| 编辑推荐: |
本文主要介绍了AIOps智能运维如何为集中监控这项传统运维领域最重要的手段(没有之一)添加智慧的引擎
。
本文来自于微信公众号擎创夏洛克AIOps,由火龙果软件Linda编辑、推荐。 |
|
关于AIOps建设的实现方法,擎创科技提出来了三大原则和六步走路线(参考上篇推送文章《智能运维建设,下一步可以做什么》),许多读者可能会希望了解,AIOps建设这盘大棋究竟为何六步走的第一步要落子于集中监控的改造?集中监控智能化的改造都需要考虑哪些方面,收益在哪里?如何通过集中监控的改造进一步的展开智能运维相关场景的建设?这里面的逻辑和衔接关系是怎样的?
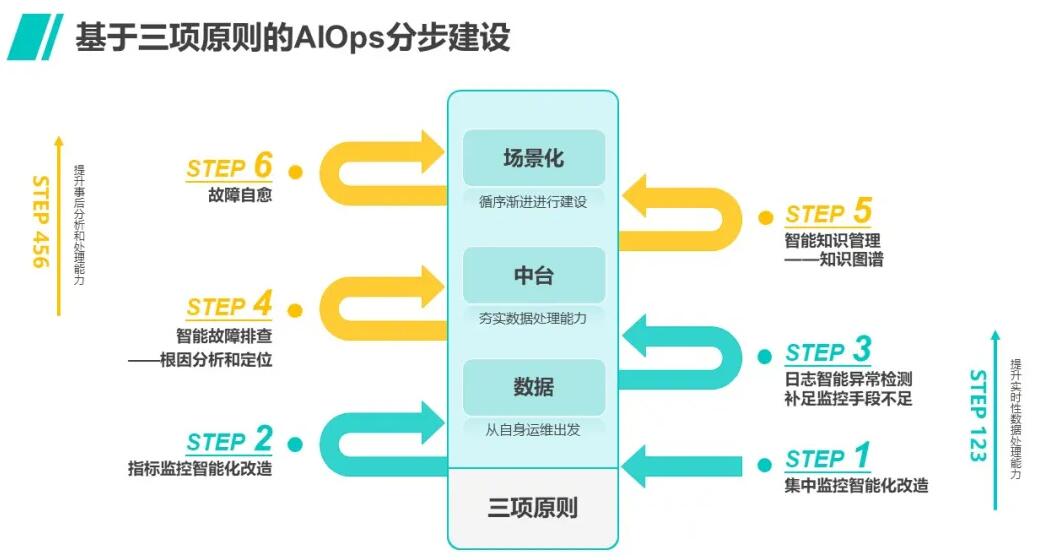
带着这些问题,我们来谈一谈AIOps智能运维如何为集中监控这项传统运维领域最重要的手段(没有之一)添加智慧的引擎。
一 传统集中监控之殇
如下图所示,运维体系中最重要的使命是及时发现问题,这在任何企业组织中都是不言而喻的。正是因为如此,企业才会在经年累月中布局了诸多监控手段,有些是商业化的工具,有些是运维人员为了获取被管理对象的状态写的形形色色的脚本,但总体都是为了及时发现问题。
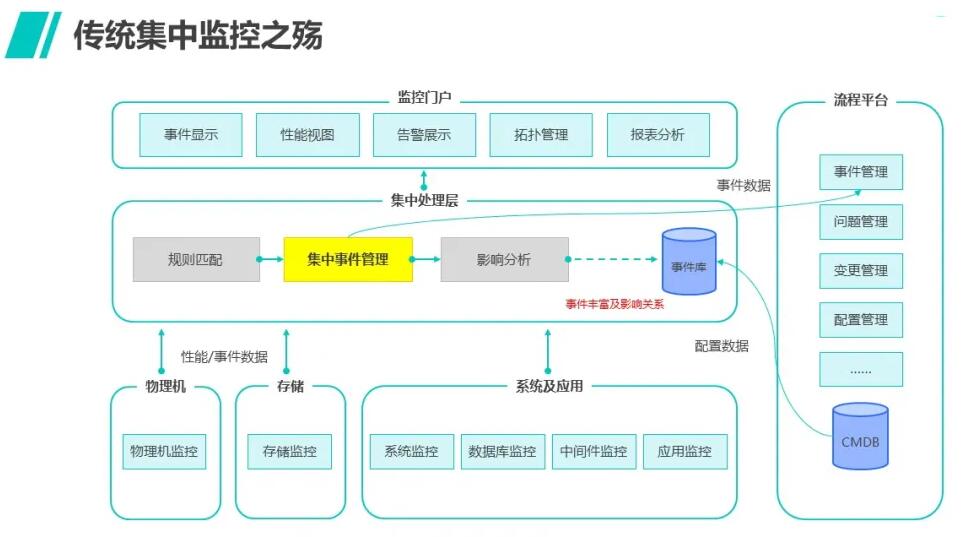
但是,当业务运行出现问题时,往往有许多监控工具都会产生多样化的事件(或者俗称告警),这些事件分散在各自不同的监控工具或者由脚本采集或者触发,没有一个统一的视角进行一站式的管理,这就是构建集中监控(或称统一监控)平台的主要动因。当然,集中监控还可以根据运维需要将事件分配给不同的运维人员进行处理,提高分工管理效率。
集中监控固然是视野够宽广,但随之而来的是另外一些问题,原始的事件里有许多重复性的、杂乱的噪音信息,而且某一个组件发生问题,往往会引发相关的组件都产生报警,这样在短时间内就会产生告警风暴,这也会严重影响运维人员的判断,因此传统的集中监控,都是依赖运维人员的经验梳理规则,并将事件归并、关联的规则运用于平台,实现告警抑制。
