| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫ Canny БпдЕМьВтЕФдРэвдМАбЇЯАЭМЯёН№зжЫўШчКЮЪЙгУН№зжЫўНјааЭМЯёШкКЯЃЌ
ЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
БОЮФРДздгкВЉПЭдАЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
19 Canny БпдЕМьВт
ФПБъ
СЫНт Canny БпдЕМьВтЕФИХФю
бЇЯАКЏЪ§ cv2.Canny()
19.1 дРэ
Canny БпдЕМьВтЪЧвЛжжЗЧГЃСїааЕФБпдЕМьВтЫуЗЈЃЌЪЧ John F.Canny
дк1986 ФъЬсГіЕФЁЃЫќЪЧвЛИігаКмЖрВНЙЙГЩЕФЫуЗЈЃЌЮвУЧНгЯТРДЛсж№ВННщЩмЁЃ
19.1.1 дыЩљШЅГ§
гЩгкБпдЕМьВтКмШнвзЪмЕНдыЩљгАЯьЃЌЫљвдЕквЛВНЪЧЪЙгУ 5x5 ЕФИпЫЙТЫВЈЦїШЅГ§дыЩљЃЌетИіЧАУцЮвУЧвбОбЇЙ§СЫЁЃ
19.1.2 МЦЫуЭМЯёЬнЖШ
ЖдЦНЛЌКѓЕФЭМЯёЪЙгУ Sobel ЫузгМЦЫуЫЎЦНЗНЯђКЭЪњжБЗНЯђЕФвЛНзЕМЪ§ЃЈЭМЯёЬнЖШЃЉЃЈGx
КЭ GyЃЉЁЃИљОнЕУЕНЕФетСНЗљЬнЖШЭМЃЈGx КЭ GyЃЉевЕНБпНчЕФЬнЖШКЭЗНЯђЃЌЙЋЪНШчЯТЃК
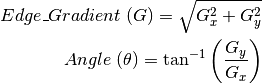
ЬнЖШЕФЗНЯђвЛАузмЪЧгыБпНчДЙжБЁЃЬнЖШЗНЯђБЛЙщЮЊЫФРрЃКДЙжБЃЌЫЎЦНЃЌКЭСНИіЖдНЧЯпЁЃ
19.1.3 ЗЧМЋДѓжЕвжжЦ
дкЛёЕУЬнЖШЕФЗНЯђКЭДѓаЁжЎКѓЃЌгІИУЖдећЗљЭМЯёзівЛИіЩЈУшЃЌШЅГ§ФЧаЉЗЧБпНчЩЯЕФЕуЁЃЖдУПвЛИіЯёЫиНјааМьВщЃЌПДетИіЕуЕФЬнЖШЪЧВЛЪЧжмЮЇОпгаЯрЭЌЬнЖШЗНЯђЕФЕужазюДѓЕФЁЃШчЯТЭМЫљЪОЃК
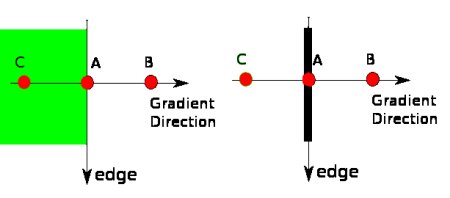
ЯждкФуЕУЕНЕФЪЧвЛИіАќКЌЁАеБпНчЁБЕФЖўжЕЭМЯёЁЃ
19.1.4 жЭКѓуажЕ
ЯждквЊШЗЖЈФЧаЉБпНчВХЪЧеце§ЕФБпНчЁЃетЪБЮвУЧашвЊЩшжУСНИіуажЕЃКminVal
