| БрМЭЦМі: |
ЮФеТЪзЯШНщЩмСЫDevOpsИХЪіЁЂдЦдЩњDevOpsЬиЕувдМАдЦдЩњDevOpsЪЕЯжЁЃ
БОЮФРДздгкдЦдЩњЩчЧј,гЩЛ№СњЙћШэМўAnnaБрМЭЦМіЁЃ |
|
DevOpsМђЪі
ЙЫУћЫМвхЃЌDevOpsОЭЪЧПЊЗЂЃЈDevelopmentЃЉгыдЫЮЌЃЈOperationsЃЉЕФНсКЯЬхЃЌЦфФПЕФОЭЪЧДђЭЈПЊЗЂгыдЫЮЌжЎМфЕФБкРнЃЌДйНјПЊЗЂЁЂдЫгЊКЭжЪСПБЃеЯЃЈQAЃЉЕШВПУХжЎМфЕФЙЕЭЈазїЃЌвдБуЖдВњЦЗНјаааЁЙцФЃЁЂПьЫйЕќДњЪНЕиПЊЗЂКЭВПЪ№ЃЌПьЫйЯьгІПЭЛЇЕФашЧѓБфЛЏЁЃЫќЧПЕїЕФЪЧПЊЗЂдЫЮЌвЛЬхЛЏЃЌМгЧПЭХЖгМфЕФЙЕЭЈКЭПьЫйЗДРЁЃЌДяЕНПьЫйНЛИЖВњЦЗКЭЬсИпНЛИЖжЪСПЕФФПЕФЁЃ
DevOpsВЂВЛЪЧвЛжжаТЕФЙЄОпМЏЃЌЖјЪЧвЛжжЫМЯыЃЌвЛжжЮФЛЏЃЌгУвдИФБфДЋЭГПЊЗЂдЫЮЌФЃЪНЕФвЛзщзюМбЪЕМљЁЃвЛАузіЗЈЪЧЭЈЙ§вЛаЉCI/CDЃЈГжајМЏГЩЁЂГжајВПЪ№ЃЉздЖЏЛЏЕФЙЄОпКЭСїГЬРДЪЕЯжDevOpsЕФЫМЯыЃЌвдСїЫЎЯпЃЈpipelineЃЉЕФаЮЪНИФБфДЋЭГПЊЗЂШЫдБКЭВтЪдШЫдБЗЂВМШэМўЕФЗНЪНЁЃЫцзХDockerКЭKubernetesЃЈвдЯТМђГЦk8sЃЉЕШММЪѕЕФЦеМАЃЌШнЦїдЦЦНЬЈЛљДЁЩшЪЉдНРДдНЭъЩЦЃЌМгЫйСЫПЊЗЂКЭдЫЮЌНЧЩЋЕФШкКЯЃЌЪЙдЦдЩњЕФDevOpsЪЕМљГЩЮЊвдКѓЕФЧїЪЦЁЃЯТУцЮвУЧЛљгкЛьКЯШнЦїдЦЦНЬЈЯъЯИНВНтЯТдЦЦНЬЈЯТDevOpsЕФТфЕиЗНАИЁЃ
дЦдЩњDevOpsЬиЕу
DevOpsЪЧPaaSЦНЬЈРяКмЙиМќЕФЙІФмФЃПщЃЌАќКЌвдЯТживЊФмСІЃКжЇГжДњТыПЫТЁЁЂБрвыДњТыЁЂдЫааНХБОЁЂЙЙНЈЗЂВМОЕЯёЁЂВПЪ№yamlЮФМўвдМАВПЪ№HelmгІгУЕШЛЗНкЃЛжЇГжЗсИЛЕФСїЫЎЯпЩшжУЃЌБШШчзЪдДЯоЖюЁЂСїЫЎЯпдЫааЬѕЪ§ЁЂЭЦЫЭДњТывдМАЭЦЫЭОЕЯёДЅЗЂСїЫЎЯпдЫааЕШЃЌЬсЙЉСЫгУЛЇдкВЛЭЌЛЗОГЯТЕФЖЫЕНЖЫИпаЇСїЫЎЯпФмСІЃЛЬсЙЉПЊЯфМДгУЕФОЕЯёВжПтжааФЃЛЬсЙЉСїЫЎЯпЛКДцЙІФмЃЌПЩвдздгЩХфжУећИіСїЫЎЯпЛђУПИіВНжшЕФдЫааЛКДцЃЌдкДњТыПЫТЁЁЂБрвыДњТыЁЂЙЙНЈОЕЯёЕШВНжшЪБОљПЩРћгУЛКДцДѓДѓЫѕЖЬдЫааЪБМфЃЌЬсЩ§жДаааЇТЪЁЃОпЬхЙІФмЧхЕЅШчЯТЃК
ЛКДцМгЫйЃКздбаШнЦїЛЏСїЫЎЯпЕФЛКДцММЪѕЃЌЭЈЙ§ДњТыБрвыКЭОЕЯёЙЙНЈЕФЛКДцИДгУЃЌЦНОљМгЫйСїЫЎЯп3~5БЖЃЛ
ЯИСЃЖШЛКДцХфжУЃКШЮвЛНзЖЮЁЂВНжшПЩвдПижЦЪЧЗёПЊЦєЛКДцМАЛКДцТЗОЖЃЛ
жЇГжСйЪБХфжУЃКгУЛЇЮоашЬсНЛМДПЩдЫааСйЪБХфжУЃЌБмУтЦЕЗБЬсНЛХфжУЮФМўЮлШОДњТыВжПтЃЛ
ПЊЯфМДгУЕФОЕЯёВжПтЃЛ
ЬсЙЉЭъећЕФШежОЙІФмЃЛ
ПЩЪгЛЏБрМНчУцЃЌСщЛюХфжУСїЫЎЯпЃЛ
жЇГжЖржжДњТыВжПтЪкШЈЃКGitHubЁЂGitLabЁЂBitbucketЕШЃЛ
ЖржжСїЫЎЯпДЅЗЂЗНЪНЃКДњТыВжПтДЅЗЂЃЌОЕЯёЭЦЫЭДЅЗЂЕШЃЛ
ЭјТчгХЛЏЃЌМгПьОЕЯёЛђвРРЕАќЕФЯТдиЫйЖШЃЛ
дЦдЩњDevOpsЪЕЯж
МђЕЅЕиЫЕЃЌдЦдЩњDevOpsФкВПЙІФмЕФЩшМЦЛљБОЩЯОљЪЧЭЈЙ§k8sЬсЙЉЕФздЖЈвхcontrollerЙІФмРДЪЕЯжЕФЃЌЛљБОТпМОЭЪЧИљОнвЕЮёашвЊГщЯѓГіЖрИіCRDЃЈCustom
