| БрМЭЦМі: |
БОЮФНЋЖдAutoMLжаЕФздЖЏЛЏЬиеїЙЄГЬФЃПщЕФЯжзДеЙПЊНщЩм,НщЩмAutoMLжаЕФММЪѕЗНАИЃЌЯЃЭћЖдФњЕФбЇЯАгжЫљАяжњЁЃ
БОЮФРДздгкВЉПЭдАЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
1. в§бд
ИіШЫвдЮЊЃЌЛњЦїбЇЯАЪЧГЏзХИќИпЕФвзгУадЁЂИќЕЭЕФММЪѕУХМїЁЂИќУєНнЕФПЊЗЂГЩБОЕФЗНЯђШЅЗЂеЙЃЌЧвAutoMLЛђепAutoDLЕФЗЂеЙЮовЩЪЧзюКУЕФжЄУїЁЃвђДЫЛЈЗбвЛаЉЪБМфбЇЯАСЫНтСЫAutoMLСьгђЕФвЛаЉжЊЪЖЃЌВЂЖдAutoMLжаЕФММЪѕЗНАИНјааЙщФЩећРэЁЃ
жкЫљжмжЊЃЌвЛИіЭъећЕФЛњЦїбЇЯАЯюФППЩИХРЈЮЊШчЯТЫФИіВНжшЁЃ

ЦфжаЃЌЬиеїЙЄГЬЃЈЬсШЁЃЉЭљЭљЪЧОіЖЈФЃаЭадФмЕФзюЙиМќвЛВНЁЃЖјЭљЭљЛњЦїбЇЯАжазюКФЪБЕФВПЗжвВе§ЪЧЬиадЙЄГЬКЭГЌВЮЪ§ЕїгХЁЃвђДЫЃЌаэЖрФЃаЭгЩгкЪБМфЯожЦЖјЙ§дчЕиДгЪЕбщНзЖЮзЊвЦЕНЩњВњНзЖЮДгЖјЕМжТВЂВЛЪЧзюгХЕФЁЃ
здЖЏЛЏЛњЦїбЇЯА(AutoML)ПђМмжМдкМѕЩйЫуЗЈЙЄГЬЪІУЧЕФИКЕЃЃЌвдБугкЫћУЧПЩвддкЬиеїЙЄГЬКЭГЌВЮЪ§ЕїгХЩЯЛЈИќЩйЕФЪБМфЃЌЖјдкФЃаЭЩшМЦЩЯЛЈИќЖрЕФЪБМфНјааГЂЪдЁЃ

БОЮФНЋЖдAutoMLжаЕФздЖЏЛЏЬиеїЙЄГЬФЃПщЕФЯжзДеЙПЊНщЩмЃЌвдЯТЪЧФПЧАжїСїЕФгаЙиAUTOMLЕФПЊдДАќЁЃ
2. ЪВУДЪЧздЖЏЛЏЬиеїЙЄГЬЃП
здЖЏЛЏЬиеїЙЄГЬжМдкЭЈЙ§ДгЪ§ОнМЏжаздЖЏДДНЈКђбЁЬиеїЃЌЧвДгжабЁдёШєИЩзюМбЬиеїНјаабЕСЗЕФвЛжжЗНЪНЁЃ
3. здЖЏЛЏЬиеїЙЄГЬЙЄОпАќ
3.1 Featuretools
FeaturetoolsЪЙгУвЛжжГЦЮЊЩюЖШЬиеїКЯГЩЃЈDeep Feature SynthesisЃЌDFSЃЉЕФЫуЗЈЃЌИУЫуЗЈБщРњЭЈЙ§ЙиЯЕЪ§ОнПтЕФФЃЪНУшЪіЕФЙиЯЕТЗОЖЁЃЕБDFSБщРњетаЉТЗОЖЪБЃЌЫќЭЈЙ§гІгУгкЪ§ОнЕФВйзїЃЈАќРЈКЭЁЂЦНОљжЕКЭМЦЪ§ЃЉЩњГЩзлКЯЬиеїЁЃР§ШчЃЌЖдРДздИјЖЈзжЖЮclient_idЕФЪТЮёСаБэгІгУsumВйзїЃЌВЂНЋетаЉЪТЮёОлКЯЕНвЛИіСажаЁЃОЁЙметЪЧвЛИіЩюЖШВйзїЃЌЕЋИУЫуЗЈПЩвдБщРњИќЩюВуЕФЬиеїЁЃFeaturetoolsзюДѓЕФгХЕуЪЧЦфПЩППадКЭДІРэаХЯЂаЙТЉЕФФмСІЃЌЭЌЪБПЩвдгУРДЖдЪБМфађСаЪ§ОнНјааДІРэЁЃ
