| 编辑推荐: |
|
预训练模型 BERT 在自然语言处理的各项任务中都展现了不错的效果。但在移动手机普及的今天,如何在移动端或者资源受限的设备上使用
BERT 模型,一直是个挑战,具体内容请看下文。
本文来自于SIGAI公众号,由火龙果软件Anna编辑、推荐。 |
|
概览
近几年,NLP 社区见证了一场预训练监督模型的革命。这些模型通常有数亿个参数,在这些模型中,BERT
的精度提升最为显著。然而,作为 NLP 中最大的模型之一,BERT 的模型容量大、时延高,使得资源有限的移动设备无法在基于移动的机器翻译、对话建模等方面发挥
BERT 的能力。
目前业界已经做了一些努力,特别是针对特定任务对 BERT 模型进行蒸馏。据我们所知,目前还没有任何工作能构建出一个与任务无关的轻量级预训练模型,也就是说,它需要跟原始
BERT 一样能在不同的下游 NLP 任务上进行一般的微调。在本文中,我们提出了 MobileBERT
来填补这一空白。在实际应用中,我们通常需要对 BERT 进行任务无关的压缩。特定任务的压缩需要先将原始的大
BERT 模型微调为特定任务的教师,然后再蒸馏。与直接微调任务无关的压缩模型相比,这样的过程要复杂得多,成本也更高。
乍一看,获得任务无关的压缩 BERT 似乎很简单。例如,可以取一个较窄或较浅版本的 BERT,通过最小化预测损失和蒸馏损失的凸组合来训练它直到收敛。不幸的是,实验结果表明,这种直接的方法会导致精度损失严重。这也许并不奇怪,众所周知,浅层网络通常没有足够的表示能力,而窄层和深层网络则很难训练。
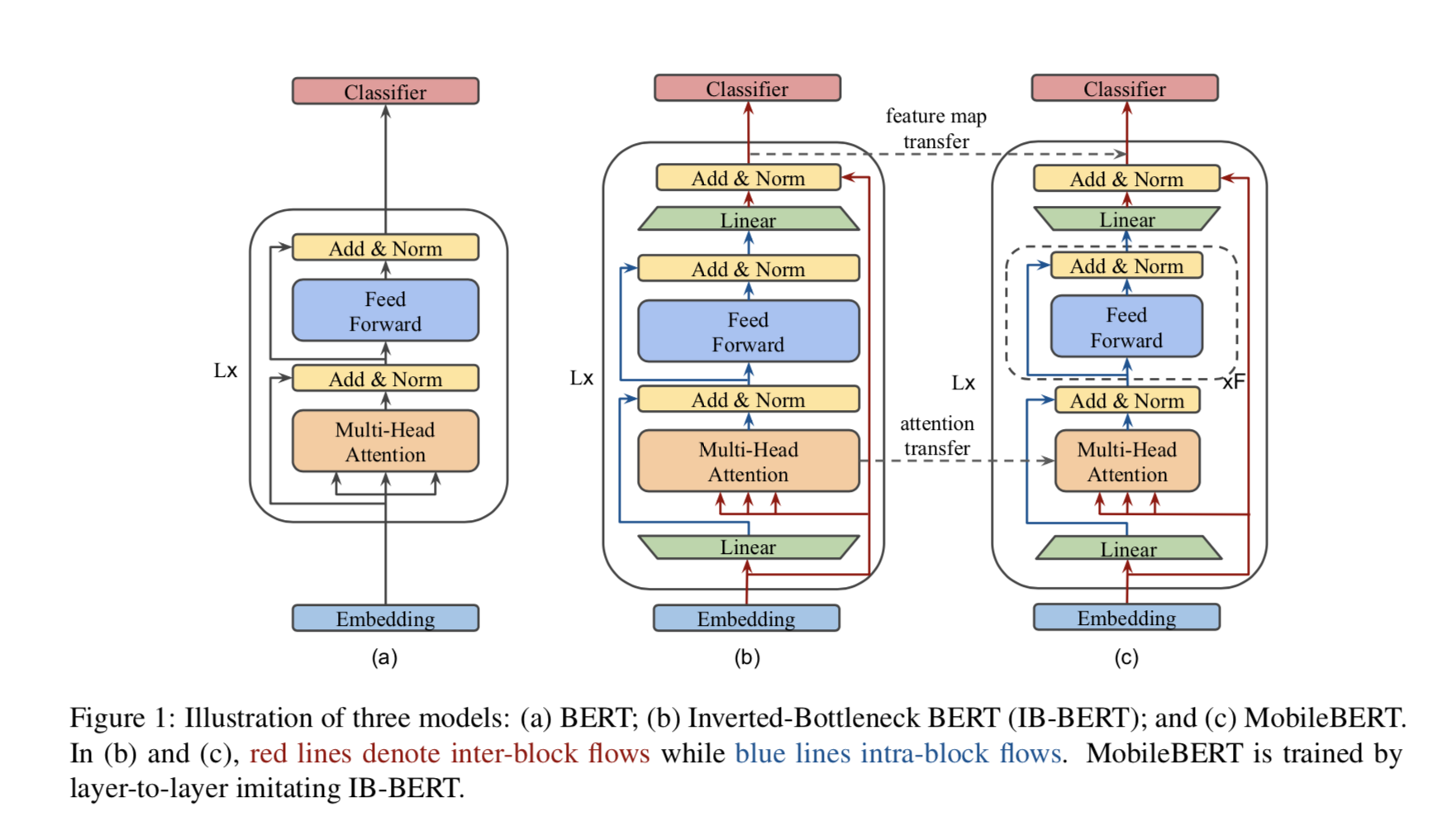
我们的 MobileBERT 被设计成和 BERT(LARGE)一样深,而每一层都通过采用 bottleneck
结构和平衡注意力机制和前馈网络进而使其变得更加狭窄(图 1)。为了训练 MobileBERT,我们首先训练了一个特殊设计的教师模型,一个包含
BERT(LARGE)模型(IB-BERT)的 inverted-bottleneck 模型。然后,我们将知识从
IB-BERT 迁移到 MobileBERT。我们在实证研究中仔细研究了各种知识迁移策略。
实证评估表明,MobileBERT 比 BERT(BASE)小 4.3 倍、快 5.5 倍,并且可以在知名的
NLP 基准上获得可观的结果。在 GLUE 的自然语言推理任务中,MobileBERT 的 GLUE
