| БрМЭЦМі: |
БОЮФжївЊНщЩмШЋСДТЗМрПизщМўгаФФаЉФПБъвЊЧѓЃЌвЛАуЕФШЋСДТЗМрПиЯЕЭГЕФЫФДѓЙІФмФЃПщЃЌвдМАШ§жжШЋСДТЗМрПиЗНАИЖдБШЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкTesterHomeЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
0 ЮЪЬтБГОА
ЫцзХЮЂЗўЮёМмЙЙЕФСїааЃЌЗўЮёАДееВЛЭЌЕФЮЌЖШНјааВ№ЗжЃЌвЛДЮЧыЧѓЭљЭљашвЊЩцМАЕНЖрИіЗўЮёЁЃЛЅСЊЭјгІгУЙЙНЈдкВЛЭЌЕФШэМўФЃПщМЏЩЯЃЌетаЉШэМўФЃПщЃЌгаПЩФмЪЧгЩВЛЭЌЕФЭХЖгПЊЗЂЁЂПЩФмЪЙгУВЛЭЌЕФБрГЬгябдРДЪЕЯжЁЂгаПЩФмВМдкСЫМИЧЇЬЈЗўЮёЦїЃЌКсПчЖрИіВЛЭЌЕФЪ§ОнжааФЁЃвђДЫЃЌОЭашвЊвЛаЉПЩвдАяжњРэНтЯЕЭГааЮЊЁЂгУгкЗжЮіадФмЮЪЬтЕФЙЄОпЃЌвдБуЗЂЩњЙЪеЯЕФЪБКђЃЌФмЙЛПьЫйЖЈЮЛКЭНтОіЮЪЬтЁЃ
ШЋСДТЗМрПизщМўОЭдкетбљЕФЮЪЬтБГОАЯТВњЩњСЫЁЃзюГіУћЕФЪЧЙШИшЙЋПЊЕФТлЮФЬсЕНЕФ
Google DapperЁЃЯывЊдкетИіЩЯЯТЮФжаРэНтЗжВМЪНЯЕЭГЕФааЮЊЃЌОЭашвЊМрПиФЧаЉКсПчСЫВЛЭЌЕФгІгУЁЂВЛЭЌЕФЗўЮёЦїжЎМфЕФЙиСЊЖЏзїЁЃ
ЫљвдЃЌдкИДдгЕФЮЂЗўЮёМмЙЙЯЕЭГжаЃЌМИКѕУПвЛИіЧАЖЫЧыЧѓЖМЛсаЮГЩвЛИіИДдгЕФЗжВМЪНЗўЮёЕїгУСДТЗЁЃвЛИіЧыЧѓЭъећЕїгУСДПЩФмШчЯТЭМЫљЪОЃК
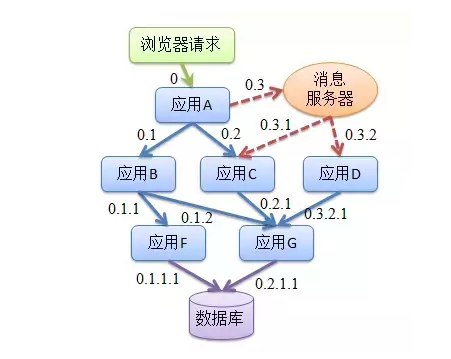
ФЧУДдквЕЮёЙцФЃВЛЖЯдіДѓЁЂЗўЮёВЛЖЯдіЖрвдМАЦЕЗББфИќЕФЧщПіЯТЃЌУцЖдИДдгЕФЕїгУСДТЗОЭДјРДвЛЯЕСаЮЪЬтЃК
1.ШчКЮПьЫйЗЂЯжЮЪЬтЃП
2.ШчКЮХаЖЯЙЪеЯгАЯьЗЖЮЇЃП
3.ШчКЮЪсРэЗўЮёвРРЕвдМАвРРЕЕФКЯРэадЃП
4.ШчКЮЗжЮіСДТЗадФмЮЪЬтвдМАЪЕЪБШнСПЙцЛЎЃП
ЭЌЪБЮвУЧЛсЙизЂдкЧыЧѓДІРэЦкМфИїИіЕїгУЕФИїЯюадФмжИБъЃЌБШШчЃКЭЬЭТСПЃЈTPSЃЉЁЂЯьгІЪБМфМАДэЮѓМЧТМЕШЁЃ
1.ЭЬЭТСПЃЌИљОнЭиЦЫПЩМЦЫуЯргІзщМўЁЂЦНЬЈЁЂЮяРэЩшБИЕФЪЕЪБЭЬЭТСПЁЃ
2.ЯьгІЪБМфЃЌАќРЈећЬхЕїгУЕФЯьгІЪБМфКЭИїИіЗўЮёЕФЯьгІЪБМфЕШЁЃ
3.ДэЮѓМЧТМЃЌИљОнЗўЮёЗЕЛиЭГМЦЕЅЮЛЪБМфвьГЃДЮЪ§ЁЃ
ШЋСДТЗадФмМрПи ДгећЬхЮЌЖШЕНОжВПЮЌЖШеЙЪОИїЯюжИБъЃЌНЋПчгІгУЕФЫљгаЕїгУСДадФмаХЯЂМЏжаеЙЯжЃЌПЩЗНБуЖШСПећЬхКЭОжВПадФмЃЌВЂЧвЗНБуевЕНЙЪеЯВњЩњЕФдДЭЗЃЌЩњВњЩЯПЩМЋДѓЫѕЖЬЙЪеЯХХГ§ЪБМфЁЃ
гаСЫШЋСДТЗМрПиЙЄОпЃЌЮвУЧФмЙЛДяЕНЃК
1.ЧыЧѓСДТЗзЗзйЃЌЙЪеЯПьЫйЖЈЮЛЃКПЩвдЭЈЙ§ЕїгУСДНсКЯвЕЮёШежОПьЫйЖЈЮЛДэЮѓаХЯЂЁЃ
2.ПЩЪгЛЏЃК ИїИіНзЖЮКФЪБЃЌНјааадФмЗжЮіЁЃ
3.вРРЕгХЛЏЃКИїИіЕїгУЛЗНкЕФПЩгУадЁЂЪсРэЗўЮёвРРЕЙиЯЕвдМАгХЛЏЁЃ
4.Ъ§ОнЗжЮіЃЌгХЛЏСДТЗЃКПЩвдЕУЕНгУЛЇЕФааЮЊТЗОЖЃЌЛузмЗжЮігІгУдкКмЖрвЕЮёГЁОАЁЃ
1 ФПБъвЊЧѓ
ШчЩЯЫљЪіЃЌФЧУДЮвУЧбЁдёШЋСДТЗМрПизщМўгаФФаЉФПБъвЊЧѓФиЃПGoogle
DapperжавВЬсЕНСЫЃЌзмНсШчЯТЃК
1. ЬНеыЕФадФмЯћКФ
APMзщМўЗўЮёЕФгАЯьгІИУзіЕНзуЙЛаЁЁЃЗўЮёЕїгУТёЕуБОЩэЛсДјРДадФмЫ№КФЃЌетОЭашвЊЕїгУИњзйЕФЕЭЫ№КФЃЌЪЕМЪжаЛЙЛсЭЈЙ§ХфжУВЩбљТЪЕФЗНЪНЃЌбЁдёвЛВПЗжЧыЧѓШЅЗжЮіЧыЧѓТЗОЖЁЃдквЛаЉИпЖШгХЛЏЙ§ЕФЗўЮёЃЌМДЪЙвЛЕуЕуЫ№КФвВЛсКмШнвзВьОѕЕНЃЌЖјЧвгаПЩФмЦШЪЙдкЯпЗўЮёЕФВПЪ№ЭХЖгВЛЕУВЛНЋИњзйЯЕЭГЙиЭЃЁЃ
2. ДњТыЕФЧжШыад
МДвВзїЮЊвЕЮёзщМўЃЌгІЕБОЁПЩФмЩйШыЧжЛђепЮоШыЧжЦфЫћвЕЮёЯЕЭГЃЌЖдгкЪЙгУЗНЭИУїЃЌМѕЩйПЊЗЂШЫдБЕФИКЕЃЁЃ