Р§згЃК
МйЩшгаШ§еХБэЃЌЗжБ№ЮЊclientsЁЂloansЁЂpaymentsЁЃ
clients ЃКгаЙиаХгУКЯзїЩчПЭЛЇЕФЛљБОаХЯЂБэЁЃУПИіПЭЛЇЖЫдкДЫЪ§ОнПђжажЛгавЛааЁЃ
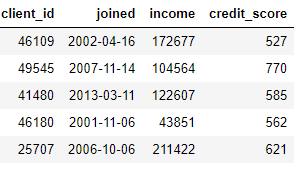
loansЃКЯђПЭЛЇЬсЙЉЕФДћПюБэЁЃУПБЪДћПюдкДЫЪ§ОнПђжажЛгаздМКЕФааЃЌЕЋПЭЛЇПЩФмгаЖрБЪДћПюЁЃ
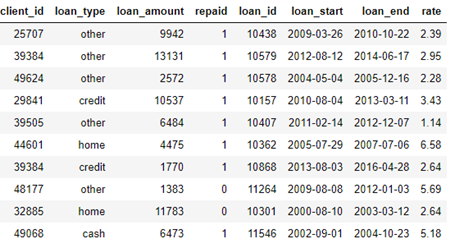
paymentsЃКДћПюГЅЛЙБэЁЃУПБЪИЖПюжЛгавЛааЃЌЕЋУПБЪДћПюЖМгаЖрБЪИЖПюЁЃ
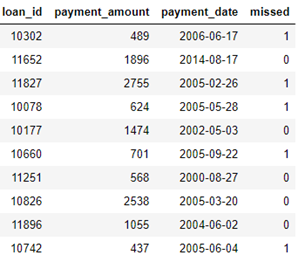
вдУПИіclient_idЮЊЖдЯѓЙЙдьЬиеїЃК
ДЋЭГЕФЬиеїЙЄГЬЗНАИЪЧРћгУPandasЖдЫљашЬиеїзіДІРэЃЌР§ШчЯТБэжаЕФЛёШЁдТЗнЁЂЪеШыжЕЕФЖдЪ§ЁЃ
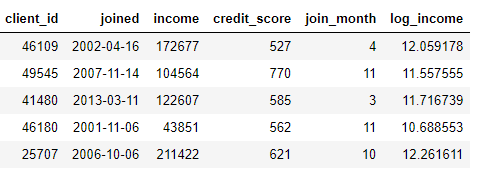
ЭЌЪБЃЌвВПЩвдЭЈЙ§гыloansБэЙиСЊЛёШЁаТЕФЬиеїЃЈУПИіclientЦНОљДћПюЖюЖШЁЂзюДѓДћПюЖюЖШЕШЃЉЁЃ
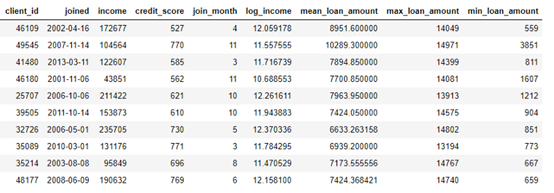
ЖјFeaturetoolsЭЈЙ§ЛљгквЛжжГЦЮЊЁА ЩюЖШЬиеїКЯГЩ ЁБЕФЗНЗЈЃЌМДЭЈЙ§ЖбЕўЖрИіЬиеїРДЭъГЩЬиеїЙЄГЬЁЃ
ЩюЖШЬиеїКЯГЩЖбЕўЖрИізЊЛЛКЭОлКЯВйзїЃЈдкЬиеїЙЄОпЕФДЪЛужаГЦЮЊЬиеїЛљдЊЃЉЃЌвдЭЈЙ§ЗжВМдкаэЖрБэжаЕФЪ§ОнДДНЈЬиеїЁЃ
FeaturetoolsгаСНИіжївЊИХФюЃК
ЕквЛИіЪЧentitiesЃЌЫќПЩБЛЪгЮЊЕЅИіБэЁЃ
ЕкЖўИіЪЧentitysetЃЌЫќЪЧЪЕЬх(Бэ)ЕФМЏКЯЃЌвдМАгУРДБэЪОЪЕЬхжЎМфЕФЙиЯЕЁЃ
ЪзЯШЃЌашвЊДДНЈвЛИіДцЗХЫљгаЪ§ОнБэЕФПеЪЕЬхМЏЖдЯѓЃК
import featuretools
as ft
es = ft.EntitySet(id='clients') |
ЯждкашвЊЬэМгЪЕЬхЃКУПИіЪЕЬхЖМБиаыгавЛИіЫїв§ЃЌЫїв§ЪЧгЩЪЕЬхжаОпгаЮЈвЛдЊЫижЕЕФСаЙЙГЩЁЃвВОЭЪЧЫЕЃЌЫїв§жаЕФУПИіжЕБиаыжЛГіЯждкБэжавЛДЮЁЃ
es = es.entity_from_dataframe(entity_id='clients',
dataframe=clients,
index='client_id', time_index='joined')
