| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫМрПиЯЕЭГИХТлЁЂЛљДЁзЪдДМрПиЁЂPrometheus
МђНщЁЂЪ§ОнФЃаЭЁЂЦфЫћМрПиЙЄОпЁЂЦфЫћМрПиЙЄОпЕШЯрЙиФкШнЁЃ
БОЮФРДздгкbubukoЃЌгЩЛ№СњЙћШэМўAnnaБрМЁЂЭЦМіЁЃ |
|
вЛЁЂМрПиЯЕЭГИХТл
МрПиЯЕЭГдкетРяЬижИЖдЪ§ОнжааФЕФМрПиЃЌжївЊеыЖдЪ§ОнжааФФкЕФгВМўКЭШэМўНјааМрПиКЭИцОЏЁЃЦѓвЕЕФ IT МмЙЙж№ВНДгДЋЭГЕФЮяРэЗўЮёЦїЃЌЧЈвЦЕНвдащФтЛњЮЊжїЕМЕФ
IaaS дЦЁЃЮоТлЛљДЁМмЙЙШчКЮЕїећЃЌЖМРыВЛПЊМрПиЯЕЭГЕФжЇГжЁЃ
ВЛНіШчДЫЁЃдНРДдНИДдгЕФЪ§ОнжааФЛЗОГЖдМрПиЯЕЭГЬсГіСЫИќдНРДдНИпЕФвЊЧѓЃКашвЊМрПиВЛЭЌЕФЖдЯѓЃЌР§ШчШнЦїЃЌЗжВМЪНДцДЂЃЌSDNЭјТчЃЌЗжВМЪНЯЕЭГЁЃИїжжгІгУГЬађЕШЃЌжжРрЗБЖрЃЌЛЙашвЊВЩМЏКЭДцДЂДѓСПЕФМрПиЪ§ОнЃЌР§ШчУПЬьЪ§TBЪ§ОнЕФВЩМЏЛузмЁЃвдМАЛљгкетаЉМрПиЪ§ОнЕФжЧФмЗжЮіЃЌИцОЏМАдЄОЏЕШЁЃ
дкУПИіЦѓвЕЕФЪ§ОнжааФФкЃЌЛђЖрЛђЩйЖМЛсЪЙгУвЛаЉПЊдДЛђепЩЬвЕЕФМрПиЯЕЭГЁЃДгМрПиЖдЯѓЕФНЧЖШРДПДЃЌПЩвдНЋМрПиЗжЮЊЭјТчМрПиЃЌДцДЂМрПиЃЌЗўЮёЦїМрПиКЭгІгУМрПиЕШЃЌвђЮЊашвЊМрПиЪ§ОнжааФЕФИїИіЗНУцЁЃЫљвдМрПиЯЕЭГашвЊзіЕНУцУцОуЕНЃЌдкЪ§ОнжааФжаГфЕБЁАЬьблЁАНЧЩЋЁЃ
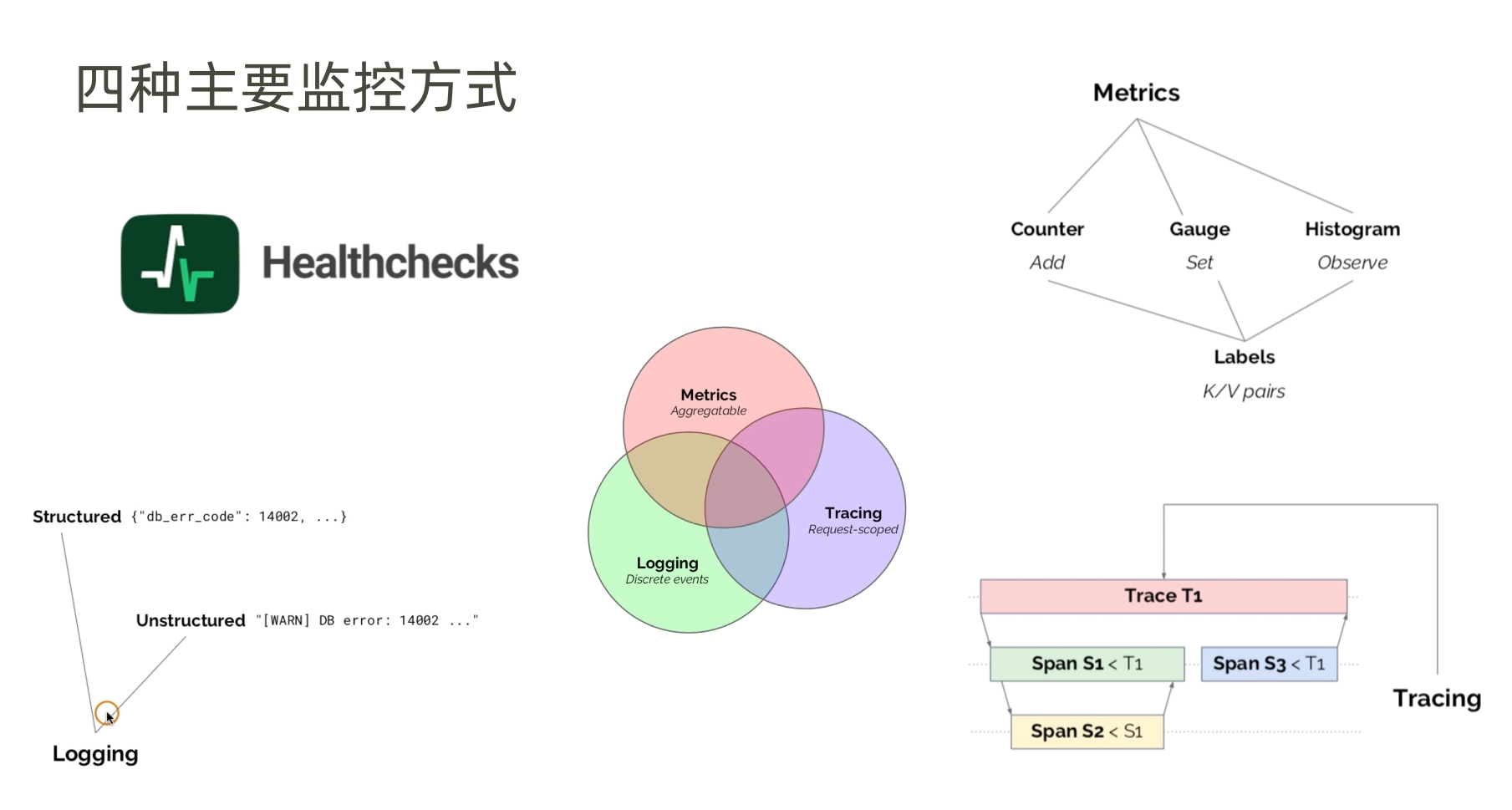
ЖўЁЂЛљДЁзЪдДМрПи
2.1ЁЂЭјТчМрПи
ЭјТчадФмМрПиЃКжївЊЩцМАЭјТчМрВтЃЌЭјТчЪЕЪБСїСПМрПиЃЈЭјТчбгГйЁЂЗУЮЪСПЁЂГЩЙІТЪЃЉКЭРњЪЗЪ§ОнЭГМЦЁЂЛузмКЭРњЪЗЪ§ОнЗжЮіЕШЙІФмЁЃ
ЭјТч***МьВтЃКжївЊеыЖдФкЭјЛђепЭтЭјЕФЭјТч***ЁЃШчDDoS***ЕФЁЃЭЈЙ§ЗжЮівьГЃСїСПРДШЗЖЈЭјТч***ааЮЊЁЃ
ЩшБИМрПиЃКжївЊеыЖдЪ§ОнжааФФкЕФЖржжЭјТчЩшБИНјааМрПиЁЃАќРЈТЗгЩЦїЃЌЗРЛ№ЧНКЭНЛЛЛЛњЕШгВМўЩшБИЃЌПЩвдЭЈЙ§snmpЕШавщЪеМЏЪ§ОнЁЃ
2.2ЁЂДцДЂМрПи
ДцДЂадФмМрПиЗНУцЃКДцДЂЭЈГЃМрПиПщЕФЖСаДЫйТЪЃЌIOPSЁЃЖСаДбгГйЃЌДХХЬгУСПЕШЃЛЮФМўДцДЂЭЈГЃМрПиЮФМўЯЕЭГinodeЁЃЖСаДЫйЖШЁЂФПТМШЈЯоЕШЁЃ
ДцДЂЯЕЭГМрПиЗНУцЃКВЛЭЌЕФДцДЂЯЕЭГгаВЛЭЌЕФжИБъЃЌР§ШчЃЌЖдгкcephДцДЂашвЊМрПиOSD, MONЕФдЫаазДЬЌЃЌИїжжзДЬЌpgЕФЪ§СПвдМАМЏШКIOPSЕШаХЯЂЁЃ
ДцДЂЩшБИМрПиЗНУцЃКЖдгкЙЙНЈдкx86ЗўЮёЦїЩЯЕФДцДЂЩшБИЃЌЩшБИМрПиЭЈЙ§УПИіДцДЂНкЕуЩЯЕФВЩМЏЦїЭГвЛЪеМЏДХХЬЁЂSSDЁЂЭјПЈЕШЩшБИаХЯЂЃЛДцДЂГЇЩЬвдКкКаЗНЪНЬсЙЉЩЬвЕДцДЂЩшБИЃЌЭЈГЃздДјМрПиЙІФмЃЌПЩМрПиЩшБИЕФдЫаазДЬЌЃЌадФмКЭШнСПЕФЁЃ
2.3ЁЂЗўЮёЦїМрПи
CPUЃКЩцМАећИі CPU ЕФЪЙгУСПЁЂгУЛЇЬЌАйЗжБШЁЂФкКЫЬЌАйЗжБШЃЌУПИі CPU ЕФЪЙгУСПЁЂЕШД§ЖгСаГЄЖШЁЂI/O
