| 编辑推荐: |
文章主要介绍了嵌入式系统中栈和堆的内存布局、常见故障原因(如栈溢出和堆碎片化),并提供了相应的工程实践与设计模式建议,以帮助开发者从根源上避免内存问题,希望对您的学习有所帮助。
本文来自于一枚嵌入式码农,由火龙果软件Alice编辑、推荐。
|
|
做嵌入式开发的朋友大概都有过这种经历:程序跑着跑着就莫名其妙挂了,看代码逻辑没问题,看外设配置也没问题,最后排查半天发现是内存出了状况。要么是 栈溢出 把别的变量给踩了,要么是堆用着用着申请不出来了。
这类问题之所以棘手,在于它往往不会立刻暴露。可能今天测试一切正常,明天换个场景就死机了。根源在于很多开发者对嵌入式系统的内存模型理解不够透彻——知道有栈和堆,但对它们具体怎么工作、什么情况下会出问题缺乏系统认知。
这篇文章就把这件事掰开了讲清楚。
嵌入式系统的内存布局
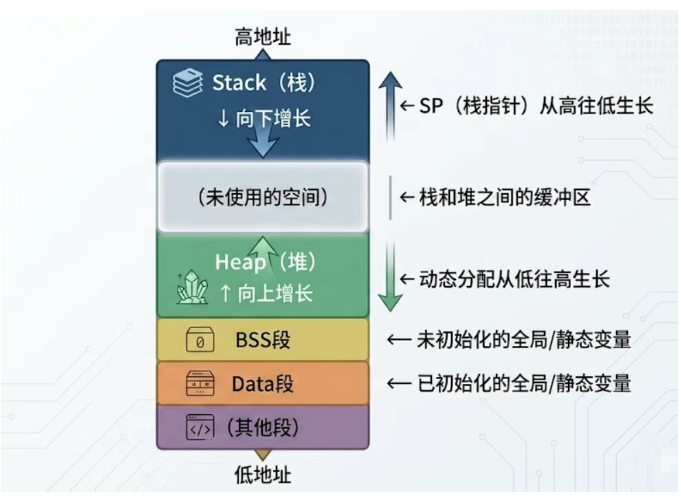
在聊具体问题之前,先搞清楚嵌入式系统(以常见的 Cortex-M 系列 MCU 为例)的 RAM 布局长什么样。一般来说,编译链接之后,RAM 里的东西是这样排列的:
关键点在于: 栈从高地址往下长,堆从低地址往上长 ,两者中间那段空间就是它们各自的"活动余量"。一旦某一方增长过快,就可能侵入对方领地,或者踩到不该踩的数据区域。
理解了这张图,后面的分析就有了根基。
栈:用起来最省心,出事也最隐蔽
栈是程序运行的"自动记账本"。每次函数调用,编译器自动在栈上开辟空间存放局部变量、函数参数和返回地址;函数执行完,这块空间自动释放。整个过程不需要开发者手动管理,干净利落。
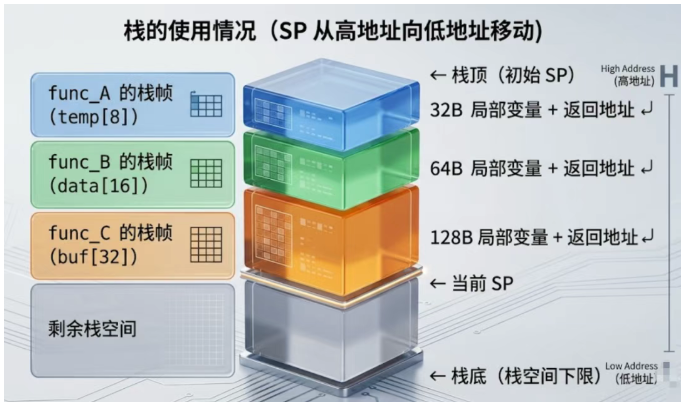
以一个简单的函数调用链为例:
void func_C(void) {
int buf[32]; // 128 字节局部变量
// ...
}
void func_B(void) {
int data[16]; // 64 字节局部变量
func_C();
}
void func_A(void) {
int temp[8]; // 32 字节局部变量
func_B();
}
|
调用过程中,栈的变化如下:
每嵌套调用一层,栈就往下"吃"一块。如果嵌套层次太深,或者某一层的局部变量太大, 栈指针 就可能越过栈空间的下限——这就是 栈溢出 。
栈溢出的典型原因
1. 函数内开了大数组
这是最常见的原因。在 PC 上写代码习惯了,随手 char buf[1024] ,在桌面端完全不是问题。但在 MCU 上,整个栈可能才 2KB 或 4KB,一个大数组直接就吃掉一半甚至全部。
void parse_packet(void) {
char buffer[512]; // 在 2KB 栈上,这一下就占了 25%
char decoded[512]; // 再来一个,直接 50% 没了
// ...
