| 编辑推荐: |
本文主要介绍了嵌入式代码复用的几条核心思路相关内容。希望对您的学习有所帮助。
本文来自于微信公众号一枚嵌入式码农,由火龙果软件Alice编辑、推荐。
|
|
写嵌入式久了的工程师,大概率都干过这种事:换了一个项目,发现 UART
收发、按键扫描、菜单切换、Flash 读写…… 这些两年前甚至两个月前就写过的东西,又得重写一遍。
不是写代码本身有多难,而是上次那一坨现在根本拿不出来:寄存器地址硬编码在业务函数里;数据结构和具体外设耦合得拆都拆不开,关键逻辑散落在四五个文件里,找出来已经比重写还费劲。
代码复用这件事,在嵌入式领域被反复谈,但很少有人讲得彻底。它不是"把函数封装好"这么轻巧的一句话,也不是装上
RTOS 就自动获得的副产品。它更像一种工程能力——是从写第一行代码起,就要在脑子里悬着的几条线。
下面这几条线,是我这些年踩坑踩出来、也看别人踩坑看出来的几个核心思路。它们之间不是并列关系,而是层层递进:架构先于设计、设计先于接口、接口先于实现,最后才是写代码时的克制。
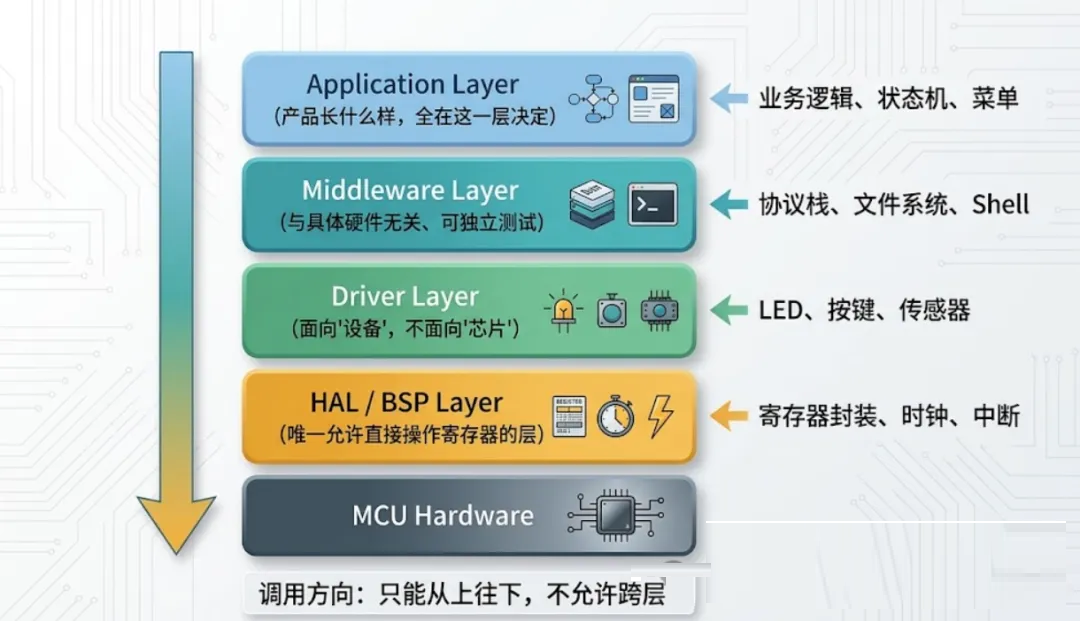
一、分层架构:复用的地基不是"封装",是"分层"
很多人理解的代码复用,是"把这段代码写成函数,下次拿来用"。这话没错,但停在函数层面,复用半径最多是几十行——下一个项目换了芯片、换了
OS,函数里那行 GPIOA->ODR |= (1<<5); 就让你前功尽弃。
真正能跨项目用的复用,得从分层开始。一个典型的嵌入式工程,应该长这样:
层与层之间只允许"从上往下调用",不允许跨层。Application 不能直接读写寄存器;Driver
不应该知道菜单是用 LCD 还是 OLED 显示的;HAL 更不能回头去调任何上层的函数。
这条规则看着像教科书原则,新项目刚开工时,所有人都同意。但只要 deadline 一近,跨层调用就开始悄悄出现:为了快点出
demo,工程师在应用层直接动了一下 GPIO,告诉自己"以后再优化";为了省一次回调,驱动层里塞了一个
printf 报错。这些"小事"日积月累,层次就模糊掉了。等下一个项目想拿这套代码用的时候才发现:HAL
改不动,因为驱动直接依赖了某个时钟寄存器;驱动也改不动,因为应用层早就跨过驱动直接戳寄存器了。
举个最小的例子——让一个 LED 闪烁。
不分层的写法,通常是这样:
while (1) {
GPIOA->ODR ^= (1 << 5);
HAL_Delay(500);
}
|
下次换芯片,这两行全得改。
分层以后,会变成:
// HAL 层:只管寄存器
void hal_gpio_toggle(gpio_port_t port, uint8_t pin);
// 驱动层:面向"LED"这个抽象概念
void led_toggle(led_id_t id); // 内部维护 id -> port/pin 的映射
// 应用层:只关心业务
while (1) {
led_toggle(LED_STATUS);
delay_ms(500);
}
|
代码量是多了几行,但换回来的是:换 MCU 只动 HAL;改原理图只动驱动里的映射表;产品逻辑要改成"按下按键才闪烁",只动应用层。三个变化点彼此独立,这才是分层的真正意义——让变化被局限在一个层里,而不是穿透整个工程。