ЕШД§АйЗжБШЁЂCPU ЯћКФзюЖрЕФНјГЬЁЂЩЯЯТЮФЧаЛЛДЮЪ§ЁЂЛКДцУќжаТЪЕШЁЃ
ФкДцЃКЩцМАФкДцЕФЪЙгУСПЁЂЪЃгрСПЁЂФкДцеМгУзюИпЕФНјГЬЁЂНЛЛЛЗжЧјДѓаЁЁЂШБвГвьГЃЕШЁЃ
ЭјТч I/OЃКЩцМАУПИіЭјПЈЕФЩЯааСїСПЁЂЯТааСїСПЁЂЭјТчбгГйЁЂЖЊАќТЪЕШЁЃ
ДХХЬ I/OЃКЩцМАгВХЬЕФЖСаДЫйТЪЁЂIOPSЁЂДХХЬгУСПЁЂЖСаДбгГйЕШЁЃ
2.4ЁЂжаМфМўМрПи
ЯћЯЂжаМфМўЃК RabbitMQЁЂKafka
Web ЗўЮёжаМфМўЃКTomcatЁЂJetty
ЛКДцжаМфМўЃКRedisЁЂMemcached
Ъ§ОнПтжаМфМўЃКMySQLЁЂPostgreSQL
2.5ЁЂгІгУГЬађМрПиЃЈAPMЃЉ
APMжївЊЪЧеыЖдгІгУГЬађЕФМрПиЃЌАќРЈгІгУГЬађЕФдЫаазДЬЌМрПиЃЌадФмМрПиЃЌШежОМрПиМАЕїгУСДИњзйЕШЁЃЕїгУСДИњзйЪЧжИзЗзйећИіЧыЧѓЙ§ГЬЃЈДггУЛЇЗЂЫЭЧыЧѓЃЌЭЈГЃжИфЏРРЦїЛђепгІгУПЭЛЇЖЫЃЉЕНКѓЖЫAPIЗўЮёвдМАAPIЗўЮёКЭЙиСЊЕФжаМфМўЃЌЛђепЦфЫћзщМўжЎМфЕФЕїгУЃЌЙЙНЈГівЛИіЭъећЕФЕїгУЭиЦЫНсЙЙЃЌВЛНіШчДЫЃЌAPM
ЛЙПЩвдМрПизщМўФкВПЗНЗЈЕФЕїгУВуДЮЃЈController-->service-->DaoЃЉЛёШЁУПИіКЏЪ§ЕФжДааКФЪБЃЌДгЖјЮЊадФмЕїгХЬсЙЉЪ§ОнжЇГХЁЃ
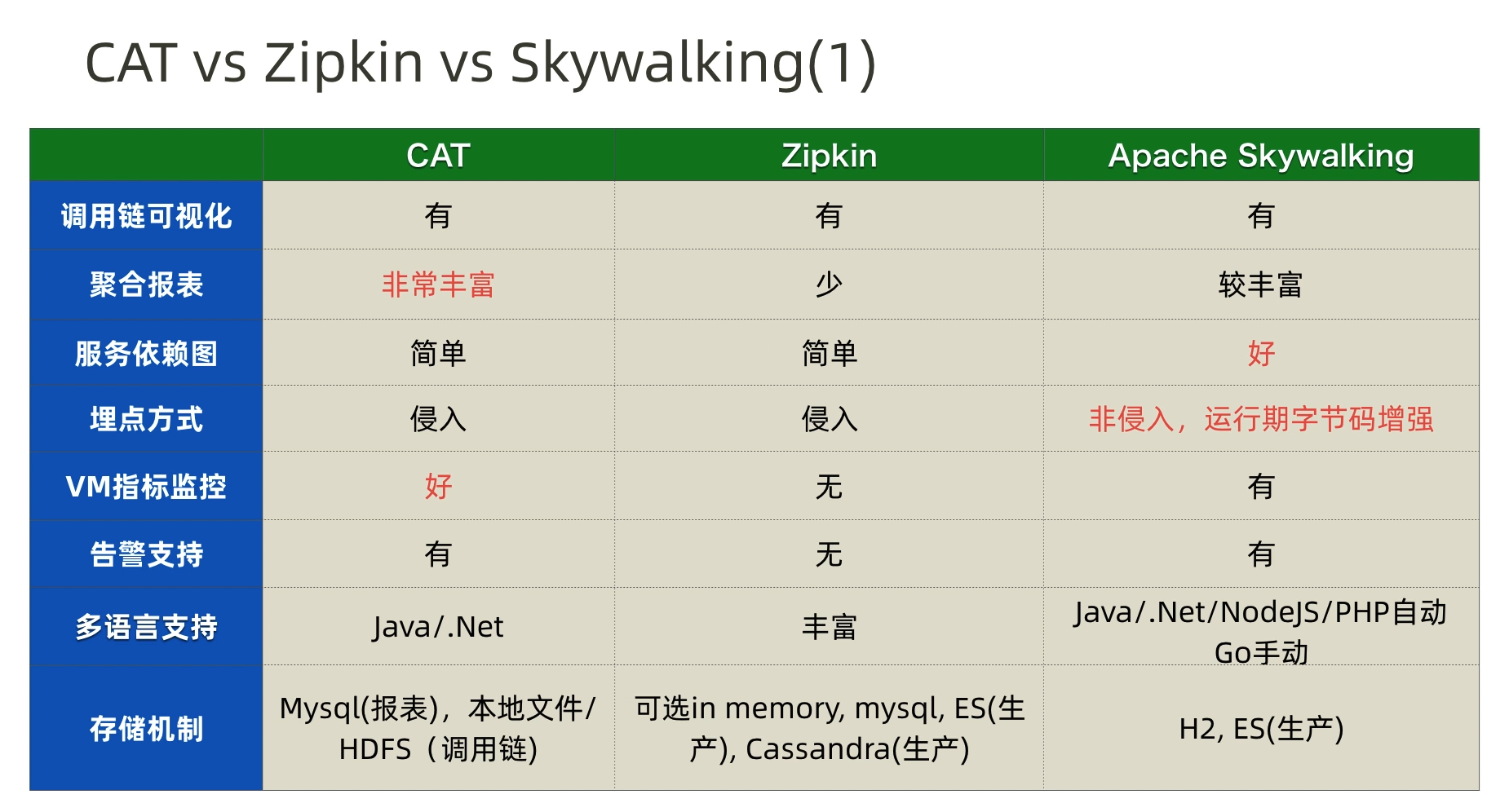
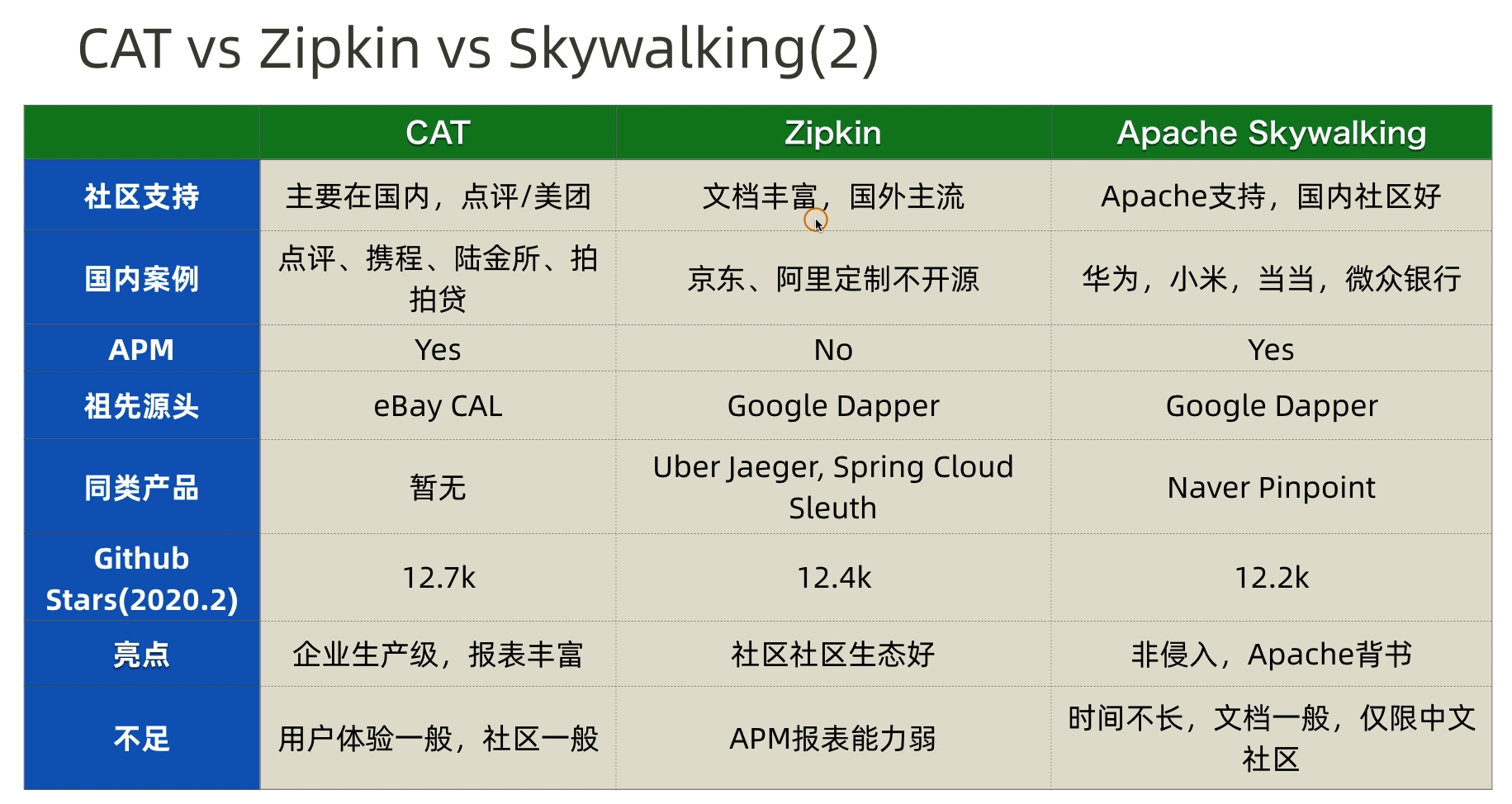
гІгУГЬађМрПиЙЄОпГ§СЫга PinpointЃЌЛЙга Twitter ПЊдДЕФ ZipkinЃЌApache
SkyWalkingЃЌУРЭХПЊдДЕФ CATЕШЁЃ
ЕїгУМќМрПи
МИПюВњЦЗЖдБШ
Pinpoint
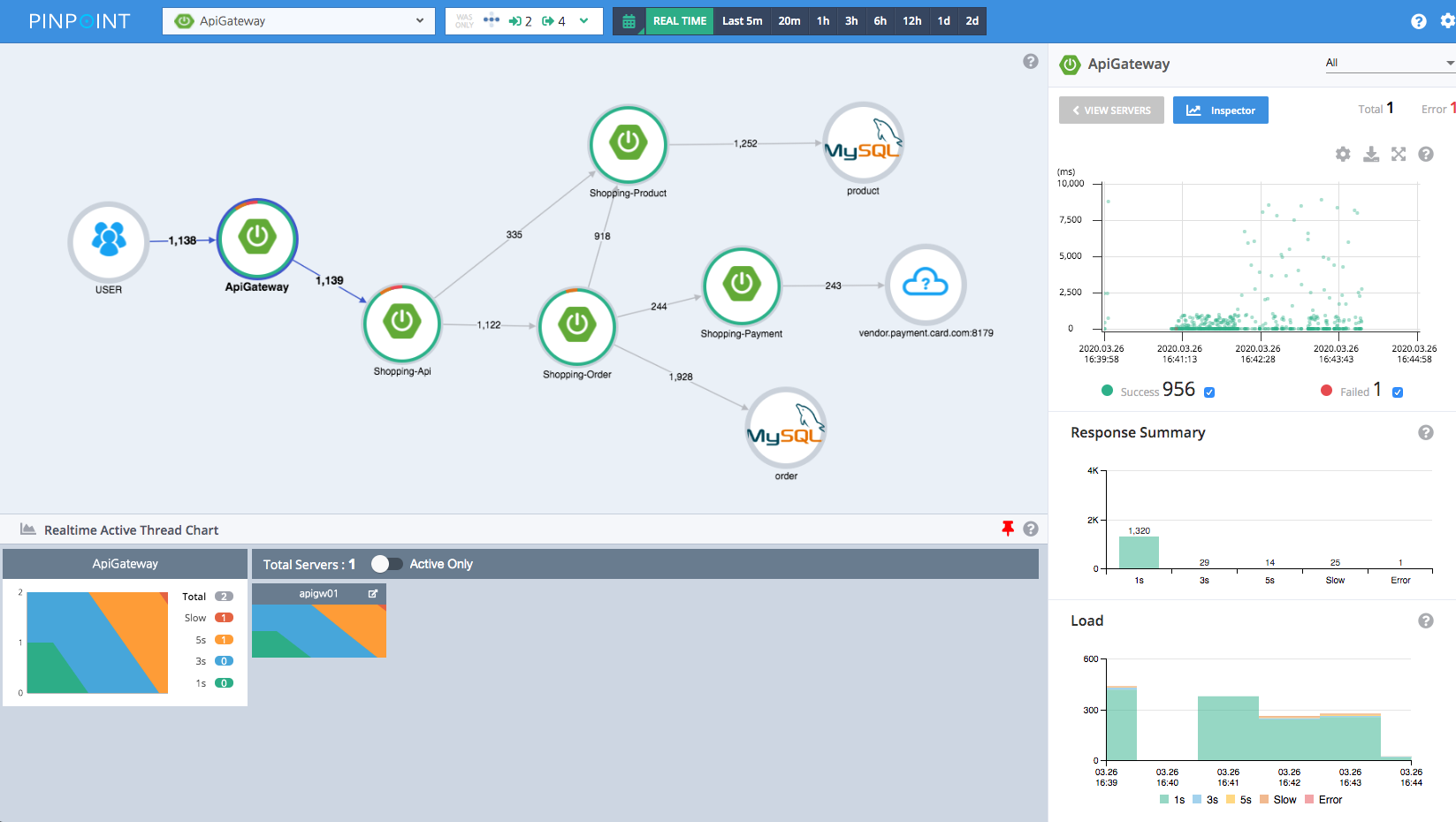
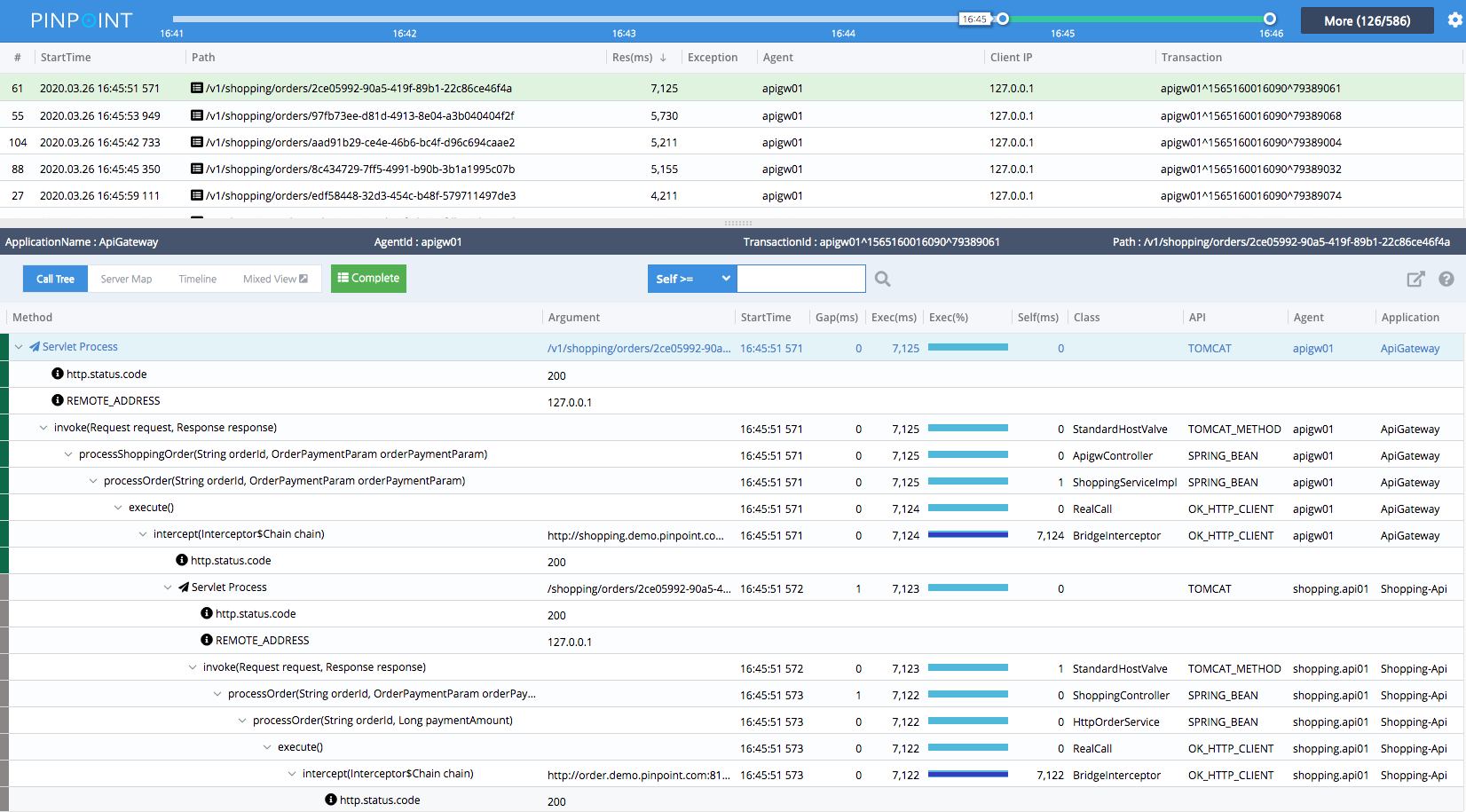
ЭЈЙ§ APM Г§СЫПЩвдНиЛёЗНЗЈЕїгУЃЌЛЙПЩвдНиЛёTCPЁЂHTTPЭјТчЧыЧѓЃЌДгЖјЛёЕУжДааКФЪБзюГЄЕФЗНЗЈКЭ
SQL гяОфЁЂбгГйзюДѓЕФ API ЕФаХЯЂЁЃ
Ш§ЁЂPrometheus МђНщ
3.1ЁЂЪВУДЪЧ Prometheus
Prometheus ЪЧвЛЬзПЊдДЕФЯЕЭГМрПиБЈОЏПђМмЁЃЫќЦєЗЂгк Google ЕФ borgmon МрПиЯЕЭГЃЌгЩЙЄзїдк
SoundCloud ЕФ google ЧАдБЙЄдк 2012 ФъДДНЈЃЌзїЮЊЩчЧјПЊдДЯюФПНјааПЊЗЂЃЌВЂгк
2015 Фъе§ЪНЗЂВМЁЃ2016 ФъЃЌPrometheus е§ЪНМгШы Cloud Native Computing
FoundationЃЌГЩЮЊЪмЛЖгЖШНіДЮгк Kubernetes ЕФЯюФПЁЃ
3.2ЁЂгХЕу
ЧПДѓЕФЖрЮЌЖШЪ§ОнФЃаЭЃК
ЪБМфађСаЪ§ОнЭЈЙ§ metric УћКЭМќжЕЖдРДЧјЗжЁЃ
ЫљгаЕФ metrics ЖМПЩвдЩшжУШЮвтЕФЖрЮЌБъЧЉЁЃ
Ъ§ОнФЃаЭИќЫцвтЃЌВЛашвЊПЬвтЩшжУЮЊвдЕуЗжИєЕФзжЗћДЎЁЃ
ПЩвдЖдЪ§ОнФЃаЭНјааОлКЯЃЌЧаИюКЭЧаЦЌВйзїЁЃ
жЇГжЫЋОЋЖШИЁЕуРраЭЃЌБъЧЉПЩвдЩшЮЊШЋ unicodeЁЃ
СщЛюЖјЧПДѓЕФВщбЏгяОфЃЈPromQLЃЉЃКдкЭЌвЛИіВщбЏгяОфЃЌПЩвдЖдЖрИі metrics НјааГЫЗЈЁЂМгЗЈЁЂСЌНгЁЂШЁЗжЪ§ЮЛЕШВйзїЁЃ
