| БрМЭЦМі: |
БОЮФжївЊНщЩмЛљгкЫцМДЬнЖШЯТНЕЕФбЇЯАгХЛЏЫуЗЈЕФРЇОжгУФкЧЖ TDA ЕФЩюЖШбЇЯАМмЙЙРДНтЮЇЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкжЊКѕЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
в§бд
ЛљгкЫцЛњЬнЖШЯТНЕЃЈSGDЃЉЕФгХЛЏЫуЗЈЕФРЇОжЃК
жЎЧАдкбЇаЃЕФЪБКђЃЌЮвдјЪдЭМРћгУФкЭјЕФТлЬГИјбЇЩњЯДФдЃЌХњХаЕБЯТЩюЖШбЇЯАЕФМИИіЦПОБКЭЮДРД TDA ПЩвдДјРДЕФЙБЯзКЭЭЛЦЦЁЃЫЕЪЕдкЃЌЯждкПДРДЃЌФЧЪБЪЧ
too young too simple СЫЃКЩюЖШбЇЯАЕФУЗПЊЖўЖШЪЧгаМсЪЕЕФЪЙгУГЁОАКЭзПдНЕФаЇЙћРДжЇГХЕФЁЃдкздМКвВЭцСЫвЛеѓзгвЛаЉПЊдДЕФЩюЖШбЇЯАПђМмКѓЃЌЛиЙЫЕБГѕЕФТлЖЯЃЈбЕСЗЕФЗтБеадЃЌЪ§ОнЃЏаХКХЕФЕЅЯђСїЖЏЃЗЧЫЋЯђЛЅЖЏЕФбЇЯАЃЌвдМАбЇЯАСїГЬЯрЖдЕФОВЬЌКЭОжВПадЃЉЃЌЫфШЛШдШЛФбвдЭЦЗЃЌЕЋЪЧЕБЯТбаОПЕФЛ№ШШЕФЧПЛЏбЇЯАЃЌжїЖЏЃЏЯпЩЯбЇЯАКЭЧЈвЦбЇЯАЃЈtransferЃЏgenerative
learningЃЉЕФЗЂеЙЗНЯђЃЌЖМдкЪдЭМЭЛЦЦетаЉЩюЖШбЇЯАЯШЬьЕФОжЯоЁЃОЁЙмШчДЫЃЌвЛаЉФПЧАЩюЖШбЇЯАРЕвдАВЩэСЂУќЕФЙиМќЫуЗЈММЧЩЃЌЦфТњзуЕФЬѕМўКЭгІгУЕФГЁОАЖМШчДЫЕФПСПЬЃЌЫЦКѕГ§СЫЭМЯёКЭгявєЗНУцЕФгІгУЃЌЗТЗ№вЛЮЛШсШѕЕФУРХЎЧАЬЈЃЌГ§СЫИјНјУХЕФПЭШЫДјРДГѕДЮвЛМћЕФОЊбоЃЌДЫЭтШУШЫЖМВЛКУвтЫМвЊЧѓЫ§ЛЙФмзіаЉЪВУДБ№ЕФЁЃ
ЪЧЕФЃЌЮвЫЕЕФЦфжавЛИіЮЪЬтОЭЪЧЛљгкЫцМДЬнЖШЯТНЕЃЈStochastic Gradient DescentЃЉЕФбЇЯАгХЛЏЫуЗЈЁЃМђЕЅРДНВЃЌSGD
