| 编辑推荐: |
文章主要介绍了嵌入式C语言开发中,如何通过合理组织数据(结构体封装、函数指针抽象、表驱动、链表/队列)来构建清晰、易维护的代码骨架,,希望对您的学习有所帮助。
本文来自于一枚嵌入式码农,由火龙果软件Alice编辑、推荐。
|
|
聊 C 语言在嵌入式领域的代码组织,绕不开一个现实问题:我们没有类、没有继承、没有现成的容器库,甚至连像样的命名空间都没有。工具就这么几样,但要维护的项目规模却不一定小——几万行几十万行的 C 代码项目比比皆是。
代码写着写着就变乱了,是很多嵌入式开发者共同的体会。函数越来越长,全局变量越来越多,模块之间的依赖像一团毛线。加新功能的时候得先花半天理清楚旧代码,改一个 bug 怕牵连出三个 bug。
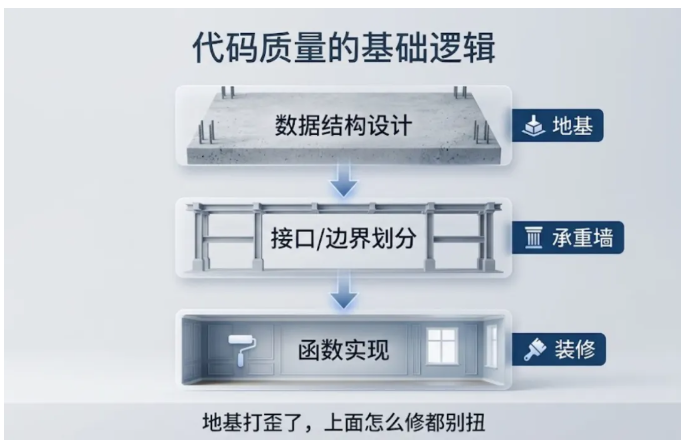
这种局面的根源,往往不在具体的语法或技巧上,而是在 用什么方式去组织数据 。数据结构决定了代码的骨架,骨架没搭对,肉再怎么堆都是变形的。
下面聊几个在嵌入式项目中非常实用的数据组织思路。
先说说什么样的代码算"好维护"
在讨论怎么组织之前,先对齐一个概念——好维护的代码到底长什么样?
在我看来,至少具备这三个特征:
- 改一处,影响范围可控 。比如增加一种新的传感器类型,只要在对应的模块内部加代码,不需要去修改调用方
- 读一段,能快速建立心智模型 。函数名、结构体字段名、模块边界一眼看过去能对得上逻辑
- 测一块,可以独立进行 。一个模块能不能单独跑起来、单独验证,而不需要把整个系统拖起来
这三条听起来是老生常谈,但真正做到的项目不多。而要做到这些,最关键的不是写好某一个函数,而是 把数据关系设计对 。
这也是为什么有经验的工程师在拿到一个需求时,往往先画 数据关系图 ,再写函数原型,最后才填实现。顺序一旦反了,很容易陷入"代码能跑但越跑越乱"的状态。
用结构体把"对象"封装起来
C 语言里没有类,但有结构体。结构体是我们在 C 中实现"面向对象"思想的最基础工具。
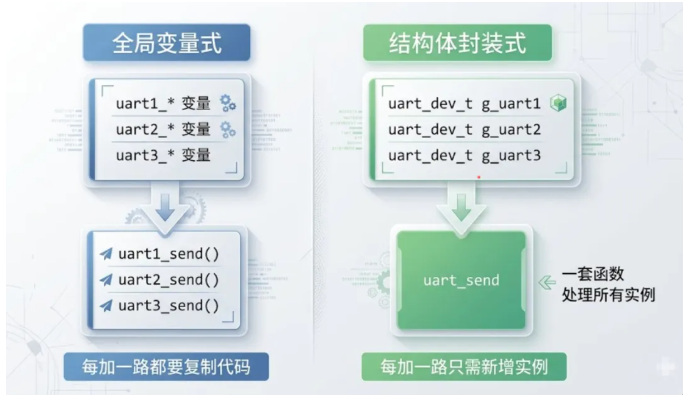
很多老项目里,会看到这种写法:一个模块把所有状态都摊成全局变量,函数之间通过这些全局变量互相传递信息。
// 典型的"全局变量综合征"
uint8_t uart1_tx_buf[256];
uint16_t uart1_tx_head;
uint16_t uart1_tx_tail;
uint8_t uart1_state;
uint32_t uart1_baud;
uint8_t uart2_tx_buf[256];
uint16_t uart2_tx_head;
uint16_t uart2_tx_tail;
// ... 同样的一套又来一遍
|
这种代码的问题在于,每加一路串口就要复制粘贴一遍,模块的状态跟实例强耦合,没办法抽象出统一的操作接口。
更好的写法是把"一个串口实例"作为一个对象抽象出来:
typedef struct {
uint8_t *tx_buf;
uint16_t tx_buf_size;
uint16_t tx_head;
uint16_t tx_tail;
uint8_t state;
uint32_t baud;
