| БрМЭЦМі: |
ЮФеТИјДѓМвНщЩмгХауЕФЪ§ОндЄДІРэЃЌКЯЪЪЕФФЃаЭНсЙЙКЭЙІФм ЃЌгХауЕФбЕСЗВпТдКЭГЌВЮЪ§ЃЌКЯЪЪЕФКѓДІРэВйзїЃЌбЯИёЕФНсЙћЗжЮі
ЯЃЭћЖдФњгаЫљАяжњЁЃ
БОЮФРДздгкcsdnЃЌгЩЛ№СњЙћШэМўDeliresБрМЁЂЭЦМіЁЃ |
|
ЪВУДЪЧAutoMLЃП
ФПЧАвЛИігХауЕФЛњЦїбЇЯАКЭЩюЖШбЇЯАФЃаЭЃЌРыВЛПЊетМИИіЗНУцЃК
вЛЁЂгХауЕФЪ§ОндЄДІРэЃЛ
ЖўЁЂКЯЪЪЕФФЃаЭНсЙЙКЭЙІФмЃЛ
Ш§ЁЂгХауЕФбЕСЗВпТдКЭГЌВЮЪ§ЃЛ
ЫФЁЂКЯЪЪЕФКѓДІРэВйзїЃЛ
ЮхЁЂбЯИёЕФНсЙћЗжЮі
етМИЗНУцЖМЖдзюжеЕФНсЙћгазХОйзуЧсжиЕФгАЯьЃЌетвВЪЧФПЧАЕФЪ§ОнЙЄГЬЪІКЭбЇепУЧЕФжївЊЙЄзїЁЃЕЋгЩгкетУПвЛЗНУцЖМЪЎЗжЗБЫіЃЌгШЦфЪЧдкЙЙНЈФЃаЭКЭбЕСЗФЃаЭЩЯЁЃЖјДѓВПЗжЧщПіЯТЃЌетаЉЙЄзїгаЮоаыЙ§ЩюзЈвЕжЊЪЖОЭФмЪЙгУЦ№РДЁЃЫљвдAutoMLжївЊЕФзїгУОЭЪЧРДАяжњЪЕЯжИпаЇЕФФЃаЭЙЙНЈКЭГЌВЮЪ§ЕїећЁЃР§ШчЩюЖШбЇЯАЭјТчЕФМмЙЙЫбЫїЁЂГЌВЮЪ§ЕФживЊадЗжЮіЕШЕШЁЃЕБШЛAutoMLВЂВЛМђЕЅЕФНјааБЉСІЛђепЫцЛњЕФЫбЫїЃЌЦфШдШЛашвЊЛњЦїбЇЯАЗНУцЕФжЊЪЖЃЌР§ШчБДвЖЫЙгХЛЏЁЂЧПЛЏбЇЯАЁЂдЊбЇЯАвдМАЧЈвЦбЇЯАЕШЕШЁЃФПЧАвВгааЉВЛДэЕФAutoMLЙЄОпАќЃЌР§ШчAlex HoncharЕФHyperoptЁЂЮЂШэЕФNNIЁЂAutokerasЕШЁЃ
здЖЏЛЏГЌВЮЪ§ЫбЫїЕФЗНЗЈгаФФаЉЃП
ФПЧАздЖЏЛЏЫбЫїжївЊАќКЌЭјИёЫбЫїЃЌЫцЛњЫбЫїЃЌЛљгкФЃаЭЕФГЌВЮгХЛЏ
ЭјИёЫбЫїЃК
ЭЈГЃЕБГЌВЮЪ§СПНЯЩйЕФЪБКђЃЌПЩвдЪЙгУЭјИёЫбЫїЗЈЁЃМДСаГіУПИіГЌВЮЪ§ЕФДѓжТКђбЁМЏКЯЁЃРћгУетаЉМЏКЯ Нјааж№ЯюзщКЯгХЛЏЁЃдкЬѕМўдЪаэЕФЧщПіЯТЃЌжиИДНјааЭјИёЫбЫїЛсЕБгХауЃЌЕБШЛУПДЮжиИДашвЊИљОнЩЯвЛВНЕУЕНЕФзюгХВЮЪ§зщКЯЃЌНјааНјвЛВНЕФЯИСЃЖШЕФЕїећЁЃЭјИёЫбЫїзюДѓЕФЮЪЬтОЭдкгкМЦЫуЪБМфЛсЫцзХГЌВЮЪ§ЕФЪ§СПжИЪ§МЖЕФдіГЄЁЃ
