| БрМЭЦМі: |
БОЮФИХРЈЕиНщЩмCNNЕФЛљБОдРэ ЃЌВЂЭЈЙ§АЂРВЎзжФИЗжРрР§згОпЬхНщЩмЦфЪЕЯжЙ§ГЬЃЌРэТлгыЪЕМљЕФНсКЯЬхЁЃ
БОЮФРДздгкSegmentFaultЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
ЖдгкОэЛ§ЩёОЭјТчЃЈCNNЃЉЖјбдЃЌЯраХКмЖрЖСепВЂВЛФАЩњЃЌИУЭјТчНќФъРДдкДѓЖрЪ§СьгђЖМБэЯжгХвьЃЌгШЦфЪЧдкМЦЫуЛњЪгОѕСьгђжаЁЃЕЋЪЧКмЖрЙЄзїШЫдБПЩФмжБНгЕїгУЯрЙиЕФЩюЖШбЇЯАЙЄОпЯфДюНЈОэЛ§ЩёОЭјТчФЃаЭЃЌВЂВЛЧхГўЦфжаОпЬхЕФдРэЁЃБОЮФНЋМђЕЅНщЩмОэЛ§ЩёОЭјТчЃЈCNNЃЉЃЌЗНБуЖСепДѓЬхЩЯСЫНтЦфЛљБОдРэМАЪЕЯжЙ§ГЬЃЌБугкКѓајЙЄзїжаЕФЪЕМЪгІгУЁЃБОЮФНЋАДвдЯТЫГађеЙПЊЃК
1.СЫНтОэЛ§Вйзї
2.СЫНтЩёОЭјТч
3.Ъ§ОндЄДІРэ
4.СЫНтCNN
5.СЫНтгХЛЏЦї
6.РэНт ImageDataGenerator
7.НјаадЄВтВЂМЦЫузМШЗад
8.demo
ЪВУДЪЧОэЛ§ЃП
дкЪ§бЇЃЈгШЦфЪЧКЏЪ§ЗжЮіЃЉжаЃЌОэЛ§ЪЧЖдСНИіКЏЪ§ЃЈfКЭgЃЉЕФЪ§бЇдЫЫуЃЌвдВњЩњЕкШ§ИіКЏЪ§ЃЌИУКЏЪ§БэЪОвЛИіКЏЪ§ЕФаЮзДШчКЮБЛСэвЛИіаоИФЁЃЃЈРДдДЃКЮЌЛљАйПЦЃЉ
ДЫВйзїдкЖрИіСьгђЖМгагІгУЃЌШчИХТЪЁЂЭГМЦЁЂМЦЫуЛњЪгОѕЁЂздШЛгябдДІРэЁЂЭМЯёКЭаХКХДІРэЁЂЙЄГЬКЭЮЂЗжЗНГЬЁЃ
ИУВйзїдкЪ§бЇЩЯБэЪОЮЊЃК
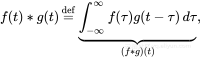
ОэЛ§Вйзї
ВщПДДЫСДНгвдИќМгжБЙлЕиСЫНтОэЛ§ВйзїЁЃ
ЪВУДЪЧШЫЙЄЩёОЭјТчЃП
ШЫЙЄЩёОЭјТчЃЈANNЃЉЛђСЌНгЯЕЭГЪЧгЩЙЙГЩЖЏЮяДѓФдЕФЩњЮяЩёОЭјТчФЃК§ЕиЦєЗЂЕФМЦЫуЯЕЭГЁЃетаЉЯЕЭГЭЈЙ§ДгЪОР§жаЁАбЇЯАЁБвджДааШЮЮёЃЌЭЈГЃВЛашвЊЪЙгУгУШЮКЮЬиЖЈЙцдђРДБрГЬЁЃЃЈРДдДЃКЮЌЛљАйПЦЃЉ
ШЫЙЄЩёОЭјТчЪЧвЛИіНЯаЁЕФДІРэЕЅдЊМЏКЯЃЌГЦЮЊШЫЙЄЩёОдЊЃЌЫќУЧгыЩњЮяЩёОдЊЯрЫЦЁЃ
ЩњЮяЩёОЛиТЗ
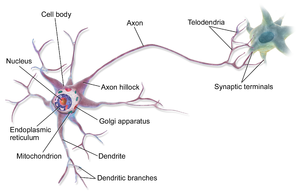
ЩёОдЊжЎМфЕФЛЅСЊЙЙГЩСЫвЛИіЭјТчФЃаЭ
ШЫЙЄЩёОЭјТч
ЯждкЃЌЮвУЧПЊЪМОпЬхЪЕЯжЁЃ
ЕМШыБивЊЕФЪ§ОнАќ
МгдиЪ§ОнМЏ

