| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫRPCМрПи
- Ъ§ОнВЩМЏЁЂRPCМрПи - Ъ§ОнеЙЯжЁЂ ПЩЪгЛЏгаЯђЭМЩшМЦЁЂOverwatchЯЕЭГНиЭМЕШЯрЙиФкШнЁЃ
БОЮФРДздгкcsdnЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
1. БГОА
аТДяДяЕФЗўЮёЖЫЪЧвЛИіХгДѓЕФЁЂЗжВМЪНЕФЁЂЮЂЗўЮёЛЏЕФЯЕЭГЃЌУПЪБУППЬЯЕЭГжЎМфЖМгазХКЃСПЕФRPCЧыЧѓЃЈжИЙувхЩЯЕФRPCЃЌАќРЈRESTНгПкЕїгУЁЂJDBCЕШЃЌЯТЭЌЃЉЁЃдкДюНЈЯЕЭГЕФГѕЦкЃЌЮвУЧНіНіЖдИїИіЯЕЭГЕФЗУЮЪШежОНјааСЫМрПиЁЃетбљЕФМрПиПЩвдШУЮвУЧЗЂЯжФГИіЯЕЭГЪЧЗёГіЯжСЫЯЕЭГДэЮѓЃЈБэЯжШчЯьгІСЫHTTP
500зДЬЌТыЃЉЃЌЕЋЪЧдкДѓЖрЪ§ЧщПіЯТЃЌЮвУЧЮоЗЈПьЫйЖЈЮЛЕНГіЯжЮЪЬтЕФЯЕЭГЃЌвђЮЊДцдкШчЯТЧщПіЃК
ИУЯЕЭГЯьгІЪЇАмЪЧвђЮЊЕїгУЦфЫћЯЕЭГЪЇАмЃЌБЈГіДэЮѓЕФЯЕЭГБОЩэВЂУЛгаЮЪЬтЁЃ
ЕїгУЦфЫћЯЕЭГЪЇАмЪЧгЩгкЭјТчЮЪЬтЃЌЧыЧѓВЂУЛгаЕНДяФПБъЯЕЭГЃЌЫљвддкФПБъЯЕЭГЕФШежОжаПДВЛЕНШЮКЮвьГЃЁЃ