ЖдгкгІгУЕФГЬађдБРДЫЕЃЌЪЧВЛашвЊжЊЕРгаИњзйЯЕЭГетЛиЪТЕФЁЃШчЙћвЛИіИњзйЯЕЭГЯыЩњаЇЃЌОЭБиаыашвЊвРРЕгІгУЕФПЊЗЂепжїЖЏХфКЯЃЌФЧУДетИіИњзйЯЕЭГвВЬЋДрШѕСЫЃЌЭљЭљгЩгкИњзйЯЕЭГдкгІгУжажВШыДњТыЕФbugЛђЪшКіЕМжТгІгУГіЮЪЬтЃЌетбљВХЪЧЮоЗЈТњзуЖдИњзйЯЕЭГЁАЮоЫљВЛдкЕФВПЪ№ЁБетИіашЧѓЁЃ
3. ПЩРЉеЙад
вЛИігХауЕФЕїгУИњзйЯЕЭГБиаыжЇГжЗжВМЪНВПЪ№ЃЌОпБИСМКУЕФПЩРЉеЙадЁЃФмЙЛжЇГжЕФзщМўдНЖрЕБШЛдНКУЁЃЛђепЬсЙЉБуНнЕФВхМўПЊЗЂAPIЃЌЖдгквЛаЉУЛгаМрПиЕНЕФзщМўЃЌгІгУПЊЗЂепвВПЩвдздааРЉеЙЁЃ
4. Ъ§ОнЕФЗжЮі
Ъ§ОнЕФЗжЮівЊПь ЃЌЗжЮіЕФЮЌЖШОЁПЩФмЖрЁЃИњзйЯЕЭГФмЬсЙЉзуЙЛПьЕФаХЯЂЗДРЁЃЌОЭПЩвдЖдЩњВњЛЗОГЯТЕФвьГЃзДПізіГіПьЫйЗДгІЁЃЗжЮіЕФШЋУцЃЌФмЙЛБмУтЖўДЮПЊЗЂЁЃ
2 ЙІФмФЃПщ
вЛАуЕФШЋСДТЗМрПиЯЕЭГЃЌДѓжТПЩЗжЮЊЫФДѓЙІФмФЃПщЃК
1.ТёЕугыЩњГЩШежО
ТёЕуМДЯЕЭГдкЕБЧАНкЕуЕФЩЯЯТЮФаХЯЂЃЌПЩвдЗжЮЊ ПЭЛЇЖЫТёЕуЁЂЗўЮёЖЫТёЕуЃЌвдМАПЭЛЇЖЫКЭЗўЮёЖЫЫЋЯђаЭТёЕуЁЃТёЕуШежОЭЈГЃвЊАќКЌвдЯТФкШнtraceIdЁЂspanIdЁЂЕїгУЕФПЊЪМЪБМфЃЌавщРраЭЁЂЕїгУЗНipКЭЖЫПкЃЌЧыЧѓЕФЗўЮёУћЁЂЕїгУКФЪБЃЌЕїгУНсЙћЃЌвьГЃаХЯЂЕШЃЌЭЌЪБдЄСєПЩРЉеЙзжЖЮЃЌЮЊЯТвЛВНРЉеЙзізМБИЃЛ
ВЛФмдьГЩадФмИКЕЃЃКвЛИіМлжЕЮДБЛбщжЄЃЌШДЛсгАЯьадФмЕФЖЋЮїЃЌЪЧКмФбдкЙЋЫОЭЦЙуЕФЃЁ
вђЮЊвЊаДlogЃЌвЕЮёQPSдНИпЃЌадФмгАЯьдНжиЁЃЭЈЙ§ВЩбљКЭвьВНlogНтОіЁЃ
2.ЪеМЏКЭДцДЂШежО
жївЊжЇГжЗжВМЪНШежОВЩМЏЕФЗНАИЃЌЭЌЪБдіМгMQзїЮЊЛКГхЃЛ
УПИіЛњЦїЩЯгавЛИі deamon зіШежОЪеМЏЃЌвЕЮёНјГЬАбздМКЕФTraceЗЂЕНdaemonЃЌdaemonАбЪеМЏTraceЭљЩЯвЛМЖЗЂЫЭЃЛ
ЖрМЖЕФcollectorЃЌРрЫЦpub/subМмЙЙЃЌПЩвдИКдиОљКтЃЛ
ЖдОлКЯЕФЪ§ОнНјаа ЪЕЪБЗжЮіКЭРыЯпДцДЂЃЛ
РыЯпЗжЮі ашвЊНЋЭЌвЛЬѕЕїгУСДЕФШежОЛузмдквЛЦ№ЃЛ
3.ЗжЮіКЭЭГМЦЕїгУСДТЗЪ§ОнЃЌвдМАЪБаЇад
ЕїгУСДИњзйЗжЮіЃКАбЭЌвЛTraceIDЕФSpanЪеМЏЦ№РДЃЌАДЪБМфХХађОЭЪЧtimelineЁЃАбParentIDДЎЦ№РДОЭЪЧЕїгУеЛЁЃ
ХзвьГЃЛђепГЌЪБЃЌдкШежОРяДђгЁTraceIDЁЃРћгУTraceIDВщбЏЕїгУСДЧщПіЃЌЖЈЮЛЮЪЬтЁЃ
вРРЕЖШСПЃК
ЧПвРРЕЃКЕїгУЪЇАмЛсжБНгжаЖЯжїСїГЬ
ИпЖШвРРЕЃКвЛДЮСДТЗжаЕїгУФГИівРРЕЕФМИТЪИп
ЦЕЗБвРРЕЃКвЛДЮСДТЗЕїгУЭЌвЛИівРРЕЕФДЮЪ§Жр
РыЯпЗжЮіЃКАДTraceIDЛузмЃЌЭЈЙ§SpanЕФIDКЭParentIDЛЙдЕїгУЙиЯЕЃЌЗжЮіСДТЗаЮЬЌЁЃ
ЪЕЪБЗжЮіЃКЖдЕЅЬѕШежОжБНгЗжЮіЃЌВЛзіЛузмЃЌжизщЁЃЕУЕНЕБЧАQPSЃЌбгГйЁЃ
4.еЙЯжвдМАОіВпжЇГж
3 Google Dapper
3.1 Span
ЛљБОЙЄзїЕЅдЊЃЌвЛДЮСДТЗЕїгУЃЈПЩвдЪЧ RPCЃЌDB ЕШУЛгаЬиЖЈЕФЯожЦЃЉДДНЈвЛИі spanЃЌЭЈЙ§вЛИі64ЮЛ
ID БъЪЖЫќЃЌuuid НЯЮЊЗНБуЃЌspan жаЛЙгаЦфЫћЕФЪ§ОнЃЌР§ШчУшЪіаХЯЂЃЌЪБМфДСЃЌkey-valueЖдЕФЃЈAnnotationЃЉtagаХЯЂЃЌparent_id
ЕШ,Цфжа parent-id ПЩвдБэЪО span ЕїгУСДТЗРДдДЁЃ

ЩЯЭМЫЕУїСЫspanдквЛДЮДѓЕФИњзйЙ§ГЬжаЪЧЪВУДбљЕФЁЃDapperМЧТМСЫspanУћГЦЃЌвдМАУПИіspanЕФIDКЭИИIDЃЌвджиНЈдквЛДЮзЗзйЙ§ГЬжаВЛЭЌspanжЎМфЕФЙиЯЕЁЃШчЙћвЛИіspanУЛгаИИIDБЛГЦЮЊroot
spanЁЃЫљгаspanЖМЙвдквЛИіЬиЖЈЕФИњзйЩЯЃЌвВЙВгУвЛИіИњзйidЁЃ
SpanЪ§ОнНсЙЙЃК
type Span struct
{
TraceID int64 // гУгкБъЪОвЛДЮЭъећЕФЧыЧѓid
Name string
ID int64 // ЕБЧАетДЮЕїгУspan_id