Resource DefinitionЃЌздЖЈвхзЪдДЖдЯѓЃЉЃЌВЂБраДЖдгІЕФcontrollerРДЪЕЯжвЕЮёТпМЁЃЮЊСЫЪЕЯжCI/CDЙІФмЃЌЮвУЧГщЯѓГіСЫЖрИіCRDЖдЯѓЃЌШчЯТЭМЫљЪОЃК
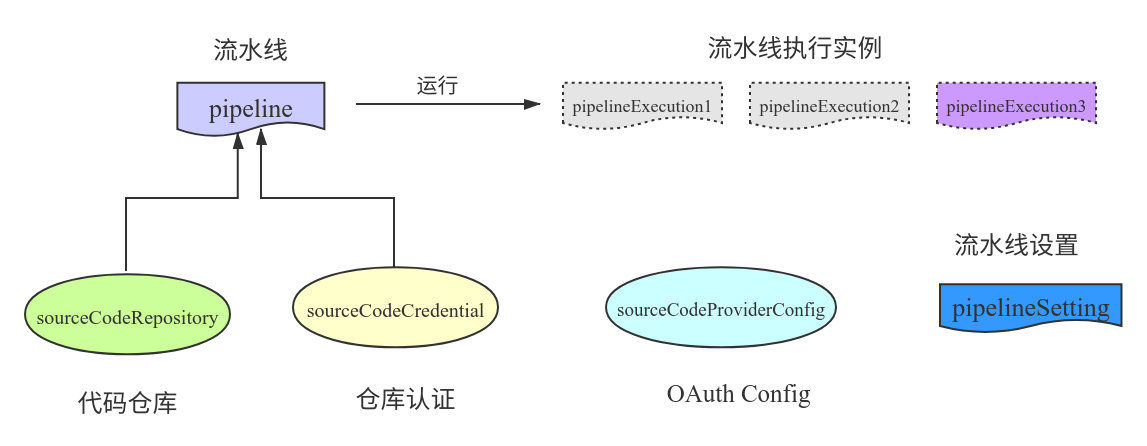
ЮвУЧжЊЕРХфжУСїЫЎЯпЭЈГЃашвЊЖдНгДњТыВжПтЃЌАќРЈВжПтЕижЗЃЌВжПтЪкШЈаХЯЂЕШЃЌвђДЫЮвУЧашвЊга3ИіCRDЖдЯѓРДМЧТМдДДњТыВжПтЕФЯрЙиаХЯЂЁЃ
sourceCodeProviderConfigЃКМЧТМВжПтOAuth AppsЕФПЭЛЇЖЫIDЁЂПЭЛЇЖЫУидПЃЛ
sourceCodeCredentialЃКМЧТМВжПтЕФШЯжЄаХЯЂЃЛ
sourceCodeRepositoryЃКМЧТМВжПтЕижЗЕШаХЯЂЁЃ
ЩшМЦКУСЫDevOpsжагыВжПтЯрЙиЕФ3ИіCRDЖдЯѓКѓЃЌЮвУЧашвЊдйЖЈвх3ИіCRDЖдЯѓРДУшЪіСїЫЎЯпЯрЙиЕФаХЯЂЁЃ
pipelineЃКМЧТМИУСїЫЎЯпЕФХфжУаХЯЂЃКВжПтЕФШЯжЄаХЯЂЁЂЙГзгДЅЗЂХфжУвдМАЯюФПДњТыЕижЗЕШЕШЃЛ
pipelineExecutionЃКМЧТМСїЫЎЯпдЫааЪБаХЯЂгыжДааНсЙћаХЯЂЕШЃЛ
pipelineSettingЃКМЧТМећИіЯюФПЯТpipelineдЫааЛЗОГаХЯЂЃКФкДцЁЂCPUЕФЯожЦЃЌзюДѓСїЫЎЯпВЂаадЫааИіЪ§ЕШЕШЁЃ
pipelineВНжшЙІФмгаКмЖржжРраЭЃЌАќРЈдЫааНХБОЁЂЙЙНЈЗЂВМОЕЯёЁЂЗЂВМгІгУФЃАхЁЂВПЪ№YAMLЁЂВПЪ№гІгУЕШЕШЁЃЮЊСЫЬсЙЉетаЉЙІФмЃЌЮвУЧВЩгУJenkinsзїЮЊЕзВуЕФCI/CDЙЄОпЃЌdocker
registry зїЮЊОЕЯёВжПтжааФЃЌminioзїЮЊШежОДцДЂжааФЕШЕШЁЃетаЉЗўЮёЪЧдЫаадкpipelineЫљдкЯюФПЕФУќУћПеМфЯТЁЃзлЩЯЃЌЮвУЧЩшМЦЕФCI/CDЯЕЭГЙІФмЕФЪЕЯжТпМШчЭМЫљЪОЃК
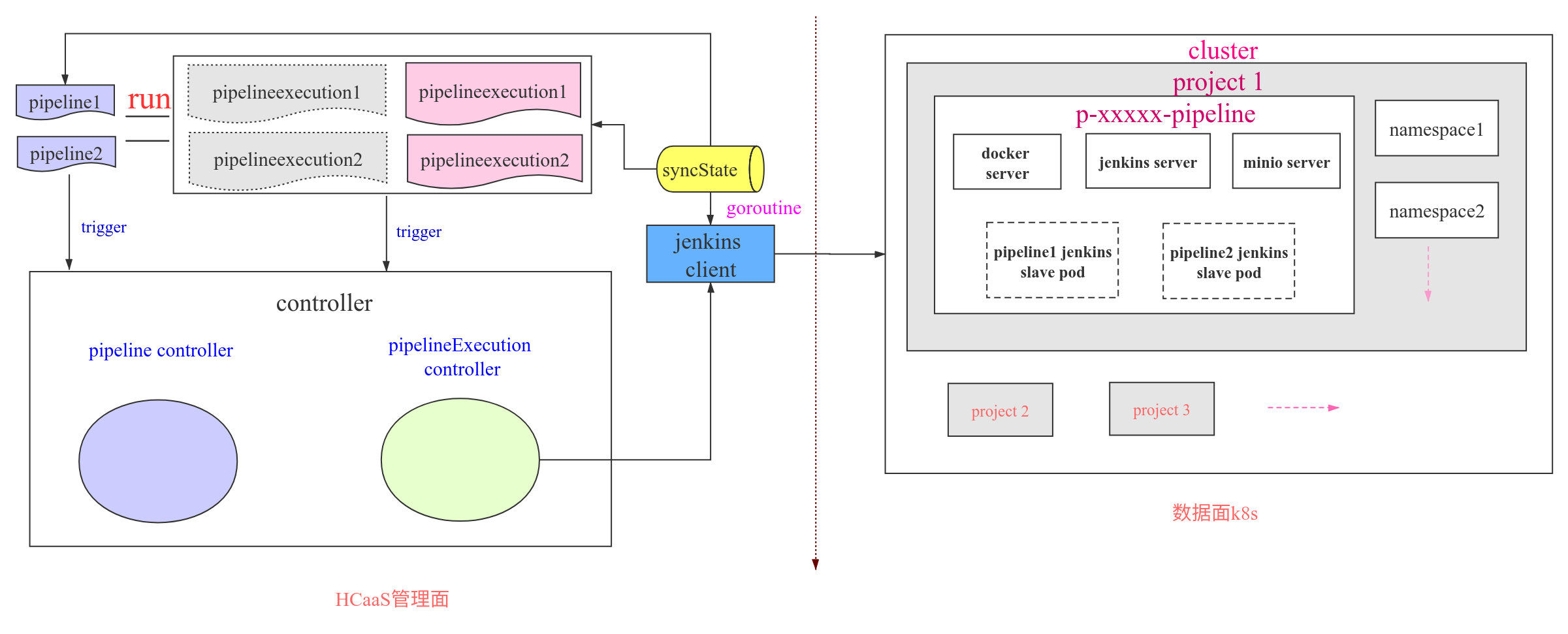
ШчЩЯЃЌЕБЕквЛДЮдЫааСїЫЎЯпЪБЃЌЯЕЭГЛсдкЪ§ОнУцk8sжаВПЪ№JenkinsЁЂminioЕШЛљДЁЙЄОпЕФЗўЮёЃЌЭЌЪБдкЙмРэУцЦєЖЏвЛИіgoroutineЃЌЪЕЪБЭЌВНЪ§ОнУцжаСїЫЎЯпЕФзївЕзДЬЌЕНЙмРэУцЕФCRDЖдЯѓжаЁЃЕБДЅЗЂpipelineжДааТпМЪБЃЌЛсВњЩњвЛИіpipelineExecution
CRDЖдЯѓЃЌвдМЧТМБОДЮдЫааpipelineЕФзДЬЌаХЯЂЁЃЕБgoroutineЃЈsyncStateЃЉЗЂЯжгааТЕФжДааЪЕЧœٜЪБЃЌОЭЛсЭЈЙ§Jenkinsв§ЧцНгПкЦєЖЏJenkins
serverЖЫСїЫЎЯпзївЕЕФдЫааЃЌJenkins serverЖЫЪеЕНаХЯЂКѓЛсЦєЖЏЕЅЖРЕФвЛИіJenkins
slave podНјааСїЫЎЯпзївЕЕФЯьгІЁЃЭЌЪБЃЌgoroutineЃЈsyncStateЃЉЛсВЛЖЯЕиЭЈЙ§в§ЧцНгПкТжбЏpipelineжДааЪЕР§ЕФдЫааЧщПіНјЖјИќаТ
pipelineExecution CRDЕФзДЬЌЃЈдЫааГЩЙІЛђЪЇАмЕШЕШЃЉЁЃЕБpipelineжДааЪЕР§ЗЂЩњзДЬЌБфЛЏЪБЃЌОЭЛсДЅЗЂЦфЖдгІЕФcontrollerвЕЮёТпМЃЌНјЖјЭЈЙ§Jenkinsв§ЧцНгПкгыJenkins