БЛЕїгУЕФЯЕЭГЯьгІГЌЪБЃЌЕМжТЕїгУЗНжїЖЏЖЯПЊСЌНгЃЌдкБЛЕїгУЗНЕФШежОжажЛФмПДЕНСЌНгвтЭтжажЙЕФвьГЃаХЯЂЁЃ
ЕїгУЦфЫћЯЕЭГДцдквЛЬѕКмГЄЕФЕїгУСДЃЌЮоЗЈПьЫйзЗзйЕНдДЭЗЁЃ
е§ЪЧгЩгкаТДяДяКѓЬЈДѓСПЕФЮЂЗўЮёЯЕЭГвдМАЯЕЭГжЎМфИДдгЕФЕїгУвРРЕЙиЯЕЃЌМгЩЯНЯИДдгЕФЭјТчЛЗОГЃЌЕМжТГіЯжЮЪЬтКѓХХВщЪЎЗжРЇФбЁЃОГЃГіЯжМИИіЯЕЭГЭЌЪБПЊЪМБЈОЏЃЌШЛКѓЮвУЧПЊЪМдкЖрИіЯЕЭГжаПЊЪМХХВщЮЪЬтЃЌзюКѓЗЂЯжЪЧгЩгкФГЬЈЪ§ОнПтЛњЦїЕФЭјТчГіЯжСЫЮЪЬтЁЃЭЌЪБЮвУЧвВвЊШЅШЗШЯЪЧЗёЫљгаЕФЯЕЭГЖМЪЧгЩгкетИіЮЪЬтЖјв§ЗЂЕФБЈОЏЃЌРЫЗбСЫДѓСПЕФШЫСІЁЃ
2. RPCМрПи - Ъ§ОнВЩМЏ
ЛљгкЩЯЪіЧщПіЃЌЮвУЧПЊЪМбаЗЂOverwatchМрПиЯЕЭГЃЌЯЃЭћФмЙЛНтОіШчЯТЮЪЬтЃК
ЪЕЪБМрПиЯЕЭГжаЫљгаЕФRPCЃЌМАЪБЗЂЯжЫљгаЕФRPCЕїгУЪЇАмЧщПіЁЃ
ФмЙЛдкЖрИіЯЕЭГЭЌЪБвьГЃЪБПьЫйЖЈЮЛЕНвьГЃЕФИљдДЁЃ
ЮЊСЫФмЙЛЗЂЯжRPCЕїгУЪЇАмЕФЫљгаЧщПіЃЈАќРЈвЕЮёЮЪЬтЁЂЯЕЭГЮЪЬтЁЂЭјТчЮЪЬтЃЉЃЌЮвУЧЬжТлШчЯТСНжжМрПиЗНАИЃК
1ЁЂДгЗўЮёЬсЙЉЗНМрПи