ParentID int64 // ЩЯВуЗўЮёЕФЕїгУspan_id зюЩЯВуЗўЮёparent_idЮЊnull
Annotation []Annotation // гУгкБъМЧЕФЪБМфДС
Debug bool
} |
3.2 Trace
РрЫЦгк ЪїНсЙЙЕФSpanМЏКЯЃЌБэЪОвЛДЮЭъећЕФИњзйЃЌДгЧыЧѓЕНЗўЮёЦїПЊЪМЃЌЗўЮёЦїЗЕЛиresponseНсЪјЃЌИњзйУПДЮ
rpc ЕїгУЕФКФЪБЃЌДцдкЮЈвЛБъЪЖtrace_idЁЃБШШчЃКФудЫааЕФЗжВМЪНДѓЪ§ОнДцДЂвЛДЮ Trace ОЭгЩФуЕФвЛДЮЧыЧѓзщГЩЁЃ
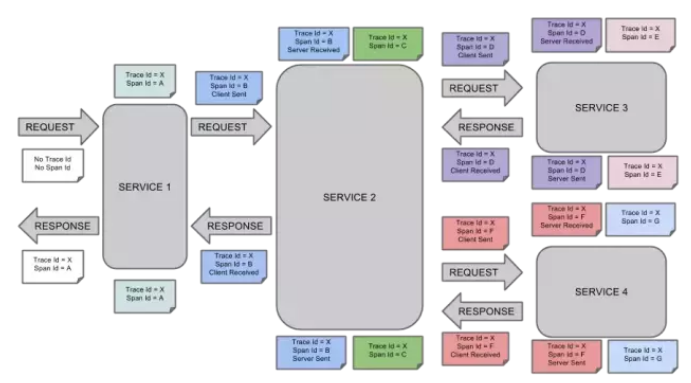
УПжжбеЩЋЕФnoteБъзЂСЫвЛИіspanЃЌвЛЬѕСДТЗЭЈЙ§TraceIdЮЈвЛБъЪЖЃЌSpanБъЪЖЗЂЦ№ЕФЧыЧѓаХЯЂЁЃЪїНкЕуЪЧећИіМмЙЙЕФЛљБОЕЅдЊЃЌЖјУПвЛИіНкЕугжЪЧЖдspanЕФв§гУЁЃНкЕужЎМфЕФСЌЯпБэЪОЕФspanКЭЫќЕФИИspanжБНгЕФЙиЯЕЁЃЫфШЛspanдкШежОЮФМўжажЛЪЧМђЕЅЕФДњБэspanЕФПЊЪМКЭНсЪјЪБМфЃЌЫћУЧдкећИіЪїаЮНсЙЙжаШДЪЧЯрЖдЖРСЂЕФЁЃ
3.3 Annotation
зЂНтЃЌгУРДМЧТМЧыЧѓЬиЖЈЪТМўЯрЙиаХЯЂЃЈР§ШчЪБМфЃЉЃЌвЛИіspanжаЛсгаЖрИіannotationзЂНтУшЪіЁЃЭЈГЃАќКЌЫФИізЂНтаХЯЂЃК
(1) csЃКClient StartЃЌБэЪОПЭЛЇЖЫЗЂЦ№ЧыЧѓ
(2) srЃКServer ReceiveЃЌБэЪОЗўЮёЖЫЪеЕНЧыЧѓ
(3) ssЃКServer SendЃЌБэЪОЗўЮёЖЫЭъГЩДІРэЃЌВЂНЋНсЙћЗЂЫЭИјПЭЛЇЖЫ
(4) crЃКClient ReceivedЃЌБэЪОПЭЛЇЖЫЛёШЁЕНЗўЮёЖЫЗЕЛиаХЯЂ
AnnotationЪ§ОнНсЙЙЃК
type Annotation
struct {
Timestamp int64
Value string
Host Endpoint
Duration int32
} |
3.4 ЕїгУЪОР§
1. ЧыЧѓЕїгУЪОР§
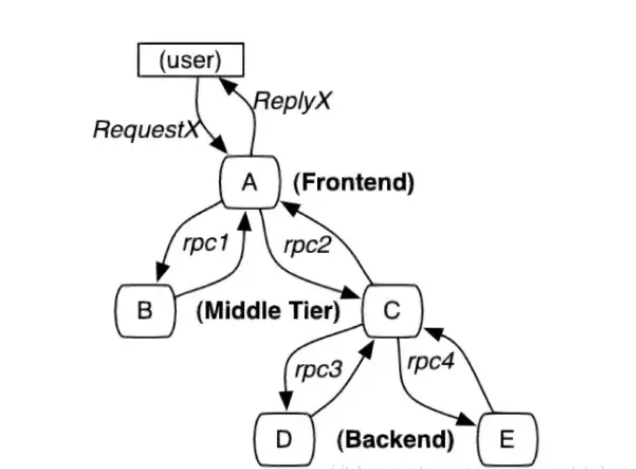
ЕБгУЛЇЗЂЦ№вЛИіЧыЧѓЪБЃЌЪзЯШЕНДяЧАЖЫAЗўЮёЃЌШЛКѓЗжБ№ЖдBЗўЮёКЭCЗўЮёНјааRPCЕїгУЃЛ
BЗўЮёДІРэЭъИјAзіГіЯьгІЃЌЕЋЪЧCЗўЮёЛЙашвЊКЭКѓЖЫЕФDЗўЮёКЭEЗўЮёНЛЛЅжЎКѓдйЗЕЛЙИјAЗўЮёЃЌзюКѓгЩAЗўЮёРДЯьгІгУЛЇЕФЧыЧѓЃЛ
2. ЕїгУЙ§ГЬзЗзй
ећИіЕїгУЙ§ГЬзЗзй:
ЧыЧѓЕНРДЩњГЩвЛИіШЋОжTraceIDЃЌЭЈЙ§TraceIDПЩвдДЎСЊЦ№ећИіЕїгУСДЃЌвЛИіTraceIDДњБэвЛДЮЧыЧѓЁЃ
Г§СЫTraceIDЭтЃЌЛЙашвЊSpanIDгУгкМЧТМЕїгУИИзгЙиЯЕЁЃУПИіЗўЮёЛсМЧТМЯТparent idКЭspan
idЃЌЭЈЙ§ЫћУЧПЩвдзщжЏвЛДЮЭъећЕїгУСДЕФИИзгЙиЯЕЁЃ
вЛИіУЛгаparent idЕФspanГЩЮЊroot spanЃЌПЩвдПДГЩЕїгУСДШыПкЁЃ
ЫљгаетаЉIDПЩгУШЋОжЮЈвЛЕФ64ЮЛећЪ§БэЪОЃЛ
ећИіЕїгУЙ§ГЬжаУПИіЧыЧѓЖМвЊЭИДЋTraceIDКЭSpanIDЁЃ
УПИіЗўЮёНЋИУДЮЧыЧѓИНДјЕФTraceIDКЭИНДјЕФSpanIDзїЮЊparent idМЧТМЯТЃЌВЂЧвНЋздМКЩњГЩЕФSpanIDвВМЧТМЯТЁЃ
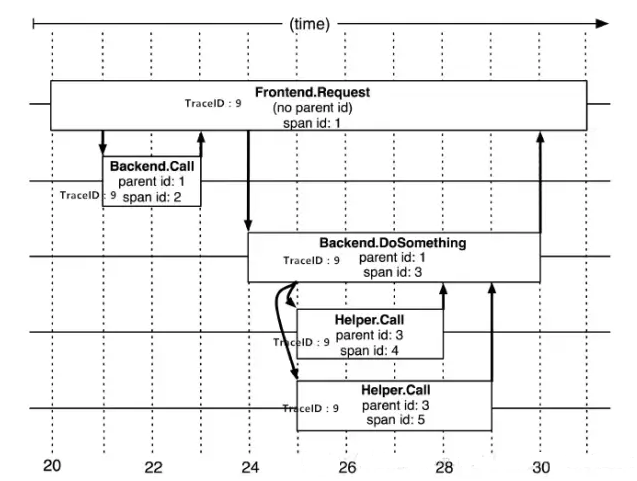
вЊВщПДФГДЮЭъећЕФЕїгУдђ жЛвЊИљОнTraceIDВщГіЫљгаЕїгУМЧТМЃЌШЛКѓЭЈЙ§parent idКЭspan
idзщжЏЦ№ећИіЕїгУИИзгЙиЯЕЁЃ
3. ЕїгУСДКЫаФЙЄзї
ЕїгУСДЪ§ОнЩњГЩЃЌЖдећИіЕїгУЙ§ГЬЕФЫљгагІгУНјааТёЕуВЂЪфГіШежОЁЃ
ЕїгУСДЪ§ОнВЩМЏЃЌЖдИїИігІгУжаЕФШежОЪ§ОнНјааВЩМЏЁЃ
ЕїгУСДЪ§ОнДцДЂМАВщбЏЃЌЖдВЩМЏЕНЕФЪ§ОнНјааДцДЂЃЌгЩгкШежОЪ§ОнСПвЛАуЖМКмДѓЃЌВЛНівЊФмЖдЦфДцДЂЃЌЛЙашвЊФмЬсЙЉПьЫйВщбЏЁЃ
жИБъдЫЫуЁЂДцДЂМАВщбЏЃЌЖдВЩМЏЕНЕФШежОЪ§ОнНјааИїжжжИБъдЫЫуЃЌНЋдЫЫуНсЙћБЃДцЦ№РДЁЃ
ИцОЏЙІФмЃЌЬсЙЉИїжжЗЇжЕОЏИцЙІФмЁЃ
4. ећЬхВПЪ№МмЙЙ
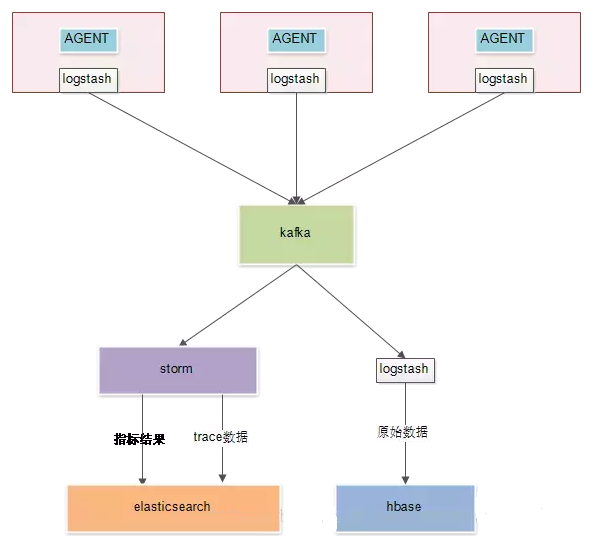
ећЬхВПЪ№МмЙЙ
ЭЈЙ§AGENTЩњГЩЕїгУСДШежОЁЃ
ЭЈЙ§logstashВЩМЏШежОЕНkafkaЁЃ
