| БрМЭЦМі: |
БОЮФжївЊДгУєНнПЊЗЂКЭГжајНЛИЖСНИігђРДНщЩмСЫDevOpsФмСІГЩЪьЖШФЃаЭЃЌЯЃЭћЖдФуЕФбЇЯАгаАяжњЁЃ
БОЮФРДздгкЮЂаХЙЋжкКХШЫдТСФIT ,гЩЛ№СњЙћШэМўAliceБрМЭЦМіЁЃ |
|
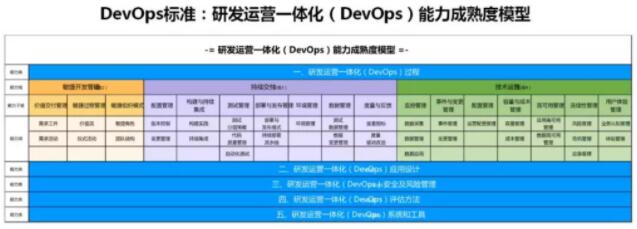
НёЬьзМБИЬИЯТDevOpsФмСІГЩЪьЖШФЃаЭЃЌжиЕуЪЧУєНнПЊЗЂКЭГжајНЛИЖСНИігђЁЃ
баЗЂдЫгЊФмСІвЛЬхЛЏФмСІГЩЪьЖШФЃаЭЪЧЙњФкЭтЕквЛИіDevOpsЯЕСаБъзМЃЌгЩжаЙњаХЯЂЭЈаХбаОПдКдЦМЦЫуПЊдДВњвЕСЊУЫЃЈOSCARЃЉСЊКЯЖрИіЕЅЮЛаавЕЖЅМЖММЪѕзЈМв100ЖрУћЙВЭЌБраДжЦЖЈЃЌЮЊСЫШУИќЖрЕФЦѓвЕФмИДгУDevOpsСьгђСьЯШЦѓвЕЛ§РлЕФЯШНјММЪѕЁЃ
ИУЯЕСаБъзМЗжЮЊУєНнПЊЗЂЙмРэЁЂГжајНЛИЖЁЂММЪѕдЫгЊЁЂгІгУЩшМЦЁЂАВШЋЗчЯеЙмРэЁЂзщжЏНсЙЙМАЯЕЭГКЭЙЄОпЕШВПЗжЃЌКИЧСЫШэМўПЊЗЂЕНдЫЮЌЕФШЋЩњУќжмЦкЃЌШчЯТЭМЃК
DevOpsЦ№дДгк2009ФъЃЌжївЊеыЖдУєЬЌвЕЮёЃЌDevOpsУЛгаЗЂУїШЮКЮММЪѕЃЌЕЋЫљгаЕФММЪѕЖМЮЊЫќЫљгУЁЃвђЮЊDevOpsЪЧвЛИіИХФюЃЌЫќДгММЪѕЩЯЩ§ЕНвЕЮёВуЃЌЛсНЈвщФузщжЏНсЙЙЕФБфИяЁЃ
ећИіЦРЙРФЃаЭЮвПЩвдПДЕНШкШыСЫЖрЗНУцЕФФкШнЃЌКЫаФЪЧШчЯТШ§ЗНУц
баЗЂЯюФПЙмРэКЭУєНнбаЗЂЗНЗЈТл
ШэМўЙЄГЬЃЌЬиБ№ЪЧГжајМЏГЩЗНЗЈТл
ITЙмПиКЭжЮРэЃЌАќРЈЖддРДITILЫМЯыЬхЯЕШкШы
дкетШ§ЗНУцвдЭтЃЌЮвУЧгжПДЕНећИіГЩЪьЖШЦРЙРРяУцКмЖрЦРЙРвЊЧѓЕФДяЕНБОЩэгжЯЃЭћФуВЩгУЮЂЗўЮёМмЙЙЫМЯыЃЌЭЈЙ§ШнЦїдЦРДЪЕЯжГжајМЏГЩКЭНЛИЖЕШЁЃетвВКЭЮвУЧОГЃЬИЕНЕФЃЌЮЂЗўЮёКЭШнЦїдЦЪЧЪЕМљDevOpsЕФСэЭтвЛИіЙиМќвЊЫиЁЃ
УєНнПЊЗЂЙмРэ
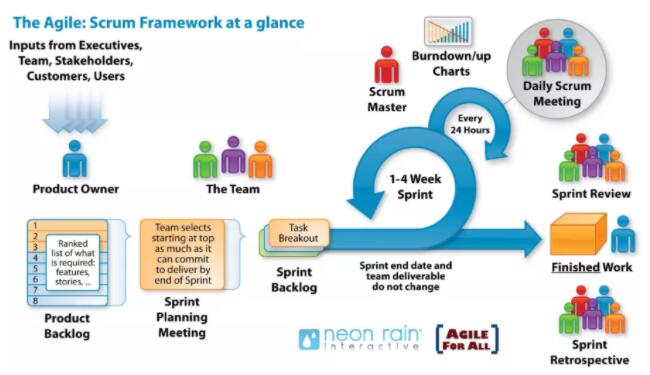
ШчЙћзіЙ§CMMIЛђУєНнЯюФПЙмРэЕФПЩвдПДЕНЪЕМЪЩЯдкЕБЧАDevOpsГЩЪьЖШФЃаЭжаЕФУєНнПЊЗЂЙмРэЛЙЪЧЯрЕБДжЕФЃЌЖјЧвЪЧНЋШэМўЙЄГЬгђФкШнКЭЙ§ГЬЙмРэФкШнШкКЯдкСЫвЛЦ№ЃЌЭЌЪБвВПЩвдПДЕНЦфКЫаФЛЙЪЧЛљгкScrumУєНнЯюФПЙмРэЗНЗЈТлЖјеЙПЊЃЌжЛЪЧИќМгЧПЕїСЫвЕЮёГЁОАЧ§ЖЏКЭМлжЕНЛИЖЕФживЊадЁЃ
DevOpsГжајМЏГЩКЭНЛИЖБОЩэОЭЪЧЮЊСЫИќМгУєНнЯьгІашЧѓЃЌПьЫйЖЬжмЦкЕФЕќДњНЛИЖЃЌвђДЫКЭУєНнЗНЗЈТлХфКЯЪЧздШЛЕФЪТЧщЁЃЭЌЪБвВПЩвдПДЕНвЊЪЕЯжУєНнЃЌашЧѓБиаыЯИСЃЖШЛЏЃЌЭЌЪБашЧѓБОЩэашвЊЬхЯжвЕЮёМлжЕЃЌЖјвЊзіЕНетЕуКЫаФОЭЪЧЛљгквЕЮёГЁОАЗжЮіГіРДЕФгУЛЇЙЪЪТКЭгУЛЇЙЪЪТЕиЭМЁЃ
гУЛЇЙЪЪТЕиЭМКЭЖдBacklogЧхЕЅИњзйИФНј
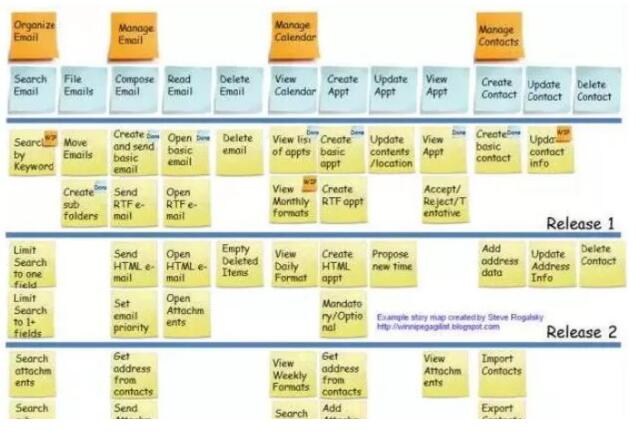
дРДЮвУЧЬИЕФОЭЪЧгУЛЇЙЪЪТЃЌProduct backlogКЭSprint backlogЃЌЯШаЮГЩВњЦЗbacklogЃЌЭЌЪБЦРЙРгХЯШМЖКЭЙІФмЕуИДдгЖШЃЌШЛКѓНЋВЛЭЌЕФгУЛЇЙЪЪТЗжХфЕНОпЬхЕФsprint
backlogРяУцаЮГЩЕБЧАЕФЕќДњАцБОЁЃНЋгУЛЇЙЪЪТНјвЛВНЯИЛЏЮЊВЛЭЌЕФЙЄзїШЮЮёЯюЃЌНЋЙЄзїШЮЮёЯТДяЕНОпЬхЕФШЫдБжДааЁЃ
дкећИіЙ§ГЬжаЛљгкbacklogСаБэаЮГЩДгашЧѓЕНПЊЗЂЕНВтЪдЕФЭъећЖЫЕНЖЫИњзйКЭбщжЄЁЃ
гУЛЇЙЪЪТБОЩэОЭЪЧвЕЮёашЧѓЕФЪЕЯжЃЌвђЮЊЮЇШЦгУЛЇЙЪЪТЕФЙмРэЪЕЯжЭъећЕФвЕЮёМлжЕНЛИЖЁЃ
ЕБЮвУЧПДЕНетаЉгУЛЇЙЪЪТЕиЭМЕФЪБКђЃЌЮвУЧЗЂЯжетжжЕиЭМЗНЪНКмКУЕФНтОідРДbacklogЧхЕЅЕФЕЅЮЌЖШЮЪЬтЃЌаЮГЩСЫвЛжжЖўЮЌЕФПЩЪгЛЏЪгЭМНсЙЙЁЃНЋОпЬхЕФгУЛЇЙЪЪТФкШнКмКУЕФГЪЯждквЛИіЖўЮЌзјБъЬхЯЕРяУцЃЌЦфжавЛИізјБъЪЧвЕЮёЛюЖЏКЭШЮЮёЃЌвЛИізјБъЪЧОпЬхЕФЕќДњАцБОЁЃ
ЭЌЪБЮвУЧЖдгУЛЇЙЪЪТБОЩэвВаЮГЩСЫЭъећЕФВуДЮНсЙЙЃЌМД
вЕЮёЛюЖЏ-ЁЗвЕЮёШЮЮё-ЁЗгУЛЇЙЪЪТЕу
ЖдгкгУЛЇЙЪЪТЕуЃЌЮвУЧПЩвдПДЕНвВНазюаЁЛЏгУЛЇЙЪЪТЃЌЖјетИідкЮвУЧЖрФъЧАЪЕЪЉscrumУєНнЗНЗЈТлЕФЪБКђВЂУЛгаетбљШЅЙмРэЃЌЭљЭљгУЛЇЙЪЪТЕуЛЙЪЧЦЋДжЃЌЖјЪЧдкШЮЮёАВХХЩЯЖдгУЛЇЙЪЪТЕуНјааСЫЯИЛЏЁЃЖјдкаТЕФФЃЪНЯТПЩвдПДЕНгУЛЇЙЪЪТЕуИќМгЯИЛЏЃЌЪЧвЛИізюаЁЕФЙІФмЪЕЯжЕуЁЃ
зюаЁЛЏгУЛЇЙЪЪТЕувВПЩФмВЛФмЖРСЂНЛИЖЃЌЕЋЪЧетВЛгАЯьЮвУЧЯИЛЏЕНзюаЁЛЏгУЛЇЙЪЪТЕуНјааЙмРэЁЃетжжзюаЁЛЏгУЛЇЙЪЪТЕуеце§НтОіСЫЮвУЧдРДгіЕНЕФСНИіЮЪЬтЃЌМДЖдгкЭЌвЛИігУЛЇЙЪЪТЃЌгУЛЇЙЪЪТБОЩэВЛФмдйНјааЯИЗжЕФЃЌЕЋЪЧгУЛЇЙЪЪТБОЩэгжАќРЈСЫКмЖрРЉеЙБпНчЃЌЛђепЫЕгУЛЇЙЪЪТБОЩэАќКЌСЫРЉеЙвЕЮёЙцдђТпМЃЌЖјетаЉдкаТгУЛЇЙЪЪТЪгЭМФЃЪНЯТЖМПЩвдНјааПЩЪгЛЏГЪЯжЃЌВЂЗжХфЕНВЛЭЌЕФЕќДњАцБОНјааЙмРэЁЃ
