| 编辑推荐: |
本文主要介绍了
Cache 的三种映射方式,及它们是如何在幕后为计算机的性能保驾护航的。 希望对您的学习有所帮助。
本文来自于微信公众号深度Linux,由火龙果软件Linda编辑、推荐。 |
|
在计算机的世界里,有一个神秘的存在,它默默地工作,却对计算机的性能起着至关重要的作用,它就是缓存(Cache)。Cache
就像是计算机的 “高速通道”,专门负责加速数据的读取,让计算机能够快速响应各种指令,极大地提升了运行效率。想象一下,CPU
就像是一位忙碌的大厨,它需要各种食材(数据)来烹饪出美味的 “程序大餐”。而主存则像是一个巨大的食材仓库,里面存放着各种各样的食材。但是,这个仓库太大了,大厨每次去取食材都要花费很长时间,这就大大降低了烹饪的效率。
这时,Cache 就登场了,它就像是大厨身边的一个小助手,会提前把一些常用的食材放在一个小篮子里(缓存),这样大厨需要的时候,就可以直接从小篮子里拿,而不用每次都跑去大仓库,大大节省了时间。Cache
之所以能够如此高效地工作,离不开它独特的映射方式。今天,我们就来深入探讨一下 Cache 的三种映射方式,揭开它们神秘的面纱,看看它们是如何在幕后为计算机的性能保驾护航的。
一、直接映射:简单直接的 “定位器”
直接映射是三种映射方式中最为简单直接的一种。它的映射规则就像是给每个主存块都分配了一个固定的 “座位”(缓存块),这个
“座位” 的确定方式是通过主存块号对缓存块数取模运算。
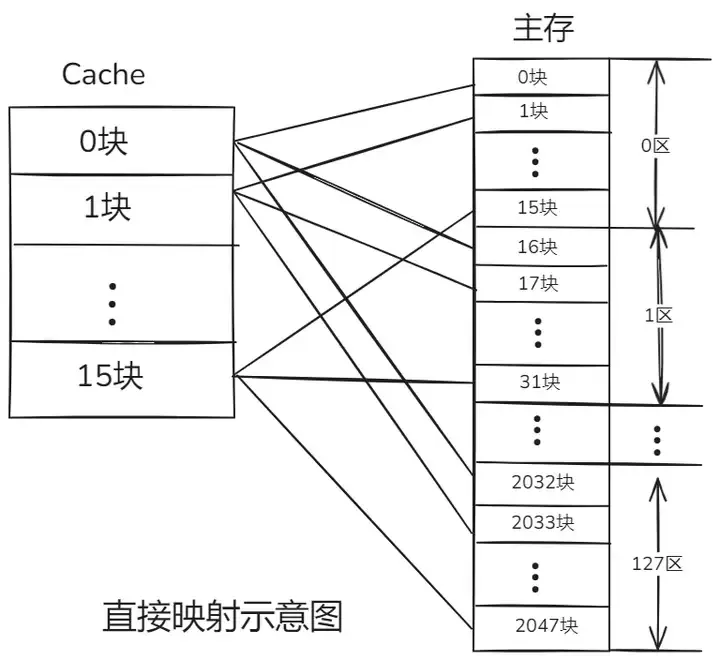
假设主存中有很多个数据块,编号从 0 开始依次递增,而缓存也被划分成了若干个缓存块。对于主存中的第
n 个数据块,它会被映射到缓存中的第(n % 缓存块数)个缓存块中。例如,如果缓存有 8 个缓存块,主存中的第
0 块、第 8 块、第 16 块…… 都会被映射到缓存的第 0 块;主存中的第 1 块、第 9 块、第
17 块…… 都会被映射到缓存的第 1 块,以此类推 。这种映射关系是固定且唯一的,每个主存块在缓存中都有且仅有一个对应的缓存块。
直接映射是最简单的地址映射方式,它的硬件简单,成本低,地址变换速度快,而且不涉及替换算法问题。但是这种方式不够灵活,Cache
的存储空间得不到充分利用,每个主存块只有一个固定位置可存放,容易产生冲突,使 Cache 效率下降,因此只适合大容量
Cache 采用。例如,如果一个程序需要重复引用主存中第 0 块与第 16 块,最好将主存第 0 块与第
16 块同时复制到 Cache 中,但由于它们都只能复制到 Cache 的第 0 块中去,即使 Cache
中别的存储空间空着也不能占用,因此这两个块会不断地交替装入 Cache 中,导致命中率降低。
1.1工作流程详解
当 CPU 需要访问某个数据时,它会首先根据数据的主存地址来判断该数据是否在缓存中。它会将主存地址分成几个部分,其中一部分用于确定缓存块的索引(也就是前面提到的取模运算得到的结果),另一部分用于作为标记(tag),还有一部分用于表示块内偏移(因为每个缓存块中可以存储多个数据)。