взгкЙмРэЃК Prometheus server ЪЧвЛИіЕЅЖРЕФЖўНјжЦЮФМўЃЌПЩжБНгдкБОЕиЙЄзїЃЌВЛвРРЕгкЗжВМЪНДцДЂЁЃ
ИпаЇЃКЦНОљУПИіВЩбљЕуНіеМ 3.5 bytesЃЌЧввЛИі Prometheus server ПЩвдДІРэЪ§АйЭђЕФ
metricsЁЃ
ЪЙгУ pull ФЃЪНВЩМЏЪБМфађСаЪ§ОнЃЌетбљВЛНігаРћгкБОЛњВтЪдЖјЧвПЩвдБмУтгаЮЪЬтЕФЗўЮёЦїЭЦЫЭЛЕЕФ metricsЁЃ
ПЩвдВЩгУ push gateway ЕФЗНЪНАбЪБМфађСаЪ§ОнЭЦЫЭжС Prometheus server
ЖЫЁЃ
ПЩвдЭЈЙ§ЗўЮёЗЂЯжЛђепОВЬЌХфжУШЅЛёШЁМрПиЕФ targetsЁЃ
гаЖржжПЩЪгЛЏЭМаЮНчУцЁЃ
взгкЩьЫѕЁЃ
3.3ЁЂзщМў
Prometheus ЩњЬЌШІжаАќКЌСЫЖрИізщМўЃЌЦфжааэЖрзщМўЪЧПЩбЁЕФЃК
Prometheus Server: гУгкЪеМЏКЭДцДЂЪБМфађСаЪ§ОнЁЃ
Client Library: ПЭЛЇЖЫПтЃЌЮЊашвЊМрПиЕФЗўЮёЩњГЩЯргІЕФ metrics ВЂБЉТЖИј Prometheus
serverЁЃЕБ Prometheus server РД pull ЪБЃЌжБНгЗЕЛиЪЕЪБзДЬЌЕФ metricsЁЃ
Push Gateway: жївЊгУгкЖЬЦкЕФ jobsЁЃгЩгкетРр jobs ДцдкЪБМфНЯЖЬЃЌПЩФмдк Prometheus
РД pull жЎЧАОЭЯћЪЇСЫЁЃЮЊДЫЃЌетДЮ jobs ПЩвджБНгЯђ Prometheus server ЖЫЭЦЫЭЫќУЧЕФ
metricsЁЃетжжЗНЪНжївЊгУгкЗўЮёВуУцЕФ metricsЃЌЖдгкЛњЦїВуУцЕФ metricesЃЌашвЊЪЙгУ
node exporterЁЃ
Exporters: гУгкБЉТЖвбгаЕФЕкШ§ЗНЗўЮёЕФ metrics Иј PrometheusЁЃ
Alertmanager: Дг Prometheus server ЖЫНгЪеЕН alerts КѓЃЌЛсНјааШЅГ§жиИДЪ§ОнЃЌЗжзщЃЌВЂТЗгЩЕНЖдЪеЕФНгЪмЗНЪНЃЌЗЂГіБЈОЏЁЃГЃМћЕФНгЪеЗНЪНгаЃКЕчзггЪМўЃЌpagerdutyЃЌOpsGenie,
webhook ЕШЁЃ
вЛаЉЦфЫћЕФЙЄОпЁЃ
3.4ЁЂМмЙЙ
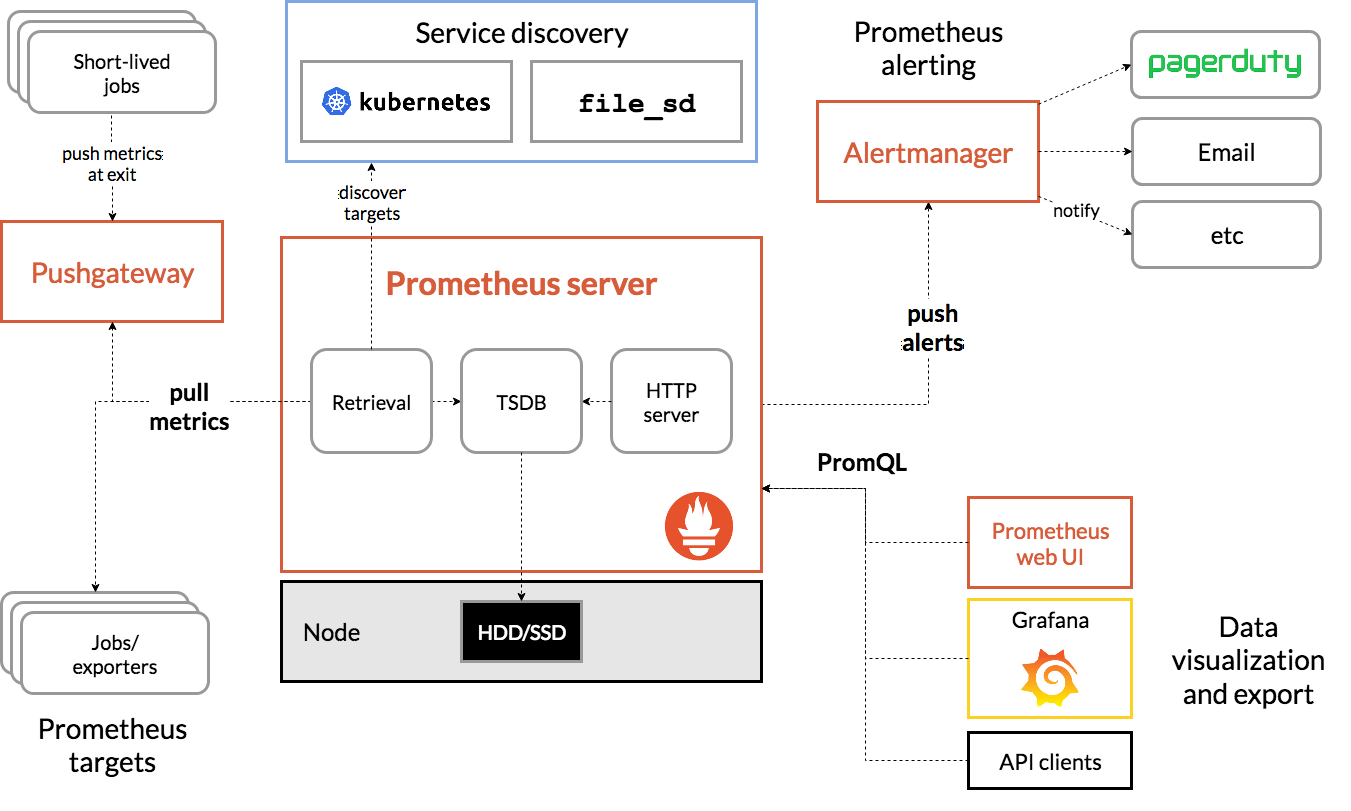
ДгетИіМмЙЙЭМЃЌвВПЩвдПДГі Prometheus ЕФжївЊФЃПщАќКЌЃЌ Server, Exporters,
Pushgateway, PromQL, Alertmanager, WebUI ЕШЁЃ
ЫќДѓжТЪЙгУТпМЪЧетбљЃК
Prometheus server ЖЈЦкДгОВЬЌХфжУЕФ targets ЛђепЗўЮёЗЂЯжЕФ targets
РШЁЪ§ОнЁЃ
ЕБаТРШЁЕФЪ§ОнДѓгкХфжУФкДцЛКДцЧјЕФЪБКђЃЌPrometheus ЛсНЋЪ§ОнГжОУЛЏЕНДХХЬЃЈШчЙћЪЙгУ remote
storage НЋГжОУЛЏЕНдЦЖЫЃЉЁЃ
Prometheus ПЩвдХфжУ rulesЃЌШЛКѓЖЈЪБВщбЏЪ§ОнЃЌЕБЬѕМўДЅЗЂЕФЪБКђЃЌЛсНЋ alert ЭЦЫЭЕНХфжУЕФ
AlertmanagerЁЃ
Alertmanager ЪеЕНОЏИцЕФЪБКђЃЌПЩвдИљОнХфжУЃЌОлКЯЃЌШЅжиЃЌНЕдыЃЌзюКѓЗЂЫЭОЏИцЁЃ
ПЩвдЪЙгУ APIЃЌ Prometheus Console Лђеп Grafana ВщбЏКЭОлКЯЪ§ОнЁЃ
3.5ЁЂЪЪгУгкЪВУДГЁОА
