| БрМЭЦМі: |
БОЮФжївЊНщЩмСЫБъзМЩёОЭјТчвдМАКЮЮЊЧАРЁЗДЯђДЋВЅШЋСЌНгЩёОЭјТчЃЌЭЈЙ§ОиеѓГЫЗЈЙЋЪНОЊабМђЕЅНщЩмЃЌЯЃЭћЖдФњЕФбЇЯАгжЫљАяжњЁЃ
БОЮФРДздгкжЊКѕЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ЧАбд
жЎЧАдФЖССЫКмЖргаЙиЩёОЭјТчЕФЪщМЎЁЂТлЮФвдМАВЉПЭЃЌЗЂЯжДѓЖрЗжЮЊСНжжЧщПіЁЃвЛжжЪЧР§ШчЁЖЩюЖШбЇЯАЁЗетРрЃЌРяУцЖбЦіСЫДѓСПЕФРэТлКЭЙЋЪНЃЌШчЙћЯИаФбаЖСЕФЛАЕФШЗПЩвдНЋЩёОЭјТчжаЕФЪ§бЇдРэРэНтЕФКмЭИГЙЁЃПЩЪЧЃЌЕБПДЭъЁЖЩюЖШбЇЯАЁЗЃЌШчЙћгаШЫШУЮвзіИіМђЕЅЕФЩёОЭјТчЗжРрЦїЃЌЮвПЩФмЛЙЪЧвЛЭЗЮэЫЎЃЌВЛжЊДгКЮЯТЪжЁЃЕкЖўжжЪЧР§ШчЁЖXXЪЕеНЁЗЃЌЁЖXXПьЫйЩЯЪжЁЗетРрЃЌИњзХЪщжаЕФДњТыШЗЪЕПЩвдгУЩёОЭјТчНтОіЪЕМЪЮЪЬтЃЌПЩЪЧЪщжагжУЛгаЖдЕзВуЕФЪ§бЇдРэНјааБШНЯЭИГЙЕФНВНтЁЃОГЃЪЧЖдЪ§бЇдРэзіИіМђЕЅНщЩмЃЌШУЖСепЖдЦфгаИіДѓжТСЫНтЃЌШЛКѓОЭПЊЪМИїжжЕїгУЯжГЩЕФАќЁЃЕїгУвЛИіАќЃЌМИааДњТыОЭДюЦ№вЛИіЩёОЭјТчЃЌЫфШЛИаОѕКмГЉПьЁЃПЩЪЧжЛЛсЕїАќгжгаЪВУДгУФиЃП
гкЪЧЃЌдкгыЭЌбЇНјааЬжТлКѓЃЌЮвУЧОіЖЈздМКРДзмНсетбљвЛЬзФкШнЁЃЦфжаМШЖдЩёОЭјТчжаЕФЪ§бЇдРэНјааЯИжТЕНУПвЛИіВНжшЕФЦЪЮіЃЌгжФмЪЕМЪДюНЈвЛИіФмЙЛжДааОпЬхШЮЮёЕФЩёОЭјТчЁЃЮвУЧДђЫуВЩгУвЛжжШЋаТЕФааЮФЙЙдьЃЌРДДяЕНвЛВНвЛЦЪЮіЃЈЪ§бЇдРэЃЉЃЌвЛВНвЛЪЕМљЃЈДњТыЪЕЯжЃЉЕФФПБъЁЃетжжааЮФЙЙдьЪЧЃКЪзЯШЬсГіФГжжашвЊНтОіЕФЪЕМЪЮЪЬтЁЃвдНтОіетИіЪЕМЪЮЪЬтЮЊГіЗЂЕуЃЌДгЕквЛВНЕНзюКѓвЛВНЃЌдкНтОіЮЪЬтЕФУПвЛИіВНжшжаЃЌНЋЪ§бЇдРэеЙПЊЦЪЮіЃЌШЛКѓТфЪЕЕНДњТыЪЕЯжЁЃЖјдкзюКѓЃЌЛЙНЋЛсВЛбсЦфЗГЕиВЩгУгУФГаЉПђМмЕїАќдйДЮНтОіИУЮЪЬтЁЃвдДяЕНЩЯЕУЬќЬУЃЈЛсгУЯжГЩЕФПђМмПьЫйЕФНтОіЪЕМЪЮЪЬтЃЉЁЂЯТЕУГјЗПЃЈЖЎЕФЩёОЭјТчУПвЛВНЕФЪ§бЇдРэЃЉЕФбЇЯАаЇЙћЁЃ
БъзМЩёОЭјТч
БъзМЩёОЭјТчЪЧзюЮЊЦеЭЈЁЂГЃЙцЕФЩёОЭјТчЁЃЪЧЦфЫћЩёОЭјТчШчЁАОэЛ§ЩёОЭјТчЃЈCNNsЃЉЁБЁЂЁАЕнЙщ/бЛЗЩёОЭјТчЃЈRNNsЃЉЁБЕФЛљДЁЁЃЦфЫћЩёОЭјТчЖМЪЧдкБъзМЩёОЭјТчЕФЛљДЁЩЯНјааИФдьЖјРДЕФЁЃ
БъзМЩёОЭјТчгаЪБвВГЦЮЊЗДЯђДЋВЅЩёОЭјТчЃЈBack propagation neural networkЃЉЛђМђГЦЮЊBPЩёОЭјТчЃЌгаЪБвВНазіЧАРЁЗДЯђДЋВЅШЋСЌНгЩёОЭјТчЁЃжСгкКЮЮЊЁАЗДЯђДЋВЅЁБЃЌКЮЮЊЁАЧАРЁЁБЃЌвдМАКЮЮЊЁАШЋСЌНгЁБдкКѓУцЛсНщЩмЕНЕФЁЃЮвУЧЯШИљОнЭМ1ЃЌЖдЩёОЭјТчЕФЙЙдьгаИіДѓЬхЕФШЯЪЖЁЃ
