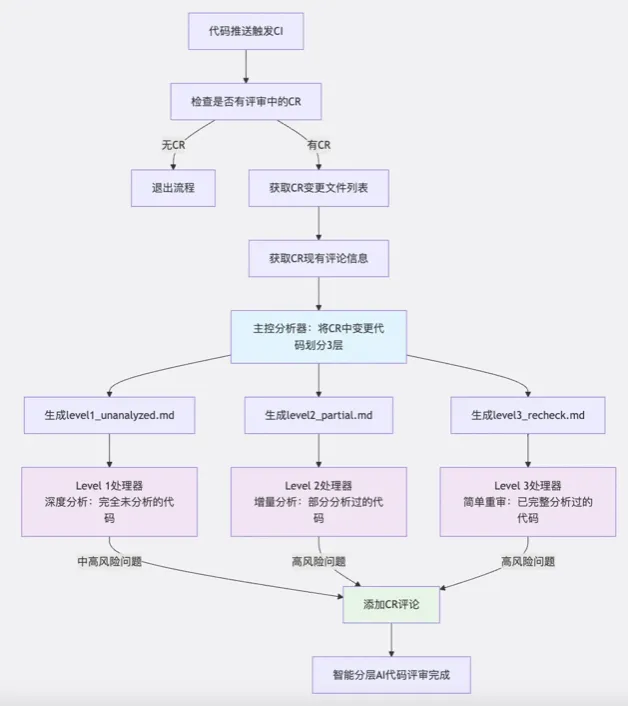
整体流程架构
核心设计要点 1. 可配置的Claude Code流水线模板
封装了一个流水线模板在代码平台市场,提供了自动安装最新Claude Code的容器环境,支持配置Claude Code API相关信息、Aone MCP Server API、容器执行Shell脚本(可以完全自定义如何调用Claude Code)、流水线触发条件和事件通知方式。
2. 基于MCP的CR信息交互
通过AONE MCP Server获取CR相关信息,避免了git获取远程信息时的权限问题。
3. 变更代码智能分层处理策略
- Level 1:完全未分析的区域 → 重点深度分析;
- Level 2:部分分析过的区域 → 对于后续新增commit里,增量的新代码进行重点分析;
- Level 3:已完整分析过的区域 → 简单的重审分析;
4. Multi/Background Agent 并行处理提升效率
3个处理器同时工作,每个专注于不同类型的代码变更,提高整体处理速度。
5. 超时控制
调用Claude Code实例时,指定最大运行时长,默认30分钟。
具体流水线配置(迭代优化中)
name: Claude Code AI CR
triggers:
push:
branches:
- feature/**
merge_request:
target-branches:
- '**'
params:
ANTHROPIC_BASE_URL:
name: ANTHROPIC_BASE_URL
description: Claude Code 环境变量,指定模型端口地址
required: true
ANTHROPIC_AUTH_TOKEN:
name: ANTHROPIC_AUTH_TOKEN
description: Claude Code 环境变量,指定模型访问密钥
required: true
ANTHROPIC_MODEL:
name: ANTHROPIC_MODEL
description: Claude Code 环境变量,指定模型型号,可为空
required: false
AONE_MCP_URL:
name: AONE_MCP_URL
description: AONE MCP SERVER的url,在code界面右侧可以获取到
required: true
shell:
name: shell
description: 执行脚本
required: false
default: |-
#!/bin/bash
# =============================================================================
# 基于 MCP 的智能分层 AI 代码评审系统
# 解决方案:通过 AONE MCP 获取 CR 信息,实现智能增量分析
# =============================================================================
# 配置 MCP 连接
cat > mcp.json << 'EOF'
{
"mcpServers": {
"aone": {
"type": "sse",
"url": "${{params.AONE_MCP_URL}}"
}
}
}
EOF
repo=${{git.repo}}
sourceBranch=${{git.branch}}
echo "仓库: ${repo}, 分支: ${sourceBranch}"
# =============================================================================
# 步骤1: 检查是否存在评审中的 CR
# =============================================================================
echo "步骤1: 查找评审中的 CR..."