БШШчЖдвЛИіМђЕЅЕФЗЂЫЭгЪМўгУЛЇЙЪЪТЃЌЮвУЧОЭЛсДцдкКмЖрЕФаЁгУЛЇЙЪЪТЕуЃЌБШШчжЇГжЗЂЫЭИНМўЃЌжЇГжЗЂЫЭЭМЦЌЖМЪЧРЉеЙЙЪЪТЕуЃЌЖјЖдгкЗЂЩњЪБКђашвЊаЃбщгЪЯфгааЇадПЩФмОЭЪЧРЉеЙЕФвЕЮёЙцдђЕуЁЃетаЉЮвУЧЖМашвЊНјааЙмРэВЂИњНјгХЯШМЖАВХХЕНВЛЭЌЕФЕќДњАцБОШЅЪЕЯжЁЃ
дкгУЛЇЙЪЪТЕиЭМРяУцгавЛИіЙиМќааЃЌМДвЛМЖгУЛЇЙЪЪТЃЌЫќУЧзщГЩСЫгУЛЇЙЪЪТЕиЭМЩЯЕФаазпЕФЙЧїРЃЈthe walking
skeletonЃЉВПЗжЁЃЖјЖдгквЛМЖгУЛЇЙЪЪТЃЌЮвУЧвВПЩвдПДЕНЃЌе§ЪЧЮвУЧдРДдкsprint backlogРяУцЙмРэЕНЕФгУЛЇЙЪЪТСЃЖШЁЃ
ЖјдквЛМЖгУЛЇЙЪЪТЩЯУцЃЌЛЙгавЛВуМДuser activitiesгУЛЇвЕЮёЛюЖЏВуЃЌЖјетВуЪЕМЪЩЯвВЯрЕБЙиМќЃЌЭЈЙ§етВуЮвУЧПЩвдНЋЮвУЧЕФгУЛЇЙЪЪТеце§КЭЪЕМЪЕФвЕЮёГЁОАЃЌвЕЮёСїГЬКЭЛюЖЏЙиСЊЦ№РДЁЃЭЈЙ§етжжЭМвВПЩвдКмЧхЮњЕФПДЕНЮвУЧЪЕЯжЕФгУЛЇЙЪЪТОПОЙЬхЯждкФФИівЕЮёСїГЬЛђвЕЮёГЁОАжаЁЃ
ЖдгкетСНВуЕФЙЙНЈЃЌЪЕМЪЩЯвВЪЧДцдкСНжжЗНЗЈПЩвдПМТЧЁЃ
здЖЅЯђЯТЃКДгвЕЮёГЁОАКЭСїГЬЗжНтШыЪжЃЌЯШЪсРэЖЈвхЧхГўвЕЮёЛюЖЏЃЌдйЯИЗжвЛМЖгУЛЇЙЪЪТЁЃ
здЕзЯђЩЯЃКЯШЭЗФдЗчБЉаЮГЩвЛМЖгУЛЇЙЪЪТЃЌШЛКѓдйЯђЩЯГщЯѓЙщРраЮГЩвЕЮёЛюЖЏВуЁЃ
ОЭетСНжжЗНЗЈРДЫЕЃЌздЖЅЯђЯТЗжЮіПЩвдШЗБЃИќМгЭъећЮоШБТЉЃЌЖјздЕзЯђЩЯЗНЗЈЭљЭљдђИќМгПьЫйКЭУєНнЁЃОпЬхВЩгУФФжжЗНЗЈНјааашвЊИљОнЯюФПЭХЖгЪЕМЪЧщПіРДзлКЯПМТЧЁЃ
дкаЮГЩСЫвЕЮёЛюЖЏКЭвЛМЖгУЛЇЙЪЪТКѓЃЌЪЃЯТОЭЪЧЖдвЛМЖгУЛЇЙЪЪТНјвЛВНВ№ЗжЮЊзюаЁЛЏгУЛЇЙЪЪТЃЌзюаЁЛЏгУЛЇЙЪЪТЪЧЗёзїЮЊШЮЮёжБНгЯТДяашвЊПДЮвУЧбаЗЂЯюФПШЮЮёЙмРэЕФДжЯИЖШЧщПіЃЌдкетРяВЂУЛгаУїШЗЕФБъзМКЭвЊЧѓЁЃШчЙћИњзйЙмРэЕФЯИЃЌГжајМЏГЩЙ§ГЬвВИпаЇПьЫйЃЌФЧУДОЭПЩвдЕНзюаЁЛЏгУЛЇЙЪЪТЃЌЗёдђОЭЕНвЛМЖгУЛЇЙЪЪТЁЃ
ЪЕМЪЩЯдквЛМЖгУЛЇЙЪЪТЕФВ№ЗжЩЯЃЌЛЙПЩвдНшМјЮвУЧдРДгУР§НЈФЃЕФОбщЃЌНЋзюаЁЛЏгУЛЇЙЪЪТЗжЮЊШ§РрЙЪЪТГЁОАЃЌМДКЫаФгУЛЇЙЪЪТЃЌРЉеЙЙЪЪТЕуЃЌвЕЮёЙцдђТпМЙЪЪТЕуВЂЗжБ№НјааЙмРэЁЃЦфжаЖдгкКЫаФгУЛЇЙЪЪТЕугХЯШМЖзюИпЃЌБиаыдкЕквЛИіЕќДњжмЦкЪЕЯжЃЌРЉеЙЙЪЪТКЭЙцдђЙЪЪТЕувВБиаывЊвРЭаКЫаФЙЪЪТЕуЖјДцдкЁЃ
ЖјЖдгкУєНнПЊЗЂЛђУєНнЯюФПЙмРэЃЌШчЙћвЊгУвЛОфЛАРДзмНсЕФЛАОЭЪЧЃЌЛљгквЕЮёГЁОАКЭгУЛЇЙЪЪТЧ§ЖЏЕФЖЬжмЦкЕќДњКЭЯюФПЭХЖгИпаЇаЭЌЃЌвдЪЕЯжПьЫйЕФвЕЮёМлжЕНЛИЖЁЃЖјетИіФПБъЯТЮвУЧОГЃЬИЕНЕФПЩЪгЛЏПДАхЃЌеОСЂЛсвщЃЌШМОЁЭМЕШвВНіНіЪЧЪЕЯжЩЯЪіФПБъЕФЙЄОпЁЃ
вВе§ЪЧетИідвђЮвУЧПДЕНЃЌвЊНјШыЕНУєНнПЊЗЂЙ§ГЬЙмРэЃЌаЮГЩЛљгквЕЮёГЁОАаЮГЩОпБИгХЯШМЖЛЎЗжЕФЯИСЃЖШгУЛЇЙЪЪТжСЙиживЊЃЌетНЋжБНгЪЧЮвУЧКѓУцЕќДњМЦЛЎАВХХЃЌВтЪдгУР§БраДЃЌНЛИЖНЛИЖЕФЛљДЁЁЃ
ЯТУцЮвУЧЛЙЪЧИљОнГЩЪьЖШФЃаЭРяУцЖдУєНнПЊЗЂЙмРэВ№ЗжЕФШ§ИізгЙ§ГЬгђЗжБ№РДЬИЯТЁЃ
01-МлжЕНЛИЖЃЈашЧѓЙЄМўЃЌашЧѓЛюЖЏЃЉ
МлжЕНЛИЖЙмРэАќРЈСЫашЧѓЙЄМўКЭашЧѓЛюЖЏСНИіВПЗжФкШнЃЌЬхЯжашЧѓЙмРэЙ§ГЬжаЕФЗжЮіЃЌВтЪдЃЌбщЪеШ§ИіНзЖЮЁЃМлжЕНЛИЖЙмРэжївЊЬхЯждкИїИіЛЗНкжаЪЕЯжУєНнЗНЗЈЬНбАгУЛЇЮЪЬтКЭЫпЧѓЃЌвЕЮёМлжЕЃЌВЂЖЈвхгааЇВњЦЗЙІФмЕФФмСІЃЌЪЪгІашЧѓБфЛЏЕФФмСІЃЌПьЫйбщжЄЗДРЁЕФФмСІЁЃ
01.1 ашЧѓЙЄМў
ЖдашЧѓКЭгУР§ЕФЙмРэЃЌПЩвдПДЕНАќРЈСЫашЧѓФкШнЃЌВтЪдгУР§ЃЌВтЪдгУР§бщжЄЃЌВтЪдгУР§ЙмРэЃЌИВИЧСЫЧАУцЬИЕНЕФашЧѓ->ВтЪд-ЁЗбщЪеЭъећЯпЬѕЃЌЖјРяУцКЫаФгжЪЧгУЛЇЙЪЪТЁЃ
01.2 ашЧѓЛюЖЏ
АќРЈСЫашЧѓЗжЮіКЭашЧѓбщЪеЃЌЖјашЧѓЗжЮіЪЧНЋВњЦЗашЧѓОпЬхЛЏЃЌаЮГЩДњАьЪТЯюСаБэЕФЙ§ГЬЃЌЛђепЫЕашЧѓЗжЮіжиЕуОЭЪЧвЊаЮГЩгУЛЇЙЪЪТЧхЕЅЃЌЖјЧвЙРЫуЙЪЪТЕуЃЌЦРЙРгХЯШМЖЮЊКѓУцаЮГЩЕќДњМЦЛЎзізМБИЁЃаЮГЩЕќДњМЦЛЎКѓВХПЩФмЖдгІЕНКѓУцЕФбщЪеЪЧЖрДЮбщЪеЃЌЖрДЮНЛИЖЁЃ
ЖдгІашЧѓЙЄМўКЭгУЛЇЙЪЪТЕФаЮГЩЃЌЫМПМСЫЯТЃЌИќМгжЕЕУВЮПМЕФзіЗЈгІИУЪЧ
ЛљгквЕЮёГЁОАЗжЮіЪсРэвЕЮёСїГЬЃЌЪЖБ№ЙиМќвЕЮёЛюЖЏЃЌВЂЪЖБ№вЛМЖгУЛЇЙЪЪТ
ЛљгкЪЖБ№ЭъГЩЕФвЛМЖгУЛЇЙЪЪТРДНјаадаЭЩшМЦКЭПЊЗЂ
ЛљгкдаЭЩшМЦдйНјвЛВНЕФЗжНтвЛМЖгУЛЇЙЪЪТЃЌаЮГЩзюаЁЛЏгУЛЇЙЪЪТКЭгХЯШМЖ(ЭъећгУЛЇЙЪЪТЕиЭМЃЉ
етжжЗНЗЈКЭВНжшПЩвдИќКУЕФНЋвЕЮёГЁОАКЭСїГЬКЭЮвУЧЪЕМЪЕФвЕЮёЙІФмЪЕЯжНсКЯдквЛЦ№ЃЌНЋОпЬхЪЕЯжЕФвЕЮёЙІФмЦЅХфЕНКЫаФвЕЮёМлжЕЪЕЯжЩЯЁЃетВХЪЧЮвУЧЬИЕНЕФМлжЕНЛИЖЖјВЛЪЧЕЅИіЙІФмЕуНЛИЖЁЃ