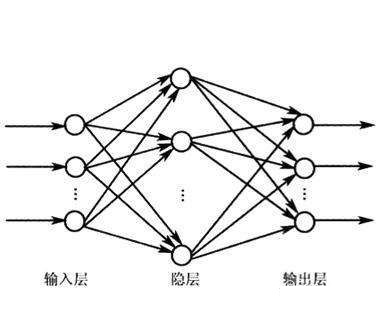
ЭМ1ЃКБъзМЩёОЭјТчЃЈАќКЌЪфШыВуЁЂвўВиВуКЭЪфГіВуЃЉ
ЭМ1ЫљЪОЪЧвЛИіБъзМЕФЩёОЭјТчЙЙдьЭМЁЃдВШІДњБэЩёОдЊЃЌдВШІжЎМфЕФМ§ЭЗДњБэЩёОдЊжЎМфЕФгаЯђСЌНгЁЃЮвУЧЪзЯШНЋЪ§ОнЪфШыЕНЪфШыВуЁЃЪ§ОнгаЖрЩйИіжЕЃЌЪфШыВуОЭгаЖрЩйИіЩёОдЊЁЃШЛКѓЪфШыВуИїИіЩёОдЊФкЕФЪ§ОнжЕАДзХМ§ЭЗЕФЗНЯђСїЯђЯТвЛВуЃЌУПИіМ§ЭЗЖМгаВЛЭЌЕФШЈжиЃЌЫљвдЪ§ОнжЕдкСїОВЛЭЌЕФМ§ЭЗЪБЛсгыВЛЭЌЕФШЈжиЯрГЫЁЃОЭетбљЃЌНЋЪ§ОнЪфШыЕНЪфШыВуЃЌОЭЛсдкЪфГіВуЕУЕНЮвУЧЯывЊЕФЪфГіЁЃШчЙћЪфГіКЭЮвУЧдЄЦкЕФНсЙћгавЛЖЈВюОрЃЌФЧУДОЭЪЪЕБаоИФМ§ЭЗЕФШЈжиЃЌЪЙЩёОЭјТчЕФЪфГіЯђИќМгЗћКЯЮвУЧдЄЦкЕФЗНЯђППНќЁЃ
УїШЗШЮЮёФПБъ
ЪзЯШЮвУЧашвЊвЛИіФбвдНјааЯпадЗжРыЕФЪ§ОнМЏЁЃетРяЮвУЧЪЙгУТна§Ъ§ОнМЏЃЌЦфЭЈЙ§ШчЯТДњТыЩњГЩЁЃдкетРяЮвУЧВЛЙизЂВњЩњТна§Ъ§ОнМЏЕФОпЬхЯИНкЃЌвђЮЊетЦЋРыСЫБОЮФЕФжїЬтЁЃЮвУЧжЛашвЊИДжЦеГЬљЯТУцетЖЮДњТыЃЌМДПЩЕУЕНШчЭМ2ЫљЪОЕФТна§Ъ§ОнМЏЃК
N = 100 # УПРрбљБОЕуЕФИіЪ§
D = 2 # ЮЌЖШЃЈУПИібљБОЕуга2ИіЬиеї,МДКсзјБъКЭзнзјБъЃЉ
K = 3 # РрБ№Ъ§ЃЈЙВШ§жжВЛЭЌРрБ№ЕФбљБОЕуЃЉ
X = np.zeros((N*K,D)) # Ъ§ОнОиеѓ (УПвЛааЪЧвЛИібљБО)
y = np.zeros(N*K, dtype='uint8') # РрБъЧЉ
for j in range(K):
ix = list(range(N*j,N*(j+1)))
r = np.linspace(0.0,1,N)
t = np.linspace(j*4,(j+1)*4,N) + np.random.randn(N)*0.2
X[ix] = np.c_[r*np.sin(t), r*np.cos(t)]
y[ix] = j
# НЋЪ§ОнПЩЪгЛЏ
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.Spectral)
plt.show() |
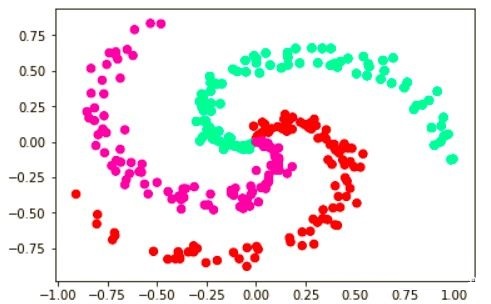
ЭМ2ЃКТна§Ъ§ОнМЏ
ЭЈЙ§ЙлВьЮвУЧПДЕНТна§Ъ§ОнМЏжагаШ§жжВЛЭЌРраЭЕФбљБОЕуЃЌУПИібљБОЕугаСНИіЬиеїЃЌЗжБ№ЪЧКсзјБъКЭзнзјБъЁЃгкЪЧЮвУЧЕФШЮЮёФПБъОЭРДСЫЃКМДАбетаЉгаСНИіЬиеїЕФбљБОЕуе§ШЗЗжРрЁЃОпЬхРДЫЕОЭЪЧЃЌНЋвЛИібљБОЕуЕФСНИіЬиеїжЕЃЈКсзјБъжЕгызнзјБъжЕЃЉзїЮЊЪфШыЃЌЕУЕНвЛИіЙигкетИібљБОЕуЪєгкФГИіРрБ№ЕФЪфГіЁЃШчЙћетИіЪфГіЗћКЯЮвУЧЕФдЄЦкЃЈМДЪфГіЕФРрБ№ОЭЪЧИУбљБОЕуЕФе§ШЗРрБ№ЃЉЃЌФЧКмЭъУРЃЌШчЙћВЛЗћКЯЮвУЧЕФдЄЦкЃЌОЭЖдЩёОЭјТчжаЕФШЈжиНјааЕїећЁЃ
