| 编辑推荐: |
魅族容器云平台主要是基于
k8s 的技术。将从以下六个方面介绍魅族容器云的实践过程,分别是基本介绍、k8s
集群、容器网络、外部访问4/7层负载均衡、监控/告警/日志、业务发布/镜像/多机房。
本文来自于csdn,由火龙果软件Anna编辑、推荐。 |
|
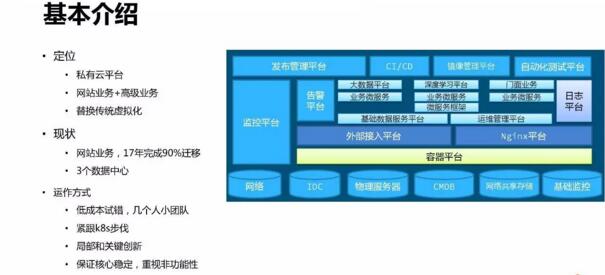
1、基本介绍
魅族云平台的定位是私有云平台,主要是用于支撑在线业务,用以替换传统的虚拟化方式。目前现状是2017年完成全国三个数据中心的建设,年内完成90%业务的迁移。
我们是以小团队紧跟 k8s 社区步伐,快速迭代、低成本试错的方式来构建我们的平台的。同时,针对一些我们遇到的问题,做一些局部创新,在保证系统核心的随社区稳定升级的前提下,解决好非功能性问题。
2、k8s 集群
对于 k8s 集群构建,将从 k8s 的单一镜像、k8s 集群 master、minion 三个方面分别展开介绍。
2.1 单一镜像

k8s 集群的安装部署是利用单一镜像 + docker run 实现一键安装。为此将所有 k8s
相关的描述文件、脚本和二进制全部打包成镜像,目的是实现集群的快速部署和升级。
2.2Master 
为了能够实现自动加载,k8s 集群核心组件使用了 Static Pod 方式。在自动修复方面,kubelet
probe 可以实现 Pod 的自检,配置了自动重启。如果需要对核心组件进行升级,指定统一镜像的版本号即可实现核心组件升级更新。
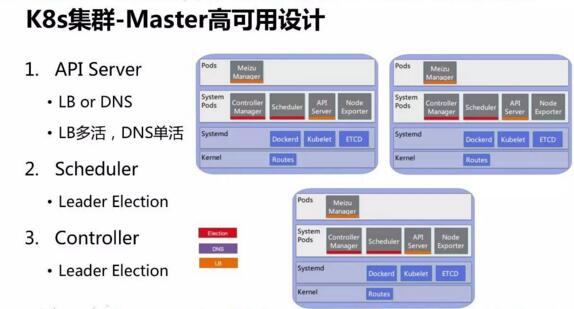
controller manager 和 scheduler 服务在三台物理机实现集群 master
高可用。API Server 的高可用既可以通过负载均衡方式实现,也能通过 DNS 方式实现。
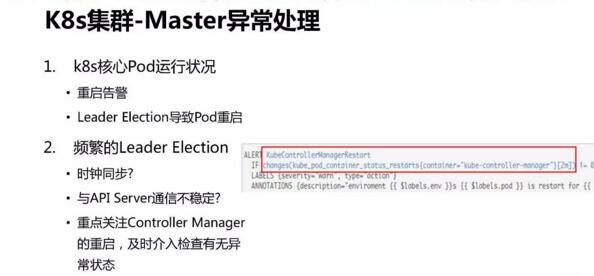
集群 controller mananger 重启可能会出现 Node 状态不同步的问题,因此对于核心组件状态,需要配置告警并及时检查有无异常状态。
2.3 minion
硬件方面并没有固定的配置,尽量利用现有的资源。在我们的集群中,常见 minion 的配置是 24核
CPU(with ht)、128GB 内存以及千兆网卡。

k8s 集群中 minion 作为计算节点,其上主要是各种业务的容器和 Systempods。
对于 minion 节点做了三个方面参数的优化,中断相关、TCPbacklog 和 swap。

minion 节点操作系统使用的是 centos 7,docker storage 使用的 devicemapper