ЫцЛњЫбЫїЃК
ЫцЛњЫбЫїЃЌЪЧвЛжжгУРДЬцДњЭјИёЫбЫїЕФЫбЫїЗНЪНЁЃЫцЛњЫбЫїгаБ№гкЭјИёЫбЫїЕФвЛЕудкгкЃЌЮвУЧВЛашвЊЩшЖЈвЛИіРыЩЂЕФГЌВЮЪ§МЏКЯЃЌЖјЪЧЖдУПИіГЌВЮЪ§ЖЈвхвЛИіЗжВМКЏЪ§РДЩњГЩЫцЛњГЌВЮЪ§ЁЃЫцЛњЫбЫїЯрБШгкЭјИёЫбЫїдквЛаЉВЛУєИаГЌВЮЩЯгЕгаУїЯдгХЪЦЁЃР§ШчЭјИёЫбЫїЖдгкХњбљБОЪ§СПЃЈbatch sizeЃЉЃЌдк[16,32,64]етаЉЗЖЮЇФкНјааж№ЯюЕїЪдЃЌетбљЕФЕїЪдЯдШЛЪевцИќЕЭЯТЁЃЕБШЛЫцЛњЫбЫївВПЩвдНјааЯИСЃЖШЗЖЮЇФкЕФжиИДЕФЫбЫїгХЛЏЁЃ
ЛљгкФЃаЭЕФГЌВЮгХЛЏЃК
гаБ№гкЩЯЪіСНжжЕФЫбЫїВпТдЃЌЛљгкФЃаЭЕФГЌВЮЕїгХЮЪЬтзЊЛЏЮЊСЫгХЛЏЮЪЬтЁЃжБОѕЩЯЛсПМТЧЪЧЗёНјаавЛИіПЩЕМНЈФЃЃЌШЛКѓРћгУЬнЖШЯТНЕНјаагХЛЏЁЃЕЋВЛавЕФЪЧЮвУЧЕФГЌВЮЪ§ЭЈГЃЧщПіЯТЪЧРыЩЂЕФЃЌЖјЧвЦфМЦЫуДњМлвРОЩКмИпЁЃ
ЛљгкФЃаЭЕФЫбЫїЫуЗЈЃЌзюГЃМћЕФОЭЪЧБДвЖЫЙГЌВЮгХЛЏЁЃгаБ№гкЕФЭјИёЫбЫїКЭЫцЛњЫбЫїЖРСЂгкЧАМИДЮЫбЫїНсЙћЕФЫбЫїЃЌБДвЖЫЙдђЪЧРћгУРњЪЗЕФЫбЫїНсЙћНјаагХЛЏЫбЫїЁЃЦфжївЊгаЫФВПЗжзщГЩЃЌ1.ФПБъКЏЪ§ЃЌДѓВПЗжЧщПіЯТОЭЪЧФЃаЭбщжЄМЏЩЯЕФЫ№ЪЇЁЃ2ЁЂЫбЫїПеМфЃЌМДИїРрД§ЫбЫїЕФГЌВЮЪ§ЁЃ3ЁЂгХЛЏВпТдЃЌНЈСЂЕФИХТЪФЃаЭКЭбЁдёГЌВЮЪ§ЕФЗНЪНЁЃ4ЁЂРњЪЗЕФЫбЫїНсЙћЁЃЪзЯШЖдЫбЫїПеМфНјаавЛИіЯШбщадЕФМйЩшВТЯыЃЌМДМйЩшвЛжжбЁдёГЌВЮЕФЗНЪНЃЌШЛКѓВЛЖЯЕФгХЛЏИќаТИХТЪФЃаЭЃЌзюжеЕФФПБъЪЧевЕНбщжЄМЏЩЯЮѓВюзюаЁЕФвЛзщГЌВЮЪ§ЁЃ
AutoML for Image Classification
We already have many good solutions for image classificaiton. Inception, ResnetЁWhy use AutoML?