cr_info=$(claude --permission-mode acceptEdits --mcp-config mcp.json --allowedTools
"mcp__aone__list_repo_merge_requests" --print "使用 aone mcp 的 list_repo_merge_requests 工具,
指定3个参数为 repo=${repo}, state=opened, sourceBranch=${sourceBranch}
来查看评审中的 CR,如果失败请重试3次,如果最终还是不存在,则返回 'CR_NOT_FOUND'")
echo "CR查询结果: $cr_info"
echo "$cr_info" | grep -q 'CR_NOT_FOUND' && {
echo "未找到评审中的 CR,退出分析"
exit 0
}
# 判断已经存在的CR评论是否已经超过限制
comments_info=$(claude --permission-mode acceptEdits --mcp-config mcp.json --allowedTools
"mcp__aone__list_merge_request_comments" --continue --print
"使用 mcp__aone__list_merge_request_comments 工具获取当前分支已经提过的所有评论信息,
如果已经存在的高风险问题评论数量超过 15个,则返回'CR_MORE_LIMIT',否则返回未超过限制")
echo "评论结果: $comments_info"
echo "$comments_info" | grep -q 'CR_MORE_LIMIT' && {
echo "添加评论已超过限制,退出分析"
exit 0
}
# =============================================================================
# 步骤2: 获取 CR 的变更文件和现有评论
# =============================================================================
echo "步骤2: 获取 CR 变更文件和现有评论..."
# 获取变更文件列表
echo "===================================获取变更文件列表 START=========================================="
claude --permission-mode acceptEdits --mcp-config mcp.json --allowedTools
"mcp__aone__list_merge_request_changed_files" --continue --print
"使用 mcp__aone__list_merge_request_changed_files 工具获取当前分支用户更改过的所有变更文件列表,
生成一个changed_files.md,必须写changed_files.md 文件成功,如果没有成功请重试3次"
cat changed_files.md
echo "
===================================获取变更文件列表 END==========================================
"
# 获取现有评论
echo "===================================获取现有评论 START=========================================="
claude --permission-mode acceptEdits --mcp-config mcp.json --allowedTools
"mcp__aone__list_merge_request_comments" --continue --print
"使用 mcp__aone__list_merge_request_comments 工具获取当前分支已经提过的所有评论信息,
生成一个existing_comments.md,必须写 existing_comments.md 文件成功,如果没有成功请重试3次"
cat existing_comments.md
echo "
===================================获取现有评论 END==========================================
"
# =============================================================================
# 步骤3: 主控分析器 - 智能分层分析
# =============================================================================
echo "步骤3: 执行智能分层分析..."
exe_info=$(claude --permission-mode acceptEdits --mcp-config mcp.json --allowedTools
"mcp__aone__get_changed_file_diff" --print "
作为代码评审的主控分析器,执行以下任务:
1. 读取当前分支中变更文件列表文档:changed_files.md
2. 读取当前分支中现有评论文档:existing_comments.md
3. 使用 mcp__aone__get_changed_file_diff 工具获取每个变更文件的具体 diff, 如果获取失败,
忽略该文件,继续获取下个变更文件的具体 diff
然后进行智能分层分析,对变更区域进行3个划分,生成3个精炼的描述文件:
**level1_unanalyzed.md** - 完全未分析的区域
- 格式:文件路径 | 行号范围 | 变更类型 | 关键信息
- 区域判断标准:没有任何评论覆盖的代码变更区域
- 要求:仅采纳高风险问题,添加的CR必须添加到对应的行数位置
**level2_partial.md** - 部分分析过的区域
- 格式:文件路径 | 行号范围 | 变更类型 | 新增部分描述
- 区域判断标准:有部分评论但存在新增行的代码区域
- 要求:仅采纳高风险问题,添加的CR必须添加到对应的行数位置
**level3_recheck.md** - 需要重新审视的区域
- 格式:文件路径 | 行号范围 | 变更类型 | 重审原因
- 区域判断标准:已有评论但代码发生显著变化的区域
- 要求:仅采纳高风险问题,添加的CR必须添加到对应的行数位置
要求:
- 执行必须检查 changed_files.md 和 existing_comments.md 是否存在,如果不存在,则返回 'FILE_NOT_FOUND'
- 严格注意底线:只看当前分支里变更的部分!不允许对当前分支未变更的部分添加评论!