ДЫДІЪЙгУЕФЪ§ОнМЏЪЧЪжаДЪ§ОнМЏЁЃ
trainIamges.csvга1024СаКЭ13440ааЁЃУПСаБэЪОЭМЯёжаЕФЯёЫиЃЌУПааБэЪОвЛеХЕЅЖРЕФЛвЖШЭМЯёЁЃУПИіЯёЫиЕФШЁжЕЗЖЮЇЪЧ0ЕН255жЎМфЕФжЕЁЃ

ПЩЪгЛЏЪ§ОнМЏ
бЕСЗЪ§ОнМЏ

ВтЪдЪ§ОнМЏ


Ъ§ОндЄДІРэ
БрТыЗжРрБфСП
ЪВУДЪЧЗжРрБфСПЃП
дкЭГМЦбЇжаЃЌЗжРрБфСПЪЧвЛИіПЩвдГаЕЃЯожЦБфСПжЎвЛЕФБфСПЃЌЛљгкФГаЉЖЈадЪєадНЋУПИіИіЬхЛђЦфЫћЙлВьЕЅдЊЗжХфИјЬиЖЈзщЛђУћвхРрБ№ЁЃЃЈРДдДЃКЮЌЛљАйПЦЃЉ
МђЕЅРДЫЕЃЌЗжРрБфСПЕФжЕБэЪОРрБ№ЛђРрЁЃ
ЮЊЪВУДашвЊБрТыЗжРрБфСПЃП
жБНгЖдБэЪОРрБ№ЕФЪ§зжжДааВйзїУЛгавтвхЁЃвђДЫЃЌашвЊЖдЦфНјааЗжРрБрТыЁЃ
ЧыВщПДДЫСДНгвдСЫНтЗжРрБфСПЪОР§ЁЃ
АЂРВЎзжФИБэжага28ИізжФИЁЃвђДЫЃЌЪ§ОнМЏга28ИіРрБ№ЁЃ

БъзМЛЏ
ЪВУДЪЧБъзМЛЏЃП
НјааЙщвЛЛЏвдЪЙећИіЪ§ОнНјШыУїШЗЖЈвхЕФЗЖЮЇЃЌвЛАубЁдёЙщвЛЛЏЕН0ЕН1жЎМф
дкЩёОЭјТчжаЃЌВЛНівЊЖдЪ§ОнНјааБъзМЛЏЃЌЛЙвЊЖдЦфНјааБъСПЛЏЃЌетбљДІРэЕФФПЕФЪЧФмЙЛИќПьЕиНгНќДэЮѓБэУцЕФШЋОжзюаЁжЕЁЃЃЈРДдДЃКStackOverflowЃЉ

