| 编辑推荐: |
本文主要介绍深度学习模型压缩和加速算法的三个方向,分别为加速网络结构设计、模型裁剪与稀疏化、量化加速。
本文来自于SIGAI公众号,由火龙果软件Anna编辑、推荐。 |
|
摘要
目前在深度学习领域分类两个派别,一派为学院派,研究强大、复杂的模型网络和实验方法,为了追求更高的性能;另一派为工程派,旨在将算法更稳定、高效的落地在硬件平台上,效率是其追求的目标。复杂的模型固然具有更好的性能,但是高额的存储空间、计算资源消耗是使其难以有效的应用在各硬件平台上的重要原因。所以,卷积神经网络日益增长的深度和尺寸为深度学习在移动端的部署带来了巨大的挑战,深度学习模型压缩与加速成为了学术界和工业界都重点关注的研究领域之一。
I. 加速网络设计
分组卷积
分组卷积即将输入的feature maps分成不同的组(沿channel维度进行分组),然后对不同的组分别进行卷积操作,即每一个卷积核至于输入的feature
maps的其中一组进行连接,而普通的卷积操作是与所有的feature maps进行连接计算。分组数k越多,卷积操作的总参数量和总计算量就越少(减少k倍)。然而分组卷积有一个致命的缺点就是不同分组的通道间减少了信息流通,即输出的feature
maps只考虑了输入特征的部分信息,因此在实际应用的时候会在分组卷积之后进行信息融合操作,接下来主要讲两个比较经典的结构,ShuffleNet[1]和MobileNet[2]结构。
1) ShuffleNet结构:
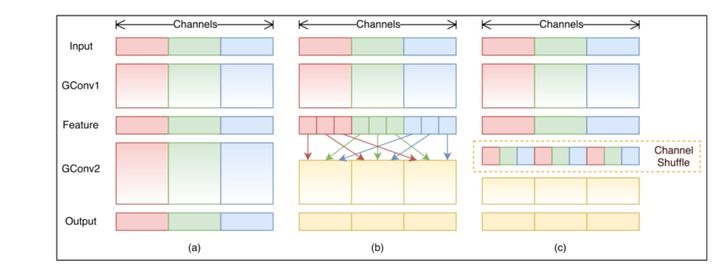
如上图所示,图a是一般的group convolution的实现效果,其造成的问题是,输出通道只和输入的某些通道有关,导致全局信息
流通不畅,网络表达能力不足。图b就是shufflenet结构,即通过均匀排列,把group convolution后的feature
map按通道进行均匀混合,这样就可以更好的获取全局信息了。 图c是操作后的等价效果图。在分组卷积的时候,每一个卷积核操作的通道数减少,所以可以大量减少计算量。
2) MobileNet结构:
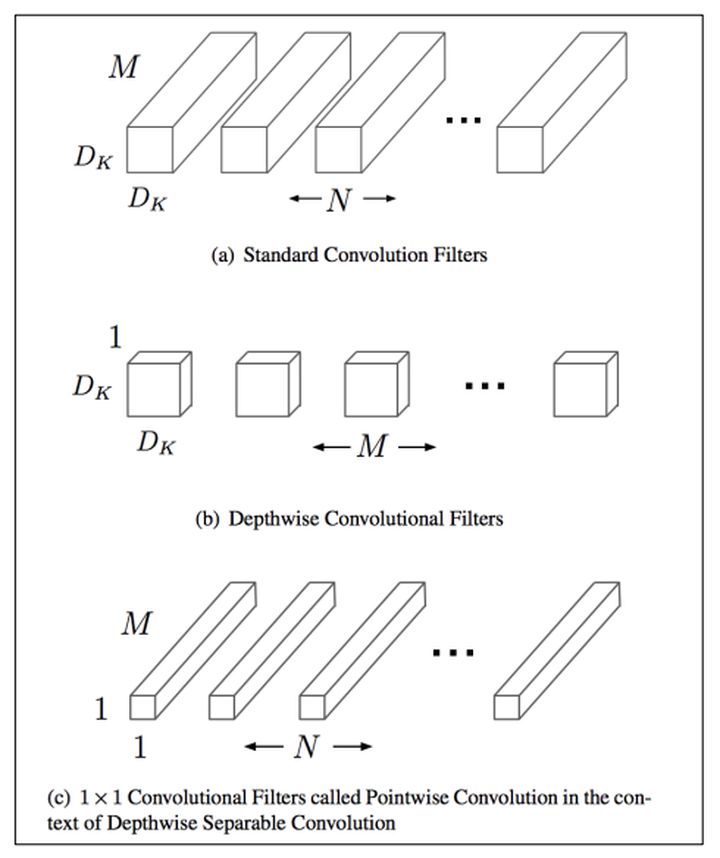
如上图所示,mobilenet采用了depthwise separable convolutions的思想,采用depthwise
(或叫channelwise)和1x1 pointwise的方法进行分解卷积。其中depthwise
separable convolutions即对每一个通道进行卷积操作,可以看成是每组只有一个通道的分组卷积,最后使用开销较小的1x1卷积进行通道融合,可以大大减少计算量。
分解卷积