- 每个描述文件内容精炼简短
- 明确标识出具体的文件路径和行号范围
- 便于后续3个处理器并行处理
- 同样的问题不能重复提评论
- 添加的评论必须添加到对应代码对应的行数位置,不允许错位
- 仅采纳高风险问题
- 添加的评论必须检查之前是否已经存在相似评论,如果已经存在相似评论,不能重复添加
- 三个分层添加的评论,必须追加到 existing_comments.md, 每次添加评论必须检查是否在
existing_comments.md 存在相似记录,存在就不能重复添加
")
echo "分层分析执行结果: $exe_info"
echo "$exe_info" | grep -q 'FILE_NOT_FOUND' && {
echo "未找到变更文件和评论,退出分析"
exit 0
}
# =============================================================================
# 步骤4: 分层并行处理(3个独立的 Claude Code 实例)
# =============================================================================
echo "步骤4: 启动分层并行处理..."
# Level 1 处理器 - 深度分析未分析区域
echo "启动 Level 1 处理器(深度分析)..."
claude --permission-mode acceptEdits --mcp-config mcp.json --allowedTools "mcp__aone" --print "
作为[仓库: ${repo}, 分支: ${sourceBranch}]代码评审的 Level 1 处理器,专注深度分析:
1. 读取 level1_unanalyzed.md 中的未分析区域
2. 对这些区域进行完整的代码审查(重点:全面分析逻辑、性能问题)
3. 给出问题点分析,严格遵守以下5个要点
**统一评论格式要求:**
- 问题标题(带风险等级标识:🔴高风险 🟡中风险 🟢低风险)
- 问题描述
- 代码范围(文件名和具体行号;如果代码不多,请用代码块直接展示出来)
- 修改建议
- Markdown 格式,良好可读性
4. 最重要的任务:仅对高风险的问题点上报CR评论,上报CR时检查existing_comments.md是否存在相似评论,存在就不再添加,
**不存在相似评论**使用mcp aone的 comment_merge_request_changed_file 工具来为CR添加评论。
⚠️ 重要提醒:你在非交互式CI环境中运行,不能建议手动操作!必须自动执行工具调用!
要求:
- 严格注意底线:只看当前分支里变更的部分!不允许对当前分支未变更的部分添加任何评论
- 添加的评论必须添加到当前分支对应的行数位置,不允许错位添加!
- 仅采纳高风险问题
- 添加的评论必须检查是否已经存在相似评论,如果已经存在相似评论,就不要再添加评论了,
只有没有存在相似评论才调用工具添加评论
- 添加的评论必须追加到 existing_comments.md, 每次添加评论前必须检查是否在 existing_comments.md
存在相似记录,存在就不能重复添加
- 类属性访问范围、接口访问范围 不添加评论
" &
level1_pid=$!
# Level 2 处理器 - 增量分析部分分析区域
echo "启动 Level 2 处理器(增量分析)..."
timeout 1800 claude --permission-mode acceptEdits --mcp-config mcp.json --allowedTools "mcp__aone" --print "
作为[仓库: ${repo}, 分支: ${sourceBranch}]代码评审的 Level 2 处理器,专注增量分析:
1. 读取 level2_partial.md 中的部分分析区域
2. 重点关注新增的代码行(重点:新增逻辑正确性、兼容性、边界情况)
3. 避免与现有评论重复,只分析新增部分
4. 给出问题点分析,严格遵守以下5个要点
**统一评论格式要求:**
- 问题标题(带风险等级标识:🔴高风险 🟡中风险 🟢低风险)
- 问题描述
- 代码范围(文件名和具体行号;如果代码不多,请用代码块直接展示出来)
- 修改建议
- Markdown 格式,良好可读性
5. 最重要的任务:仅对高风险的问题点上报CR评论,上报CR时检查existing_comments.md是否存在相似评论,存在就不再添加,
**不存在相似评论**使用mcp aone的 comment_merge_request_changed_file 工具来为CR添加评论。
⚠️ 重要提醒:你在非交互式CI环境中运行,不能建议手动操作!必须自动执行工具调用!