Prometheus ЪЪгУгкМЧТМЮФБОИёЪНЕФЪБМфађСаЃЌЫќМШЪЪгУгквдЛњЦїЮЊжааФЕФМрПиЃЌвВЪЪгУгкИпЖШЖЏЬЌЕФУцЯђЗўЮёМмЙЙЕФМрПиЁЃдкЮЂЗўЮёЕФЪРНчжаЃЌЫќЖдЖрЮЌЪ§ОнЪеМЏКЭВщбЏЕФжЇГжгаЬиЪтгХЪЦЁЃPrometheus
ЪЧзЈЮЊЬсИпЯЕЭГПЩППадЖјЩшМЦЕФЃЌЫќПЩвддкЖЯЕчЦкМфПьЫйеяЖЯЮЪЬтЃЌУПИі Prometheus Server
ЖМЪЧЯрЛЅЖРСЂЕФЃЌВЛвРРЕгкЭјТчДцДЂЛђЦфЫћдЖГЬЗўЮёЁЃЕБЛљДЁМмЙЙГіЯжЙЪеЯЪБЃЌФуПЩвдЭЈЙ§ Prometheus
ПьЫйЖЈЮЛЙЪеЯЕуЃЌЖјЧвВЛЛсЯћКФДѓСПЕФЛљДЁМмЙЙзЪдДЁЃ
3.6ЁЂВЛЪЪКЯЪВУДГЁОА
Prometheus ЗЧГЃжиЪгПЩППадЃЌМДЪЙдкГіЯжЙЪеЯЕФЧщПіЯТЃЌФувВПЩвдЫцЪБВщПДгаЙиЯЕЭГЕФПЩгУЭГМЦаХЯЂЁЃШчЙћФуашвЊАйЗжжЎАйЕФзМШЗЖШЃЌР§ШчАДЧыЧѓЪ§СПМЦЗбЃЌФЧУД
Prometheus ВЛЬЋЪЪКЯФуЃЌвђЮЊЫќЪеМЏЕФЪ§ОнПЩФмВЛЙЛЯъЯИЭъећЁЃетжжЧщПіЯТЃЌФузюКУЪЙгУЦфЫћЯЕЭГРДЪеМЏКЭЗжЮіЪ§ОнвдНјааМЦЗбЃЌВЂЪЙгУ
Prometheus РДМрПиЯЕЭГЕФЦфгрВПЗжЁЃ
ЫФЁЂЪ§ОнФЃаЭ
4.1ЁЂЪ§ОнФЃаЭ
Prometheus ЫљгаВЩМЏЕФМрПиЪ§ОнОљвджИБъЃЈmetricЃЉЕФаЮЪНБЃДцдкФкжУЕФЪБМфађСаЪ§ОнПтЕБжаЃЈTSDBЃЉЃКЪєгкЭЌвЛжИБъУћГЦЃЌЭЌвЛБъЧЉМЏКЯЕФЁЂгаЪБМфДСБъМЧЕФЪ§ОнСїЁЃГ§СЫДцДЂЕФЪБМфађСаЃЌPrometheus
ЛЙПЩвдИљОнВщбЏЧыЧѓВњЩњСйЪБЕФЁЂбмЩњЕФЪБМфађСазїЮЊЗЕЛиНсЙћЁЃ
жИБъУћГЦКЭБъЧЉ
УПвЛЬѕЪБМфађСагЩжИБъУћГЦЃЈMetrics NameЃЉвдМАвЛзщБъЧЉЃЈМќжЕЖдЃЉЮЈвЛБъЪЖЁЃЦфжажИБъЕФУћГЦЃЈmetric
nameЃЉПЩвдЗДгГБЛМрПибљБОЕФКЌвхЃЈР§ШчЃЌhttp_requests_total ЁЊ БэЪОЕБЧАЯЕЭГНгЪеЕНЕФ
HTTP ЧыЧѓзмСПЃЉЃЌжИБъУћГЦжЛФмгЩ ASCII зжЗћЁЂЪ§зжЁЂЯТЛЎЯпвдМАУАКХзщГЩЃЌЭЌЪББиаыЦЅХфе§дђБэДяЪН
[a-zA-Z_:][a-zA-Z0-9_:]*ЁЃ
[info] зЂвт
УАКХгУРДБэЪОгУЛЇздЖЈвхЕФМЧТМЙцдђЃЌВЛФмдк exporter жаЛђМрПиЖдЯѓжБНгБЉТЖЕФжИБъжаЪЙгУУАКХРДЖЈвхжИБъУћГЦЁЃ
ЭЈЙ§ЪЙгУБъЧЉЃЌPrometheus ПЊЦєСЫЧПДѓЕФЖрЮЌЪ§ОнФЃаЭЃКЖдгкЯрЭЌЕФжИБъУћГЦЃЌЭЈЙ§ВЛЭЌБъЧЉСаБэЕФМЏКЯЃЌЛсаЮГЩЬиЖЈЕФЖШСПЮЌЖШЪЕР§ЃЈР§ШчЃКЫљгаАќКЌЖШСПУћГЦЮЊ
/api/tracks ЕФ http ЧыЧѓЃЌДђЩЯ method=POST ЕФБъЧЉЃЌОЭЛсаЮГЩОпЬхЕФ http
ЧыЧѓЃЉЁЃИУВщбЏгябддкетаЉжИБъКЭБъЧЉСаБэЕФЛљДЁЩЯНјааЙ§ТЫКЭОлКЯЁЃИФБфШЮКЮЖШСПжИБъЩЯЕФШЮКЮБъЧЉжЕЃЈАќРЈЬэМгЛђЩОГ§жИБъЃЉЃЌЖМЛсДДНЈаТЕФЪБМфађСаЁЃ
БъЧЉЕФУћГЦжЛФмгЩ ASCII зжЗћЁЂЪ§зжвдМАЯТЛЎЯпзщГЩВЂТњзуе§дђБэДяЪН [a-zA-Z_][a-zA-Z0-9_]*ЁЃЦфжавд
__ зїЮЊЧАзКЕФБъЧЉЃЌЪЧЯЕЭГБЃСєЕФЙиМќзжЃЌжЛФмдкЯЕЭГФкВПЪЙгУЁЃБъЧЉЕФжЕдђПЩвдАќКЌШЮКЮ Unicode
БрТыЕФзжЗћЁЃ