分解卷积,即将普通的kxk卷积分解为kx1和1xk卷积,通过这种方式可以在感受野相同的时候大量减少计算量,同时也减少了参数量,在某种程度上可以看成是使用2k个参数模拟k*k个参数的卷积效果,从而造成网络的容量减小,但是可以在较少损失精度的前提下,达到网络加速的效果。
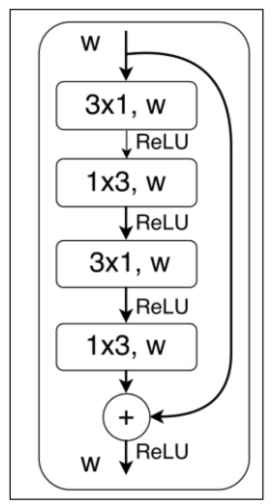
右图是在图像语义分割任务上取得非常好的效果的ERFNet[3]的主要模块,称为NonBottleNeck结构借鉴自ResNet[4]中的Non-Bottleneck结构,相应改进为使用分解卷积替换标准卷积,这样可以减少一定的参数和计算量,使网络更趋近于efficiency。
Bottleneck结构
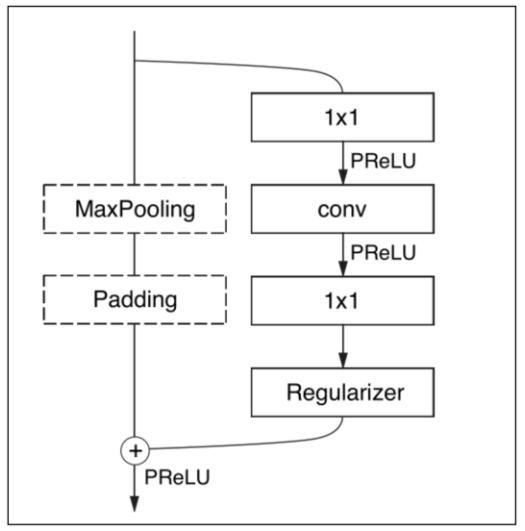
右图为ENet[5]中的Bottleneck结构,借鉴自ResNet中的Bottleneck结构,主要是通过1x1卷积进行降维和升维,能在一定程度上能够减少计算量和参数量。其中1x1卷积操作的参数量和计算量少,使用其进行网络的降维和升维操作(减少或者增加通道数)的开销比较小,从而能够达到网络加速的目的。
C.ReLU[7]结构
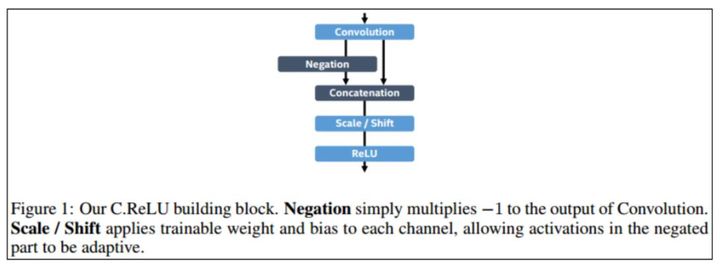
C.ReLU来源于CNNs中间激活模式引发的。输出节点倾向于是"配对的",一个节点激活是另一个节点的相反面,即其中一半通道的特征是可以通过另外一半通道的特征生成的。根据这个观察,C.ReLU减少一半输出通道(output
channels)的数量,然后通过其中一半通道的特征生成另一半特征,这里使用 negation使其变成双倍,最后通过scale操作使得每个channel(通道)的斜率和激活阈值与其相反的channel不同。
SqueezeNet[8]结构
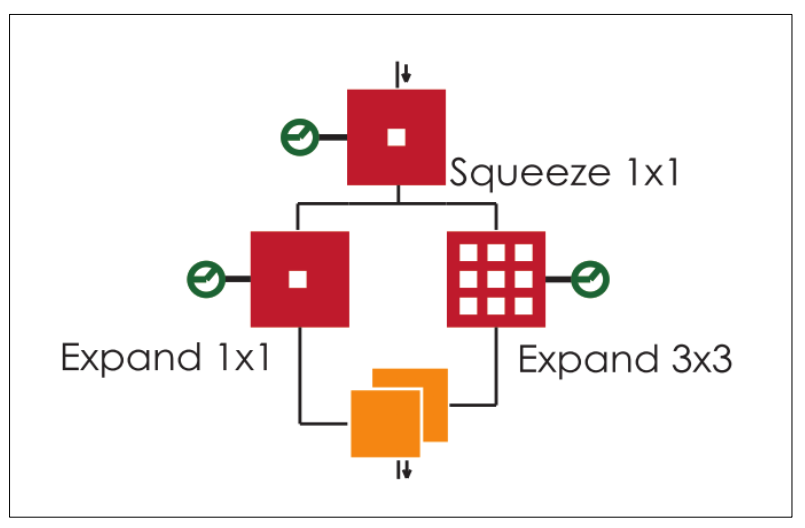
SqueezeNet思想非常简单,就是将原来简单的一层conv层变成两层:squeeze层+expand层,各自带上Relu激活层。在squeeze层里面全是1x1的卷积kernel,数量记为S11;在expand层里面有1x1和3x3的卷积kernel,数量分别记为E11和E33,要求S11
< input map number。expand层之后将 1x1和3x3的卷积output
feature maps在channel维度拼接起来。
神经网络搜索[18]
神经结构搜索(Neural Architecture Search,简称NAS)是一种自动设计神经网络的技术,可以通过算法根据样本集自动设计出高性能的网络结构,在某些任务上甚至可以媲美人类专家的水准,甚至发现某些人类之前未曾提出的网络结构,这可以有效的降低神经网络的使用和实现成本。
NAS的原理是给定一个称为搜索空间的候选神经网络结构集合,用某种策略从中搜索出最优网络结构。神经网络结构的优劣即性能用某些指标如精度、速度来度量,称为性能评估,可以通过NAS自动搜索出高效率的网络结构。