得分为 77.7,仅比 BERT(BASE)低 0.6,在 Pixel 4 手机上的延迟为 62ms。在
SQuAD v1.1/v2.0 问答任务中,MobileBER 获得的 dev F1 得分为 90.3/80.2,甚至比
BERT(BASE)高出 1.5/2.1。
MobileBERT 原理详解
在本节中,我们将详细介绍 MobileBERT 的体系结构设计和高效训练 MobileBERT 的训练策略。具体的模型配置汇总在表
1,这些配置是通过大量的结构搜索实验获得的,将在第 4.1 节中介绍。
瓶颈层和倒瓶颈层
MobileBERT 的体系结构如图 1(c)所示。它和 BERT(LARGE)一样深,但每个构建块都小得多。如表
1 所示,每个构建块的隐状态大小仅为 128。另一方面,我们为每个构建块引入两个线性变换,以将其输入和输出维度调整为
512。根据(He 等人,2016)中的术语,我们将这种架构称为瓶颈层。
训练这样一个深并且瘦小的网络是很大的挑战。为了解决这一问题,我们首先构建了一个教师网络,并对其进行训练直至收敛,然后将知识从这个教师网络迁移到
MobileBERT。我们发现这比从头开始直接训练 MobileBERT 的效果要好得多。各种训练策略将在后面的章节中讨论。这里,我们介绍教师网络的架构设计,如图
1(b)所示。事实上,教师网络就是 BERT(LARGE),同时增加了倒瓶颈结构(Sandler 等人,2018),将其
feature map 大小调整为 512。在下文中,我们将教师网络称为 IB-BERT(LARGE)。请注意,IB-BERT
和 MobileBERT 具有相同的 feature map 大小,即 512。因此,我们可以直接比较
IB-BERT 和 MobileBERT 的 layer-wise 输出的差异。我们的知识迁移战略需要这样一种直接的比较。
值得指出的是,同时引入瓶颈和倒瓶颈结构使得体系结构设计具有相当的灵活性。我们可以只使用 MobileBERT
的瓶颈(相应地,教师变为 BERT)或者只使用 IB-BERT 的倒瓶颈(MobileBERT 中没有瓶颈)来对齐它们的特征映射。然而,当使用这两种方法时,我们可以允许
IB-BERT(LARGE)在保证 MobileBERT 足够紧凑的同时保持 BERT(LARGE)的性能。
堆叠式前馈网络
MobileBERT 的瓶颈结构带来的一个问题是,多头注意力(MHA)模块和前馈网络(FFN)模块之间的平衡被打破。MHA