ЪБађбљБО
дкЪБМфађСажаЕФУПвЛИіЕуГЦЮЊвЛИібљБОЃЈsampleЃЉЃЌбљБОгЩвдЯТШ§ВПЗжзщГЩЃК
жИБъЃЈmetricЃЉЃКжИБъУћГЦКЭУшЪіЕБЧАбљБОЬиеїЕФ labelsetsЃЛ
ЪБМфДСЃЈtimestampЃЉЃКвЛИіОЋШЗЕНКСУыЕФЪБМфДСЃЛ
бљБОжЕЃЈvalueЃЉЃК вЛИі folat64 ЕФИЁЕуаЭЪ§ОнБэЪОЕБЧАбљБОЕФжЕЁЃ
ИёЪН
ЭЈЙ§ШчЯТБэДяЗНЪНБэЪОжИЖЈжИБъУћГЦКЭжИЖЈБъЧЉМЏКЯЕФЪБМфађСаЃК
| <metric name>{<label
name>= <label value>, ...} |
Р§ШчЃЌжИБъУћГЦЮЊ api_http_requests_totalЃЌБъЧЉЮЊ
method="POST" КЭ handler="/messages"
ЕФЪБМфађСаПЩвдБэЪОЮЊЃК
| api_http_requests_total { method="POST",
handler="/messages"} |
етгы OpenTSDB жаЪЙгУЕФБъМЧЗЈЯрЭЌЁЃ
4.2ЁЂжИБъРраЭ
Prometheus ЕФПЭЛЇЖЫПтжаЬсЙЉСЫЫФжжКЫаФЕФжИБъРраЭЁЃЕЋетаЉРраЭжЛЪЧдкПЭЛЇЖЫПтЃЈПЭЛЇЖЫПЩвдИљОнВЛЭЌЕФЪ§ОнРраЭЕїгУВЛЭЌЕФ
API НгПкЃЉКЭдкЯпавщжаЃЌЪЕМЪдк Prometheus server жаВЂВЛЖджИБъРраЭНјааЧјЗжЃЌЖјЪЧМђЕЅЕиАбетаЉжИБъЭГвЛЪгЮЊЮоРраЭЕФЪБМфађСаЁЃВЛЙ§ЃЌНЋРДЮвУЧЛсХЌСІИФБфетвЛЯжзДЕФЁЃ
Counter
вЛжжРлМгЕФ metricЃЌЕфаЭЕФгІгУШчЃКЧыЧѓЕФИіЪ§ЃЌНсЪјЕФШЮЮёЪ§ЃЌ ГіЯжЕФДэЮѓЪ§ЕШЕШЁЃ
Р§Шч Prometheus server жа http_requests_total, БэЪО Prometheus
ДІРэЕФ http ЧыЧѓзмЪ§ЃЌЮвУЧПЩвдЪЙгУ delta, КмШнвзЕУЕНШЮвтЧјМфЪ§ОнЕФдіСПЃЌетИіЛсдк PromQL
вЛНкжаЯИНВЁЃ
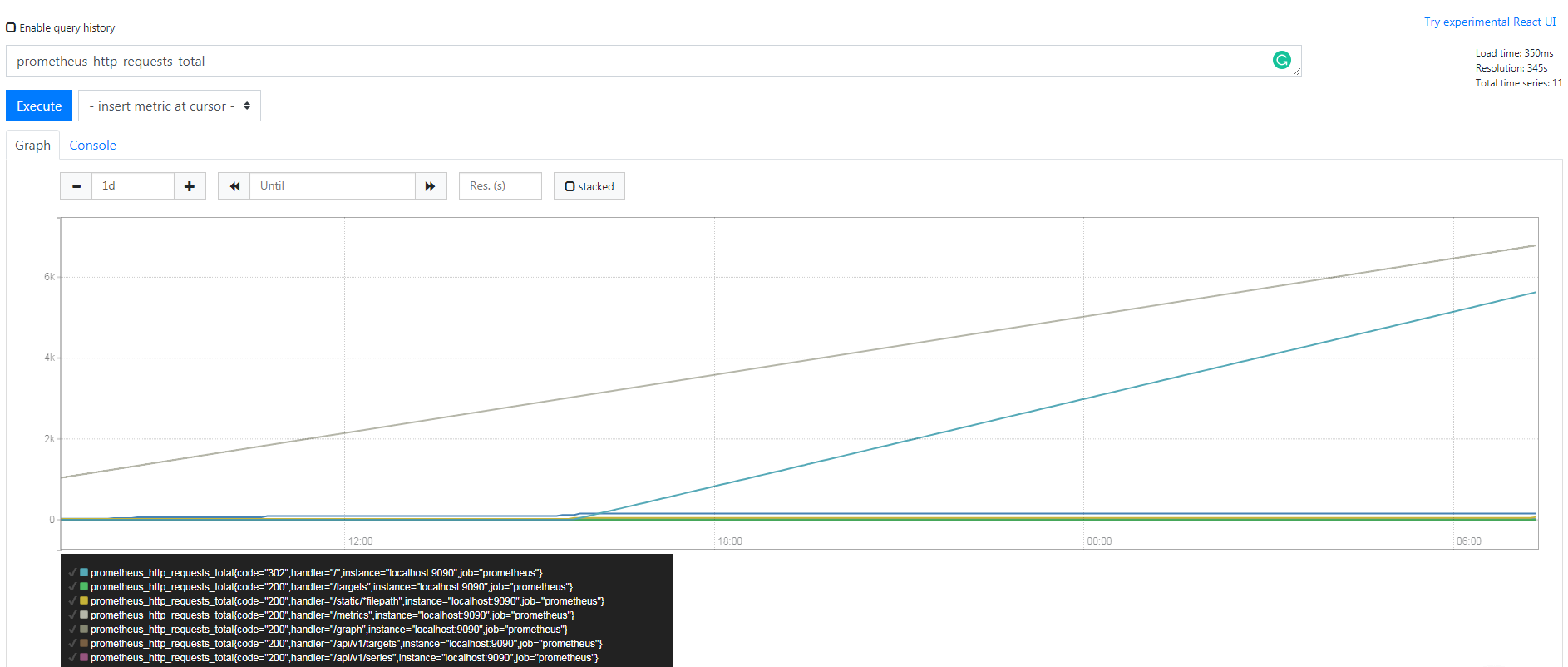
Gauge
вЛжжГЃЙцЕФ metricЃЌЕфаЭЕФгІгУШчЃКЮТЖШЃЌдЫааЕФ goroutines ЕФИіЪ§ЁЃ
ПЩвдШЮвтМгМѕЁЃ
Р§Шч Prometheus server жа go_goroutines, БэЪО Prometheus
ЕБЧА goroutines ЕФЪ§СПЁЃ
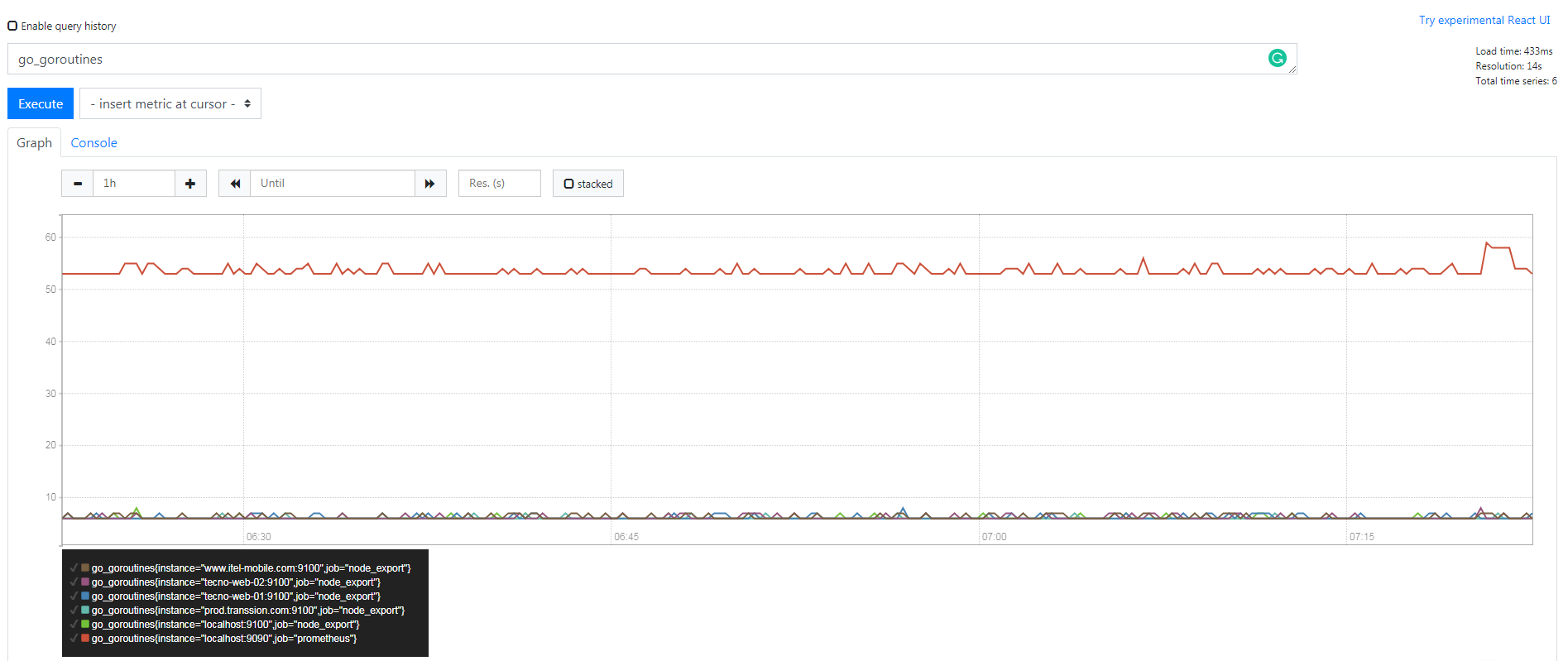
Histogram
ПЩвдРэНтЮЊжљзДЭМЃЌЕфаЭЕФгІгУШчЃКЧыЧѓГжајЪБМфЃЌЯьгІДѓаЁЁЃ
ПЩвдЖдЙлВьНсЙћВЩбљЃЌЗжзщМАЭГМЦЁЃ
Р§ШчЃЌВщбЏ prometheus_http_request _duration_seconds_sum
{handler="/api/v1/query", instance="localhost:9090",
job="prometheus"}ЪБЃЌЗЕЛиНсЙћШчЯТЃК
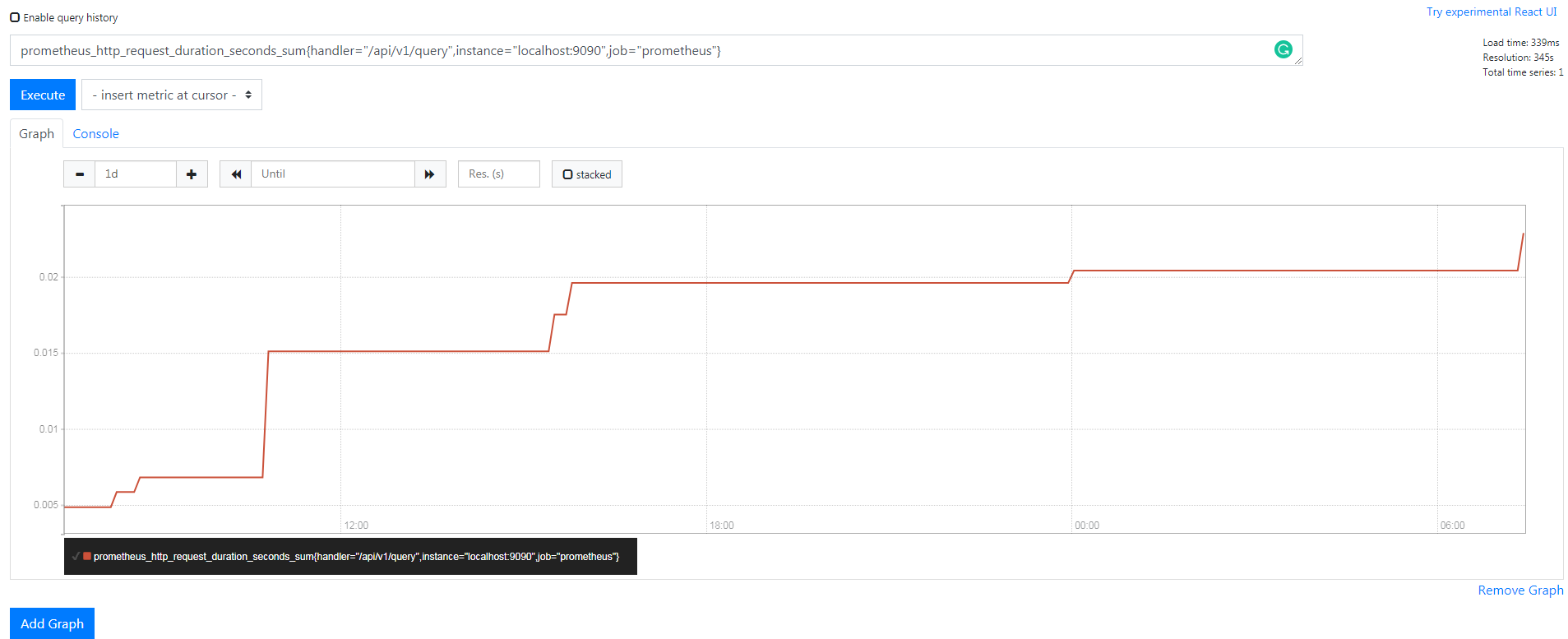
Summary
РрЫЦгк Histogram, ЕфаЭЕФгІгУШчЃКЧыЧѓГжајЪБМфЃЌЯьгІДѓаЁЁЃ
ЬсЙЉЙлВтжЕЕФ count КЭ sum ЙІФмЁЃ
ЬсЙЉАйЗжЮЛЕФЙІФмЃЌМДПЩвдАДАйЗжБШЛЎЗжИњзйНсЙћЁЃ
4.3ЁЂinstance КЭ jobs
Prometheus жаЃЌНЋШЮвтвЛИіЖРСЂЕФЪ§ОндДЃЈtargetЃЉГЦжЎЮЊЪЕР§ЃЈinstanceЃЉЁЃАќКЌЯрЭЌРраЭЕФЪЕР§ЕФМЏКЯГЦжЎЮЊзївЕЃЈjobЃЉЁЃ