дЄДІРэ
ЭЈГЃЮвУЧашвЊЖдЪ§ОнМЏНјаадЄДІРэЁЃдкБОР§жаЃЌЫљгаЬиеїжЕвбОКмКУЕФНщгк-1жС1жЎМфЃЌвђДЫЮвУЧПЩвдЬјЙ§ДЫВНжшЁЃ
ГѕЪМЛЏЪфШыВуКЭвўВиВужЎМфЕФВЮЪ§
жЎЧАЬсЕНЙ§ЃЌЪ§ОнгаЖрЩйИіжЕЃЌЪфШыВуОЭгаЖрЩйИіЩёОдЊЁЃФЧУДЁАЪ§ОнгаЖрЩйИіжЕЁБЪЧЪВУДКЌвхЃПЦфЪЕОЭЪЧжИвЛИібљБОЕугаЖрЩйИіЬиеїЁЃдкетРяЃЌвЛИібљБОЕугаСНИіЬиеїЃЌФЧУДЪфШыВуОЭгаСНИіЩёОдЊЁЃЮвУЧвдФГИібљБОЕуЮЊР§ЃЌБШШчвЛИізјБъЮЊЃЈ0.25ЃЌ
0.50ЃЉЕФТЬЩЋбљБОЕуЁЃЪфШыЕНЪфШыВужЎКѓШчЭМ3ЫљЪОЃК
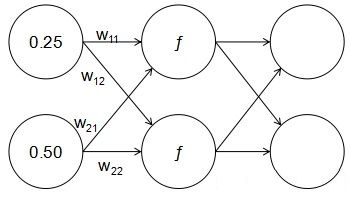
ЭМ3ЃКНЋзјБъЮЊЃЈ0.25ЃЌ0.50ЃЉЕФбљБОЕуЪфШыЕНЪфШыВу
ЮвУЧПДЕНУПИіЬиеїжЕЖМгывўВиВуЕФЫљгаЩёОдЊЯрСЌЃЌетвВОЭЪЧЁАШЋСЌНгЁБвЛДЪЕФгЩРДЁЃМДУПвЛИіЩёОдЊЖМгыКѓвЛВуЕФЫљгаЩёОдЊЯрСЌНгЁЃгЩЭМЮвУЧФмЙЛПДГіЃЌШчЙћвўВиВугаСНИіЩёОдЊЃЌФЧУДЪфШыВуКЭвўВиВужЎМфОЭашвЊга2ЁС2=4ИіСЌНгШЈжиЁЃ
ФмЙЛПДЕНСїШыЕНвўВиВуЕквЛИіЩёОдЊЕФЪ§жЕгІИУЮЊ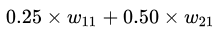 ЃЌЕЋЦфЪЕЛЙгІИУМгЩЯвЛИіГЦжЎЮЊЦЋжУЕФЪ§жЕ
[b] ЃЌМД ЃЌЕЋЦфЪЕЛЙгІИУМгЩЯвЛИіГЦжЎЮЊЦЋжУЕФЪ§жЕ
[b] ЃЌМД 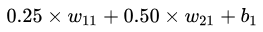 ЮЊСїШыЕНвўВиВуЕквЛИіЩёОдЊЕФЪ§жЕЁЃЭЌРэЃЌ ЮЊСїШыЕНвўВиВуЕквЛИіЩёОдЊЕФЪ§жЕЁЃЭЌРэЃЌ 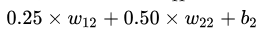 ЮЊСїШыЕНвўВиВуЕкЖўИіЩёОдЊЕФЪ§жЕЁЃНЋЦфаДЮЊОиеѓЕФаЮЪНЃЌМДШчЯТЃК ЮЊСїШыЕНвўВиВуЕкЖўИіЩёОдЊЕФЪ§жЕЁЃНЋЦфаДЮЊОиеѓЕФаЮЪНЃЌМДШчЯТЃК
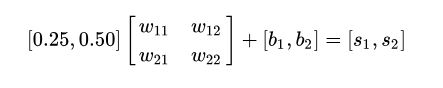
Цфжа [ЙЋЪН] КЭ [ЙЋЪН] ЗжБ№ДњБэСїШывўВиВуЕквЛИіЩёОдЊКЭЖўИіЩёОдЊЕФЪ§жЕЁЃ
ФЧУДШчЙћЮвУЧвўВиВуга100ИіЩёОдЊЃЌгкЪЧЪфШыВуКЭвўВиВужЎМфОЭга2ЁС100=200ИіСЌНгШЈжиЁЃЭЌРэЦфОиеѓГЫЗЈгІЪЧШчЯТаЮЪНЃК
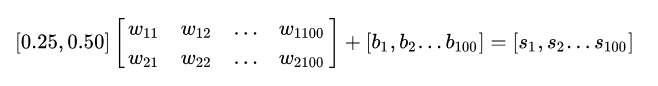
гЩгкзюПЊЪМЮвУЧвВВЛжЊЕРетаЉСЌНгШЈживдМАЦЋжУЕФжЕгІИУЪЧЖрЩйЃЌгкЪЧЮвУЧНЋетаЉШЈжиЕФГѕЪМжЕЩшжУЮЊЫцЛњжЕЁЃЮвУЧНЋЦфЩшжУЮЊЗўДгОљжЕЮЊ0ЃЌБъзМВюЮЊ1ЕФе§ЬЌЗжВМЕФЫцЛњжЕЃЌетбљИќЗћКЯЮяРэЪРНчЕФвЛАуЙцТЩЃЌМДППНќ0ИННќЕФжЕИќЖрвЛаЉЁЃЖјНЋЦЋжУГѕЪМЛЏЮЊ0жЕЃК
# ГѕЪМЛЏВЮЪ§
W1 = 0.01 * np.random.randn(D, 100)
b1 = np.zeros((1,100)) |
