| БрМЭЦМі: |
БОЮФНВНтTensorBoardЪЧTensorflowздДјЕФЭјТчФЃаЭПЩЪгЛЏЕФЙЄОпЃЌЪЙгУепПЩвдЧхГўЕиПДЕНЭјТчЕФНсЙЙЁЂЪ§ОнСїЯђЁЂЫ№ЪЇКЏЪ§БфЛЏЕШвЛЯЕСагыЭјТчФЃаЭгаЙиЕФЪ§ОнЁЃЯЃЭћЖдФњгаЫљАяжњЁЃ
БОЮФРДздгкcsdnЃЌгЩЛ№СњЙћШэМўDeloresБрМЁЂЭЦМіЁЃ |
|
ЭјТчНсЙЙ
ЕЅДПЪЙгУtensorboardВщПДЭјТчНсЙЙжЛашвЊдкГЬађРяМгШыЯТУцвЛааДњТыЃК
writer = tf.summary.FileWriter
('C:\\Users\\45374\\logs',sess.graph) |
ЪЙгУЭъКѓЖдгІТЗОЖНЋЛсЩњГЩвЛИіЛЗОГЮФМўЃЌШчЯТЭМЁЃ
етЪБЮвУЧДђПЊcmdЃЈгЩгкЮвЪЧдкanacondaЯТНЈЕФtensorflowЛЗОГЃЌЫљвдЮвгУЕФanaconda promptЃЌВЂЯШНјШыЕНtensorflowЕФЛЗОГжаЃЉЃЌЪфШыtensorboard --logdir='ТЗОЖ' ЕУЕНШчЯТНсЙћЃК

ЃЈШчЙћВЛЪЧздМКНЈЕФtensorflowЛЗОГВЛашвЊЧАУцФЧОфactivate tensorflowЃЌЖјЧвзЂвтетРяЕФtensorflowЪЧЮвздМКИјЛЗОГШЁЕФУћзжЃЉЃЌвЛАуДѓМвжЛашдкcmdжаЪфШыtensorboard --logdir='ТЗОЖ' ЁЃ
ШЛКѓЛсЗЕЛивЛИіЭјжЗЃЌИДжЦИУЭјжЗШЛКѓдкдкфЏРРЦїжаДђПЊЃЈЭЦМігУЛ№КќЛђЙШИшфЏРРЦїЃЌгаЕФфЏРРЦїПЩФмДђВЛПЊЃЉЃЌШчЯТЃК
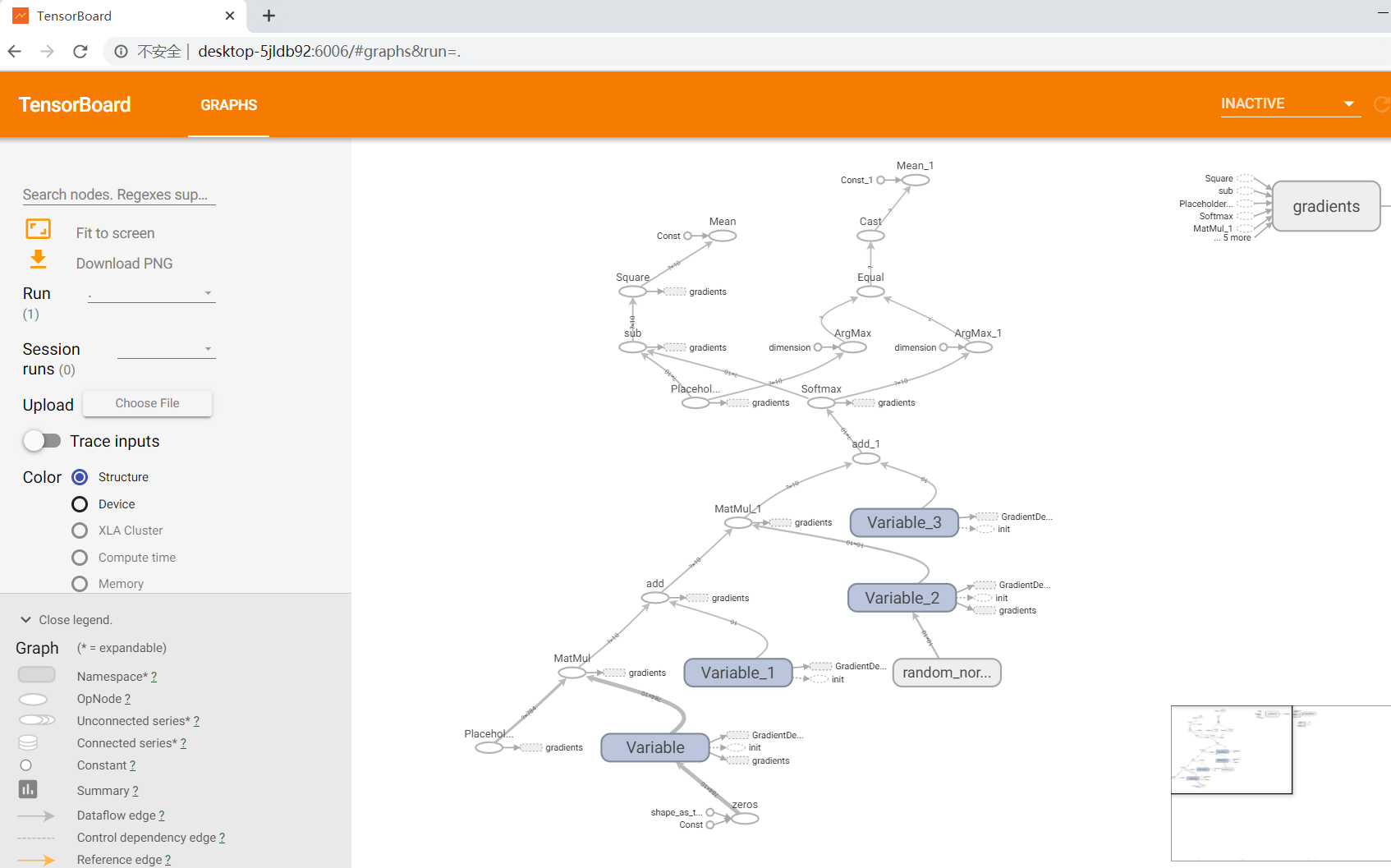