КЭ maxValЁЃЕБЭМЯёЕФЛвЖШЬнЖШИпгк maxVal ЪББЛШЯЮЊЪЧецЕФБпНчЃЌФЧаЉЕЭгк minVal ЕФБпНчЛсБЛХзЦњЁЃШчЙћНщгкСНепжЎМфЕФЛАЃЌОЭвЊПДетИіЕуЪЧЗёгыФГИіБЛШЗЖЈЮЊеце§ЕФБпНчЕуЯрСЌЃЌШчЙћЪЧОЭШЯЮЊЫќвВЪЧБпНчЕуЃЌШчЙћВЛЪЧОЭХзЦњЁЃШчЯТЭМЃК
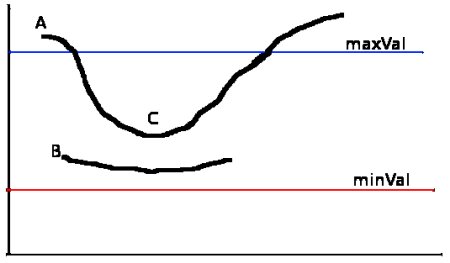
A ИпгкуажЕ maxVal ЫљвдЪЧеце§ЕФБпНчЕуЃЌC ЫфШЛЕЭгк maxVal ЕЋИпгкminVal ВЂЧвгы
A ЯрСЌЃЌЫљвдвВБЛШЯЮЊЪЧеце§ЕФБпНчЕуЁЃЖј B ОЭЛсБЛХзЦњЃЌвђЮЊЫћВЛНіЕЭгк maxVal ЖјЧвВЛгыеце§ЕФБпНчЕуЯрСЌЁЃЫљвдбЁдёКЯЪЪЕФ
maxValКЭ minVal ЖдгкФмЗёЕУЕНКУЕФНсЙћЗЧГЃживЊЁЃ
дкетвЛВНвЛаЉаЁЕФдыЩљЕувВЛсБЛГ§ШЅЃЌвђЮЊЮвУЧМйЩшБпНчЖМЪЧвЛаЉГЄЕФЯпЖЮЁЃ
19.2 OpenCV жаЕФ Canny БпНчМьВт
дк OpenCV жажЛашвЊвЛИіКЏЪ§ЃКcv2.Canny()ЃЌОЭПЩвдЭъГЩвдЩЯМИВНЁЃ
ШУЮвУЧПДШчКЮЪЙгУетИіКЏЪ§ЁЃетИіКЏЪ§ЕФЕквЛИіВЮЪ§ЪЧЪфШыЭМЯёЁЃЕкЖўКЭЕкШ§ИіЗжБ№ЪЧ minVal КЭ maxValЁЃЕкШ§ИіВЮЪ§ЩшжУгУРДМЦЫуЭМЯёЬнЖШЕФ
SobelОэЛ§КЫЕФДѓаЁЃЌФЌШЯжЕЮЊ 3ЁЃзюКѓвЛИіВЮЪ§ЪЧ L2gradientЃЌЫќПЩвдгУРДЩшЖЈЧѓЬнЖШДѓаЁЕФЗНГЬЁЃШчЙћЩшЮЊ
TrueЃЌОЭЛсЪЙгУЮвУЧЩЯУцЬсЕНЙ§ЕФЗНГЬЃЌЗёдђЪЙгУЗНГЬЃКEdge\_Gradient \; (G) =
|G_x| + |G_y|. ДњЬцЃЌФЌШЯжЕЮЊ FalseЁЃ
import cv2
import numpy as np
from matplotlib import pyplot as plt
img = cv2.imread('messi5.jpg',0)
edges = cv2.Canny(img,100,200)
plt.subplot(121),plt.imshow(img,cmap = 'gray')
plt.title('Original Image'), plt.xticks([]),
plt.yticks([])
plt.subplot(122),plt.imshow(edges,cmap = 'gray')
plt.title('Edge Image'), plt.xticks([]), plt.yticks([])
plt.show() |
НсЙћЃК
ЮвЕФНсЙћ

ЙйЗННсЙћ