server ЭЈаХНјааВЛЭЌЕФВйзїЃЌБШШчЃЌднЭЃСїЫЎЯпЕФдЫааЃЌдЫааЭъЧхГ§ВЛашвЊЕФзЪдДЕШЕШЁЃЕБСїЫЎЯпзївЕЗЂЩњзДЬЌБфЛЏЪБЃЌгжЛсЭЈЙ§goroutineЃЈsyncStateЃЉИќИФpipelineжДааЪЕР§ЕФзДЬЌЃЌНјЖјгжДЅЗЂЖдгІЕФcontrollerвЕЮёДњТыНјааВЛЭЌЕФвЕЮёТпМДІРэЃЌЭљИДбЛЗЃЌжБЕНСїЫЎЯпдЫааНсЪјЁЃетОЭЪЧећИіpipelineжДааЪБЕФвЛИіТпМСїГЬЁЃ
CRDЖЈвх
ЯТУцЪЧЯъЯИЕФCRDНсЙЙЬхНВНтЃЌУєИааХЯЂЪЙгУСЫЁЏ*ЁЎДњЬцЁЃ
pipelineSettingЃКИУНсЙЙЬхБЃДцзХећИіЯюФПЯТЫљгаpipelineЕФдЫааЛЗОГаХЯЂЃЌБШШчCPU/ФкДцзЪдДЯоЖюЁЂЛКДцТЗОЖвдМАСїЫЎЯпдЫааЕФзюДѓВЂааИіЪ§ЕШЕШЃЌВЛЭЌЙІФмЕФХфжУаХЯЂБЃДцдкВЛЭЌЕФCRDЯТЁЃ
devops-cache-dir
12d
executor-cpu-limit 12d
executor-cpu-request 12d
executor-memory-limit 12d
executor-memory-request 12d
executor-quota 12d
...
// БШШчЃЌПДЯТexecutor-quotaЯъЯИаХЯЂ
apiVersion: project.cubepaas.com/v3
kind: PipelineSetting
metadata:
labels:
cubepaas.com/creator: linkcloud
name: executor-quota
namespace: p-zwmcv
default: "2" // ФЌШЯзюЖрПЩЭЌЪБдЫаа2Иіpipeline
projectName: c-86tgg:p-zwmcv
value: "3" // здЖЈвхЩшжУЃЌзюЖрПЩЭЌЪБдЫаа3ИіpipelineЃЌУЛгажЕЛсШЁЩЯУцФЌШЯжЕ |
pipelineЃКИУНсЙЙЬхМЧТМзХСїЫЎЯпЕФХфжУдЊаХЯЂЃЌБШШчИУСїЫЎЯпЖдНгФФИіЯюФПДњТыЁЂгыВжПтЭЈаХЕФШЯжЄаХЯЂвдМАЩЯДЮИУСїЫЎЯпдЫааЕФНсЙћЕШЕШЁЃШчЯТЭМЫљЪОЃК
ЯъЯИЕФНсЙЙзжЖЮНВНтШчЯТЃК
apiVersion:
project.cubepaas.com/v3
kind: Pipeline
metadata:
labels:
cubepaas.com/creator: linkcloud
name: p-d5frn
namespace: p-zwmcv
spec:
currentBranch: master // СїЫЎЯпдЫааЪБФЌШЯДњТыЗжжЇ
imageWebHookToken: // етЪЧЭЦЫЭОЕЯёЪБДЅЗЂИУСїЫЎЯпдЫааЕФЩшжУаХЯЂ
- branches:
- master
comment: a
imageType: harbor // жЇГж harbor dockerhub aliyunЕШОЕЯёВжПт
token: 7c102c82-66d9-44c1-8718-**** // ЭЦЫЭОЕЯёДЅЗЂСїЫЎЯпдЫааЪБЕФ
token ШЯжЄ
trigger: nginx // ЕБЭЦЫЭ nginx ОЕЯёЪБЛсДЅЗЂСїЫЎЯпдЫаа
projectName: c-86tgg:p-zwmcv
repositoryUrl: https://github.com/gophere/ devops-go.git
// ЯюФПДњТыЕижЗ
sourceCodeCredentialName: u-8sq**:p-zwmcv-github-gophere
// жИЯђЖдгІЕФгУЛЇШЯжЄаХЯЂ
triggerWebhookPush: true // ЙГзгВйзїЃЌЕБpushДњТыЕНВжПтЪБЛсДЅЗЂИУСїЫЎЯпжДаа
status:
lastRunState: Success // зюаТвЛДЮдЫааЕФзюКѓНсЙћ
nextRun: 2 // ЯТДЮдЫааЪБжДааЪЕР§ЖдгІЕФађКХ
pipelineState: active // ИУСїЫЎЯпДІгкгааЇзДЬЌ
sourceCodeCredential: // ЩЯЪівбНщЩмЃЌДЫДІВЛдйзИЪі
...