ЭЌЪБЩЯУцетжжЗНЗЈЮвУЧЛЙПДЕННјвЛВННЋашЧѓЗжЮіЙ§ГЬКЭЮвУЧКѓајЕФВњЦЗЙцЛЎКЭЕќДњАцБОМЦЛЎЙ§ГЬНєУмЕФНсКЯдкСЫвЛЦ№ЃЌгЩгкгУЛЇЙЪЪТОпБИгХЯШМЖЃЌдкНјаагХЯШМЖЗжЮіЙ§ГЬжаНсКЯЕНЕќДњАцБОМЦЛЎАВХХЃЌдкЙЪЪТЕуЙРЫуЙ§ГЬжаЗжЮіОпЬхЕФЙЄзїСПЃЌетаЉЖМЮЊКѓајЕФАцБОМЦЛЎАВХХКЭШЮЮёЯТДяЕьЖЈСЫЛљДЁЁЃ
ЖјЖдгкашЧѓЕФЙмРэЃЌРяУцЬИЕНЕФБШНЯДжЃЌЖдгкашЧѓЕФзЗзйЃЌашЧѓЕФБфИќЙмРэЃЌашЧѓЕФЗЂВММЦЛЎЃЌашЧѓЕФбщжЄЕШЖМгІИУЪєгкашЧѓЙмРэЕФЗЖГыЁЃжЛЪЧдкУєНнПЊЗЂЙ§ГЬжаЕФашЧѓЙмРэЃЌИќМгЧПЕїЮЇШЦгУЛЇЙЪЪТаЮГЩвЛЬѕЯпЕФЖЫЕНЖЫЙмРэЃЌВЂЪЕЯжМлжЕНЛИЖЕФФПБъЁЃ
02 УєНнЙ§ГЬЙмРэЃЈМлжЕСїЃЌвЧЪНЛюЖЏЃЉ
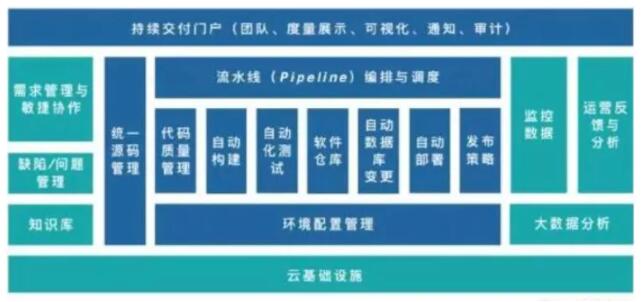
УєНнЙ§ГЬЙмРэЪЧВњЦЗОРэЃЌбаЗЂЭХЖгвдМАгыВњЦЗЯрЙиЕФИЩЯЕШЫЮЇШЦвЕЮёМлжЕНЛИЖНјааЕФШэМўбаЗЂЙ§ГЬЃЌАќРЈМлжЕСїКЭвЧЪНЛюЖЏСНИіВПЗжЃЌвЊЧѓЩЯЪіШЫдБНЈСЂвдОЁдчКЭГжајЕФНЛИЖМлжЕЕФШэМўЮЊФПБъЃЌЭЈЙ§ИпаЇЕФЙЕЭЈЗНЪНЃЌИпаЇЕФПЩЪгЛЏЙЄзїСїЃЌгааЇЕФЖШСПКЭПьЫйЗДРЁЛњжЦЃЌЪЕЯжШэМўбаЗЂвЕЮёМлжЕзюДѓЛЏЁЃ
02.1 МлжЕСї
НЋШэМўВњЦЗзЊЛЏЮЊвЕЮёМлжЕЕФФмСІЃЌАќРЈАДеегУЛЇЕиЭМАДашНЛИЖПЩгУЕФШэМўЃЌЭЌЪБАќРЈСЫНЛИЖжЪСПЙмРэЃЌНЛИЖЖШСПЃЌКЭГжајЕФМлжЕСїИњзйЁЃвВОЭЪЧЫЕетРяУцШыПкЪЧгУЛЇЙЪЪТЕиЭМЃЌШЛКѓЪЧПЩЪгЛЏЕФНЛИЖШЋСїГЬЕФИњзйКЭЗДРЁЃЌЦфДЮЪЧдкећИіЙ§ГЬжаЛЙашвЊЮЇШЦМлжЕНЛИЖНЈСЂгааЇЕФЖШСПКЭЦРЙРЛњжЦЁЃ
02.2 вЧЪНЛюЖЏ
ЭЈЙ§НЈСЂМлжЕСїЖЏЕФЙмПиЛњжЦЃЌПЩЪгЛЏЕФЙмРэМлжЕСїГЬЃЌПижЦСїЖЏНкзрЃЌВЛЖЯЬсЩ§МлжЕНЛИЖаЇТЪЁЃАќРЈИїРрМЦЛЎЛсвщЃЌЦРЩѓЛсвщЕШЁЃетИіПЩвдНјвЛВНВЮПМУєНнЙ§ГЬЙмРэжаЕФвЛаЉзюМбЪЕМљЁЃ
МђЕЅРДЫЕУєНнЙ§ГЬЙмРэКЫаФЪЧПЩЪгЛЏЃЌЙмПиЛњжЦЃЌЖШСПЛњжЦЃЌИпаЇЕФаЭЌКЭЗДРЁЛњжЦНЈСЂЁЃЫљгаЕФетаЉЛњжЦНЈСЂЖМгжЪЧЮЇШЦМлжЕНЛИЖЗўЮёЁЃ
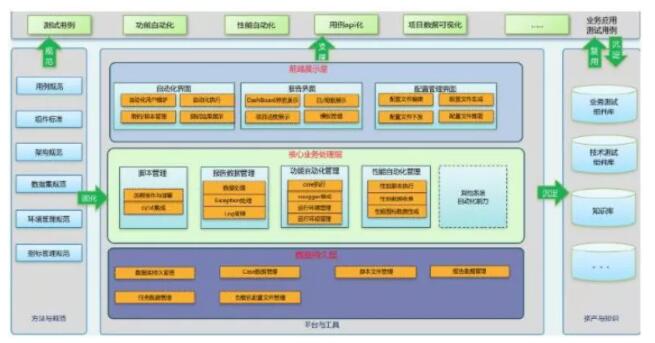
03 УєНнзщжЏФЃЪНЃЈУєНнНЧЩЋЃЌЭХЖгНсЙЙЃЉ
УєНнзщжЏФЃЪНЪЧжИЭХЖгдкбаЗЂЙ§ГЬжаЕФНЧЩЋЖЈвхЃЌНЧЩЋФмСІвдМАжЎМфЕФазїЃЌЭХЖгНсЙЙЕФЙЄзїЗНЪНЃЌЭХЖгМфЕФазїФЃЪНЕШЗНУцЕФвЊЧѓЃЌжївЊДгУєНнНЧЩЋКЭЭХЖгНсЙЙСНИіЗНУцНјааЖЈвхЁЃ
03.1 УєНнНЧЩЋ
жИВњЦЗОРэЃЌУєНнНЬСЗКЭЭХЖгжЎМфЕФжАд№ЗжЙЄЃЌФмСІЬсЩ§КЭажњЗНЪНЃЌНЧЩЋЖМФмЙЛвдМлжЕНЛИЖЮЊФПБъЃЌГжајЕФЬсЩ§НЛИЖаЇТЪЁЃ
УєНнНЬСЗдкЩюПЬЕФРэНтУєНнЕФМлжЕЙлЕФЛљДЁЩЯЃЌЭЌЪБашвЊОпБИЗсИЛЕФУєНнММЪѕЪЕМљОбщЃЌвдМАгЕгаЛљгкЭХЖгЕФЪЕМЪЧщПіВЩгУКЯЪЪЕФУєНнЪЕМљЕФФмСІЁЃетРяУцЪЕМЪАќРЈСЫашЧѓЗжЮіКЭВ№ЗжЃЌгУЛЇЙЪЪТЕиЭМЃЌашЧѓгАЯьЗжЮіЃЌЙЪЪТЕуЙЪЪТЃЌашЧѓгХЯШМЖЦРЙРЃЌЕќДњМЦЛЎАВХХЕШвЛЯЕСаЕФУєНнЪЕМљЁЃ
ВњЦЗОРэЪЧЖдВњЦЗЕФROIИКд№ЃЌИКд№ЪсРэВњЦЗашЧѓЃЌЙцЛЎВњЦЗЙІФмСаБэЃЌШЗЖЈгХЯШМЖЃЌВЮгыЙцЛЎЛюЖЏЃЌВЂбщжЄзюжеЕФНЛИЖГЩЙІЁЃЖдгкscrumРяУцЧПЕїЕФproduct
ownerИќМгЧПЕїУцЯђЪаГЁКЭПЭЛЇЃЌжЛЪЧВЮгыЖјВЛЪЧОпЬхШЅжДааУєНнПЊЗЂЙ§ГЬжаЕФОпЬхЪТЮёРрЛюЖЏЁЃ
УєНнНЬСЗжиЕуЪЧв§ЕМЭХЖгНјааУєНнзЊаЭЃЌЧ§ЖЏУєНнЪЕМљЕФдЫзЊЁЃПЩвдШЋжАЃЌвВПЩвдМцжАЁЃ
03.2 ЭХЖгНсЙЙ
ЭХЖгНсЙЙдкбаЗЂЙ§ГЬжавдзюаЁЛЏЕФЙІФмЭХЖгЃЌвдЙВЭЌЕФМлжЕЙлЃЌЭЈЙ§ПЩЪгЛЏЕФЗНЪНЃЌНєУмКЯзїЃЌЪЕЯжвЕЮёМлжЕЕФПьЫйНЛИЖЁЃЭХЖгзуЙЛаЁЃЌЦфИїИіЭХЖгЯрЛЅЖРСЂЃЌФмЙЛЖРздЭъГЩНЛИЖЁЃ
ЖдгкЭХЖгМмЙЙЃЌЪЕМЪЩЯдкdevopsЙ§ГЬЪЕМљРяУцБОЩэЪЧЖдЭХЖгНсЙЙгавЊЧѓЕФЃЌЖјетИідкДЋЭГЕФУєНнЗНЗЈТлРяУцЪЧВЛЩцМАЕФЁЃБШШчЮвУЧОГЃЬИЕНШчЙћВ№ЗжЮЊСНИіЖРСЂЕФЮЂЗўЮёФЃПщЃЌФЧУДСНИіФЃПщЩцМАЕНЕФЧАЖЫПЊЗЂЃЌЩшМЦЃЌЪ§ОнПтШЫдБЭъШЋЪЧЗжРыЕФЃЌФмЙЛЪЕЯжЖРСЂЙмРэКЭаЭЌЁЃ
ГжајНЛИЖ
ЪзЯШЮвУЧПДЯТГжајМЏГЩЕФЖЈвхЃЌМДГжајМЏГЩЪЧвЛжжШэМўПЊЗЂЪЕМљЃЌМДЭХЖгПЊЗЂГЩдБОГЃМЏГЩЫћУЧЕФЙЄзїЃЌЭЈГЃУПИіГЩдБУПЬьжСЩйМЏГЩвЛДЮЃЌвВОЭвтЮЖзХУПЬьПЩФмЛсЗЂЩњЖрДЮМЏГЩЁЃУПДЮМЏГЩЖМЭЈЙ§здЖЏЛЏЕФЙЙНЈЃЈАќРЈБрвыЃЌЗЂВМЃЌздЖЏЛЏВтЪдЃЉРДбщжЄЃЌДгЖјОЁдчЕиЗЂЯжМЏГЩДэЮѓЁЃ
ДгетИіЖЈвхРяУцПЩвдПДЕНжиЕудкгкМЏГЩСНИізжЃЌМДЖрИіПЊЗЂШЫдБЕФДњТыУПЬьвЊНјаавЛДЮМЏГЩЃЌШчКЮМьбщМЏГЩГЩЙІЃПМДЮвУЧЫЕЕФжДааСЫздЖЏЛЏЕФБрвыЙЙНЈЃЌВЂдЫааздЖЏЛЏЕФВтЪдЁЃ