写下"分层"两个字很容易,真正难的是工程纪律:谁都不能在赶工的时候开口子。一旦开了,后面就守不住了。
二、硬件抽象:让代码不被一颗芯片绑死
很多人把 HAL 理解成"在原厂库上再包一层自己的函数",改个名叫 MY_GPIO_Init
就算完事。这种"包了等于没包"的封装,只是把代码拉长了,并没有获得真正的抽象。
真正的抽象,核心是让上层"不知道"下层用的是什么。接口要面向需求,而不是面向实现。
举个例子,UART 抽象。
错误的写法:
void my_uart_send(USART_TypeDef *uart, uint8_t *data, uint16_t len);
|
参数里直接出现了 USART_TypeDef——这是 STM32 HAL 库的类型。一旦换平台,这个接口签名就要改,所有调用者都得跟着改。
正确的写法:
typedef struct uart_dev uart_dev_t; // 不透明结构体
int uart_open (uart_dev_t *dev, const uart_config_t *cfg);
int uart_send (uart_dev_t *dev, const uint8_t *data, uint16_t len);
int uart_recv (uart_dev_t *dev, uint8_t *buf, uint16_t len, uint32_t timeout_ms);
void uart_close(uart_dev_t *dev);
|
uart_dev_t 内部是 STM32 的 USART 句柄、GD32 的外设、还是 Linux
的 tty,只有实现层知道。上层拿到的只是一个"UART 设备"的概念。
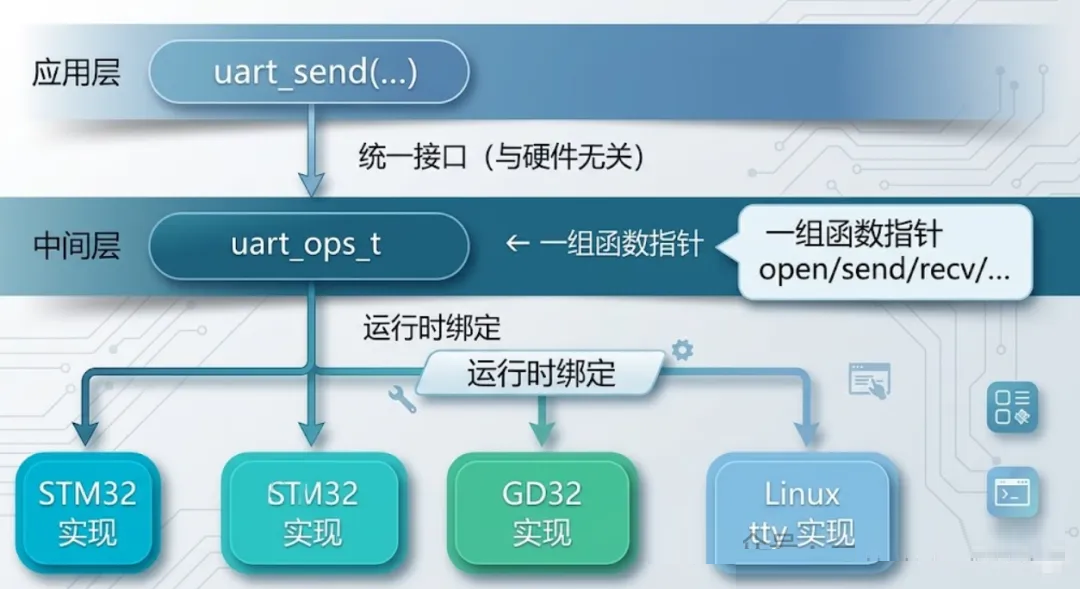
下面这张图把这种结构表达得更清楚:
中间这个 uart_ops_t 就是关键:
typedef struct {
int (*open) (uart_dev_t *, const uart_config_t *);
int (*send) (uart_dev_t *, const uint8_t *, uint16_t);
int (*recv) (uart_dev_t *, uint8_t *, uint16_t, uint32_t);
void (*close)(uart_dev_t *);
} uart_ops_t;
|
每一种芯片只要提供一份 uart_ops_t 实现,上层代码一行不动,就能跑在不同平台上。
这种"操作集 + 数据结构"的模式,本质上是 C 语言版的面向对象——Linux
内核里的 file_operations、block_device_operations 全都是这一路;FreeRTOS
移植靠的 port.c、Zephyr 的 device driver model,也是同一个思路。学这套模式的成本很低,带来的复用价值却很高。
抽象的另一面,是配置驱动。常见的抽象失败,是把"硬件相关的常量"散落在各个 .c
文件里:GPIOA、PA5、USART1 这些值,只要出现在驱动以外的代码里,就是一个移植障碍。
把它们提到一个 board.h(或者 device tree 风格的配置文件)里:
// boards/stm32f4_disco.h
#define LED_STATUS_PORT GPIOA
#define LED_STATUS_PIN 5
#define UART_LOG_INSTANCE USART1
#define UART_LOG_BAUDRATE 115200
|
// boards/gd32f1_demo.h
#define LED_STATUS_PORT GPIOB
#define LED_STATUS_PIN 2
#define UART_LOG_INSTANCE USART0
#define UART_LOG_BAUDRATE 115200
|
驱动代码不变,换板子只换一个头文件。
判断硬件抽象是否到位,有一个简单方法:把芯片型号关键字(比如 STM32、GD32)在整个工程里全局搜一遍,如果它出现在
driver/ 或 bsp/ 以外的任何文件里,就是抽象漏了。
还有一种很隐蔽的"假抽象"——HAL 函数里偷偷调用了业务逻辑。比如在 uart_send
的实现里加一句:
int uart_send(uart_dev_t *dev, const uint8_t *data, uint16_t len) {
if (in_test_mode) {
led_blink(); // ← 业务逻辑混进 HAL
}
return _hw_uart_write(dev, data, len);
}
|
看似只多了一行,但 HAL 从此和应用层绑死了。等下个项目要复用这段 UART 代码,会发现它还依赖一个叫
led_blink 的函数,以及一个叫 in_test_mode 的全局状态——整个调用链都拽了出来。
HAL 永远只该做硬件相关的事。任何业务逻辑应该通过回调、事件机制让上层自己决定——HAL 提供"发生了什么"的通知,业务层负责"怎么回应"。这条原则一旦守住,HAL
的可复用性就有了底。
三、模块化设计:单一职责,比"封装得好不好"更重要
分层解决"谁调用谁",模块化解决" 一个模块到底该装什么"。
判断一个模块是否合格,有一条很简单的标准:用一句话能说清它做什么吗? 如果描述它的时候你必须用"……以及……还有……",这个模块就大概率超载了,得拆。
举个例子,一个"按键模块"。
合格的描述:
不合格的描述:
扫描按键、过滤抖动、维护菜单状态、发送按键事件给
LCD 模块。 |
后者其实是三个模块的工作混在一起。菜单状态不该由按键模块维护——按键模块只该产生"按下、释放、长按"这种事件;状态机和
LCD 联动是应用层的事。
单一职责一旦做对,模块对外的接口自然就少。下面是一个合格的按键模块对外接口:
// key.h —— 只暴露最小必要的接口
typedef enum {
KEY_EVENT_PRESS,
KEY_EVENT_RELEASE,
KEY_EVENT_LONG_PRESS,
} key_event_t;
typedef void (*key_callback_t)(uint8_t key_id, key_event_t event);
void key_init(key_callback_t cb);
void key_scan(void); // 由 1ms tick 周期性调用
|