ШчЯТЪЧвЛИіКЌгаЫФИіжиИДЪЕР§ЕФзївЕЃК
- job: api-server
- instance 1: 1.2.3.4:5670
- instance 2: 1.2.3.4:5671
- instance 3: 5.6.7.8:5670
- instance 4: 5.6.7.8:5671 |
здЩњГЩБъЧЉКЭЪБађ
Prometheus дкВЩМЏЪ§ОнЕФЭЌЪБЃЌЛсздЖЏдкЪБађЕФЛљДЁЩЯЬэМгБъЧЉЃЌзїЮЊЪ§ОндДЃЈtargetЃЉЕФБъЪЖЃЌвдБуЧјЗжЃК
job: The configured job name that the target belongs
to.
instance: The <host>:<port>
part of the targetЁЎs URL that was scraped.
ШчЙћЦфжаШЮвЛБъЧЉвбОдкДЫЧАВЩМЏЕФЪ§ОнжаДцдкЃЌФЧУДНЋЛсИљОн honor_labels ЩшжУбЁЯюРДОіЖЈаТБъЧЉЁЃЯъМћЙйЭјНтЪЭЃК
scrape configuration documentation
ЖдУПвЛИіЪЕР§ЖјбдЃЌPrometheus АДеевдЯТЪБађРДДцДЂЫљВЩМЏЕФЪ§ОнбљБОЃК
up{job="<job-name>", instance="<instance-id>"}:
1 БэЪОИУЪЕР§е§ГЃЙЄзї
up{job="<job-name>", instance="<instance-id>"}:
0 БэЪОИУЪЕР§ЙЪеЯ
scrape_duration_seconds{job="<job-name>",
instance="<instance-id>"}
БэЪОРШЁЪ§ОнЕФЪБМфМфИє
scrape_samples_post_metric_relabeling{job="<job-name>",
instance="<instance-id>"}
БэЪОВЩгУжиЖЈвхБъЧЉЃЈrelabelingЃЉВйзїКѓШдШЛЪЃгрЕФбљБОЪ§
scrape_samples_scraped{job="<job-name>",
instance="<instance-id>"}
БэЪОДгИУЪ§ОндДЛёШЁЕФбљБОЪ§
Цфжа up ЪБађПЩвдгааЇгІгУгкМрПиИУЪЕР§ЪЧЗёе§ГЃЙЄзїЁЃ
ЮхЁЂЦфЫћМрПиЙЄОп
дкЧАбджаЃЌМђЕЅНщЩмСЫЮвУЧбЁдё Prometheus ЕФРэгЩЃЌвдМАЪЙгУКѓИјЮвУЧДјРДЕФКУДІЁЃ
дкетРяжївЊКЭЦфЫћМрПиЗНАИЖдБШЃЌЗНБуДѓМвИќКУЕФСЫНт PrometheusЁЃ
Prometheus vs Zabbix
Zabbix ЪЙгУЕФЪЧ C КЭ PHP, Prometheus ЪЙгУ Golang, ећЬхЖјбд Prometheus
дЫааЫйЖШИќПьвЛЕуЁЃ
Zabbix ЪєгкДЋЭГжїЛњМрПиЃЌжївЊгУгкЮяРэжїЛњЃЌНЛЛЛЛњЃЌЭјТчЕШМрПиЃЌPrometheus ВЛНіЪЪгУжїЛњМрПиЃЌЛЙЪЪгУгк
Cloud, SaaS, OpenstackЃЌContainer МрПиЁЃ
Zabbix дкДЋЭГжїЛњМрПиЗНУцЃЌгаИќЗсИЛЕФВхМўЁЃ
Zabbix ПЩвддк WebGui жаХфжУКмЖрЪТЧщЃЌЕЋЪЧ Prometheus ашвЊЪжЖЏаоИФЮФМўХфжУЁЃ
Prometheus vs Graphite
Graphite ЙІФмНЯЩйЃЌЫќзЈзЂгкСНМўЪТЃЌДцДЂЪБађЪ§ОнЃЌ ПЩЪгЛЏЪ§ОнЃЌЦфЫћЙІФмашвЊАВзАЯрЙиВхМўЃЌЖј
Prometheus ЪєгквЛеОЪНЃЌЬсЙЉИцОЏКЭЧїЪЦЗжЮіЕФГЃМћЙІФмЃЌЫќЬсЙЉИќЧПЕФЪ§ОнДцДЂКЭВщбЏФмСІЁЃ