USART_TypeDef *hw; // 对应的硬件寄存器基址
} uart_dev_t;
static uart_dev_t g_uart1 = { .hw = USART1, .baud = 115200, /*...*/ };
static uart_dev_t g_uart2 = { .hw = USART2, .baud = 9600, /*...*/ };
void uart_send(uart_dev_t *dev, const uint8_t *data, uint16_t len);
void uart_recv(uart_dev_t *dev, uint8_t *buf, uint16_t len);
|
差别在哪?
右边的写法把"类型"和"实例"分离开, uart_dev_t 定义了串口设备这类东西长什么样,具体的实例则是数据。函数操作的是类型,通过传入不同实例来处理不同对象。这是 C 语言里最朴素也最有效的封装方式。
用函数指针把"行为"也抽象出来
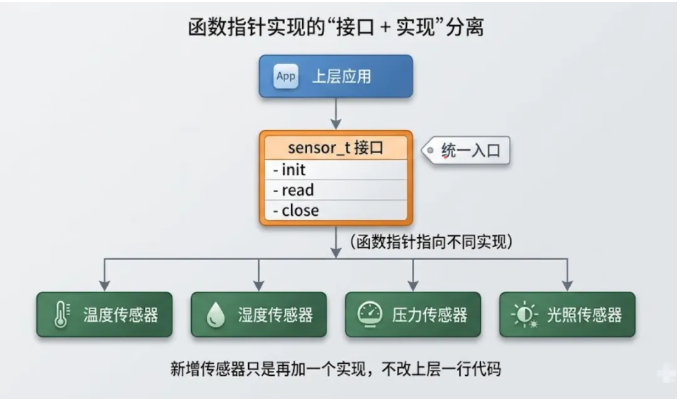
光有数据封装还不够。考虑一个更实际的场景:系统里有多种传感器——温度、湿度、压力、光照,它们的数据类型、采集周期、校准方式各不相同,但对上层来说都需要提供"初始化、读取、关闭"这样的统一接口。
如果用 if-else 或 switch-case 来区分,代码会变成这样:
void sensor_read(int type, void *data) {
switch (type) {
case SENSOR_TEMP: read_temp(data); break;
case SENSOR_HUMI: read_humidity(data); break;
case SENSOR_PRESSURE: read_pressure(data); break;
case SENSOR_LIGHT: read_light(data); break;
// 每加一种传感器,这里就要改一次
}
}
|
这种写法有个结构性问题: 上层代码要感知每一种传感器的存在 。新增传感器要改上层,删除传感器也要改上层,完全违背了"改一处,影响范围可控"的原则。
用函数指针就能优雅地解决:
typedef struct sensor sensor_t;
struct sensor {
const char *name;
int (*init)(sensor_t *self);
int (*read)(sensor_t *self, void *data);
int (*close)(sensor_t *self);
void *priv; // 各传感器私有数据
};
// 上层统一的调用方式
int sensor_read(sensor_t *s, void *data) {
return s->read(s, data);
}
|
每种具体传感器只要填充自己的那套函数就行,上层完全不关心下层的实现差异:
这种"结构体 + 函数指针"的组合,在 Linux 内核、各类 RTOS、很多开源嵌入式项目里都是标配套路。学会它,C 代码的可扩展性会直接上一个台阶。
用表驱动替代成堆的 if-else