kafkaИКд№ЬсЙЉЪ§ОнИјЯТгЮЯћЗбЁЃ
stormМЦЫуЛуОлжИБъНсЙћВЂТфЕНesЁЃ
stormГщШЁtraceЪ§ОнВЂТфЕНesЃЌетЪЧЮЊСЫЬсЙЉБШНЯИДдгЕФВщбЏЁЃБШШчЭЈЙ§ЪБМфЮЌЖШВщбЏЕїгУСДЃЌПЩвдКмПьВщбЏГіЫљгаЗћКЯЕФtraceIDЃЌИљОнетаЉtraceIDдйШЅ
Hbase ВщЪ§ОнОЭПьСЫЁЃ
logstashНЋkafkaдЪМЪ§ОнРШЁЕНhbaseжаЁЃhbaseЕФrowkeyЮЊtraceIDЃЌИљОнtraceIDВщбЏЪЧКмПьЕФЁЃ
5. AGENTЮоЧжШыВПЪ№
ЭЈЙ§AGENTДњРэЮоЧжШыЪНВПЪ№ЃЌНЋадФмВтСПгывЕЮёТпМЭъШЋЗжРыЃЌПЩвдВтСПШЮвтРрЕФШЮвтЗНЗЈЕФжДааЪБМфЃЌетжжЗНЪНДѓДѓЬсИпСЫВЩМЏаЇТЪЃЌВЂЧвМѕЩйдЫЮЌГЩБОЁЃИљОнЗўЮёПчЖШжївЊЗжЮЊСНДѓРрAGENTЃК
a. ЗўЮёФкAGENTЃЌетжжЗНЪНЪЧЭЈЙ§ Java ЕФagentЛњжЦЃЌЖдЗўЮёФкВПЕФЗНЗЈЕїгУВуДЮаХЯЂНјааЪ§ОнЪеМЏЃЌШчЗНЗЈЕїгУКФЪБЁЂШыВЮЁЂГіВЮЕШаХЯЂЁЃ
b. ПчЗўЮёAGENTЃЌетжжЧщПіашвЊЖджїСїRPCПђМмвдВхМўаЮЪНЬсЙЉЮоЗьжЇГжЁЃВЂЭЈЙ§ЬсЙЉБъзМЪ§ОнЙцЗЖвдЪЪгІздЖЈвхRPCПђМмЃК
ЃЈ1ЃЉDubboжЇГжЃЛ
ЃЈ2ЃЉRestжЇГжЃЛ
ЃЈ3ЃЉздЖЈвхRPCжЇГжЃЛ
6. ЕїгУСДМрПиКУДІ
зМШЗеЦЮеЩњВњвЛЯпгІгУВПЪ№ЧщПіЃЛ
ДгЕїгУСДШЋСїГЬадФмНЧЖШЃЌЪЖБ№ЖдЙиМќЕїгУСДЃЌВЂНјаагХЛЏЃЛ
ЬсЙЉПЩзЗЫнЕФадФмЪ§ОнЃЌСПЛЏ IT дЫЮЌВПУХвЕЮёМлжЕЃЛ
ПьЫйЖЈЮЛДњТыадФмЮЪЬтЃЌажњПЊЗЂШЫдБГжајадЕФгХЛЏДњТыЃЛ
ажњПЊЗЂШЫдБНјааАзКаВтЪдЃЌЫѕЖЬЯЕЭГЩЯЯпЮШЖЈЦкЃЛ
4 ЗНАИБШНЯ
ЪаУцЩЯЕФШЋСДТЗМрПиРэТлФЃаЭДѓЖрЖМЪЧНшМј Google Dapper
ТлЮФЃЌБОЮФжиЕуЙизЂвдЯТШ§жжAPMзщМў
1.ZipkinЃКгЩTwitterЙЋЫОПЊдДЃЌПЊЗХдДДњТыЗжВМЪНЕФИњзйЯЕЭГЃЌгУгкЪеМЏЗўЮёЕФЖЈЪБЪ§ОнЃЌвдНтОіЮЂЗўЮёМмЙЙжаЕФбгГйЮЪЬтЃЌАќРЈЃКЪ§ОнЕФЪеМЏЁЂДцДЂЁЂВщевКЭеЙЯжЁЃ
2.PinpointЃКвЛПюЖдJavaБраДЕФДѓЙцФЃЗжВМЪНЯЕЭГЕФAPMЙЄОпЃЌгЩКЋЙњШЫПЊдДЕФЗжВМЪНИњзйзщМўЁЃ
3.SkywalkingЃКЙњВњЕФгХауAPMзщМўЃЌЪЧвЛИіЖдJAVAЗжВМЪНгІгУГЬађМЏШКЕФвЕЮёдЫааЧщПіНјаазЗзйЁЂИцОЏКЭЗжЮіЕФЯЕЭГЁЃ
вдЩЯШ§жжШЋСДТЗМрПиЗНАИашвЊЖдБШЕФЯюЬсСЖГіРДЃК
1.ЬНеыЕФадФм
жївЊЪЧagentЖдЗўЮёЕФЭЬЭТСПЁЂCPUКЭФкДцЕФгАЯьЁЃЮЂЗўЮёЕФЙцФЃКЭЖЏЬЌадЪЙЕУЪ§ОнЪеМЏЕФГЩБОДѓЗљЖШЬсИпЁЃ
2.collectorЕФПЩРЉеЙад
ФмЙЛЫЎЦНРЉеЙвдБужЇГжДѓЙцФЃЗўЮёЦїМЏШКЁЃ
3.ШЋУцЕФЕїгУСДТЗЪ§ОнЗжЮі
ЬсЙЉДњТыМЖБ№ЕФПЩМћадвдБуЧсЫЩЖЈЮЛЪЇАмЕуКЭЦПОБЁЃ
4.ЖдгкПЊЗЂЭИУїЃЌШнвзПЊЙи
ЬэМгаТЙІФмЖјЮоашаоИФДњТыЃЌШнвзЦєгУЛђепНћгУЁЃ
5.ЭъећЕФЕїгУСДгІгУЭиЦЫ
здЖЏМьВтгІгУЭиЦЫЃЌАяжњФуИуЧхГўгІгУЕФМмЙЙ
4.1 ЬНеыЕФадФм
БШНЯЙизЂЬНеыЕФадФмЃЌБЯОЙAPMЖЈЮЛЛЙЪЧЙЄОпЃЌШчЙћЦєгУСЫСДТЗМрПизщНЈКѓЃЌжБНгЕМжТЭЬЭТСПНЕЕЭЙ§АыЃЌФЧвВЪЧВЛФмНгЪмЕФЁЃЖдskywalkingЁЂzipkinЁЂpinpointНјааСЫбЙВтЃЌВЂгыЛљЯпЃЈЮДЪЙгУЬНеыЃЉЕФЧщПіНјааСЫЖдБШЁЃ
бЁгУСЫвЛИіГЃМћЕФЛљгкSpringЕФгІгУГЬађЃЌЫћАќКЌSpring Boot,
Spring MVCЃЌredisПЭЛЇЖЫЃЌmysqlЁЃ МрПиетИігІгУГЬађЃЌУПИіtraceЃЌЬНеыЛсзЅШЁ5Иіspan(1
Tomcat, 1 SpringMVC, 2 Jedis, 1 Mysql)ЁЃетБпЛљБОКЭ skywalkingtest
ЕФВтЪдгІгУВюВЛЖрЁЃ
ФЃФтСЫШ§жжВЂЗЂгУЛЇЃК500ЃЌ750ЃЌ1000ЁЃЪЙгУjmeterВтЪдЃЌУПИіЯпГЬЗЂЫЭ30ИіЧыЧѓЃЌЩшжУЫМПМЪБМфЮЊ10msЁЃЪЙгУЕФВЩбљТЪЮЊ1ЃЌМД100%ЃЌетБпгыЩњВњПЩФмгаВюБ№ЁЃpinpointФЌШЯЕФВЩбљТЪЮЊ20ЃЌМД50%ЃЌЭЈЙ§ЩшжУagentЕФХфжУЮФМўИФЮЊ100%ЁЃzipkinФЌШЯвВЪЧ1ЁЃзщКЯЦ№РДЃЌвЛЙВга12жжЁЃЯТУцПДЯТЛузмБэЃК