ПЩвдЪдзХНЋШЈжиОиеѓДђгЁГіРДЃЌФмЙЛжБЙлЕиПДЕНетЪЧвЛИі2аа100СаЕФОиеѓЁЃЖјЦЋжУЪЧвЛИі1аа100СаЕФааЯђСПЁЃ
ДгвўВиВуСїГі
ИљОнЩЯЪіОиеѓГЫЗЈЙЋЪНЃЌПЩвдКмШнвзЕФЧѓГіСїШыЕНвўВиВуЩёОдЊЕФжЕЁЃШЛЖјЃЌСїШыЕНвўВиВуЩёОдЊЕФжЕВЂЗЧдЗтВЛЖЏЕидйДгвўВиВуЩёОдЊСїГіЁЃЖјЪЧОЙ§вЛИіГЦжЎЮЊЁАМЄЛюКЏЪ§ЁБЕФКЏЪ§НјааМЄЛюЁЃМђЖјбджЎЃЌОЭЪЧвЊАбСїШыЕНвўВиВуЩёОдЊЕФжЕзїЮЊФГИіКЏЪ§ЕФЪфШыЃЌЕУЕНИУКЏЪ§ЕФЪфГіЃЌНЋИУКЏЪ§ЕФЪфГізїЮЊСїГівўВиВуЩёОдЊЕФжЕЁЃ
етРяЮвУЧЪЙгУReLuКЏЪ§зїЮЊвўВиВуЩёОдЊЕФМЄЛюКЏЪ§ЃЌМД [ЙЋЪН] ЁЃReLuКЏЪ§ЭМЯёШчЭМ4ЫљЪОЃК
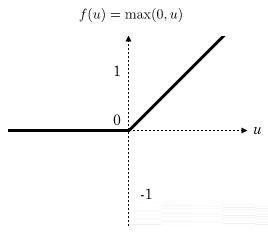
ЭМ4ЃКReLuКЏЪ§ЭМЯё
ЯдШЛЃЌЕБReLuКЏЪ§ЕФЪфШыаЁгк0ЪБЃЌЦфЪфГіЮЊ0ЁЃЕБReLuКЏЪ§ЕФЪфШыДѓгк0ЪБЃЌЦфЪфГіЕШгкЪфШыжЕЁЃгЩДЫЃЌПЩвдЫуГівўВиВуЕФЪфГіЃЌЦфДњТыШчЯТЃК
| hidden_layer
= np.maximum(0, np.dot(X, W1) + b1) |
ЦфжаЃЌhidden_layer ДњБэвўВиВуЕФЪфГіЁЃРэТлЩЯРДЫЕетгІИУЪЧвЛИі1аа100СаЕФааЯђСПЁЃЕЋЪЧжЕЕУзЂвтЕФЪЧЃЌЮвУЧВЂЗЧжЛгУЕЅЖРвЛИібљБОЕуЕФЬиеїЯђСПзідЫЫуЃЌЖјЪЧгУ300ИібљБОЕуЕФЬиеїОиеѓ
[X] ЭЌЪБзідЫЫуЁЃ300ИібљБОЕуЕФЬиеїОиеѓ [X] ШчЯТЃК
вђДЫЃЌзюжеЕУЕНЕФЪфГіЪЧ300аа100СаЕФЪфГіОиеѓЃЈОЁЙмЦЋжУЯђСПЩшжУЮЊ1аа100СаЕФЃЌЕЋЪЧpythonдкжДаа300аа100СаЕФОиеѓгы1аа100СаЕФЯђСПЯрМгЪБЃЌЛсздЖЏНЋ1аа100СаЕФЯђСПАДааИДжЦ300ЗнЃЌЪЙЦЋжУГЩЮЊвЛИі300аа100СаЦфжаУПааЖМЯрЕШЕФОиеѓЃЉЁЃ
ДгЪфГіВуСїГі
жЎЧАЮвУЧГѕЪМЛЏСЫЪфШыВуКЭвўВиВужЎМфЕФВЮЪ§ЃЌАќРЈ2аа100СаЕФШЈжиОиеѓКЭ1аа100СаЕФЦЋжУЯђСПЁЃетДЮЮвУЧгУЭЌбљЕФЗНЗЈЃЌГѕЪМЛЏвўВиВуКЭЪфГіВужЎМфЕФВЮЪ§ЁЃЮвУЧСюЪфГіВуАќКЌ3ИіЩёОдЊЁЃЪфГіВуЪЙгУ3ИіЩёОдЊЕФдвђЪЧбљБОЕуЗжЮЊШ§жжРраЭЁЃвђДЫЃЌдкЪфГіВуЕФШ§ИіЩёОдЊЕФЪфГіжЕжаЃЌШєЕквЛИіЩёОдЊЕФЪфГіжЕзюДѓЃЌдђПЩШЯЮЊИУбљБОЕуЪєгквЛРрЁЃЭЌРэЃЌШєЕкЖўИіЩёОдЊЕФЪфГіжЕзюДѓЃЌдђПЩШЯЮЊИУбљБОЕуЪєгкЖўРрЁЃвбжЊвўВиВуЕФЪфГіМДhidden_layerЪЧ300аа100СаЕФааЯђСПЃЌвђДЫвўВиВуЕНЪфГіВужЎМфЕФШЈжиОиеѓгІИУЪЧ100аа3СаЕФОиеѓЁЃЖјЦЋжУЯђСПгІИУЪЧ1аа3СаЕФааЯђСПЁЃГѕЪМЛЏвўВиВуЕНЪфГіВужЎМфЕФШЈжиОиеѓКЭЦЋжУЯђСПДњТыШчЯТЃК
W2 = 0.01 * np.random.randn(100,K)