Ц№ЕНЕФЙиМќзїгУдкгкЮЊвЛИіЩюЖШбЇЯАФЃаЭдкЗтБеЕФбЕСЗЙ§ГЬжаЃЌжИГіЕќДњгХЛЏЕФЗНЯђЁЃдкКмЖрЭМЯёКЭгявєЕФЪ§ОнЩЯЃЌХфЩЯЧПДѓЕФдЫЫугВМўЃЌSGD
газХШУШЫГдОЊЕФаЇЙћЃЌШУФЃаЭКмгааЇЕФЭљзюаЁЛЏбЇЯАЮѓВюЃЈlearning lossЃЉЕФЗНЯђбЕСЗЃЏбЇЯАЃЌНЋзюКѓЕФВтЪдаЇЙћЯджјЬсЩ§ЃЌР§ШчвЛХкЖјКьЕФ
AlexNet КЭ AlphaGoЁЃЕЋЪЧдкаэЖрГфТњдывєКЭЫцЛњадЕФбЕСЗЪ§ОнЩЯЃЌЛљгк SGD ЕФгХЛЏЦїЛсЯнгкОжВПЕФзюгХНтЕФДѓПгРяКмФбХРГіРДЃЌШчЯТЭМЯнШыЕФаЧКХБъМЧЕФЭнЕиЃЈетЛЙВЛЬсЫќЫљашвЊЕФЮѓВюКЏЪ§ЕФПЩЮЂЗжадЃЉЃК
ИќКЇШЫЕФТЉЖДдкгкЃЌетаЉЛљгк SGD ЕФгХЛЏЫуЗЈЃЌКмШнвзБЛШЫРћгУЃЌзівЛаЉШУШЫРрПДЦ№РДВЛПЩЫМвщЕФДРЪТЃЌМДЫљЮНЕФ
ЖдПЙбљБОЃЈadversarial examplesЃЉЃК
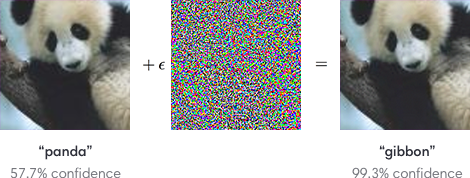
етРяЭЌбљШтблПДРДЖМЪЧамУЈЕФЭМЃЌМгСЫТэШќПЫЕФгвБпЕФЭМдкЛњЦїПДРДОЭЪЧдГКяЁЃ
етбљЕФТЉЖДЃЌдкЩюЖШбЇЯАЪЕМЪЕФгІгУжагаПЩФмЪЧжТУќЕФЁЃР§ШчЃЌздЖЏМнЪЛвРРЕЖдгкТЗБъЕФЭМЯёЪЖБ№ЃЌШчЙћЯёЩЯУцФЧбљЃЌИјЧАааЕФТЗБъЬљвЛВуШтблПДВЛГіРДЕФТэШќПЫЃЌШУЛњЦїЖСЦ№РДгаКмИпЕФИХТЪШЯЮЊЪЧЯђзѓзЊЃЌКйКйЁЃЁЃЁЃЫљвдЯТДЮФњдкЪЎзжТЗПкПДЕНЖдУцПЊЙ§РДвЛЬЈЬиЫЙРЃЌаЁаФЕуПЊТ§ЕуЪЧУЛДэЕФЁЃ
Г§ДЫжЎЭтЃЌЭЌбљРДзд OpenAI ЕФ Chris Olah ЕФВЉПЭ Colah гавЛЦЊКмПЊФдЖДЕФВЉЮФЁЃетЦЊвдЩёОЭјТчЃЌСїаЮКЭЭиЦЫбЇ
УќУћЕФВЉЮФвВжИГіЕБЧАЩюЖШбЇЯАдкЭъШЋКіТдбЕСЗЪ§ОнЕФШЋУВКЭаЮзДЯТдкФЃаЭГѕЪМЛЏЃЈinitialisationЃЉКЭВЮЪ§ЮЌЖШЃЈdimensionalityЃЉЩшЖЈЩЯгаПЩФмГдЕФПїЃЌвдМАЭиЦЫбЇПЩвдДјРДЕФНтОШЁЃ
