| БрМЭЦМі: |
дкБОЮФжаЃЌНЋНщЩмвЛжжAutoMLЩшжУЃЌЪЙгУPythonЁЂFlaskдкдЦжабЕСЗКЭВПЪ№ЙмЕРЃЛвдМАСНИіПЩздЖЏЭъГЩЬиеїЙЄГЬКЭФЃаЭЙЙНЈЕФAutoMLПђМмЁЃ
БОЮФРДздгкЫбКќЭјЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
AutoMLЕНЕзЪЧЪВУДЃП
AutoMLЪЧвЛИіКмПэЗКЕФЪѕгяЃЌРэТлЩЯРДЫЕЃЌЫќФвРЈДгЪ§ОнЬНЫїЕНФЃаЭЙЙНЈетвЛЭъећЕФЪ§ОнПЦбЇбЛЗжмЦкЁЃЕЋЪЧЃЌЮвЗЂЯжетИіЪѕгяИќЖрЪБКђЪЧжИздЖЏЕФЬиеїдЄДІРэКЭбЁдёЁЂФЃаЭЫуЗЈбЁдёКЭГЌВЮЪ§ЕїгХЃЌетаЉВНжшДІдкЪ§ОнПЦбЇСїГЬЕФФЉЖЫЁЃ
СїГЬжаЕФдчЦкВНжшЃЌМДЪ§ОнЬНЫїЁЂЧхРэКЭЬиеїЙЄГЬКмФбздЖЏЛЏЃЌвђЮЊЫќУЧМШашвЊзЈвЕжЊЪЖЃЌвВашвЊШЫЮЊХаЖЯЁЃСюШЫИпаЫЕФЪЧЃЌAutoMLПЩШУФЃаЭбЁдёКЭПЊЗЂЕШЙЄзїжаШпГЄЕЅЕїЕФВНжшЪЕЯжздЖЏЛЏЃЌДгЖјНтЗХЪ§ОнПЦбЇМвЃЌШУЫћУЧЙизЂИќгаШЄЕФЙЄзїЁЃ
ЯТУцЮвНЋЯъЯИНщЩмВПЪ№AutoMLЗўЮёЕФОбщЁЃ
ЮхИіжївЊЕФвЊЕу
1.AutoMLПЩЮЊФЃаЭбЁдёКЭгХЛЏЬсЙЉЧаЪЕЕФКУДІЁЃ
2.ЫќЗЧГЃШнвзШыЪжЁЃКмЖрAutoMLПђМмЖМгыscikit-learnЛђЦфЫћЙуЪмЛЖгЕФЪ§ОнПЦбЇЙЄОпМцШнЁЃ
3.AutoMLЬНЫїЕФЫуЗЈКЭВЮЪ§СьгђвЊБШвЛАуЕФЪ§ОнПЦбЇЙЄзїСїГЬИќЮЊЙуРЋЁЃФњЪЧВЛЪЧФЋЪиГЩЙцЃЌЛЙОаФргкRandom
ForestЛђGradient Boosted TreesЃПAutoMLПЩвдАяжњФњЧЩУюЕиЬНЫїаТЕФЁЂгааЇЕФЗНЗЈЁЃ
4.вЊЛёЕУзюгХНсЙћЃЌашвЊИќГЄЪБМфЕФбЕСЗЃЈДгЪ§аЁЪБЕНМИЬьЃЉЃЌВЂЪЙгУВЛЭЌВЮЪ§ЖрДЮдЫааЁЃ
5.ЪЙгУФПЧАПЩгУЕФПЊдДЙЄОпЃЌПЩвдНЈСЂвЛИіЭъШЋздЖЏЛЏЕФЪБађЗжРрЙмЕРЁЃ
