| 编辑推荐: |
本文主要给大家分享了深度学习的应用,以及在思考做一个深度学习平台之后,我们的考虑和架构设计,希望能给大家带来一些帮助。
本文来自于简书,由火龙果软件Alice编辑、推荐。 |
|
摘要
深度学习的概念源于人工神经网络的研究,含多隐层的多层感知器就是一种深度学习结构。深度学习通过组合低层特征形成更加抽象的高层表示属性类别或特征,以发现数据的分布式特征表示。
机器学习与深度学习应用
机器学习是通过机器进行自主学习数据而非以编码的方式;深度学习是机器学习的一个分支,主要包括四种最基本的网络结构。
CNN是卷积神经网络。通过卷积网络的模型,可以高效地处理图像分类或人脸识别等应用。
MLP是多层感知机,也就是传统的神经网络。已经被Google大量应用在Youtube视频推荐和APP推荐上。
RNN模型是在神经元里加入带记忆的神经元结构,可以处理和时间序列有关的问题。
RL是Alphago用到的增强学习,它的底层也用到一些深度学习技术。
CaseStudy:Image Classification
假如有一个应用要通过大量图片训练分辨出猫和狗的图片。如果按照传统的方法,程序员自己写应用来区别猫狗图片,可能需要很多规则和图形处理技巧,必须是一个图像专家。
但现在有了神经网络,输入只是数据,只要定义一个简单的神经网络,把应用写好后通过数据训练,就能实现一个效果不错的图像分类应用。

Google已经开源了Inception的模型,是层数比较高的一个多层神经网络。这个网络有些复杂,用GPU机器可能要训练两到三周才能实现。有了Tensorflow这样的工具后,可以在Github地址上直接下载它的模型。
CaseStudy:Game AI
GameAI是游戏人工智能,通过图像的结果用增强学习和Qlearning的算法,就可以实现它自动最大化地得到分数。