和 FFN 在 Transformer 结构中扮演着不同的角色:前者允许模型共同处理来自不同子空间的信息,而后者增加了模型的非线性。在原始的
BERT 中,MHA 和 FFN 中的参数之比总是 1:2。但在瓶颈结构中,MHA 的输入来自更宽的特征映射(块间大小),而
FFN 的输入来自更窄的瓶颈(块内大小)。这导致 MobileBERT 中的 MHA 模块相对包含更多的参数。
为了解决这个问题,我们建议在 MobileBERT 中使用堆叠式前馈网络来重新平衡 MHA 和 FFN
之间的相对大小。如图 1(c)所示,每个 MobileBERT 层包含一个 MHA,但多个堆叠的 FFN。在
MobileBERT 中,我们在每个 MHA 之后使用 4 个堆叠 FFN。
操作优化
通过模型延迟分析,我们发现,layer 层归一化(Ba 等人,2016)和 gelu 激活函数(Hendrycks
和 Gimpel,2016)占总延迟的相当大比例。因此,我们提议在 MobileBERT 中用新的操作来取代它们。
移除层归一化 我们将 n-channel 的隐状态 h 的层归一化替换为 element-wise
的线性变换:
式中,γ,β∈Rn 和 o 表示哈达玛积。请注意,即使在测试模式下,NoNorm 也具有与 LayerNorm
不同的属性,因为原始层归一化不是一个批向量的线性操作。
使用 relu 激活 我们用更简单的 relu 激活代替了 gelu 激活(Nair 和 Hinton,2010)。
Embedding 因子分解
BERT 模型中的嵌入表占模型大小的很大一部分。为了压缩嵌入层,如表 1 所示,我们将 MobileBERT
中的嵌入维度减少到 128。然后,我们对原始 token 嵌入应用核大小为 3 的一维卷积来产生 512
维的输出。
训练目标
我们提出使用以下两个知识迁移目标,即特征映射迁移和注意力迁移,来训练 MobileBERT。图 1
说明了提出的 layer-wise 的知识迁移目标。我们的最后对于第 l 层的知识迁移损失 L(KT)(l)是以下两个目标的线性组合:
特征映射迁移(FMT) 由于 BERT 中的每一层只把前一层的输出作为输入,因此在 layer-wise
的知识迁移中最重要的是每一层的特征映射应该尽可能接近教师的特征映射。特别地,MobileBERT 学生和
IB-BERT 教师的特征映射之间的均方误差被用作知识迁移目标:
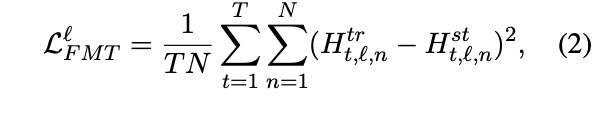