CPU 会根据索引找到对应的缓存块,然后将主存地址中的标记与缓存块中的标记进行比较。如果两者相同,并且缓存块中的有效位为
1(表示该缓存块中的数据是有效的),那么就表示命中,CPU 可以直接从缓存块中读取数据;如果标记不同或者有效位为
0,那就表示未命中,CPU 需要从主存中读取数据,并且将该数据所在的主存块调入缓存中,同时更新缓存块的标记和有效位。
1.2主存与cache地址格式

当主存的数据块调入Cache中时,该块的块号(主存标记)保存于调入Cache行的对应标记位(即块表中)
块表的东西应为2^m * S位
1.3优劣势深度分析
直接映射的优点非常明显,首先它的硬件实现非常简单,因为映射规则固定,不需要复杂的硬件电路来进行地址映射和查找。这就使得它的成本相对较低,而且地址变换的速度非常快,能够快速地响应
CPU 的访问请求。
然而,它的缺点也同样突出。由于每个主存块只能映射到固定的缓存块,这就导致了缓存的冲突率非常高。当多个主存块都需要映射到同一个缓存块时,就会发生冲突,后面的主存块会覆盖前面主存块的数据,使得缓存的命中率降低。例如,如果程序频繁地访问主存中第
0 块和第 8 块的数据,而它们都映射到缓存的第 0 块,那么这两个块的数据就会不断地在缓存中替换,导致每次访问都可能需要从主存中读取数据,大大降低了缓存的效率
。这种冲突问题也使得缓存的利用率很低,很多缓存空间无法得到充分利用,因为即使其他缓存块空闲,主存块也不能随意映射到这些空闲块中。
1.4案例分析
【例】设主存容量1MB , cache容量16KB,块的大小为512B,采用全相联映射方式。
(1)写出cache的地址格式?
cache的容量是16KB,所以按字编码的话,cache的总线长度是14位。
块(行)的大小是512B,也就是说块(行)内地址是9位。
因此行标记 14-9=5位 ,也就是说cache一共有32行。
(2)写出主存的地址格式?
主存容量1MB,一共是20位。
块的大小是9位,所以块标记公用11位。 一共2048块
(3)块表的容量多大?
根据行的数量和块标记的位数,可以得到块表的容量是 32*11位
这个块表不包含地址部分,只有标记部分,块表中块的数量由cache行的数量决定。
(4)主存地址为CDE8FH的单元,在cache中的什么位置?
主存地址为CDE8FH的单元可映射到cache中的任何一个字块位置;
CDE8FH1100 1101 1110 1000 1111 B其块7行内地址为:010001111。
二、全相联映射:自由灵活的 “数据收纳盒”
全相联映射与直接映射截然不同,它赋予了数据块极高的自由度。在全相联映射的规则下,主存中的任何一个数据块都能够随心所欲地映射到缓存中的任意一个缓存块位置
。这就好比一个大型图书馆,每本书(主存数据块)可以被放置在图书馆的任意一个书架格子(缓存块)里,没有固定的限制区域。这种映射方式彻底打破了直接映射的那种固定对应关系的束缚,极大地提高了缓存使用的灵活性。