driver,日志基本写到外挂的 EmptyDir volume,docker 存储使用得很少。
我们为 EmptyDir Volume 专门开辟了普通分区,没有使用 lvm,因为日志量不好预估,遭遇过因为
lvm metadata 的事故。

使用 Device Mapper 还遭遇过 kernel issue,因此需要更新内核。
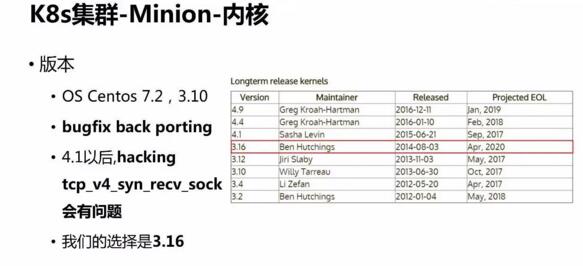
默认内核是3.10版本,长期维护的内核版本的是我们需要的。而且考虑到要对某些内核模块做 hacking,4.0及以上变化较大,hackingtcp_v4_syn_recv_sock
存在问题,所以我们最终选择了自行编译 3.16内核。
考虑到和 CMDB 的结合,minion 节点打上了 Label,例如标记它的功能是什么,物理位置信息,机柜等。这些信息对于
Pod 调度非常重要。包括 Pod 的 Node 亲和性,Pod 亲和性和反亲和性。
3、容器网络 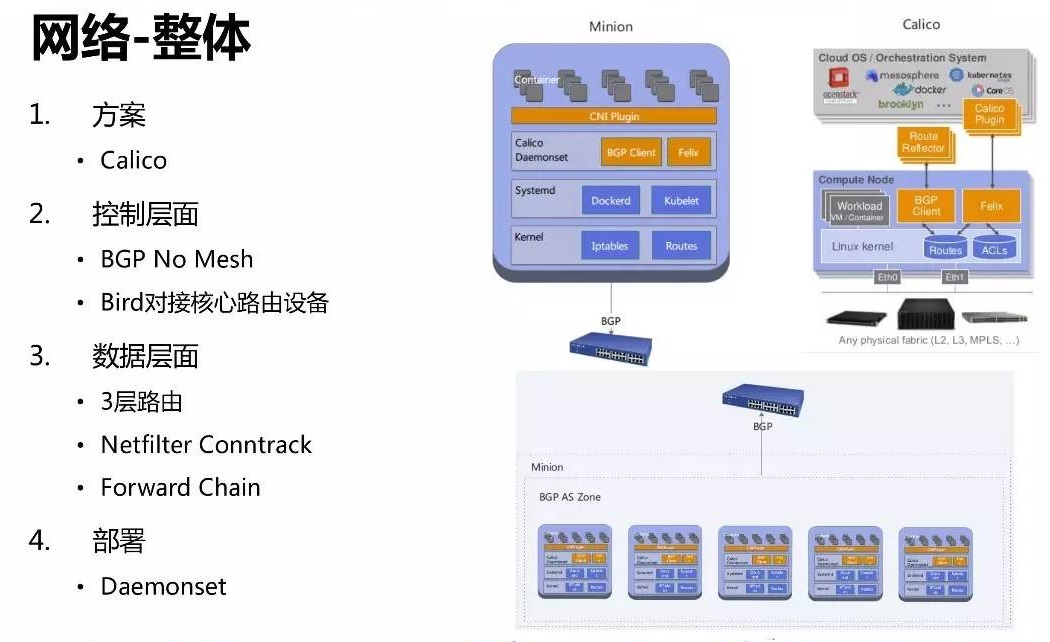
容器网络的方面我们采用的是 calico 的方案。主机通过 BGP 直接和核心路由设备对接,这里也可以用
RouteReflector 替代。
控制层面走 BGP,数据层面走三层路由。网络封包会经过主机的 netfilter框架,最后经由主机
forward chain 进入容器,默认都会被 conntrack。部署方面,Calico 通过
k8s 的 Daemonset 方式,部署非常方便

优化主要是针对 conntrack,建议尽量使用 headless service,少产生 iptables
rule。同时,对 conntrack 用量进行监控。容错方面,容器会主动去 ping 交换机,确保网络的连通性。当
calico 出现问题的时候,容器是不会加入服务的,由此来保证服务的可靠性。
对于我们系统,绝大部分流量来自外部 LVS,其可信任度高,默认的方式会产生大量的 conntrack
记录,所以应当把 LVS 过来的流量直接给 bypass conntrack。
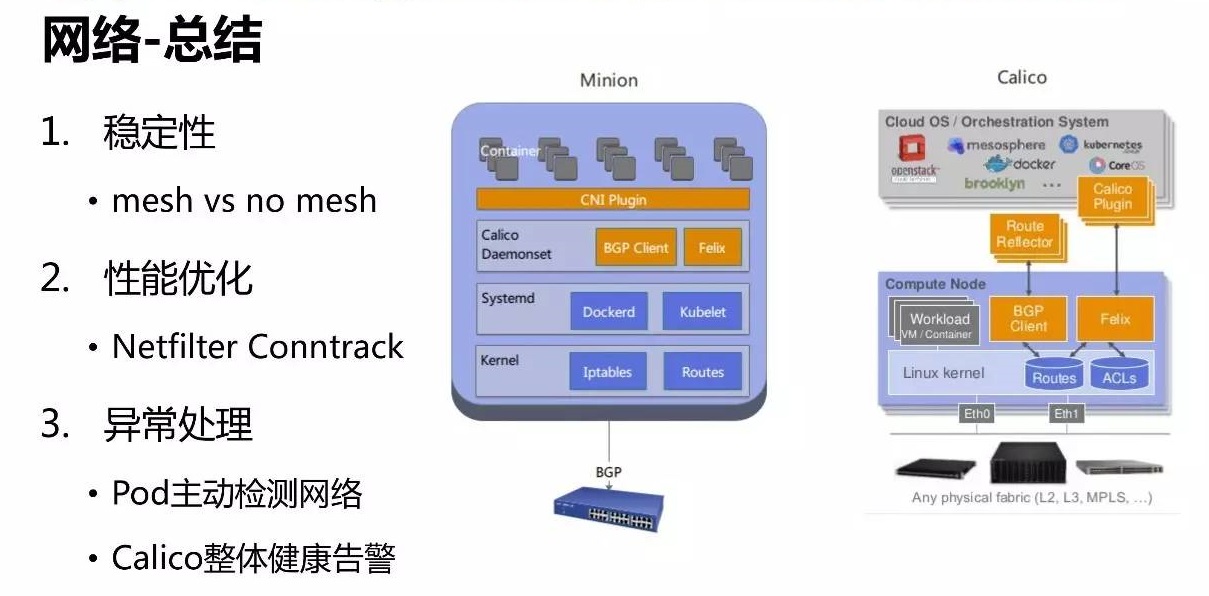
经过生产实践效果验证,no mesh 模式的稳定性要优于 mesh 模式。异常处理主要分为 POD
主动检测网络和 calico 的整体健康监控告警。
4、外部访问4/7层负载均衡
我们做的是对外服务,大部分流量都是从外部打进来的,终端用户都是外部的客户,所以针对外部的访问做了4层和7层的负载均衡。我们做的是对外服务,大部分流量都是从外部打进来的,终端用户都是外部的客户,所以针对外部的访问做了4层和7层的负载均衡。