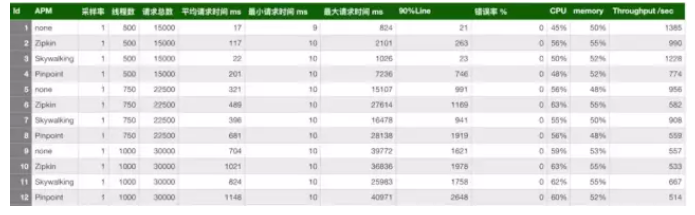
ДгЩЯБэПЩвдПДГіЃЌдкШ§жжСДТЗМрПизщМўжаЃЌskywalkingЕФЬНеыЖдЭЬЭТСПЕФгАЯьзюаЁЃЌzipkinЕФЭЬЭТСПОгжаЁЃpinpointЕФЬНеыЖдЭЬЭТСПЕФгАЯьНЯЮЊУїЯдЃЌдк500ВЂЗЂгУЛЇЪБЃЌВтЪдЗўЮёЕФЭЬЭТСПДг1385НЕЕЭЕН774ЃЌгАЯьКмДѓЁЃШЛКѓдйПДЯТCPUКЭmemoryЕФгАЯьЃЌдкФкВПЗўЮёЦїНјааЕФбЙВтЃЌЖдCPUКЭmemoryЕФгАЯьЖМВюВЛЖрдк10%жЎФкЁЃ
4.2 collectorЕФПЩРЉеЙад
collectorЕФПЩРЉеЙадЃЌЪЙЕУФмЙЛЫЎЦНРЉеЙвдБужЇГжДѓЙцФЃЗўЮёЦїМЏШКЁЃ
1.zipkin
ПЊЗЂzipkin-ServerЃЈЦфЪЕОЭЪЧЬсЙЉЕФПЊЯфМДгУАќЃЉЃЌzipkin-agentгыzipkin-ServerЭЈЙ§httpЛђепmqНјааЭЈаХЃЌhttpЭЈаХЛсЖде§ГЃЕФЗУЮЪдьГЩгАЯьЃЌЫљвдЛЙЪЧЭЦМіЛљгкmqвьВНЗНЪНЭЈаХЃЌzipkin-ServerЭЈЙ§ЖЉдФОпЬхЕФtopicНјааЯћЗбЁЃетИіЕБШЛЪЧПЩвдРЉеЙЕФЃЌЖрИіzipkin-ServerЪЕР§НјаавьВНЯћЗбmqжаЕФМрПиаХЯЂЁЃ
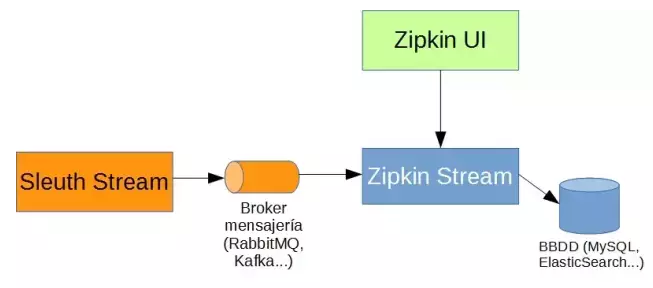
skywalking
skywalkingЕФcollectorжЇГжСНжжВПЪ№ЗНЪНЃКЕЅЛњКЭМЏШКФЃЪНЁЃcollectorгыagentжЎМфЕФЭЈаХЪЙгУСЫgRPCЁЃ
pinpoint
ЭЌбљЃЌpinpointвВЪЧжЇГжМЏШККЭЕЅЛњВПЪ№ЕФЁЃpinpoint agentЭЈЙ§thriftЭЈаХПђМмЃЌЗЂЫЭСДТЗаХЯЂЕНcollectorЁЃ
4.3 ШЋУцЕФЕїгУСДТЗЪ§ОнЗжЮі
ШЋУцЕФЕїгУСДТЗЪ§ОнЗжЮіЃЌЬсЙЉДњТыМЖБ№ЕФПЩМћадвдБуЧсЫЩЖЈЮЛЪЇАмЕуКЭЦПОБЁЃ
zipkin
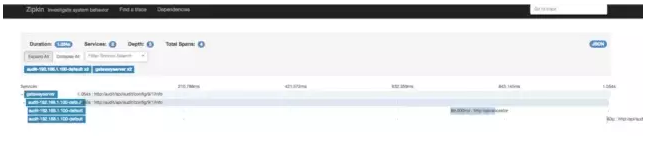
zipkinЕФСДТЗМрПиСЃЖШЯрЖдУЛгаФЧУДЯИЃЌДгЩЯЭМПЩвдПДЕНЕїгУСДжаОпЬхЕННгПкМЖБ№ЃЌдйНјвЛВНЕФЕїгУаХЯЂВЂЮДЩцМАЁЃ
skywalking

skywalking ЛЙжЇГж20+ЕФжаМфМўЁЂПђМмЁЂРрПтЃЌБШШчЃКжїСїЕФdubboЁЂOkhttpЃЌЛЙгаDBКЭЯћЯЂжаМфМўЁЃЩЯЭМskywalkingСДТЗЕїгУЗжЮіНиШЁЕФБШНЯМђЕЅЃЌЭјЙиЕїгУuserЗўЮёЃЌгЩгкжЇГжжкЖрЕФжаМфМўЃЌЫљвдskywalkingСДТЗЕїгУЗжЮіБШzipkinЭъБИаЉЁЃ
pinpoint
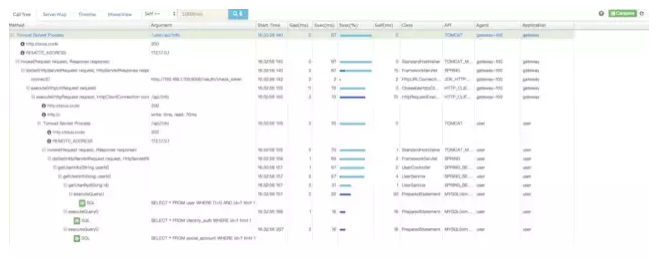
pinpointгІИУЪЧетШ§жжAPMзщМўжаЃЌЪ§ОнЗжЮізюЮЊЭъБИЕФзщМўЁЃЬсЙЉДњТыМЖБ№ЕФПЩМћадвдБуЧсЫЩЖЈЮЛЪЇАмЕуКЭЦПОБЃЌЩЯЭМПЩвдПДЕНЖдгкжДааЕФsqlгяОфЃЌЖМНјааСЫМЧТМЁЃЛЙПЩвдХфжУБЈОЏЙцдђЕШЃЌЩшжУУПИігІгУЖдгІЕФИКд№ШЫЃЌИљОнХфжУЕФЙцдђБЈОЏЃЌжЇГжЕФжаМфМўКЭПђМмвВБШНЯЭъБИЁЃ
4.4 ЖдгкПЊЗЂЭИУїЃЌШнвзПЊЙи
ЖдгкПЊЗЂЭИУїЃЌШнвзПЊЙиЃЌЬэМгаТЙІФмЖјЮоашаоИФДњТыЃЌШнвзЦєгУЛђепНћгУЁЃЮвУЧЦкЭћЙІФмПЩвдВЛаоИФДњТыОЭЙЄзїВЂЯЃЭћЕУЕНДњТыМЖБ№ЕФПЩМћадЁЃ
ЖдгкетвЛЕуЃЌZipkin ЪЙгУаоИФЙ§ЕФРрПтКЭЫќздМКЕФШнЦї(Finagle)РДЬсЙЉЗжВМЪНЪТЮёИњзйЕФЙІФмЁЃЕЋЪЧЃЌЫќвЊЧѓдкашвЊЪБаоИФДњТыЁЃskywalkingКЭpinpointЖМЪЧЛљгкзжНкТыдіЧПЕФЗНЪНЃЌПЊЗЂШЫдБВЛашвЊаоИФДњТыЃЌВЂЧвПЩвдЪеМЏЕНИќЖрОЋШЗЕФЪ§ОнвђЮЊгазжНкТыжаЕФИќЖраХЯЂЁЃ
4.5 ЭъећЕФЕїгУСДгІгУЭиЦЫ
здЖЏМьВтгІгУЭиЦЫЃЌАяжњФуИуЧхГўгІгУЕФМмЙЙЁЃ
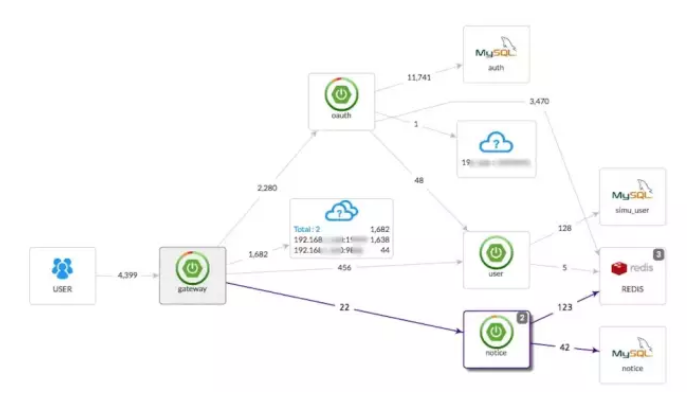
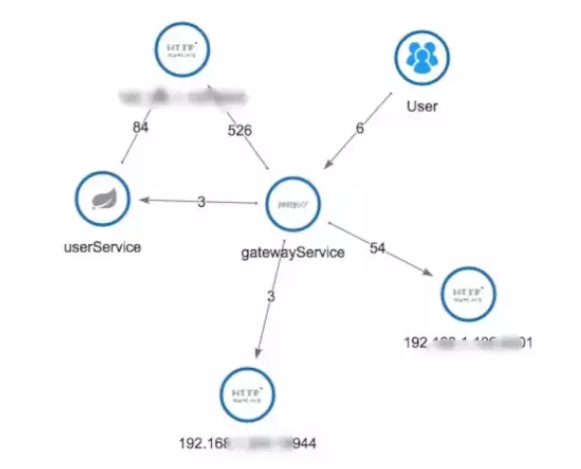