b2 = np.zeros((1,K)) |
ШЛКѓНЋвўВиВуЕФЪфГіжЕhidden_layerгыВЮЪ§зідЫЫуЃЌЕУЕНЪфГіВуЕФЪфГіЃК
| scores = np.dot(hidden_layer,
W2) + b2 |
ЮвУЧНЋЪфГіВуЕФЪфГіГЦЮЊЗжЪ§ЯђСПЃЌвђЮЊЪфГіЕФ3ИіжЕЗжБ№ДњБэСЫбљБОЕуПЩФмЪєгкУПИіРрБ№ЕФЗжЪ§ЁЃзюжеЕУЕНЕФЯдШЛЪЧвЛИі300аа3СаЕФЗжЪ§ОиеѓЁЃЦфжаУПааДњБэУПИібљБОЕуЃЌУПСаДњБэЖдгІУПИіРрБ№ЕФЗжЪ§ЁЃЮвУЧПЩвдНЋЗжЪ§ОиеѓжБЙлЕиДђгЁГіРДЃЌШчЭМ5ЃК
ЭМ5ЃК300аа3СаЕФЗжЪ§Оиеѓ
КтСПгыгыецЪЕЧщПіЕФВюОр
НгЯТРДЕФвЛИіЙиМќвђЫиОЭЪЧЫ№ЪЇКЏЪ§ЃЌЮвУЧашвЊгУЫќРДМЦЫуЮвУЧЕФЫ№ЪЇЁЃФЧУДКЮЮЊЁБЫ№ЪЇЁАЃПЁБЫ№ЪЇЁАМДдЄВтНсЙћКЭецЪЕЧщПіЯрВюЖрЩйЁЃецЪЕЧщПіКЭдЄВтНсЙћЯрВюдНДѓЃЌЫ№ЪЇжЕдНДѓЁЃецЪЕЧщПіКЭдЄВтНсЙћдННгНќЃЌЫ№ЪЇжЕдНаЁЁЃдкетРяЃЌЮвУЧЯЃЭће§ШЗЕФРрБ№гІИУБШЦфЫћРрБ№гаИќИпЕФЗжЪ§ЃЌШєШЗЪЕШчДЫЃЌдђЫ№ЪЇгІИУКмЕЭЃЌЗёдђЫ№ЪЇгІИУКмИпЁЃСПЛЏетжжжБОѕЕФЗНЗЈгаКмЖржжЃЌЕЋдкетРяЮвУЧЪЙгУгыНЛВцьиЫ№ЪЇЁЃЮвУЧЪзЯШгУ
[F] БэЪОвЛИібљБОЕФРрБ№ЗжЪ§ЯђСПЃЈМДАќКЌШ§ИіЪ§жЕЕФЯђСПЃЉЃЌгкЪЧЫ№ЪЇКЏЪ§ШчЯТЃК
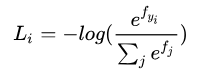
ЮвУЧЪзЯШЖдЩЯЪіЙЋЪННјааНтЖСЃКЪзЯШ li ДњБэбљБО i ЕФЫ№ЪЇжЕЁЃ yiДњБэбљБО
i ЕФецЪЕРрБ№БъЧЉЃЈШчЙћбљБО i ЪєгквЛРрЃЌдђРрБ№БъЧЉЪЧ1ЃЉЃЌвђДЫШєбљБО i ЕФРрБ№ЗжЪ§ЯђСПЮЊ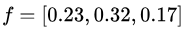 ЃЌЧвбљБО
i ЪєгквЛРрЃЌдђ ЃЌЧвбљБО
i ЪєгквЛРрЃЌдђ 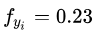 ЁЃЖј jДњБэfжадЊЫиЕФЫїв§ЁЃЙЪЖдгкбљБОЗжЪ§ЯђСПЮЊ ЁЃЖј jДњБэfжадЊЫиЕФЫїв§ЁЃЙЪЖдгкбљБОЗжЪ§ЯђСПЮЊ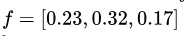 ЕФбљБО i РДЫЕЃЌЫ№ЪЇжЕ
ЕФбљБО i РДЫЕЃЌЫ№ЪЇжЕ
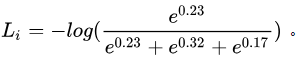
ЮвУЧФмЙЛПДГіРДЃЌ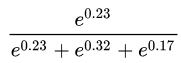 ЕФжЕгРдЖНщгк0КЭ1жЎМфЃЌЮвУЧНЋетГЦЮЊецЪЕРрБ№ЕФЙщвЛЛЏИХТЪЁЃЯдШЛЃЌбљБО
i ЕФецЪЕРрБ№ЕФЗжЪ§дНИпЃЌдђецЪЕРрБ№ЕФЙщвЛЛЏИХТЪдННгНќ1ЃЌвђДЫЫ№ЪЇжЕ [ЙЋЪН] дНЕЭЁЃЗДжЎЃЌШєбљБО
i ЕФецЪЕРрБ№ЖдгІЕФЗжЪ§НЯЕЭЃЌдђецЪЕРрБ№ЕФЙщвЛЛЏИХТЪдННгНќ0ЃЌвђДЫЫ№ЪЇжЕ LiдНИпЁЃ ЕФжЕгРдЖНщгк0КЭ1жЎМфЃЌЮвУЧНЋетГЦЮЊецЪЕРрБ№ЕФЙщвЛЛЏИХТЪЁЃЯдШЛЃЌбљБО