ЖјдкDevOpsРяУцИќМгЧПЕїГжајНЛИЖЃЌетИіКЭГжајМЏГЩЕФЧјБ№ОЭЪЧГжајНЛИЖЕФећИіЩњУќжмЦкЙ§ГЬИќГЄСЫЃЌУцЯђЕФЪЧзюжеПЭЛЇЃЌзюжеЕФЩњВњЛЗОГЃЌвђДЫВЛЪЧМђЕЅЕФМЏГЩГЩЙІОЭЭъЪТЃЌИќМгживЊЕФОЭЪЧЯђПЭЛЇЃЌЯђЩњВњЛЗОГЕФНЛИЖЪЧГЩЙІЕФЃЌЪЧПЩвдГжајНјааЕФЁЃетЪЧСНепзюДѓЕФЧјБ№ЁЃ
ЮвзюНќдкЯИЖСDevOpsГЩЪьЖШФЃаЭЃЌдйДЮИаОѕећИіФкШнДжПДКмЭъећЃЌЕЋЪЧЯИПДИаОѕОЭКмТвЃЌЦфЬхЯЕЛЏКЭбЯНїГЬЖШКЭCMMIЃЌPMBOKЕШБШНЯЦ№РДВюОрКмДѓЁЃГіРДЕФКмВжДйЃЌЖјЧвКмДѓЕФвЛИіИаОѕОЭЪЧВЮгыБраДШЫдБКмЖрВЛЪЧРДздгквЛЯпDevOpsЯюФПЪЕМљЁЃЮввЛжБЧПЕїЃЌКмЖрЬхЯЕКЭФЃаЭЕФНЈЩшЃЌвЛЖЈЪЧашвЊДѓСПЖрбљадЪЕМљКѓВХФмЙЛЭъГЩКЫаФЭЈгУМлжЕЕФГщЯѓЁЃ
01 ХфжУЙмРэ
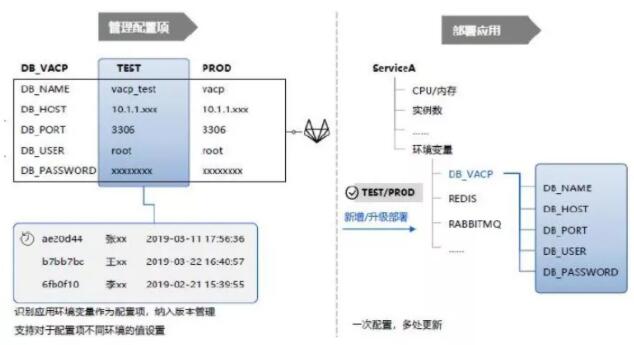
ХфжУЙмРэЪЧЖдЫљгагыЯюФПЯрЙиЕФВњЮяЃЌвдМАЫќУЧжЎМфЕФЙиЯЕЖМБЛЮЈвЛЖЈвхЃЌаоИФЃЌДцДЂКЭМьЫїЕФЙ§ГЬЃЌБЃжЄСЫШэМўАцБОНЛИЖЩњУќжмЦкЙ§ГЬжаЫљгаНЛИЖВњЮяЕФЭъећадЃЌвЛжТадКЭПЩзЗЫнадЁЃХфжУЙмРэЪЧГжајНЛИЖЕФЛљДЁЃЌЪЧБЃеЯГжајНЛИЖе§ШЗадЕФЧАЬсЃЌСМКУЩшМЦЕФХфжУЙмРэВпТдЃЌПЩЬсИпзщжЏазїаЇТЪЃЌИФЩЦВњЦЗМлжЕНЛИЖСїГЬЁЃ
ХфжУЙмРэЗжЮЊСЫАцБОПижЦКЭБфИќЙмРэСНИізгФкШнЃЌЪЕМЪЩЯЖдгкХфжУЙмРэЕФФкШнЃЌЭъШЋПЩвдВЮПМCMMIЖўМЖРяУцЕФХфжУЙмРэЙ§ГЬгђЃЌФкШнЯрЕБРДЫЕИќМгЯИЛЏКЭЭъећЁЃ
ЖдгкАцБОПижЦЪзЯШвЊЬИЕФЕФОЭЪЧВЛНіНіЪЧдДДњТыЃЌЖјЪЧећИіШэМўНЛИЖЙ§ГЬжаЩцМАЕНЕФдДДњТыЃЌХфжУЮФМўЃЌЪ§ОнПтНХБОЃЌЙЄОпЛЗОГЃЌЪ§ОнЃЌВњЦЗЯрЙиЮФЕЕЕШЖМгІИУФЩШыЕНАцБОПижЦЯЕЭГжаНјааЙмРэЁЃ
ЫљгаЕФЩЯЪіФкШнЖМгІИУЖдгІЕНОпЬхЕФАцБОЃЌЭЌЪБЫљгаЕФБфИќЖМгІИУеыЖдЯргІЕФАцБОНјааЃЌгаБфИќвВвЛЖЈЩцМАЕНАцБОБфЛЏЁЃ
ЦфДЮАцБОПижЦРяУцЕФвЛИіжиЕуОЭЪЧЮвУЧГЃЫЕЕФЗжжЇВпТдКЭМЏГЩВпТдЃЌОПОЙгІИУЖЈвхМИИіЗжжЇЃПЗжжЇШчКЮЯђжїИЩКЯВЂЃЌЦЕТЪгжШчКЮЃЌШчКЮЙмРэГхЭЛЖМЪЧгІИУПМТЧЕФЮЪЬтЁЃ
дкDevOpsзюМбЪЕМљРяУцПЩвдПДЕНЃЌвЛЖЈЪЧВЛашвЊЖдПЊЗЂЃЌВтЪдЃЌЩњВњЃЌBugЕШЖМЙЙНЈГіРДВЛЭЌЕФЗжжЇЃЌЬЋЖрЕФЗжжЇБОЩэвВЛсЕМжТЮвУЧЙмРэИДдгЖШЕФдіМгЁЃ
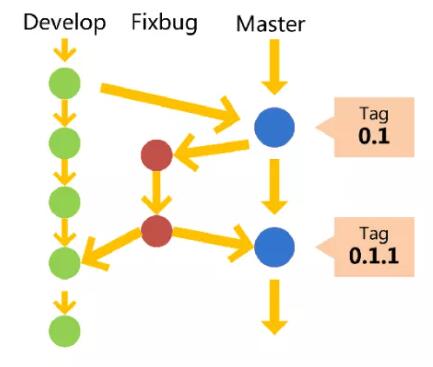
ФЧУДГжајНЛИЖЕФЙ§ГЬжаЃЌЗжжЇШчКЮНЈЩшЪЧвЛжжБШНЯКУЕФЗНАИЃП
ГѕВНЫМПМРДЫЕЃЌжСЩйгІИУЪЧНЈСЂПЊЗЂКЭЩњВњСНИіЗжжЇЃЌЩњВњАцБОЮШЖЈадВЛИпдђдйдіМгBugЗжжЇЃЌМДвЛИіАцБОЫљгаЕФВтЪдЖМЭЈЙ§зМБИЯђЩњВњНЛИЖЕФЪБКђЃЌПЊЗЂЛЗОГЗжжЇДњТыДђБъЧЉКЭЛљЯпЃЌШЛКѓНЋДњТыDeliverЕНЩњВњЗжжЇЁЃетИіЪБКђПЊЗЂЗжжЇПЩвдПЊЪМЯТвЛИіЕќДњАцБОЕФПЊЗЂКЭБфИќЃЌШдШЛЪЧНјааГжајМЏГЩЁЃ
етжжЗНЪНПЩвдНтОіЮвУЧЪЕМЪжаЕФШчЯТМИИіЮЪЬт
ЩњВњЛЗОГБЛЦЦЛЕашвЊжиаТВПЪ№ЕЋЪЧОЕЯёБОЩэвВЖЊЪЇЃЌФЧЮвУЧПЩвддкЩњВњЗжжЇжиаТЙЙНЈВЂВПЪ№
ЩњВњЛЗОГГіЯжBugашвЊаоИДЃЌЮвУЧжБНгдкЩњВњЗжжЇаоИФBugКѓНјааГжајМЏГЩЃЌЕЅЖРЦ№вЛИіBugбщжЄЛЗОГ
НЋBugаоИФЭЌЪБдкЩњВњЗжжЇКЭПЊЗЂЗжжЇНјаааоИФ
ПЩвдПДЕНЃЌШчЙћЮвУЧВЛЯЃЭћзіЕк3ВНЃЌФЧУДЛЙашвЊЦєгУBugЗжжЇЃЌШЛКѓГЏПЊЗЂКЭЩњВњЗжжЇНјааDeliverВйзїЁЃОпЬхЪЧЗёЦєгУBugЗжжЇашвЊПДБОЩэЩњВњЛЗОГАцБОЕФЮШЖЈГЬЖШЁЃ
вдЩЯЪЧеыЖдвЛИіЯюФПЕФЧщПіЃЌЕЋЪЧШчКЮЮвУЧвЛИіШэМўВњЦЗУцЯђЧАЗНЖрИіЯюФПЃЌУПИіЯюФПЖМПЩФмДцдкЖЈжЦПЊЗЂЕФЪБКђШчКЮДІРэЃПетИівВЪЧЮвУЧПЊЗЂЭХЖгОГЃЛсгіЕНЕФКмЯжЪЕЕФЮЪЬтЁЃ
ФЧЮвУЧРДПДЯТШчЙћЯждкашвЊжЇГХAЃЌBЃЌCШ§ИіЯюФПЕФШэМўЖЈжЦЛЏашЧѓПЊЗЂЁЃЪЕМЪЩЯЮвУЧашвЊдкжїИЩЗжжЇЩЯРШЁШ§ИіЖРСЂЕФЗжжЇГіРДНјааЖЈжЦЛЏПЊЗЂЃЌИїЯюФПЖЈжЦЕФФкШнНіНіЪЪгУгкИїИіЯюФПБОЩэЁЃ
вЛИіЙВадЙІФмЕФЬэМгЃПашвЊдкжїИЩЗжжЇЭъГЩЃЌШЛКѓDeliverЕНШ§ИіЖРСЂЗжжЇЁЃ
вЛИіBugаоИФЃПШчКЮAЯюФПЗЂЯжЙВадBugЃЌA-BugЗжжЇаоИФЃЌШЛКѓDevlierжїИЩЃЌдйDeliverЕНBКЭCЗжжЇЁЃ
вђДЫвВПЩвдПДЕНЃЌЖЈжЦЛЏЕФЯюФПдНЖрЃЌЮвУЧЪЕМЪЩЯЙмРэЦ№РДОЭдНИДдгЁЃШчКЮжЦЖЈИќКУЕФЗжжЇЙмРэВпТдЪЧЦфвЛЃЌИќМгживЊЕФЪЧШчКЮЛЎЗжКУЮЂЗўЮёФЃПщЃЌШУЙВадФЃПщОЁСПЙВадЛЏЬсЙЉЙЋЙВФмСІЃЌМДЖдгІЛљДЁЙВадФЃПщВЛДцдкУцЖдИїИіЖРСЂЯюФПашвЊЖРСЂЦ№ЗжжЇЧщПіЃЌЫљгаЯюФПЖМгУвЛИіЗжжЇЃЌвЛЬзДњТыРДжЇГХЁЃ
