| 编辑推荐: |
本文首先回顾了AIOps对监控报警架构的挑战,然后从工程角度聊了聊AIOps落地难的应对之策。
本文来自于微信公众号AIOps智能运维,由火龙果软件Linda编辑、推荐。 |
|
干货概览
监控报警是故障发现的重要一环,也是百度在AIOps的最早切入方向之一,目前百度AIOps在监控报警方面已经有两个场景取得突出效果:智能异常检测和智能报警合并。
如何支撑AIOps算法在监控报警系统的快速落地并产生业务价值,这对监控报警架构提出了很大的挑战!在上篇《AIOps对监控报警架构的挑战》文章中,我们介绍了监控报警系统在故障处理流程中的位置(故障发现和故障通告),并且分析了AIOps对监控报警架构的三个挑战。在本篇,我们将详细介绍应对这三个挑战的方案:
为了应对挑战一,我们研发了策略运行平台,让AIOps算法迭代找到飞一般的感觉。
为了应对挑战二,我们提出了基于状态机的事件管理引擎,让事件管理so easy。
为了应对挑战三,我们设计了灵活的报警合并方案,让值班工程师彻底跟报警风暴say bye bye。
下面我们来详细看下这三个方案的实现细节。
策略运行平台,让算法迭代飞起来
在上篇《AIOps对监控报警架构的挑战》文章中,我们提到异常判断在落地AIOps智能异常检测算法时,遇到的最大挑战是算法迭代周期长达一个月,费时费力,算法的迭代成本非常高。
为了能快速落地AIOps算法,并能产生好的效果,提高报警准确率,我们希望算法的迭代周期从月降低到天级别,为了达到这个目标,需要异常判断系统满足这些需求:
减少算法工程实现成本,弥合线下算法脚本和线上运行代码的鸿沟,从而能快速验证算法脚本的真实效果。
快速评估算法的稳定性、性能和资源消耗,尽早发现问题,不将问题带到线上,保证线上算法运行环境的稳定性。
分离算法代码和算法模型,支持算法模型的独立更新,加快算法模型的迭代速度。
基于这些需求,我们研发了策略运行平台。策略运行平台共分为三个环境:
离线环境:离线环境提供了策略开发框架,策略人员基于策略框架的标准Lib接口开发算法。同时策略开发框架还支持算法的离线回溯、时序数据可视化等功能。
在线环境:在线环境提供了一个稳定可靠的算法运行环境。在线环境会为每个任务启动一个子进程,在子进程中启动策略运行时环境,运行环境会提供跟策略开发框架一致的Lib接口,这样就可以将离线开发的算法脚本直接放到线上运行。
近线环境:近线环境和在线环境其实是同一套架构,只是目的不同。近线环境会引入线上的小流量数据提前进行算法验证,保证线上和线下的运行效果一致;另外,近线环境还会评估算法脚本的资源消耗和稳定性,如果评估结果不符合预期,那么算法脚本就会在近线环境被拦截住,从而保证线上环境的高可靠。

架构介绍 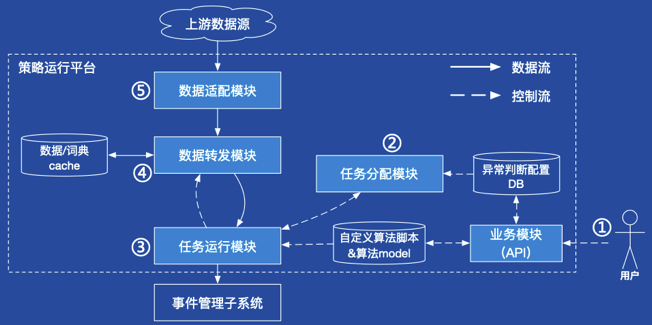
上图是策略运行平台的架构图,我们以新建一个报警策略的场景来依次介绍下每个模块的功能:
上层业务系统调用API接口,向业务模块发起新建策略的请求,业务模块会将报警配置、算法脚本和算法参数模型存储起来。
任务分配模块会实时感知到新创建的报警策略,并将报警策略转化为任务,然后分配给任务运行模块。
任务运行模块周期性汇报心跳给任务分配模块,通过心跳拉取分配给自己的任务列表。任务运行模块根据任务列表为每个任务启动一个策略运行时环境,运行时环境负责启动算法脚本,并周期性地驱动算法脚本执行异常判断逻辑。另一方面,任务运行模块根据报警策略配置向数据转发模块订阅所需的数据,将接收到的数据转发给运行时环境,并将算法脚本返回的异常判断结果发送给下游的事件管理系统。