ЩЯУцШ§ЗљЭМЃЌЗжБ№еЙЪОСЫAPMзщМўИїздЕФЕїгУЭиЦЫЃЌЖМФмЪЕЯжЭъећЕФЕїгУСДгІгУЭиЦЫЁЃЯрЖдРДЫЕЃЌpinpointНчУцЯдЪОЕФИќМгЗсИЛЃЌОпЬхЕНЕїгУЕФDBУћЃЌzipkinЕФЭиЦЫОжЯогкЗўЮёгкЗўЮёжЎМфЁЃ
4.6 PinpointгыZipkinЯИЛЏБШНЯ
4.6.1 PinpointгыZipkinВювьад
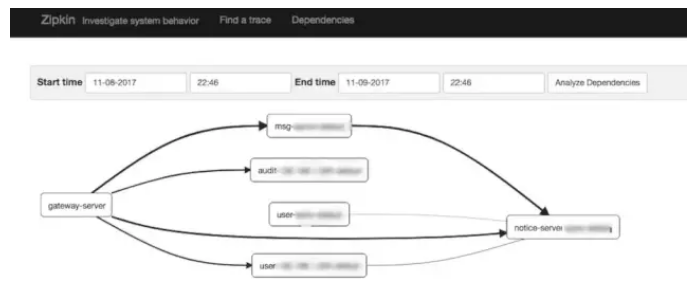
Pinpoint ЪЧвЛИіЭъећЕФадФмМрПиНтОіЗНАИЃКгаДгЬНеыЁЂЪеМЏЦїЁЂДцДЂЕН
Web НчУцЕШШЋЬзЬхЯЕЃЛЖј Zipkin жЛВржиЪеМЏЦїКЭДцДЂЗўЮёЃЌЫфШЛвВгагУЛЇНчУцЃЌЕЋЦфЙІФмгы Pinpoint
ВЛПЩЭЌШеЖјгяЁЃЗДЖј Zipkin ЬсЙЉга Query НгПкЃЌИќЧПДѓЕФгУЛЇНчУцКЭЯЕЭГМЏГЩФмСІЃЌПЩвдЛљгкИУНгПкЖўДЮПЊЗЂЪЕЯжЁЃ
Zipkin ЙйЗНЬсЙЉгаЛљгк Finagle ПђМмЃЈScala гябдЃЉЕФНгПкЃЌЖјЦфЫћПђМмЕФНгПкгЩЩчЧјЙБЯзЃЌФПЧАПЩвджЇГж
JavaЁЂScalaЁЂNodeЁЂGoЁЂPythonЁЂRuby КЭ C# ЕШжїСїПЊЗЂгябдКЭПђМмЃЛЕЋЪЧ
Pinpoint ФПЧАжЛгаЙйЗНЬсЙЉЕФ Java Agent ЬНеыЃЌЦфЫћЕФЖМдкЧыЧѓЩчЧјжЇдЎжаЃЈЧыВЮМћ
#1759 КЭ #1760ЃЉЁЃ
Pinpoint ЬсЙЉга Java Agent ЬНеыЃЌЭЈЙ§зжНкТызЂШыЕФЗНЪНЪЕЯжЕїгУРЙНиКЭЪ§ОнЪеМЏЃЌПЩвдзіЕНеце§ЕФДњТыЮоЧжШыЃЌжЛашвЊдкЦєЖЏЗўЮёЦїЕФЪБКђЬэМгвЛаЉВЮЪ§ЃЌОЭПЩвдЭъГЩЬНеыЕФВПЪ№ЃЛЖј
Zipkin ЕФ Java НгПкЪЕЯж BraveЃЌжЛЬсЙЉСЫЛљБОЕФВйзї APIЃЌШчЙћашвЊгыПђМмЛђепЯюФПМЏГЩЕФЛАЃЌОЭашвЊЪжЖЏЬэМгХфжУЮФМўЛђдіМгДњТыЁЃ
Pinpoint ЕФКѓЖЫДцДЂЛљгк HBaseЃЌЖј Zipkin Лљгк
CassandraЁЃ
4.6.2 PinpointгыZipkinЯрЫЦад
Pinpoint гы Zipkin ЖМЪЧЛљгк Google Dapper
ЕФФЧЦЊТлЮФЃЌвђДЫРэТлЛљДЁДѓжТЯрЭЌЁЃСНепЖМЪЧНЋЗўЮёЕїгУВ№ЗжГЩШєИЩгаМЖСЊЙиЯЕЕФ SpanЃЌЭЈЙ§ SpanId
КЭ ParentSpanId РДНјааЕїгУЙиЯЕЕФМЖСЊЃЛзюКѓдйНЋећИіЕїгУСДСїОЕФЫљгаЕФ Span ЛуОлГЩвЛИі
TraceЃЌБЈИцИјЗўЮёЖЫЕФ collector НјааЪеМЏКЭДцДЂЁЃ
МДБудкетвЛЕуЩЯЃЌPinpoint ЫљВЩгУЕФИХФювВВЛЭъШЋгыФЧЦЊТлЮФвЛжТЁЃБШШчЫћВЩгУ TransactionId
РДШЁДњ TraceIdЃЌЖјеце§ЕФ TraceId ЪЧвЛИіНсЙЙЃЌРяУцАќКЌСЫ TransactionId,
SpanId КЭ ParentSpanIdЁЃЖјЧв Pinpoint дк Span ЯТУцгждіМгСЫвЛИі
SpanEvent НсЙЙЃЌгУРДМЧТМвЛИі Span ФкВПЕФЕїгУЯИНкЃЈБШШчОпЬхЕФЗНЗЈЕїгУЕШЕШЃЉЃЌвђДЫ Pinpoint
ФЌШЯЛсБШ Zipkin МЧТМИќЖрЕФИњзйЪ§ОнЁЃ
ЕЋЪЧРэТлЩЯВЂУЛгаЯоЖЈ Span ЕФСЃЖШДѓаЁЃЌЫљвдвЛИіЗўЮёЕїгУПЩвдЪЧвЛИі
SpanЃЌФЧУДУПИіЗўЮёжаЕФЗНЗЈЕїгУвВПЩвдЪЧИі SpanЃЌетбљЕФЛАЃЌЦфЪЕ Brave вВПЩвдИњзйЕНЗНЗЈЕїгУМЖБ№ЃЌжЛЪЧОпЬхЪЕЯжВЂУЛгаетбљзіЖјвбЁЃ
4.6.3 зжНкТызЂШы vs API ЕїгУ
Pinpoint ЪЕЯжСЫЛљгкзжНкТызЂШыЕФ Java Agent ЬНеыЃЌЖј Zipkin ЕФ Brave
ПђМмНіНіЬсЙЉСЫгІгУВуУцЕФ APIЃЌЕЋЪЧЯИЯыЮЪЬтдЖВЛФЧУДМђЕЅЁЃзжНкТызЂШыЪЧвЛжжМђЕЅДжБЉЕФНтОіЗНАИЃЌРэТлЩЯРДЫЕЮоТлШЮКЮЗНЗЈЕїгУЃЌЖМПЩвдЭЈЙ§зЂШыДњТыЕФЗНЪНЪЕЯжРЙНиЃЌвВОЭЪЧЫЕУЛгаЪЕЯжВЛСЫЕФЃЌжЛгаВЛЛсЪЕЯжЕФЁЃЕЋ
Brave дђВЛЭЌЃЌЦфЬсЙЉЕФгІгУВуУцЕФ API ЛЙашвЊПђМмЕзВуЧ§ЖЏЕФжЇГжЃЌВХФмЪЕЯжРЙНиЁЃ
БШШчЃЌMySQL ЕФ JDBC Ч§ЖЏЃЌОЭЬсЙЉгазЂШы interceptor
ЕФЗНЗЈЃЌвђДЫжЛашвЊЪЕЯж StatementInterceptor НгПкЃЌВЂдк Connection
String жаНјааХфжУЃЌОЭПЩвдКмМђЕЅЕФЪЕЯжЯрЙиРЙНиЃЛЖјгыДЫЯрЖдЕФЃЌЕЭАцБОЕФ MongoDB ЕФЧ§ЖЏЛђепЪЧ