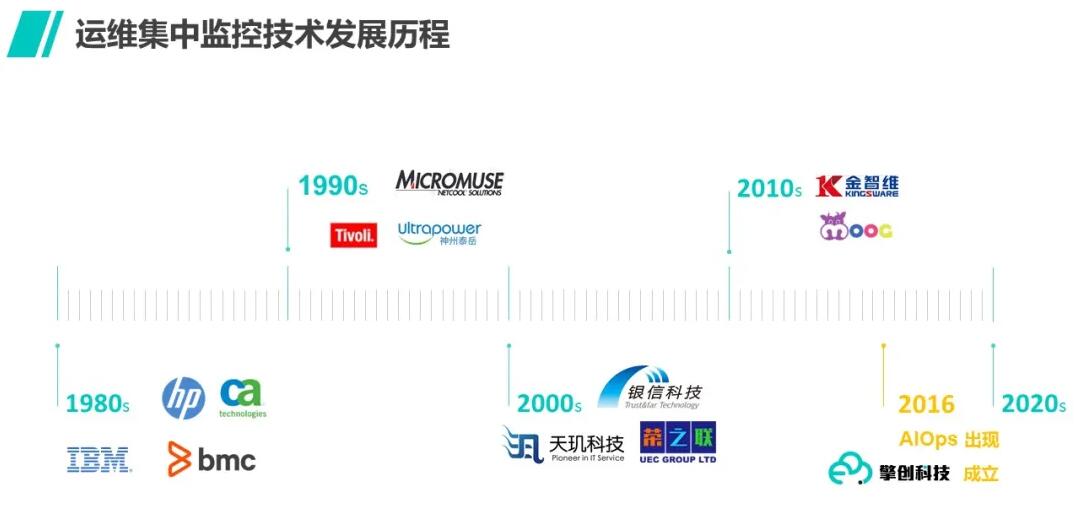
这种方式在传统运维领域已经有超过二十年历史,早在2002年,世界上第一家利用内存处理技术运行事件处理规则的产品Netcool
Omibus就在国内开始了业务,后来这家公司被IBM收购,至今还是IBM监控产品Tivoli的旗舰产品,国内也还有大量客户在使用。为什么要使用In
memory DB技术,就是因为规则会越积累越多,而基于规则匹配去处理事件,需要很多计算资源,否则处理速度赶不上事件产生的速度,就会丢漏事件,这是监控的大忌。
后来,BMC、HP等公司都开始用这种技术做集中监控产品,近年来国内的诸多公司也纷纷跟进,集中监控用设定规则处理告警的方式已经成为惯例。唯一的不同在于,由于业务逐渐走向分布式架构,近年来告警的量级达到一种一般关系型数据库难以企及的架构后,有些公司采用分布式数据库来替代传统架构,但上层的应用逻辑仍然是基于规则匹配处理。从表面上看,集中监控的出现确实实现了以集中视角看到各类告警的需求,一线人员对于告警有了一站式处理平台,效率相对于分散的监控工具确实得到了提升。
运维的世界真的就此安宁了吗?并非如此。
众所周知,规则,是一种经验的总结。只有出现过,甚至反复出现的规律,才能被总结为规则。因此传统集中监控仍然存在一些无法根治的弊端:

1 经验规则是有局限性的
若运维人员缺乏足够的经验,就无法梳理出有效的规则;再者,运维人员往往对自己负责的局部领域有经验,但对于其他部分则是小白,业务应用的载体一定是复杂的多个组件构成,不同领域的经验兼具才能发现一些相关性规则,而这些相关性无法仅仅通过“集中”就能发现,所以规则只能解决一部分问题。
2 对于新发生的或者偶发的事件关注度非常不够