数据转发模块根据订阅配置到数据源订阅数据,将接收到的数据转发给任务运行模块。同时,数据转发模块还会将所有接收到的数据存储到数据cache中,允许算法脚本在运行过程中方便地拉取近期的数据。
数据适配模块可以适配不同的上游数据源,支持推和拉两种获取数据模式。策略运行平台允许多个针对不同上游数据源的数据适配模块同时存在,从而支持平台中的报警策略使用来自于不同数据源的数据。
为了负载平衡和Failover,任务分配模块需要将报警任务在任务运行模块中的不同实例间移动。当一个报警任务从实例A移动到实例B上后,实例B会向数据转发模块订阅任务需要的数据,而实例A则相应取消数据订阅。这样,数据订阅模块就能够将数据转发到正确的实例上,从而保证任务的正常运行。
如果算法脚本在运行过程中存在内部状态,任务在实例B上启动后,可以在初始化的时候向数据cache请求近期的数据以重建内部状态。根据我们的实践经验,大部分任务只需要最近1到2个小时的数据就能够重建内部状态了。
通过策略运行平台,我们已经将算法迭代周期从月减少到天级别。另外,我们还将框架开放给业务运维工程师使用,业务运维工程师具有丰富的业务运维经验,由他们自己来开发异常检测算法,可以将他们的专家经验固化到报警系统中,提高报警的准确性。
状态机引擎,让事件管理更轻松
为什么报警事件需要用状态机描述呢?为了回答这个问题,我们首先介绍下什么是报警事件。
什么是报警事件? 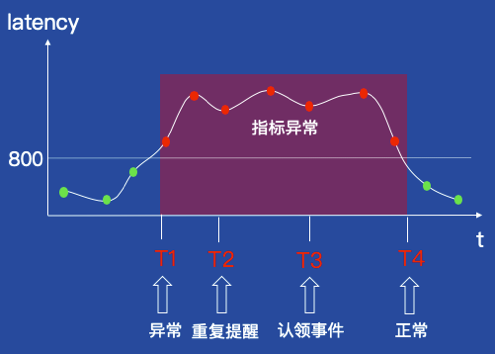
我们先来看一个简单的故障场景,上图中的时序数据展示了某服务的平均响应时间(latency),假设监控策略是如果latency大于800则报警:
很明显,在T1-T2时间段latency指标处于异常状态,在这期间有7个异常点,从运维工程师看来,这7个异常点应该归属为一个报警事件,所以报警事件是具有持续性(特征一)。
异常发生后,报警系统会在故障期间重复通告Oncall工程师,故障恢复后也需要发送恢复通知,所以一个报警事件会产生多个报警消息(特征二)。
另外,为了保证Oncall工程师介入处理故障期间免受打扰,我们还需要提供报警认领功能。如果报警认领的对象是报警消息(比如短信)。一方面,一个报警事件会产生多条报警消息,这意味着同一个人对同一个故障需要认领多次;另一方面,假设故障已经恢复,但是报警消息还没有被认领,会继续提醒Oncall工程师认领,这也不符合Oncall工程师的预期。所以报警认领的对象需要为报警事件(特征三)。
我们再来看一个更复杂的场景。在实际运维过程中,我们会分省份和运营商维度采集服务的平均响应时间(latency),即多维度数据。如果我们分别针对不同省份和运营商都单独配置一个监控策略,很明显,这会导致报警配置的管理成本很高,实际上运维工程师希望配置类似latency{isp=*,province=*}
> 80的报警策略,就可以同时对所有省份和运营商的latency指标进行分别判断,这就是所谓的多维度异常判断配置。
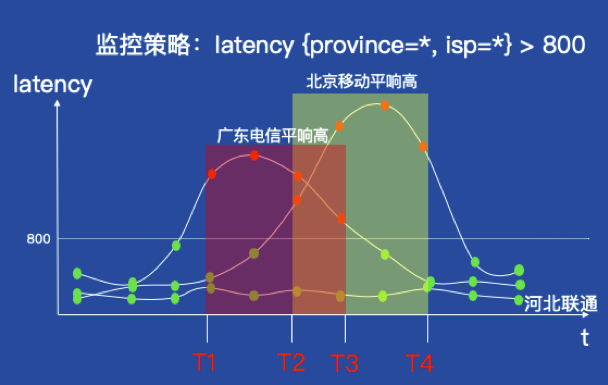
上图展示了一个多维度判断配置的例子,很明显,在T2-T3期间,广东电信和北京移动的latency指标同时发生异常。如果策略在故障期间只产生一个报警事件,那么我们根据事件无法区分是哪个省份和运营商的数据异常了,所以一个策略需要针对每个数据维度分别产生一个报警事件(特征四)。
上面通过两个业务场景介绍了报警事件的业务模型,以及报警事件的四个特征,让大家对报警事件有一个直观的认识,下面我们来看下基于状态机的事件管理引擎。
为什么需要状态机?