ЖдЗўЮёЬсЙЉЗНгІгУШнЦїЕФЗУЮЪШежОЃЈШчTomcatЕФaccess.logЃЉНјааМрПиЃЌНЋЫљгагІгУЕФетаЉШежОЮФМўЭЈЙ§ЙЋЫОЯжгаЕФШежОЪеМЏ-ЗжЮіЯЕЭГНјааЭГвЛЪеМЏЗжЮіЁЃетбљЕФЗНАИПЩвдПьЫйЪЕЪЉЧвЮоашаоИФЯжгаДњТыЃЌПЊЗЂСПвВНЯЩйЁЃ
ШЛЖјетбљзіЕФЮЪЬтвВКмУїЯдЃК
ЮоЗЈМрПиЕНЭјТчЮЪЬтЃЌвђЮЊЧыЧѓЛсгЩгкЭјТчдвђУЛгаЕНДяЗўЮёЬсЙЉЗНЃЈConnect TimeoutЃЉ
ЧыЧѓЯьгІГЌЪБЃЈRead TimeoutЃЉЃЌетбљЕФЧыЧѓВЛЛсеЙЯждкЗУЮЪШежОжаЃЈвЛаЉАцБОЕФTomcatДцдкИУЮЪЬтЃЌАќРЈЮвУЧе§дкЪЙгУЕФАцБОЃЉ
ЮоЗЈМрПиЕНвьГЃЕФЯьгІЧыЧѓЃЌМДЫфШЛЗЕЛиСЫHTTP 200зДЬЌТыЃЌЕЋЪЧЪЕМЪЩЯЪЧЧыЧѓЪЇАмЃЈШчЗЕЛиJSONзжЗћДЎ{ЁАstatusЁБ:
ЁАfailedЁБ}ЃЉ
ЮвУЧВЛФмДгЗўЮёЬсЙЉЗННјааЁАжїЙлЁБЕФМрПиЁЃЗўЮёЪЧИјЗўЮёЯћЗбЗНЪЙгУЕФЃЌЗўЮёЬсЙЉЗНЫљШЯЮЊЕФЁАе§ШЗЁБЪЧВЛЙЛЁАПЭЙлЁБЕФЃЌжЛгаЗўЮёЯћЗбЗНШЯЮЊЧыЧѓГЩЙІЃЌВХЪЧЁАПЭЙлЁБЕФЧыЧѓГЩЙІЁЃ
2ЁЂДгЗўЮёЯћЗбЗНМрПи
ДгЗўЮёЯћЗбЗНПЩвдЪЕЯжЩЯЪіЕФЁАПЭЙлЁБЕФМрПиЁЃ