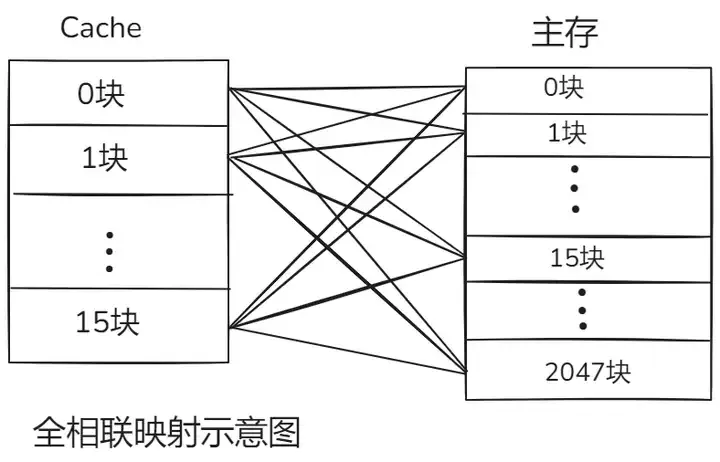
全相联映射方式比较灵活,主存的各块可以映射到 Cache 的任一块中,Cache 的利用率高,块冲突概率低,只要淘汰
Cache 中的某一块,即可调入主存的任一块。但是,由于 Cache 比较电路的设计和实现比较困难,这种方式只适合于小容量
Cache 采用。
2.1查找匹配过程
当 CPU 需要从缓存中读取数据时,它会将主存地址拆分成标记(tag)和块内偏移两部分。接下来,CPU
会逐一比较缓存中每一个缓存块的标记与主存地址中的标记。这个过程就像是在图书馆里,工作人员需要拿着书籍编号(主存地址标记),在所有的书架格子(缓存块)中寻找与之匹配的编号。如果找到了匹配的标记,并且该缓存块的有效位为
1,那就意味着命中了,CPU 可以直接从这个缓存块中读取数据;要是遍历完所有缓存块都没有找到匹配的标记,那就表示未命中,CPU
不得不从主存中读取数据,并且将该数据所在的主存块调入缓存中,同时更新缓存块的标记和有效位 。
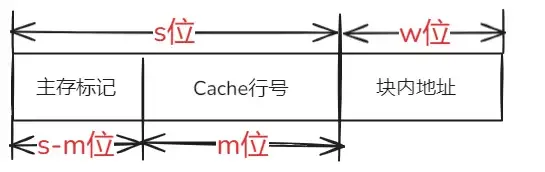
2.2主存地址格式
假设主存共2^n个单元,分成2^s个块,每块单元数为2^w个,则主存地址为s+w位。(2^s个块代表块标记数目,每块单元数2^w代表块内地址位数)
Cache空间被分成2^m行,每行大小也应该为2^w单元,则Cache地址为m+w位。
2.3全面评价优缺点
全相联映射的优点非常突出,由于它允许主存块自由映射到缓存的任意位置,这使得缓存的命中率得到了显著提高,缓存空间的利用率也达到了很高的水平。在实际应用中,当程序访问的数据具有较强的随机性和分散性时,全相联映射能够充分发挥其优势,大大减少了缓存未命中的情况,从而提高了系统的性能
。
然而,全相联映射也存在着明显的缺点。由于查找数据时需要遍历缓存中的所有块来对比标记,这就使得查找过程变得非常复杂,需要耗费大量的时间,导致访问速度较慢。而且,为了实现这种自由映射和快速查找,需要配备复杂的硬件电路和大量的比较器,这无疑大大增加了硬件成本和实现难度
。
也正是因为这些缺点,全相联映射在实际应用中受到了一定的限制,通常只适用于对缓存容量要求较小的场景,比如一些对成本不太敏感但对缓存命中率要求极高的高端处理器缓存设计中
。
三、组相联映射:取两者之长的 “调和者”
组相联映射就像是一个精心规划的 “分组社区”,它巧妙地融合了直接映射和全相联映射的优点 。在组相联映射的规则下,缓存被细致地划分为多个组(Set),每个组里面又包含了若干个缓存块(Block)。主存中的数据块首先会依据特定的规则被映射到缓存中的某一个组,这个映射规则类似于直接映射,通过主存块号对缓存组数取模运算来确定组号
。例如,如果缓存被分成 8 个组,主存中的第 0 块、第 8 块、第 16 块…… 都会被映射到缓存的第
0 组。
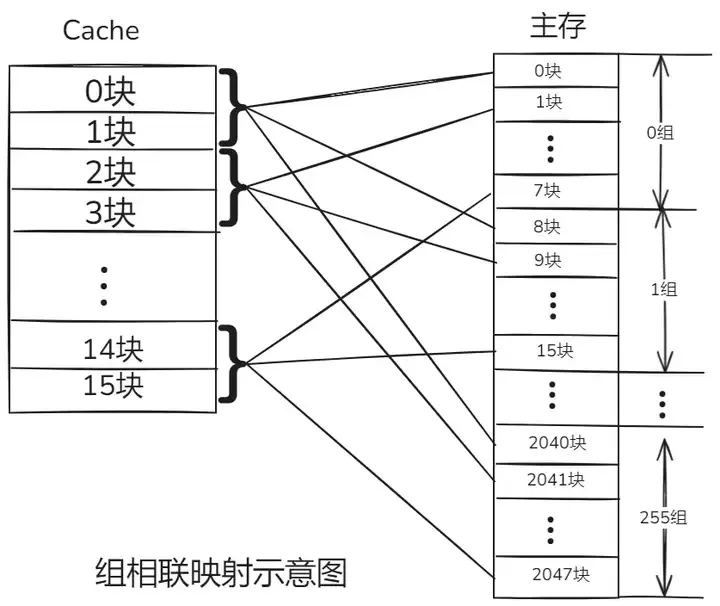
而在组内,数据块的映射方式则采用了全相联映射,也就是说,主存中的数据块可以自由地映射到它所对应的组内的任意一个缓存块中