es = es.entity_from_dataframe(entity_id='loans',
dataframe=loans,
index='loans_id', time_index='joined') |
ЖјЖдгкУЛгаЮЈвЛЫїв§ЕФБэЃКашвЊДЋШыВЮЪ§make_index = TrueВЂжИЖЈЫїв§ЕФУћГЦЁЃ
ДЫЭтЃЌЫфШЛfeaturetoolsЛсздЖЏЭЦЖЯЪЕЬхжаУПИіСаЕФЪ§ОнРраЭЃЌЕЋШдПЩвдЭЈЙ§НЋСаРраЭЕФзжЕфДЋЕнИјВЮЪ§variable_typesРДжиаТЖЈвхЪ§ОнРраЭЁЃР§ШчЖдЁАmissedЁБзжЖЮЮвУЧЖЈвхЮЊРрБ№аЭБфСПЁЃ
es = es.entity_from_dataframe(entity_id='payments',
dataframe=payments,
variable_types={'missed': ft.variable_types.Categorical},
make_index=True, index='payment_id', time_index='payment_date') |
дкжДааОлКЯМЦЫуЪБЃЌвЊдкfeaturetoolsжажИЖЈБэжЎМфЕФЙиЯЕЪБЃЌжЛашжИЖЈНЋСНИіБэЙиСЊдквЛЦ№ЕФЬиеїзжЖЮЁЃclientsКЭloansБэЭЈЙ§client_idзжЖЮЙиСЊЃЌloansКЭpaymentsЭЈЙ§loan_idзжЖЮЙиСЊЁЃ
ДДНЈБэжЎМфЙиЯЕВЂНЋЦфЬэМгЕНentitysetЕФДњТыШчЯТЫљЪОЃК
# 'clients'БэгыloansБэЙиСЊ
r_client_previous = ft.Relationship(es['clients']['client_id'],
es['loans']['client_id'])
# НЋЙиЯЕЬэМгЕНЪЕЬхМЏ
es = es.add_relationship(r_client_previous)
# loansБэгыpaymentsБэЙиСЊ
r_payments = ft.Relationship(es['loans']['loan_id'],
es['payments']['loan_id'])
# НЋЙиЯЕЬэМгЕНЪЕЬхМЏ
es = es.add_relationship(r_payments) |
дкЬэМгЪЕЬхКЭаЮЪНЛЏЙиЯЕжЎКѓЃЌentitysetОЭЭъГЩСЫЁЃ
ашвЊзЂвтЃЌfeaturetools ЪЧЭЈЙ§вдЯТСНжжВйзїНјааЬиеїЙЙдьЃК
Aggregations:ЗжзщОлКЯ
Transformations:СажЎМфМЦЫу
дк featuretools жаЃЌПЩвдЪЙгУетаЉдгяздааДДНЈаТЬиадЃЌвВПЩвдНЋЖрИідгяЕўМгдквЛЦ№ЁЃЯТУцЪЧfeaturetoolsжаЕФвЛаЉЙІФмдгяСаБэЃК