дкЫЎЦНРЉеЙЗНАИвдМАЪ§ОнДцДЂжмЦкЩЯЃЌGraphite зіЕФИќКУЁЃ
Prometheus vs InfluxDB
InfluxDB ЪЧвЛИіПЊдДЕФЪБађЪ§ОнПтЃЌжївЊгУгкДцДЂЪ§ОнЃЌШчЙћЯыДюНЈМрПиИцОЏЯЕЭГЃЌ ашвЊвРРЕЦфЫћЯЕЭГЁЃ
InfluxDB дкДцДЂЫЎЦНРЉеЙвдМАИпПЩгУЗНУцзіЕФИќКУ, БЯОЙКЫаФЪЧЪ§ОнПтЁЃ
Prometheus vs OpenTSDB
OpenTSDB ЪЧвЛИіЗжВМЪНЪБађЪ§ОнПтЃЌЫќвРРЕ Hadoop КЭ HBaseЃЌФмДцДЂИќГЄОУЪ§ОнЃЌ
ШчЙћФуЯЕЭГвбОдЫааСЫ Hadoop КЭ HBase, ЫќЪЧИіВЛДэЕФбЁдёЁЃ
ШчЙћЯыДюНЈМрПиИцОЏЯЕЭГЃЌOpenTSDB ашвЊвРРЕЦфЫћЯЕЭГЁЃ
Prometheus vs Nagios
Nagios Ъ§ОнВЛжЇГжздЖЈвх Labels, ВЛжЇГжВщбЏЃЌИцОЏвВВЛжЇГжШЅдыЃЌЗжзщ, УЛгаЪ§ОнДцДЂЃЌШчЙћЯыВщбЏРњЪЗзДЬЌЃЌашвЊАВзАВхМўЁЃ
Nagios ЪЧЩЯЪРМЭ 90 ФъДњЕФМрПиЯЕЭГЃЌБШНЯЪЪКЯаЁМЏШКЛђОВЬЌЯЕЭГЕФМрПиЃЌЯдШЛ Nagios ЬЋЙХРЯСЫЃЌКмЖрЬиадЖМУЛгаЃЌЯрБШжЎЯТPrometheus
вЊгХауКмЖрЁЃ
Prometheus vs Sensu
Sensu ЙувхЩЯНВЪЧ Nagios ЕФЩ§МЖАцБОЃЌЫќНтОіСЫКмЖр Nagios ЕФЮЪЬтЃЌШчЙћФуЖд Nagios
КмЪьЯЄЃЌЪЙгУ Sensu ЪЧИіВЛДэЕФбЁдёЁЃ
Sensu вРРЕ RabbitMQ КЭ RedisЃЌЪ§ОнДцДЂЩЯРЉеЙадИќКУЁЃ
змНс
Prometheus ЪєгквЛеОЪНМрПиИцОЏЦНЬЈЃЌвРРЕЩйЃЌЙІФмЦыШЋЁЃ
Prometheus жЇГжЖддЦЛђШнЦїЕФМрПиЃЌЦфЫћЯЕЭГжївЊЖджїЛњМрПиЁЃ
Prometheus Ъ§ОнВщбЏгяОфБэЯжСІИќЧПДѓЃЌФкжУИќЧПДѓЕФЭГМЦКЏЪ§ЁЃ
Prometheus дкЪ§ОнДцДЂРЉеЙадвдМАГжОУадЩЯУЛга InfluxDBЃЌOpenTSDBЃЌSensu
КУЁЃ
СљЁЂExport
6.1ЁЂЮФБОИёЪН
дкЬжТл Exporter жЎЧАЃЌгаБивЊЯШНщЩмвЛЯТ Prometheus ЮФБОЪ§ОнИёЪНЃЌвђЮЊвЛИі Exporter
БОжЪЩЯОЭЪЧНЋЪеМЏЕФЪ§ОнЃЌзЊЛЏЮЊЖдгІЕФЮФБОИёЪНЃЌВЂЬсЙЉ http ЧыЧѓЁЃ
Exporter ЪеМЏЕФЪ§ОнзЊЛЏЕФЮФБОФкШнвдаа (\n) ЮЊЕЅЮЛЃЌПеааНЋБЛКіТд, ЮФБОФкШнзюКѓвЛааЮЊПеаа
зЂЪЭ
ЮФБОФкШнЃЌШчЙћвд # ПЊЭЗЭЈГЃБэЪОзЂЪЭЁЃ
вд # HELP ПЊЭЗБэЪО metric АяжњЫЕУїЁЃ
вд # TYPE ПЊЭЗБэЪОЖЈвх metric РраЭЃЌАќКЌ counter, gauge, histogram,
summary, КЭ untyped РраЭЁЃ
ЦфЫћБэЪОвЛАузЂЪЭЃЌЙЉдФЖСЪЙгУЃЌНЋБЛ Prometheus КіТдЁЃ
ВЩбљЪ§Он
ФкШнШчЙћВЛвд # ПЊЭЗЃЌБэЪОВЩбљЪ§ОнЁЃЫќЭЈГЃНєАЄзХРраЭЖЈвхааЃЌТњзувдЯТИёЪНЃК
metric_name [
"{" label_name "=" `"`
label_value `"` { "," label_name
"=" `"` label_value `"` }
[ "," ] "}"
] value [ timestamp ] |
ЯТУцЪЧвЛИіЭъећЕФР§згЃК