Spring Data MongoDB ЕФЪЕЯжОЭУЛгаШчДЫНгПкЃЌЯывЊЪЕЯжРЙНиВщбЏгяОфЕФЙІФмЃЌОЭБШНЯРЇФбЁЃ
вђДЫдкетвЛЕуЩЯЃЌBrave ЪЧгВЩЫЃЌЮоТлЪЙгУзжНкТызЂШыЖрУДРЇФбЃЌЕЋжСЩйвВЪЧПЩвдЪЕЯжЕФЃЌЕЋЪЧ
Brave ШДгаЮоДгЯТЪжЕФПЩФмЃЌЖјЧвЪЧЗёПЩвдзЂШыЃЌФмЙЛЖрДѓГЬЖШЩЯзЂШыЃЌИќЖрЕФШЁОігкПђМмЕФ API ЖјВЛЪЧздЩэЕФФмСІЁЃ
4.6.4 ФбЖШМАГЩБО
ОЙ§МђЕЅдФЖС Pinpoint КЭ Brave ВхМўЕФДњТыЃЌПЩвдЗЂЯжСНепЕФЪЕЯжФбЖШгаЬьШРжЎБ№ЁЃдкЖМУЛгаШЮКЮПЊЗЂЮФЕЕжЇГХЕФЧАЬсЯТЃЌBrave
БШ Pinpoint ИќШнвзЩЯЪжЁЃBrave ЕФДњТыСПКмЩйЃЌКЫаФЙІФмЖММЏжадк brave-core
етИіФЃПщЯТЃЌвЛИіжаЕШЫЎЦНЕФПЊЗЂШЫдБЃЌПЩвддквЛЬьжЎФкЖСЖЎЦфФкШнЃЌВЂЧвФмЖд API ЕФНсЙЙгаЗЧГЃЧхЮњЕФШЯЪЖЁЃ
Pinpoint ЕФДњТыЗтзАвВЪЧЗЧГЃКУЕФЃЌгШЦфЪЧеыЖдзжНкТызЂШыЕФЩЯВу
API ЕФЗтзАЗЧГЃГіЩЋЃЌЕЋЪЧетвРШЛвЊЧѓдФЖСШЫдБЖдзжНкТызЂШыЖрЩйгавЛаЉСЫНтЃЌЫфШЛЦфгУгкзЂШыДњТыЕФКЫаФ
API ВЂВЛЖрЃЌЕЋвЊЯыСЫНтЭИГЙЃЌПжХТЛЙЕУЩюШы Agent ЕФЯрЙиДњТыЃЌБШШчКмФбвЛФПСЫШЛЕФРэНт addInterceptor
КЭ addScopedInterceptor ЕФЧјБ№ЃЌЖјетСНИіЗНЗЈОЭЪЧЮЛгк Agent ЕФгаЙиРраЭжаЁЃ
вђЮЊ Brave ЕФзЂШыашвЊвРРЕЕзВуПђМмЬсЙЉЯрЙиНгПкЃЌвђДЫВЂВЛашвЊЖдПђМмгавЛИіШЋУцЕФСЫНтЃЌжЛашвЊжЊЕРФмдкЪВУДЕиЗНзЂШыЃЌФмЙЛдкзЂШыЕФЪБКђШЁЕУЪВУДЪ§ОнОЭПЩвдСЫЁЃОЭЯёЩЯУцЕФР§згЃЌЮвУЧИљБОВЛашвЊжЊЕР
MySQL ЕФ JDBC Driver ЪЧШчКЮЪЕЯжЕФвВПЩвдзіЕНРЙНи SQL ЕФФмСІЁЃ
ЕЋЪЧ Pinpoint ОЭВЛШЛЃЌвђЮЊ Pinpoint МИКѕПЩвддкШЮКЮЕиЗНзЂШыШЮКЮДњТыЃЌеташвЊПЊЗЂШЫдБЖдЫљашзЂШыЕФПтЕФДњТыЪЕЯжгаЗЧГЃЩюШыЕФСЫНтЃЌЭЈЙ§ВщПДЦф
MySQL КЭ Http Client ВхМўЕФЪЕЯжОЭПЩвдЖДВьетвЛЕуЃЌЕБШЛетвВДгСэЭтвЛИіВуУцЫЕУї Pinpoint
ЕФФмСІШЗЪЕПЩвдЗЧГЃЧПДѓЃЌЖјЧвЦфФЌШЯЪЕЯжЕФКмЖрВхМўвбОзіЕНСЫЗЧГЃЯИСЃЖШЕФРЙНиЁЃ
еыЖдЕзВуПђМмУЛгаЙЋПЊ API ЕФЪБКђЃЌЦфЪЕ Brave вВВЂВЛЭъШЋЮоМЦПЩЪЉЃЌЮвУЧПЩвдВЩШЁ
AOP ЕФЗНЪНЃЌвЛбљФмЙЛНЋЯрЙиРЙНизЂШыЕНжИЖЈЕФДњТыжаЃЌЖјЧвЯдШЛ AOP ЕФгІгУвЊБШзжНкТызЂШыМђЕЅКмЖрЁЃ
вдЩЯетаЉжБНгЙиЯЕЕНЪЕЯжвЛИіМрПиЕФГЩБОЃЌдк Pinpoint ЕФЙйЗНММЪѕЮФЕЕжаЃЌИјГіСЫвЛИіВЮПМЪ§ОнЁЃШчЙћЖдвЛИіЯЕЭГМЏГЩЕФЛАЃЌФЧУДгУгкПЊЗЂ
Pinpoint ВхМўЕФГЩБОЪЧ 100ЃЌНЋДЫВхМўМЏГЩШыЯЕЭГЕФГЩБОЪЧ 0ЃЛЕЋЖдгк BraveЃЌВхМўПЊЗЂЕФГЩБОжЛга
20ЃЌЖјМЏГЩГЩБОЪЧ 10ЁЃДгетвЛЕуЩЯПЩвдПДГіЙйЗНИјГіЕФГЩБОВЮПМЪ§ОнЪЧ 5:1ЁЃ
ЕЋЪЧЙйЗНгжЧПЕїСЫЃЌШчЙћга 10 ИіЯЕЭГашвЊМЏГЩЕФЛАЃЌФЧУДзмГЩБООЭЪЧ
10 * 10 + 20 = 120ЃЌОЭГЌГіСЫ Pinpoint ЕФПЊЗЂГЩБО 100ЃЌЖјЧвашвЊМЏГЩЕФЗўЮёдНЖрЃЌетИіВюОрОЭдНДѓЁЃ
4.6.5 ЭЈгУадКЭРЉеЙад
КмЯдШЛЃЌетвЛЕуЩЯ Pinpoint ЭъШЋДІгкСгЪЦЃЌДгЩчЧјЫљПЊЗЂГіРДЕФМЏГЩНгПкОЭПЩМћвЛАпЁЃ
Pinpoint ЕФЪ§ОнНгПкШБЗІЮФЕЕЃЌЖјЧввВВЛЬЋБъзМЃЈВЮПМТлЬГЬжТлЬћЃЉЃЌашвЊдФЖСКмЖрДњТыВХПЩФмЪЕЯжвЛИіздМКЕФЬНеыЃЈБШШч
Node ЕФЛђеп PHP ЕФЃЉЁЃЖјЧвЭХЖгЮЊСЫадФмПМТЧЪЙгУСЫ Thrift зїЮЊЪ§ОнДЋЪфавщБъзМЃЌБШЦ№
HTTP КЭ JSON ЖјбдФбЖШдіМгСЫВЛЩйЁЃ
4.6.6 ЩчЧјжЇГж
