编辑推荐:
文章主要介绍了嵌入式系统中从轮询到事件驱动的架构演进,重点讲解了回调函数的三要素、事件分发中心的实现,以及回调使用中的常见陷阱与对应的设计模式,希望对您的学习有所帮助。
先看一段很多嵌入式入门者都写过的代码:
while ( 1 ) { if (key_pressed()) handle_key(); if (uart_has_data()) handle_uart(); if (timer_expired()) handle_timer(); if (sensor_ready()) handle_sensor(); // ... 不断加新的 if }
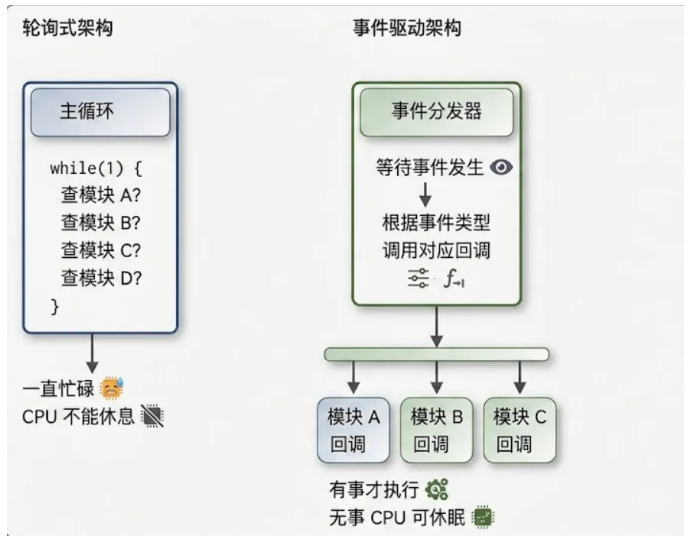
这种超级循环加轮询的写法,在功能少、时序简单的场合完全够用。但只要模块稍微多一点、响应实时性要求稍微高一点,问题就暴露出来:主循环越来越长,某个模块处理稍慢就拖累全局,想加一个新功能得改主循环、想删一个旧功能还是得改主循环。
事件驱动架构提供了另一种思路——不让 CPU 反复去"问"每个模块"你有事吗",而是让模块在有事的时候 主动告诉框架 ,然后框架去调用对应的处理函数。这里的"主动告诉",在 C 语言里就是通过 回调函数 实现的。
回调函数在嵌入式开发中的地位,类似于面向对象语言里的方法调用——看似只是个小语法特性,但用好了能重塑整个系统的架构。这篇文章就把回调从基础到进阶的完整图景梳理清楚。
先对比一下两种风格
下面这张图把两种架构的差别画得很直白:
事件驱动的核心好处有三个:
1. CPU 利用率高 ——没事可以进低功耗模式,由中断/事件唤醒
2. 模块解耦 ——模块 A 触发事件时不需要知道谁来处理
3. 扩展性好 ——新增模块不需要动主循环,只要注册自己的回调
这三条放在资源受限又要求长时间稳定运行的嵌入式系统上,价值非常直接。
回调函数:不只是传个函数指针
很多入门资料讲回调,就是一句"把函数当参数传进去"。这么说语法上没错,但错过了最重要的那层意思—— 控制反转 。
看这个例子:
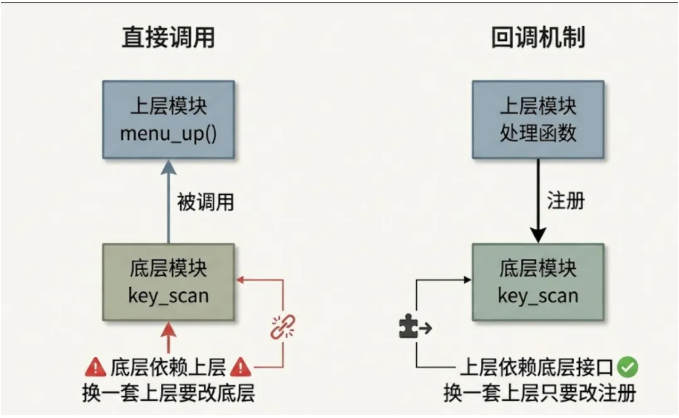
// 不用回调的按键处理 void key_scan ( void ) { uint8_t key = read_key_hw(); if (key == KEY_UP) menu_up(); else if (key == KEY_OK) menu_confirm(); // key_scan 要知道所有处理函数 }
这里 key_scan 直接调用了 menu_up / menu_confirm ,也就是说 底层扫描代码必须知道上层菜单模块的存在 。这是一种"从下往上"的硬依赖。
换成回调的写法:
// 用回调的按键处理 typedef void (* key_cb_t ) ( uint8_t key) ; static key_cb_t s_key_cb = NULL ; void key_register_callback ( key_cb_t cb) { s_key_cb = cb; } void key_scan ( void ) { uint8_t key = read_key_hw(); if (s_key_cb) s_key_cb(key); } // 上层使用 static void my_key_handler ( uint8_t key) { // ... 处理逻辑 } int main ( void ) { key_register_callback(my_key_handler); // ... }