公开接口只有三个:一个枚举、一个回调签名、两个函数。其他所有东西——按键状态机、消抖计数器、长按阈值、键位映射表——全部封在
key.c 里,用 static 关键字挡住外部访问:
// key.c —— 外面看不到的内部细节
static uint8_t s_key_state[KEY_NUM];
static uint16_t s_debounce_cnt[KEY_NUM];
static key_callback_t s_user_cb;
static void handle_state_change(uint8_t id, uint8_t new_state);
static uint8_t read_raw_key(uint8_t id);
|
static 是 C 语言里实现 "private" 的唯一方式。只要严格用它把内部细节挡住,模块就有了真正的"边界"。
模块边界还有一个常被忽视的部分——头文件设计。一个合格的模块通常会有两份头文件:
• key.h:对外公开接口,放在 include/ 目录,任何用到本模块的代码都可以 #include。
• key_internal.h(可选):本模块内部多个 .c 文件共享的声明,只在模块内部 #include,绝不对外暴露。
这样做的好处是:即使你后来要把 key 模块拆成多个文件(比如分成 key.c 和 key_filter.c),对外接口也不变。外部依赖的是接口,不是文件——这一点很多工程师在头文件混着写的时候没意识到。
还有一个常见的坑:头文件里包含了不必要的 #include。key.h 如果 #include "led.h",那所有用按键的代码都被迫间接依赖了
LED 模块,完全没必要。公开头文件只 include 它"接口签名里用到"的类型——这条规则在大工程里能省下大量的编译时间和模块耦合。
边界画出来大概是这样:
实战里有一个更小的例子,几乎所有嵌入式项目都用得上——环形缓冲区。
不合格的写法:把 buffer、head、tail 全部声明为全局变量,在多个 .c 文件里直接读写:
uint8_t uart_buf[256];
uint16_t uart_head, uart_tail;
|
下个项目想再加一个环形缓冲区(比如给日志用),要么变量重命名,要么把整段逻辑复制一份。
合格的写法,封装成一个可实例化的数据结构:
typedef struct {
uint8_t *buf;
uint16_t size;
uint16_t head;
uint16_t tail;
} ring_t;
void ring_init (ring_t *r, uint8_t *buf, uint16_t size);
int ring_push (ring_t *r, uint8_t byte);
int ring_pop (ring_t *r, uint8_t *byte);
uint16_t ring_count(const ring_t *r);
|
要几个就实例化几个:UART 一个、日志一个、传感器缓冲再一个,互不干扰。这种"数据结构
+ 操作函数"是 C 工程里最朴素、也最强大的复用模式。Linux 内核、FreeRTOS、lwIP……全是这一套。
判断模块化做得好不好,有个简单粗暴的测试:把这个模块整个目录拷贝到另一个空工程里,它能不能编译过?
