| 编辑推荐: |
本文主要介绍了一个struct,从结构体在内存里的第一个字节开始,一路讲到怎么用它搭出可扩展的软件架构等相关内容,希望对您的学习有所帮助。
本文来自于微信公众号一枚嵌入式码农,由火龙果软件Alice编辑、推荐。
|
|
很多人觉得结构体没什么好讲的,不就是把几个变量打包在一起吗?说实话,我以前也这么想。直到有一次排查一个诡异的硬件通信Bug,折腾了两天,最后发现根源竟然是结构体的内存对齐问题——从那以后,我决定把结构体从头到尾搞透。
做嵌入式开发,结构体是你用得最多的数据组织方式,没有之一。寄存器映射、通信协议解析、驱动抽象层……到处都是它的身影。但多数人对它的理解,停留在"定义-赋值-传参"的层面,遇到稍复杂的场景就抓瞎。
这篇文章,我想从结构体在内存里的第一个字节开始,一路讲到怎么用它搭出可扩展的软件架构。不堆概念,每个知识点都配场景和图,争取让你看完之后对struct有一个立体的认知。
结构体在内存里长什么样?
先从最基本的问题开始:一个结构体变量,在内存里到底是怎么摆放的?
typedef struct {
uint8_t id;
uint32_t data;
uint16_t crc;
} Packet;
|
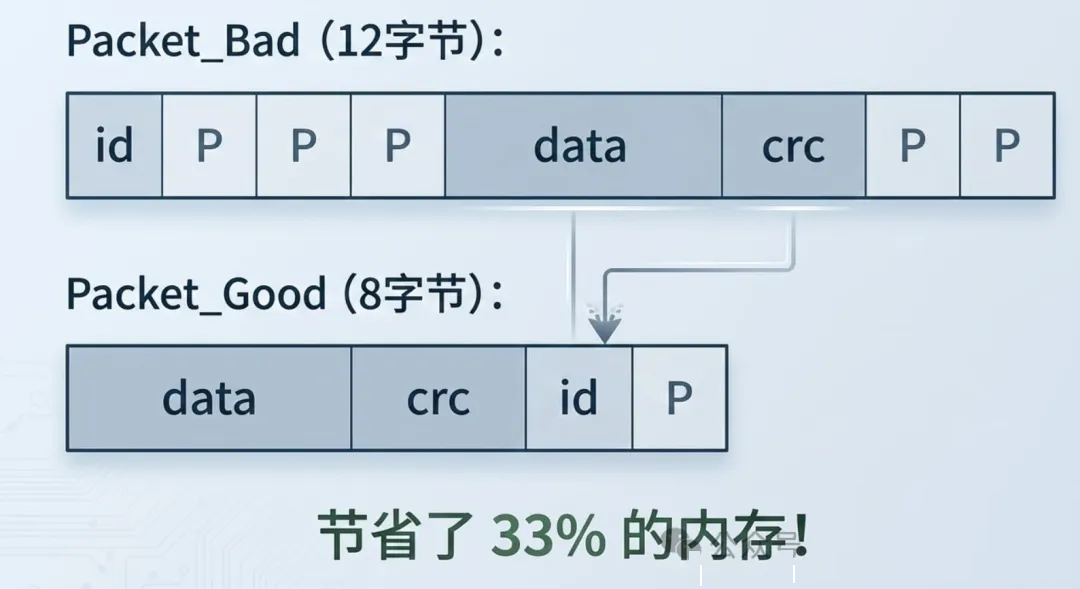
很多人的第一反应:1 + 4 + 2 = 7字节。但如果你真去sizeof一下,大概率是12字节。
多出来的5个字节去哪了?答案是编译器偷偷塞进去的填充字节(Padding)。来看它在内存里的真实布局:
为什么要这么干?因为CPU访问对齐地址的数据效率更高。在ARM Cortex-M系列上,访问一个4字节对齐的uint32_t只需要一次总线操作;如果地址没对齐,轻则多花一个时钟周期,重则直接触发Hard
Fault。
对齐规则和省内存的实战技巧
编译器的对齐规则其实不复杂,记住两条就够用:
规则1: 每个成员的起始地址,必须是自身大小的整数倍。uint32_t必须放在4的倍数地址上,uint16_t必须放在2的倍数地址上。
规则2: 整个结构体的大小,必须是最大成员大小的整数倍。
理解了规则,优化手段就很直观了——按成员大小从大到小排列:
// ❌ 浪费内存的写法
typedef struct {
uint8_t id; // 偏移0,后面填充3字节
uint32_t data; // 偏移4
uint16_t crc; // 偏移8,尾部填充2字节
} Packet_Bad; // sizeof = 12
// ✅ 紧凑的写法
typedef struct {
uint32_t data; // 偏移0
uint16_t crc; // 偏移4
uint8_t id; // 偏移6,尾部填充1字节
} Packet_Good; // sizeof = 8
|
内存对比图:
在一个只有几十KB RAM的MCU上,如果你有一个包含100个元素的数组,这种优化能省出400字节——可能刚好就是你跑不跑得动的区别。