。这种独特的映射方式既保留了直接映射简单快速的特点,又具备了全相联映射灵活高效的优势,有效地降低了缓存冲突的概率,提高了缓存的利用率
。
3.1实际工作机制
当 CPU 需要访问数据时,组相联映射的工作机制开始发挥作用。CPU 首先会根据主存地址中的组索引字段找到对应的缓存组,这个过程就像是在一个大型社区中找到对应的楼栋。然后,它会在这个组内逐一比较各个缓存块的标记(tag)与主存地址中的标记
。这一步就像是在楼栋里找到对应的房间,通过房间号(标记)来确认是否找对了地方。如果找到了匹配的标记,并且该缓存块的有效位为
1,那就意味着命中了,CPU 可以直接从这个缓存块中读取数据;如果没有找到匹配的标记,那就表示未命中,CPU
需要从主存中读取数据,并将该数据所在的主存块调入缓存中,同时更新缓存块的标记和有效位 。
3.2性能综合评估
组相联映射在性能上有着出色的表现。它有效地降低了缓存冲突率,相比于直接映射,它允许更多的主存块映射到缓存中,减少了因冲突导致的数据替换,从而提高了缓存的命中率
。在一个程序频繁访问多个主存块,但这些主存块不会都映射到同一个缓存组的情况下,组相联映射能够很好地满足数据访问需求,使得数据能够更快速地被
CPU 获取,提升了系统的整体性能 。
在缓存利用率方面,组相联映射也表现得相当出色。由于组内采用全相联映射,主存块可以更灵活地放置在缓存中,避免了直接映射中因固定映射导致的缓存空间浪费问题,使得缓存空间得到了更充分的利用
。
当然,组相联映射也并非完美无缺。由于在组内需要进行标记比较,这使得它的硬件复杂度要高于直接映射,需要更多的比较器和复杂的控制电路来实现
。查找数据的时间也会相对增加,因为除了要找到对应的组,还需要在组内进行逐一比较 。但总体来说,它在冲突率、利用率和硬件复杂度之间取得了一个较好的平衡,在实际应用中得到了广泛的使用
。
四、三种映射方式的应用场景与选择策略
4.1不同场景下的适用性分析
在实际应用中,不同的计算机系统和应用场景对 Cache 的性能有着不同的要求,因此需要根据具体情况选择合适的映射方式。
对于一些简单的小型系统或嵌入式系统,直接映射方式往往是一个不错的选择。这些系统通常对成本非常敏感,并且数据访问模式相对简单,数据的访问具有一定的规律性。在这样的系统中,直接映射的简单性和低成本优势就能够得到充分体现
。一些简单的微控制器系统,它们的任务相对单一,数据访问主要集中在几个固定的区域,使用直接映射 Cache
可以在保证一定性能的前提下,大大降低硬件成本,提高系统的性价比 。
而对于那些对性能要求极高,对成本不太敏感的高性能计算系统,全相联映射则更能发挥其优势。在高性能计算中,程序通常需要处理大量复杂的数据,数据访问模式非常复杂且具有高度的随机性。全相联映射能够提供极高的命中率,减少缓存未命中的情况,从而显著提高系统的性能
。在一些超级计算机的缓存设计中,就可能会采用全相联映射方式,以满足其对高速数据访问的严格要求 。