Introduce Tensorflow
Tensorflow是Google开源的一个Deep Learning Library,提供了C++和Python接口,支持使用GPU和CPU进行训练,也支持分布式大规模训练。
在使用Tensorflow的时候,只写一个静态纯文本的文件,通过Python解释器去运行,所以Tensorflow本质上只是一个Deep
Learning Library。
Summary Of?Tensorflow
Tensorflow这个Library需要人工安装,脚本需要手动运行,环境需要手动配置。分布式的Tensorflow要把一个脚本拷贝到多台机器上,手动配置。要进行代码调优需要手动Run和Tune。
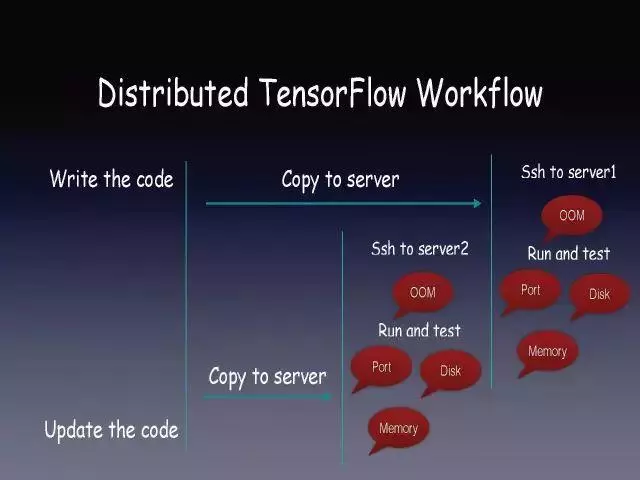
我们想做Tensorflow模型调优,但服务器可能出现OOM、可能使用的端口被别人占用、也可能磁盘出现故障,服务器环境变成应用开发者的负担。
分布式Tensorflow同样需要把代码拷贝到分布式的各台机器上,且不论Tensorflow的性能是否随着节点数越多而增强,服务器维护成本已呈线性增加了。
虽然Google开源了一个非常好的深度学习工具,但它并没有解决深度学习应用部署和调度的问题。
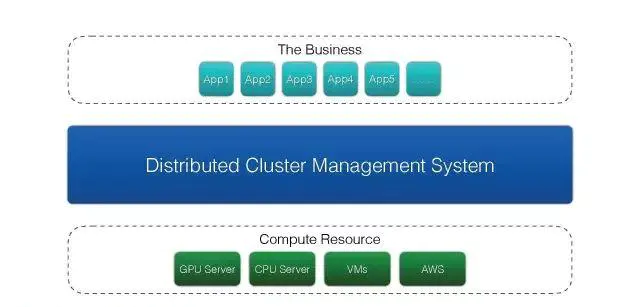
有人说过,任何复杂的问题都能通过抽象来解决。我们在中间引入一个分布式的管理系统,让上层业务应用不需要直接管理底层资源,由统一的调度系统去实现。
深度学习平台架构与设计
Cloud-ML:The Principles
我们希望这是一个云计算,而不是提供裸机的服务。用户只需写好应用代码提交,不用通过Ssh或登录到服务器上用脚本运行。
我们想把模型的训练和服务进行集成。一个模型训练完成后会得到一些模型文件,可以直接把这些模型文件应用起来。
我们希望这个平台是高可用的,即使用户的任务训练失败,也能重新给用户做一个调度。
用户之间的任务是需要做资源隔离和动态调度。
我们希望能支持并发的训练。
通过Automatically Tuning平台,用户可以一次提交多个超参数组合,让它并行训练,等训练结束可以直接看到效果。
Cloud-ML:All-In-One Platform
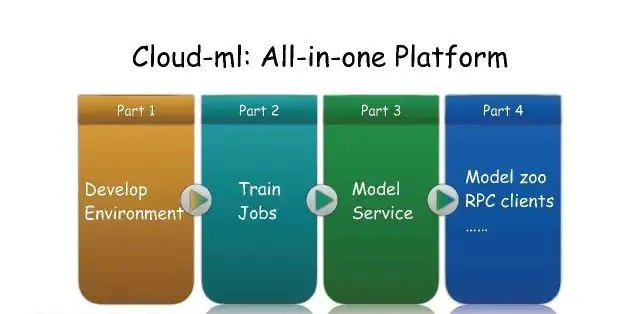
目前这个平台已经为用户提供深度学习框架的开发环境,开发完之后可以把代码提交上去,然后就可以训练,训练结果会直接保存在我们自己的分布式存储里。用户可以通过这个平台起一个RPC服务,他的手机或业务服务器能够直接调用这个服务。我们还提供了Model
Zoo以及RPC客户端的一些功能。
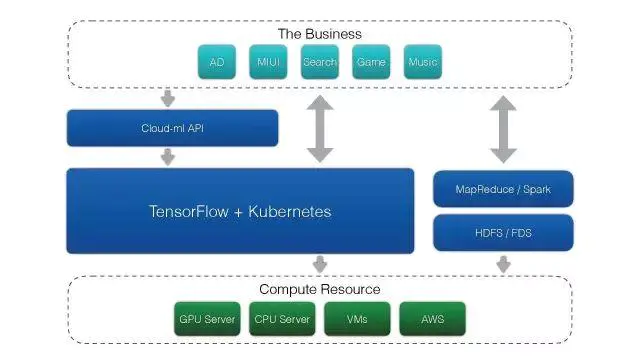
这是深度学习平台的基本架构。
最上层是用户业务,有广告、搜索、游戏等,都有自己的业务场景,可以根据自己的数据格式编写一些Tensorflow、深度学习的脚本。通过Cloud-Ml的API把任务提交到服务端,由服务端创建一个容器,把它调用到真正的物理机计算资源上。
这整个大平台主要是由Tensorflow和Kubermetes实现的。由这个平台管理底层维护的CPU服务器和GPU服务器、虚拟机以及AWS的机器。
Cloud-ML:Kubernetes Inside
Kubermetes是一个容器的集群管理系统,它会依赖一个多节点的Etcd集群,有一个或多个Master去管理Kubelet节点。每个物理机会部署一个Kubelet和Docker进程,在上面会运行多个Docker的Container。
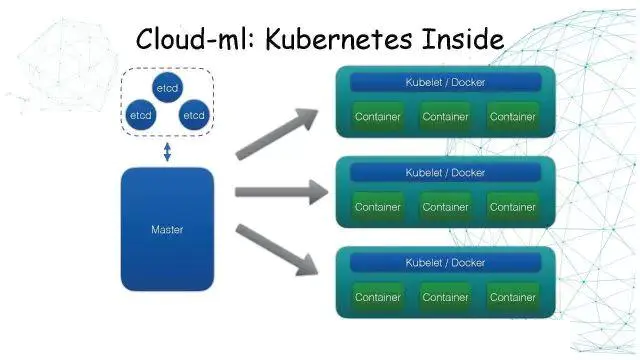
我们这个平台封装了一个Kubelet,让用户把业务代码提交上来,组成一个Docker容器的格式,然后由Kubelet去调度。
Cloud-ML:The Architecture
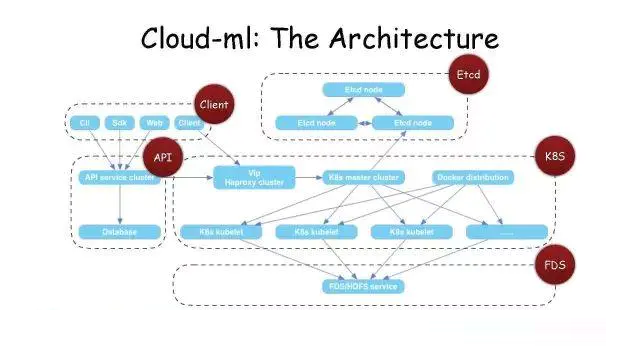
这是一个分层和解耦的基本架构,好处就是API服务只需要负责授权认证、任务管理,调度通过Kubermetes去做,Kubermetes的元数据都通过Etcd去存储,每一部分都利用API进行请求。这样就能把整个系统的组件解耦。
Cloud-ML:Train Job