}
|
2. 递归调用层次不可控
递归本身不是问题,问题是在资源受限的嵌入式环境中,递归深度往往难以预测。特别是处理不确定长度的数据结构时,很容易失控。
// 危险:递归深度取决于链表长度,不可控
void process_list(node_t *p) {
if (p == NULL) return;
do_something(p);
process_list(p->next);
}
|
3. 中断嵌套
这是嵌入式场景特有的问题。每次中断触发都会压栈保存现场,如果多个中断嵌套触发,栈消耗会在很短时间内急剧增加。更麻烦的是,这种情况在测试中很难复现,往往要特定的时序条件才能触发。
栈溢出的表现
栈溢出之所以难排查,是因为它的表现五花八门:
- 程序跑飞,直接进 HardFault
- 全局变量莫名其妙被改了值(栈越界踩到了 BSS/Data 段)
- 某个功能时好时坏,呈现出"随机性"
- 中断处理偶尔异常
没有经验的话,很容易把这些现象往外设驱动或者业务逻辑上想,白白浪费大量排查时间。
堆:灵活的代价是不确定性
和栈的"自动管理"不同,堆是开发者主动申请、主动释放的内存区域。 malloc() / free() (或者 RTOS 中的 pvPortMalloc() / vPortFree() )操作的就是堆。
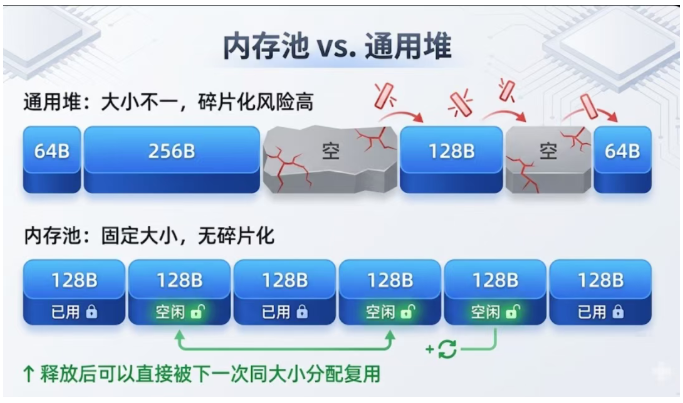
堆的优势是灵活——需要多少申请多少,不够了可以再要。但在嵌入式环境中,这种灵活性带来了一个严重的问题: 内存碎片化 。
碎片化是怎么产生的
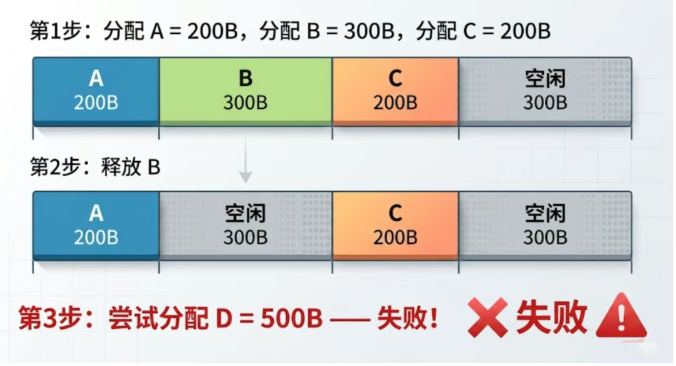
想象一下这个场景:你的系统有一块 1KB 的堆空间,程序按顺序做了这些操作:
明明总共有 600B 的空闲空间(300 + 300),但因为它们被 C 隔开了,没有连续的 500B 可以分配。这就是碎片化—— 空闲内存总量够用,但找不到足够大的连续块 。
碎片化的两种形态
准确来说,堆碎片分为两种:
外部碎片是大家比较熟悉的那种,也是危害最大的。内部碎片则是分配器实现机制导致的,通常可以通过合理的分配策略来减小。
碎片化在嵌入式上为什么尤其危险
在桌面或服务器环境中,操作系统有虚拟内存机制兜底,物理内存不连续没关系,MMU 可以通过页表映射成逻辑连续的地址空间。
但大多数 MCU 没有 MMU。你拿到的地址就是物理地址,内存是什么样就是什么样。碎片化了,没有任何机制帮你"收拾残局"。
而且嵌入式系统往往是长时间运行的——7x24 不关机的工业设备、医疗仪器、车载控制器。时间越长,频繁的 malloc / free 操作就越容易把堆搅成一盘散沙。可能跑个几天甚至几小时, malloc 就开始返回 NULL 了。
一个更真实的例子
比如一个嵌入式通信模块,每次收到数据包就动态分配一块缓冲区,处理完释放。数据包大小不固定——有时 64B,有时 256B,有时 128B。
void on_packet_received(uint8_t *data, size_t len) {
uint8_t *buf = (uint8_t *)malloc(len); // 大小每次不同
if (buf == NULL) {
// 分配失败——可能并不是内存真的用完了
error_handler();
return;
}
memcpy(buf, data, len);
process_packet(buf, len);
free(buf);
}
|