ашвЊЬиБ№зЂвтЕФЪЧЃЌМйЩшВЩбљЪ§Он metric Назі x, ШчЙћ x ЪЧ histogram Лђ summary
РраЭБиашТњзувдЯТЬѕМўЃК
ВЩбљЪ§ОнЕФзмКЭгІБэЪОЮЊ x_sumЁЃ
ВЩбљЪ§ОнЕФзмСПгІБэЪОЮЊ x_countЁЃ
summary РраЭЕФВЩбљЪ§ОнЕФ quantile гІБэЪОЮЊ x{quantile="y"}ЁЃ
histogram РраЭЕФВЩбљЗжЧјЭГМЦЪ§ОнНЋБэЪОЮЊ x_bucket{le="y"}ЁЃ
histogram РраЭЕФВЩбљБиаыАќКЌ x_bucket{le="+Inf"},
ЫќЕФжЕЕШгк x_count ЕФжЕЁЃ
summary КЭ historam жа quantile КЭ le БиашАДДгаЁЕНДѓЫГађХХСаЁЃ
6.2ЁЂГЃгУВщбЏ
ЪеМЏЕН node_exporter ЕФЪ§ОнКѓЃЌЮвУЧПЩвдЪЙгУ PromQL НјаавЛаЉвЕЮёВщбЏКЭМрПиЃЌЯТУцЪЧвЛаЉБШНЯГЃМћЕФВщбЏЁЃ
зЂвтЃКвдЯТВщбЏОљвдЕЅИіНкЕузїЮЊР§згЃЌШчЙћДѓМвЯыВщПДЫљгаНкЕуЃЌНЋ instance="xxx"
ШЅЕєМДПЩЁЃ
CPU ЪЙгУТЪ
| 100 - (avg by
(instance) (irate(node_cpu_seconds_total {mode="idle"}[5m]))
* 100) |
CPU Иї mode еМБШТЪ
| avg by (instance,
mode) (irate(node_cpu_seconds_total[5m])) * 100 |
ЛњЦїЦНОљИКди
node_load1{instance="xxx"}
// 1ЗжжгИКди
node_load5{instance="xxx"} // 5ЗжжгИКди
node_load15{instance="xxx"} // 15ЗжжгИКди |
ФкДцЪЙгУТЪ
| 100 - ((node_memory_MemFree_bytes
+node_memory_Cached_bytes +node_memory_Buffers_bytes) /node_memory_MemTotal_bytes)
* 100 |
ДХХЬЪЙгУТЪ
| 100 - node_filesystem_free
{instance="xxx",fstype!~ "rootfs
| selinuxfs | autofs | rpc_pipefs | tmpfs | udev
| none | devpts | sysfs | debugfs | fuse.*"}
/ node_filesystem_size {instance="xxx", fstype!~"rootfs | selinuxfs | autofs | rpc_pipefs | tmpfs | udev | none | devpts | sysfs | debugfs |fuse.*"}
* 100 |
ЛђепФувВПЩвджБНгЪЙгУ {fstype="xxx"} РДжИЖЈЯыВщПДЕФДХХЬаХЯЂ
ЭјТч IO
// ЩЯааДјПэ
sum by (instance) (irate(node_network_receive_bytes {instance="xxx", device!~"bond.*?|lo"}[5m])/128)
// ЯТааДјПэ
sum by (instance) (irate(node_network_transmit_bytes {instance="xxx", device!~"bond.*?|lo"}[5m])/128) |
ЭјПЈГі/ШыАќ
// ШыАќСП
sum by (instance) (rate(node_network_receive_bytes
{instance="xxx", device!="lo"}[5m]))
// ГіАќСП
sum by (instance) (rate(node_network_transmit_bytes
{instance="xxx", device!="lo"}[5m]))
|
|