能,就是合格的模块;不能,说明它和当前工程之间还有看不见的耦合,继续切。
四、可移植性:不被编译器和字长坑死
前面三节都在讲架构和设计。但代码复用还有一个不那么显眼的对手——编译器和硬件平台的差异。一段在 STM32(Cortex-M)上跑得好好的代码,搬到
DSP、AVR、x86 仿真环境,可能因为字长、字节序、对齐、编译器扩展而直接崩。
第一条铁律:不要用 int、long、short 这种"长度不确定"的类型。它们的大小依赖编译器和平台。Cortex-M
上 int 是 4 字节,AVR 上是 2 字节,x86_64 上又是 4 字节。复用代码里出现一个
int counter,就埋了一颗雷。
正确做法是 #include <stdint.h>,用长度明确的类型:
uint8_t flag; // 一定是 1 字节
uint16_t counter; // 一定是 2 字节
int32_t signed_val; // 一定是 4 字节,有符号
|
布尔用 <stdbool.h> 提供的 bool,不要用 int 充当布尔。
第二条:不要假设字节序和对齐。下面这一行非常常见,也非常危险:
uint32_t value = *(uint32_t *)&buf[1];
|
在 x86 上能跑,在严格对齐的 Cortex-M0/M3 上、buf[1] 不是 4 字节对齐时直接
HardFault;ARM 大端模式下值还会错。
正确写法是字节逐个组装:
uint32_t value = ((uint32_t)buf[1])
| ((uint32_t)buf[2] << 8)
| ((uint32_t)buf[3] << 16)
| ((uint32_t)buf[4] << 24);
|
慢一点点,但任何平台都能跑。
第三条:条件编译有用,但用多了等于自己制造一团乱麻。这种代码大家都见过:
void send(const uint8_t *data, uint16_t len) {
#if defined(STM32F4)
HAL_UART_Transmit(&huart1, data, len, 100);
#elif defined(GD32F1)
gd_uart_send(USART0, data, len);
#elif defined(SIMULATOR)
fwrite(data, 1, len, stdout);
#endif
}
|