етвЛЕувВВЛБиЖрЫЕЃЌZipkin гЩ Twitter ПЊЗЂЃЌПЩвдЫуЕУЩЯЪЧУїаЧЭХЖгЃЌЖј
Naver ЕФЭХЖгжЛЪЧвЛИіФЌФЌЮоЮХЕФаЁЭХЖгЃЈДг #1759 ЕФЬжТлжаПЩвдПДГіЃЉЁЃЫфШЛЫЕетИіЯюФПдкЖЬЦкФкВЛЬЋПЩФмЯћЪЇЛђЭЃжЙИќаТЃЌЕЋБЯОЙВЛШчЧАепгУЦ№РДИќМгЗХаФЁЃ
ЖјЧвУЛгаИќЖрЩчЧјПЊЗЂГіРДЕФВхМўЃЌШУ Pinpoint жЛвРППЭХЖгздЩэЕФСІСПЭъГЩжюЖрПђМмЕФМЏГЩЪЕЪєРЇФбЃЌЖјЧвЫћУЧФПЧАЕФЙЄзїжиЕувРШЛЪЧдкЬсЩ§адФмКЭЮШЖЈадЩЯЁЃ
4.6.7 ЦфЫћ
Pinpoint дкЪЕЯжжЎГѕОЭПМТЧЕНСЫадФмЮЪЬтЃЌwww.naver.com
ЭјеОЕФКѓЖЫФГаЉЗўЮёУПЬьвЊДІРэГЌЙ§ 200 вкДЮЕФЧыЧѓЃЌвђДЫЫћУЧЛсбЁдё Thrift ЕФЖўНјжЦБфГЄБрТыИёЪНЁЂЖјЧвЪЙгУ
UDP зїЮЊДЋЪфСДТЗЃЌЭЌЪБдкДЋЕнГЃСПЕФЪБКђвВОЁСПЪЙгУЪ§ОнВЮПМзжЕфЃЌДЋЕнвЛИіЪ§зжЖјВЛЪЧжБНгДЋЕнзжЗћДЎЕШЕШЁЃетаЉгХЛЏвВдіМгСЫЯЕЭГЕФИДдгЖШЃКАќРЈЪЙгУ
Thrift НгПкЕФФбЖШЁЂUDP Ъ§ОнДЋЪфЕФЮЪЬтЁЂвдМАЪ§ОнГЃСПзжЕфЕФзЂВсЮЪЬтЕШЕШЁЃ
ЯрБШжЎЯТЃЌZipkin ЪЙгУЪьЯЄЕФ Restful НгПкМг JSONЃЌМИКѕУЛгаШЮКЮбЇЯАГЩБОКЭМЏГЩФбЖШЃЌжЛвЊжЊЕРЪ§ОнДЋЪфНсЙЙЃЌОЭПЩвдЧсвзЕФЮЊвЛИіаТЕФПђМмПЊЗЂГіЯргІЕФНгПкЁЃ
СэЭт Pinpoint ШБЗІеыЖдЧыЧѓЕФВЩбљФмСІЃЌЯдШЛдкДѓСїСПЕФЩњВњЛЗОГЯТЃЌВЛЬЋПЩФмНЋЫљгаЕФЧыЧѓШЋВПМЧТМЃЌетОЭвЊЧѓЖдЧыЧѓНјааВЩбљЃЌвдОіЖЈЪВУДбљЕФЧыЧѓЪЧЮвашвЊМЧТМЕФЁЃPinpoint
КЭ Brave ЖМжЇГжВЩбљАйЗжБШЃЌвВОЭЪЧАйЗжжЎЖрЩйЕФЧыЧѓЛсБЛМЧТМЯТРДЁЃЕЋЪЧЃЌГ§ДЫжЎЭт Brave ЛЙЬсЙЉСЫ
Sampler НгПкЃЌПЩвдздЖЈвхВЩбљВпТдЃЌгШЦфЪЧЕБНјаа A/B ВтЪдЕФЪБКђЃЌетбљЕФЙІФмОЭЗЧГЃгавтвхСЫЁЃ
4.6.8 змНс
ДгЖЬЦкФПБъРДПДЃЌPinpoint ШЗЪЕОпгабЙЕЙадЕФгХЪЦЃКЮоашЖдЯюФПДњТыНјааШЮКЮИФЖЏОЭПЩвдВПЪ№ЬНеыЁЂзЗзйЪ§ОнЯИСЃЛЏЕНЗНЗЈЕїгУМЖБ№ЁЂЙІФмЧПДѓЕФгУЛЇНчУцвдМАМИКѕБШНЯШЋУцЕФ
Java ПђМмжЇГжЁЃЕЋЪЧГЄдЖРДПДЃЌбЇЯА Pinpoint ЕФПЊЗЂНгПкЃЌвдМАЮДРДЮЊВЛЭЌЕФПђМмЪЕЯжНгПкЕФГЩБОЖМЛЙЪЧИіЮДжЊЪ§ЁЃ
ЯрЗДЃЌеЦЮе Brave ОЭЯрЖдШнвзЃЌЖјЧв Zipkin ЕФЩчЧјИќМгЧПДѓЃЌИќгаПЩФмдкЮДРДПЊЗЂГіИќЖрЕФНгПкЁЃдкзюЛЕЕФЧщПіЯТЃЌЮвУЧвВПЩвдздМКЭЈЙ§
AOP ЕФЗНЪНЬэМгЪЪКЯгкЮвУЧздМКЕФМрПиДњТыЃЌЖјВЂВЛашвЊв§ШыЬЋЖрЕФаТММЪѕКЭаТИХФюЁЃЖјЧвдкЮДРДвЕЮёЗЂЩњБфЛЏЕФЪБКђЃЌPinpoint
ЙйЗНЬсЙЉЕФБЈБэЪЧЗёФмТњзувЊЧѓвВВЛКУЫЕЃЌдіМгаТЕФБЈБэвВЛсДјРДВЛПЩвддЄВтЕФЙЄзїФбЖШКЭЙЄзїСПЁЃ
5 Tracing КЭ Monitor ЧјБ№
MonitorПЩЗжЮЊЯЕЭГМрПиКЭгІгУМрПиЁЃЯЕЭГМрПиБШШчCPUЃЌФкДцЃЌЭјТчЃЌДХХЬЕШЕШећЬхЕФЯЕЭГИКдиЕФЪ§ОнЃЌЯИЛЏПЩОпЬхЕНИїНјГЬЕФЯрЙиЪ§ОнЁЃетвЛРраХЯЂЪЧжБНгПЩвдДгЯЕЭГжаЕУЕНЕФЁЃгІгУМрПиашвЊгІгУЬсЙЉжЇГжЃЌБЉТЖСЫЯргІЕФЪ§ОнЁЃ
БШШчгІгУФкВПЧыЧѓЕФQPSЃЌЧыЧѓДІРэЕФбгЪБЃЌЧыЧѓДІРэЕФerrorЪ§ЃЌЯћЯЂЖгСаЕФЖгСаГЄЖШЃЌБРРЃЧщПіЃЌНјГЬРЌЛјЛиЪеаХЯЂЕШЕШЁЃMonitorжївЊФПБъЪЧЗЂЯжвьГЃЃЌМАЪББЈОЏЁЃ
TracingЕФЛљДЁКЭКЫаФЖМЪЧЕїгУСДЁЃЯрЙиЕФmetricДѓЖрЖМЪЧЮЇШЦЕїгУСДЗжЮіЕУЕНЕФЁЃTracingжївЊФПБъЪЧЯЕЭГЗжЮіЁЃЬсЧАевЕНЮЪЬтБШГіЯжЮЪЬтКѓдйШЅНтОіИќКУЁЃ
TracingКЭгІгУМЖЕФMonitorММЪѕеЛЩЯгаКмЖрЙВЭЌЕуЁЃЖМгаЪ§ОнЕФВЩМЏЃЌЗжЮіЃЌДцДЂКЭеЙЪНЁЃжЛЪЧОпЬхЪеМЏЕФЪ§ОнЮЌЖШВЛЭЌЃЌЗжЮіЙ§ГЬВЛвЛбљЁЃЃЈendЃЉ
|