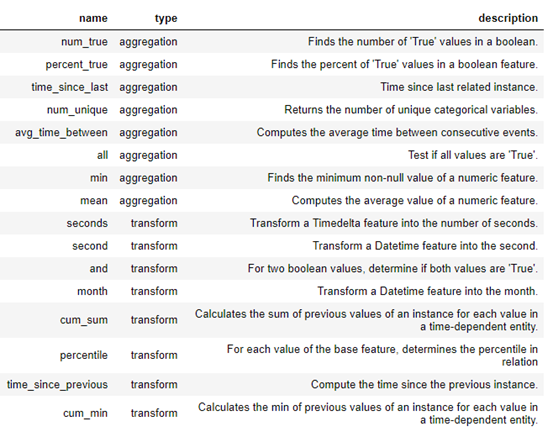
ДЫЭтЃЌЮвУЧвВПЩвдЖЈвхздЖЈвхдгя
НгЯТРДЪЧНјааЬиеїЙЙдьЃЌетвВЪЧздЖЏЛЏЬиеїЙЄГЬжазюживЊЕФвЛВНЃК
features, feature_names
= ft.dfs(entityset=es, target_entity='clients',
agg_primitives=['mean', 'max', 'percent_true',
'last'],
trans_primitives=['years', 'month', 'subtract',
'divide']) |
ЕБШЛЃЌвВПЩвдШУ featuretools здЖЏЮЊЮвУЧбЁдёЬиеїЃК
| features, feature_names
= ft.dfs(entityset=es, target_entity='clients',
max_depth=2) |
3.2 Boruta
BorutaжївЊЪЧгУРДНјааЬиеїбЁдёЁЃЫљвдбЯИёвтвхЩЯЃЌBorutaВЂВЛЪЧЮвУЧЫљашвЊЕФздЖЏЛЏЬиеїЙЄГЬАќЁЃ
Boruta-pyЪЧbroutaЬиеїдММђВпТдЕФвЛжжЪЕЯжЃЌдкИУВпТджаЃЌЮЪЬтвдвЛжжЭъШЋЯрЙиЕФЗНЪНЙЙНЈЃЌЫуЗЈБЃСєЖдФЃаЭгаЯджјЙБЯзЕФЫљгаЬиеїЁЃетгыаэЖрЬиеїдММђЫуЗЈЫљгІгУЕФзюаЁзюгХЬиеїМЏЯрЗДЁЃborutaЗНЗЈЭЈЙ§ДДНЈгЩФПБъЬиеїЕФЫцЛњжиХХађжЕзщГЩЕФКЯГЩЬиеїРДШЗЖЈЬиеїЕФживЊадЃЌШЛКѓдкдЪМЬиеїМЏЕФЛљДЁЩЯбЕСЗвЛИіМђЕЅЕФЛљгкЪїЕФЗжРрЦїЃЌдкетИіЗжРрЦїжаЃЌФПБъЬиеїБЛКЯГЩЬиеїЫљЬцДњЁЃЫљгаЬиадЕФадФмВювьгУгкМЦЫуЯрЖдживЊадЁЃ
BorutaКЏЪ§ЭЈЙ§бЛЗЕФЗНЪНЦРМлИїБфСПЕФживЊадЃЌдкУПвЛТжЕќДњжаЃЌЖддЪМБфСПКЭгАзгБфСПНјааживЊадБШНЯЁЃШчЙћдЪМБфСПЕФживЊадЯджјИпгкгАзгБфСПЕФживЊадЃЌдђШЯЮЊИУдЪМБфСПЪЧживЊЕФЃЛШчЙћдЪМБфСПЕФживЊадУїЯдЕЭгкгАзгБфСПЕФживЊадЃЌдђШЯЮЊИУдЪМБфСПЪЧВЛживЊЕФЁЃЦфжаЃЌдЪМБфСПОЭЪЧЮвУЧЪфШыЕФвЊНјааЬиеїбЁдёЕФБфСПЃЛгАзгБфСПОЭЪЧИљОндЪМБфСПЩњГЩЕФБфСП
ЩњГЩЙцдђЪЧЃК
ЯШЯђдЪМБфСПжаМгШыЫцЛњИЩШХЯюЃЌетбљЕУЕНЕФЪЧРЉеЙКѓЕФБфСП
ДгРЉеЙКѓЕФБфСПжаНјааГщбљЃЌЕУЕНгАзгБфСП
ЪЙгУpythonРДЪЕЯжгАзгЬиеїЃЌРрЫЦгкЃК
# ДгбЕСЗЪ§ОнМЏЛёШЁЬиеї
z = train_df[f].values