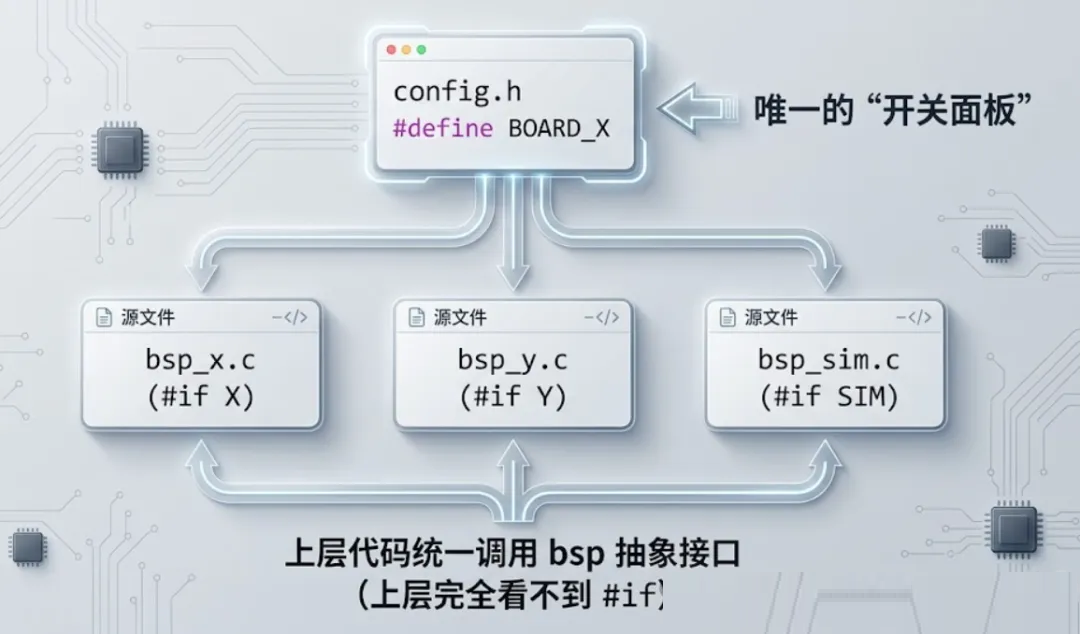
#if 一旦超过三层、跨多个文件,代码基本就读不下去了。条件编译应该集中在一处——通常是 port.c
或 bsp_xxx.c,根据 board.h 的宏选择对应实现。其他地方的代码应该看不见 #if。
整张图大致如下:
第四条:config.h 是项目的总开关。所有可调参数(缓冲区大小、任务栈、超时时间、功能开关)全部集中在一处:
// config.h
#define UART_RX_BUF_SIZE 128
#define KEY_LONG_PRESS_MS 1000
#define ENABLE_SHELL 1
#define ENABLE_LOG 1
|
模块代码里不应该出现"魔法数字",所有可配置值都通过 config.h 读入。移植或裁剪时只动这一个文件。
第五条:静态优先于动态。嵌入式平台不像 PC——malloc 失败、内存碎片化、释放后再用,任何一个都能让产品挂机。复用代码尽量用编译期分配的静态数组,把"上限"通过宏暴露给上层:
// 不推荐
ring_t *r = malloc(sizeof(ring_t));
// 推荐
static uint8_t s_uart_buf[UART_RX_BUF_SIZE];
static ring_t s_uart_ring;
ring_init(&s_uart_ring, s_uart_buf, UART_RX_BUF_SIZE);
|
可移植性这五条合起来,其实就一句话:让你的代码不依赖任何"恰巧"在当前平台为真的假设。
五、克制:不是所有东西都值得抽象
讲到这里,可能你已经摩拳擦掌想把项目里所有代码都"复用化"了。慢一点。
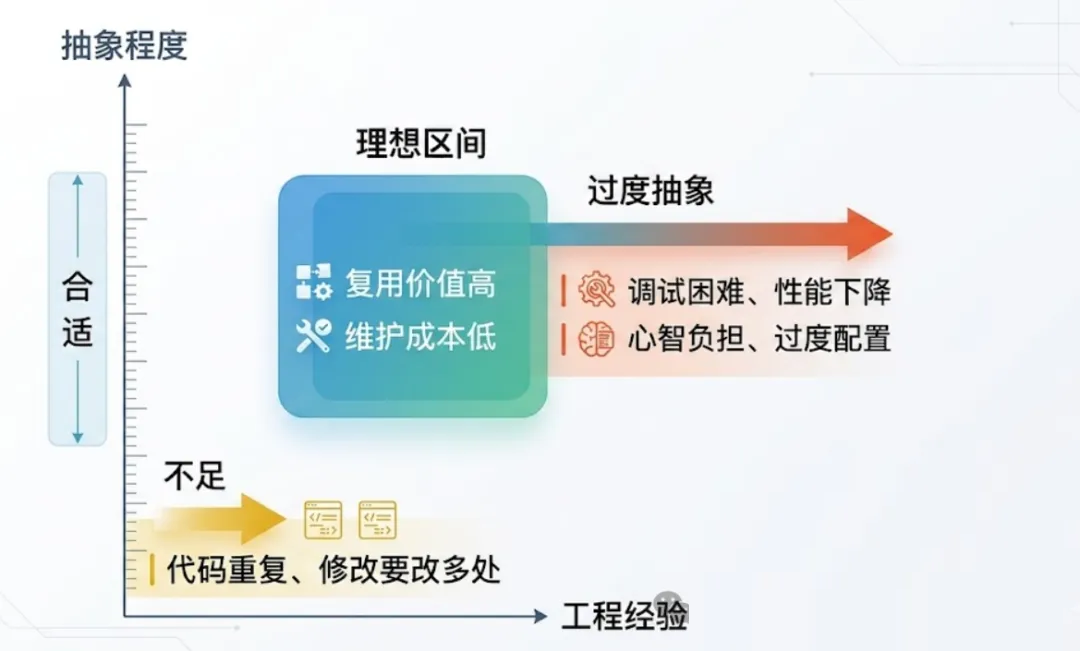
代码复用是手段,不是目的。过度抽象比没有抽象更糟糕,因为它的代价是隐性的。我见过的几个真实反例:
• 三层包装的 GPIO:app_led_toggle → bsp_led_toggle → hal_gpio_toggle
→ MCU_GPIO_Toggle。点亮一个引脚要跳四层函数,调试时寄存器视图和源码完全对不上,排查问题极其痛苦。
• 被过度配置化的 LED:为了"可配置",一个 LED 闪烁被设计成可配置周期、可配置占空比、可配置回调、可配置颜色——而这块板上只有一颗红色
LED。配置项比实现代码还长。