要求:
- 严格注意底线:只看当前分支里变更的部分!不允许对当前分支未变更的部分添加任何评论
- 添加的评论必须添加到当前分支对应的行数位置,不允许错位添加!
- 仅采纳高风险问题
- 添加的评论必须检查是否已经存在相似评论,如果已经存在相似评论,就不要再添加评论了,只有没有存在相似评论才调用工具添加评论
- 添加的评论必须追加到 existing_comments.md, 每次添加评论前必须检查是否在 existing_comments.md 存在相似记录,存在就不能重复添加
- 类属性访问范围、接口访问范围 不添加评论
" &
level2_pid=$!
# Level 3 处理器 - 轻量重审变更影响
echo "启动 Level 3 处理器(变更影响重审)..."
timeout 1800 claude --permission-mode acceptEdits --mcp-config mcp.json --allowedTools "mcp__aone" --print "
作为[仓库: ${repo}, 分支: ${sourceBranch}]代码评审的 Level 3 处理器,专注变更影响重审:
1. 读取 level3_recheck.md 中需要重审的区域
2. 分析代码变更对现有逻辑的影响(重点:接口变更、业务逻辑风险)
3. 检查是否有破坏性变更或逻辑冲突
4. 给出问题点分析,严格遵守以下5个要点
**统一评论格式要求:**
- 问题标题(带风险等级标识:🔴高风险 🟡中风险 🟢低风险)
- 问题描述
- 代码范围(文件名和具体行号;如果代码不多,请用代码块直接展示出来)
- 修改建议
- Markdown 格式,良好可读性
5. 最重要的任务:仅对高风险的问题点上报CR评论,上报CR时检查existing_comments.md是否存在相似评论,存在就不再添加,
**不存在相似评论**使用mcp aone的 comment_merge_request_changed_file 工具来为CR添加评论。
⚠️ 重要提醒:你在非交互式CI环境中运行,不能建议手动操作!必须自动执行工具调用!
要求:
- 严格注意底线:只看当前分支里变更的部分!不允许对当前分支未变更的部分添加任何评论
- 添加的评论必须添加到当前分支对应的行数位置,不允许错位添加!
- 仅采纳高风险问题
- 添加的评论必须检查是否已经存在相似评论,如果已经存在相似评论,就不要再添加评论了,只有没有存在相似评论才调用工具添加评论
- 添加的评论必须追加到 existing_comments.md, 每次添加评论前必须检查是否在 existing_comments.md 存在相似评论,存在就不能重复添加!
- 类属性访问范围、接口访问范围 不添加评论
" &
level3_pid=$!
# 等待所有并行处理器完成(带超时监控)
echo "等待所有处理器完成(最多10分钟)..."
start_time=$(date +%s)
max_wait=1800 # 10分钟
while true; do
current_time=$(date +%s)
elapsed=$((current_time - start_time))
# 检查是否超过最大等待时间
if [ $elapsed -gt $max_wait ]; then
echo "处理器运行时间超过 ${max_wait} 秒,强制终止..."
kill $level1_pid $level2_pid $level3_pid 2>/dev/null
echo "所有处理器已强制终止"
break
fi
# 检查所有进程是否完成
if ! kill -0 $level1_pid 2>/dev/null && ! kill -0 $level2_pid 2>/dev/null && ! kill -0 $level3_pid 2>/dev/null; then
echo "所有处理器已完成"
break
fi
# 显示进度
running_count=0
kill -0 $level1_pid 2>/dev/null && running_count=$((running_count + 1))
kill -0 $level2_pid 2>/dev/null && running_count=$((running_count + 1))
kill -0 $level3_pid 2>/dev/null && running_count=$((running_count + 1))
echo "还有 ${running_count} 个处理器在运行中... (已运行 ${elapsed}s)"
sleep 30 # 每30秒检查一次
done
echo "智能分层 AI 代码评审完成!"