здЖЏЛЏЕФЬиеїЙЄГЬКЭФЃаЭЙЙНЈ
ЮвВтЪдВЂзщКЯЪЙгУЙ§СНПюПЊдДPythonЙЄОпЃКtsfreshЃЌетЪЧвЛПюздЖЏЛЏЕФЬиеїЙЄГЬЙЄОпЃЛTPOTЃЌвЛПюздЖЏЛЏЕФЬиеїдЄДІРэКЭФЃаЭгХЛЏЙЄОпЁЃНсЙћЕУЕНвЛИіздЖЏЛЏЕФЪБађЗжРрЙмЕРЃЌПЩвдгУЫќРДеыЖдЖрЮЌЖШЁЂШЮвтаЮзДЕФЪ§ОнЙЙНЈФЃаЭЁЃ
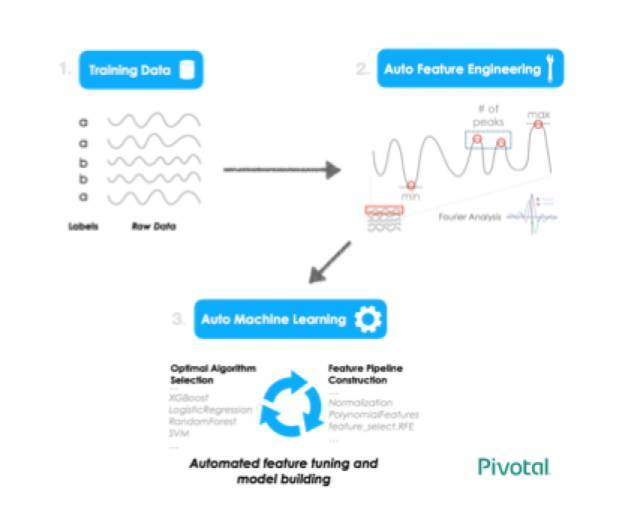
гУгкЪБађЗжРрЕФздЖЏЛЏЙмЕР
ЫфШЛзмЕФРДЫЕЃЌздЖЏЛЏЕФЬиеїЙЄГЬЪЧвЛИіФбЬтЃЌЕЋдкЪБађЪ§ОнЗНУцНќЦкгавЛаЉНјВНЁЃЪ§ОнПЦбЇМвЪЙгУИЕРявЖЗжЮіРДР§ааДДНЈЬиеїЃЌЗЖЮЇДгЪБгђеЊвЊЭГМЦЕНИќЯШНјЕФЦЕгђЬиеїЁЃtsfresh
ПтПЩЮЊФњжДааетаЉМЦЫуЃЌЛЙФмЬсЙЉИќЯШНјЕФЙІФмЁЃ
ЙЙНЈЬиеїжЎКѓЃЌTPOTПЩвддкКѓЬЈЪЙгУвХДЋЫуЗЈжЧФмЕиЙЙНЈЬиеїдЄДІРэКЭНЈФЃЙмЕРЁЃР§ШчЃЌЪЙгУЛљвђБрГЬЕФЫцЛњЗНЗЈвЊБШЭјИёЫбЫїЗНЗЈИќгагХЪЦЃЌдвђдкгкЫќФмЦЋРыЮоаЇЙмЕРЃЌЛЙФмЗЕЛиЪ§ОнПЦбЇМвЮДжЊЕФШЋаТЙмЕРЁЃБОжЪЩЯРДЫЕЃЌздЖЏНЈФЃЙмЕРПЊЗЂПЩвдИФНјзюжеФЃаЭЃЌЭЌЪБЯђЪ§ОнПЦбЇМвНвЪОаТЕФЗНЗЈЁЃ
TPOTеыЖдУПИіЙмЕРМЦЫуЪЙгУKДЮНЛВцбщжЄЃЌФЌШЯЧщПіЯТЪЧгХгкЙ§ЖШФтКЯЕФЁЃЧЖЬзЕФНЛВцбщжЄЗНЗЈЖдЙмЕРадФмЕФдЄЙРЫљВњЩњЕФЦЋВюИќЩйЃЌЕЋдкМЦЫуЩЯЗЧГЃКФЗбзЪдДЁЃ
ЮвУЧПЩвддкЩЯЪіетаЉПтжаМгШыМИааДњТыЁЃР§ШчЃЌЪЙгУfitФЃаЭвдscikit-learnЕФЗНЪНбЕСЗTPOTЁЃЩЯЪіЪЧвЛжжЗНЗЈЃЌЛЙгаКмЖрЦфЫћAutoMLПтПЩвдЪЙгУЁЃ
ВПЪ№AutoMLдЦЗўЮё