# Shuffle
np.random.shuffle(z)
# гАзгЬиеї
train_df[f + "shadow"] = z |
ЯТУцЪЧBorutaЫуЗЈдЫааЕФВНжшЃК
ЪзЯШЃЌЫќЭЈЙ§ДДНЈЛьКЯЪ§ОнЕФЫљгаЬиеїЃЈМДгАзгЬиеїЃЉЮЊИјЖЈЕФЪ§ОнМЏдіМгСЫЫцЛњадЁЃ
ШЛКѓЃЌЫќбЕСЗвЛИіЫцЛњЩСжЗжРрЕФРЉеЙЪ§ОнМЏЃЌВЂВЩгУвЛИіЬиеїживЊадДыЪЉЃЈФЌШЯЩшЖЈЮЊЦНОљМѕЩйОЋЖШЃЉЃЌвдЦРЙРЕФУПИіЬиеїЕФживЊадЃЌдНИпдђвтЮЖзХдНживЊЁЃ
дкУПДЮЕќДњжаЃЌЫќМьВщвЛИіецЪЕЬиеїЪЧЗёБШзюКУЕФгАзгЬиеїОпгаИќИпЕФживЊадЃЈМДИУЬиеїЪЧЗёБШзюДѓЕФгАзгЬиеїЕУЗжИќИпЃЉВЂЧвВЛЖЯЩОГ§ЫќЪгЮЊЗЧГЃВЛживЊЕФЬиеїЁЃ
зюКѓЃЌЕБЫљгаЬиеїЕУЕНШЗШЯЛђОмОјЃЌЛђЫуЗЈДяЕНЫцЛњЩСждЫааЕФвЛИіЙцЖЈЕФЯожЦЪБЃЌЫуЗЈЭЃжЙЁЃ
3.3 tsfresh
tsfreshЪЧЛљгкПЩЩьЫѕМйЩшМьбщЕФЪБМфађСаЬиеїЬсШЁЙЄОпЁЃИУАќАќКЌЖржжЬиеїЬсШЁЗНЗЈКЭТГАєЬиеїбЁдёЫуЗЈЁЃ
tsfreshПЩвдздЖЏЕиДгЪБМфађСажаЬсШЁ100ЖрИіЬиеїЁЃетаЉЬиеїУшЪіСЫЪБМфађСаЕФЛљБОЬиеїЃЌШчЗхжЕЪ§СПЁЂЦНОљжЕЛђзюДѓжЕЃЌЛђИќИДдгЕФЬиеїЃЌШчЪБМфЗДзЊЖдГЦадЭГМЦСПЕШЁЃ
етзщЬиеїПЩвдгУРДдкЪБМфађСаЩЯЙЙНЈЭГМЦЛђЛњЦїбЇЯАФЃаЭЃЌР§ШчдкЛиЙщЛђЗжРрШЮЮёжаЪЙгУЁЃ
ЪБМфађСаЭЈГЃАќКЌдыЩљЁЂШпгрЛђЮоЙиаХЯЂЁЃвђДЫЃЌДѓВПЗжЬсШЁГіРДЕФЬиеїЖдЕБЧАЕФЛњЦїбЇЯАШЮЮёУЛгагУДІЁЃЮЊСЫБмУтЬсШЁВЛЯрЙиЕФЬиадЃЌtsfreshАќгавЛИіФкжУЕФЙ§ТЫЙ§ГЬЁЃетИіЙ§ТЫЙ§ГЬЦРЙРУПИіЬиеїЖдгкЪжЭЗЕФЛиЙщЛђЗжРрШЮЮёЕФНтЪЭФмСІКЭживЊадЁЃЫќНЈСЂдкЭъЩЦЕФМйЩшМьбщРэТлЕФЛљДЁЩЯЃЌВЩгУСЫЖржжМьбщЗНЗЈЁЃ
ашвЊзЂвтЕФЪЧЃЌдкЪЙгУtsfreshЬсШЁЬиеїЪБЃЌашвЊЬсЧААбНсЙЙНјаазЊЛЛЃЌвЛАуЩЯашзЊЛЛЮЊ(None,2)ЕФНсЙЙЃЌР§ШчЯТЭМЫљЪОЃК
Р§згЃК
import matplotlib.pylab
as plt
from tsfresh import extract_features, select_features
from tsfresh.utilities.dataframe_functions import