强制取消对齐:__packed
有时候你就是需要结构体严格按定义的顺序、不带任何填充地排列,比如解析网络协议包。这时候可以用编译器扩展:
// GCC / Clang
typedef struct __attribute__((packed)) {
uint8_t type;
uint32_t seq;
uint16_t length;
} __attribute__((packed)) FrameHeader;
// sizeof = 7,没有任何填充
// Keil ARM Compiler
__packed typedef struct {
uint8_t type;
uint32_t seq;
uint16_t length;
} FrameHeader;
|
注意:packed结构体的成员地址可能不对齐,在ARM Cortex-M0等不支持非对齐访问的平台上,直接通过指针访问成员可能会触发异常。使用时务必确认你的目标平台。
|
位域——用结构体操作每一个bit
嵌入式开发绕不开寄存器操作。传统做法是位掩码+移位,写多了眼睛都花。位域(Bit-field)让你像访问普通成员一样操作单个bit。
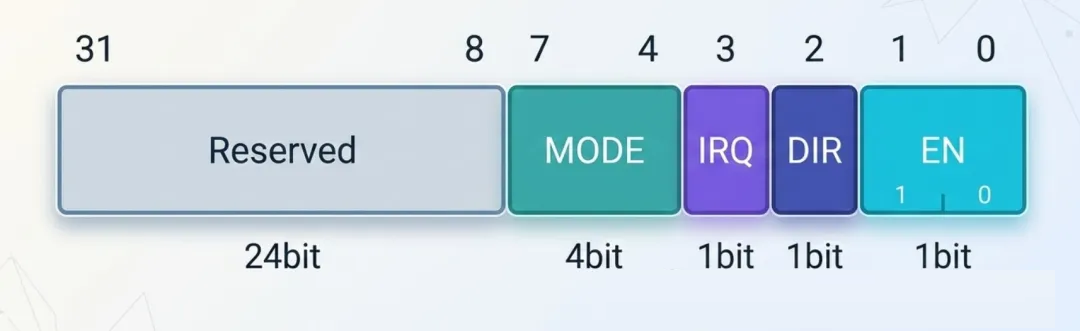
假设某个外设的控制寄存器长这样:
用位域定义:
typedef struct {
uint32_t enable : 1; // Bit 0
uint32_t dir : 1; // Bit 1
uint32_t irq_en : 1; // Bit 2
uint32_t reserved : 1; // Bit 3
uint32_t mode : 4; // Bit 4-7
uint32_t padding : 24; // Bit 8-31
} GPIO_CtrlReg;
|
操作起来非常直观:
|
volatile GPIO_CtrlReg *ctrl = (GPIO_CtrlReg *)0x40020000;
ctrl->enable = 1; // 使能外设
ctrl->mode = 0x05; // 设置模式
ctrl->irq_en = 1; // 开启中断
|
对比传统的位操作写法:
// 传统写法:可读性差
*reg |= (1 << 0); // 使能
*reg = (*reg & ~(0xF << 4)) | (0x05 << 4); // 设置模式
*reg |= (1 << 2); // 开中断
|
哪个更清晰,一目了然。
注意: 位域的内存排列顺序(MSB-first还是LSB-first)取决于编译器和平台。跨平台项目中慎用位域映射硬件寄存器,建议先在目标平台验证。
|
结构体指针——零拷贝协议解析
嵌入式通信场景下,一个很常见的需求是:串口/CAN/SPI收到一堆原始字节,怎么快速解析成有意义的数据?