其中,l 是层的索引,T 是序列长度,N 是特征映射大小。在实际应用中,我们发现将这一损失项分解为归一化的特征映射差异和特征映射统计差异有助于训练的稳定性。
注意力迁移(AT) 注意机制极大地提高了 NLP 的性能,并成为 Transformer 和 BERT
中的一个关键构建块(Clark et al.,2019a;Jawahar et al.,2019)。这促使我们使用来自最优化教师的自注意力映射,以帮助
MobileBERT 在增强特征映射迁移方面的训练。特别是,我们最小化了 MobileBERT 学生和
IB-BERT 教师的每个注意力分布之间的 KL 距离:
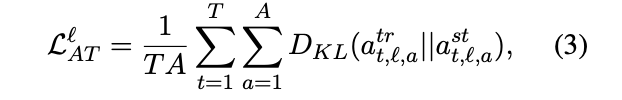
其中 A 是注意力的数量。
预训练蒸馏 (PD) 除了 layer-wise 的知识迁移,我们也可以在训练前使用知识蒸馏损失。我们使用原始掩码语言建模(MLM)损失、下一句预测(NSP)损失和新的
MLM 知识蒸馏(KD)损失的线性组合作为预训练的蒸馏损失:
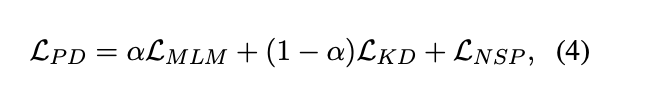
其中α是(0,1)中的超参数。
训练策略
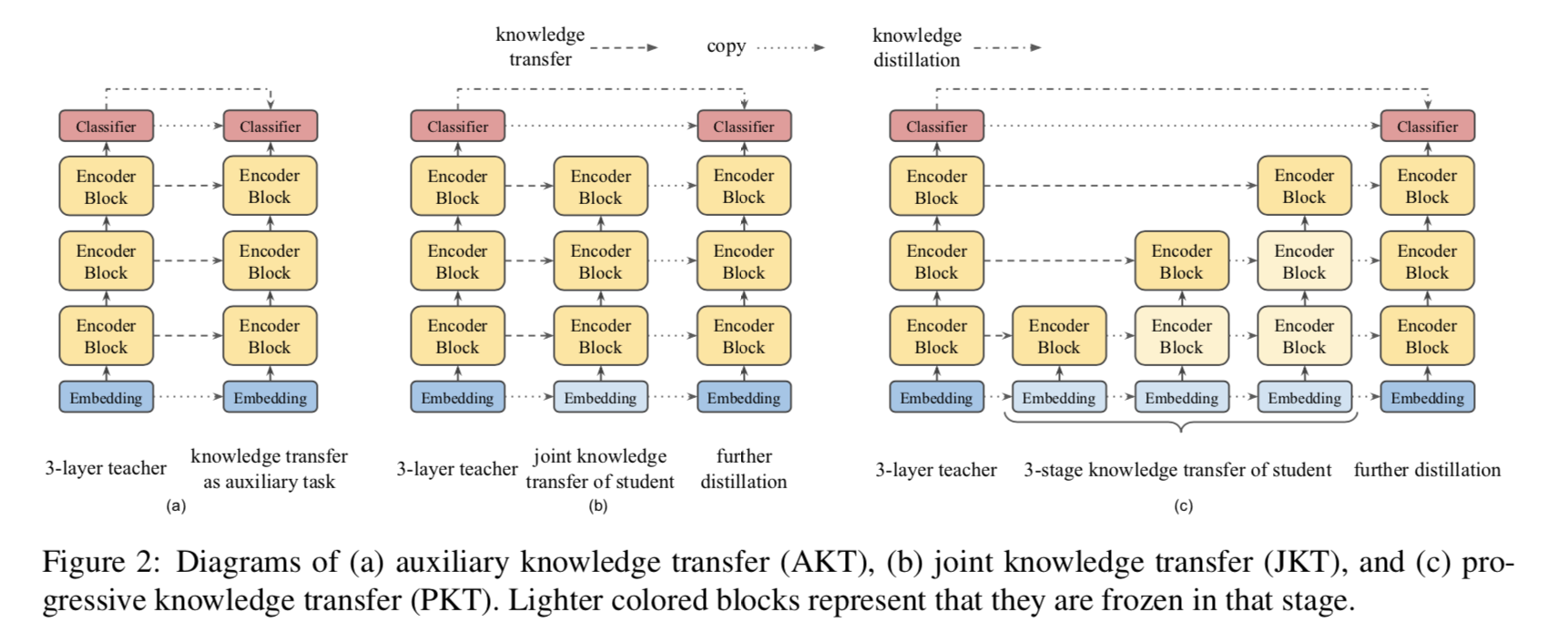
鉴于上述目标,在训练中可以有各种组合策略。本文讨论了三种策略。
辅助知识迁移 在该策略中,我们将中间知识迁移作为知识蒸馏的辅助任务。我们使用单个损失,它是来自所有层的知识迁移损失和预训练蒸馏损失的线性组合。
联合知识迁移 然而,IB-BERT 教师的中间知识(即注意力映射和特征映射)可能不是 MobileBERT
学生的最佳解决方案。因此,我们建议将这两个损失项分离开来,首先对 MobileBERT 进行 layer-wise
知识迁移损失联合训练,然后通过训练前蒸馏进一步训练。
渐进式知识迁移 人们还可能担心,如果 MobileBERT 不能完全模仿 IB-BERT 教师,来自较低层的错误可能会影响较高层的知识迁移。因此,我们建议在知识迁移的各个层面上逐步进行训练。渐进式知识迁移分为
L 个阶段,其中 L 是层的数目。
图 2 展示了这三种策略的示意图。对于联合知识迁移和渐进知识迁移,在 layer-wise 知识迁移阶段,初始嵌入层和最终分类器没有知识迁移。它们被
从 IB-BERT 老师复制了到 MobileBERT 学生。此外,对于渐进式的知识迁移,当我们训练第