总结
本节主要介绍了模型模型设计的思路,同时对模型的加速设计以及相关缺陷进行分析。总的来说,加速网络模型设计主要是探索最优的网络结构,使得较少的参数量和计算量就能达到类似的效果。
II. Winograd、模型裁剪与稀疏化
FFT / Winograd的卷积算法[19]
FFT / Winograd的卷积算法即通过某种线性变换将feature map和卷积核变换到另外一个域,空间域下的卷积在这个域下变为逐点相乘,再通过另一个线性变换将结果变换到空间域。FFT卷积采用傅里叶变换处理feature
map和卷积核,傅里叶逆变换处理结果;Winograd卷积使用了其他的线性变换。
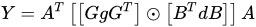
具体而言FFT将空间意义上的实数变换到频域上的复数,最后在复数上做逐点相乘,然后再把这个频率的复数变化为这个空间域的实数。Winograd则是一直在实数域上进行变换。事实上由于FFT需要复数乘法,如果没有特殊指令支持的话需要用实数乘法来模拟,实数的浮点计算量可能下降的不多。因此FFT也没有Winograd实用。FFT和Winograd变化实际上是可以实现极高的一个加速比,举个例子,Winograd变换对于3×3卷积,最高可以实现9倍的加速比,但精度损失严重。当然我们实际上不会用那么大,可能会用到6倍,那么这时候精度损失还是可以接受的。
模型剪枝
结构复杂的网络具有非常好的性能,其参数也存在冗余,因此对于已训练好的模型网络,可以寻找一种有效的评判手段,将不重要的connection或者filter进行裁剪来减少模型的冗余。
剪枝方法基本流程如下[9]:
1. 正常流程训练一个神经网络,得到训练好的model;
2. 确定一个需要剪枝的层,一般为全连接层,设定一个裁剪阈值或者比例。实现上,通过修改代码加入一个与参数矩阵尺寸一致的mask矩阵。mask矩阵中只有0和1,实际上是用于重新训练的网络。
3. 重新训练微调,参数在计算的时候先乘以该mask,则mask位为1的参数值将继续训练通过BP调整,而mask位为0的部分因为输出始终为0则不对后续部分产生影响。
4. 输出模型参数储存的时候,因为有大量的稀疏,所以需要重新定义储存的数据结构,仅储存非零值以及其矩阵位置。重新读取模型参数的时候,就可以还原矩阵。
神经网络的参数量往往非常多,而其中大部分的参数在训练好之后都会趋近于零,对整个网络的贡献可以忽略不计。通过剪枝操作可以使网络变得稀疏,需要存储的参数量减少,但是剪枝操作同样会降低整个模型的容量(参数量减少),在实际训练时,有时候会通过调整优化函数,诱导网络去利用模型的所有参数,实质上就是减少接近于零的参数量。最后,对于如何自动设定剪枝率,如何自适应设定剪枝阈值,在这里不做过多讨论。