告警虽然集中了,但却无法甄别出告警是否是全新的或者偶发的,这种类型的告警任何既有规则都无法覆盖,但往往蕴含杀机。举例来讲,任何变更后新增告警事件都应该给予高度关注,现在应用的敏捷迭代造成变更频发,一旦发现变更后出现罕见的事件,往往是故障发生的端倪。
3 缺乏优秀的综合排障和复盘分析机制
集中监控平台虽然能及时看到全局的告警,但是每条告警是分列的,缺乏分析某一个故障究竟和哪一些告警存在关系的能力,也无法甄别哪些告警可能是周期性出现的,或者每次故障发生前某一类告警存在一种数量递增的相关性趋势,这样的复盘分析能力缺失导致平台不能支持运维工作可持续改进,就很难进一步有效梳理出有利于故障发现的经验规则,持续提升运维一线处理效率,缩短MTTR也就难上加难。
正因为存在这些不足,传统集中监控往往是上线初期耳目一新,但经过一段时间使用后,仍然呈现出“没什么故障时,事件很少也没有人看,故障一旦发生时事件多得看不过来”的尴尬局面。
二 AIOps如何进行传统集中监控的智慧赋能
AIOps智能运维对于已经构建的传统集中监控系统首先是一种赋能的作用,也就是新建立的AIOps智能告警系统可以和既有的系统协同工作,这里会有一个并存的过程;在第二阶段,就可以随着智能监控的日益成熟逐步完成转型,也就是将主要的工作舞台迁移到智能集中监控系统;当然,对于还未构建集中监控的企业,完全可以换道超车,直接建立具备智能运维能力的集中监控系统。
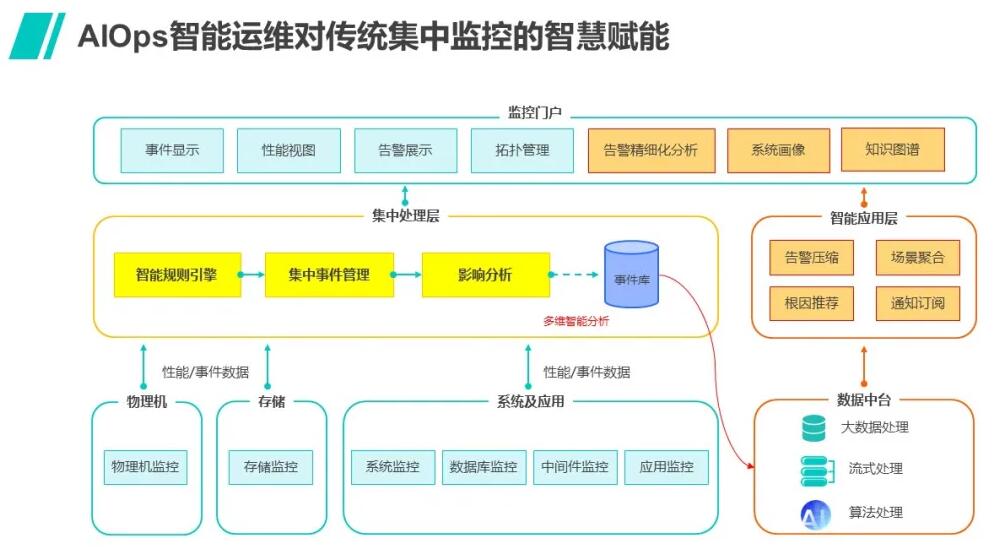
我们下面以擎创科技的夏洛克AIOps告警辨析中心为例,来展开分析这种AI赋能的几种方式:
1 对既有的完全基于经验进行规则梳理的处理方式的智慧赋能

夏洛克AIOps首先可以通过算法甄别重复性、相似性、相关性事件来进行告警事件的自动化抑制,从而使运维人员无须费心费力总结这些规则就能够达到很高的降噪压缩比,而同时,既有的规则仍然可以同时运行,因此夏洛克AIOps能够有效结合机器学习的洞察能力和既有运维经验所梳理的规则,充分提升了告警质量。