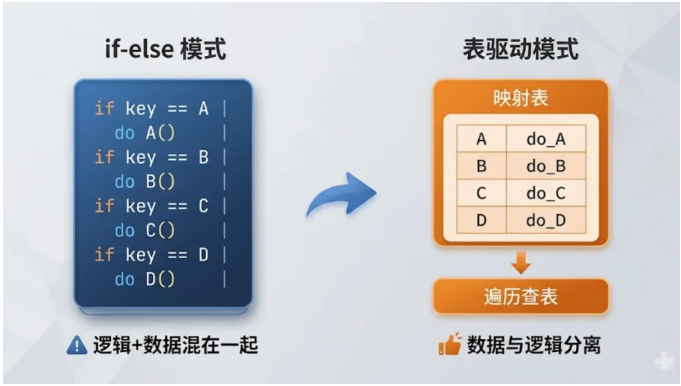
嵌入式代码里有大量"根据某个值做某件事"的逻辑:根据按键码调用对应处理函数,根据协议命令字解析不同报文,根据菜单索引跳转到不同界面……
初学者容易写成这样:
void on_key_pressed(uint8_t key) {
if (key == KEY_UP) menu_up();
else if (key == KEY_DOWN) menu_down();
else if (key == KEY_OK) menu_confirm();
else if (key == KEY_BACK) menu_back();
else if (key == KEY_MENU) menu_open();
// 按键越多,这里越长
}
|
问题不言自明——加一个按键就要加一行 if,代码膨胀的同时,还容易漏掉 break、漏掉 else、写错条件。
表驱动 的思路是把" 映射关系 "数据化:
typedef struct {
uint8_t key;
void (*handler)(void);
} key_map_t;
static const key_map_t key_table[] = {
{ KEY_UP, menu_up },
{ KEY_DOWN, menu_down },
{ KEY_OK, menu_confirm },
{ KEY_BACK, menu_back },
{ KEY_MENU, menu_open },
};
void on_key_pressed(uint8_t key) {
for (size_t i = 0; i < sizeof(key_table)/sizeof(key_table[0]); i++) {
if (key_table[i].key == key) {
key_table[i].handler();
return;
}
}
}
|
逻辑和数据彻底分离。新增按键只需要在表里加一行,处理函数归处理函数,映射关系归映射关系。而且这张表还可以放进 const 区,在资源紧张的 MCU 上省 RAM。
表驱动还有一个扩展应用—— 状态转移表 。当模块包含复杂的状态机逻辑时,把"当前状态 + 事件 → 下一状态 + 动作"的映射做成一张表,代码会比一堆嵌套 switch 清晰得多:
typedef struct {
state_t cur_state;
event_t event;
state_t next_state;
void (*action)(void);
} transition_t;
static const transition_t fsm_table[] = {
{ STATE_IDLE, EVT_START, STATE_RUNNING, start_motor },
{ STATE_RUNNING, EVT_STOP, STATE_IDLE, stop_motor },
{ STATE_RUNNING, EVT_ERROR, STATE_FAULT, report_fault },
{ STATE_FAULT, EVT_RESET, STATE_IDLE, reset_system },