i ЕФецЪЕРрБ№ЕФЗжЪ§дНИпЃЌдђецЪЕРрБ№ЕФЙщвЛЛЏИХТЪдННгНќ1ЃЌвђДЫЫ№ЪЇжЕ [ЙЋЪН] дНЕЭЁЃЗДжЎЃЌШєбљБО
i ЕФецЪЕРрБ№ЖдгІЕФЗжЪ§НЯЕЭЃЌдђецЪЕРрБ№ЕФЙщвЛЛЏИХТЪдННгНќ0ЃЌвђДЫЫ№ЪЇжЕ LiдНИпЁЃ
ЮвУЧдкетРяЧѓГі300ИібљБОЕФЦНОљЫ№ЪЇжЕЃЌвдКтСПЩёОЭјТчЕФадФмЁЃЮвУЧГЦжЎЮЊЦНОљНЛВцьиЫ№ЪЇЃК
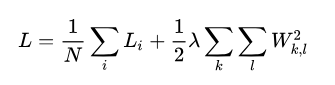
ЙЋЪНЕФЧААыВПЗжздШЛЪЧ300ИібљБОЕФНЛВцьиЫ№ЪЇЕФЦНОљжЕЃЌМДЦНОљНЛВцьиЫ№ЪЇЁЃЖјКѓАыВПЗжЃЌГЦжЎЮЊе§дђЛЏЫ№ЪЇЁЃКЮЮЊЁБе§дђЛЏЫ№ЪЇЁАЃПЮвУЧЭЈЙ§вЛИіР§згРДРэНте§дђЛЏЫ№ЪЇЃЌБШШчбљБОЕу
i ЕФСНИіЬиеїМДКсзнзјБъЮЊЃЈ1.0ЃЌ1.0ЃЉЁЃЖјМйЩшДЫЪБгаСНзщВЛЭЌЕФШЈжиЯђСП  ЁЃбљБОЕФЬиеїгыСНзщВЛЭЌЕФШЈжизіФкЛ§ЕФНсЙћЯрЕШЃЌЖМЮЊ1ЁЃПЩЪЧМгЩЯе§дђЛЏЫ№ЪЇКѓЃЌКмУїЯд
ЁЃбљБОЕФЬиеїгыСНзщВЛЭЌЕФШЈжизіФкЛ§ЕФНсЙћЯрЕШЃЌЖМЮЊ1ЁЃПЩЪЧМгЩЯе§дђЛЏЫ№ЪЇКѓЃЌКмУїЯд 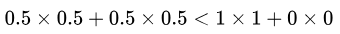 ЁЃЫљвдбЁдёW2зїЮЊШЈжиЃЌе§дђЛЏЫ№ЪЇИќаЁЁЃе§дђЛЏЫ№ЪЇЕФзїгУдкгкдіЧПЗКЛЏФмСІЃЌШЅГ§ШЈжиЕФВЛШЗЖЈадЁЃ
ЁЃЫљвдбЁдёW2зїЮЊШЈжиЃЌе§дђЛЏЫ№ЪЇИќаЁЁЃе§дђЛЏЫ№ЪЇЕФзїгУдкгкдіЧПЗКЛЏФмСІЃЌШЅГ§ШЈжиЕФВЛШЗЖЈадЁЃ
ФЧУДЯждкОЭПЩвдИљОнЙЋЪНвдМАвбжЊЕФЗжЪ§ОиеѓЃЌМЦЫуЫ№ЪЇСЫЁЃЮвУЧЪзЯШНЋЗжЪ§ОиеѓзЊЛЛЮЊИХТЪОиеѓЃК
# ЕУЕНбљБОЪ§СП
num_examples = X.shape[0]
# ЕУЕНЗЧЙщвЛЛЏИХТЪ
exp_scores = np.exp(scores)
# ЕУЕНУПИібљБОЖдгІИїИіРрБ№ЕФЙщвЛЛЏИХТЪ
probs = exp_scores / np.sum(exp_scores, axis=1,
keepdims=True) |
ЯждкЮвУЧгаСЫвЛИі300аа3СаЕФИХТЪОиеѓЃЌВЂЧвЮвУЧвбОНЋУПвЛааЕФИХТЪЖМНјааСЫЙщвЛЛЏЃЌЪЙЕУУПвЛааЕФШ§ИіИХТЪжЎКЭЮЊ1ЁЃЯждкЮвУЧОЭПЩвдНЋУПИібљБОЖдгІецЪЕРрБ№ЕФИХТЪЬсШЁГіРДЃЌзі
[ЙЋЪН] гГЩфЁЃ
| corect_logprobs
= -np.log(probs[range(num_examples),y]) |
гкЪЧЕУЕНСЫвЛИіАќКЌ300ИідЊЫиЕФвЛЮЌЯђСПЃЌЦфжаУПИідЊЫиЖМЪЧЯргІбљБОЕФНЛВцьиЫ№ЪЇжЕЁЃНгЯТРДМЦЫуЦНОљНЛВцьиЫ№ЪЇвдМАе§дђЛЏЫ№ЪЇЃЌВЂНЋЖўепЯрМгЃК
# МЦЫуЫ№ЪЇЃКЦНОљНЛВцьиЫ№ЪЇКЭе§дђЛЏЫ№ЪЇ
data_loss = np.sum(corect_logprobs)/num_examples
reg_loss = 0.5 * reg * np.sum(W1 * W1) + 0.5 *