| |
ДгЗўЮёЬсЙЉЗНМрПи |
ДгЗўЮёЯћЗбЗНМрПи |
| ВЛашаоИФДњТы |
Yes |
No |
| ИажЊДэЮѓЯьгІ |
Yes |
Yes |
| ИажЊЭјТчДэЮѓ |
No |
Yes |
| ИажЊЯьгІГЌЪБ |
Maybe |
Yes |
| ИажЊВЛе§ШЗЗЕЛижЕ |
No |
Yes |
| ЪЕЪБ |
Maybe |
Yes |
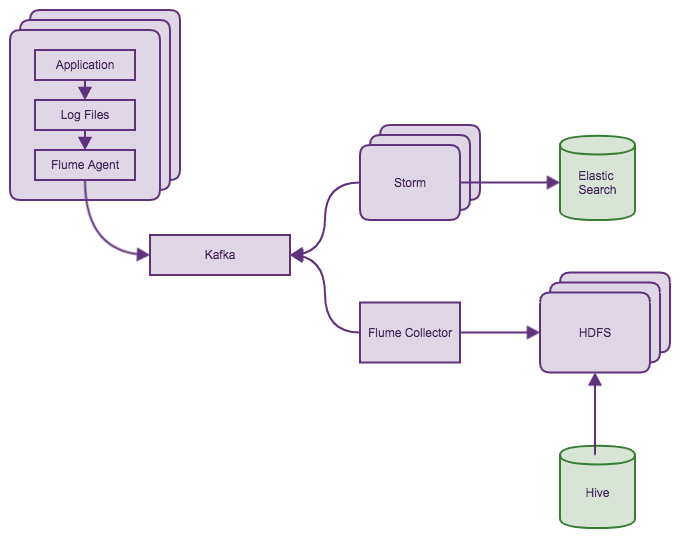
ЕЋЪЧЮвУЧашвЊздМКЪЕЯжаХЯЂЕФЪеМЏвдМАОлКЯЃЌЭЌЪБЮвУЧашвЊвЛИідкЗўЮёНјГЬжаЕФAgentШЅЪеМЏRPCаХЯЂЁЃЮвУЧВЩгУСЫKafkaНјааЪ§ОнЕФЪеМЏЃЌStormНјааЪ§ОнЕФОлКЯЃЌзюКѓНЋЪ§ОнНЛИјOverwatchЗўЮёНјГЬНјааДцДЂКЭеЙЯжЁЃетбљЮвУЧПЩвдзіЕНвЛИібгГйдкУыМЖЕФЪЕЪБМрПиЯЕЭГЁЃ
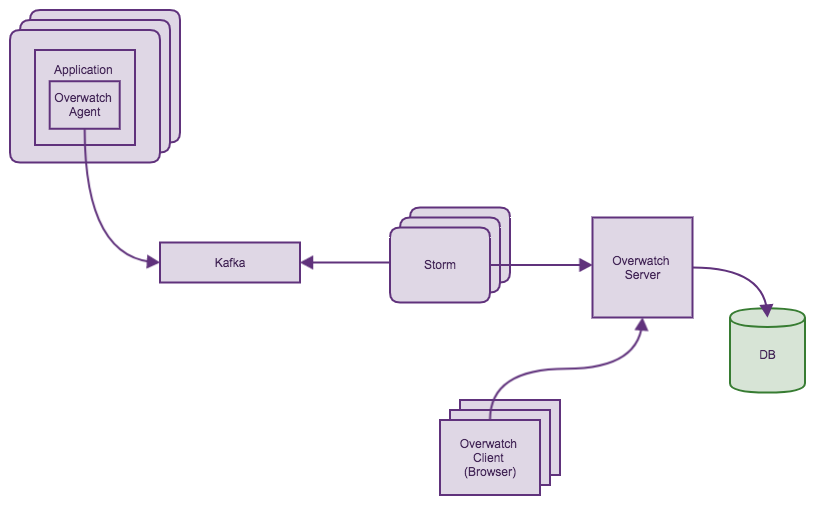
3. RPCМрПи - Ъ§ОнеЙЯж
жСДЫЃЌЮвУЧЛЙашвЊНтОівЛИіЮЪЬтЃКШчКЮФмЙЛдкЖрИіЯЕЭГЭЌЪБвьГЃЪБЃЌПьЫйЖЈЮЛЕНвьГЃЕФИљдДЁЃДЋЭГЕФМрПиЖрвджљзДЭМЁЂелЯпЭМЕФаЮЪНеЙЯжаХЯЂЁЃ
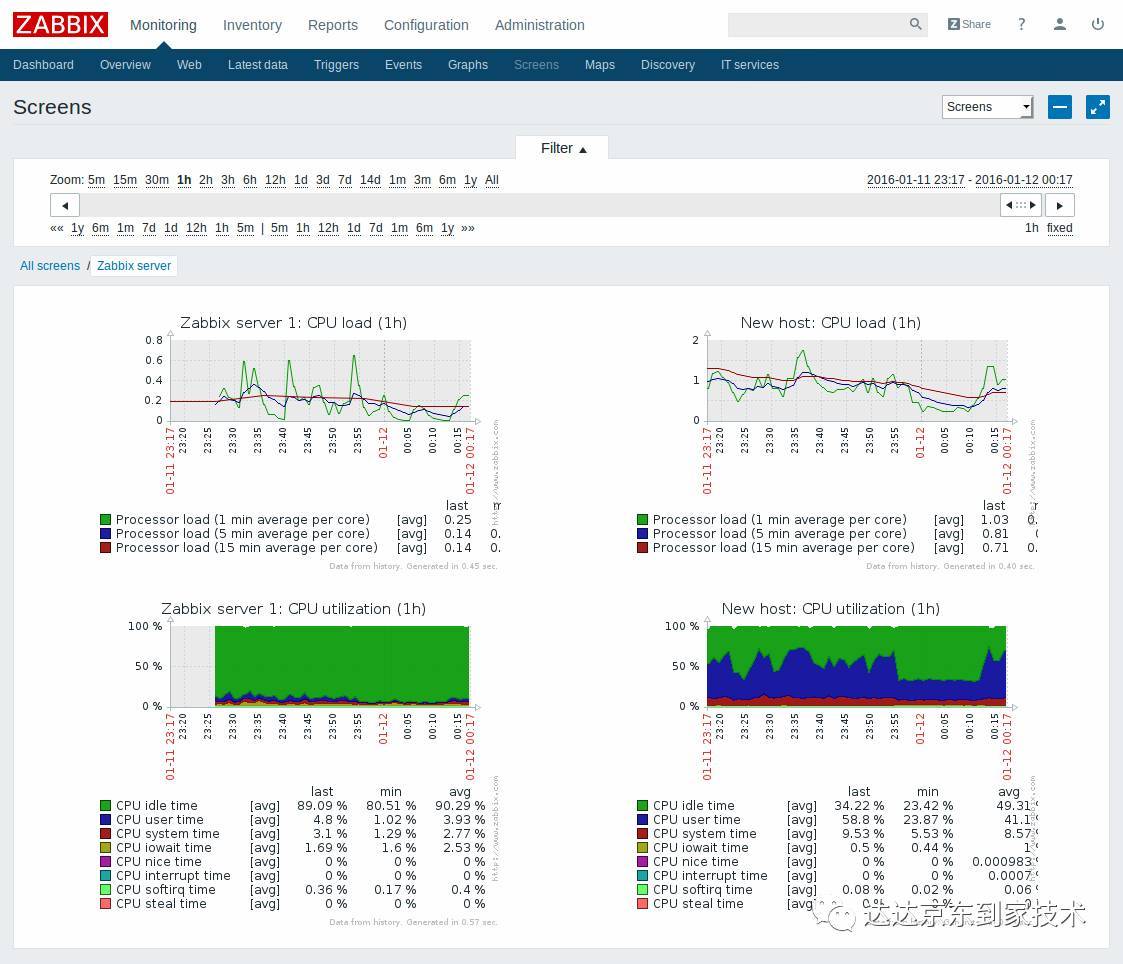