ИќЖрзЪдД
1. Canny edge detector at Wikipedia
2. Canny Edge Detection Tutorial by Bill Green, 2002.
СЗЯА
1. аДвЛИіаЁГЬађЃЌПЩвдЭЈЙ§ЕїНкЛЌЖЏЬѕРДЩшжУуажЕ minVal КЭ
maxVal НјЖјРДНјаа Canny БпНчМьВтЁЃетбљФуОЭЛсРэНтуажЕЕФживЊадСЫЁЃ
20 ЭМЯёН№зжЫў
ФПБъ
бЇЯАЭМЯёН№зжЫў
ЪЙгУЭМЯёДДНЈвЛИіаТЫЎЙћЃКЁАщйзгЦЛЙћЁБ
НЋвЊбЇЯАЕФКЏЪ§гаЃКcv2.pyrUp()ЃЌcv2.pyrDown()ЁЃ
20.1 дРэ
вЛАуЧщПіЯТЃЌЮвУЧвЊДІРэЪЧвЛИБОпгаЙЬЖЈЗжБцТЪЕФЭМЯёЁЃЕЋЪЧгааЉЧщПіЯТЃЌЮвУЧашвЊЖдЭЌвЛЭМЯёЕФВЛЭЌЗжБцТЪЕФзгЭМЯёНјааДІРэЁЃБШШчЃЌЮвУЧвЊдквЛЗљЭМЯёжаВщевФГИіФПБъЃЌБШШчСГЃЌЮвУЧВЛжЊЕРФПБъдкЭМЯёжаЕФГпДчДѓаЁЁЃетжжЧщПіЯТЃЌЮвУЧашвЊДДНЈДДНЈвЛзщЭМЯёЃЌетаЉЭМЯёЪЧОпгаВЛЭЌЗжБцТЪЕФдЪМЭМЯёЁЃЮвУЧАбетзщЭМЯёНазіЭМЯёН№зжЫўЃЈМђЕЅРДЫЕОЭЪЧЭЌвЛЭМЯёЕФВЛЭЌЗжБцТЪЕФзгЭММЏКЯЃЉЁЃШчЙћЮвУЧАбзюДѓЕФЭМЯёЗХдкЕзВПЃЌзюаЁЕФЗХдкЖЅВПЃЌПДЦ№РДЯёвЛзљН№зжЫўЃЌЙЪЖјЕУУћЭМЯёН№зжЫўЁЃ
гаСНРрЭМЯёН№зжЫўЃКИпЫЙН№зжЫўКЭРЦеРЫЙН№зжЫўЁЃ
ИпЫЙН№зжЫўЕФЖЅВПЪЧЭЈЙ§НЋЕзВПЭМЯёжаЕФСЌајЕФааКЭСаШЅГ§ЕУЕНЕФЁЃЖЅВПЭМЯёжаЕФУПИіЯёЫижЕЕШгкЯТвЛВуЭМЯёжа
5 ИіЯёЫиЕФИпЫЙМгШЈЦНОљжЕЁЃетбљВйзївЛДЮвЛИі MxN ЕФЭМЯёОЭБфГЩСЫвЛИі M/2xN/2 ЕФЭМЯёЁЃЫљвдетЗљЭМЯёЕФУцЛ§ОЭБфЮЊдРДЭМЯёУцЛ§ЕФЫФЗжжЎвЛЁЃетБЛГЦЮЊ
OctaveЁЃСЌајНјааетбљЕФВйзїЮвУЧОЭЛсЕУЕНвЛИіЗжБцТЪВЛЖЯЯТНЕЕФЭМЯёН№зжЫўЁЃЮвУЧПЩвдЪЙгУКЏЪ§cv2.pyrDown()
КЭ cv2.pyrUp() ЙЙНЈЭМЯёН№зжЫўЁЃ
КЏЪ§ cv2.pyrDown() ДгвЛИіИпЗжБцТЪДѓГпДчЕФЭМЯёЯђЩЯЙЙНЈвЛИіН№згЫўЃЈГпДчБфаЁЃЌЗжБцТЪНЕЕЭЃЉЁЃ
img = cv2.imread('messi5.jpg')
lower_reso = cv2.pyrDown(higher_reso) |
ЯТЭМЪЧвЛИіЫФВуЕФЭМЯёН№зжЫўЁЃ

КЏЪ§ cv2.pyrUp() ДгвЛИіЕЭЗжБцТЪаЁГпДчЕФЭМЯёЯђЯТЙЙНЈвЛИіН№згЫўЃЈГпДчБфДѓЃЌЕЋЗжБцТЪВЛЛсдіМгЃЉЁЃ
| higher_reso2
= cv2.pyrUp(lower_reso) |

ФувЊМЧзЁЕФЪЧЪЧ higher_reso2 КЭ higher_reso
ЪЧВЛЭЌЕФЁЃвђЮЊвЛЕЉЪЙгУ cv2.pyrDown()ЃЌЭМЯёЕФЗжБцТЪОЭЛсНЕЕЭЃЌаХЯЂОЭЛсБЛЖЊЪЇЁЃЯТЭМОЭЪЧДг
cv2.pyrDown() ВњЩњЕФЭМЯёН№зжЫўЕФЃЈгЩЯТЕНЩЯЃЉЕкШ§ВуЭМЯёЪЙгУКЏЪ§cv2.pyrUp()
ЕУЕНЕФЭМЯёЃЌгыдЭМЯёЯрБШЗжБцТЪВюСЫКмЖрЁЃ
РЦеРЫЙН№зжЫўПЩвдгаИпЫЙН№зжЫўМЦЫуЕУРДЃЌЙЋЪНШчЯТЃК
РЦеРН№зжЫўЕФЭМЯёПДЦ№РДОЭЯёБпНчЭМЃЌЦфжаКмЖрЯёЫиЖМЪЧ 0ЁЃЫћУЧОГЃБЛгУдкЭМЯёбЙЫѕжаЁЃЯТЭМОЭЪЧвЛИіШ§ВуЕФРЦеРЫЙН№зжЫўЃК