# =============================================================================
# 验证步骤:检查是否真的添加了评论
# =============================================================================
echo "验证步骤: 检查AI是否真的添加了评论..."
claude --permission-mode acceptEdits --mcp-config mcp.json --allowedTools
"mcp__aone__list_merge_request_comments" --print "
验证任务:
1. 使用 mcp__aone__list_merge_request_comments 工具重新获取CR的所有评论
2. 对比旧的existing_comments.md,检查是否有新的AI评论被添加
3. 如果没有发现新评论,明确报告'验证失败:AI未添加任何评论'
4. 如果发现了新评论,报告'验证成功:AI成功添加了X条评论'
"
# =============================================================================
# 完成总结
# =============================================================================
echo "
✅分析完成总结:
"
jobs:
claude-code:
image: alios-8u
steps:
- uses: checkout
- uses: setup-env
inputs:
node-version: 20
tnpm-version: 10
tnpm-cache: true
- id: Claude_Code_Run
run: |-
tnpm install -g @anthropic-ai/claude-code
export ANTHROPIC_BASE_URL=${{params.ANTHROPIC_BASE_URL}}
export ANTHROPIC_AUTH_TOKEN=${{params.ANTHROPIC_AUTH_TOKEN}}
export ANTHROPIC_MODEL=${{params.ANTHROPIC_MODEL}}
echo claude-code安装成功
${{params.shell}}
|
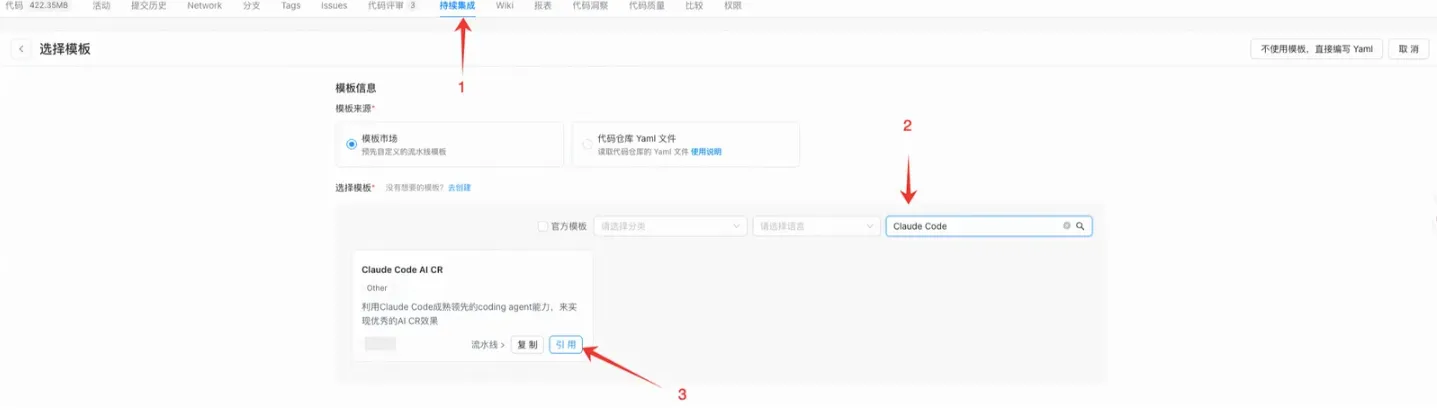
使用方式:如何让你的代码库一分钟快速接入
1. 在代码仓库的 持续集成 页面,点击 新建任务。
2. 在模板市场中,搜索 Claude Code AI CR 模板并引用。
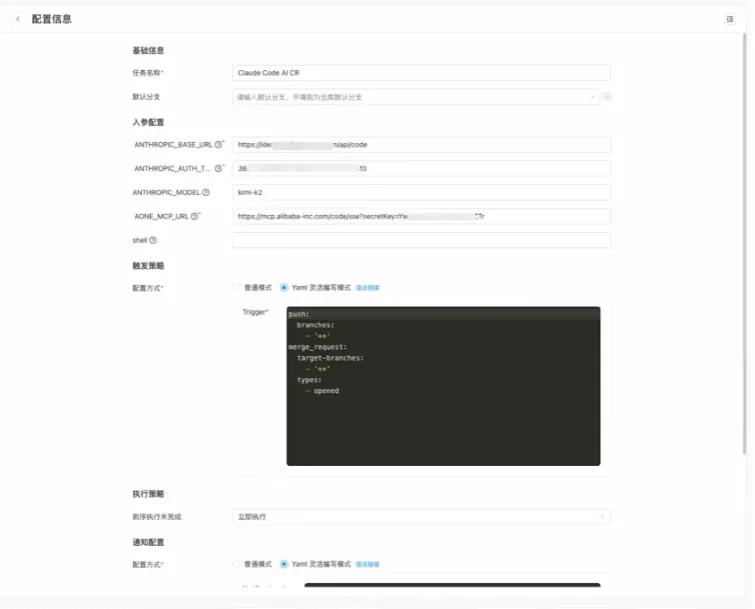
3. 配置4个环境变量:
- ANTHROPIC_BASE_URL : Claude Code 模型端点地址;
- ANTHROPIC_AUTH_TOKEN : Claude Code 访问密钥;
- ANTHROPIC_MODEL : 模型型号;