l 层时,我们会冻结下面各层中所有可训练的参数。在实践中,我们可以将训练过程软化如下。当训练一个层时,我们进一步调整较低层的学习速度,而不是完全冻结。
实验
在这一部分中,我们首先介绍了我们的结构搜索实验,这些提供了表 1 中的模型设置,然后介绍了 MobileBERT
和各种基线的基准测试的经验结果。
模型设置
我们进行了广泛的实验,为 IB-BERT 老师和 MobileBERT 学生寻找良好的模型设置。我们从
SQuAD v1.1 dev F1 分数开始,作为搜索模型设置的性能指标。在这一部分中,我们只训练每个模型
125k 步,2048 个批次,这是原始 BERT 训练计划的一半。
IB-BERT 的体系结构搜索 我们对于教师模型的设计理念是尽可能使用小的块间隐藏大小(特征映射大小),只要不存在精度损失。在这个指导下,我们设计实验来操作
BERT(LARGE)大小的 IB-BERT 的块间大小,结果如表 2 所示,带有标签(a)-(e)。我们可以看到,减小块间隐状态大小不会损害
BERT 的性能,直到它小于 512。因此,我们选择块间隐状态大小为 512 的 IB-BERT(LARGE)作为教师模型。
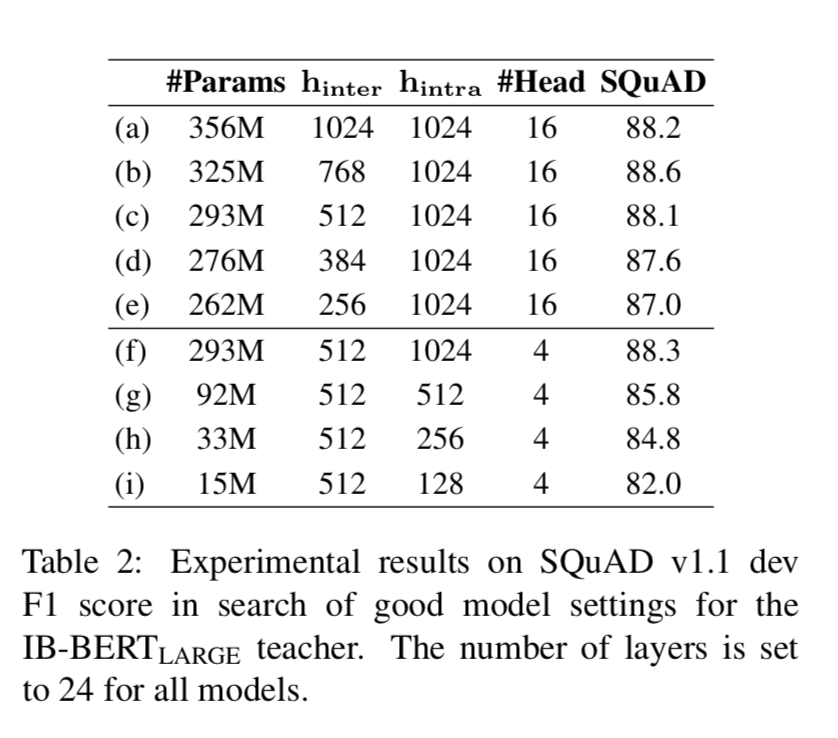
人们可能会怀疑我们是否也可以缩小教师的块内隐大小。我们进行了实验,结果如表 2 所示,带有标签(f)-(i)。我们可以看到,当块内隐大小减小时,模型的性能会大大降低。这意味着块内隐大小在
BERT 中起着至关重要的作用,它代表了非线性模块的表示能力。因此,与块间隐大小不同,我们不缩减教师模型的块内隐大小。
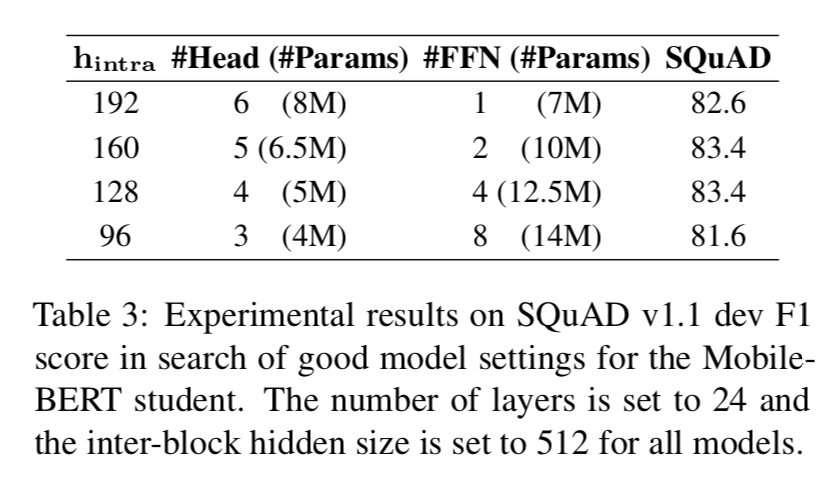
MobileBERT 的架构搜索 我们为 BERT(BASE)寻求 4 倍的压缩比,为了选择一个好的
MobileBERT 学生模型,因此我们设计了一组 MobileBERT 模型,这些模型的近似为 25M
参数,但 MHA 和 FFN 中的参数个数之比不同。表 3 显示了我们的实验结果。它们在 MHA 和
FFN 之间有不同的平衡。从表中可以看出,当 MHA 和 FFN 中的参数之比为 0.4~0.6 时,模型的性能达到峰值。这也许可以解释为什么原始
Transformer 选择 MHA 和 FFN 的参数比为 0.5。
考虑到模型的准确性和训练效率,我们选择 128 个块内隐大小和 4 个层叠 FFN 的结构作为 MobileBERT
学生模型。我们还相应地将教师模型中的注意力头数量设置为 4,为 layer-wise 知识迁移做准备。表