我们分报警认领和报警升级两个场景来介绍基于状态机的事件管理引擎。
1报警认领场景 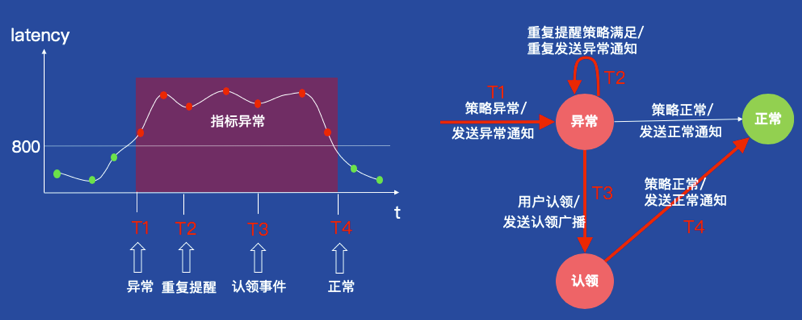
我们结合状态机来看下报警认领场景中,报警事件的生命周期是如何演化的:
T1时刻:latency指标异常,监控系统会产生一个异常状态的报警事件,并发送异常通知给Oncall工程师。
T2时刻:Oncall工程师没有响应报警,监控系统重复发送报警给Oncall工程师。
T3时刻:Oncall工程师响应报警,完成认领报警,表示已经在跟进中。同时,监控系统会将认领操作广播给所有的Oncall工程师,表示已经有人在跟进报警了。
T4时刻:Oncall工程师修复故障后,该报警事件变为正常状态,监控系统会发送故障恢复通知。
我们可以看到,报警事件的状态变迁过程其实就是一个状态机的运行过程,每个状态都有对应的进入条件和动作,所以我们将报警事件抽象成状态机来描述它。
2报警升级场景
我们再来看一个报警升级的场景,假设对应的报警升级配置如下所示:
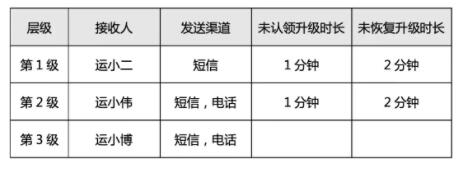
其中第1级配置的含义是:报警接收人为运小二,报警发送渠道为短信,如果超过1分钟没有进行报警认领,或者认领了但是超过2分钟故障没有恢复,则报警事件会升级到第二级。其他层级的配置含义以此类推。
这个报警升级配置对应的状态机如下图所示。
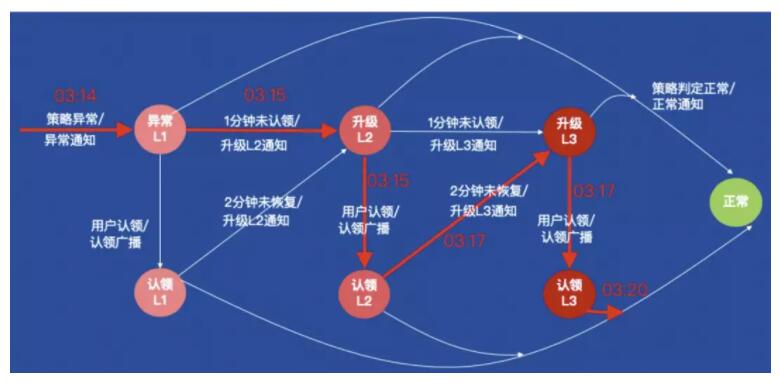
我们通过一个真实的报警认领场景来了解状态机的变迁过程:
03:14 – 线上服务发生故障,监控系统发送短信报警给第一级接收人:运小二。
03:15 – 由于运小二超过1分钟没有认领报警事件,则事件状态升级到第二级,并发送短信和电话给第二级接收人:运小伟。运小伟收到报警后,立即认领故障,监控系统同时会给运小二和运小伟发送认领信息。
03:17 – 由于运小伟不太熟悉业务,过了2分钟,故障还没有恢复,则报警事件升级到第三级,并发送短信和电话给三线值班人:运小博,运小博认领了故障后,和运小伟一起定位故障。