组相联映射则在大多数现代计算机系统中得到了广泛应用,因为它在性能和成本之间取得了一个很好的平衡。无论是桌面计算机、服务器还是移动设备,这些系统既需要一定的性能来保证用户的使用体验,又需要控制成本以满足市场需求
。组相联映射既能有效降低缓存冲突率,提高命中率,又不会像全相联映射那样带来过高的硬件成本和复杂度,非常适合这类系统的需求
。在常见的个人电脑中,CPU 的一级缓存(L1 Cache)和二级缓存(L2 Cache)通常会采用组相联映射方式,以提供良好的性能和合理的成本
。
4.2选择时的关键考量因素
在选择 Cache 映射方式时,有几个关键因素需要仔细考量。首先是成本因素,硬件成本在系统设计中是一个重要的制约因素。直接映射方式由于硬件实现简单,所需的硬件资源最少,因此成本最低;全相联映射则需要复杂的硬件电路和大量的比较器,成本最高;组相联映射的成本介于两者之间
。如果系统对成本控制较为严格,那么直接映射可能是首选;而对于那些追求极致性能且对成本不敏感的高端系统,则可以考虑全相联映射
。
性能是另一个至关重要的考量因素。性能主要体现在缓存命中率和访问速度上。全相联映射的命中率最高,因为它可以将主存块自由地映射到缓存的任意位置,最大限度地减少了冲突,对于那些数据访问模式复杂且随机的应用,能够提供最佳的性能
。直接映射的访问速度最快,因为它的映射规则简单,每次访问只需检查一个固定的缓存块位置,但由于冲突率高,命中率相对较低
。组相联映射在命中率和访问速度之间取得了平衡,它通过合理的分组和组内全相联映射,降低了冲突率,提高了命中率,同时访问速度也不会太慢
。
缓存大小也会对映射方式的选择产生影响。对于较小的缓存,全相联映射可能更适用,因为小缓存中的缓存块数量有限,全相联映射可以更充分地利用这些缓存块,提高缓存的利用率和命中率
。而对于较大的缓存,直接映射可能会导致严重的冲突问题,降低缓存的性能,此时组相联映射则是更好的选择,它可以通过分组来减少冲突,提高缓存的整体性能
。
五、Cache映射案例分析
5.1实际例子
下面展示了现代 Intel 处理器的 CPU cache 是如何组织的。有关 cache 的讨论往往缺乏具体的实例,使得一些简单的概念变得扑朔迷离。也许是我可爱的小脑瓜有点迟钝吧,但不管怎样,至少下面讲述了故事的前一半,即
Core 2 的 L1 cache 是如何被访问的:
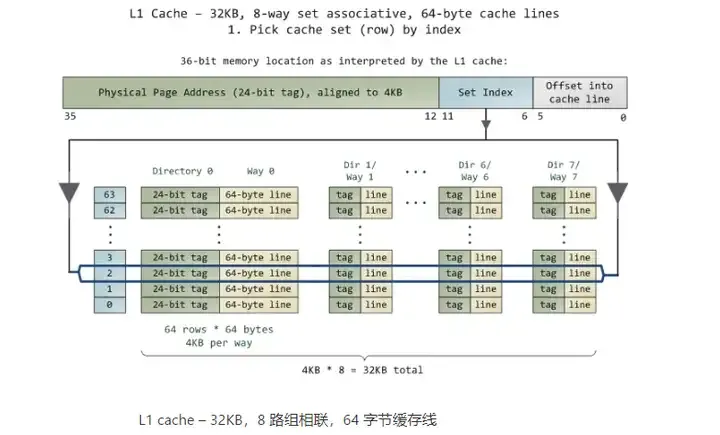
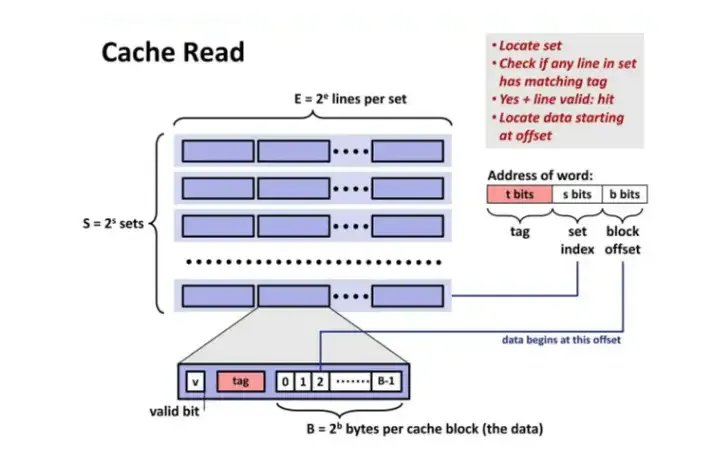
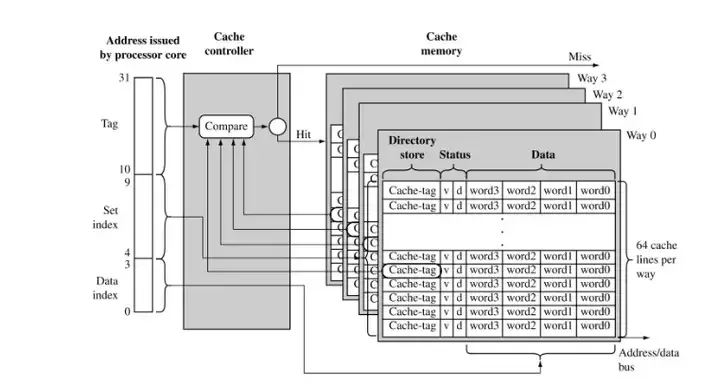
5.2由索引拣选缓存组(行)
在 cache 中的数据是以缓存线(line)为单位组织的,一条缓存线对应于内存中一个连续的字节块。这个
cache 使用了 64 字节的缓存线。这些线被保存在 cache bank 中,也叫路(way)。每一路都有一个专门的目录(directory)用来保存一些登记信息。你可以把每一路连同它的目录想象成电子表格中的一列,而表的一行构成了