НгЯТРДЃЌЮвУЧРДЫЕЫЕ TDA ФмЬсЙЉЕФНтвЉЁЃ
РДзд TDA ЕФНтОШ
етИіЪБКђЃЌTDA ЛђепЭиЦЫбЇжаЩюКёЕФЛ§ЕэЛђаэФмЬєГівЛаЉЯжГЩЕФЙЄОпРДНтЮЇЁЃ
ЦфвЛЃЌЪЧЭиЦЫбЇЪЖБ№ОжВПзюгХНтКЭШЋОжзюгХНтЕФФмСІЃЈlocal minimum vs. global
minimumЃЉЃК
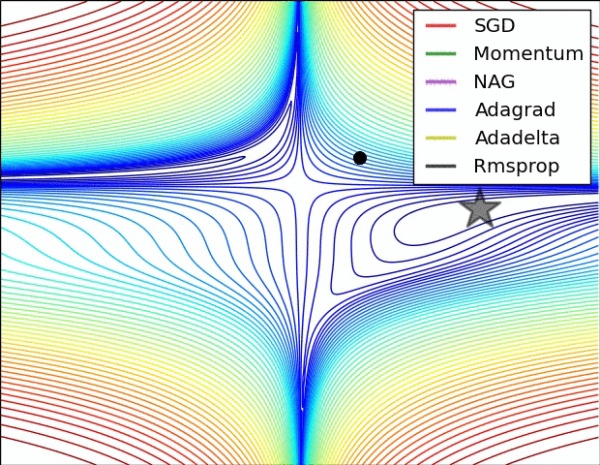
етРяЃЌгЬЫћжнСЂЕФЭѕБД НЬЪк дкбЕСЗжїЖЏбЇЯАФЃаЭЪБЃЌДњШы TDA ОпБИЕФЪЖБ№ЁИИќШЋОжЁЙЕФзюгХНтЕФФмСІ
ШЅзіжїЖЏбАевЃЈЩИбЁЃЉФЃаЭбЕСЗЕФзгбљБОЃЌШчЩЯЭМЕФзѓЭМЕФбЕСЗЪ§ОнЪЧИљОнОжВПНтШЅЩИбЁбЕСЗбљБОЃЌЖјЛљгкTDAЕФЩИбЁЕФзюгХНтЪЧИќШЋОжЕФСНИіЗхжЕЁЃ
ЦфЖўЃЌЪЧЭиЦЫбЇЦфжаЕФвЛИіРэТлЃЈMorse Smale TheoryЃЉЃЌЕБжаЖдгкОжВПзюгХНтЕФХфЖдКЭЖдЯћЕФПЩФмадЕФЖЈТлЃЈcritical
point offsettingЃЉПЩвдШУЮѓВюКЏЪ§ЕФгХЛЏБфЕУИќМгжБНгКЭгааЇЃК
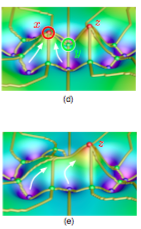
етРяЕФЩЯЭМжага3ИіМЋжЕЃКxЃЌy КЭ zЁЃЦфжа x КЭ y ЪЧЯрЖдгк z ЕФОжВПМЋжЕЃЌMorse Smale
РэТлИцЫпЮвУЧЃЌдкВЛИФБфБъЕФПеМфЕФЃЈЭЌЕїЃЉЭиЦЫНсЙЙЕФЧАЬсЯТЃЌЭЈЙ§МђЕЅЕФЮЂЕїЃЌПЩвдЖдЯћ x КЭ yЃЌЪЃЯТ
z зїЮЊУћИБЦфЪЕЕФШЋОжМЋжЕЃЈglobal critical pointЃЉзїЮЊгХЛЏЕФФПБъЕуЁЃ
ЦфШ§ЃЌЪЧдкжЎЧАЕФзЈРИЮФеТжаеЙПЊТлЪіЕФЃЌ TDA ЕФПЙдыадКЭВЖзНжмЦкадЕФФмСІЁЃ
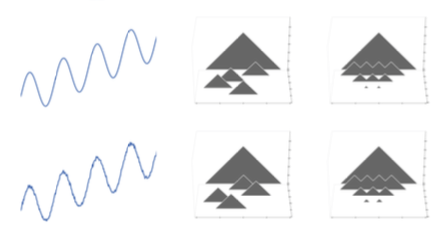
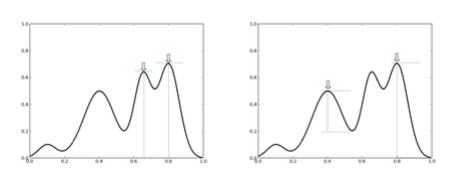
ЩЯЭМЕФзѓБпЪЧСНИіВЈаЮЕФЪ§ОнМЏЃЌЧјБ№дкгкЯТУцЕФВЈаЮЪЧгаОтГнзДЕФдывєЕФЃЌЕЋЭЈЙ§ TDA ХмГіРДЕФ ГжајадЗхШКЃЈpersistent