03:20 – 经过两人的一番努力,线上故障恢复了,则报警事件状态变成正常,并发送恢复正常通知。
经过上面的案例分析,我们看到,在报警升级场景下,报警事件的状态变迁过程将变得更加复杂,而且不同事件状态之间变迁的触发条件和执行动作也可能会各不相同。基于状态机的报警事件模型不仅足够抽象,表达能力强,可以囊括繁杂多样的事件管理需求;而且可扩展性强,通过状态机描述文件定义状态机行为,可以快速添加“数据断流”、“报警失效”等新状态,来满足无数据检测和报警失效检测等更多复杂的事件管理需求。
报警合并,让报警风暴成为过去
在上篇《AIOps对监控报警架构的挑战》文章中,我们通过三个场景给大家呈现报警风暴的真面目,其中提到了可以对大量报警消息进行有效的组织,然后再发送,从而将运维工程师从报警风暴中解救出来,这就是所谓的报警合并。
报警合并的基本思路是将相关联的报警消息组成到一起,作为一条信息发送给运维工程师,这样运维工程师可以根据这种相关性来辅助故障定位。
那如何来描述这种相关性呢?基于百度的运维场景,我们挖掘出以下三类相关性:
报警消息具有相同的维度属性,比如具有相同的策略名,或者相同的部署属性(比如产品线、模块、集群、实例、机器等属性)。
报警消息所属的模块具有关联关系,比如A模块调用B模块,如果B出现异常,一般A也会有相关异常,而我们可以通过历史的异常事件来挖掘这类关联性。
当发生机房故障时,位于同一个机房内部所产生的报警消息没必要一一发送了,可以有效组织成一条消息发送给运维工程师。
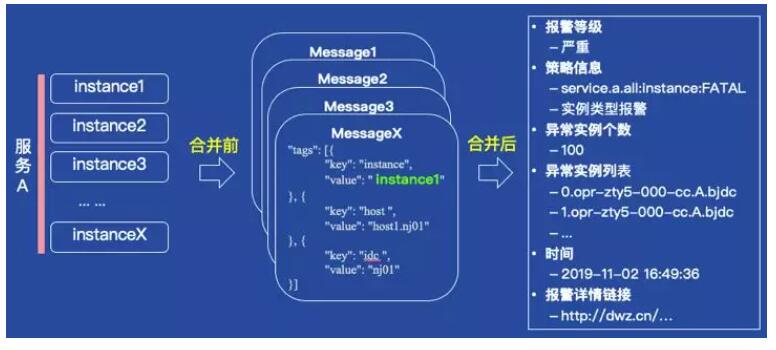
下图展示了服务A下多个实例同时故障,如果对每个实例的故障,都给运维工程师发送一条消息,那么就很容易产生报警风暴。我们通过将报警缓存一段时间(可以设置最大延迟时间,从而保证报警时效性),然后将缓存内所有属于服务A的报警合并到一起后发送,这样运维工程师只会收到一条报警,而且在报警信息中还会告知运维人员,服务A下有大量实例异常,这样运维人员可以根据这个提示有针对性去排查故障。
|