етбљЕФаХЯЂеЙЯжЯдШЛВЛФмТњзуЮвУЧЕФашЧѓЃЌOverwatchдкаХЯЂЕФеЙЯжЗНЪНЩЯашвЊзїГіИФБфЃЌЮвУЧВЩгУСЫгаЯђЭМЕФЗНЪНеЙЯжМрПиЪ§ОнЁЃгаЯђЭМеЙЯжRPCМрПиЪ§ОнгаШчЯТгХЕуЃК
ПЩвддквЛеХЭМБэжаЭъећеЙЯжЫљгаЯЕЭГЕФзДЬЌЁЃ
гЩгкRPCЪЧгаЯђЕФЃЈДгЯћЗбЗНЯђЬсЙЉЗНЃЉЃЌЪЙгУгаЯђЭМПЩвдЭъУРБэДяГіИУаХЯЂЁЃ
ЭМПЩвдБэДяЯЕЭГжЎМфЕФвРРЕЙиЯЕЃЌЕБЖрИіЯЕЭГЭЌЪБвьГЃЪБЃЌПЩвдЭЈЙ§ЙлВьЭМжаЕФвРРЕЙиЯЕРДевЕНвьГЃЕФИљдДЁЃ
ЪЙгУгаЯђЭМвВДцдквЛаЉЮЪЬтЃКДЋЭГЭМБэПЩвдеЙЯжЁАМрПиЭГМЦжЕ-ЪБМфЁБетбљЕФЖўЮЌЙиЯЕЃЌЖјдкгаЯђЭМжаеЙЯжетаЉЪ§ОнВЂУЛгаФЧУДМђЕЅЃЌЮвУЧдкжЎКѓЕФеТНкЬжТлжаЛсЬжТлеЙЯжЕФЗНЗЈЁЃ
дкOverwatchжаЃЌЮвУЧЛсеЙЯжЯЕЭГзюНќвЛЗжжгЁЂзюНќ5ЗжжгЦНОљЁЂзюНќ15ЗжжгЦНОљЕФЭГМЦжЕЃЈРрЫЦгкLinuxжаЕФuptimeЫљеЙЪОЕФаХЯЂЃЉЁЃвЊеЙЯжетаЉЪ§ОнЃЌOverwatchБиаыШЁзюНќ15ЗжжгЕФЫљгаМрПиЪ§ОнЃЌВЂНјааЯргІЕФОлКЯМЦЫуЃЌетЪЧПЊЯњЬиБ№ДѓЕФВйзїЃЌЯдШЛВЛПЩФмЖдгкУПДЮгУЛЇЕФВщПДМрПиЧыЧѓЖМНјаавЛДЮетбљЕФВйзїЁЃЖдгкетВПЗжЕФЪЕЯжЃЌЮвУЧВЩгУСЫCQRSЕФФЃЪНЁЃ