...
token: e667bbb9-7230-48d4-9d29-***** // гУгкДњТыВжПтДЅЗЂСїЫЎЯпдЫааЪБЕФ
token ШЯжЄ
webhookId: "245901183" // ДњТыВжПтЕФЙГзгаХЯЂ |
pipelineExecutionЃКСїЫЎЯпжДааЪЕР§ЃЌУПЕБСїЫЎЯпдЫаавЛДЮЃЌЛсВњЩњвЛИіИУЖдЯѓМЧТМзХСїЫЎЯпЕФжДааНсЙћЕШаХЯЂЁЃШчЯТЭМЫљЪОЃК
ЯъЯИЕФНсЙЙзжЖЮНВНтШчЯТЃК
apiVersion:
project.cubepaas.com/v3
kind: PipelineExecution
metadata:
labels:
cubepaas.com/creator: linkcloud
pipeline.project.cubepaas.com /finish: "true"
name: p-d5frn-2
namespace: p-zwmcv
spec:
branch: master // БОДЮдЫааЕФДњТыЗжжЇ
commit: f5b78969586cd90918020cb7a 138fe88c7e25f9d
// ДњТы commitid
message: Update .cubepaas -devops.yml // ДњТы
commit ЫЕУї
pipelineConfig: // вдЯТЪЧpipelineОпЬхЕФstageКЭstepЕФХфжУаХЯЂЃЌУПДЮдЫааЪБДгДњТыВжПтЕФХфжУЮФМўЃЈ.cubepaas.devops.ymalЃЉРШЁЯТРДЬюГфИУНсЙЙ
stages:
- name: Clone // ПЫТЁДњТы
steps:
- sourceCodeConfig: {}
- name: Build // дЫааНХБОБрвыДњТы
...
pipelineName: p-zwmcv:p-d5frn
projectName: c-86tgg:p-zwmcv
ref: master
repositoryUrl: https://github.com/gophere/ devops-go.git
// ЯюФПДњТыЕижЗ
run: 2 // ДЫДЮдЫааађКХ
triggerUserName: u-8sq** // ДЅЗЂгУЛЇ
triggeredBy: user
status: // вдЯТМЧТМзХpipelineУПИіstageКЭstepЕФдЫааНсЙћаХЯЂ
executionState: Success
stages:
- ended: 2020-09-03T06:01:01Z
state: Success
steps:
- ended: 2020-09-03T06:01:01Z
state: Success
...
... |
жСДЫЃЌЮвУЧЭъГЩСЫСїЫЎЯпЙІФмЕФЛљДЁЖдЯѓЖЈвхЁЃ
controller ЪЕЯж
Г§СЫГщЯѓГіЖдгІЕФCRDЭтЃЌЮвУЧЛЙашвЊБраДЖдгІЕФcontrollerДњТыЪЕЯжЖдгІЕФвЕЮёТпМЃЌБШШчЕБpipelineдЫааЪБЃЌЮвУЧашвЊВњЩњpipelineжДааЪЕР§ЃЌВЂЪЕЪБЭЌВНЦфдЫааЕФзДЬЌаХЯЂЕШЕШЁЃ
ЕБДЅЗЂСїЫЎЯпжДааТпМЪБЃЌЯЕЭГЛсИљОнpipeline CRDЖдЯѓКЭИУСїЫЎЯпЖдгІЕФДњТыВжПтжаЕФХфжУЮФМўЃЈ.cubepaas.devops.ymalЃЉВњЩњвЛИіpipelineExecution
CRDЖдЯѓЃЌетЪБЛсДЅЗЂpipelineExecutionЖдгІЕФcontrollerдЫаавЕЮёТпМЁЃЯТУцжЛеЊШЁживЊЕФДњТыТпМЃЌШчЯТЫљЪОЃК
| func (l *Lifecycle)
Sync (obj *v3.PipelineExecution) (runtime.Object,
error) {
...
// ШчЙћ pipeline жДааЪЕР§БЛднЭЃЃЌдђЛсЭЃжЙСїЫЎЯпзївЕ
if obj.Status.ExecutionState == utils.StateAborted
{
if err := l.doStop(obj); err != nil {
return obj, err
}
}
// ШчЙћ pipeline жДааЪЕР§дЫааЭъБЯЃЌдђЛсЧхРэСїЫЎЯпзївЕЕФвЛаЉзЪдД
// БШШчЃЌВњЩњЕФJenkins slave pod
if obj.Labels != nil && obj.Labels [utils.PipelineFinishLabel]
== "true" {
return l.doFinish(obj)
}
// ШчЙћ pipeline жДааЪЕР§е§дкдЫаажаЃЌдђжБНгЗЕЛиЃЌЮоВйзї
if v3. PipelineExecutionConditionInitialized .GetStatus(obj)
!= "" {
return obj, nil
}
// ХаЖЯСїЫЎЯпзївЕЪЧЗёГЌГізЪдДЯоЖю
exceed, err := l.exceedQuota(obj)
if err != nil {
return obj, err
}
// ШчЙћГЌГізЪдДЯоЖюЃЌдђЛсЩшжУЕБЧА pipeline жДааЪЕР§ЮЊзшШћзДЬЌ
if exceed {
obj.Status.ExecutionState = utils.StateQueueing
obj.Labels[utils.PipelineFinishLabel] = ""
if err := l.newExecutionUpdateLastRunState(obj);
err != nil {
return obj, err
}
return obj, nil
} else if obj.Status.ExecutionState == utils.StateQueueing
{
obj.Status.ExecutionState = utils.StateWaiting
}
// ИќаТ pipeline жДааЪЕР§ЕФзДЬЌ: БШШчдЫааађКХ+1
if err := l.newExecutionUpdateLastRunState(obj);
err != nil {
return obj, err
}
v3 . PipelineExecutionConditionInitialized .CreateUnknownIfNotExists(obj)
obj.Labels[utils.PipelineFinishLabel] = "false"
// дкЪ§ОнУцВПЪ№pipelineЙІФмЫљашзЪдД
if err := l.deploy (obj.Spec.ProjectName); err
!= nil {
obj.Labels [utils.PipelineFinishLabel] = "true"
obj.Status.ExecutionState = utils.StateFailed
v3 .PipelineExecutionConditionInitialized .False(obj)
v3 .PipelineExecutionConditionInitialized .ReasonAndMessageFromError(obj,
err)
}
// НЋ configMap ДцДЂЕФdockerОЕЯёВжПтЖЫПкаХЯЂЭЌВНЕНpipelineжДааЪЕР§жаШЅ.