核的稀疏化
核的稀疏化,是在训练过程中,对权重的更新加以正则项进行诱导,使其更加稀疏,使大部分的权值都为0。核的稀疏化方法分为regular和irregular,regular的稀疏化后,裁剪起来更加容易,尤其是对im2col的矩阵操作,效率更高;而irregular的稀疏化会带来不规则的内存访问,参数需要特定的存储方式,或者需要平台上稀疏矩阵操作库的支持,容易受到带宽的影响,在GPU等硬件上加速并不明显。
论文[10]提出了Structured Sparsity Learning的学习方式,能够学习一个稀疏的结构来降低计算消耗,所学到的结构性稀疏化能够有效的在硬件上进行加速。由于在GEMM中将weight
tensor拉成matrix的结构(即im2col操作),因此可以通过将filter级与shape级的稀疏化进行结合来将2D矩阵的行和列稀疏化,再分别在矩阵的行和列上裁剪掉剔除全为0的值可以来降低矩阵的维度从而提升模型的运算效率。该方法是regular的方法,压缩粒度较粗,可以适用于各种现成的算法库,但是训练的收敛性和优化难度不确定。
论文[11]提出了一种动态的模型裁剪方法,包括以下两个过程:pruning和splicing,其中pruning就是将认为不中要的weight裁掉,但是往往无法直观的判断哪些weight是否重要,因此在这里增加了一个splicing的过程,将哪些重要的被裁掉的weight再恢复回来。该算法采取了剪枝与嫁接相结合、训练与压缩相同步的策略完成网络压缩任务。通过网络嫁接操作的引入,避免了错误剪枝所造成的性能损失,从而在实际操作中更好地逼近网络压缩的理论极限。属于irregular的方式,但是权值(网络连接)重要性评估在不同的模型以及不同的层中无法确定,并且容易受到稀疏矩阵算法库以及带宽的限制,在相关GPU等硬件环境下加速不明显。
III. 量化加速
二值权重网络[12]
二值权重网络(BWN)是一种只针对神经网络系数二值化的二值网络算法。BWN只关心系数的二值化,并采取了一种混和的策略,构建了一个混有单精度浮点型中间值与二值权重的神经网络--BinaryConnect。BinaryConnect在训练过程中针对特定层的权重进行数值上的二值化,即把原始全精度浮点权重强行置为-1、+1两个浮点数,同时不改变网络的输入和层之间的中间值,保留原始精度。而真正在使用训练好的模型时,由于权重的取值可以抽象为-1、+1,因此可以采用更少的位数进行存放,更重要的是,很显然权重取值的特点使得原本在神经网络中的乘法运算可以被加法代替。
乘法运算转变为加法的好处在于:计算机底层硬件在实现两个n位宽数据的乘法运算时必须完成2*n位宽度的逻辑单元处理,而同样数据在执行加法时只需要n个位宽的逻辑单元处理,因此理论上可以得到2倍的加速比。
二值神经网络[13]