key_scan 不再关心"谁来处理按键",它只管把按键事件抛出来。依赖方向变成了"上层依赖下层提供的注册接口",而不是"下层依赖上层的具体实现"。
用图来表达就是:
这种"控制反转"的思想,是回调函数真正的价值所在。它让底层模块变得"可复用"——同一套按键扫描代码,配不同的回调就能服务完全不同的应用场景。
回调的三要素
写过一阵子回调之后,你会发现一个成熟的回调接口通常包含三部分:
1. 函数指针本身
这是最直白的部分——被回调的函数长什么样(参数、返回值)。设计时要想清楚参数,改起来很麻烦。
2. 用户数据(context / user_data)
这是新手最容易忽略的一点。比如定时器到期回调,可能有好几个定时器都用同一个回调函数,回调函数怎么知道"这次是哪个定时器触发的"?答案是在注册时附带一个 void *user_data ,回调时原样传回:
typedef void (* timer_cb_t ) ( void *user_data) ; void timer_register ( uint32_t period, timer_cb_t cb, void *user_data) ; // 使用时 static my_context_t ctx1 = { .id = 1 , /*...*/ }; static my_context_t ctx2 = { .id = 2 , /*...*/ }; timer_register( 1000 , on_timer, &ctx1); timer_register( 2000 , on_timer, &ctx2); // 回调里通过 user_data 区分 static void on_timer ( void *user_data) { my_context_t *ctx = ( my_context_t *)user_data; // 根据 ctx->id 做不同处理 }
user_data 把"谁订阅的这个事件"的信息带回来,避免了一堆全局变量或者多个回调函数。
3. 触发时机与上下文
回调到底在什么地方被调用?是在中断里,还是在主循环,还是在某个任务里?这决定了回调函数能做什么、不能做什么。后面讲陷阱的时候会详细展开。
从单一回调到事件分发中心
单一回调解决的是"一对一"的问题——一个事件源,一个处理者。但实际系统里经常是"一对多":同一个事件,可能有多个模块都想响应。
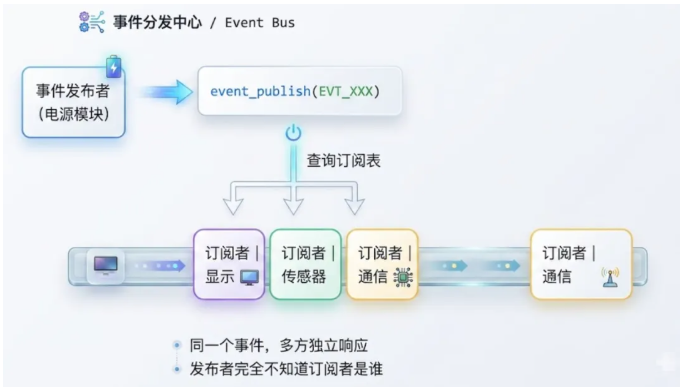
比如系统进入低功耗前,显示模块要关屏、传感器模块要停止采样、通信模块要完成数据上报。如果还是老办法——每个模块单独注册一个回调,而电源模块只支持一个回调——那就只能把所有模块的响应代码揉到一个回调函数里。这违背了模块化的初衷。
更好的做法是引入一个 事件分发中心 (也叫事件总线):
事件分发中心的核心数据结构其实很简单——一张"事件类型 → 订阅者链表"的映射表:
typedef void (* event_cb_t ) ( uint32_t evt_id, void *payload, void *user_data) ; typedef struct subscriber { event_cb_t cb; void *user_data; struct subscriber * next ; } subscriber_t ; static subscriber_t *s_subscribers[EVT_MAX]; int event_subscribe ( uint32_t evt_id, event_cb_t cb, void *user_data) { subscriber_t *s = malloc ( sizeof (*s)); s->cb = cb; s->user_data = user_data; s->next = s_subscribers[evt_id]; s_subscribers[evt_id] = s; return 0 ; } void event_publish ( uint32_t evt_id, void *payload) { subscriber_t *s = s_subscribers[evt_id]; while (s) { s->cb(evt_id, payload, s->user_data); s = s->next; } }
有了这个分发中心,模块之间就完全解耦了。电源模块只负责 event_publish(EVT_SUSPEND, NULL) ,谁爱订阅谁订阅,跟发布者毫无关系。
这其实就是 观察者模式
回调用好了是利器,用不好全是坑
回调用在嵌入式里,有几个经典的坑需要提前知道。
坑一:在中断里直接调用用户回调
这是最危险的一个。如果你的回调是在中断服务程序(ISR)里被调用的,那回调函数就继承了 ISR 的所有限制:不能阻塞、不能调用非中断安全的 API、不能占用太长时间。
而框架的使用者写回调时,通常意识不到这一点——他们可能在回调里调用 printf 、申请内存、拿互斥锁,然后系统莫名其妙就挂了。
稳妥的做法是 把中断事件投递到一个队列,由专门的任务取出来再分发给回调 :
坑二:回调里再触发事件导致递归
回调 A 处理完后发出了事件 B,事件 B 的回调又发出事件 A……如果事件分发是同步递归调用的,很容易出现栈溢出或者逻辑死循环。解决思路还是把事件放队列,用异步分发替代同步回调。
坑三:生命周期不匹配
注册了回调,但回调里用到的对象已经被销毁了——这在动态场景中特别常见。一个模块退出前务必要反注册(unsubscribe)自己的回调,否则就会变成悬挂指针。
坑四:回调链无法优雅地中断
当多个订阅者都响应同一个事件时,某个订阅者想"拦截"这个事件不让后面的处理,怎么办?这需要设计回调的返回值语义,比如返回 STOP_PROPAGATION 就终止后续调用。很多框架在这方面都做了细致的约定。
这些坑没有一个是语法能帮你避开的,它们全是 设计层面的问题 。
回头看看,我们其实在实现设计模式
把前面讲的东西串起来看:
单个回调注册 → 策略模式 的基础形态
回调 + user_data → 函子(functor) 的 C 实现
多订阅者事件分发 → 观察者模式
"事件入队再处理"的异步分发 → 命令模式 + 生产者消费者
中断投递到任务处理 → 半同步半异步(Half-Sync/Half-Async)模式
事件驱动架构不是一个具体的技术,而是一系列设计模式的组合应用。当你真正用回调写过几个模块、踩过几次坑后,你会自然而然地意识到—— 自己做的每一个架构决定,其实前人都早已总结成了模式 。
这就是为什么我一直建议嵌入式工程师系统学习设计模式。不是要你能背出 GoF
而且设计模式学完之后,读开源代码的速度会快非常多——当你看到 Linux 内核里的 notifier_chain ,你会直接识别出这是观察者;看到 FreeRTOS 的 xQueue + xTimer ,你会直接看出里面的生产者消费者和命令模式。代码的结构在你眼里不再是一堆函数指针的迷宫,而是清晰的模式组合。






 订阅
订阅