20.2 ЪЙгУН№зжЫўНјааЭМЯёШкКЯ
ЭМЯёН№зжЫўЕФвЛИігІгУЪЧЭМЯёШкКЯЁЃР§ШчЃЌдкЭМЯёЗьКЯжаЃЌФуашвЊНЋСНЗљЭМЕўдквЛЦ№ЃЌЕЋЪЧгЩгкСЌНгЧјгђЭМЯёЯёЫиЕФВЛСЌајадЃЌећЗљЭМЕФаЇЙћПДЦ№РДЛсКмВюЁЃетЪБЭМЯёН№зжЫўОЭПЩвдХХЩЯгУГЁСЫЃЌЫћПЩвдАяФуЪЕЯжЮоЗьСЌНгЁЃетРяЕФвЛИіОЕфАИР§ОЭЪЧНЋСНИіЫЎЙћШкКЯГЩвЛИіЃЌПДПДЯТЭМвВаэФуОЭУїАзЮвдкНВЪВУДСЫЁЃ

ФуПЩвдЭЈЙ§дФЖСКѓБпЕФИќЖрзЪдДРДСЫНтИќЖрЙигкЭМЯёШкКЯЃЌРЦеРЫЙН№зжЫўЕФЯИНкЁЃ
ЪЕЯжЩЯЪіаЇЙћЕФВНжшШчЯТЃК
1. ЖСШыСНЗљЭМЯёЃЌЦЛЙћКЭОфзг
2. ЙЙНЈЦЛЙћКЭщйзгЕФИпЫЙН№зжЫўЃЈ6 ВуЃЉ
3. ИљОнИпЫЙН№зжЫўМЦЫуРЦеРЫЙН№зжЫў
4. дкРЦеРЫЙЕФУПвЛВуНјааЭМЯёШкКЯЃЈЦЛЙћЕФзѓБпгыщйзгЕФгвБпШкКЯЃЉ
5. ИљОнШкКЯКѓЕФЭМЯёН№зжЫўжиНЈдЪМЭМЯёЁЃ
ЯТЭМЪЧеЊздЁЖбЇЯА OpenCVЁЗеЙЪОСЫН№згЫўЕФЙЙНЈЃЌвдМАШчКЮДгН№зжЫўжиНЈдЪМЭМЯёЕФЙ§ГЬЁЃ
ећИіЙ§ГЬЕФДњТыШчЯТЁЃЃЈЮЊСЫМђЕЅЃЌУПвЛВНЖМЪЧЖРСЂЭъГЩЕФЃЌетЛиЯћКФИќЖрЁЂЕФФкДцЃЌШчЙћФудИвтЕФЛАПЩвдЖдЫћНјаагХЛЏЃЉ
import cv2
import numpy as np,sys
A = cv2.imread('apple.jpg')
B = cv2.imread('orange.jpg')
# generate Gaussian pyramid for A
G = A.copy()
gpA = [G]
for i in xrange(6):
G = cv2.pyrDown(G)
gpA.append(G)
# generate Gaussian pyramid for B
G = B.copy()
gpB = [G]
for i in xrange(6):
G = cv2.pyrDown(G)
gpB.append(G)
# generate Laplacian Pyramid for A
lpA = [gpA[5]]
for i in xrange(5,0,-1):
GE = cv2.pyrUp(gpA[i])
L = cv2.subtract(gpA[i-1],GE)
lpA.append(L)
# generate Laplacian Pyramid for B
lpB = [gpB[5]]
for i in xrange(5,0,-1):
GE = cv2.pyrUp(gpB[i])
L = cv2.subtract(gpB[i-1],GE)
lpB.append(L)
# Now add left and right halves of images in
each level
LS = []
for la,lb in zip(lpA,lpB):
rows,cols,dpt = la.shape
ls = np.hstack((la[:,0:cols/2], lb[:,cols/2:]))
LS.append(ls)
# now reconstruct
ls_ = LS[0]
for i in xrange(1,6):
ls_ = cv2.pyrUp(ls_)
ls_ = cv2.add(ls_, LS[i])
# image with direct connecting each half
real = np.hstack((A[:,:cols/2],B[:,cols/2:]))
cv2.imwrite('Pyramid_blending2.jpg',ls_)
cv2.imwrite('Direct_blending.jpg',real) |
|