cache 的一组(set)。列中的每一个单元(cell)都含有一条缓存线,由与之对应的目录单元跟踪管理。图中的
cache 有 64 组、每组 8 路,因此有 512 个含有缓存线的单元,合计 32KB 的存储空间。
在 cache 眼中,物理内存被分割成了许多 4KB 大小的物理内存页(page)。每一页都含有
4KB / 64 bytes == 64 条缓存线。在一个 4KB 的页中,第 0 到 63 字节是第一条缓存线,第
64 到 127 字节是第二条缓存线,以此类推。每一页都重复着这种划分,所以第 0 页第 3 条缓存线与第
1 页第 3 条缓存线是不同的。
在全相联缓存(fully associative cache)中,内存中的任意一条缓存线都可以被存储到任意的缓存单元中。这种存储方式十分灵活,但也使得要访问它们时,检索缓存单元的工作变得复杂、昂贵。由于
L1 和 L2 cache 工作在很强的约束之下,包括功耗,芯片物理空间,存取速度等,所以在多数情况下,使用全相联缓存并不是一个很好的折中。
取而代之的是图中的组相联缓存(set associative cache)。意思是,内存中一条给定的缓存线只能被保存在一个特定的组(或行)中。所以,任意物理内存页的第
0 条缓存线(页内第 0 到 63 字节)必须存储到第 0 组,第 1 条缓存线存储到第 1 组,以此类推。每一组有
8 个单元可用于存储它所关联的缓存线,从而形成一个 8 路关联的组(8-way associative
set)。当访问一个内存地址时,地址的第 6 到 11 位(译注:组索引)指出了在 4KB 内存页中缓存线的编号,从而决定了即将使用的缓存组。举例来说,物理地址
0x800010a0 的组索引是 000010,所以此地址的内容一定是在第 2 组中缓存的。
但是还有一个问题,就是要找出一组中哪个单元包含了想要的信息,如果有的话。这就到了缓存目录登场的时刻。每一个缓存线都被其对应的目录单元做了标记(tag);这个标记就是一个简单的内存页编号,指出缓存线来自于哪一页。由于处理器可以寻址
64GB 的物理 RAM,所以总共有 64GB / 4KB == 224 个内存页,需要 24 位来保存标记。前例中的物理地址
0x800010a0 对应的页号为 524,289。下面是故事的后一半:
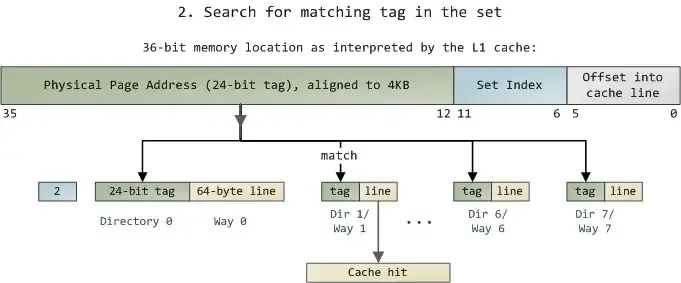
5.3在组中搜索匹配标记
由于我们只需要去查看某一组中的 8 路,所以查找匹配标记是非常迅速的;事实上,从电学角度讲,所有的标记是同时进行比对的,我用箭头来表示这一点。如果此时正好有一条具有匹配标签的有效缓存线,我们就获得一次缓存命中(cache
hit)。否则,这个请求就会被转发的 L2 cache,如果还没匹配上就再转发给主系统内存。通过应用各种调节尺寸和容量的技术,Intel
给 CPU 配置了较大的 L2 cache,但其基本的设计都是相同的。
比如,你可以将原先的缓存增加 8 路而获得一个 64KB 的缓存;再将组数增加到 4096,每路可以存储