if err := l.markLocalRegistryPort(obj); err
!= nil {
return obj, err
}
return obj, nil
} |
ЦфжаЃЌdeployКЏЪ§ЕФТпМОЭЪЧЕквЛДЮдЫааЪБЭЈЙ§ХаЖЯЪ§ОнУцжаЪЧЗёДцдкpipelineЕФУќУћПеМфЃЌШчЙћДцдкОЭДњБэЛљДЁзЪдДвбОХфжУЭъГЩЃЌжБНгзпreconcileRbКЏЪ§ЃЌИУКЏЪ§ЕФТпММћЯТУцЃЛШчЙћВЛДцдкЃЌОЭЛсдкЪ§ОнУцжаГѕЪМЛЏБивЊЕФЛљДЁзЪдДЃЌБШШчЃКpipelineУќУћПеМф,
Jenkins docker minioЗўЮё, ХфжУconfigMap, secretЕШЕШЁЃ
func (l *Lifecycle)
deploy(projectName string) error {
clusterID, projectID := ref.Parse(projectName)
ns := getPipelineNamespace(clusterID, projectID)
// ШчЙћИУpipelineЕФnamespaceвбОгаСЫЃЌЫЕУїЯТУцЕФзЪдДВПЪ№вбОЭъГЩСЫЃЌдђжБНгзпreconcileRbСїГЬ
// ЗёдђзпЯТУцЕФзЪдДВПЪ№СїГЬ
if _, err := l.namespaceLister.Get("",
ns.Name); err == nil {
return l.reconcileRb(projectName)
} else if !apierrors.IsNotFound(err) {
return err
}
// ДДНЈpipelineЖдгІЕФУќУћПеМфЃЌШчp-qqxs7-pipeline
if _, err := l.namespaces.Create(ns); err !=
nil && !apierrors.IsAlreadyExists(err)
{
return errors.Wrapf(err, "Error creating
the pipeline namespace")
}
...
// ЫцЛњВњЩњвЛИіtokenЃЌгУгкХфжУЯТУцЕФsecret
token, err := randomtoken.Generate()
nsName := utils.GetPipelineCommonName(projectName)
ns = getCommonPipelineNamespace()
// ДДНЈгУгкВПЪ№dockerОЕЯёВжПтЕФДњРэЗўЮёЕФУќУћПеМф
if _, err := l.namespaces.Create(ns); err !=
nil && !apierrors.IsAlreadyExists(err)
{
return errors.Wrapf(err, "Error creating
the cattle-pipeline namespace")
}
// дк pipeline namespace ФкДДНЈsecret : pipeline-secret
secret := getPipelineSecret(nsName, token)
l.secrets.Create(secret);
...
// ЛёШЁЙмРэУцЯюФПЕФЯЕЭГгУЛЇtoken
apikey, err := l.systemAccountManager .GetOrCreateProjectSystemToken
(projectID)
...
// дк pipeline namespace ФкДДНЈsecret: pipeline-api-keyЃЌгУгкЪ§ОнУцгыЙмРэУцЭЈаХЕФЦОжЄ
secret = GetAPIKeySecret(nsName, apikey)
l.secrets.Create(secret);
// ЕїаГ docker ОЕЯёВжПтЕФжЄЪщХфжУЃЈдкПижЦУцжаЃЉ
if err := l.reconcileRegistryCASecret (clusterID);
err != nil {
return err
}
// НЋПижЦУцжаЕФ docker ОЕЯёВжПтЕФжЄЪщХфжУЭЌВНЕНЪ§ОнУцжа
if err := l.reconcileRegistryCrtSecret (clusterID,
projectID); err != nil {
return err
}
// дк pipeline namespace ФкДДНЈ serviceAccount
: jenkins
sa := getServiceAccount(nsName)
if _, err := l.serviceAccounts.Create(sa); err
!= nil && !apierrors.IsAlreadyExists(err)
{
return errors.Wrapf (err, "Error creating
a pipeline service account")
}
...
// дк pipeline namespace ФкДДНЈ service: jenkins
jenkinsService := getJenkinsService(nsName)
if _, err := l.services.Create(jenkinsService);
err != nil && !apierrors.IsAlreadyExists(err)
{
return errors.Wrapf (err, "Error creating
the jenkins service")
}
// дк pipeline namespace ФкДДНЈ deployment: jenkins
jenkinsDeployment := GetJenkinsDeployment(nsName)
if _, err := l.deployments.Create (jenkinsDeployment);
err != nil && !apierrors.IsAlreadyExists(err)
{
return errors.Wrapf (err, "Error creating
the jenkins deployment")
}
// дк pipeline namespace ФкДДНЈ service: docker-registry
registryService := getRegistryService(nsName)
if _, err := l.services.Create(registryService);
err != nil && !apierrors.IsAlreadyExists(err)
{
return errors.Wrapf (err, "Error creating
the registry service")
}
// дк pipeline namespace ФкДДНЈ deployment: docker-registry
registryDeployment := GetRegistryDeployment(nsName)
if _, err := l.deployments.Create (registryDeployment);
err != nil && !apierrors.IsAlreadyExists(err)
{
return errors.Wrapf(err, "Error creating
the registry deployment")
}
// дк pipeline namespace ФкДДНЈ service: minio
minioService := getMinioService(nsName)
if _, err := l.services.Create(minioService);
err != nil && !apierrors.IsAlreadyExists(err)
{
return errors.Wrapf(err, "Error creating
the minio service")
}
// дк pipeline namespace ФкДДНЈ deployment: minio
minioDeployment := GetMinioDeployment(nsName)
if _, err := l.deployments.Create(minioDeployment);
err != nil && !apierrors.IsAlreadyExists(err)
{
return errors.Wrapf(err, "Error creating
the minio deployment")
}
// ЕїаГ configMap: proxy-mappingsЃЌгУгкХфжУdockerОЕЯёВжПтДњРэЗўЮёЕФЖЫПкаХЯЂ
if err := l.reconcileProxyConfigMap(projectID);
err != nil {
return err
}
// ДДНЈsecret: devops-docker-registryЃЌДцДЂЗУЮЪdockerВжПтЕФШЯжЄаХЯЂ
if err := l.reconcileRegistryCredential(projectName,
token); err != nil {
return err
}
// ДДНЈ daemonset: registry-proxyЃЌУПИіНкЕуВПЪ№вЛЬзdockerОЕЯёВжПтЕФnginxДњРэЗўЮё
// ПЩвддкШЮвтвЛИіНкЕуЩЯЭЈЙ§ВЛЭЌЕФЖЫПкМДПЩЗУЮЪЕНВЛЭЌЕФdockerОЕЯёВжПт
nginxDaemonset := getProxyDaemonset()
if _, err := l.daemonsets.Create (nginxDaemonset);
err != nil && !apierrors.IsAlreadyExists(err)
{
return errors.Wrapf (err, "Error creating
the nginx proxy")
}
return l.reconcileRb(projectName)
} |
reconcileRbКЏЪ§ЕФЙІФмОЭЪЧБщРњЫљгаnamespace,
ЖдЦфЕїаГrolebindings, ФПЕФЪЧШУ pipeline serviceAccount(jenkins)
ЖдИУprojectЯТЕФЫљгаnamespaceОпгаЫљашвЊЕФВйзїШЈЯоЃЌетбљJenkins serverВХФмЙЛдкЪ§ОнУцжае§ГЃЬсЙЉCI/CDЛљДЁЗўЮёЁЃ
| func (l *Lifecycle)
reconcileRb(projectName string) error {
...