impute
from tsfresh.feature_extraction import ComprehensiveFCParameters
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import pandas as pd
import numpy as np
if __name__ == '__main__':
N = 500
df = pd.read_csv('UCI HAR Dataset/train/Inertial
Signals/body_acc_x_train.txt', delim_whitespace=True,
header=None)
y = pd.read_csv('UCI HAR Dataset/train/y_train.txt',
delim_whitespace=True, header=None, squeeze=True)[:N]
# plt.title('accelerometer reading')
# plt.plot(df.ix[0, :])
# plt.show()
#
extraction_settings = ComprehensiveFCParameters()
master_df = pd.DataFrame({'feature': df[:N].values.flatten(),
'id': np.arange(N).repeat(df.shape[1])})
# ЪБМфађСаЬиеїЙЄГЬ
X = extract_features(timeseries_container=master_df,
n_jobs=0, column_id='id', impute_function=impute,
default_fc_parameters=extraction_settings)
X_train, X_test, y_train, y_test = train_test_split(X,
y, test_size=0.2)
cl = DecisionTreeClassifier()
cl.fit(X_train, y_train)
print(classification_report(y_test, cl.predict(X_test)))
# ЮДНјааЪБМфађСаЬиеїЙЄГЬ
X_1 = df.ix[:N - 1, :]
X_train, X_test, y_train, y_test = train_test_split(X_1,
y, test_size=.2)
cl = DecisionTreeClassifier()
cl.fit(X_train, y_train)
print(classification_report(y_test, cl.predict(X_test))) |
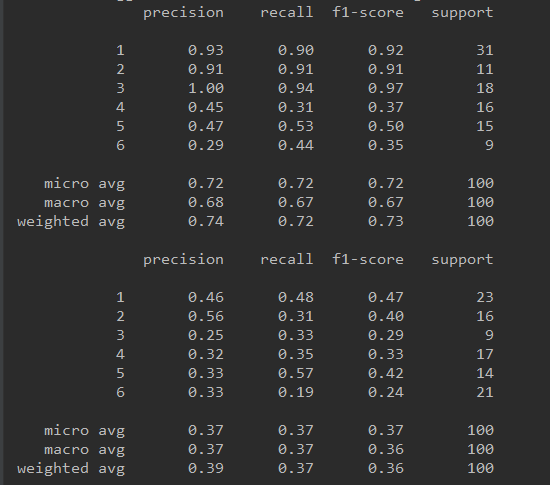
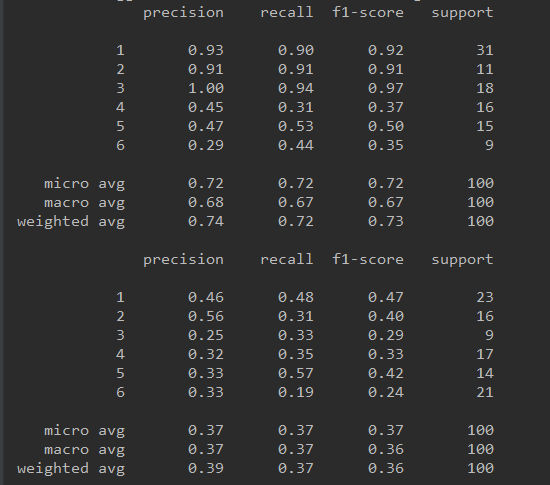
ДЫЭтЃЌЖдгкНјааЪБМфађСаЬиеїЙЄГЬКѓЕФЪ§ОнМЏНјааЬиеїбЁдёЃЌНјвЛВНЬсИпФЃаЭжИБъЁЃ