БфИќЙмРэЪЧжИШэМўЯЕЭГжаЕФЫљгаБфИќЖМПЩвдзЗЫнБфИќЕФЯъЯИаХЯЂМЧТМЃЌВЂЯђЩЯзЗЫнБфИќЕФдЪМашЧѓЃЌСїзЊЙ§ГЬЕШЫљгаЙиСЊаХЯЂЁЃжївЊАќРЈБфИќЙ§ГЬЃЌБфИќзЗЫнКЭБфИќЛиЙіШ§ЗНУцЁЃПЩзЗЫнадЪЧАцБОЛиЙіЕФРњЪЗвРОнКЭЪЕЪЉЛљДЁЃЌНЈСЂСМКУЕФАцБОПЩзЗЫнадПЩЪЕЯжЖдШЮвЛАцБОЭъећЛЗОГСїГЬЕФздЖЏЛЏЃЌОЋШЗЛиЙіЃЌПьЫйжиЯжЮЪЬтКЭЛжИДе§ГЃЛЗОГЁЃ
БфИќЙ§ГЬДгБфИќЧыЧѓЗЂЦ№ПЊЪМЃЌвЛжБЕНБфИќгАЯьЗжЮіЃЌБфИќЛюЖЏжДааЃЌБфИќбщжЄЙиБевЊаЮГЩБеЛЗЕФСїГЬЃЌЭЌЪБЫљгаЕФБфИќЖМЩцМАЕНЖдХфжУЯюЕФаоИФЃЌашвЊНјааЖдгІЃЌВХПЩФмЪЕЯжБфИќЕФШЋСїГЬПЩзЗЫнЁЃ
ФЧЮвУЧдйРДПДЯТБфИќЕФЛиЙіЃЌПЩвдПДЕНШчЙћвЛИіаЁАцБОга3ИіБфИќаоИФЃЌШчЙћЖМвЊЛиЙіЯрЖдШнвзЃЌЮвУЧПЩвджБНгЭЫЛиЕНЩЯвЛИіЛљЯпАцБОЃЌЕЋЪЧШчЙћжЛЛиЙіРяУцвЛИіБфИќЖдДњТыЮФМўЕФаоИФЃЌЯрЖдРДЫЕОЭВЛШнвзЃЌОЭЛЙЪЧашвЊШЫЙЄШЅДІРэКЭЪЖБ№ОпЬхашвЊЛиЙіЕФФкШнЁЃ
02 ЙЙНЈгыГжајМЏГЩ
ЙЙНЈЪЧНЋШэМўдДДњТыЭЈЙ§ЙЙНЈЙЄОпзЊЛЛЮЊПЩжДааГЬађЕФЙ§ГЬЃЌвЛАуАќКЌБрвыКЭСДНгСНИіВНжшЃЌНЋИпМЖДњТыгябдзЊЛЏЮЊПЩжДааЕФЛњЦїДњТыВЂНјааЯргІЕФгХЛЏЃЌЬсЩ§дЫаааЇТЪЁЃ
ЙЙНЈЪЕМљЪЧЙизЂШэМўДњТыЕНПЩдЫааГЬађжЎМфЕФЙ§ГЬЃЌЭЈЙ§ЙцдђЃЌзЪдДКЭЙЄОпЕФгааЇНсКЯЃЌЬсЩ§ЙЙНЈжЪСПКЭЙЙНЈЫйЖШЃЌЪЙЙЙНЈГЩЮЊвЛИіЧсСПМЖЃЌПЩПППЩжиИДЕФЙ§ГЬЁЃЙЙНЈзюжеЕФВњЮяВЩгУЧхЮњЕФАцБОНјааБъЪЖЃЌЙЙНЈВњЮяПЩвдзЗЫнЃЌПЩЛиЙіЁЃ
ЙЙНЈЪЕМљБОЩэАќРЈСЫЙЙНЈЗНЪНЃЌЙЙНЈЛЗОГЃЌЙЙНЈМЦЛЎКЭЙЙНЈжАд№ЫФИіВПЗжЕФФкШнЁЃ
ЖдгкЙЙНЈЪЕМљБОЩэзюЛљБОЕФвЊЧѓОЭЪЧЭЈЙ§ЙЙНЈНХБОЪЕЯжЙЙНЈЙ§ГЬздЖЏЛЏЃЌЭЌЪБгазЈУХЕФЙЙНЈЛЗОГКЭЗўЮёЦїЁЃдкШ§МЖЧПЕїЙЙНЈНХБОИДгУКЭПЩЙмРэадЃЌЙЙНЈЛЗОГХфжУЕФБъзМЛЏЃЛдкЫФМЖЧПЕїЙЙНЈЙ§ГЬЕФПЩЪгЛЏБрХХЃЌЙЙНЈзЪдДЕФЖЏЬЌЗжХфКЭЛиЪеЃЌЛљгкШнЦїЛЏЕФЗжВМЪНМЏШКЕФгІгУЁЃ

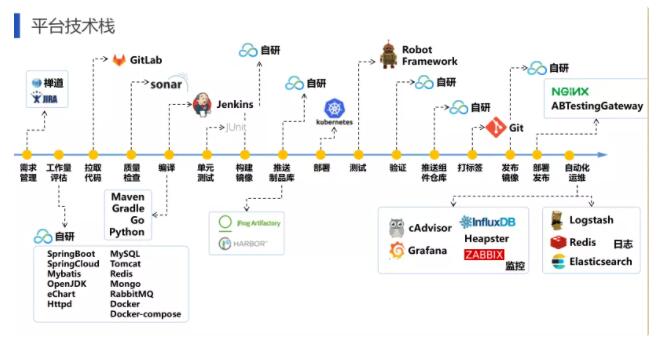
ЖдгкJavaЯюФПЃЌЮвУЧвЛАуЛсВЩгУJekinsНјааГжајЙЙНЈКЭМЏГЩЁЃ
JenkinsЪЧвЛИіПЊдДЕФЁЂЬсЙЉгбКУВйзїНчУцЕФГжајМЏГЩ(CI)ЙЄОпЃЌЦ№дДгкHudsonЃЈHudsonЪЧЩЬгУЕФЃЉЃЌжївЊгУгкГжајЁЂздЖЏЕФЙЙНЈ/ВтЪдШэМўЯюФПЁЂМрПиЭтВПШЮЮёЕФдЫааЃЈетИіБШНЯГщЯѓЃЌднЧваДЩЯЃЌВЛзіНтЪЭЃЉЁЃJenkinsгУЁЂЙЙНЈЙЄОпНсКЯЪЙгУЁЃГЃгУЕФАцБОПижЦЙЄОпгаSVNЁЂGITЃЌЙЙНЈЙЄОпгаMavenЁЂAntЁЂGradleЁЃ
ГжајМЏГЩЪЧШэМўЙЄГЬСьгђжаЕФвЛжжзюМбЪЕМљЃЌМДЙФРјбаЗЂШЫдБЦЕЗБЕФЯђжїИЩЗжжЇЬсНЛДњТыЃЌЦЕТЪЮЊжСЩйУПЬьвЛДЮЁЃУПДЮЬсНЛЖМДЅЗЂЭъећЕФБрвыЙЙНЈКЭздЖЏЛЏВтЪдСїГЬЃЌЫѕЖЬЗДРЁжмЦкЃЌМАЪБаоИДЮЪЬтЃЌДгЖјБЃжЄШэМўДњТыжЪСПЃЌМѕЩйДѓЙцФЃДњТыКЯВЂЕФГхЭЛКЭЮЪЬтЁЃ
ИУЙ§ГЬжївЊАќРЈСЫМЏГЩЗўЮёЃЌМЏГЩЦЕТЪЃЌМЏГЩЗНЪНКЭЗДРЁжмЦкЫФИіЗНУцЕФФкШнЁЃ
ЖдгкГжајМЏГЩЃЌвЛЗНУцЪЧЪЕЯжБрвыЙЙНЈЙ§ГЬЕФздЖЏЛЏЃЌвЛЗНУцЪЧЪЕЯжВтЪдЙ§ГЬЕФздЖЏЛЏЃЌЭЌЪБСНепжЎМфФмЙЛзіЕНИпаЇаЭЌЁЃЖдгкЦфЫќГжајМЏГЩЕФФкШнЃЌдкЩЯЦЊЮФеТвбОзіСЫЯъЯИУшЪіЃЌдйДЮВЛдйеЙПЊЁЃ
ЖдгкГжајМЏГЩЙ§ГЬКЭНЛИЖЙ§ГЬжаЛсЪЙгУЕНДѓСПЕФПЊдДЙЄОпММЪѕНјааМЏГЩЃЌЦфжаАќРЈСЫХфжУЙмРэЃЌБрвыЙЙНЈЃЌздЖЏЛЏВПЪ№ЃЌздЖЏЛЏВтЪдЕШИїИіЩњУќжмЦкЙ§ГЬЃЌОпЬхШчЯТЃК
03 ВтЪдЙмРэ
ВтЪдЙмРэЪЧвЛИіЙ§ГЬЃЌЭЈЙ§ИУЙ§ГЬЃЌЫљгаКЭВтЪдЯрЙиЕФЗНЗЈЃЌСїГЬЃЌШЫдБЖМБЛЖЈвхЁЃдкВњЦЗЭЖШыЕНЩњВњЛЗОГдЫаажЎЧАЃЌЭЈЙ§ВтЪдЙ§ГЬбщжЄВњЦЗЕФашЧѓЃЌОЁПЩФмЕиЗЂЯжШэМўжаЕФШБЯнЃЌДгЖјЬсИпШэМўВњЦЗЕФжЪСПЁЃВтЪдЙмРэЗжЮЊВтЪдЗжВуВпТдЃЌДњТыжЪСПЙмРэКЭздЖЏЛЏВтЪдШ§ИіЮЌЖШНјааБэДяЁЃ
ВтЪдЗжВуВпТд

ЮвУЧРДЬИЯТгаФФаЉВтЪдЗжРрЕФЗНЗЈЃЌдкГжајМЏГЩРяУцЮвУЧЕБШЛИќМгЛсЧПЕїздЖЏЛЏВтЪдЃЌвђДЫПЩвдРэНтЮЊШЫЙЄВтЪдКЭздЖЏЛЏВтЪдСНРрЃЛвВПЩвдРыПЊЮЊДњТыМЖВтЪдЃЌНгПкВтЪдКЭЧАЖЫВтЪдЗжРыЁЃвВПЩвдРэНтЮЊЙІФмВтЪдКЭЗЧЙІФмВтЪдСНРрЁЃ
ЕБШЛвВПЩвдПДЕНЃЌдкЮЂЗўЮёМмЙЙЯТЃЌЮвУЧЯЃЭћЮвУЧБОЩэЕФПЊЗЂвВЪЧЗжВуЕФЃЌМДжаЬЈФЃПщ+ЗўЮёНгПк+ЧАЬЈЙІФмЃЌМДЮвУЧЭЈГЃЫЕЕФЧАКѓЖЫЗжРыЃЌдкетжжЧАКѓЖЫЗжРыЕФЧщПіЯТЃЌПЩвдИќМгЗНБуЮвУЧНјааВтЪдЗжВуЩшМЦКЭздЖЏЛЏВтЪдЁЃжЛвЊЪЧКёжаЬЈ+БЁЧАЬЈФЃЪНЃЌФЧУДОЭдНШнвзЪЕЯжВтЪдЙ§ГЬЕФздЖЏЛЏЁЃ