在4层接入上采用了是阿里开源的 Fullnat LVS 方案,看中了它运维方便、水平扩展性好。工作在4层的
LVS 服务既可以支持 TCP 同时也支持 UDP,流量从client 端经过 LVS 做 Fullnat
后到达 minion,应答直接路由回对应的LVS。
对于4层负载均衡的配置,是通过自动化方式来实现的,无需人工配置,可以自动在路由设备宣告 vip,并生成对应的
ECMP 路由。LVS 的 VirtualServer 配置也是自动生成的,VirtualServer
到 EndPoint ip 的自动映射。
我们对 LVS 控制程序做了改造,暴露了一些指标,包括网络和应用服务相关的数据,并以此实现了 Grafana
可视化和监控告警。
一方面是对 LVS 整体流量异常告警,另一方面 realserver (Pod) 做高延迟异常检测告警。
七层负载均衡采用的是 POD 里面跑 nginx+ingress controller,它的定位是业务专属的反向代理,能够实现自动扩缩容,面向的
upstream 主要是 Jetty 业务容器。
由于四层负载均衡采用的是 FullnatLVS,真正的终端 ip 地址已经被隐藏起来了,需要从 TCPoption
中获取。realserver 默认取到的是 LVS 的 local ip 地址,需要使用 TOA 模块来获取终端
ip。
开源版本的 TOA 一直没有升级,为此我们将其移植到 3.16,对于大多数业务来说,客户端 ip
地址是不可或缺的。
在把 nginx 容器化之后,踩了一些坑,其中一个是延迟过高。从 access.log 看,upstream
的 RT 时间长达几秒,而直接访问 upstream Pod 服务又是很快的,说明是 nginx 的问题。经分析后发现配置不合理,nginx
容器化之后缺少对 worker 数量和亲和性的优化。
按照默认配置,一台24核 CPU 的机器上,对于一个业务的 nginx,自动配置为
24个 worker 进程,而 cpu limit 往往只设置成 5、6个核,worker 没有 cpu
资源导致高延迟。同时,调整 worker 进程的亲和性,防止压力堆积在前几个核上。
Nginx 动态缩容需考虑柔性,比如某业务原来有3个 Nginx 容器,现在要缩成2个,被停掉这个
Nginx 容器需要做一些优雅退出的准备工作,否则可能导致服务整体响应延迟陡增。
这个 POD 一开始就从 LB 上被摘掉了,我们利用 Pod 的 prestop hook,等待并优雅退出。
扩容时,需要考虑启动时间和热身问题。有的业务可能需要几秒或几十秒,要有充足的初始化时间,否则,请求过去就会失败。