етИіЭМНсЙћНЯЮЊЛьТвЃЌЭМжа4ИіБфСПЗжБ№ЪЧСНзщwКЭbЁЃЮЊСЫШУЭјТчНсЙЙИќЧхЮњЃЌЮвУЧПЩвдЖдВПЗжБфСПКЭВйзїЩшжУУќУћПеМфЃЌЪЙНсЙЙИќШнвзЙлВьЃЌДњТыПЩзїШчЯТаоИФЃК
with tf.name_scope("input"):
x = tf.placeholder(tf.float32,
[None,784],name='x_input')
y = tf.placeholder(tf.float32,
[None,10],name='y_input')
#ЪфШыВуЕНвўВиВу
with tf.name_scope('layer'):
with tf.name_scope('wights'):
W = tf.Variable(tf.zeros([784,10]))
#етРяWГѕЪМЛЏЮЊ0ЃЌПЩвдИќПьЪеСВ
with tf.name_scope('biases'):
b = tf.Variable(tf.zeros([10]))
with tf.name_scope('Wx_plus_b_L1'):
Wx_plus_b_L1 = tf.matmul(x,W) + b
#вўВиВуЕНЪфГіВу
with tf.name_scope('output'):
with tf.name_scope('wights'):
W2 = tf.Variable(tf.random_normal([10,10]))
#вўВиВуВЛФмГѕЪМЛЏЮЊ0
with tf.name_scope('biases'):
b2 = tf.Variable(tf.zeros([10]))
with tf.name_scope('softmax'):
prediction = tf.nn.softmax
(tf.matmul(Wx_plus_b_L1,W2)+b2)
#ЖўДЮДњМлКЏЪ§
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.square(y-prediction))
#ЬнЖШЯТНЕЗЈбЕСЗ
train_step = tf.train.GradientDescentOptimizer(0.2).