CQRSЃЈCommand Query Responsibility SegregationЃЉЪЧжИЖдгкЪ§ОнЕФаоИФЁЂИќаТВйзїЃЈCommandЃЉКЭЖСШЁЃЈQueryЃЉВйзїЗжБ№ЪЙгУВЛЭЌЕФModelЁЃетЖдгкЦеЭЈЕФCRUDвЕЮёашЧѓРДЫЕжЛЛсдіМгЯЕЭГИДдгЖШЃЌЕЋЪЧдкOverwatchетбљИДдгВщбЏЁЂМђЕЅаДШыЕФГЁОАЯТЃЌЪЧвЛжжЗЧГЃКЯЪЪЕФФЃЪНЁЃ
гЩгкOverwatchЕФЗўЮёЖЫгЩNodeJSЪЕЯжЃЌЫљвдПЩвдЭъУРЪЕЯжвЛИіЪТМўЧ§ЖЏЕФЁЂДгЗўЮёЦїЕНфЏРРЦїЕФCQRSМмЙЙЁЃМмЙЙЩшМЦШчЯТЃК
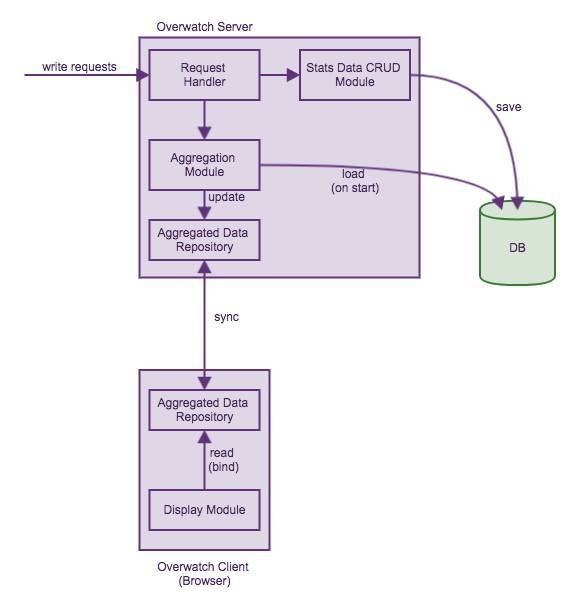
4. ПЩЪгЛЏгаЯђЭМЩшМЦ
ЩЯЮФЬсЕНСЫгаЯђЭМЕФЮЪЬтЃЌМДФбвдеЙЯжвЛИіЪБМфжсЁЃЯдЪОЦїЖМЪЧЖўЮЌЕФЃЌДЋЭГЕФжљзДЭМгУвЛЮЌБэЪОЭГМЦжЕЃЌСэвЛЮЌБэЪОЪБМфЃЌЖўепаЮГЩЕФзјБъЕуКЭЖўЮЌЯдЪОЦїЩЯЕФЕуЖдгІЁЃЖјгаЯђЭМашвЊеЙЯжвЛИіЁАЗНЯђЁБЃЌНкЕуашвЊдквЛИіЦНУцФкеЙЯжЃЌЫљвдЯдЪОЦїЩЯЕФСНИіЮЌЖШвбОБЛгУЭъСЫЁЃЮЊСЫеЙЪОЪБМфЮЌЖШЕФаХЯЂЃЌЮвУЧВЩгУСЫЯдЪОЦїЕФЕкШ§ИіЮЌЖШЁЊЁЊбеЩЋЁЃ