ШчЙћПЩвдЭЈЙ§здЖЏЫбЫїЃЌевЕНБШШЫРрЩшМЦЕФзюКУЫуЗЈЛЙКУЕФЫуЗЈЃЌФЧУДЫЕУїетвЛСьгђЕФбаОПМлжЕЁЃ
ЭМЯёЗжРрШЮЮёвбОБЛКмКУбЇЯАСЫЃЌAutoMLвдДЫЮЊЦ№ЕуИќМгКЯЪЪЁЃ
NASЃЈNeural Architecture SearchЃЉOne example of AutoML
NASМђНщ
Neural Architecture SearchЛљБОзёбетбљвЛИібЛЗЃКЪзЯШЃЌЛљгквЛаЉВпТдЙцдђДДдьМђЕЅЕФЭјТчЃЌШЛКѓЖдЫќбЕСЗВЂдквЛаЉбщжЄМЏЩЯНјааВтЪдЃЌзюКѓИљОнЭјТчадФмЕФЗДРЁРДгХЛЏетаЉВпТдЙцдђЃЌЛљгкетаЉгХЛЏКѓЕФВпТдРДЖдЭјТчВЛЖЯНјааЕќДњИќаТЁЃ
ЪЙгУЧПЛЏбЇЯА
жЎЧАЕФNASЙЄзїПЩвдДѓжТЗжЮЊСНЗНУцЃЌЪзЯШЪЧЧПЛЏбЇЯАЃЌдкЩёОНсЙЙЫбЫїжаашвЊбЁдёКмЖрЕФдЊЫиЃЌШчЪфШыВуКЭВуВЮЪ§ЃЈБШШчбЁдёКЫЮЊ3ЛЙЪЧ5ЕФОэЛ§ВйзїЃЉЕФЩшжУЃЌЩшМЦећИіЩёОЭјТчЕФЙ§ГЬПЩвдПДзївЛЯЕСаЕФЖЏзїЃЌЖЏзїЕФНБЩЭОЭЪЧдкбщжЄМЏЩЯЕФЗжРрзМШЗТЪЁЃЭЈЙ§ВЛЖЯЖдЖЏзїИќаТЃЌЪЙжЧФмЬхбЇЯАЕНдНРДдНКУЕФЭјТчНсЙЙЃЌетбљЧПЛЏбЇЯАКЭNASОЭСЊЯЕЦ№РДСЫЁЃ
ЪЙгУвХДЋЫуЗЈ
СэвЛЗНУцNASЪЧвЛаЉНјЛЏЫуЗЈЃЌетвЛДѓРрЗНЗЈЕФжївЊЫМТЗЪЧЃЌгУвЛДЎЪ§ЖЈвхвЛИіЩёОЭјТчНсЙЙЁЃШчЭМЪЧICCV2017аЛСшъиВЉЪПЕФЙЄзїЃЌЫћгУвЛДЎЖўНјжЦТыЖЈвхвЛжжЙцдђРДБэДяЬиЖЈЕФЩёОЭјТчСЌНгЗНЪНЃЌзюПЊЪМЕФТыЪЧЫцЛњЕФЃЌДгетаЉЕуГіЗЂПЩвдзівЛаЉЭЛБфЃЌЩѕжСдкСНИіЪ§ДЎЃЈгЕгаНЯИпбщжЄзМШЗТЪЃЉжЎМфзіЭЛБфЃЌОЙ§вЛЖЮЪБМфОЭПЩвдЬсЙЉИќКУЕФЩёОЭјТчНсЙЙЁЃ
NASЕФШБЕу
ЫуСІвЊЧѓЬЋИпЃЁ
ТлЮФШЯЮЊЭјТчгЩаэЖрИіCellЙЙГЩЁЃЪзЯШЫбЫїПЩжиИДЕФcells(ПЩвдПДзїЪЧResidual block)ЃЌвЛЕЉевЕНвЛИіcellЃЌОЭПЩвдздгЩЕибЁдёЦфЕўМгЗНЪНЃЌаЮГЩвЛИіЭъећЕФЭјТч.