дНЪЧГжајМЏГЩздЖЏЛЏГаЕЃдНИпЃЌФЧУДздЖЏЛЏВтЪдЕФБШжиОЭЛсдНДѓЁЃ
ПЩвдПДЕНЪзЯШдкМмЙЙЩшМЦЩЯОЭвЊзіЕНЧАКѓЖЫЗжРыЃЌжаЬЈ+ЗўЮё+ЧАЬЈЃЌетжжЗжРыКѓПЩвдИќМгЗНБуКѓУцНјааКѓЖЫДњТыКЭНгПкЕФздЖЏЛЏВтЪдЙЄзїЁЃ
ПЩвдПДЕНдкВтЪдЗжВуВпТдРяУцЕФЫФЕНЮхМЖУшЪіРяУцЃЌЮвУЧПДЕНTDDВтЪдЧ§ЖЏПЊЗЂЗНУцЕФФкШнЃЌБШШчЯШаДВтЪдДњТыдйаДЪЕЯжДњТыЛђепСНепЭЌЪБдкНјааЕШЁЃЦфДЮЃЌЮвУЧЛЙЪЧвЊНЋдкећИіdevopsзюМбЪЕМљРяУцЃЌВЛНіНіПЊЗЂЙ§ГЬЪЧГжајдіСПНјааЕФЃЌЖдгкВтЪдЙ§ГЬБОЩэвВЪЧГжајдіСПНјааЕФЃЌСНепБиаыЦЅХфЁЃ
ЛђепРэЯызДЬЌгІИУЪЧУЛгаЖРСЂЕФВтЪджмЦкЃЌПЊЗЂЭъГЩЕФНзЖЮЭљЭљОЭЪЧВтЪдвВХфЬзЭъГЩЕФЪБМфЕуЁЃ
ДњТыжЪСПЙмРэ
ЪЧШэМўбаЗЂЙ§ГЬжаБЃжЄДњТыжЪСПЕФвЛжжЛњжЦЃЌМДдкДњТыБфИќКѓЃЌашвЊЖдДњТыНјааМьВщЃЌЗжЮіЃЌВЂИјГіНсТлКЭИФНјНЈвщЃЌЖдДњТыжЪСПЪ§ОнНјааЙмРэЃЌВЂПЩвдЖдДњТыжЪСПНјаазЗЫнЁЃжївЊАќРЈСЫжЪСПЙцдМЃЌМьВщЗНЪНЃЌЗДРЁДІРэШ§ЗНУцЕФФкШнЁЃ
ДњТыжЪСПЙмРэМДЮвУЧГЃЫЕЕФДњТыОВЬЌМьВщЃЌЦфЛљгкЮвУЧжЦЖЈЕФДњТыжЪСПЙцдМНјааЁЃжЪСПЙцдМЪЧжИЖдШэМўДњТыжЪСПЕФвЊЧѓКЭЙцЗЖЃЌЦфжаАќКЌСЫБрТыЙцЗЖЃЌИДдгЖШЃЌИВИЧТЪЃЌвдМААВШЋТЉЖДЃЌКЯЙцадвЊЧѓЕШЖрИіЗНУцЕФФкШнЁЃЦфжаМьВщЗНЪНМДАќРЈСЫЮвУЧДЋЭГЪжЙЄЗНУцЕФМьВщКЭCodeReviewЃЌвВАќРЈСЫдЫааЯрЙиЕФздЖЏЛЏМьВщЙЄОпНјааМьВщЁЃ
здЖЏЛЏВтЪд
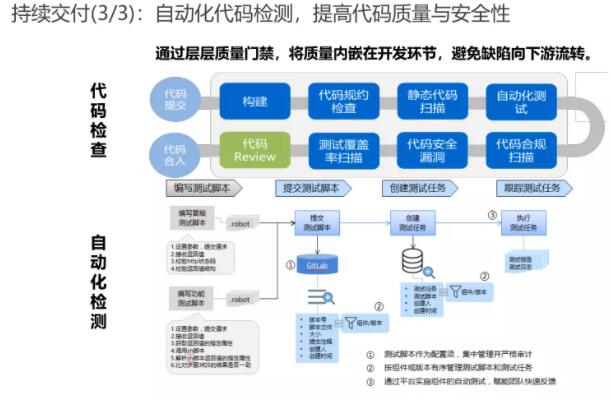
здЖЏЛЏВтЪдЪЧАбвдШЫЮЊЧ§ЖЏЕФВтЪдааЮЊзЊЛЏЮЊЛњЦїжДааЕФвЛжжЙ§ГЬЃЌдкдЄЩшЬѕМўЯТдЫааЯЕЭГЛђгІгУГЬађЃЌжДааВтЪдВЂЦРЙРВтЪдНсЙћЃЌвдДяЕННкЪЁзЪдДКЭШЫСІЃЌЬсИпВтЪдаЇТЪКЭзМШЗадЃЌжївЊАќРЈСЫздЖЏЛЏЩшМЦЃЌздЖЏЛЏПЊЗЂЃЌздЖЏЛЏжДааКЭздЖЏЛЏЗжЮіЁЃ
ЖдгкздЖЏЛЏВтЪдПЩвдПДЕНЃЌЖдгкЗўЮёНгПкКЭДњТыМЖЕФздЖЏЛЏВтЪдЯрЖдРДЫЕБШНЯШнвзЪЕЯжЃЌЕЋЪЧЖдгкЧАЖЫКЭUIМЖЕФздЖЏЛЏВтЪдЯрЖдРДЫЕОЭБШНЯРЇФбаЉЁЃвђДЫЖдгкЧАЦкЪЕМљЃЌЮвУЧвВЪЧНЈвщЯШЪЕЯжНгПкЗўЮёКЭДњТыМЖЕФздЖЏЛЏВтЪдЃЌдйРДППЧАЖЫUIЕФздЖЏЛЏВтЪдЁЃ
ЖдгкадФмВтЪдгЩгкПЩвдЬсЧАТМжЦНХБОЃЌЯрЖдРДЫЕздЖЏЛЏВтЪдЪЕЯжЦ№РДБШНЯШнвзЁЃВЛТлЪЧФЧжжРраЭЕФздЖЏЛЏВтЪдЖМПЩвдПДЕНЃЌЪЕМЪЩЯПЩвдПДЕНШчЯТМИИіЙиМќЕуЁЃ
здЖЏЛЏВтЪдДњТыЛђНХБОЕФБраДЃЌПЩвдЪЧШЫЙЄБраДЃЌвВПЩвдЭЈЙ§ТМжЦЩњГЩЁЃ
ВтЪдЪ§ОнЕФВњЩњЮЪЬтЃЌжДааздЖЏЛЏВтЪдЧАЭљЭљЖМЩцМАЕНВтЪдЪ§ОнЕФВњЩњКЭЪЙгУЃЌВЮПМВтЪдЙмРэЙ§ГЬгђ
здЖЏЛЏВтЪдНХБОФмЙЛжиИДжДааЕФвЊЧѓЃЌетЕуБиаывЊзіЕНЃЌШЗБЃУПДЮГжајМЏГЩЖМФмЙЛжиИДдЫааВтЪдНХБО
ЕНСЫздЖЏЛЏВтЪдЕФЕкЫФМЖПЊЪМЃЌПЩвдПДЕНдіМгСЫЖдЖРСЂЕФздЖЏЛЏВтЪдЦНЬЈЕФвЊЧѓЃЌЭЌЪБвВдіМгСЫЖдВтЪдНсЙћЗжЮіКЭЖШСПЕФвЊЧѓЃЌМДЭЈЙ§ВтЪдНсЙћЕФЖШСПЗжЮіРДНјвЛВНИФНјВтЪдаЇТЪЃЌЬсЩ§ДњТыжЪСПЁЃ
4.ВПЪ№КЭЗЂВМЙмРэ
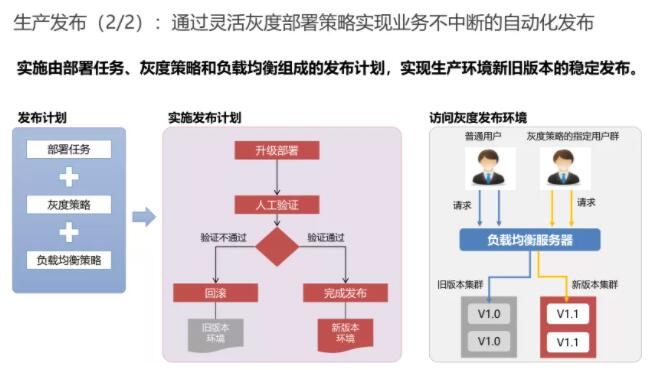
ВПЪ№КЭЗЂВМЗКжИШэМўЩњУќжмЦкжаЃЌНЋШэМўгІгУЯЕЭГЖдгУЛЇПЩМћЃЌВЂЬсЙЉЗўЮёЕФвЛЯЕСаЛюЖЏЃЌАќРЈЯЕЭГХфжУЃЌЗЂВМЃЌАВзАЕШЁЃећИіВПЪ№КЭЗЂВМЙ§ГЬИДдгЃЌЭљЭљЩцМАЕНЖрИіЭХЖгжЎМфЕФаЭЌКЭНЛЛЅЃЌашвЊСМКУЕФМЦЛЎКЭбнСЗРДБЃжЄВПЪ№ЗЂВМЙ§ГЬЕФе§ШЗадЁЃ
ВПЪ№ЦЋММЪѕЪЕМљЃЌМДШэМўДњТыЃЌгІгУЃЌХфжУКЭЪ§ОнПтБфИќЕНВтЪдКЭЩњВњЛЗОГЕФЙ§ГЬЁЃЖјЗЂВМЦЋвЕЮёЪЕМљЃЌЪЧжИНЋВПЪ№ЭъГЩЕФгІгУШэМўЙІФме§ЪНЖдгУЛЇПЩМћЕФЙ§ГЬЃЌЬсЙЉЯпЩЯЗўЮёЕФЙ§ГЬЁЃМДВПЪ№ЭъСЫВЛвЛЖЈОЭТэЩЯЖдвЕЮёКЭгУЛЇПЩМћЃЌЖјжЛгаЗЂВМКЭХфжУЭъСЫВХЖдгУЛЇПЩМћЃЌетбљвВОЭИќКУРэНтЛвЖШЗЂВМЕФИХФюСЫЁЃ
ВПЪ№КЭЗЂВМФЃЪН
ВПЪ№КЭЗЂВМФЃЪНЙизЂНЛИЖЙ§ГЬжаЕФОпЬхЪЕМљЃЌНЋВПЪ№ЛюЖЏздЖЏЛЏВЂЧАвЦЕНПЊЗЂНзЖЮЃЌЭЈЙ§ЦЕЗБЕФбнСЗКЭЪЕМљВПЪ№ЛюЖЏЃЌГЩЮЊбаЗЂШеГЃЙЄзїЕФвЛВПЗжЃЌДгМѕЩйзюжеВПЪ№ЕФРЇФбКЭВЛШЗЖЈадЃЌПЩПППЩжиИДЕФЭъГЩВПЪ№ЗЂВМШЮЮёЁЃ
зюЛљБОЕФвЊЧѓЪЧећИіВПЪ№СїГЬБъзМЛЏКЭЙцЗЖЛЏЃЌЭЌЪБЭЈЙ§здЖЏЛЏЕФВПЪ№НХБОНјааВПЪ№ВйзїЁЃдкШ§МЖОЭвЊЧѓВПЪ№Й§ГЬЪЕЯжШЋздЖЏЛЏЃЌЭЌЪБгІгУКЭЛЗОГзіЮЊВПЪ№ЕФзюаЁЕЅЮЛЃЌгІгУКЭХфжУНјааЗжРыЁЃдкЫФМЖвЊЧѓВПЪ№Й§ГЬСщЛюПЩБрХХПЩХфжУЃЌПЩвдвЛДЮздЖЏВПЪ№ЖрЛЗОГЃЌПЩвджЇГжЛвЖШЗЂВМЁЃ