minimize(loss)#бЇЯАТЪЮЊ0.2
init = tf.global_variables_initializer() |
етЪБtensorboardжаВщПДЕФЭјТчНсЙЙШчЯТЃК
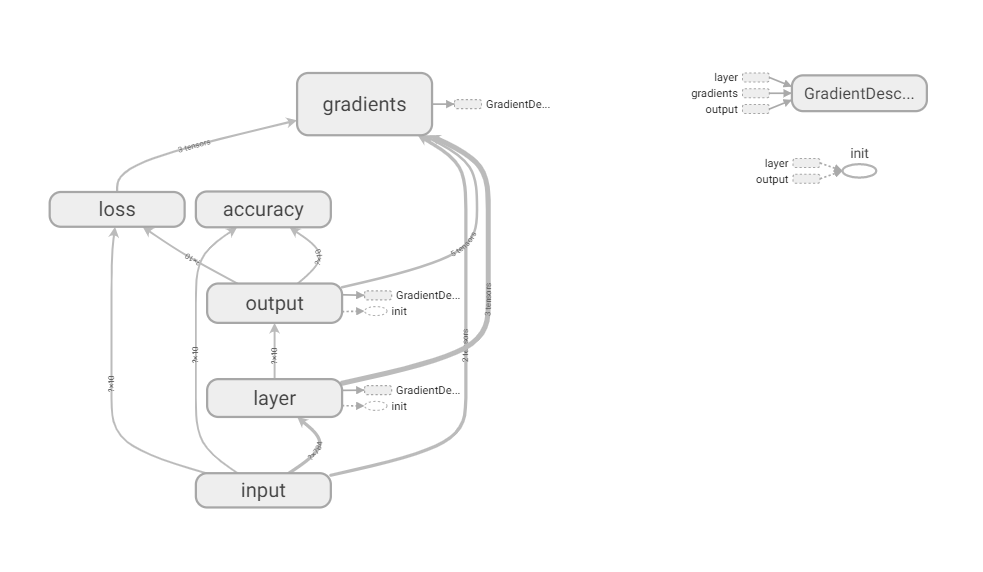
УПвЛИіУќУћПеМфПЩвдЫЋЛїДђПЊВщПДФкВПНсЙЙЃК
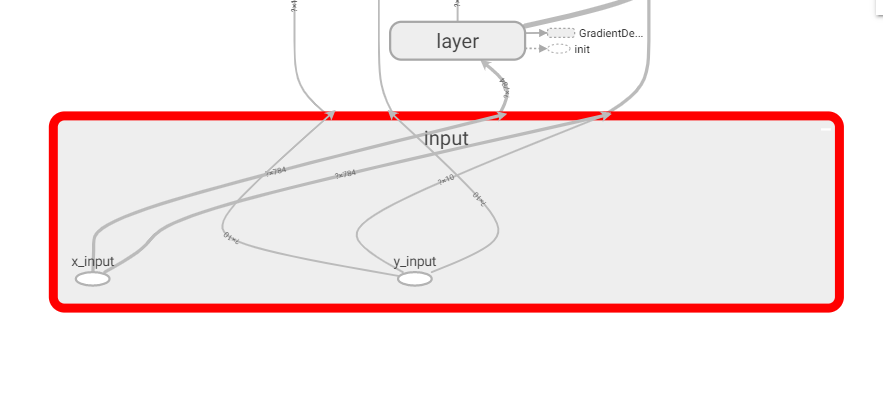
вВПЩвдгвМќбЁдёАбФГвЛВПЗжЕЅЖРФУГіРДЛђЗХНјЭјТчЃК
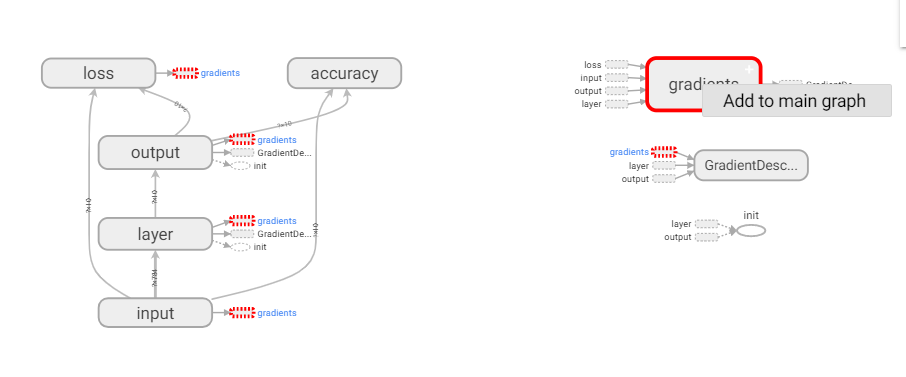
ВЛЙ§зЂвтЃЌШчЙћЖрДЮдЫааГЬађЃЌБиаыЯШНЋГЬађЙиБеЃЌШЛКѓжиаТдЫааЃЌВЂЧвНЋlogsЮФМўжаЕФenventoutЮФМўЩОГ§ЁЃВЛШЛПЩФмЛсГіЯжЖрИіЭјТчЭЌЪБЯдЪОЕФЧщПіЃЌШчЯТЃК
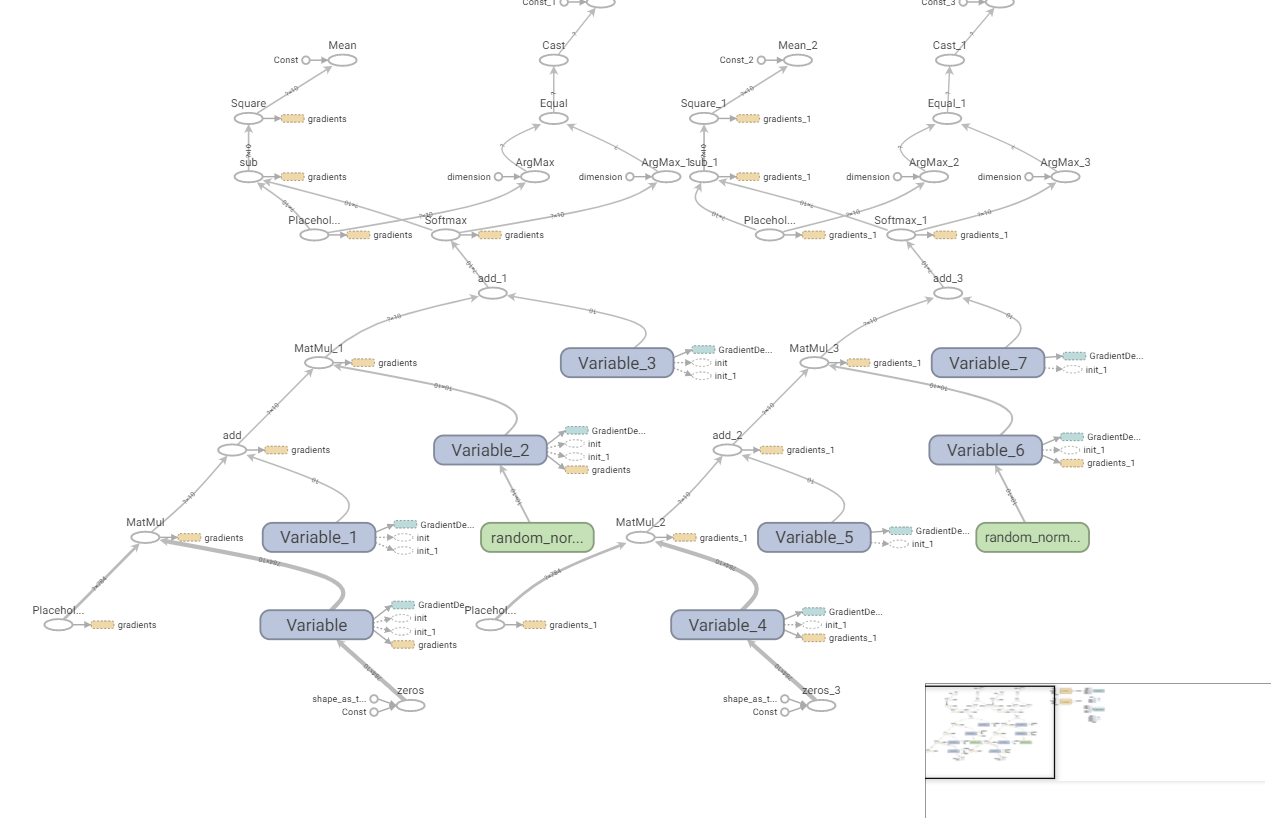
ВЮЪ§БфЛЏ
дкЭјТчбЕСЗЙ§ГЬжаЃЌЛсгаКмЖрВЮЪ§ЕФБфЛЏЙ§ГЬЃЌЮвУЧПЩвдЖдетаЉВЮЪ§ЕФБфЛЏЙ§ГЬНјааЯдЪОЁЃ
ЮвУЧПЩвдЯШЖЈвхвЛИіКЏЪ§ЃК
def variable_summarise(var):
with tf.name_scope('summarise'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean',mean)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean
(tf.square(var
- mean)))
#tf.summary.scalarЪфГіБъСП
#tf.summary.histogramЪфГіжБЗНЭМ