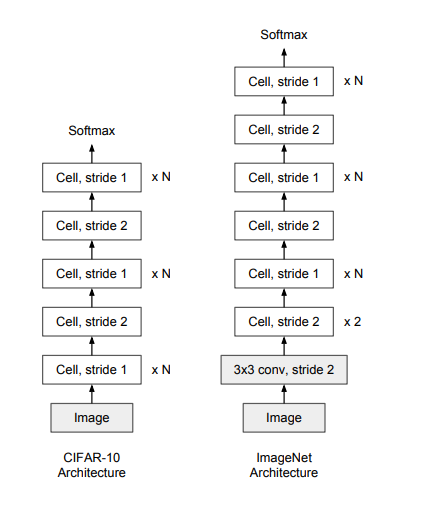
вЛИіЭјТчЭЈГЃгЩетШ§ИівЊЫиРДШЗЖЈЃКcellЕФНсЙЙЃЌcellжиИДЕФДЮЪ§NЃЌУПвЛИіcellжаЕФОэЛ§КЫИіЪ§FЃЌЮЊСЫПижЦЭјТчЕФИДдгЖШЃЌNКЭFЭЈГЃОЪжЙЄЩшМЦЁЃПЩвдРэНтЮЊЃЌNПижЦЭјТчЕФЩюЖШЃЌFПижЦЭјТчЕФПэЖШЁЃ

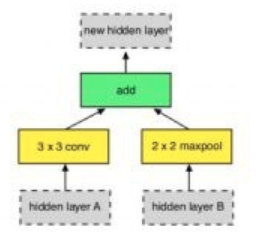
ЖдгкЛвЩЋЕФВПЗжЃЌЫќЪЧЪфШыЃЌПЩФмЪЧШ§жжРДдДЃК

ЖдгкЛЦЩЋЕФЗНПђЃЌМДO1,O2
етЦфЪЕЪЧЖдИеВХбЁШЁЕФвўКЌВуЕФвЛдЊдЫЫуЗћЃЌЫќАќКЌСЫ33ЕФОэЛ§ЃЌ55ЕФОэЛ§ЃЌ77ЕФОэЛ§ЃЌidentityЃЌ33ЕФОљжЕГиЛЏЃЌ33ЕФзюДѓжЕГиЛЏЃЌ33ЕФМгПэГиЛЏвдМА17КѓНг71ЕФОэЛ§ЁЃШУЪ§ОндкЫбЫїПеМфжабЇЯАевЕНзюЪЪКЯЕФВйзї

ЖдгкТЬЩЋЕФЗНПђ
ТЬЩЋПђДњБэCетИідЫЫуЃЌЫќАбгЩI1,I2
ВњЩњЕФO1,O2
ЭЈЙ§вЛЖЈЕФЗНЪНзщКЯЕНвЛЦ№ЃЌВњЩњвЛИіаТЕФвўКЌПеМфЁЃетИіCВйзїЪЧАДЮЛМгКЭЕФВйзї
Naive Algorithm
жБНгНјааЫбЫїЖдгквЛИіАќКЌЮхИіblockЕФcellЦфПЩФмЕФЫбЫїПеМфЮЊ
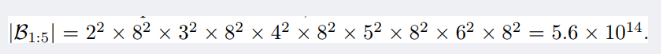
жЎЧАНщЩмЕФЮоТлЪЧЧПЛЏбЇЯАЛЙЪЧЛљгкНјЛЏЫуЗЈЃЌЖМЪЧжБНгЫбЫїЃЌетбљдкЫбЫїЪБЪЧЗЧГЃУдУЃЕФЁЃ