2 对事件的精细化分析能力的智慧赋能
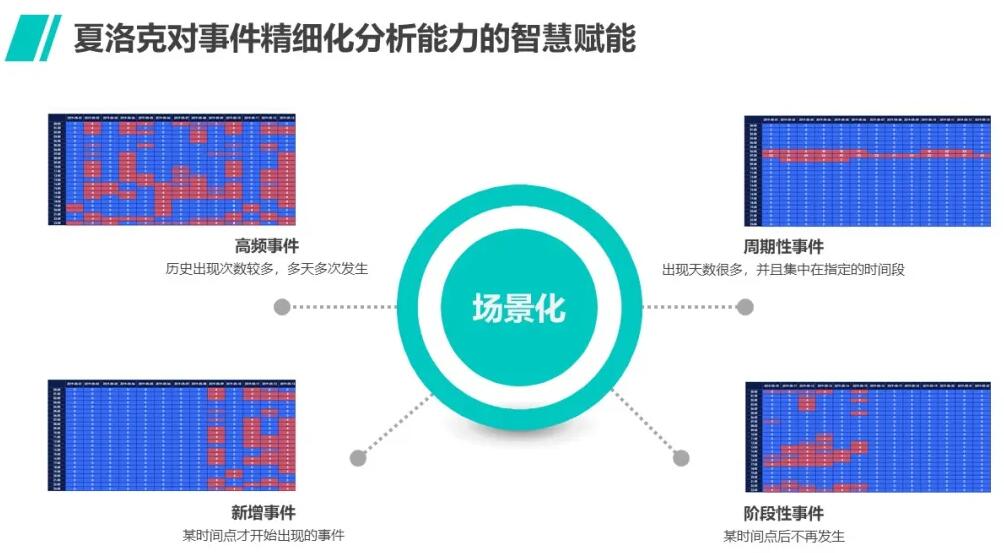
仅仅是在告警处理时降低噪声是远远不够的,传统监控往往是败在告警的分析能力不足上,看似监控是实时性更重要,但对于已发生的事件是否能进行有效的分析,直接关系到未来类似事件的处理能力是否能够提升,这一点往往在管理上重视度不够,任何事件发生,都应该以这样一种管理思路去分析。
(1)这究竟是什么性质的事件:这就要求做历史事件的特征分析
只有了解历史,才有机会认识未来。
历史事件给予的许多线索,通过算法洞察会比人的经验观察有效许多,夏洛克AIOps的告警智能辨析能力,能够有效的通过分类分析历史告警,从而了解事件的性质。究竟哪些是偶然发生的,哪些是首次出现的,哪些是经常且周期性发生的,而哪些是只在某个特殊阶段才出现的,这些分析有很重要的意义,因为这会使那些偶发或者突发新增的故障事件得到更多的关注,也可以降低对那些时常发生但并不影响业务的白噪声告警的关注度,这种智能分析力提升了对传统监控来说难以企及的数据洞察力。
(2)还有哪些相关性的事件:多种维度的相关性分析
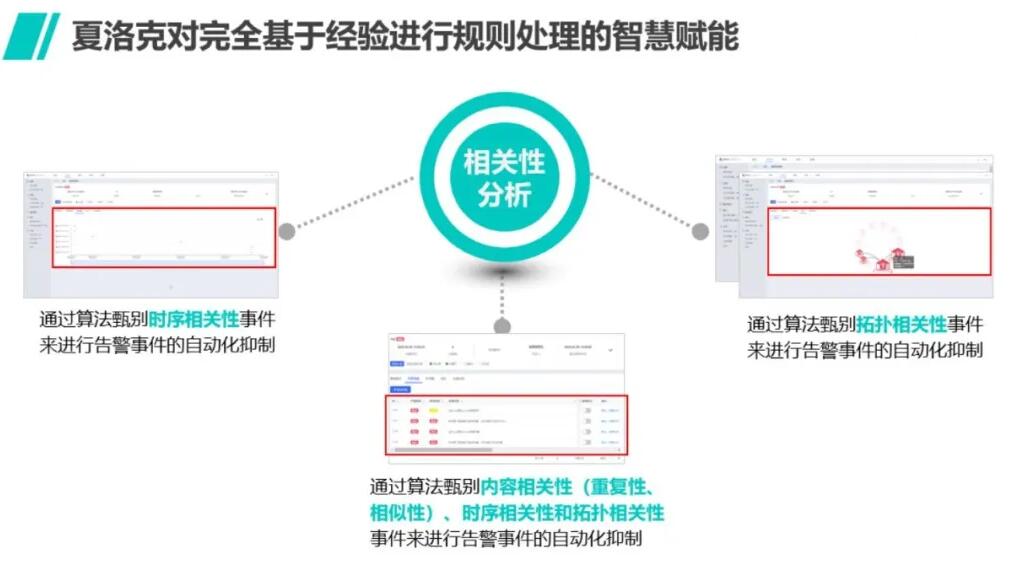
很少有告警是孤立发生的,因为业务服务架构复杂,往往牵一发而动全身,但告警间的关系也比较复杂,一般要从三个维度去考虑:第一是发生时间的关系,第二是告警内容逻辑上的关系,第三是拓扑结构的关系。
第一种,时间维度比较容易理解,告警发生的先后顺序往往对于指出根因有意义,但因为各个告警来源的不同造成时钟不同步,所以这种关系未必完全准确,只能作为参考;
第二种是内容逻辑维度,也就是语义上的相关性,比如通过算法可以识别出包含同某一种服务器名或者IP、URL地址的告警,进行聚类合并;