var namespacesInProject []*corev1.Namespace
for _, namespace := range namespaces {
parts := strings.Split(namespace.Annotations[projectIDLabel],
":")
if len(parts) == 2 && parts[1] == projectID
{
// Й§ТЫГіЪєгкИУprojectЯТЕФЫљгаnamespace
namespacesInProject = append(namespacesInProject,
namespace)
} else {
// ЖдЗЧИУprojectЯТЕФnamespace, ЧхГ§гаЙиИУ pipeline ЕФ rolebinding
if err := l.roleBindings.DeleteNamespaced(namespace.Name,
commonName, &metav1.DeleteOptions{}); err
!= nil && !apierrors.IsNotFound(err)
{
return err
}
}
}
for _, namespace := range namespacesInProject
{
// ЖдЪєгкИУprojectЯТЕФnamespace, ДДНЈ rolebinding: Жд
jenkins serviceAccount АѓЖЈНЧЩЋ
// МДИГгш jenkins serviceAccount ЖдИУprojectЯТЕФЫљгаnamespaceЫљашвЊЕФВйзїШЈЯо
rb := getRoleBindings(namespace.Name, commonName)
if _, err := l.roleBindings.Create(rb); err
!= nil && !apierrors.IsAlreadyExists(err)
{
return errors.Wrapf(err, "Error create
role binding")
}
}
// ИГгш jenkins serviceAccount дк cluster ФкДДНЈКЭаоИФ
namespace ЕФШЈЯо
// ЕБВПЪ№гІгУЪБПЩвджИЖЈДДНЈаТЕФУќУћПеМф
clusterRbs := []string{roleCreateNs, projectID
+ roleEditNsSuffix}
for _, crbName := range clusterRbs {
crb := getClusterRoleBindings(commonName, crbName)
if _, err := l.clusterRoleBindings.Create(crb);
err != nil && !apierrors.IsAlreadyExists(err)
{
return errors.Wrapf(err, "Error create
cluster role binding")
}
}
return nil
} |
goroutineЃЈsyncStateЃЉЕФДњТыТпМБШНЯМђЕЅЃЌЕБВњЩњаТЕФpipelineжДааЪЕР§ЪБОЭЛсЦєЖЏJenkins
serverЖЫСїЫЎЯпзївЕЕФдЫааВЂЪЕЪБЭЌВНЦфдЫаазДЬЌЕНpipelineжДааЪЕР§жаЁЃДњТыТпМШчЯТЃК
func (s *ExecutionStateSyncer)
syncState() {
set := labels.Set(map[string]string{utils.PipelineFinishLabel:
"false"})
allExecutions, err := s.pipelineExecutionLister.List("",
set.AsSelector())
executions := []*v3.PipelineExecution{}
// БщРњИУclusterЯТЕФ pipeline жДааЪЕР§
for _, e := range allExecutions {