1 展示了 IB-BERT(LARGE)教师和 MobileBERT 学生的模型设置。
人们可能会怀疑,减少头的个数是否会损害教师模型的表现。通过比较表 2 中的(a)和(f),我们可以看出,将头数量从
16 个减少到 4 个并不影响 IB-BERT(LARGE)的性能。
实现细节
继 BERT(Devlin et al,2018)之后,我们使用了 BookCorpus(Zhu et
al.,2015)和英文的 Wikipedia 作为我们的预训练数据。为了使 IB-BERT(LARGE)教师达到与原始
BERT(LARGE)相同的精度,我们在 256 TPU v3 芯片上对 IB-BERT(LARGE)进行
500 步训练,批量大小为 4096,采用 LAMB 优化器(You 等人,2019)。
为了与最初的 BERT 进行公平的比较,我们不在其他 BERT 变体中使用训练技巧(Liu et
al,2019b;Joshi et al,2019)。对于 MobileBERT,我们在训练前蒸馏阶段使用相同的训练计划。此外,我们使用渐进式的知识迁移来训练
MobileBERT,它在 24 层上额外增加了 240k 步数。在消融研究中,我们将 MobileBERT
的预训练蒸馏计划减半,以加速实验。此外,在知识迁移策略的消融研究中,为了公平比较,联合知识迁移和辅助知识迁移也采取了额外的
240k 步。
对于下游任务,所有报告的结果都是通过简单的微调 MobileBERT 获得的,就像原始 BERT
所做的那样。为了对预先训练的模型进行微调,我们在搜索空间中搜索优化超参数,包括不同的批大小(16/32/48)、学习率((1-10)*e-5)和
epoch 数(2-10)。搜索空间不同于原始的 BERT,因为我们发现 MobileBERT 通常需要更高的学习率和更多的微调训练时间。我们根据它们在验证集上的性能来选择测试模型。
在 GLUE 的结果
通用语言理解评估(GLUE)基准(Wang 等人,2018)是 9 项自然语言理解任务的集合。我们比较了
MobileBERT 和 BERT(BASE),以及 GLUE 排行榜上一些最先进的预训练 BERT
模型:OpenAI GPT(Radford 等人,2018)和 ELMo(Peters 等人,2018)。我们还比较了最近提出的三种压缩
BERT 模型:BERT-PKD(Sun et al,2019)和 DistilBERT(Sanh