由于BWN取得的成功,人们开始尝试对二值网络进行更加深入的研究改造,并试图从中获得更大的性能提升。其中,最重要的基础工作是Matthieu
Courbariaux 等人在几个月后提出的二值神经网络(BNN)。这一方法在BWN的基 础上进一步加大二值化力度,进而完全改变了整个神经网络中的计算方式,将所需的计算量压缩到极低的水平。
BNN要求不仅对权重做二值化,同时也要对网络中间每层的输入值进行二值化,这一操作使得所有参与乘法运算的数据都被强制转换为“-1”、“+1”二值。我们知道计算机的硬件实现采用了二进制方式,而神经网络中处理过的二值数据
恰好与其一致,这样一来就可以考虑从比特位的角度入手优化计算复杂度。
BNN也正是这样做的:将二值浮点数“-1”、“+1”分别用一个比特“0”、“1”来表示,这样,原本占用32个比特位的浮点数现在只需1个比特位就可存放,稍加处理就可以实现降低神经网络前向过程中内存占用的效果。同时,一对“-1”、“+1”进行乘法运算,得到的结果依然是“-1”、“+1”,通过这一特性就可将原本的浮点数乘法用一个比特的位运算代替,极大的压缩了计算量,进而达到提高速度、降低能耗的目的。然而,大量的实验结果表明,BNN只在小规模数据集上取得了较好的准确性,在大规模数据集上则效果很差。
同或网络[14](XNOR-net)
XNOR-net是一种针对CNN的简单、高效、准确近似方法,它的核心思想是:在BNN的基础上,针对二值化操作给每一层数据造成的误差,引入最佳的近似因子,以此来弥补二值化带来的精度损失,提高训练精度的同时还能保持BNN在速度和能耗方面的优势。
在BNN中,无论对权重二值化还是对中间值二值化,都会给本身的全精度数据造成严重的精度损失。而我们知道全精度数据本身是可以得到较好的训练效果的,因此,减小二值化带来的精度损失以达到全精度时能够实现的良好效果是最直接的思路。XNOR-net的解决办法是引入近似因子,并且针对权重和中间值分别引入近似因子,在一次计算后将近似因子添加到计算结果中去,通过少量的额外计算来弥补尽可能多的精度损失。
同时,如果卷积的所有操作数都是二值的,则可以通XNOR和位计数操作估计卷积,如下图所示:
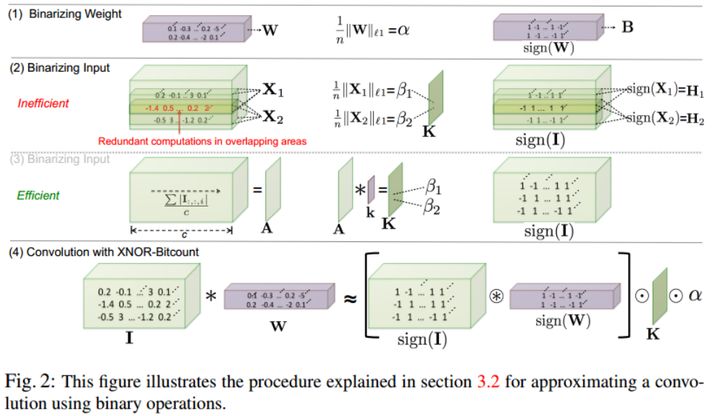
如上图第三和第四行所示,正常两个矩阵之间的点乘如果用在两个二值矩阵之间,那么就可以将点乘换成XNOR-Bitcounting
operation,从32位浮点数之间的操作直接变成1位的XNOR门操作,这就是加速的核心。
同或网络在大规模数据集上的效果取得了巨大进步,其中在ImageNet上的正确性只比全精度的相同网络低十个百分点。但是,在很多复杂任务中,这一结果依然不能满足生产生活的需要。
三值权重网络[15]