tf.summary.scalar('srddev',stddev)
tf.summary.scalar('max',tf.reduce_max(var))
tf.summary.scalar('min',tf.reduce_min(var))
tf.summary.histogram('histogram',var) |
КЏЪ§РяЖЈвхзХЮвУЧЯыжЊЕРЕФаХЯЂЃЌЮвУЧЯыжЊЕРФЧИіБфСПаХЯЂЃЌОЭЕїгУетИіКЏЪ§ЁЃ
Ы№ЪЇКЏЪ§КЭзМШЗТЪУПДЮжЛгавЛИіБъСПжЕЃЌЫљвджЛашвЛИіsummary.scalarКЏЪ§ЃК
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.square(y-prediction))
tf.summary.scalar('loss',loss)
with tf.name_scope('accuracy'):
correct_prediction = tf.equal(tf.argmax(y,1),
tf.argmax(prediction,1))
#equlХаЖЯЪЧЗёЯрЕШЃЌargmaxЗЕЛиеХСПзюДѓжЕЕФЫїв§
accuracy = tf.reduce_mean(tf.cast
(correct_prediction,tf.float32))
#НЋВМЖћаЭзЊЛЛЮЊИЁЕуаЭ
tf.summary.scalar('accuracy',accuracy) |
ШЛКѓКЯВЂЫљгаsummaryЃК
| merged = tf.summary.merge_all() |
НЋ mergedКЏЪ§КЭЭјТчбЕСЗвЛЦ№НјааЃК
summary,_ = sess.run([merged,train_step],
feed_dict={x:batch_xs,y:batch_ys}) |
зюКѓНЋsummaryжаЪ§ОнаДШыЮФМўЃК
| writer.add_summary(summary,epoch)