et al.,2019)。为了进一步显示 MobileBERT 模型相对于最近的 small BERT
模型的优势,我们还评估了 MobileBERT(TINY)模型的一个较小的变量,该模型的参数约为 15M,它减少了每个层中的
ffn 数量,并使用了较轻的 MHA 结构。此外,为了验证 MobileBERT 在实际移动设备上的性能,我们使用
TensorFlow Lite API 导出模型,并在固定序列长度为 128 的 4 个线程的 Pixel
4 phone 上测量推理延迟。结果见表 4。
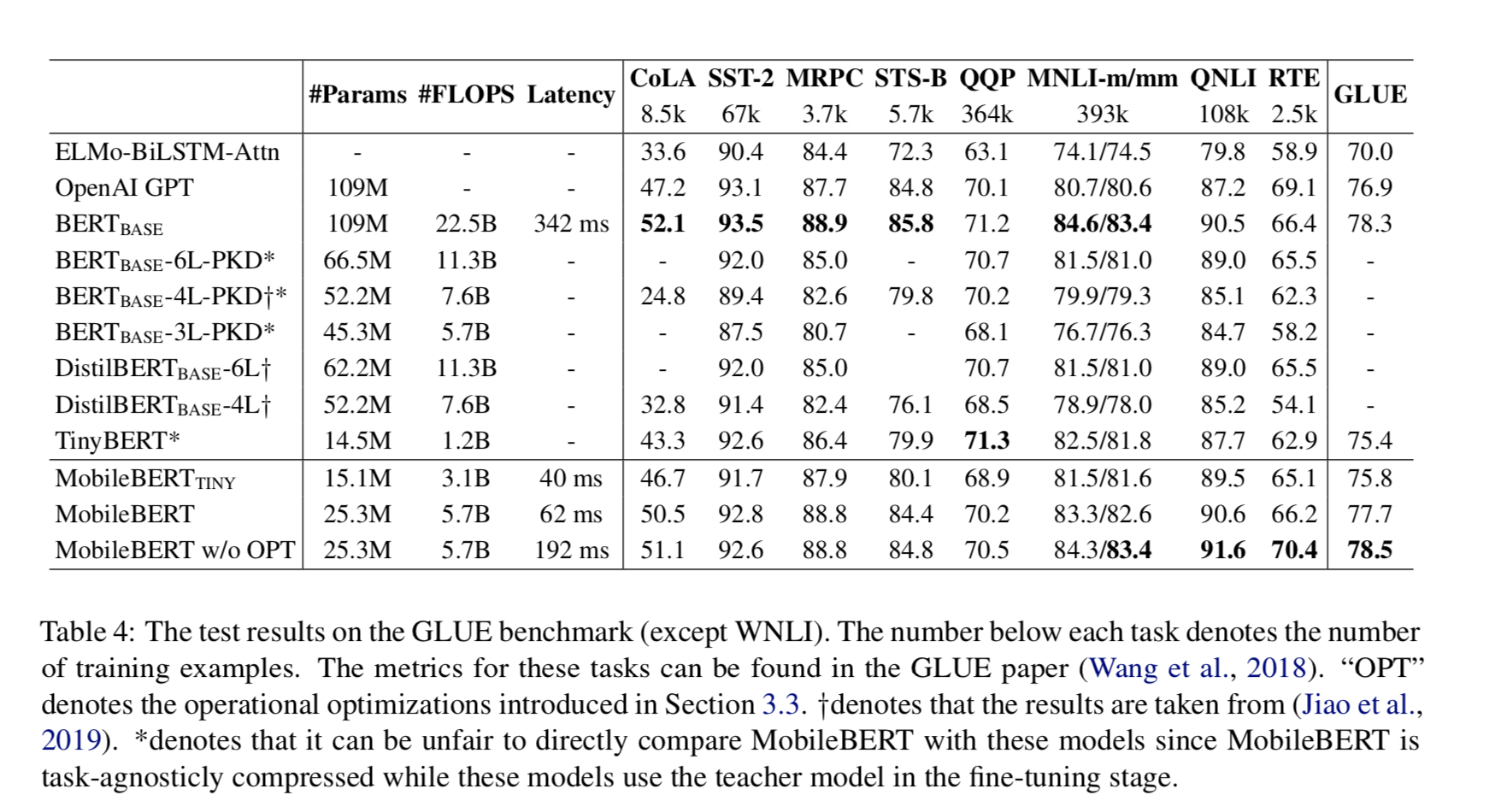
从表中我们可以看出,MobileBERT 在 GLUE 基准上非常有竞争力。MobileBERT 的
GLUE 总分为 77.7 分,仅比 BERT(BASE)低 0.6 分,比 BERT(BASE)小
4.3 倍,快 5.5 倍。此外,它在 4.3×更小的模型尺寸下,比强大的 OpenAI GPT 基线性能好
0.8 个 GLUE 分数。它的性能也优于其他所有较小或相似大小的压缩 BERT 模型。最后,我们发现引入的操作优化对模型性能造成了一定的影响。如果没有这些优化,MobileBERT
甚至可以比 BERT(BASE)高出 0.2 个 GLUE 分数。
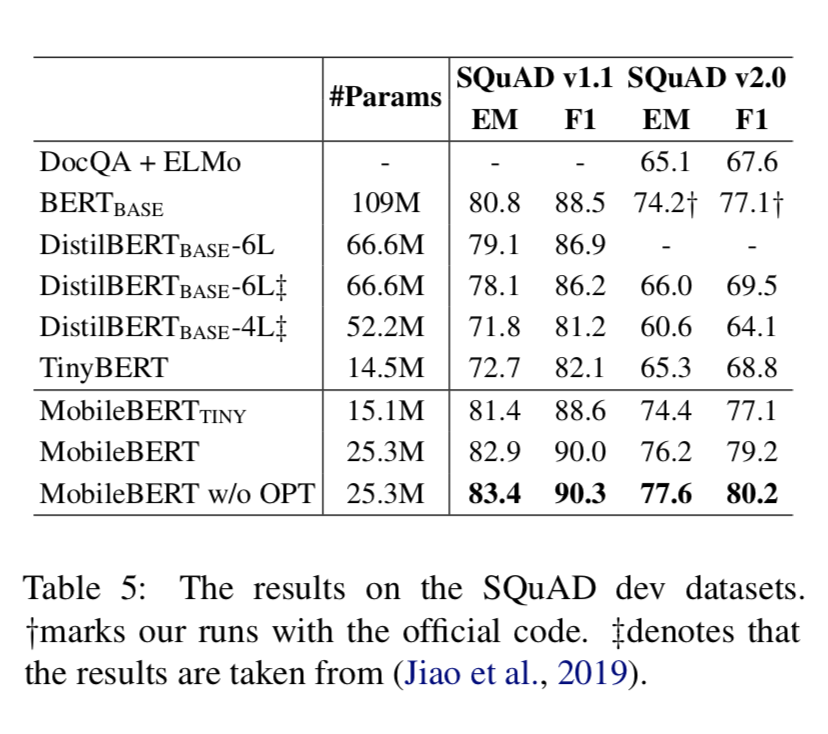
在 SQuAD 的结果
SQuAD 是一个大型阅读理解数据集。SQuAD1.1(Rajpurkar 等人,2016)仅包含给定上下文有答案的问题,而
SQuAD2.0(Rajpurkar 等人,2018)包含无法回答的问题。我们只在 SQuAD 验证数据集上评估
MobileBERT,因为在 SQuAD 测试排行榜上几乎没有单一的模型提交。我们将我们的 MobileBERT
与 BERT(BASE)、DistilBERT 和强大的基线 DocQA 进行了比较(Clark 和
Gardner,2017)。
如表 5 所示,MobileBERT 的表现优于其他较小或相似的模型。
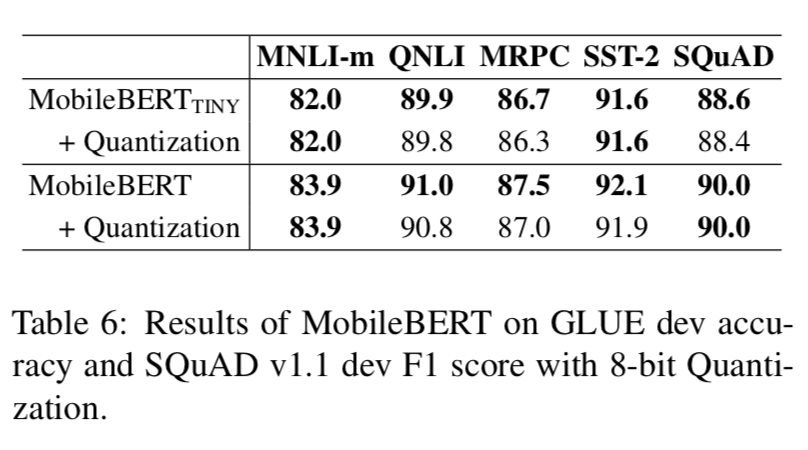
量化
我们将 TensorFlow Lite 中的标准训练后量化应用于 MobileBERT。结果见表 6。我们发现,虽然量化可以进一步压缩
MobileBERT 4 倍,但几乎没有性能下降。这表明 MobileBERT 在压缩方面还有很大的空间。