ЪзЯШбЕСЗЫљгаЕФ1-block cellsЃЌжЛга256ИіетбљЕФcellЁЃЫфШЛПЩвдЭЈЙ§УЖОйЕФЗНЪНЃЌЕЋадФмЛсКмЕЭЃЌвђЮЊжЛга1ИіblockЕФcellВЛШчАќКЌ5ИіblockЕФcellгааЇЁЃЕЋЪЧЃЌетВПЗжадФмаХЯЂПЩвдЮЊЪЧЗёМЬајВЩгУетИіcellЕФаХКХЬсЙЉИЈжњЃЌЛљгк1-block cellЕФБэЯжЃЌЮвУЧПЩвдГЂЪдЗЂЯжзюгаЯЃЭћЕФ2-block cellЃЌВЂЖдЦфНјаабЕСЗЃЌШчДЫЕќДњЃЌМДПЩЙЙНЈећИіЭјТчЁЃ
ЩЯУцЕФЯыЗЈПЩвдМђЕЅИХРЈЮЊвЛИіМђЕЅЕФЫуЗЈЃЌбЕСЗКЭЦРЙРЕБЧАгаbИіblocksЕФcellsЃЌШЛКѓИљОнЦфжазюКУЕФKИіcellsРДУЖОйb+1ИіblocksЃЌШЛКѓШЅбЕСЗКЭЦРЙРЁЃ
ЕЋЪЧЪЕМЪЩЯЃЌетИіЫуЗЈЪЧгаЮЪЬтЕФЃЌЖдгквЛИіКЯРэЕФ K(10^2)ЃЌашвЊбЕСЗЕФзгЭјТчОЭИпДя10^5 ИіЁЃетИідЫЫуСПвбОГЌЙ§СЫвдЭљЕФЗНЗЈЁЃвђДЫЃЌЮвУЧЬсГіСЫвЛИізМШЗТЪдЄВтЦїЃЌЫќПЩвдВЛгУбЕСЗКЭВтЪдЃЌЖјЪЧжЛЭЈЙ§ЙлВьЪ§ДЎЃЌОЭФмЦРЙРвЛИіФЃаЭЪЧЗёЪЧгаЧБСІЕФЁЃ
Progressive Neural Architecture Search
ЪЙгУвЛИіLSTMЭјТчРДзізМШЗТЪдЄВтЦїЃЌжЎЫљвдЪЙгУЫќЃЌЪЧвђЮЊдкВЛЭЌЕФblockжаПЩвдЪЙгУЭЌвЛИідЄВтЦїЁЃ