if controller.ObjectInCluster(s.clusterName,
e) {
executions = append(executions, e)
}
}
for _, execution := range executions {
if v3.PipelineExecutionConditionInitialized.IsUnknown(execution)
{
// МьВщЪ§ОнУцk8sжа Jenkins pod ЪЧЗёе§ГЃЃЌе§ГЃдђдЫааИУ pipeline
job
s.checkAndRun(execution)
} else if v3.PipelineExecutionConditionInitialized.IsTrue(execution)
{
e := execution.DeepCopy()
// ШчЙћвбОЦєЖЏСЫЃЌдђЭЌВНдЫаазДЬЌ
updated, err := s.pipelineEngine.SyncExecution(e)
if updated {
// ИќаТзюаТЕФзДЬЌЕН pipelineExecution crd жа
s.updateExecutionAndLastRunState(e);
}
} else {
// ИќаТзюаТЕФзДЬЌЕН pipelineExecution crd жа
s.updateExecutionAndLastRunState(execution);
}
}
logrus.Debugf("Sync pipeline execution
state complete")
} |
ЛКДцжЇГж
дЦЛЗОГЯТЕФСїЫЎЯпЪЧЭЈЙ§ЦєЖЏШнЦїРДдЫааОпЬхЕФЙІФмВНжшЃЌУПДЮдЫааСїЫЎЯпПЩФмЛсБЛЕїЖШЕНВЛЭЌЕФМЦЫуНкЕуЩЯЃЌетЛсЕМжТвЛИіЮЪЬтЃКШнЦїдЫааЭъЪЧВЛЛсБЃДцЪ§ОнЕФЃЌУПЕБСїЫЎЯпжиаТдЫааЪБЃЌгжЛсжиаТРШЁДњТыЁЂБрвыДњТыЁЂЯТдивРРЕАќЕШЕШЃЌЪЇШЅСЫБОЕиЫожїЛњБрвыДњТыЁЂЙЙНЈОЕЯёЪБЛКДцЕФзїгУЃЌДѓДѓбгГЄСЫСїЫЎЯпдЫааЪБМфЃЌРЫЗбКмЖрВЛБивЊЕФЪБМфЁЂЭјТчКЭМЦЫуГЩБОЕШЁЃЮЊСЫЬсИпгУЛЇЪЙгУСїЫЎЯпЕФЬхбщЃЌМгШыжЇГжЛКДцЕФЙІФмЁЃ
ЮЊСЫШУСїЫЎЯпОпгаЛКДцЙІФмЃЌЮвУЧашвЊдкСїЫЎЯпдЫааЪБМгШыГжОУЛЏЪ§ОнЕФФмСІЁЃЪзЯШЯыЕНЕФОЭЪЧk8sЬсЙЉЕФБОЕиГжОУЛЏДцДЂЃЈМДLocal
Persistent VolumeЃЌвдЯТМђГЦLocal PVЃЉЃЌЛђвРРЕдЖГЬДцДЂЗўЮёЦїРДЬсЙЉГжОУЛЏЃЌдЖГЬДцДЂаЇТЪвРРЕгкЭјТчЃЌВЂЧвЛЙашвЊБЃжЄдЖГЬДцДЂИпПЩгУЃЌетЛиДјРДКмЖрИДдгадЃЌвВвЛЖЈГЬЖШЩЯЪЇШЅСЫЛКДцЕФзїгУЁЃзлКЯПМТЧЃЌЮвУЧбЁдёБОЕиДцДЂЪЕЯжЛКДцЃЌЕЋЪЧk8sЬсЙЉЕФLocal
PVЪЧашвЊКЭНкЕуАѓЖЈдквЛЦ№ЕФЃЌвВОЭЪЧЫЕвЛЕЉСїЫЎЯпЕїЖШЕНФГИіНкЕуЩЯдЫааЃЌФЧУДЯТДЮдЫааЛЙЛсАѓЖЈЕНИУНкЕудЫааЃЌЫфШЛЪЕЯжСЫЛКДцЕФзїгУЃЌЕЋЪЧвВдьГЩСЫСїЫЎЯпУПДЮжЛФмдкИУНкЕуЩЯдЫааЃЌШчЙћгаЖрЬѕСїЫЎЯпЭЌЪБХмЃЌПЩФмЛсЕМжТИУНкЕузЪдДКФОЁЛђепЛКДцГхЭЛЃЌЪЇШЅСЫдЦЦНЬЈБОЩэИљОнзЪдДЪЙгУЧщПіЦНКтЕїЖШЕФЬиадЁЃ
вђДЫЃЌЮЊСЫЦНКтЛКДцгыЕїЖШМфЕФЙиЯЕЃЌЮвУЧВЩгУСЫЙвдиhostPath VolumeЗНЪНЃЌетбљвРЭагкk8sЧПДѓЕФШнЦїЕїЖШФмСІЃЌЮвУЧПЩвдЭЌЪБдЫааКмЖрЬѕСїЫЎЯпЖјВЛгУЕЃаФзЪдДКФОЁЛђЛКДцГхЭЛЕФЮЪЬтЃЌЕЋЪЧСїЫЎЯпУПДЮдЫааЪБПЩФмЛсБЛЕїЖШЕНВЛЭЌЕФНкЕуЩЯЃЌШчЙћЕБЧАНкЕуУЛгадЫааЙ§СїЫЎЯпЃЌдђЦ№ВЛЕНЛКДцЕФзїгУЁЃФЧУДШчКЮНтОіhostPath