НЈСЂГжајгХЛЏЕФВПЪ№МрПиЛњжЦЃЌВПЪ№ЧАФмЙЛНјааздЖЏЛЏЕФВтЪдЃЌВПЪ№ЪЇАмФмЙЛздЖЏЛиЙіЁЃ
ВПЪ№СїЫЎЯп
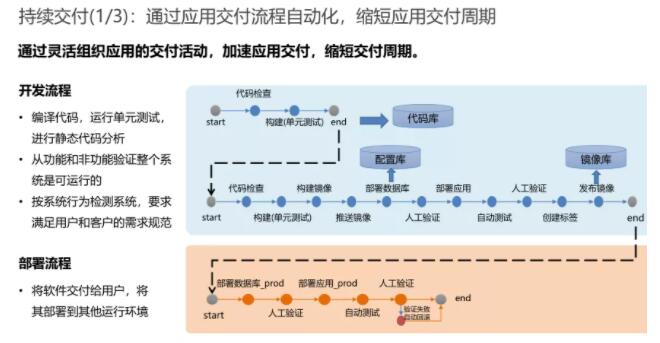
ВПЪ№СїЫЎЯпЪЧDevOpsЕФКЫаФЪЕМљЃЌЭЈЙ§ПЩППЃЌПЩжиИДЕФСїЫЎЯпЃЌДђЭЈЖЫЕНЖЫЕФМлжЕНЛИЖЃЌЪЕЯжНЛИЖЙ§ГЬжаИїИіЛЗНкЛюЖЏЕФздЖЏЛЏКЭПЩЪгЛЏЁЃВПЪ№СїЫЎЯпЭЈЙ§НЋИДдгЕФШэМўНЛИЖСїГЬЯИЗжЮЊЖрИіНзЖЮЃЌУПИіНзЖЮВуВуЕнНјЃЌЬсЩ§ШэМўНЛИЖжЪСПЕФаХЯЂЃЌВЂЧвдкСїЫЎЯпЙ§ГЬжаЬсЙЉПьЫйЗДРЁЃЌМѕЩйКѓЖЫЛЗНкРЫЗбЁЃ
зЂвтдкШ§МЖРяУцСїЫЎЯпЙ§ГЬЧПЕїСЫДђЭЈШэМўНЛИЖЙ§ГЬжаЕФИїИіЛЗНкЃЌНЈСЂШЋСїГЬЕФздЖЏЛЏФмСІЃЌВЂИљОнздЖЏЛЏВтЪдНсЙћБЃжЄШэМўНЛИЖжЪСПЁЃдкЫФМЖЧПЕїСЫПЩЪгЛЏЕФВПЪ№СїЫЎЯпИВИЧећИіШэМўНЛИЖЙ§ГЬЃЌУПДЮБфИќЖМЛсДЅЗЂЭъећЕФздЖЏЛЏВПЪ№СїЫЎЯпзївЕЁЃ
ЖдгкПЩЪгЛЏЕФВПЪ№СїЫЎЯпЃЌЮвШдШЛМсГжЮвЕФЙлЕуЃЌМДвЛЖЈгавЛИіЖЅВуСїЫЎЯпЪЧВЛНіНіЪЧМђЕЅЕФЕНГжајМЏГЩЙ§ГЬЭъГЩЃЌЖјЪЧИВИЧЕНећИіДгsitЕНuatЃЌДгuatЕНЩњВњЕФЛЗОГЧЈвЦЙ§ГЬЁЃМђЕЅРДЫЕЃЌЕНЩњВњЕФЛЗОГЧЈвЦБОЩэОЭЪЧвЛИіГжајНЛИЖЕФЙ§ГЬЁЃ
ЕНЩњВњЕФНЛИЖБОЩэПЩвдЪЧЖРСЂЕФзгСїЫЎЯпЃЌвђДЫЮвУЧдкСїЫЎЯпЩшМЦЩЯУцжЇГжЗжВуЪЧЯрЕБживЊЕФвЛИіЙІФмЁЃШчЙћЪЧСНИіЖРСЂЕФСїЫЎЯпЃЌФЧУДвЛЖЈДцдкЖЯЕуЃЌЕЋЪЧЭъећЕФГжајМЏГЩКЭНЛИЖЙ§ГЬвЛЖЈЪЧДгашЧѓКЭБфИќПЊЪМЖЫЕНЖЫЧ§ЖЏЕФЃЌЖјВЛЪЧЫцвтПЩвдДЅЗЂжДааЕФЁЃ
5.ЛЗОГЙмРэ
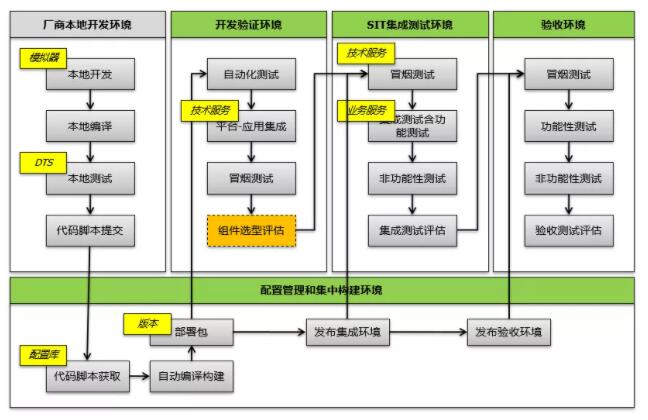
ЛЗОГзіЮЊDevOpsГжајНЛИЖЙ§ГЬжазюжеГадиЃЌАќРЈЛЗОГЕФЩњУќжмЦкЙмРэЃЌвЛжТадЙмРэЃЌЛЗОГЕФАцБОЙмРэЃЌЛЗОГЙмРэЪЧгУзюаЁЕФДњМлРДДяЕНКЭШЗБЃвЛжТадЕФжеМЋФПБъЃЌжївЊАќРЈЛЗОГРраЭЃЌЛЗОГЙЙНЈЃЌЛЗОГвРРЕКЭХфжУЙмРэМИИіВПЗжЕФФкШнЁЃ
ЖдгкДѓаЭЯюФПРДЫЕЃЌЮвУЧПЩвдПДЕНЛсАќРЈСЫDEVПЊЗЂЛЗОГЃЌSITМЏГЩВтЪдЛЗОГЃЌUATгУЛЇбщЪеВтЪдЛЗОГКЭPRDЩњВњЛЗОГЫФЬзЛЗОГЃЌИќИДдгЕФЭљЭљЛЙгадЄЩњВњЗЂВМЛЗОГЃЌЩњВњПЫТЁЛЗОГЕШЁЃ
ЖдгкDEVПЊЗЂВтЪдЛЗОГЕФзїгУжївЊЪЧЗНБуПЊЗЂВтЪдНзЖЮЕФЖрИіЮЂЗўЮёФЃПщжЎМфЕФНгПкСЊЕїЃЌетаЉЕНСЫSITМЏГЩВтЪдНзЖЮзіЯдШЛЪЧВЛКЯЪЪЕФЃЌШчЙћВЛОпБИПЊЗЂВтЪдЛЗОГОЭашвЊПЊЗЂШЫдБЛњЦїСЌНгЕНSITЛЗОГЕФНгПкЗўЮёНјааСЊЕїЃЌетжжЧщПіЯдШЛвВВЛЬЋКЯЪЪЁЃЭЌЪБЖдгкDEVПЊЗЂВтЪдЛЗОГвВЗНБуЮвУЧШЅдЫааздЖЏЛЏВтЪдНХБОНјааздЖЏЛЏВтЪдЁЃ
ЖдгкSITМЏГЩВтЪдКЭUATВтЪдЃЌЪЕМЪжиЕуЖМЛсЦЋКкКаВтЪдСЫЃЌжСЩйгІИУШЗБЃгавЛЬзКкКаВтЪдЛЗОГЁЃ
дкШ§МЖРяУцОЭвбОЧПЕїашвЊгаЖРСЂЕФПЊЗЂВтЪдЛЗОГЃЌЭЌЪБЛЗОГЕФзМБИФмЙЛДяЕНаЁЪБМЖЭъГЩЃЌЭЌЪБгжвдгІгУЮЊжааФЃЌгаЗўЮёМЖвРРЕЕФХфжУЙмРэФмСІЃЌБШШчвРРЕЕФЙиСЊЗўЮёЃЌЪ§ОнПтЗўЮёЃЌЛКДцЗўЮёЕШЁЃдкЫФМЖЧПЕїНЈСЂШЋУцЕФВтЪдКЭЛвЖШЛЗОГЃЌЛЗОГЕФЙЙНЈПЩвдЭЈЙ§ШнЦїЛЏПьЫйНЛИЖЃЌЖјЧвДяЕНЗжжгМЖЁЃ
ЛЗОГЪЧЖРСЂЕФХфжУЙмРэЖдЯѓЃЌЛЗОГвРЭагкОпЬхЕФащФтЛЏзЪдДЛђШнЦїзЪдДЃЌЭЌЪБВЛЭЌЛЗОГгаВЛЭЌЕФВювьЛЏХфжУЮФМўЃЌХфжУЮФМўвРРЕгкВЛЭЌЕФЛЗОГЖдЯѓЁЃ
вЛИіДѓЕФгІгУЭљЭљЛсЗжЮЊЖрИіЮЂЗўЮёФЃПщЃЌУПИіЮЂЗўЮёФЃПщЭъШЋЖРСЂЙмРэЃЌвђДЫЖМПЩвдзіЕНЖРСЂЕФЖЈвхЛЗОГКЭЛЗОГХфжУБфСПаХЯЂЁЃДѓгІгУКЭЖрИіЮЂЗўЮёФЃПщМфБОЩэвВЪЧвЛжжЫЩёюКЯЕФЙиЯЕЁЃ
вЛИіЪЧЛЗОГЕФзМБИКЭНЈСЂПЩвдзіЕНПьЫйЃЌБШШчЮвУЧГжајМЏГЩвбОе§ГЃдЫааЃЌЮвУЧПЩвдПьЫйЕФзМБИвЛЬзбнЪОЛЗОГИјПЭЛЇЪЙгУЃЌЭЌЪБвВвЊзіЕНЛЗОГКЭзЪдДЫЩёюКЯЃЌЛЗОГПЩвдзіЕНПьЫйЕФЯњЛйвдЛиЪезЪдДЁЃ
6.Ъ§ОнЙмРэ
ЯЕЭГПЊЗЂЙ§ГЬжаЮЊСЫТњзуВЛЭЌЛЗОГЕФВтЪдашЧѓЃЌвдМАБЃжЄЩњВњЪ§ОнЕФАВШЋЃЌашвЊШЫЮЊзМБИЪ§ОнХгДѓЕФВтЪдЪ§ОнЃЌашвЊБЃжЄЪ§ОнЕФгааЇадвдЪЪгІВЛЭЌЕФгІгУГЬађАцБОЁЃСэЭтгІгУГЬађдкдЫааЙ§ГЬжаЛсВњЩњДѓСПЪ§ОнЃЌетаЉЪ§ОнКЭгІгУБОЩэЕФЩњУќжмЦкВЛЭЌЃЌзіЮЊгІгУзюгаМлжЕЕФФкШнашвЊЭзЩЦБЃДцЃЌВЂЫцгІгУГЬађЕФЩ§МЖКЭЛиЙіНјааЧЈвЦЁЃ
ВтЪдЪ§ОнЙмРэ

ВтЪдЪ§ОнгІИУТњзуЖржжВтЪдРраЭЕФашЧѓЃЈЪжЙЄВтЪдЃЌздЖЏЛЏВтЪдЃЉЃЌИВИЧе§ГЃзДЬЌЃЌДэЮѓзДЬЌКЭБпНчзДЬЌЃЌВтЪдЪ§ОнгІИУЭЌЪБТњзуВтЪдаЇТЪКЭЪ§ОнСПЕФвЊЧѓЃЌВтЪдЪ§ОнЕФЪфШыашвЊЪмПиЃЌВЂдЫаадкЪмПиЛЗОГжаЃЌБЃжЄЪфГіЕФгааЇадЁЃЮЊСЫФЃФтЩњВњЛЗОГЧщПіЃЌЭљЭљашвЊВЩгУЗТЩњВњЪ§ОнЃЌЪЙгУЪБКђашвЊзЂвтАВШЋКЭЭбУєЁЃ