ЮвЯыРЉеЙетИіЗНЗЈЃЌдкдЦжаВПЪ№ЫќЃЌВЂЪЙгУFlaskНЋЦфЬсЙЉИјAPIЁЃЮветУДзіЪЧГігкМИИідвђЁЃзюжївЊЕФдвђЪЧНЋЛњЦїбЇЯАЙмЕРВПЪ№ЮЊЗўЮёЪЧНЋЪ§ОнПЦбЇФЃаЭЭЖШыЩњВњЕФКУЗНЗЈЁЃЖјЧвЭЈЙ§дЫгУСщЛюЕФЩшМЦЃЌЮвУЧПЩвдВЂааЗжЮіЖрИіФЃаЭЃЌЖјетЭЈГЃЪЧЯжЪЕЙЄзїжаЖдВПЪ№ФЃаЭЕФвЊЧѓЁЃ
етИіЙмЕРПЩвдВПЪ№ЕНШЮвтжЇГжPythonЕФдЦЛЗОГжаЁЃдкPivotalЃЌЮвУЧОГЃЪЙгУCloud FoundryЃЌЫќОпБИЗЧГЃКУЕФЩњВњМЖгХЪЦЃЌАќРЈздЖЏЛЗОГЩшжУЁЂРЉеЙадКУЁЂИКдиОљКтЁЂФкжУЕФАВШЋадвдМАЦфЫћЩњВњгХЪЦЁЃ
ИУгІгУЭЈЙ§вЛИіRESTful APIЬсЙЉФЃаЭбЕСЗКЭФЃаЭдЄВтЙІФмЁЃЖдгкФЃаЭбЕСЗЃЌЪфШыЪ§ОнКЭБъЧЉЭЈЙ§POSTЧыЧѓЗЂЫЭЃЌЙмЕРЕУЕНбЕСЗЃЌФЃаЭдЄВтНсЙћЭЈЙ§дЄВтТЗгЩНјааЗУЮЪЁЃДЫЭтЃЌЙмЕРЪЙгУЮЈвЛЕФМќНјааДцДЂЃЌвђДЫПЩвдЪЙгУВЛЭЌЕФЬиеїЙЙНЈКЭНЈФЃЙмЕРЖдЭЌвЛЪ§ОнзіГіЪЕЪБдЄВтЁЃ
ФЃаЭбЕСЗЭЈЙ§HTTP POSTЧыЧѓЗЂЦ№ЁЃЭЈЙ§АќКЌЕФВЮЪ§ЮФМўЃЌИїжжздЖЏЛЏЕФЬиеїЙЄГЬКЭФЃаЭЙЙНЈЙмЕРПЩвдЕУЕНМЦЫуВЂгыВЛЭЌЕФЙмЕРIDБЃГжвЛжТЁЃ
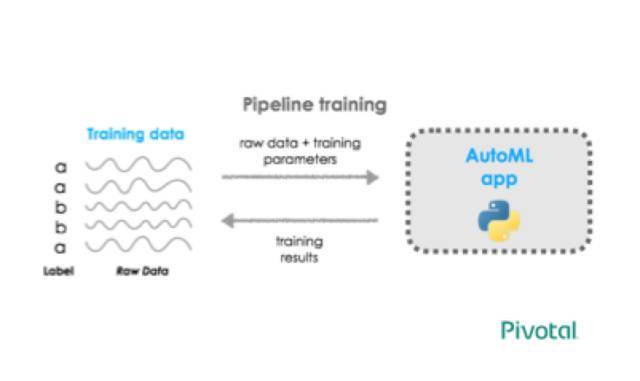
ФЃаЭбЕСЗТпМБэЪОЮЊRESTЖЫЕуЁЃдЪМЕФДјБъЧЉбЕСЗЪ§ОнЭЈЙ§POSTЧыЧѓЩЯДЋЃЌжЦЖЈвЛИізюгХЕФНЈФЃЙмЕРЁЃ
ВЮЪ§ЮФМўАќКЌгУгкЬиеїЙЄГЬКЭФЃаЭЙЙНЈЕФбЁЯюЃК
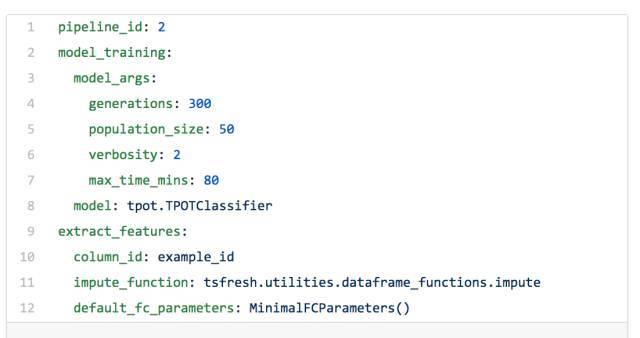
гЩгкЬиеїЙЄГЬЪЧздЖЏЛЏЕФЃЌЬиеїМЦЫуОЭВЛдйЪЧЬиЖЈгкЪ§ОнМЏЕФЃЌвђДЫПЩвдеыЖдВЛЭЌЪБМфДАПкЕФВЛЭЌЪ§ОнМЏбЕСЗЙмЕРЁЃextract_featuresВЮЪ§ЪЧЬиЖЈгкtsfresh
extract_featuresФЃПщЕФЁЃЧыВЮдФДЫЮФЕЕСЫНтИќЖраХЯЂЁЃ