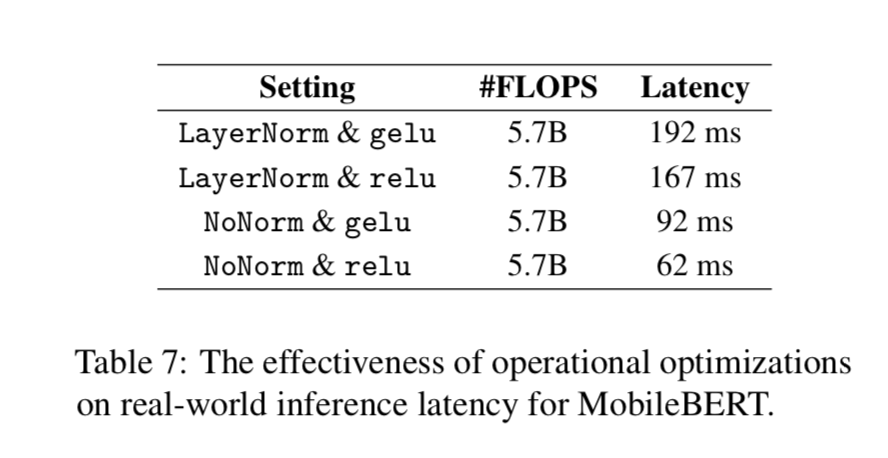
消融实验
操作优化 我们评估了第 3.3 节中介绍的两种操作优化的有效性,即用 NoNorm 替换层归一化(LayerNorm)和用
relu 替换 gelu 激活。我们报告推理延迟,使用与第 4.6.1 节相同的实验设置。从表 7
可以看出,NoNorm 和 relu 在降低 MobileBERT 的延迟方面都非常有效,而这两种操作优化并没有减少
FLOPS。这揭示了真实世界的推理延迟和理论计算开销(即 FLOPS)之间的差距。
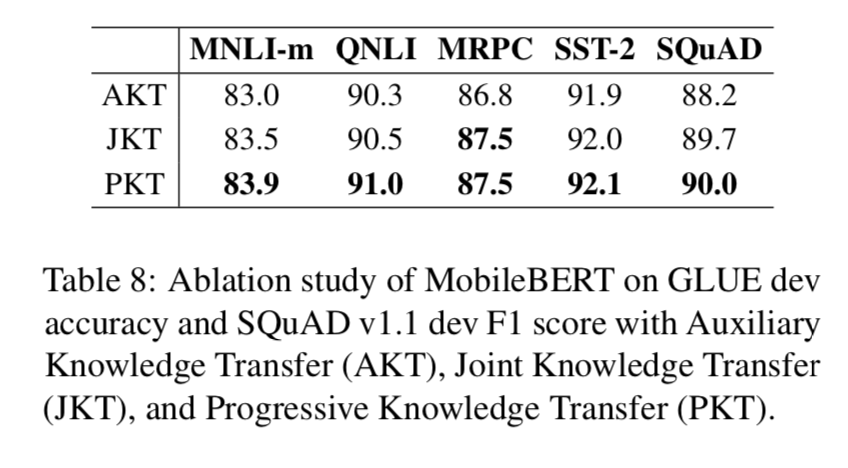
训练策略 研究了辅助知识迁移、联合知识迁移、渐进知识迁移等训练策略的选择对 MobileBERT 效果的影响。如表
8 所示,渐进式知识迁移策略明显优于其他两种策略。我们注意到辅助知识迁移与其他两种策略之间存在显著的效果差距。我们认为原因是教师的中间层知识(即注意力映射和特征映射)可能对学生不是最优的,所以学生需要一个额外的预训练蒸馏阶段来微调其参数。
训练目标 最后,我们进行了一组关于注意迁移(AT)、特征映射迁移(FMT)和预训练蒸馏(PD)的消融实验。在这些实验中,操作优化(OPT)被重新移除,以便在
MobileBERT 和原始 BERT 之间进行公平的比较。结果见表 9。
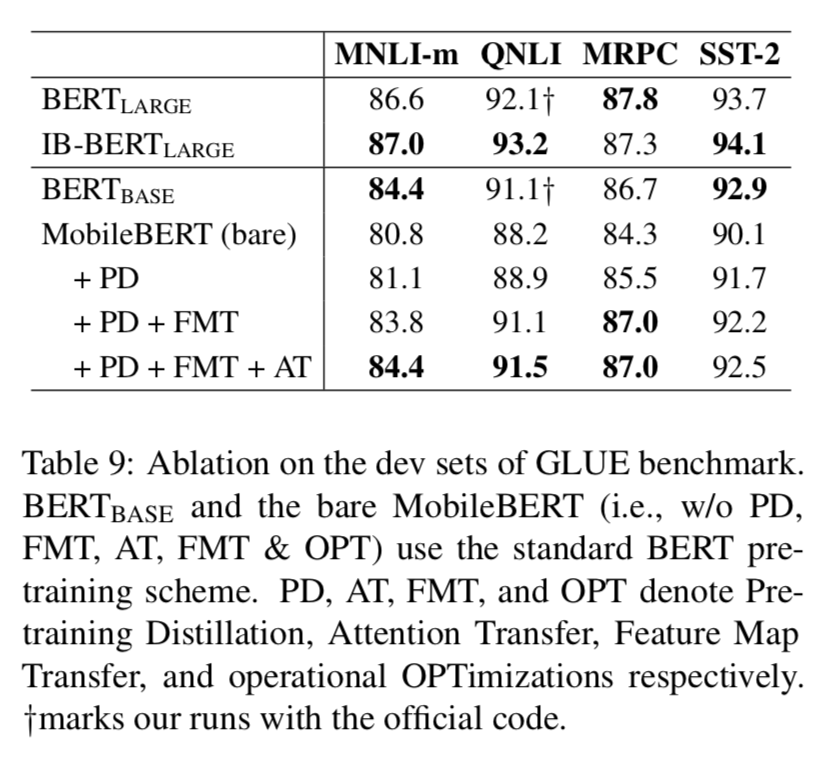
我们可以看出,所提出的特征映射变换对 MobileBERT 的性能提高贡献最大,而注意迁移和预训练蒸馏也起到了积极的作用。我们还可以发现,我们的
IB-BERT(LARGE)老师和原来的 IB-BERT(LARGE)老师一样强大,而 MobileBERT
老师相比之下却退化了很多。因此,我们相信 MobileBERT 仍有很大的改进空间。
结论
我们介绍了 MobileBERT,它是 BERT 的一个任务无关的压缩变种。对流行的 NLP 基准的实证结果表明,MobileBERT
可以与 BERT(BASE)相媲美,同时更小更快。MobileBERT 可以使各种 NLP 应用程序轻松地部署在移动设备上。
本文的研究表明:1)保持 MobileBERT 的深度和厚度是关键;2)瓶颈/倒瓶颈结构能够实现有效的
layer-wise 知识迁移;3)渐进式知识迁移能够有效地训练 MobileBERT。我们相信我们的发现是通用的,可以应用于其他模型压缩问题。 |