|
НгЯТРДОЭПЩвддкtensorboardжаВщПДИеИеМЧТМЕФИїжжЪ§ОнЃК
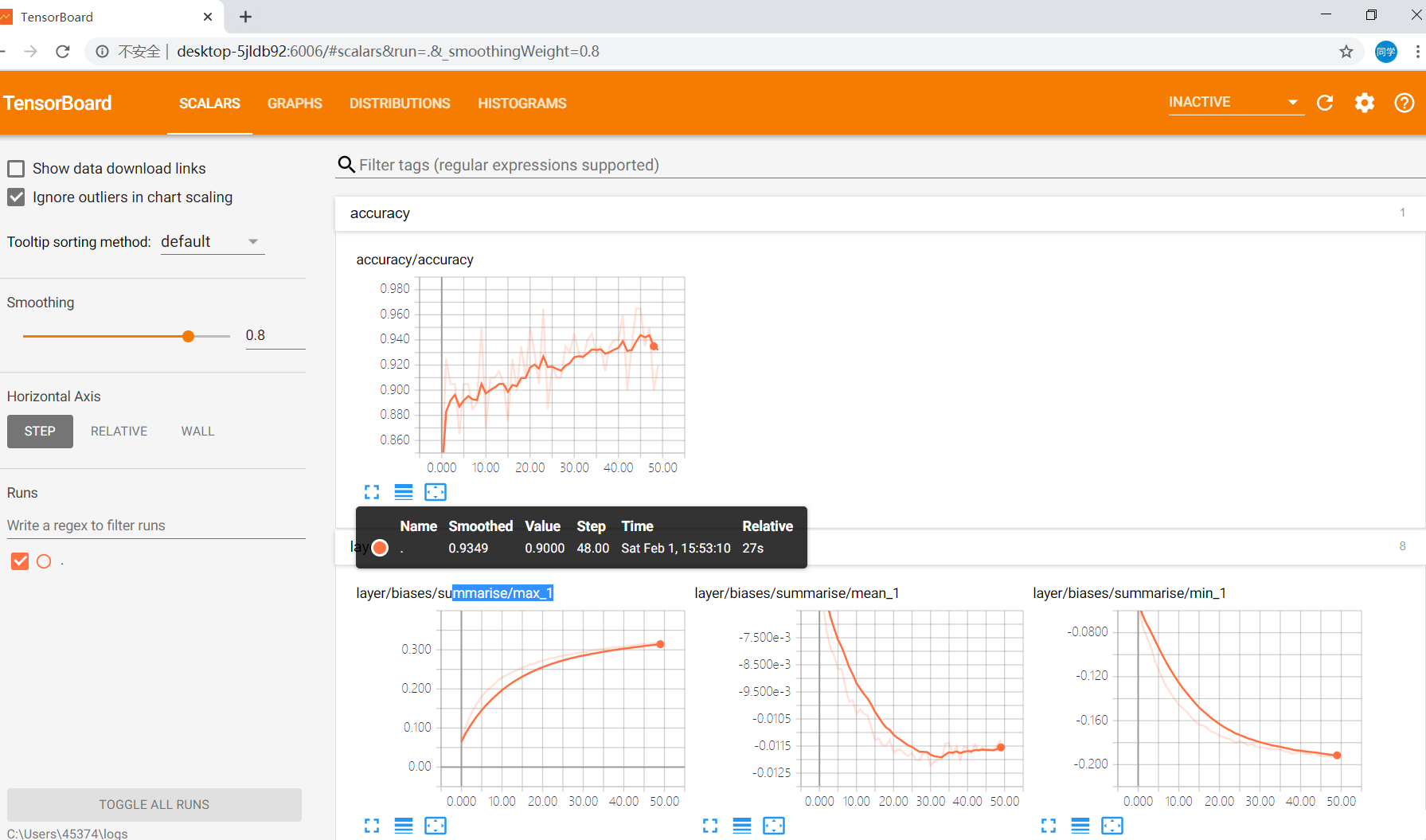
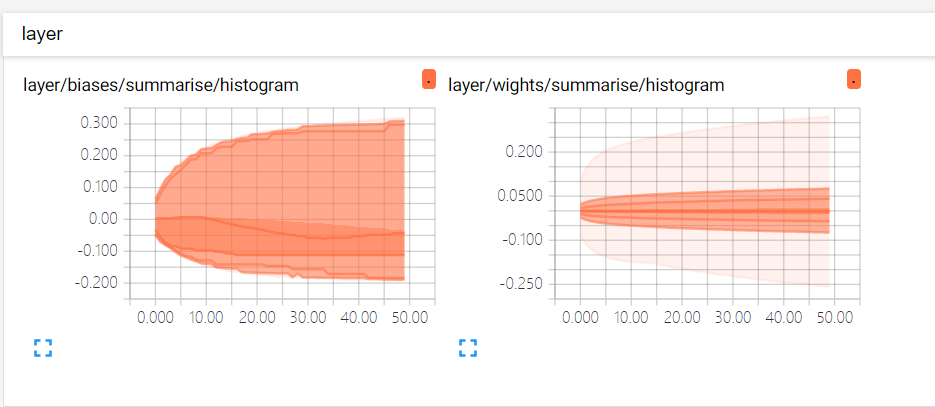
ЭъећДњТыШчЯТЃК
import tensorflow
as tf
from tensorflow.examples.tutorials.mnist
import
input_data
#диШыЪ§Он
mnist = input_data.read_data_sets
("E:/mnist",one_hot=True)
#УПИіХњДЮДѓаЁ
batch_size = 200
#МЦЫувЛЙВгаЖрЩйИіХњДЮ
n_batch = mnist.train.num_examples
//batch_size
#ећГ§
def variable_summarise(var):
with tf.name_scope('summarise'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean',mean)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean
(tf.square(var
- mean)))
tf.summary.scalar('srddev',stddev)
tf.summary.scalar('max',tf.reduce_max(var))
tf.summary.scalar('min',tf.reduce_min(var))
tf.summary.histogram('histogram',var)
with tf.name_scope("input"):
x = tf.placeholder(tf.float32,
[None,784],name='x_input')
y = tf.placeholder(tf.float32,