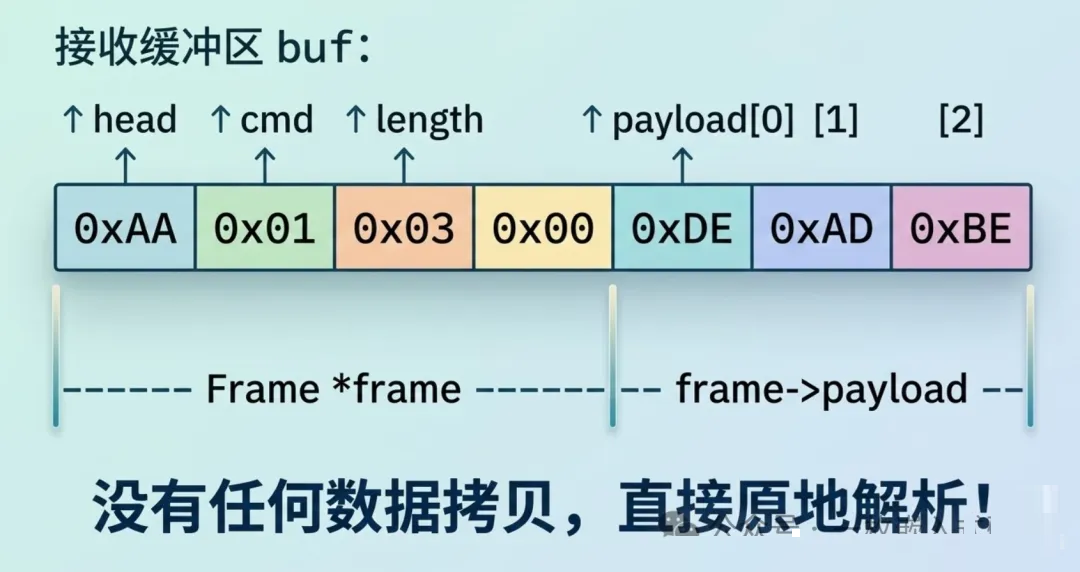
最笨的办法是一个字节一个字节去拼。聪明的做法是——把结构体指针直接"贴"到缓冲区上:
// 定义协议帧格式(packed确保无填充)
typedef struct __attribute__((packed)) {
uint8_t head; // 帧头 0xAA
uint8_t cmd; // 命令字
uint16_t length; // 数据长度
uint8_t payload[]; // 柔性数组,变长数据
} Frame;
|
解析过程只需要一次指针转换:
void on_data_received(uint8_t *buf, uint16_t len)
{
Frame *frame = (Frame *)buf; // 零拷贝,直接映射
if (frame->head != 0xAA)
return;
printf("命令: 0x%02X, 长度: %d\n", frame->cmd, frame->length);
process_payload(frame->payload, frame->length);
}
|
整个过程的内存示意:
这种零拷贝的思路在嵌入式里非常实用,特别是在RAM紧张或数据量大的场景下。很多开源协议栈(如lwIP)的底层实现,都大量使用了这个技巧。
结构体 + 函数指针 = C语言的"面向对象"
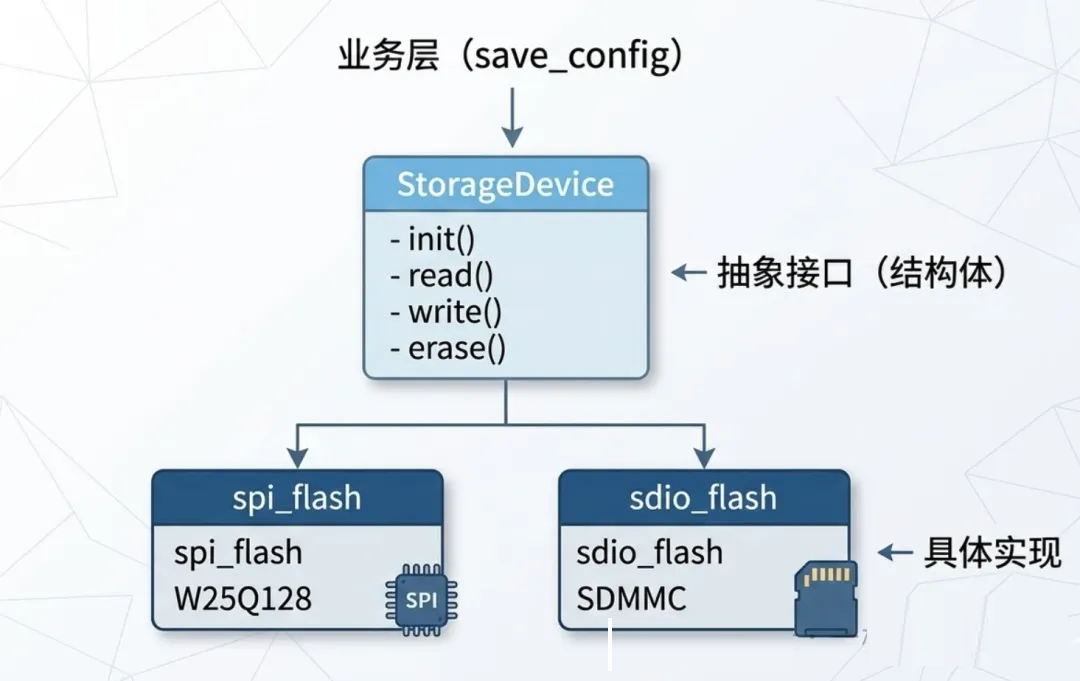
写到这里,结构体已经从一个存数据的容器,变成了操控硬件、解析协议的工具。但它的能力远不止于此。
嵌入式项目做大了之后,你一定会遇到这个问题:怎么让驱动层的代码可以被替换?比如你的产品同时支持SPI