landscapeЃЉЃЌЫљЛёЕУЕФНсЙћЃЈжаМфКЭгвБпЕФЭМЃЉЃЌЩЯЯТЭМБШНЯвЛЯТЃЌПЩвдПДЕНЛљБОЩЯУЛгаЪмЕНетаЉдывєЕФгАЯьЁЃ
ЭЌбљЃЌжЎЧАгУ TDA ЗжЮіЙЩЦБМлИёЕФЪБађЪ§ОнЃЌШчЩЯЭМЃЌЭЈЙ§ЬѕаЮТыЕФГЄЖЬЃЈКьЩЋЕФЯпЬѕЃЉвВФмКмПьЕФЪЖБ№Гіеце§ЕФеЧЕјжмЦкЃЌЖјВЛЪЧЕБжаЕФаЁЗљЕФе№ЕДВЈЖЏЁЃ
ФкЧЖ TDA ЕФЩюЖШбЇЯАМмЙЙКєжЎгћГі
ЯТУцЪЧ ЬЈЭхжабадКЭХЖг зіЕФвЛИігУРДИјвєРжвєЦЕЕФЪБађЪ§ОнзіБъЧЉЗжРрЕФФЃаЭЕФ TDA + CNN МмЙЙЁЃШ§ВуОэЛ§ЩёОЭјТчЃЈConvolutional
Neural NetworkЃЉЕФжаМфвЛВуЃЌМгШыСЫ TDA МЦЫуГжајадЭЌЕїЃЈpersistent homologyЃЉЭиЦЫНсЙЙЕФзщМўЃЌШЛКѓКЭ
CNN ВЂСЊЃЌДгЖјдіЧПСЫФЃаЭЖдгкИпЦЕжмЦкадаХКХЕФВЖзНФмСІЁЃ
ИЛЪПбаОПдКвВгУРрЫЦЕФМмЙЙЃЈЪБађЪ§ОнЕФЩюЖШбЇЯАЃЉРДЗжЮіЦфЫќЕФЪБађЪ§ОнЃЌЛёЕУИќЧПОЂЕФаЇЙћЃК
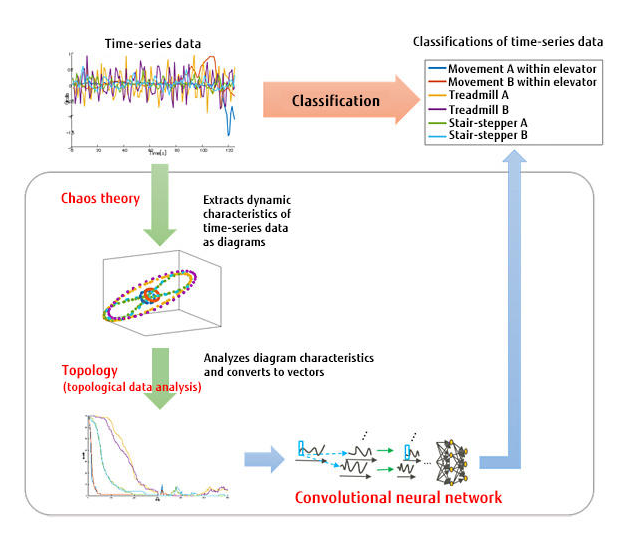
етРяИНЩЯЫћУЧЕФ ТлЮФСДНгЁЃ
ЧПдкФФЖљЃП
жабадКЭХЖгЕФФЃаЭМмЙЙЃЌНЯжЎЙ§ШЅзюгХЕФCNNвєЦЕФЃаЭЃЌгаЭГМЦЩЯСПЛЏЕФзМШЗТЪЕФЬсЩ§ЁЃ
БГКѓжБЙлИаадЕФдвђЃЌЮвЯыЪЧЃКTDA ЬсШЁГіРДЕФаХКХЬюВЙСЫДЋЭГ CNN ШБЪЇЕФеыЖдЪБађЪ§ОнЕБжаЕФжмЦкадЬиеїЕФ
ЧП ВЖзНФмСІЁЃ
ЖјИЛЪПЪЕбщЪвдђЩљГЦДяЕНСЫ НгНќ 25% ЕФОЋзМЖШЕФЬсЩ§ЁЃ
змНсРДЫЕЃЌTDA дкЩюЖШбЇЯАЕБжаПЩвдЙБЯзЕФМлжЕдкгкЫќдкЩюЖШбЇЯАБШНЯФббЇЕНЕФЃЈжмЦкадЃЉЬиеїЕФЬсШЁЩЯ
КЭбЇЯАГЩБОЕФ гХЛЏЕФжИв§ ЩЯЁЃЮвУЧгаРэгЩЦкД§ИќЖрЕФетИіЗНЯђЕФбаЗЂГЩЙћКЭЩЬвЕгІгУЁЃT.B.CЁЃ
|