[None,10],name='y_input')
#ЪфШыВуЕНвўВиВу
with tf.name_scope('layer'):
with tf.name_scope('wights'):
W = tf.Variable(tf.zeros([784,10]))
#етРяWГѕЪМЛЏЮЊ0ЃЌПЩвдИќПьЪеСВ
variable_summarise(W)
with tf.name_scope('biases'):
b = tf.Variable(tf.zeros([10]))
variable_summarise(b)
with tf.name_scope('Wx_plus_b_L1'):
Wx_plus_b_L1 = tf.matmul(x,W) + b
#вўВиВуЕНЪфГіВу
with tf.name_scope('output'):
with tf.name_scope('wights'):
W2 = tf.Variable(tf.random_normal([10,10]))
#вўВиВуВЛФмГѕЪМЛЏЮЊ0
with tf.name_scope('biases'):
b2 = tf.Variable(tf.zeros([10]))
with tf.name_scope('softmax'):
prediction = tf.nn.softmax(tf.matmul
(Wx_plus_b_L1,W2)+b2)
#ЖўДЮДњМлКЏЪ§
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.square(y-prediction))
tf.summary.scalar('loss',loss)
#ЬнЖШЯТНЕЗЈбЕСЗ
train_step =
tf.train.GradientDescentOptimizer(0.2).
minimize(loss)#бЇЯАТЪЮЊ0.2
init = tf.global_variables_initializer()