有了深度学习平台之后,通过已经支持的API声明提交任务的名称,编写好Python代码的地址。运行代码的参数通过Post请求过来。
我们也提供SDK对API做了封装。
命令行工具Command能够直接把写好的脚本提交到云平台进行训练。还有内部集成的Web
Console。
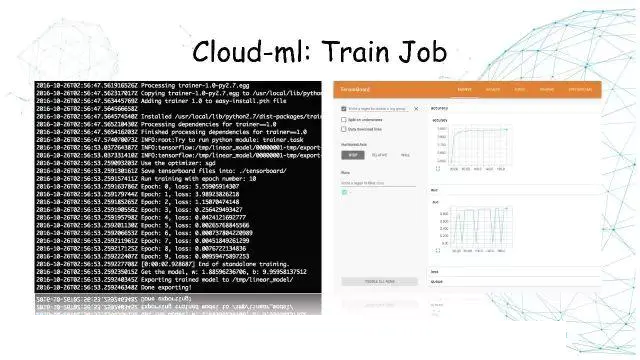
训练任务提交之后,在命令行可以看到任务训练日志。
Tensorboard可以看定义的模型结构。
Cloud-ML:Model Service
训练任务结束后可以直接起一个Model Service。因为文件已经保存在云存储里了,只要再发一个API请求,在后端也封装了一个Docker
Image。
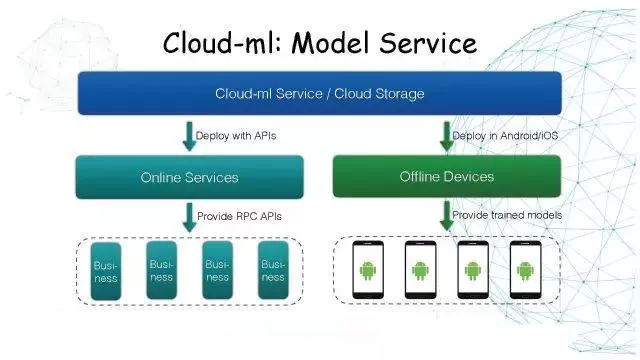
底层是依赖Google已经开源的Tensorflow Serving直接加载模型文件。
左边是Online Services,用户把模型训练完保存在这里,起一个容器,对外提供高性能的RPC服务。
Cloud-ML:Predict Client
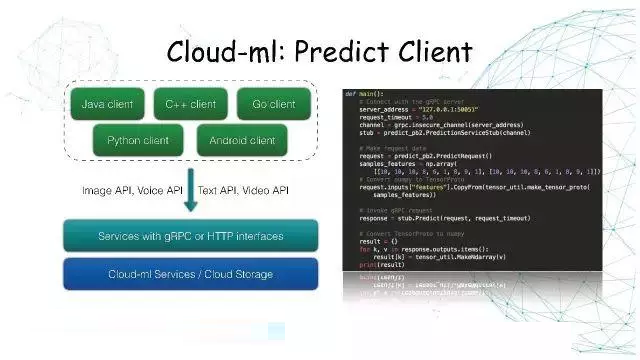
在线服务支持Grpc和HTTP接口,理论上支持大部分编程语言。可以使用Java客户端、C++客户端、Go客户端和Python客户端,或直接在Andriod请求模型服务。
通过一个统一的接口对外提供图像相关的API,底层是由Kubermetes进行调度和资源隔离。
右边是Python的Grpc客户端,当模型起来以后,用户只需要编写二十几行Python代码,把模型的输入准备好,就可以请求服务。
Cloud-ML:Wrap-Up
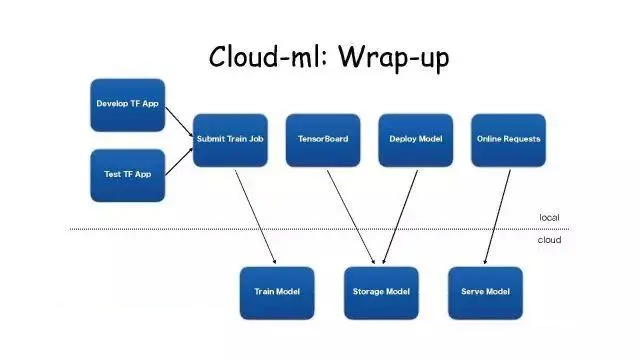
在有深度学习平台以后,工作流是这样的。上面是工作环境,云端有服务器和基础架构维护的服务。用户在本地环境编写自己的Tensorflow应用,在本地验证这个应用能否跑起来。
通过Submit Train Job的API把任务提交到云端,真正用GPU或CPU训练的代码就在云端运行。运行完之后会把模型保存到分布式存储里面。
用户可以用官方提供的Test TF APP去看模型训练的效果如何,如果没问题,在用户自己的环境调用Deploy
Model的API,这样就会把Model拿出来起一个容器,对外提供RPC服务。
用户就可以选择自己喜欢的客户端,用RPC的方式请求模型服务。
深度学习平台实践与应用
Practice:Distributed Training