ЖдЦфНјааБфаЮВйзїЪЙЕУУПЬѕЪ§ОнБэЪОвЛИіЦНУцЭМЯё

АДЙІФмЛЎЗжЕФСужааФНЋУПИібљБОЕФжааФжУСуЃЌВЂжИЖЈЦНОљжЕЁЃШчЙћЮДжИЖЈЃЌдђЖдЫљгабљЦЗЦРЙРЦНОљжЕЁЃ
НЈСЂCNN
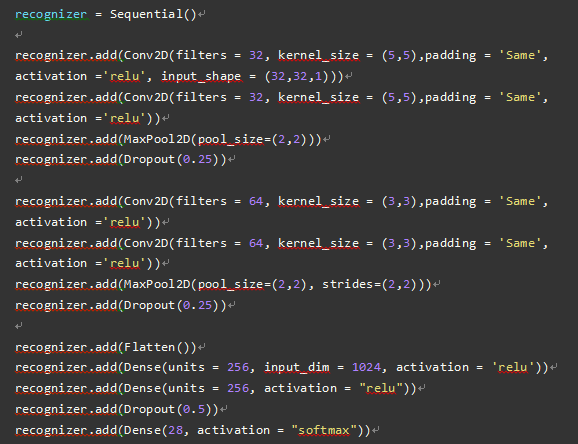
зюДѓГиЛЏЃЈMax PoolingЃЉЪЧЪВУДЃП
ГиЛЏвтЮЖзХзщКЯвЛзщЪ§ОнЃЌзщКЯЪ§ОнЕФЙ§ГЬжагІИУзёбвЛаЉЙцдђЁЃ
ИљОнЖЈвхЃЌзюДѓГиЛЏбЁШЁвЛзщЪ§ОнжаЕФзюДѓжЕзїЮЊЦфЪфГіжЕЁЃЃЈРДдДЃКmachinelearningonline.blogЃЉ
зюДѓГиЛЙПЩвдгУгкМѕаЁЬиеїЮЌЖШЃЌЫќЛЙПЩвдБмУтЙ§ФтКЯЕФЗЂЩњЁЃВщПДДЫВЉПЭЃЌвдБуИќКУЕиСЫНтMax PoolingЁЃ
ЪВУДЪЧDropoutЃП
DropoutЪЧвЛжже§дђЛЏММЪѕЃЌЭЈЙ§ЗРжЙЖдбЕСЗЪ§ОнНјааИДдгЕФаЭЌЪЪгІРДМѕЩйЩёОЭјТчжаЕФЙ§ФтКЯЃЌетЪЧЩёОЭјТчФЃаЭжаЪЎЗжгааЇЕФЗНЗЈжЎвЛЁЃЁАЖЊЪЇЁБжИЕФЪЧдкЩёОЭјТчжавдФГвЛИіИХТЪЫцЛњЕиЖЊЦњВПЗжЩёОЕЅдЊЁЃЃЈРДдДЃКЮЌЛљАйПЦЃЉ
ЪВУДЪЧFlattenЃП
ЖдЬиеїЭМНјааеЙЦНЃЌвдНЋЖрЮЌЪ§ОнзЊЛЛЮЊвЛЮЌЬиеїЯђСПЃЌвдЙЉЯТвЛВуЃЈУмМЏВуЃЉЪЙгУ
ЪВУДЪЧУмМЏВуЃП
УмМЏВужЛЪЧвЛВуШЫЙЄЩёОЭјТчЃЌвВБЛГЦзїШЋСЌНгВуЁЃ
CNNЕФгХЛЏЗНЗЈ
ЪВУДЪЧгХЛЏЃП
гХЛЏЫуЗЈАяжњЮвУЧзюаЁЛЏЃЈЛђзюДѓЛЏЃЉФПБъКЏЪ§ЃЌФПБъКЏЪ§жЛЪЧвЛИіЪ§бЇКЏЪ§ЃЌШЁОігкФЃаЭФкВППЩбЇЯАЕФВЮЪ§ЁЃФЃаЭжаЪЙгУдЄВтБфСПМЏЃЈXЃЉМЦЫуФПБъжЕЃЈYЃЉЁЃР§ШчЃЌЮвУЧНЋЩёОЭјТчЕФШЈжиЃЈWЃЉКЭЦЋВюЃЈbЃЉжЕГЦЮЊЦфФкВППЩбЇЯАВЮЪ§ЃЌгУгкМЦЫуЪфГіжЕЃЌВЂдкзюгХНтЕФЗНЯђЩЯбЇЯАКЭИќаТетаЉВЮЪ§ЃЌМДзюаЁЛЏЫ№ЪЇЭјТчЁЃетОЭЪЧЩёОЭјТчЕФбЕСЗЙ§ГЬЁЃЃЈРДдДЃКЪ§ОнПЦбЇЃЉ 
БОЮФдкетРяЪЙгУЕФгХЛЏЦїЪЧRMSpropЃЌЕуЛїДЫДІвдСЫНтгаЙиRMSpropЕФИќЖраХЯЂЁЃ