#ЧѓзМШЗТЪ
with tf.name_scope('accuracy'):
correct_prediction = tf.equal
(tf.argmax(y,1),tf.argmax
(prediction,1))#equlХаЖЯЪЧЗёЯрЕШЃЌ
argmaxЗЕЛиеХСПзюДѓжЕЕФЫїв§
accuracy = tf.reduce_mean(tf.cast
(correct_prediction,tf.float32))
#НЋВМЖћаЭзЊЛЛЮЊИЁЕуаЭ
tf.summary.scalar('accuracy',accuracy)
merged = tf.summary.merge_all()
with tf.Session() as sess:
sess.run(init)
writer = tf.summary.FileWriter
('C:\\Users\\45374\\logs',sess.graph)
#ЕќДњбЕСЗ20ДЮ
for epoch in range(50):
for batch in range(n_batch):
#бЕСЗМЏЪ§ОнгыБъЧЉ
batch_xs,batch_ys =
mnist.train.next_batch(batch_size)
# sess.run(train_step,feed_dict=
{x:batch_xs,y:batch_ys})
summary,_ = sess.run([merged,train_step],
feed_dict=
{x:batch_xs,y:batch_ys})
writer.add_summary(summary,epoch)
acc = sess.run(accuracy,feed_dict
={x:mnist.test.images,y:mnist.test.labels})
print("Iter " + str(epoch) + "
Accuracy" + str(acc)) |
|