ЪзЯШбЕСЗВЂЦРЙРЕБЧАbИіblocksЕФKИіcellsЃЌШЛКѓЭЈЙ§етаЉЪ§ОнЕФБэЯжРДИќаТзМШЗТЪдЄВтЦїЃЌПЩвдЪЙзМШЗТЪдЄВтЦїИќОЋШЗЃЌНшжњдЄВтЦїЪЖБ№KИізюгаПЩФмЕФb+1ИіblockЁЃетбљбЇГіРДЕФНсЙћПЩФмВЛЪЧзюе§ШЗЕФЃЌЕЋШДЪЧвЛИіКЯРэЕФtrade-offНсЙћЁЃ
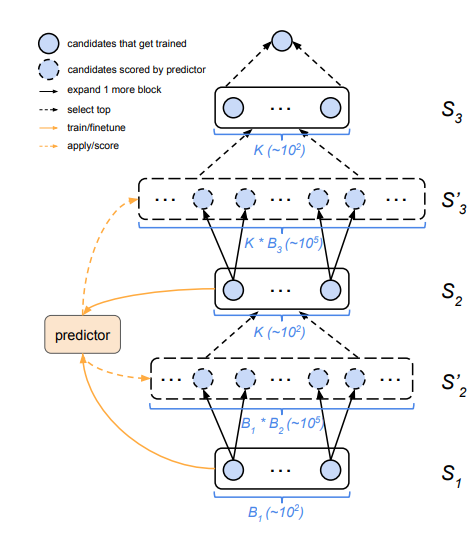
зюПЊЪМb=1ЃЌQ1ЪБга256ИіЭјТчЃЌЖдЫќШЋВПбЕСЗВтЪдЃЌШЛКѓгУетKИіЪ§ОнЕубЕСЗзМШЗТЪдЄВтЦїЁЃУЖОйQ1ЕФЫљгаКѓДњM1ЃЌВЂАбетИізМШЗТЪдЄВтЦїдЫгУдкM1ЕФУПИідЊЫиЩЯЃЌбЁГіЦфжазюКУЕФKИіЃЌМДЕУЕНСЫb=2ЪБЕФМЏКЯQ2ЁЃШЛКѓНЋb=2ЕФЭјТчНјаабЕСЗВтЪдЃЌОЙ§ЩЯЪіЯрЭЌЕФЙ§ГЬЃЌПЩвдЕУЕНQ3ЁЃQ3жазюКУЕФФЃаЭМДЮЊPNASЗЕЛиЕФНсЙћЁЃ
ЫуЗЈ

ЪЕбщ
ШчЭМЪЧзюКѓбЇЯАЕНЕФЭјТчНсЙЙЃЌПЩвдПДГіЃЌзюПЊЪМбЇЯАЕНЕФЪЧseparableКЭmax convolutionЕФзщКЯЃЌКѓУцНЅНЅбЇЯАЕНИќЖрЕФзщКЯЁЃ
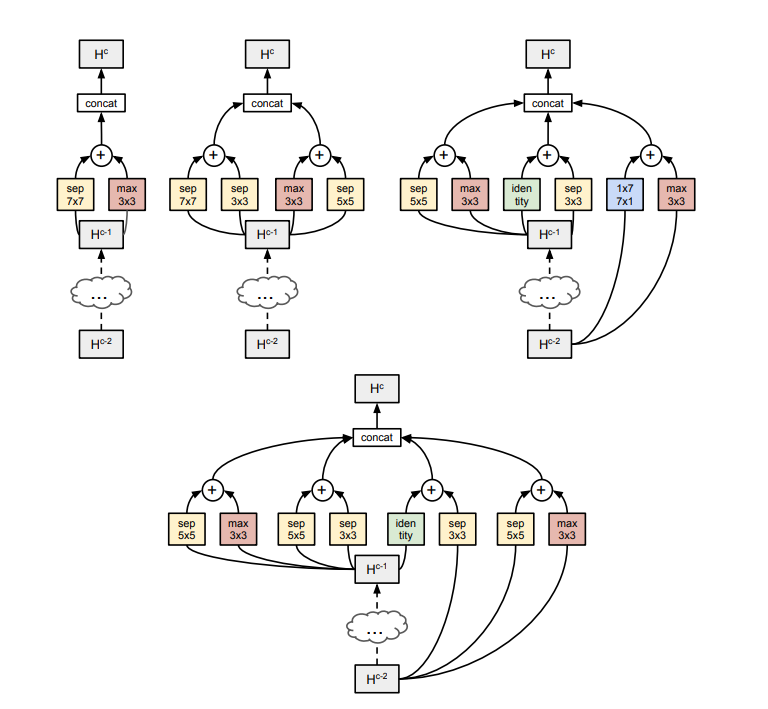
ImageNetЩЯЕФНсЙћ
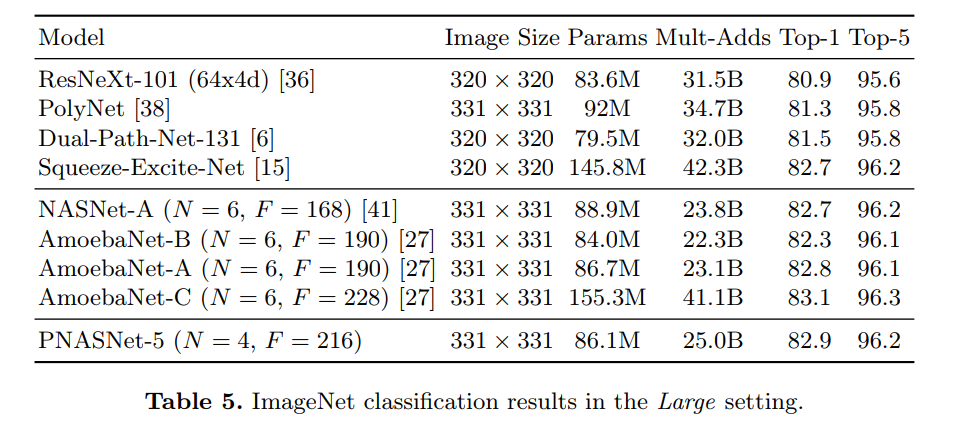
|