如果 Probe Timeout 设置得比较小,会导致 Pod 被强制重启或者摘除,导致整体服务的雪崩。在实际运行过程中,应根据监控情况对
CPU request 和 Hpa 配置持续优化。
5、监控/告警/日志 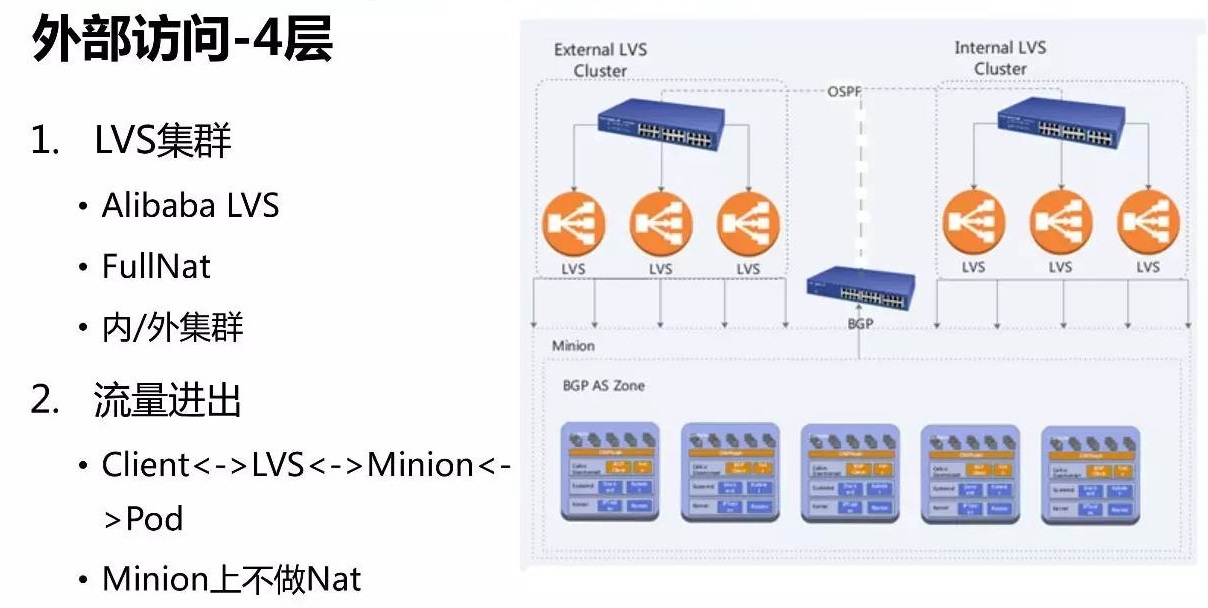
监控采用的是 prometheus,开箱即用的整体方案。部署方面是在 k8s 上部署成 Daemonsets
或者 Deployment,针对其特点会调度到特定的机型,通过类型拆分成几种 map 来方便管理。
监控指标包括两个方面,一个是硬指标,例如,从 nginx 获取当前业务的qps、http code
分布、当前整个业务的资源消耗情况以及后端的 jetty 消耗情况。
另一方面是业务的软指标,指的是内部指标,主要包括 jvm 的指标,内部的logger 相关,如 error
计数器。
日志的处理是收集到 elasticsearch 处理的。ES 的部署和 prometheus 类似也是
POD 的方式。部署 ES 的 datanode、master 和 client 需要关注线程数据和
CPU limit 的匹配问题。
日志收集容器试过使用 fluentd 进行收集,与业务容器共享一个存储,发现有日志滞后和资源消耗高的问题。用
filebeat 容器替代 fluentd 之后,资源占用率很小,消耗不到0.1核、内存不到 100M
就可以实现比较好的日志传输效果。
6、业务发布/镜像/多机房 
业务发布考虑到效率和交互性,需要给用户提供一个交互界面,能够生成 k8s的资源描述文件,并能执行具体的
Action,如创建/更新/删除。
实现上是通过 json schema 的方式来描述所有参数,默认值+结合用户输入最终生成 k8s
的资源描述文件。
利用 ansible 调用 kubectl 来实现自动化部署。实现了部署进度,发布历史管理,模板化部署。对于多集群管理,ansible
通过切换不同 k8s 集群的 context,发布业务到不同机房。
对于镜像的选择我们的原则就是够小、够用,为了保证兼容性我们加入 glibc 支持。Docker 其实推荐只跑一个进程,但很多业务都是需要多个进程配合的,S6
用于应对这种场景,作为进程和服务的管理器来实现一些比较复杂的功能。
总的来说,这是一套低成本的私有云实现方案,核心部分持续享受到 k8s 的红利,可以集中力量解决 4/7
层负载均衡及一些非功能性问题。同时,利用k8s核心系统的能力,快速构建外部支撑系统,如监控、告警、日志、发布系统等,在很大程度上提高了效率和可维护性。
|