这段代码逻辑上没问题,每次都有 free ,不存在内存泄漏。但如果系统中还有其他模块也在做动态分配,不同大小的块交替申请释放,时间一长,堆就被"打碎"了。
工程实践:怎么防、怎么治
了解了原理,回到实际工程中。以下是一些经过验证的做法。
针对栈溢出
合理设置栈大小并监控使用量
链接脚本( .ld 文件)或 IDE 配置中都可以设置栈大小。不要拍脑袋随便给个值,而是结合最深调用路径做计算。很多 IDE(如 Keil、IAR)带有静态栈分析工具,可以辅助评估。
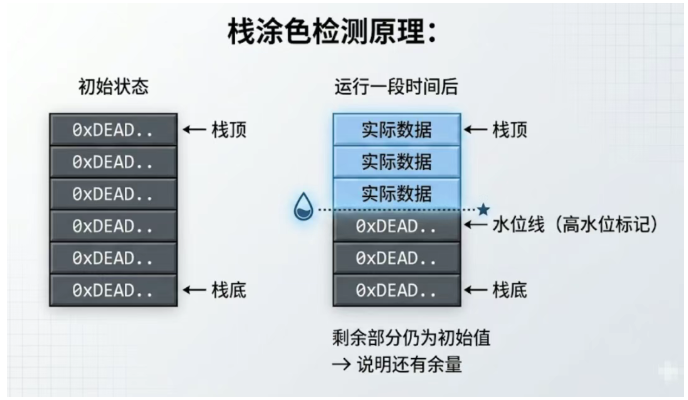
在 RTOS 环境中,可以用"栈涂色"(Stack Painting)技术监控栈的实际使用量——创建任务时用特定的模式值(比如 0xDEADBEEF )填充整个栈空间,运行一段时间后检查有多少被覆盖,就知道栈实际用了多少。
FreeRTOS 中的 uxTaskGetStackHighWaterMark() 就是基于这个原理实现的。
避免在函数内定义大数组
局部大数组是栈溢出的头号元凶。如果确实需要大缓冲区,用 static 修饰使其分配到 BSS /Data 段,或者改为全局变量、使用内存池。当然 static 局部变量意味着函数不可重入,在多任务环境中要考虑互斥。
递归改迭代
在嵌入式环境中,尽量把递归逻辑改写为迭代。如果业务上确实需要递归,务必限制最大深度。
针对堆碎片化
能不用堆就不用堆
这是嵌入式开发中的一条经验准则。很多编码规范(如 MISRA C)甚至直接禁止在安全关键系统中使用动态内存分配。能在编译期确定大小的,就用静态分配。
使用内存池(Memory Pool)替代通用堆
内存池的思路是:预先分配一组固定大小的内存块,需要时从池子里取,用完放回去。因为每块大小相同,不存在碎片问题。
FreeRTOS 提供了多种堆管理方案(heap_1 到 heap_5),其中 heap_4 支持合并相邻空闲块来减少碎片。如果你的应用场景中分配大小比较固定,可以考虑 heap_2 或自己实现专用内存池。
分区管理
如果系统中确实存在多种不同大小的分配需求,可以将堆划分为几个区域,每个区域服务于特定大小范围的请求。这样即使某个区域碎片化了,也不影响其他区域的分配。
从内存管理到代码架构:问题不止于技术细节
写到这里,其实可以停下来想一个问题:为什么同样是嵌入式开发,有的项目内存问题频出,有的项目却很少遇到?
抛开硬件资源差异不谈,很大程度上取决于 代码的组织方式 。
你会发现,内存问题往往不是孤立存在的——函数内开大数组,背后可能是模块划分不合理,该在上层管理的缓冲区被下放到了每个底层函数里;堆碎片化严重,背后可能是资源的申请和释放散落在各处,没有统一的生命周期管理;中断栈溢出,背后可能是中断处理函数承担了太多不该在中断里做的事情。
这些本质上都是 架构层面的问题 。
而解决架构问题,靠的不是逐个修补,而是系统化的设计思维。这正是 设计模式 发挥作用的地方——对象池模式可以从根源上解决堆碎片问题,观察者模式可以理清中断与业务逻辑的耦合, 状态机模式 可以让复杂流程的资源管理变得清晰可控。
设计模式不是 Java 或 C++ 的专利。在 C 语言主导的嵌入式领域,设计模式同样适用,甚至更加必要——因为语言本身提供的抽象能力有限,更需要开发者主动用设计思维去组织代码。
如果你在内存管理上踩过坑,不妨退后一步,从设计模式的角度重新审视自己的代码结构。很多时候,好的设计比好的调试技巧更能从根本上避免问题的发生。
| 





 订阅
订阅