етРяЃЌПЩвдРћгУtsfresh.select_featuresЗНЗЈНјааЬиеїбЁдёЃЌШЛЖјгЩгкЦфНіЪЪгУгкЖўНјжЦЗжРрЛђЛиЙщШЮЮёЃЌЫљвдЖдгк6ИіБъЧЉЕФЖрЗжРрЃЌЮвУЧНЋЖрЗжРрЮЪЬтзЊЛЛЮЊ6ИіЖўдЊЗжРрЮЪЬтЃЌЙЪЖдгкУПвЛжжЗжРрЃЌЖМПЩвдЭЈЙ§ЖўЗжРрНјааЬиеїбЁдёЃК
relevant_features
= set()
for label in y.unique():
y_train_binary = y_train == label
X_train_filtered = select_features(X_train, y_train_binary)
print("Number of relevant features for class
{}: {}/{}".format(label, X_train_filtered.shape[1],
X_train.shape[1]))
relevant_features = relevant_features.union(set(X_train_filtered.columns))
X_train_filtered = X_train[list(relevant_features)]
X_test_filtered = X_test[list(relevant_features)]
cl = DecisionTreeClassifier()
cl.fit(X_train_filtered, y_train)
print(classification_report(y_test, cl.predict(X_test_filtered))) |
зЂвтЃКдкWindowsПЊЗЂЛЗОГЯТЃЌЛсХзГіЁАThe "freeze_support()"
line can be omitted if the program is not going to
be frozen to produce an executable.ЁБЖрНјГЬЕФДэЮѓЃЌЕМжТЮоЯобЛЗЃЌНтОіЗНЗЈЪЧдкДњТыжДааЪБв§ШыЁБ
if __name__ == '__main__ЁЏЃКЁА ЁЃПЩВЮПМЃК https://github.com/blue-yonder/tsfresh/issues/185
ЁЃ
вдЯТЪЧЗжБ№ЪЙгУtsfreshНјааЬиеїЙЄГЬЁЂЮДНјааЬиеїЙЄГЬвдМАЪЙгУtsfreshНјааЬиеїЙЄГЬ+ЬиеїбЁдёКѓЕФФЃаЭаЇЙћЃК
4. змНс
здЖЏЛЏЬиеїЙЄГЬНтОіСЫЬиеїЙЙдьЕФЮЪЬтЃЌЕЋЭЌЪБвВВњЩњСЫСэвЛИіЮЪЬтЃКдкЪ§ОнСПвЛЖЈЕФЧАЬсЯТЃЌгЩгкВњЩњЙ§ЖрЕФЬиеїЃЌЭљЭљашвЊНјааЯргІЕФЬиеїбЁдёвдБмУтФЃаЭадФмЕФНЕЕЭЁЃЪТЪЕЩЯЃЌвЊБЃжЄФЃаЭадФмЃЌЦфЫљашЕФЪ§ОнСПМЖашвЊЫцзХЬиеїЕФЪ§СПГЪжИЪ§МЖдіГЄЁЃ |