};
|
整个状态机的行为一目了然,review 代码、写文档、画状态图都方便。
用链表和队列让数据流动起来
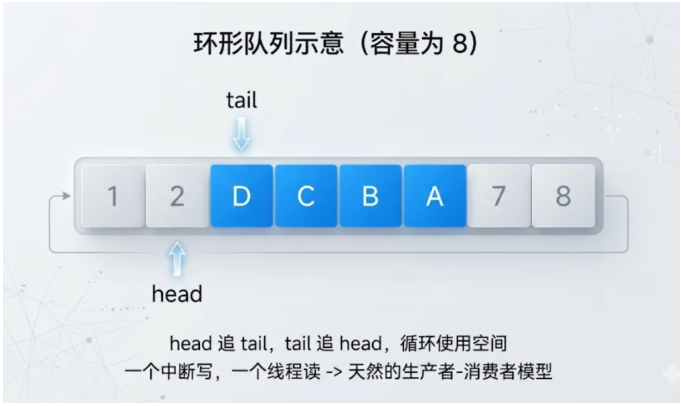
除了封装静态的"对象",嵌入式系统还经常要处理 流动的数据 :串口接收到的字符、定时触发的事件、待发送的网络报文。这类场景里,链表和环形队列是两种最常用的数据结构。
环形队列 适合固定容量、高频读写的场景。典型用法是串口收发缓冲:中断里往队列尾部写,主循环从队列头部读,两者各操作各的指针,不会互相干扰。
链表 适合容量不固定、插入删除频繁的场景。比如系统中注册的定时器、待处理的事件、动态加入的设备。
合理选用这两种结构,能让很多看起来复杂的异步逻辑变得非常简洁。
提炼一下:维护性代码的三条准则
把前面几节的做法收束一下,可以提炼出三条简单的准则:
1. 数据在前,函数在后
想清楚要处理哪些数据、数据之间是什么关系,再去想函数怎么写。结构体字段就是模块的内部状态,把状态定义清楚了,函数基本就是围绕这些字段做操作。
2. 用"数据 + 函数指针"表达变化点
凡是未来可能扩展的地方(更多设备、更多协议、更多策略),都用结构体 + 函数指针的方式留出接口。避免用 switch-case 把变化点硬编码在上层。
3. 把逻辑尽量变成"查表"
能用表表达的映射关系,不要写成 if-else 链。查表代码稳定、可读、易扩展,还方便做静态校验和文档化。
这三条看起来朴素,但做到的话,代码品质会比大多数项目高一大截。
然而,数据结构只是起点
写到这里,其实还有一个更深层的问题需要摆出来。
数据结构是代码的骨架,能解决"代码怎么组织得有条理"的问题。但随着项目规模变大,你会遇到一些数据结构本身答不上来的问题:
- 同一类设备有多种创建方式,该怎么统一管理?
- 一个事件需要通知好几个模块响应,该怎么解耦?
- 复杂的业务流程如何清晰地表达出来?
- 多个模块要共享一块资源,怎么协调访问?
这些问题的本质,是 怎么组织数据结构之间的协作方式 。单个结构体设计得再好,一旦涉及多个模块的配合,就需要更高层次的组织思路。
这就是 设计模式 真正的价值所在。
工厂模式、单例模式、 观察者模式 、状态模式、命令模式……这些模式不是什么玄乎的东西,它们是前人把"数据结构之间怎么协作"这个问题做成了标准答案。每一个模式,都对应着一类典型的模块协作场景。
而且不要被"设计模式是面向对象语言的专属"这种说法误导。C 语言完全可以实现这些模式——事实上前面讲的"结构体 + 函数指针"实现传感器抽象,本身就是 策略模式 + 工厂模式 的 C 语言版本。Linux 内核里的 file_operations 、FreeRTOS 中的任务调度、LVGL 里的对象系统,全都是 C 语言实现的设计模式实战范例。
对嵌入式工程师来说,学习设计模式的回报是非常直接的:你会发现很多平时头疼的架构问题,其实早有成熟的套路;你会在阅读开源项目源码时豁然开朗;你会在写新模块时自然而然地想到"这个地方用 XX 模式更合适"。
更重要的是,设计模式会反过来提升你对数据结构的理解——因为你开始从"整个系统怎么协作"的视角来看待每一个结构体的定义。
| 





 订阅
订阅