第三种最为重要,可以引入来自于CMDB的拓扑关系的维度来分析,当然这种维度也有其不确定性,比如源数据存在变更后未及时维护的错误。但是,AI和大数据的妙用在于利用模糊的信息得出相对可靠的推论,夏洛克AIOps利用专利的多维熵值算法模型,兼顾多种因素综合判断,从而使一些隐藏的规律被机器“学习”出来供运维人员使用。
(3)影响了何种业务:故障场景化的事件分析
相关性的发现最重要的价值在于故障排查,也就是了解哪些告警和具体的故障现象有联系,在夏洛克AIOps系统中,这种和某种故障有联系的多个告警组合称之为“场景”,若根据业务的基本架构,把同一业务服务的各个组件中那些可能存在相关性的告警汇聚到一个场景后,往往可以找到故障的根因,至少也可以给复杂排障提供一种前所未有的视角,从前一条条分列的告警,需要多个人分头排查,而有了自动生成的场景,多个不同专业的运维人员可以第一时间看到故障相关告警平铺在面前,对于协同排障和发现根因都很有帮助。
3 通过建立人工和智能相融合的迭代反馈机制促使监控持续优化

人不是万能的,有其局限性,但AI同样也有其局限性。因此关键在于如何利用AI的洞察力结合人的经验迭代反馈。在夏洛克AIOps告警辨析中心,告警的处理机制就是人机融合的典型例证。
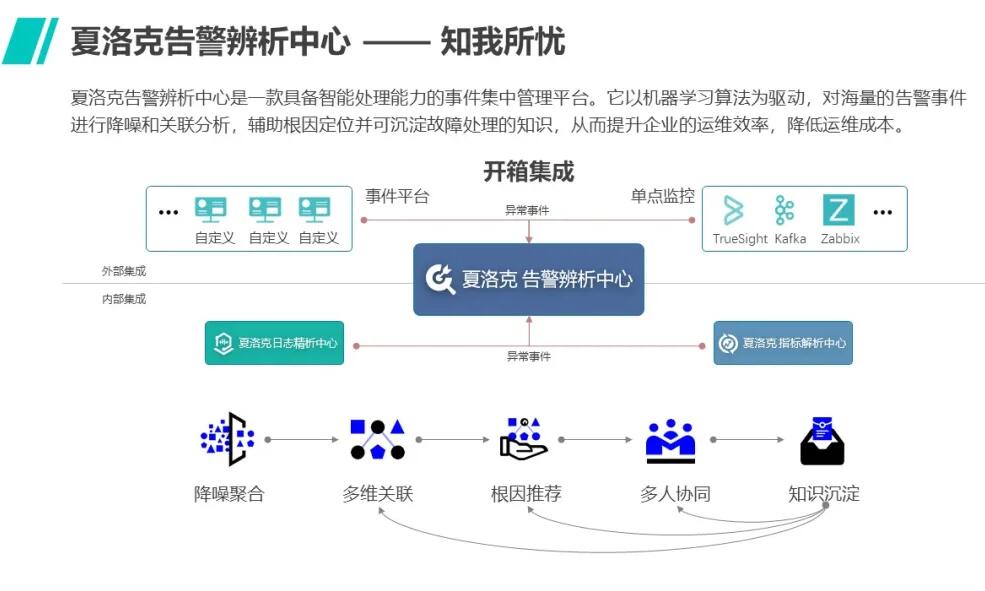
(1)通过不断分析反馈优化事件处理规则,提升监控准确度
通过多维相关性分析能力生成的业务故障场景,其准确性初期一定不会是100%的,但却可以通过运维人员的经验有效甄别,原来集合专家排障的喧闹的War
room,现在可以革新为在夏洛克告警辨析中心独创的机器学习沙盒中一起审核“场景”,机器推荐的优先级可以在这里得到判定,准确率高的场景推荐会被认可为留存知识,而其中的场景组合和根因可以被AI记录为算法迭代的要素,从而持续改进算法模型,为更准确的推荐故障场景做铺垫。同时,确定性高的场景还可以被规则化,为未来匹配度高的告警序列提供预警。这就形成了一种有持续改进智慧的集中监控系统。