支持分布式训练。用户在Python脚本里定义了一系列参数,把这个脚本拷贝到各台机器上去运行。
我们让用户把分布式节点个数和当前进程角色通过环境变量定义,环境变量名是固定的。这样它只需要一个环境变量就可以定义进程在分布式训练里的角色。
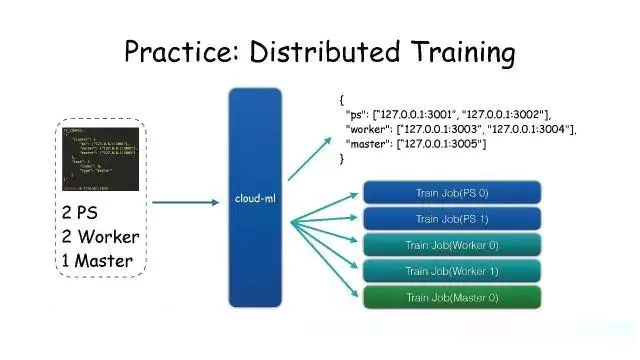
我们把用户的脚本拿出来以后,不需要它去管理服务器的环境,只需要声明这个集群有多少个PS、Worker和Master,把这些参数提交给Cloud-Ml的API服务,由它来申请可用的IP和端口。
Practice:Storage Integration

我们对存储系统做了集成。开源的Tensorflow目前只支持本地存储,因为我们在云端训练,任务由我们调度到特定的机器,用户不可能直接把训练数据放到本地。
我们希望用户能直接访问我们的分布式存储,所以对Tensorflow源码做了修改。提交任务的时候可以直接指定一个FDS的路径,系统就能根据用户的权限直接读取训练数据。
对Google官方的Tensorflow做了拓展。训练完之后数据全部放在分布式存储里,用Tensorflow指定FDS路径。
训练完把模型导出到FDS以后,通过Cloud-Ml的API创建一个服务,加载它的模型文件。
针对不同的模型声明不同的请求数据,输入类型和输入的值通过Json定义,就可以请求模型服务了。
Practice:Support HPAT
HPAT是神经网络里的超参数自动调优,极大缩短了科研人员和专注做算法模型人员的时间。

Practice:Dependency Management

让用户提交代码的时候提交一个标准的Python Package。
Practice:BringYour Own Image

让用户的Docker直接提交到Kubermetes集群里,真正彻底解决用户依赖的问题。
Practice:ModelZoo
我们把Model文件放到存储中,通过API把Paper实现了,不同的Model都可以部署到这个平台上,这样就可以通过RPC来直接访问这个服务了。
总结
我们也相信云计算大数据时代已经到来,下一个时代将会是深度学习,并且未来会继续往云深度学习发展。谢谢大家!
|