256KB。经过这两次修改,就得到了一个 4MB 的 L2 cache。在此情况下,需要 18 位来保存标记,12
位保存组索引;缓存所使用的物理内存页的大小与其一路的大小相等。(译注:有 4096 组,就需要 lg
(4096)==12 位的组索引,缓存线依然是 64 字节,所以一路有 4096*64B==256KB
字节;在 L2 cache 眼中,内存被分割为许多 256KB 的块,所以需要 lg (64GB/256KB)==18
位来保存标记。)
如果有一组已经被放满了,那么在另一条缓存线被存储进来之前,已有的某一条则必须被腾空(evict)。为了避免这种情况,对运算速度要求较高的程序就要尝试仔细组织它的数据,使得内存访问均匀的分布在已有的缓存线上。举例来说,假设程序中有一个数组,元素的大小是
512 字节,其中一些对象在内存中相距 4KB。这些对象的各个字段都落在同一缓存线上,并竞争同一缓存组。如果程序频繁的访问一个给定的字段(比如,通过虚函数表
vtable 调用虚函数),那么这个组看起来就好像一直是被填满的,缓存开始变得毫无意义,因为缓存线一直在重复着腾空与重新载入的步骤。
在我们的例子中,由于组数的限制,L1 cache 仅能保存 8 个这类对象的虚函数表。这就是组相联策略的折中所付出的代价:即使在整体缓存的使用率并不高的情况下,由于组冲突,我们还是会遇到缓存缺失的情况。然而,鉴于计算机中各个存储层次的相对速度,不管怎么说,大部分的应用程序并不必为此而担心。
一个内存访问经常由一个线性(或虚拟)地址发起,所以 L1 cache 需要依赖分页单元(paging
unit)来求出物理内存页的地址,以便用于缓存标记。与此相反,组索引来自于线性地址的低位,所以不需要转换就可以使用了(在我们的例子中为第
6 到 11 位)。因此 L1 cache 是物理标记但虚拟索引的(physically tagged
but virtually indexed),从而帮助 CPU 进行并行的查找操作。因为 L1 cache
的一路绝不会比 MMU 的一页还大,所以可以保证一个给定的物理地址位置总是关联到同一组,即使组索引是虚拟的。在另一方面
L2 cache 必须是物理标记和物理索引的,因为它的一路比 MMU 的一页要大。但是,当一个请求到达
L2 cache 时,物理地址已经被 L1 cache 准备(resolved)完毕了,所以 L2
cache 会工作得很好。
最后,目录单元还存储了对应缓存线的状态(state)。在 L1 代码缓存中的一条缓存线要么是无效的(invalid)要么是共享的(shared,意思是有效的,真的
J)。在 L1 数据缓存和 L2 缓存中,一条缓存线可以为 4 个 MESI 状态之一:被修改的(modified),独占的(exclusive),共享的(shared),无效的(invalid)。Intel
缓存是包容式的(inclusive):L1 缓存的内容会被复制到 L2 缓存中。 | 






 订阅
订阅