ЮвУЧЪЙгУШ§ИіЭЌаФдВБэЪОвЛИіНкЕуЃЌУПИідВЕФбеЩЋИљОнИУЯЕЭГЫљгаRPCЕїгУЕФГЩЙІТЪДгРЖЃЈ100%ЃЉЕНЛЦЃЈ<99.9%ЃЉЕНКьЃЈ<99%ЃЉЁЃзюФкВрЕФдВБэЪОзюНќвЛЗжжгЕФГЩЙІТЪЃЛжаМфЕФдВБэЪОзюНќ5ЗжжгЕФГЩЙІТЪЃЛзюЭтВрЕФдВБэЪОзюНќ15ЗжжгЕФГЩЙІТЪЁЃЭЈЙ§етШ§ИіЭЌаФдВЃЌЮвУЧОЭПЩвджБЙлСЫНтЕНИУЯЕЭГЕБЧАЕФзДЬЌвдМАзюНќ15ЗжжгЕФБфЛЏЁЃ
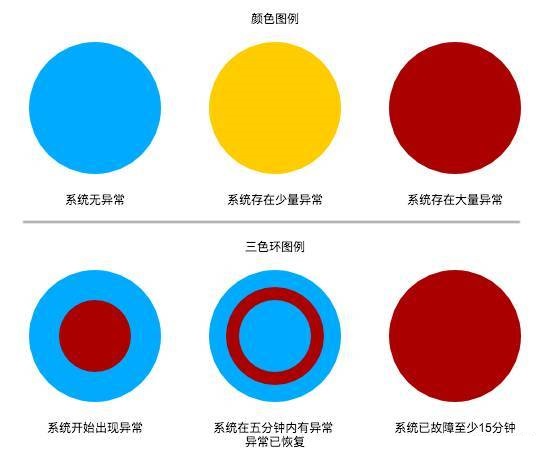
Г§ДЫжЎЭтЮвУЧЪЙгУНкЕуЕФДѓаЁБэЪОНкЕузюНќвЛЗжжгЕФЗУЮЪСПЃЌгУБпЕФбеЩЋБэЪОСНИіЯЕЭГжЎМфЕФRPCЕїгУЕФГЩЙІТЪЁЃ
ЕБЖрИіЯЕЭГЭЌЪБвьГЃЪБЃЌЭЈЙ§ЯЕЭГМфЕФвРРЕЙиЯЕЃЌЮвУЧПЩвдбИЫйевЕНвьГЃЕФИљдДЃЌвВПЩвдЦРЙРвьГЃЕФгАЯьЗЖЮЇЁЃ
5. OverwatchЯЕЭГНиЭМ
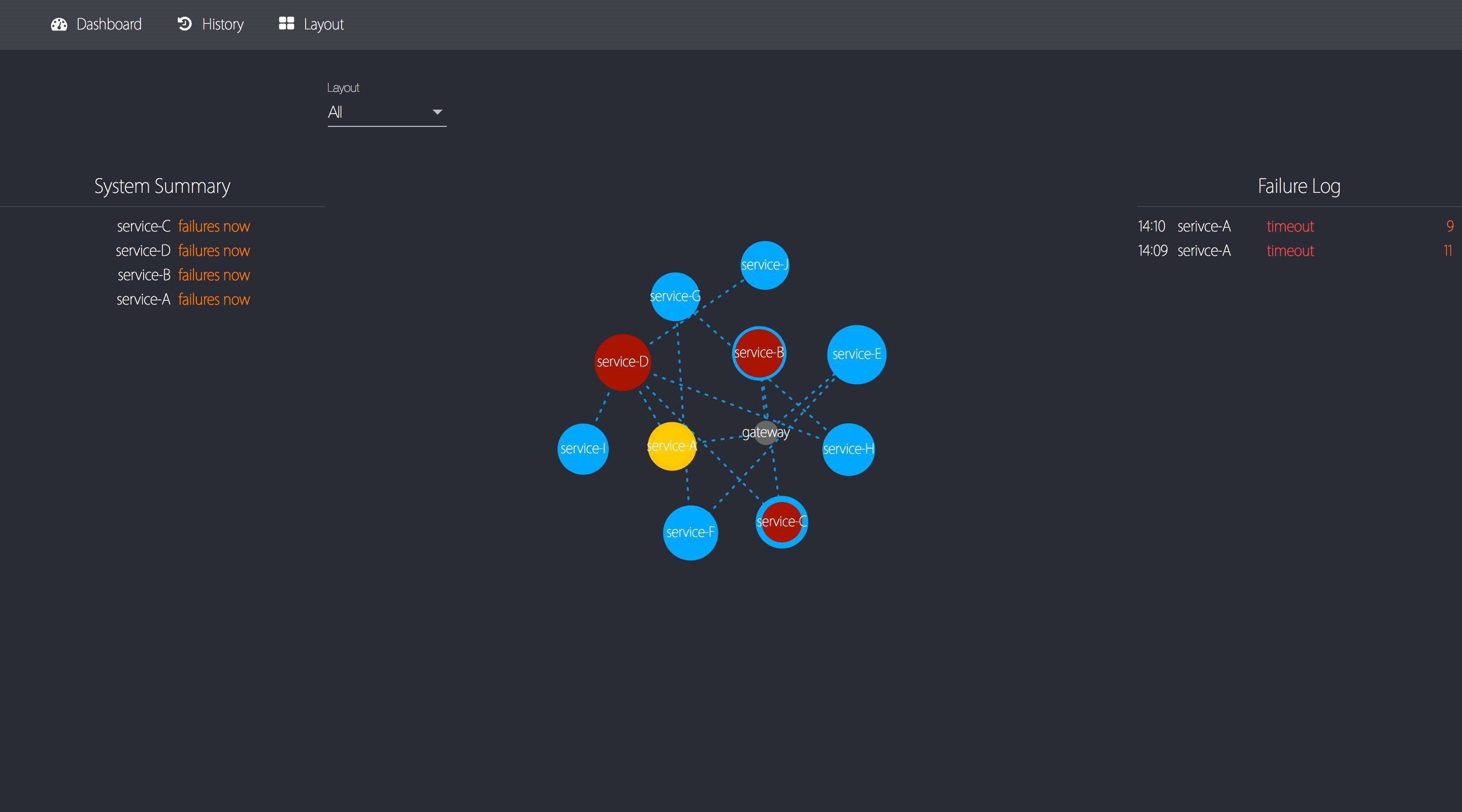
гаЯђЭМЁЂЪЕЪБДэЮѓШежОЁЂЯЕЭГзмРР
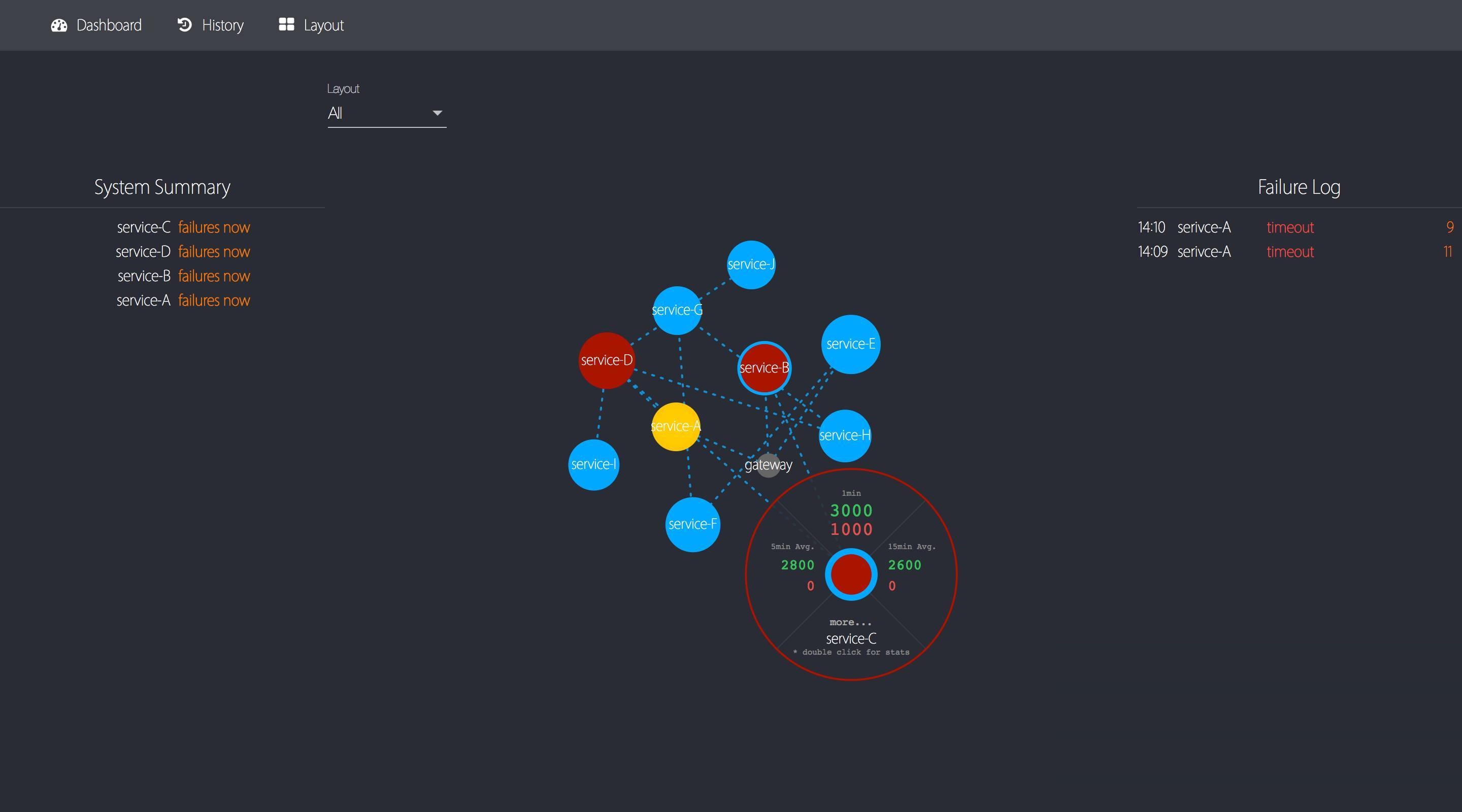
НкЕуаХЯЂЃЌАќРЈ5ЗжжгЁЂ10ЗжжгЁЂ15ЗжжгЭГМЦ
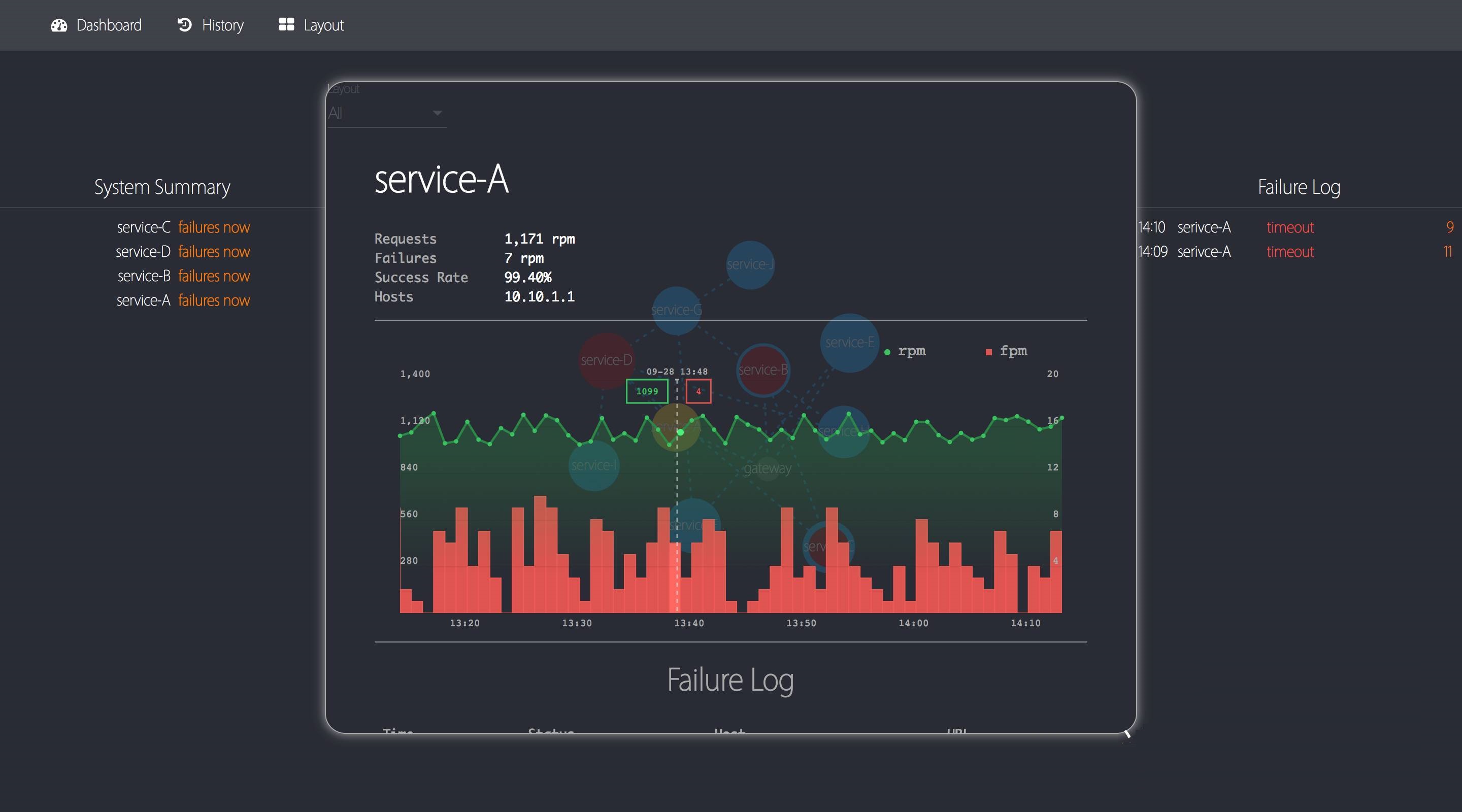