Ъ§ОнРДдДЃКзюЛљБОЪЧздМКЪжЙЄЪфШыЃЌЦфДЮЪЧЩњВњЛЗОГЕМГідйЕМШыВтЪдЛЗОГЃЌДІРэЙ§ГЬжаашвЊЧхЯДКЭЭбУєЁЃдйЫФМЖПЊЪМЧПЕїСЫашвЊгаФмСІФмЙЛЭЈЙ§ДњТыЛђapiНгПкЕїгУРДздЖЏЩњВњТњзуашвЊЕФВтЪдЪ§ОнЁЃ
Ъ§ОнИВИЧЃКдкЖўМЖжЛЧПЕїСЫВтЪдЪ§ОнИВИЧжївЊГЁОАЃЌАќРЈе§ГЃЃЌвьГЃДэЮѓКЭБпНчГЁОАЁЃЖјЕНСЫШ§МЖЃЌЧПЕїашвЊНЈСЂЬхЯЕЛЏВтЪдЪ§ОнЃЌНјааЪ§ОнвРРЕЙмРэЃЌИВИЧШЋВПВтЪдЗжВуВпТдвЊЧѓЕФВтЪдРраЭЁЃ
Ъ§ОнЖРСЂадЃКдкЖўМЖЧПЕїСЫВтЪдЪ§ОнгаУїШЗЕФБИЗнЛжИДЛњжЦЃЌЭЌЪБЪЕЯжВтЪдЪ§ОнИДгУКЭБЃжЄВтЪдвЛжТадЁЃдкШ§МЖПЊЪМЧПЕїВтЪдгУР§ЕФжДааВЛвРРЕЦфЫќВтЪдгУР§жДааЫљВњЩњЕФЪ§ОнЁЃМѕЩйВтЪдЪ§ОнМфЕФвРРЕЙиЯЕЁЃ
Ъ§ОнБфИќЙмРэ
Ъ§ОнБфИќЙмРэЪЧжИгІгУГЬађЩ§МЖКЭЛиЙіЙ§ГЬжаЕФЪ§ОнПтНсЙЙКЭЪ§ОнЕФБфИќЃЌСМКУЕФБфИќВпТдгІБЃжЄгІгУАцБОКЭЪ§ОнПтАцБОМцШнЦЅХфЃЌвдгІЖдгІгУЕФПьЫйРЉШнЫѕШнЕШЯпЩЯГЁОАЁЃЭЈЙ§гІгУБфИќКЭЪ§ОнБфИќЕФНтёюЃЌМѕЩйЯЕЭГБфИќЕФЯрЛЅвРРЕЃЌЪЕЯжСщЛюЕФЩ§МЖВПЪ№ЃЌжївЊАќРЈСЫБфИќЙ§ГЬЃЌМцШнЛиЙіКЭЪ§ОнМрПиЁЃ
зЂвтећИіБфИќРяУцЪЕМЪЧПЕїСЫвдЯТМИИіЙиМќЕу
гІгУВПЪ№КЭЪ§ОнБфИќВПЪ№НтёюЃЌЯрЛЅЖРСЂЃЌЪ§ОнБфИќгжАќРЈСЫНсЙЙБфИќКЭЪ§ОнБОЩэБфИќ
Ъ§ОнБфИќгІИУОпБИЯђЯТМцШнадКЭОпЬхЕФЛиЙіЗНЗЈ
ЖдгкЪ§ОнБфИќЯђЯТМцШнашвЊЗжПЊЬжТлЃЌЪзЯШЪЧЖдгкЪ§ОнПтНсЙЙЕФБфИќЃЌддђЩЯашвЊЭъШЋзіЕНЯђЯТМцШнЃЌМДЪ§ОнПтНсЙЙдкБфЛЏКѓВЛНјааЛиЙіЃЌЯђЯТМцШнЃЌБШШчЭиеЙСЫзжЖЮЛђГЄЖШЕШЁЃЦфДЮЪЧЪ§ОнБОЩэЕФИќаТЛђГѕЪМЛЏЃЌШчЙћЪЧаТдідіСПГѕЪМЛЏЪ§ОнЭљЭљВЂВЛашвЊЛиЙіЃЌЕЋЪЧШчЙћЪЧЖдвбгаЪ§ОнНјааupdateВйзїЃЌЭљЭљОЭашвЊХфКЯгІгУГЬађЕФЛиЙівЛЭЌНјааЛиЙіВйзїЁЃ
ФЧУДЮвУЧдкВПЪ№ЪЇАмЕФЪБКђЕФЛиЙіОЭашвЊжиЕуШЅПМТЧЃЌЧАепЪЧОЕЯёЛиЙіЃЌКѓепЪЧашвЊдЫааЪТЯШзМБИКУЕФЛиЙіНХБОНјааЪ§ОнФкШнЕФЛиЙіВХааЁЃ
ЖдгкећИіЪ§ОнЙмРэЙ§ГЬгђЃЌЪЕМЪЩшМЦЕФВЛЬЋКЯРэЃЌАДЕРРэВтЪдЪ§ОнЙмРэгІИУФЩШыЕНВтЪдЙмРэетИіЙ§ГЬгђЃЌЖјЖдгкЪ§ОнБфИќЙмРэБОЩэгІИУФЩШыЕНДѓЕФБфИќЙмРэЙ§ГЬгђИќМгКЯРэЁЃ
7. ЖШСПКЭЗДРЁ
DevOpsЛљгкОЋвцЫМЯыЗЂеЙЖјРДЃЌЦфжаГжајИФНјЪЧОЋвцЫМЯыЕФКЫаФРэФюжЎвЛЁЃ
DevOpsжїеХдкГжајНЛИЖЕФУПвЛИіЛЗНкНЈСЂгааЇЕФЖШСПКЭЗДРЁЛњжЦЃЌЦфжаЭЈЙ§ЩшСЂЧхЮњПЩСПЛЏЕФЖШСПжИБъЃЌгажњгкКтСПИФНјаЇЙћКЭЪЕМЪВњГіЃЌВЂВЛЖЯЕќДњКѓајИФНјЗНЯђЁЃСэЭтЩшСЂМАЪБгааЇЕФЗДРЁЛњжЦЃЌПЩвдМгПьаХЯЂДЋЕнЫйТЪЃЌгажњгкдкГѕЦкЗЂЯжЮЪЬтЃЌНтОіЮЪЬтЃЌВЂМАЪБаое§ФПБъЃЌМѕЩйКѓајЗЕЙЄДјРДЕФГЩБОРЫЗбЁЃЖШСПКЭЗДРЁПЩвдБЃжЄећИіЭХЖгФкВПаХЯЂЛёШЁЕФМАЪБадКЭвЛжТадЃЌБмУтаХЯЂВЛЭЌВНЕМжТЕФЮЪЬтЃЌУїШЗвЕЮёМлжЕНЛИЖФПБъКЭзДЬЌЃЌЭЦНјЖЫЕНЖЫМлжЕЕФПьЫйгааЇСїЖЏЁЃ
ЖШСПжИБъ
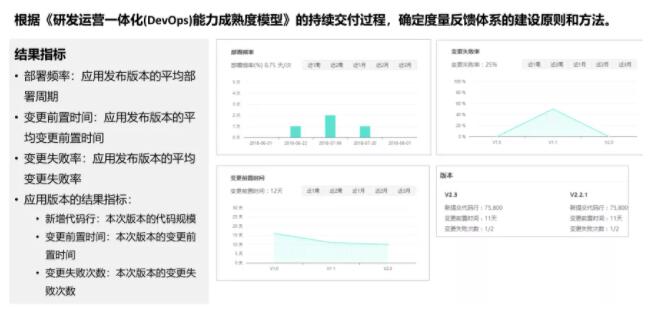
ЖШСПжИБъЕФМ№бЁКЭЩшЖЈЪЧЖШСПКЭЗДРЁЕФЧАЬсКЭЛљДЁЃЌПЦбЇКЯРэЕФЩшЖЈЖШСПжИБъгажњгкИФНјФПБъЕФДяГЩЁЃдкМ№бЁЖШСПжИБъЪБашвЊЙизЂСНИіЗНУцЃЌМДЖШСПжИБъЕФКЯРэадКЭЖШСПжИБъЕФгааЇадЁЃ
КЯРэадЗНУцвРЭагкЖдЕБЧАвЕЮёМлжЕСїЕФЗжЮіЃЌДгЙ§ГЬжИБъКЭНсЙћжИБъСНИіЮЌЖШРДЪЖБ№DevOpsЪЕЪЉНсЙћЃЌвдМАећИіШэМўНЛИЖЙ§ГЬЕФИФНјЗНЯђЁЃ
гааЇадЗНУцвЛАузёбSMARTддђЃЌМДжИБъБиаыЪЧОпЬхЕФЁЂПЩКтСПЕФЁЂПЩДяЕНЕФЁЂЭЌЦфЫћФПБъЯрЙиЕФКЭгаУїШЗЕФНижЙЪБМфЃЌЭЈЙ§етЮхДѓддђПЩвдБЃжЄФПБъЕФПЦбЇгааЇЁЃ
ЖШСПЧ§ЖЏИФНј
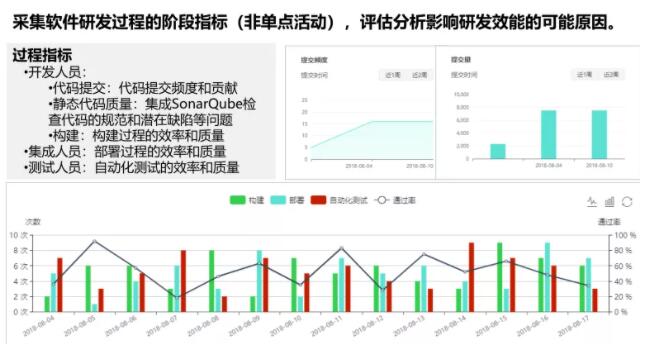
ЖШСПЧ§ЖЏИФНјЙизЂШэМўНЛИЖЙ§ГЬжаИїжжЖШСПЪ§ОнЕФЪеМЏЃЌЭГМЦЃЌЗжЮіКЭЗДРЁЃЌЭЈЙ§ПЩЪгЛЏЕФЖШСПЪ§ОнПЭЙлЗДгГећИібаЗЂЙ§ГЬЕФзДЬЌЃЌвдШЋОжЪгНЧРДЗжЮіЯЕЭГдМЪјЕуЃЌВЂдкЭХЖгФкВПЗжЯэЃЌАяжњЩшЖЈПЭЙлгааЇЕФИФНјФПБъЁЃЪЕМЪРяУцгаСНИіЙиМќФкШнЁЃ
вЛИіЪЧЖШСПаХЯЂЕФЗжРрЗжНтКЭПЩЪгЛЏГЪЯжЃЌБШШчЧПЕїЭЈЙ§ПЩЪгЛЏПДАхРДЪЕЪБеЙЪОЖШСПЪ§ОнЃЌБЈИцПЩвдЖрЮЌЖШЪЕЪБеЙЪОЃЌЭЌЪБЛЙжЇГжздЖЏЩњГЩЪ§ОнЧїЪЦЭМКЭЧїЪЦЗжЮіЁЃЦфДЮОЭЪЧЖШСПЗЂЯжЕФЮЪЬтвЊгаЮЪЬтИњзйКЭЗДРЁЛњжЦЃЌаЮГЩЮЪЬтБеЛЗКЭГжајИФНјЁЃ
|