VolumeЛКДцгыЕїЖШМфЕФоЯоЮЙиЯЕФиЃПЮвУЧЧЩУюЕиРћгУСЫk8sЬсЙЉЕФЧзКЭадЕїЖШЬиадЃЌЕБСїЫЎЯпдЫааЪБЮвУЧЛсМЧТМЕБЧАдЫааНкЕуЃЌЯТДЮдЫааЪБЭЈЙ§ЩшжУPodЕФЧзКЭадгХЯШЕїЖШЕНИУНкЕуЩЯЃЌЫцзХСїЫЎЯпдЫааДЮЪ§дНРДдНЖрЃЌЮвУЧЛсЕУЕНвЛИідЫааНкЕуСаБэЁЃШчЯТЫљЪОЃК
// АДЪБМфХХађЃЌзюНќдЫааСїЫЎЯпЕФНкЕуХХдкзюЧАУц
executionScheduledInfo:
- creationTimestamp: "2020-09-02T06:42:45Z"
executionId: 8
nodeName: ******
- creationTimestamp: "2020-08-26T14:19:21Z"
executionId: 7
nodeName: ******
- creationTimestamp: "2020-08-26T10:52:15Z"
executionId: 5
nodeName: ******
- creationTimestamp: "2020-08-26T10:48:43Z"
executionId: 4
nodeName: ******
- creationTimestamp: "2020-08-25T07:47:27Z"
executionId: 3
nodeName: ******
- creationTimestamp: "2020-08-25T07:16:29Z"
executionId: 1
nodeName: ******
......
|
жДааЪЕР§ЕїЖШаХЯЂЛсБЃДцЕНpipeline CRDЖдЯѓжаЃЌУПДЮдЫааСїЫЎЯпЪБЃЌЯЕЭГЛсИљОнНкЕуСаБэЩшжУPodЕФЧзКЭадЃЌФЌШЯЮвУЧЛсШЁзюНќдЫааСїЫЎЯпЕФ10ИіНкЕуЃЌддђЪЧзюНќдЫааСїЫЎЯпЕФНкЕугХЯШМЖдНИпЁЃДњТыШчЯТЃК

ДДаТадЕФЁАHostpath Volume + ЧзКЭадЕїЖШЁБЛКДцЩшМЦЗНАИЃЌВЛНіЪЕЯжСЫСїЫЎЯпЕФВЂЗЂадЛКДцЙІФмЃЌЖјЧвЪЕЯжИДдгЖШЕЭЃЌПЩздгЩХфжУШЮвЛНзЖЮЁЂВНжшЕФЛКДцПЊЙивдМАЛКДцТЗОЖЁЃЮоЛКДцгыгаЛКДцдЫааЕФЖдБШШчЯТЭМЫљЪОЃЌПЩМћЭЈЙ§ЛКДцМгЫйДѓДѓЬсИпСЫСїЫЎЯпЕФдЫаааЇТЪЁЃ
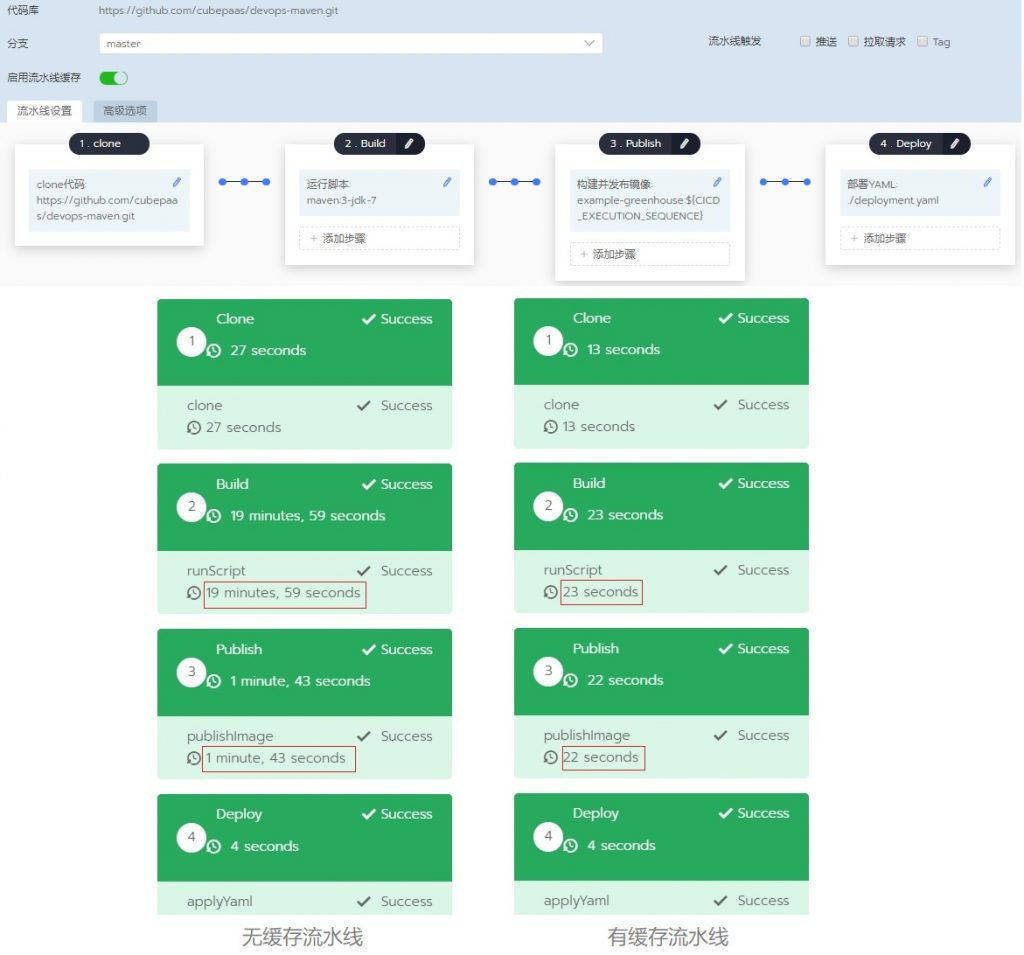
HCaaS DevOpsЪЙгУ
вдЩЯЩшМЦдкHCaaSЦНЬЈЩЯЕУЕНЪЕЯжЃЈhttps://cubepaas.comЃЉдкHCaaSПижЦЬЈЩЯЕуЛїDevOpsБъЧЉЃЌЭЈЙ§ДњТыЪкШЈКѓЃЌМДПЩЭЈЙ§UIНчУцЧсЫЩЕиБрМСїЫЎЯпЃЌвВПЩЭЈЙ§БрМyamlЮФМўХфжУОпЬхЕФЙІФмВНжшЃЌШчЭМЫљЪОЃК
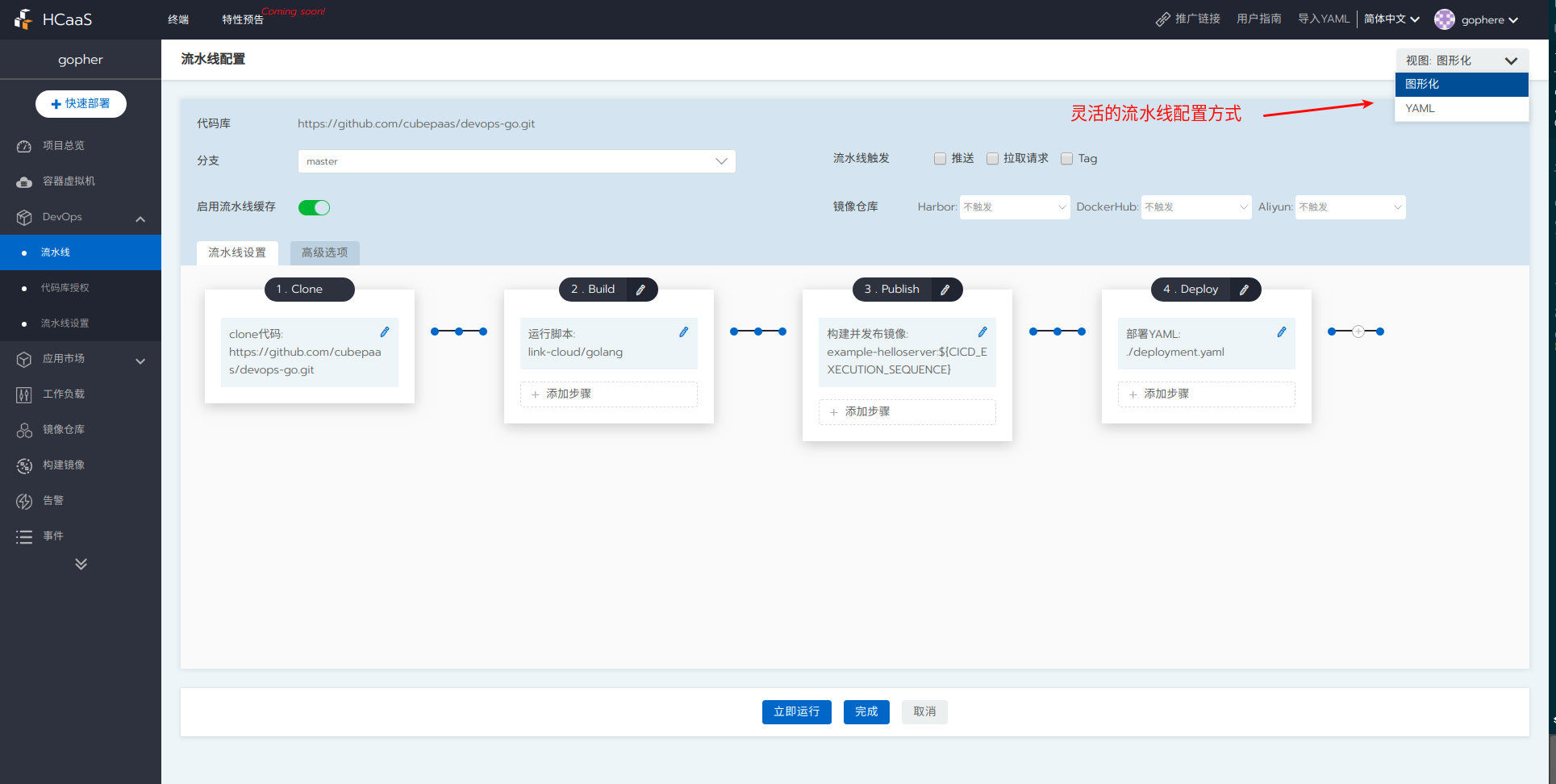
ЭЈЙ§ЕуЛїВщПДШежОЃЌФуПЩвдПДЕНpipelineИїИіНзЖЮдЫааЕФЯъЯИШежОаХЯЂЃЌШчЯТЭМЫљЪОЃК
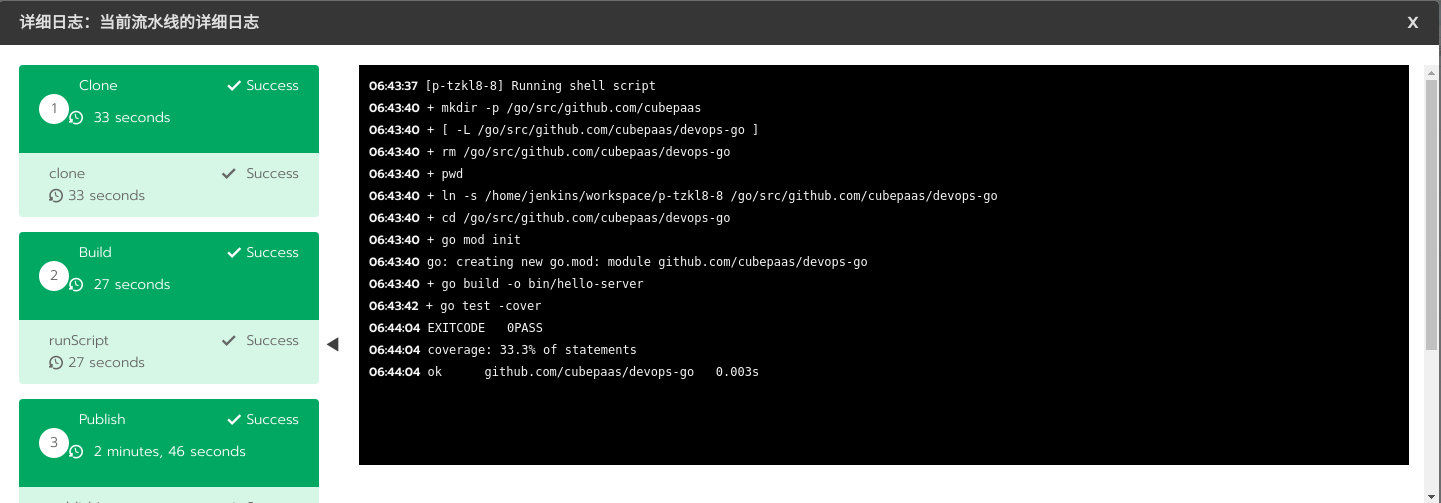
ЁОзЂвтЁПЪзДЮдЫааpipelineЪБЯЕЭГЛсДгЭјТчЯТдиJenkinsЁЂdockerЁЂminioвдМАЦфЫћpipeline-toolsОЕЯёЃЌЧыЩдзїЕШД§ЁЃШчЙћГЄЪБМфЮДдЫааЃЌЧыВщПДЭјТчЪЧЗёгаЮЪЬтЁЃ
|