三值网络主要是指三值权重网络(TWN)。二值网络中精度的损失主要来自于 对数据强置为(-1, +1)时与本身全精度之间产生的误差,而神经网络中训练得到的
权重服从均值为 0 的正态分布,这就意味着绝大部分权重在二值后会产生将近1的误差,这对计算结果造成的影响将是十分巨大的。为了解决这一问题,提高二值网络的正确率,Fengfu
Li和 Bo Zhang等人在二值的基础上提出了TWN。
TWN的核心在于计算出量化阈值Δ,将数值大小处于阈值内的数据强置为0,其他值依然强置为-1或+1,对于阈值的计算,作者也给了论证,能够最小三值化误差所带来的精度损失,还能够使神经网络权重稀疏化,减小计算复杂度的同时也能得到更好的准确率和泛化能力。在运行效率上,TWN与BWN相当,但是准确率却有着明显的提升。
量化神经网络[16]
Song Han等人在量化神经网络(QNN)方面做了大量研究工作。这一网络的主要目的是裁剪掉数据的冗余精度,原本32位精度的浮点数由“1
8 23”的结构构成,裁剪的方法是根据预训练得到的全精度神经网络模型中的数据分布,分别对阶码和位数的长度进行适当的减少。实验证明,对于大部分的任务来说,6位比特或者8位比特的数据已经能够保证足够好的测试准确率。
QNN在实际的操作中通常有两种应用方式,一种是直接在软件层面实现整形的量化,通过更少的数据位数来降低神经网络在使用时计算的复杂度;另一种重要的应用是针对于AI专用芯片的开发。
由于芯片开发可以设计各种位宽的乘法器,因此将神经网络中32位的全精度数据可以被处理成6位或8位的浮点数,同时结合硬件指定的乘法规则,就可以在硬件上实现更高的运算效率,达到实时运行深度神经网络的目的。这也是QNN最大的理论意义。但是如果从软件角度而非硬件角度出发,只是将浮点数量化成整形数,就没有办法显著地降低计算复杂度(除非对整形再进行量化),也就无法达到在低配硬件环境上实时运行深度神经网络的目的。因此,在软件设计的层面上,QNN相比BNN并没有特别明显的优势。
总结
本节主要介绍量化加速在深度学习模型压缩和加速方向的应用,涉及到的主要技术包括:二值权重网络、二值神经网络、同或网络、三值权重网络、量化神经网络等。在对网络进行加速的同时,通过不同的优化策略来降低精度的损失。
总结
本文主要介绍了三种主流的深度学习模型压缩和模型加速的方向,分别为:加速网络结构设计,即通过优化网络结构的设计去减少模型的冗余和计算量;模型裁剪和稀疏化,即通过对不重要的网络连接进行裁剪,模型裁剪主要针对已经训练好的模型,而核的稀疏化主要是在训练的过程中进行诱导训练;量化加速,即通过对网络中的浮点值进行量化处理,使得浮点数计算转换为位操作(或者小整数计算),不仅能够减少网络的存储,而且能够大幅度进行加速,使得神经网络在CPU上的运行成为可能!当然,深度学习模型压缩和加速的方法不局限于我在本文中的介绍,还有其他很多类似的压缩和加速算法,如递归二值网络等 |