reg * np.sum(W2 * W2)
loss = data_loss + reg_loss |
ИќаТВЮЪ§
ЮвУЧЕФВЮЪ§ЪЧЫцЛњГѕЪМЛЏЕФЃЌЫљвдЩёОЭјТчЪфГіЕФНсЙћБиШЛКЭецЪЕЧщПігаЫљВюОрЁЃЖјЮвУЧЯждкЕФФПБъЪЧЪЙетжжВюОрОЁПЩФмЕФаЁЃЌМДевЕНВЮЪ§W1ЁЂb1ЁЂW2ЁЂb2ШЁЪВУДжЕЕФЪБКђЃЌЫ№ЪЇжЕзюаЁЁЃЮвУЧПЩвдЧѓЫ№ЪЇЖдВЮЪ§ЕФЕМЪ§ЃЌгУЬнЖШЯТНЕевЕНЕМЪ§ЮЊ0ЕФЕуЃЌМДЮЊМЋаЁжЕЕуЁЃетРяЮвУЧдк
[ЙЋЪН] КЭ [ЙЋЪН] жЎМфв§ШывЛИіжаМфБфСП [ЙЋЪН] ЃЌЦфКЌвхЮЊвЛИіЙщвЛЛЏИХТЪЕФЯђСПЁЃгкЪЧбљБО i
ЕФЫ№ЪЇЮЊЃК
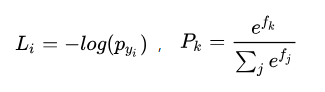
ЮвУЧЯждкЯывЊжЊЕРбљБО i ЕФЗжЪ§ЯђСП [ЙЋЪН] жаЕФдЊЫи [ЙЋЪН] ШчКЮИФБфВХФмМѕЩйЫ№ЪЇ [ЙЋЪН]
ЃЌДгЖјМѕЩйећЬхЫ№ЪЇ [ЙЋЪН] ЁЃвђДЫЃЌЮвУЧашвЊЧѓГі [ЙЋЪН] ЁЃЖјгЩгкдк [ЙЋЪН] КЭ [ЙЋЪН] жЎМфв§ШыСЫжаМфБфСП
[ЙЋЪН] ЃЌвђДЫ [ЙЋЪН] ЁЃШнвзЕУГі [ЙЋЪН] ЁЃЖјЖдгк [ЙЋЪН] ЃЌдђЗжСНжжЧщПіЃК
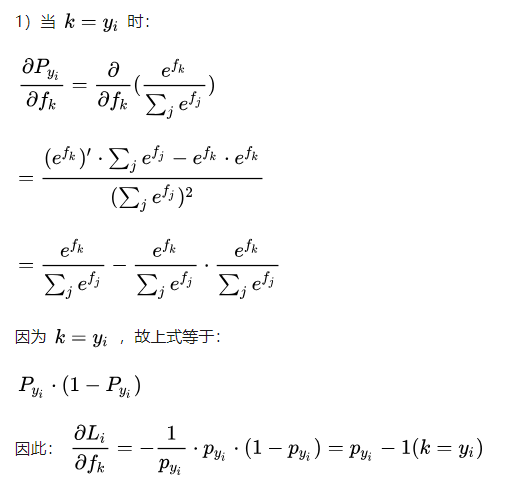

вђДЫЮвУЧФмЙЛЕУЕН [ЙЋЪН] Жд [ЙЋЪН] ЕФЬнЖШЯђСПЁЃМйЩшбљБО i ЕФЙщвЛЛЏИХТЪЯђСПЮЊ [ЙЋЪН]
ЃЌЧвбљБО i ЕФецЪЕРрБ№БъЧЉЮЊ1ЃЌдђ [ЙЋЪН] Жд [ЙЋЪН] ЕФЬнЖШЯђСПЮЊ [ЙЋЪН] ЁЃвдЯТДњТыЮЊЩЯЪіЙ§ГЬЕФЪЕЯжЁЃЦфжаprobДцДЂ300ИібљБОЕФЙщвЛЛЏРрБ№ИХТЪОиеѓЃЌdscoreДцДЂЫ№ЪЇЖдЗжЪ§ЕФЬнЖШОиеѓЃК
dscores = probs
dscores[range(num_examples),y] -= 1
dscores /= num_examples |
ЖјгЩгкscores = np.dot(hidden_layer, W2) + b2ЃЌвђДЫПЩжЊscoresЖдW2ЕФЬнЖШОиеѓгІИУЪЧhidden_layerЕФзЊжУЃЌЖјЖдb2ЕФЬнЖШОиеѓгІИУЫљгадЊЫиЖМЮЊ1ЁЃЧвгаЫ№ЪЇЖдЗжЪ§ЕФЬнЖШДцДЂдкdscoresжаЃЌвђДЫИљОнСДЪНЧѓЕМЗЈдђЃЌЫ№ЪЇЖдW2КЭb2ЕФЬнЖШШчЯТДњТыЃК
# РћгУЗДЯђДЋВЅЧѓЫ№ЪЇЖдЪфГіВуШЈжиКЭЦЋжУЕФЬнЖШ
dW2 = np.dot(hidden_layer.T, dscores)
db2 = np.sum(dscores, axis=0, keepdims=True) |
ЭЌРэЃЌЮвУЧвЊЯыЧѓЫ№ЪЇЖдW1КЭb1ЕФЬнЖШЃЌПЩвдЯШЧѓЫ№ЪЇЖдhidden_layerЕФЬнЖШЃЌдйЧѓhiddenlayerЖдW1КЭb1ЕФЬнЖШЃЌдйИљОнСДЪНЧѓЕМЗЈдђМДПЩЧѓЕУЫ№ЪЇЖдW1КЭb1ЕФЬнЖШЁЃ
ИљОнСДЪНЧѓЕМЗЈдђЃЌЫ№ЪЇЖдhidden_layerЕФЬнЖШШчЯТДњТыЃЌЦфжаdhiddenЮЊЫ№ЪЇЖдhidden_layerЕФЬнЖШОиеѓЁЃ
| dhidden = np.dot(dscores,
W2.T) |