(2)通过告警分析结果指导解决监控的覆盖面和有效性问题
持续改进不仅仅体现在告警处理和分析机制,事实上,我们还可以从分析结果中得到更多指导建议。
比对业务故障和既有场景中的相关事件,我们不难发现两种问题。第一是存在大量的被抑制的误报事件,而进一步分类分析则可以发现这些类别的噪音事件是由哪些对象产生的,具体反映若是指标类告警的,往往是由于该指标阀值设定得不合理,这就要考虑对于该类指标处理的智能化改造,具体的改进方式我们可以在下一讲再分享;
第二则是要比对哪些故障的根因是无法在既有发现的告警中找到的,这就是漏报,这是很严重的问题,要考虑扩大监控手段,有时可能比较简单,比如是监控集中的覆盖度不够,还存在未被纳管的指标、未被集中进来的监控工具或者未被有效利用的运维数据,比如APM的告警或者调用链信息;有些可能就比较复杂,特别是业务类的故障,往往在基础架构侧确实没有什么告警指向该问题,这时要考虑日志数据的利用,比如引入日志模式实时异常检测,帮助在第一时间发现异类业务日志模版或者某类日志量级上的异常变化,这些异常往往意味着故障根因,或者提升日志分析中的实时告警能力,这也会在后续文章中进一步讲解。
三 总结
综上所述,集中监控作为运维的“双眼”,应该是AIOps智慧赋能的第一站,赋能后的智能化集中监控将具备三大优势:
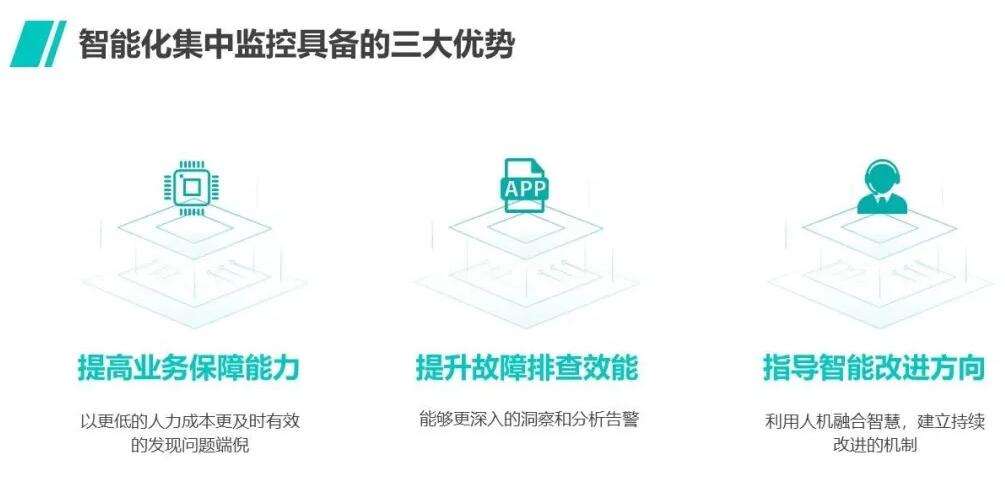
能够以更低的人力成本更及时有效地发现问题端倪,提高了业务保障能力;
能够更深入的洞察和分析告警,提升了故障排查效能;
能够利用人机融合的智慧,建立持续改进的机制,并且为进一步进行基础指标监控以及日志分析等其他领域的智能化改造提供了指导方向。
|