• 用宏模拟泛型:为了让一个链表"通用",写了一堆 #define LIST_DECLARE(type,
name) ...。同事在 gdb 里完全看不出这是什么类型,调试两行变量得猜半小时。
抽象的代价是真实的:多一层调用栈、多一次间接寻址、多一份脑力开销。所以抽象必须配得上它的代价。
我个人用一个反复实测过的标准来判断"是否值得抽象":它至少在第三个项目里被原样使用过。
第一次写、第二次有改动、到第三次能不改一行直接拿来——这时候才算真正复用上。在此之前,优先实现,不要优先抽象。
性能也是要考虑的一面。函数指针、回调、ops 表,在 Cortex-M 上每次调用多一次间接寻址,中断处理或
1µs 级别的循环里,这点开销可能就是致命的。这种场景下,直接用 static inline,或者干脆不抽象,反而是对的。复用不该和性能打架,真打架的时候,先让产品能用。
最后一条,最省力的复用方式其实是站在巨人的肩膀上:FreeRTOS、Zephyr、RT-Thread、lwIP、LittleFS、CMSIS-DSP、TinyUSB——这些东西已经被几十家芯片厂、上千个量产产品打磨过。能用别人的,就别再造一遍。但在用之前最好把它的设计读一遍——理解"人家为什么这么设计",比直接拿来用更值钱。读懂这些工程的分层、抽象、配置方式,等于把整套复用方法论免费拿到手。
抽象与不抽象之间的关系,可以用这张图来表达:
复用的甜区,永远在中间一段。
写在最后
回到开头那个问题:为什么换一个项目,UART、按键、菜单总要重写一遍?
不是因为这些东西难,而是上一次写的时候,没把"将来要拿来用"放进设计目标里。等真的要复用时,才发现处处是绊脚石。
代码复用是一个工程问题,不是一个技巧问题。它需要你在分层、抽象、模块化、可移植性这四件事上各做一点投入,再加一份克制——不为不需要的灵活性付出复杂度。
第一次写,要慢一点。看起来慢,但你写下去的不再只是一段功能,而是一份资产——下一次项目启动时,它会替你把时间还回来。
顺便聊聊
写到这里你可能也发现了,本文谈的「复用」拆开看是五个独立的点,合起来看,其实指向的是同一件事——嵌入式软件的架构设计。
很多嵌入式项目都是这样:前期功能写得飞快,后期却越来越难维护——模块互相调用、全局变量到处飞、协议和业务耦合、状态机一锅粥、RTOS
任务随手就拆、现场问题难以定位。这些问题的根源,通常不是某个函数没写好,而是项目从一开始就没把"架构"当作正经事来做。
复用只是其中一个切面。 | 






 订阅
订阅