Flash和SDIO Flash,业务逻辑一样,底层操作不同。
Linux内核给了我们答案——把函数指针塞进结构体,构造出"接口":
// 定义一个"存储设备"的抽象接口
// 定义一个"存储设备"的抽象接口
typedef struct {
const char *name;
int (*init)(void);
int (*read)(uint32_t addr, uint8_t *buf, uint32_t len);
int (*write)(uint32_t addr, const uint8_t *buf, uint32_t len);
int (*erase)(uint32_t addr, uint32_t len);
} StorageDevice;
|
然后不同的驱动各自实现:
// SPI Flash 驱动
static int spi_flash_init(void) { /* SPI初始化 */ }
static int spi_flash_read(...) { /* SPI读操作 */ }
static int spi_flash_write(...) { /* SPI写操作 */ }
static int spi_flash_erase(...) { /* SPI擦除 */ }
const StorageDevice spi_flash = {
.name = "W25Q128",
.init = spi_flash_init,
.read = spi_flash_read,
.write = spi_flash_write,
.erase = spi_flash_erase,
};
|
业务层完全不需要知道底层细节:
void save_config(const StorageDevice *dev, Config *cfg)
{
dev->erase(CFG_ADDR, sizeof(Config));
dev->write(CFG_ADDR, (uint8_t *)cfg, sizeof(Config));
}
// 调用时传入不同的设备,逻辑完全一致
save_config(&spi_flash, &my_config);
save_config(&sdio_flash, &my_config);
|
这就是用C语言实现多态的核心思路,也是Linux内核驱动框架的基本设计思想。整体架构如下:
当你能把结构体用到这个程度,写出来的代码和C++的虚函数表已经异曲同工了。
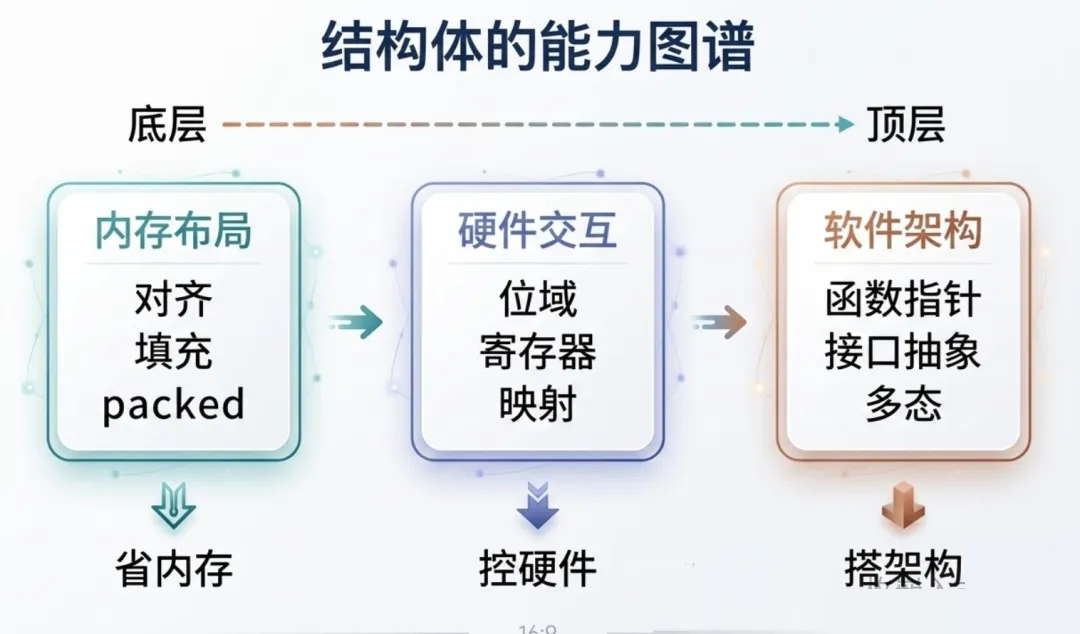
一张图看清结构体的能力边界
把上面讲的串起来,结构体在嵌入式开发里的能力图谱大概是这样的:
从存储布局到硬件操控再到架构设计,一个struct关键字,贯穿了嵌入式开发的各个层次。
写在最后
回过头看,结构体这东西,入门容易精通难。基础用法人人都会,但真正拉开差距的,是你能不能用它构建出清晰、可扩展的代码结构。
文章最后一节讲的"结构体+函数指针"实现接口抽象,其实只是冰山一角。在真实的嵌入式项目中,这种思路可以进一步演化出工厂模式、观察者模式、策略模式等设计模式——这些模式不是Java/C++的专利,C语言照样能玩得转,而且在资源受限的场景下,玩得还特别有味道。
如果你对这块感兴趣,推荐看看我之前整理的嵌入式C语言设计模式系列,里面用实际项目案例拆解了如何在MCU上用纯C写出高内聚低耦合的代码:
嵌入式C语言设计模式合集
把结构体用好是基本功,把设计模式用好才是内功。共勉。 | 






 订阅
订阅