ЖјгЩгквўВиВуЕФМЄЛюКЏЪ§ЪЧReLuКЏЪ§ЃЌМД [ЙЋЪН] ЁЃЫљвдвўВиВуЩёОдЊЪфГіДѓгк0ЕФЃЌЖдReLuКЏЪ§ЪфШыжЕЕФЕМЪ§ЮЊ1ЃЛвўВиВуЩёОдЊЪфГіЕШгк0ЕФЃЌЖдReLuКЏЪ§ЪфШыжЕЕФЕМЪ§ЮЊ0ЁЃвђДЫЫ№ЪЇЖдReLuКЏЪ§ЪфШыжЕМДвўВиВуЪфШыжЕЕФЬнЖШЮЊЃК
# биReLuКЏЪ§НјааЗДЯђДЋВЅ
dhidden[hidden_layer <= 0] = 0 |
ЯждкdhiddenжаДцДЂЕФЪЧЫ№ЪЇЖдвўВиВуЪфШыЕФЬнЖШОиеѓЁЃгаСЫЫ№ЪЇЖдвўВиВуЪфШыЕФЬнЖШЃЌЧвгаСЫвўВиВуЪфШыЖдW1КЭb1ЕФЬнЖШЃЌИљОнСДЪНЗЈдђПЩвдЧѓЕУЫ№ЪЇЖдW1вдМАb1ЕФЬнЖШЃК
# зюжеЧѓЕУЫ№ЪЇЖдгывўВиВуЩёОдЊЯрСЌЕФШЈжиКЭЦЋжУЕФЬнЖШ
dW1 = np.dot(X.T, dhidden)
db1 = np.sum(dhidden, axis=0, keepdims=True) |
ЯждкЗжБ№гаСЫЫ№ЪЇЖдW1ЃЌW2ЃЌb1ЃЌb2ЕФЬнЖШЃЌМДПЩЖдВЮЪ§НјааИќаТСЫЁЃВЮЪ§ИќаТЕФЙЋЪНШчЯТЃЈвдW1жаЕквЛааЕквЛСаЕФдЊЫи
[ЙЋЪН] ЮЊР§ЃЉЃК
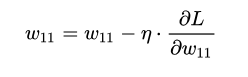
етОЭЪЧЫљЮНЕФЭЈЙ§ЬнЖШЯТНЕЧѓМЋаЁжЕЕуЁЃШчЭМ6ЫљЪОЃЌЕБ [ЙЋЪН] ЪБЃЌНЋ [ЙЋЪН] МѕаЁвЛЕуЃЌОЭЛсЪЙ
[ЙЋЪН] ИќНгНќМЋаЁжЕЁЃЗДжЎЃЌЕБ [ЙЋЪН] ЪБЃЌНЋ [ЙЋЪН] діДѓвЛЕуЃЌОЭЛсЪЙ [ЙЋЪН] ИќНгНќМЋаЁжЕЁЃ
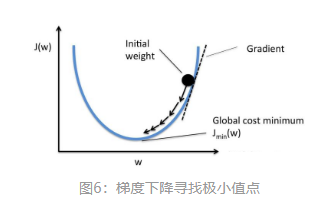
ЭМ6ЃКЬнЖШЯТНЕбАевМЋаЁжЕЕу
ЖдећИіW1ЁЂW2ЁЂb1вдМАb2ЬнЖШОиеѓРћгУЩЯЪіЙЋЪНжДааВЮЪ§ИќаТВйзїЃК
# ВЮЪ§ИќаТ
W1 += -step_size * dW1
b1 += -step_size * db1
W2 += -step_size * dW2
b2 += -step_size * db2 |
етбљЮвУЧОЭЕУЕНСЫвЛзщаТЕФВЮЪ§ЃЌВЂЧвгІгУетзщаТВЮЪ§ЕФЩёОЭјТчЕФЪфГіНЋЛсИќМгЗћКЯецЪЕЧщПіЁЃЮвУЧНЋШЋВПЩЯЪіДњТыЗХдквЛИібЛЗжаЃЌбЛЗжДаа10000ДЮЁЃетбљЃЌЮвУЧЕФВЮЪ§ОЭИќаТСЫ10000ДЮЃЌЪЙЕУЩёОЭјТчЕФЪфГіЯђецЪЕЧщПіППНќСЫвЛЭђВНЁЃ
ВтЪдзМШЗЖШ
# МЦЫудкЪ§ОнМЏЩЯЕФРрБ№дЄВтОЋЖШ
hidden_layer = np.maximum(0, np.dot(X, W) + b)
scores = np.dot(hidden_layer, W2) + b2
predicted_class = np.argmax(scores, axis=1)
print('training accuracy: %.2f' % (np.mean(predicted_class
== y))) |
ЕБЮвУЧНЋ300ИібљБОЕуЕФЬиеїОиеѓЪфШыЕНЩёОЭјТчжаЃЌЩёОЭјТчЖд300ИібљБОЕуЕФЫљЪєРрБ№НјаадЄВтЁЃНЋдЄВтНсЙћгыецЪЕЧщПіБШЖдЃЌзюжеЪфГіе§ШЗТЪЮЊ98%ЁЃвВОЭЪЧЫЕ300ИібљБОЕужаЃЌЩёОЭјТче§ШЗдЄВтСЫЦфжа98%ИібљБОЕуЕФРрБ№ЁЃ
|









