| 编辑推荐: |
机器学习是一种能够实现人工智能的技术,可以通过大量的数据,训练出来一个处理数据的模型。本文将与大家分享:机器学习的相关实践应用。
本文来自于人人都是产品经理,由火龙果软件Alice编辑、推荐。
|
|
我所理解的机器学习是一种能够实现人工智能的技术,建立能从经验(数据)中进行学习的模型,从而使这个模型可以达到自行处理此类数据的能力。
也可以理解为:通过大量的数据,训练出一个能处理此类数据的模型。使得这个模型可以根据已知的数据,准确率很高的判断出未知的数据,从而使得人类能够采取正确的方法去处理某些事情。
想要了解机器学习你需要知道以下几点:
一、机器学习的流程
从实际的应用场景出发,要训练出来一个能够适应某场景的模型需要经过以下几步:
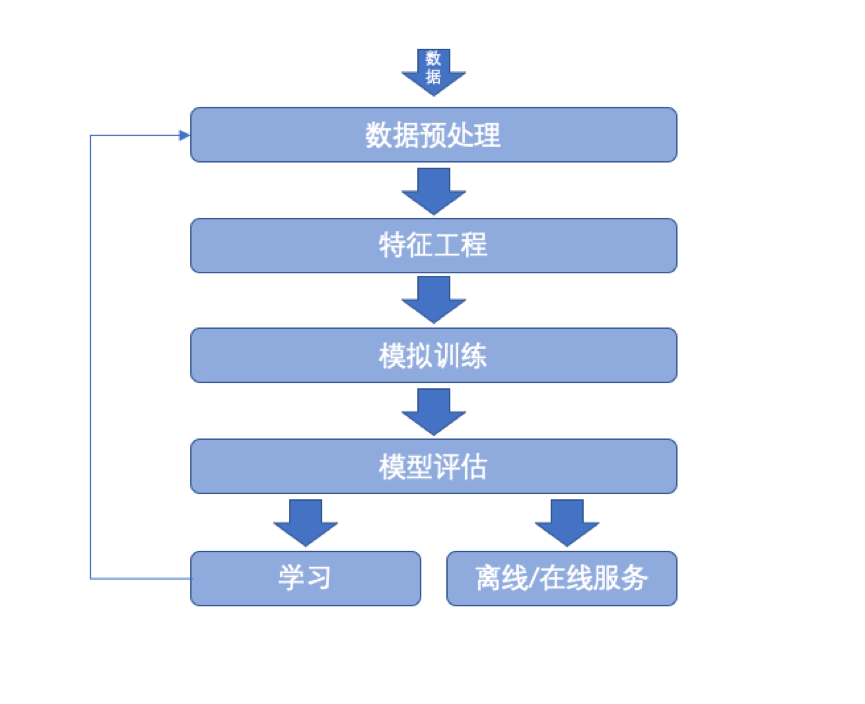
1. 场景解析
场景解析就是将业务逻辑,抽象成为通过算法能够解决的问题。
比如:做一个心脏病预测系统,那么就可以抽象为二分类问题——要么有心脏病,要么没有。然后,根据已有的数据看看有没有目标值,可以判断出:是监督学习还是无监督学习,还是半监督学习。从而,选择出能够处理好此类数据的算法。
(不同场景采用的算法是不同的)高频的有以下几种类型的场景:
分类场景:广告投放预测,网站用户点击预测。
聚类场景:人群划分,产品种类划分。
回归场景:商品购买量预测和股票成交额预测。
文本分析类场景:新闻的标签提取,文本自动分类和文本关键信息抽取。
关系图算法:社交网络关系,网络关系挖掘和金融风险控制。
模式识别:语音识别,图像识别和手写文字识别。
2. 数据预处理
场景解析完,选择适合处理此类数据的算法后,需要对数据进行预处理——就是对数据进行清洗工作,对空值,乱码进行处理。
数据预处理的主要目的就是:减少噪音数据对训练数据的影响。
3. 特征工程
特征工程是机器学习中最重要的一部分,因为根据已有的训练数据,可选用的算法是有限的,那么在同样的算法下特征的选取是不同的,100个人对一件事情会有100种看法,也就有100种特征,最后特征的质量决定模型的好坏。特征工程需要做的包括:特征抽象,特征重要性的评估,特征衍生,特征降维。
4. 模拟训练
在经过以上过成后,进入训练模块,生成模型。
5. 模型评估
对生成模型的成熟度进行评估。
6. 离线/在线服务
在实际运用过程中,需要配合调度系统来使用。
案例场景:每天将用户当日新增的数据量流入数据库表里,通过调度系统启用离线训练服务,生成最新的离线模型,然后通过在线预测服务进行实时预测。
二、数据源结构
结构化数据:机构化数据是指以矩阵结构储存的数据。
数据库里的数据就是以这种结构存在,可以通过二维结构来显示,如下图:
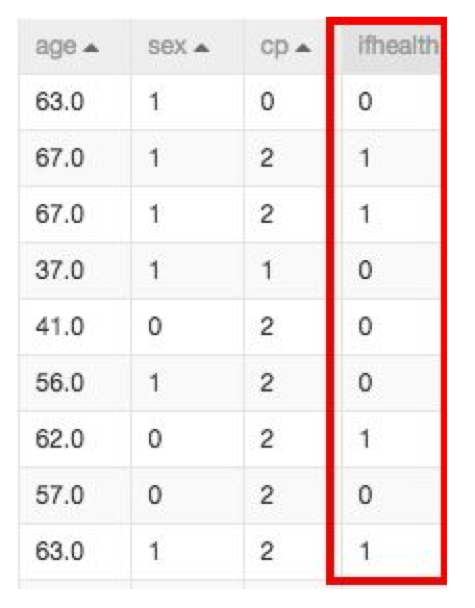
结构化数据中,有两个重要的概念需要介绍一下:特征列和目标列。
上图里age,sex,cp列都是特征列,ifhealth是目标列。
非结构化数据:典型的非结构化数据是图像,文本,语音等文件。这些数据不能以矩阵的结构储存,目前的做法也是通过把非结构化的数据转化为二进制储存格式。
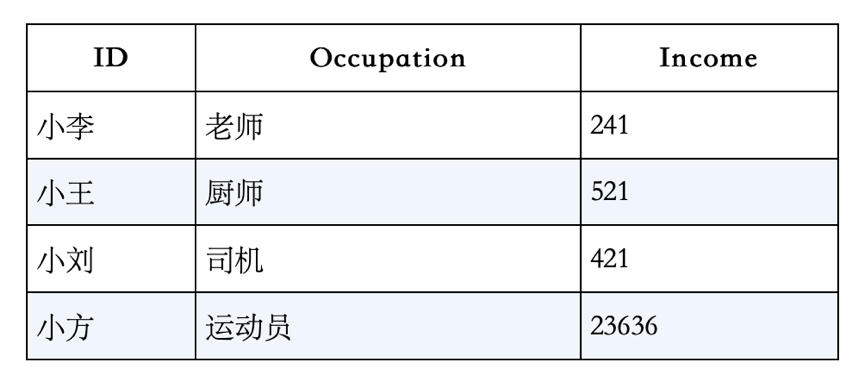
半结构化数据:半结构化数据是指按照一定的结构储存,但不一定是二维的数据库行存储形态的数据。还有一种是以二维数据形态储存的,但某些字段是文本类型,某些字段是数值类型的。如下图:
三、算法分类
监督学习:是指每个进入算法的训练样本数据都有对应的目标值。
如上图2所示,Ifhealth为目标值。
常见的监督学习算法:

无监督学习:就是训练样本的数据里没有目标列,不依赖于打标好的机器学习算法。
那么,这样的数据可能对一些分类和回归的场景就不太适合了。
无监督学习主要是来解决一些聚类场景的问题。

半监督学习:
通过上面的监督学习和无监督学习的概念,再来看半监督学习就比较好理解了。
也就是说,训练数据里只有部分数据是打标的。目前,半监督学习的算法,都是监督学习算法的变形。
强化学习:
强化学习是一种比较复杂的机器学习种类。强调的是:系统与外界不断的交换,获得外界的反馈,然后决定自身的行为。
如:无人驾驶,阿尔法狗下围棋就是强化学习的应用。
四、过拟合问题(欠拟合这里不做详细的介绍)
过拟合是数据挖掘(通过大量数据,训练模型的过程也称为数据挖掘)领域中最常见的问题,是指:通过训练集训练了一个模型,这个模型对于训练集的预测准确率很高,可以达到95%以上,但是换一份儿数据集进行预测,准确率大幅度下降。
出现这种情况的原因可能是:训练的过拟合现象。
导致过拟合问题的原因有以下三种:
训练数据集样本单一。
训练样本噪音数据干扰过大。
模型过于复杂。
五、结果评估
机器学习最终的目的是生成模型。
模型生成后需要一些指标来评估这个模型的好坏。
常用到的概念有:精确率,召回率,F1值,ROC和AUC几种。
首先介绍一下精确率,召回率和F1值。这3个指标是由:TP,TN,FP,FN这4个值计算而来的(这里不做解释了)。
精确率=TP/(TP+FP)
召回率=TP/(TP+FN)
F1=(2*精确率*召回率)/(精确率*召回率)

ROC曲线是常用的二分类场景的模型评估算法曲线,下图齿状弧形曲线就是ROC曲线。
如图所示:
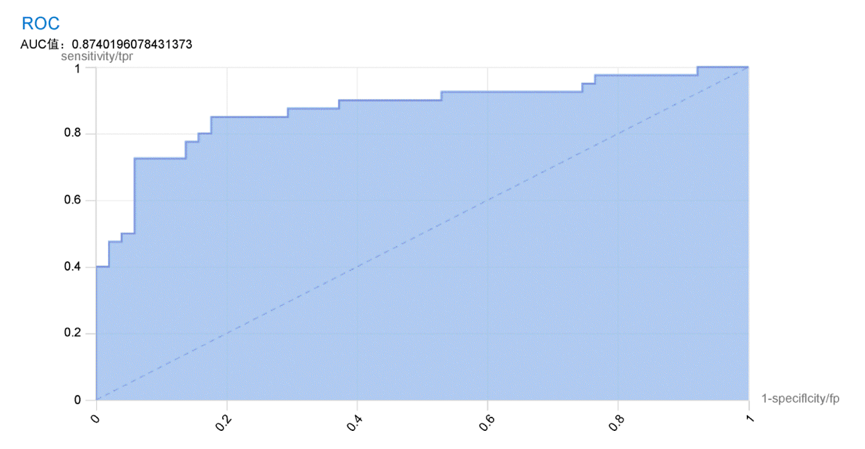
通过ROC曲线可以清晰的展示出来,只要模型曲线越来越接近左上角就说明模型的效果越好。
AUC的值是ROC与横轴所围起来的面积(图中带阴影的部分),这个AUC的值越大说明模型的效果越好。
AUC的值取0~1之间,通常大于0.5,当AUC的值大于0.9以上时,证明这个模型的效果比较好。
以上对机器学习的流程,和一些概念做了解释。但距离真正可以上手操作还有很远的距离。如非结构化数据和半结构化数据,如何转化为结构化数据?特征抽象,特征衍生,特征降维如何操作?等等,实际的操作问题,还需要一定的篇幅来介绍。
|