ЕЅЯЕЭГаХЯЂПьЫйеЙЪОЃЌАќРЈзюНќвЛаЁЪБЭГМЦЭМБэвдМАДэЮѓШежО
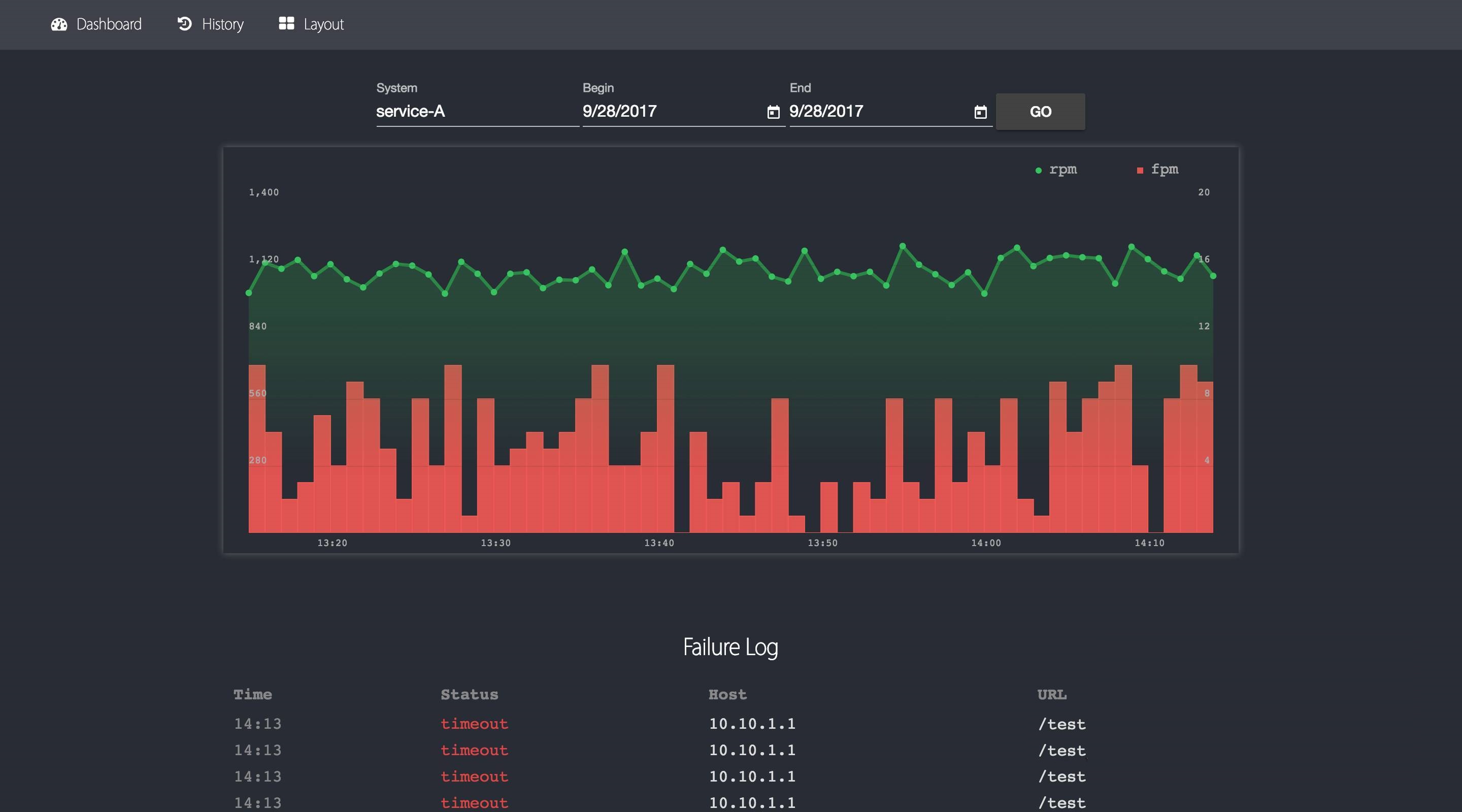
ЕЅЯЕЭГРњЪЗаХЯЂВщбЏ
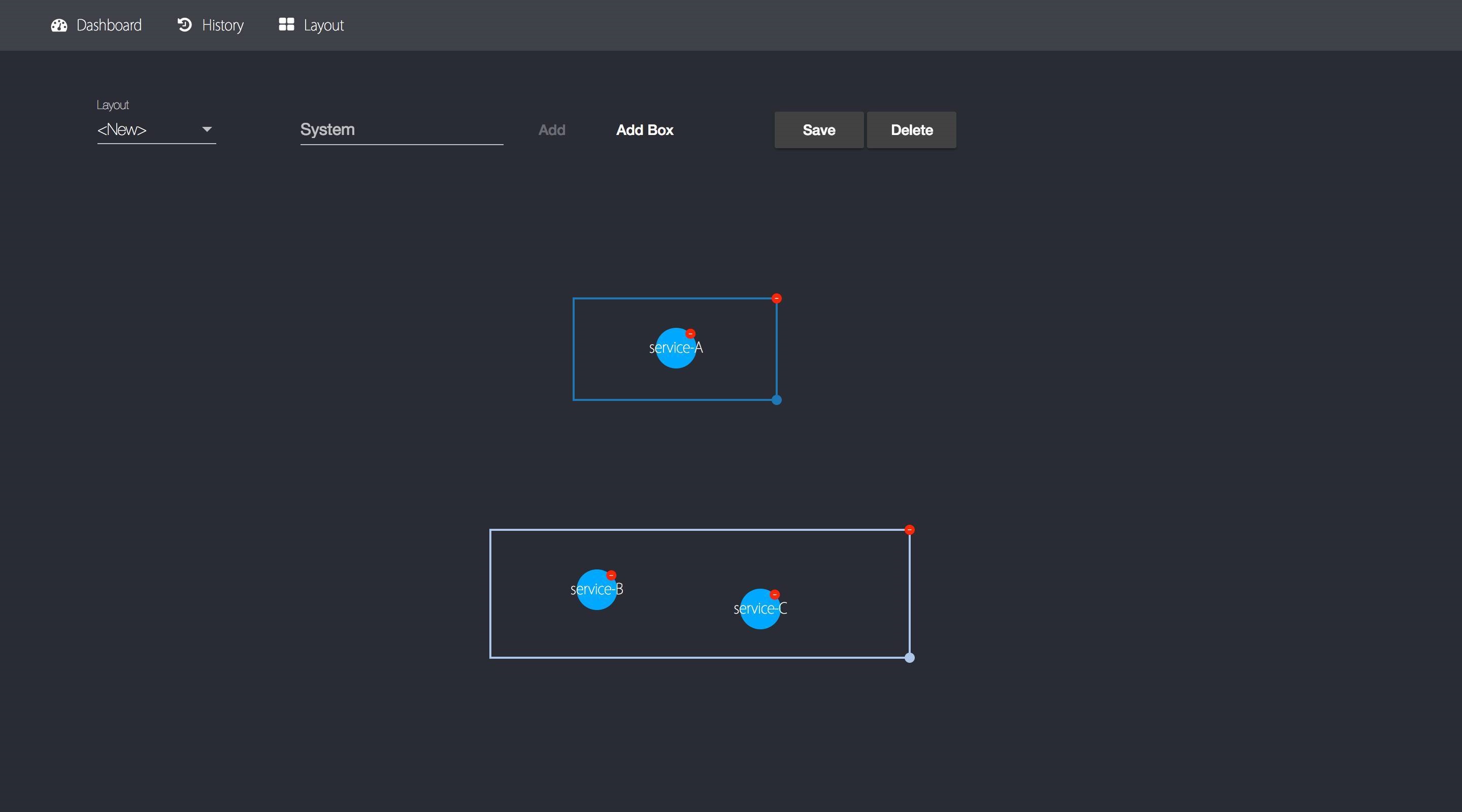
гаЯђЭМВМОжЩшжУ
6. змНс
OverwatchЗжВМЪНЯЕЭГМрПиЦНЬЈПЩвдЖдЫљгаКѓЬЈЯЕЭГМфЕФRPCЭЈаХНјааЪЕЪБЕФМрПиЁЃЭМаЮЛЏЕФеЙЯжЪЙЕУЙЄГЬЪІВЛгУШЅНтЖСДѓСПЕФЁЂИДдгЕФЪ§ОнБЈБэЁЃНіЭЈЙ§вЛеХгаЯђЭМЃЌЙЄГЬЪІБуПЩвдПьЫйРэНтВЂеЦЮеЕБЧАЯЕЭГЕФећЬхзДПіЃЌАяжњЙЄГЬЪІПьЫйЖЈЮЛВЂаоИДЯЕЭГвьГЃЁЃЭЌЪБЃЌЮвУЧвВдкВЛЖЯгХЛЏМгЧПOverwatchЕФЙІФмЃЌOverwatchгазХМЋДѓЕФРЉеЙЕФЧБСІЃЌЭЈЙ§ЖдПЭЛЇЖЫЪеМЏГЬађЕФМгЧПЃЌЮвУЧЛЙПЩвдЪЕЯжвдЯТЙІФмЃК
ЖдгкЪ§ОндДЁЂжаМфМўЕФМрПиЃЈШчMySQLЁЂRedisЁЂЯћЯЂЖгСаЃЉЃЌдкгаЯђЭМжаМгШыЛљДЁзщМўЃЌШЋУцМрПиЫљгаЯЕЭГМфЕФвРРЕвдМАЕїгУЧщПіЁЃ
жЇГжИќЖрRPCавщ ЃЈШчThriftЁЂgRPCЃЉ
ИќЖрЕФmetricЃЌЪЕЯжОЋШЗЕНAPIЕФМрПиКЭеЙЯж
|