- AONE_MCP_URL : Aone · 代码平台的MCP端口;
4. 确认一下,触发策略这里最后选上这2个时机(通配符规则自己定)。
5. 提交配置。
6. 随后,开启一个代码评审,即可触发。通过观测流水线日志和CR评论区,来判断是否运行成功。
💡 注意入参配置里的shell,不填的话会默认使用我提供的命令(见上面流水线的脚本)。如果你觉得效果不好,需要调整(确实有很多细节要调整),可以自己设置哦。
使用建议
为了获得更好的CR效果,建议在项目中:
- 定制优化你的流水线Shell命令:当前流水线模板相当于提供了运行Claude Code的容器环境,里面如何执行命令、如何调用Claude Code,完全由你来自定义(将运行命令脚本填入入参配置里的shell字段,容器会在配置好Claude Code环境后,运行你的脚本)。
- 维护好CLAUDE.md(如果不了解,请查一下Claude Code相关使用教程)。
- 针对项目的特点, 优化prompt和工具调用 ,比如重要项目强调数据一致性问题的检查。
- 建立起 需求文档在代码库中的维护 习惯,AI Coding后期本质上将会是文档工程,文档质量决定了Agent在代码研发周期里的提效上限。
后续优化方向
1. Background Agent 模式的应用:当前我们只是简单的对CR中变更代码,就“是否已经被分析过”来进行了简单的划分,然后并行执行。在不同的项目中,完全可以进行不同纬度的划分,来并行处理。
2. Sub Agent 模式的应用:是由Claude Code支持的模式,可以在一个agent实例中将任务分给不同的子agent去并行做不同的事,专人专职,分析力更强,减少了上下文限制和幻觉的影响。比如,对一个CR任务,可以建立起 代码规范检查agent、上下游业务影响分析agent、数据一致性分析agent、稳定性分析agent 的协作机制。
3. Prompt 工程、上下文工程的调优:如何在提出要求之前准备好模型可能需要的一切?
4. Memory 机制的建立:如何将整个代码库的历史变更、历史文档、历史CR,作为长期记忆留存下来并反哺?
总结
通过这次Claude Code AI CR流水线的实践,我们实现了包括但不限于:
- 自动检测评审中的CR并进行智能分析;
- 基于现有评论避免重复分析,提高效率;
- 通过分层处理策略,针对不同复杂度的代码变更采用不同的分析深度;
- 多个Claude Code实例并行处理,显著缩短分析时间;
- 直接在CR页面添加结构化的评审意见,包含问题描述、风险等级、修改建议等;
- 发现人工容易遗漏的潜在问题(如案例中的死循环阻塞问题);
- 沉淀了可配置的流水线模板,支持一键部署和复用;
AI Coding Agent在代码评审场景的应用证明了其实用价值,50%+的提效 不仅减轻了人工负担,也提升了问题发现的广度和深度。 这套方案展示了将AI Agent集成到现有研发流程中的一种可行路径,为团队探索AI提效提供了具体的参考案例。
当然,这个方案更多是 给大家提供一个实践思路和技术起点 ,后续的优化空间还很大。
希望这次分享能启发更多团队探索AI Coding在自己业务场景中的应用可能性,共同推动研发效率的提升!欢迎大家尝试使用并提供反馈建议!
|







 订阅
订阅