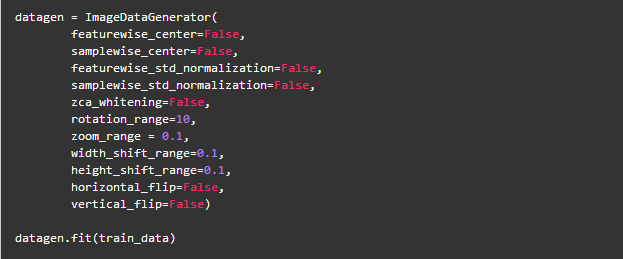
ЪВУДЪЧImageDataGeneratorЃП
ЕБФуЕФЪ§ОнМЏЙцФЃБШНЯаЁЪБЃЌФуПЩФмЛсгІгУЕНЭМЯёЪ§ОнЩњГЩЦїЃЌЫќгУгкЩњГЩОпгаЪЕЪБдіЧПЕФХњСПеХСПЭМЯёЪ§ОнЃЌРЉДѓЪ§ОнМЏЙцФЃЁЃвЛАуЖјбдЃЌЕБЪ§ОнСПдіЖрЪБЃЌФЃаЭадФмЛсЕУИќКУЁЃ
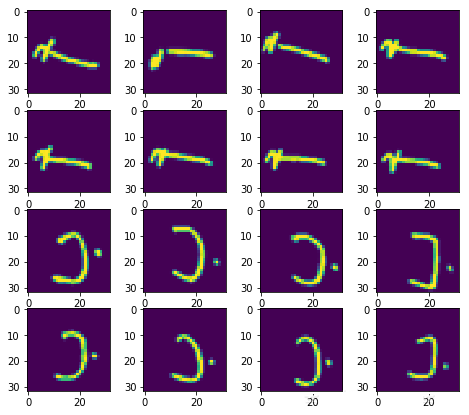
вдЯТДњТыгУгкХњСПМгдиЭМЯёЃК
CNNФтКЯбЕСЗЪ§Он

зіГідЄВт

ЩњГЩЛьЯ§Оиеѓ
ЪВУДЪЧЛьЯ§ОиеѓЃП
ЛьЯ§ОиеѓЪЧгУгкзмНсЗжРрЫуЗЈадФмЕФвЛжжММЪѕЁЃШчЙћУПИіРрБ№жаЕФЙлВьЪ§СПВЛЕШЃЌЛђепЪ§ОнМЏжагаСНИівдЩЯЕФРрЃЌЕЅЖРЕФЗжРрзМШЗадПЩФмЛсВњЩњЮѓЕМЁЃМЦЫуЛьЯ§ОиеѓПЩвдШУЮвУЧИќКУЕиСЫНтЗжРрФЃаЭЕФе§ШЗадвдМАЫќЫљЗИЕФДэЮѓРраЭЁЃРДдДЃКmachinelearningonline.blog

МЦЫузМШЗад

БОЮФЛёЕУСЫ97ЃЅЕФзМШЗЖШЃЌИааЫШЄЕФЖСепПЩвдздМКГЂЪдЯТЁЃ
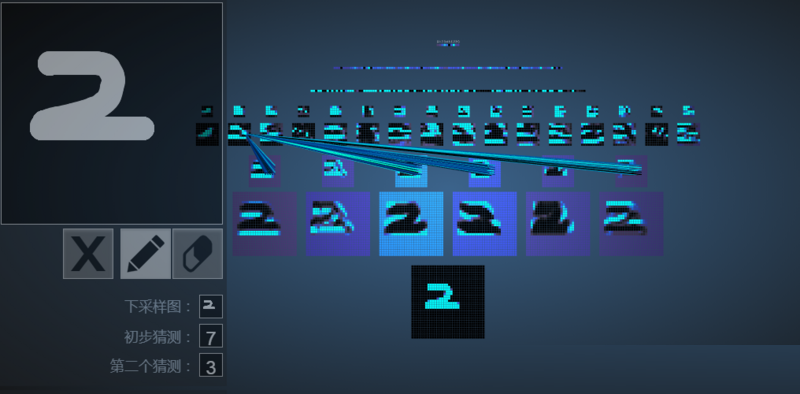
CNNЪжаДЪ§зжЪЖБ№demo
ЕуЛїДЫСДНгПЩвдЪЕЪБВщПДCNNЕФЙЄзїЧщПіЃЌИУdemoЯдЪОСЫCNNЕФЙЄзїЙ§ГЬЃЌвдМАУПВуЪфГіЕФЬиеїЭМЁЃзюКѓИУCNNЭјТчОЙ§бЕСЗКѓФмЙЛЪЖБ№ЪжаДЪ§зжЁЃ
|