POSTЧыЧѓАќРЈдЪМЪ§ОнЁЂБъЧЉКЭВЮЪ§ЃК

зЂвтЃКвЛАуРДЫЕЃЌЗжРрГЬађдЫааЕФЪБМфдНГЄЃЌЫбЫїЕФФЃаЭПеМфдНДѓЃЌФЃаЭЕФНсЙћдНКУЁЃTPOTЕФзїепНЈвщФЃаЭдЫааЕФЪБГЄгІИУАДаЁЪБЛђЬьЃЌЖјВЛЪЧАДЗжжгМЦЁЃ
дкгІгУЬиеїЙЄГЬР§ГЬжЎКѓЃЌЛсбЁдёНЈФЃЙмЕРЃЌВЂЗЕЛивЛИіФтКЯЙмЕРЃК

дкДЫЪОР§жаЃЌЙЙНЈЕФЪЧЖбЕўЙмЕРЃЌдкЪфШыТпМЛиЙщФЃаЭЪБЯШЙЙНЈКЯГЩЬиеїЃЌЕЋЪЧвВПМТЧСЫКмЖрЗНЗЈЁЃ
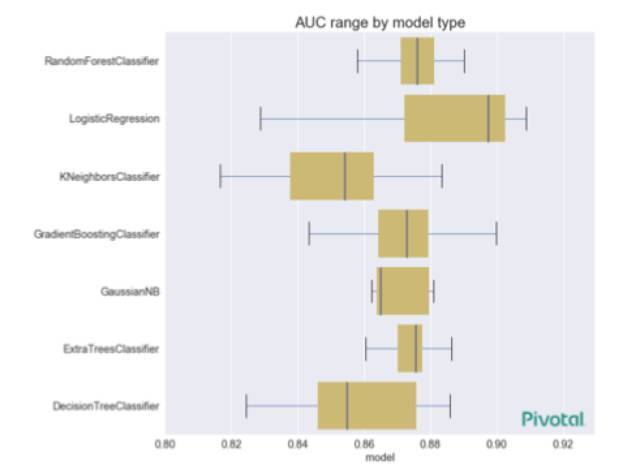
дкЫбЫїЙ§ГЬжаЃЌTPOTЛсЦРЙРКмЖрВЛЭЌЕФЫуЗЈЁЂГЌВЮЪ§КЭдЄДІРэР§ГЬЁЃетжжзіЗЈгыУПИівбЦРЙРЕФФЃаЭРраЭЕФФЃаЭадФм(AUC)ЯђЖдгІЁЃ
дкШЗЖЈзюгХЕФЬиеїЙЄГЬКЭФЃаЭЙЙНЈЙмЕРжЎКѓЃЌЮвУЧЕФЙмЕРБЃДцдкFlaskгІгУЕФPythonФПТМжаЃЌИУФПТМЕФМќОЭЪЧВЮЪ§ЮФМўжажИЖЈЕФЙмЕРIDЁЃ
бЕСЗжЎКѓЃЌвббЕСЗЕФНЈФЃЙмЕРНЋЖдДЋШыЕФдЪМЪ§ОнжДааЪЕЪБЕФдЄВтЁЃ
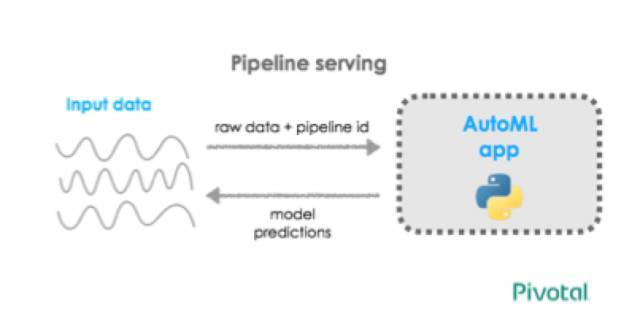
вббЕСЗЙмЕРЕФдЄВтЭЈЙ§REST APIжДаа
дЪМЪ§ОнКЭВЮЪ§ШдЪЧЭЈЙ§POSTЧыЧѓЗЂЫЭЃК

ЗЕЛиЕФJSONЖдЯѓАќКЌУПИіЪОР§IDКЭвЛИідЄВтНсЙћЃК

ЭЈЙ§дкPSOTЧыЧѓжажИЖЈЙмЕРIDЃЌЮвУЧПЩвдЪЙгУУПИіНЈФЃЙмЕРЗЕЛиЖрИідЄВтНсЙћЁЃ
зюжеЃЌЮвУЧПЩвдЪЙгУвббЕСЗФЃаЭВщПДвббЕСЗЙмЕРЕФСаБэЃК

дкЪЕМљжаЃЌШчЙћВЛАбвббЕСЗЙмЕРБЃДцдкPythonФПТМжаЃЌЮвУЧПЩвдАбЙмЕРБЃДцдкRedisЛђPivotal
Cloud CacheЕШЪ§ОнЛКДцжаЁЃетбљвЛРДЃЌЦфЫћгІгУКЭгІгУЕФЖрИіЪЕР§ЖМПЩвдЗУЮЪвббЕСЗЕФЙмЕРЁЃ
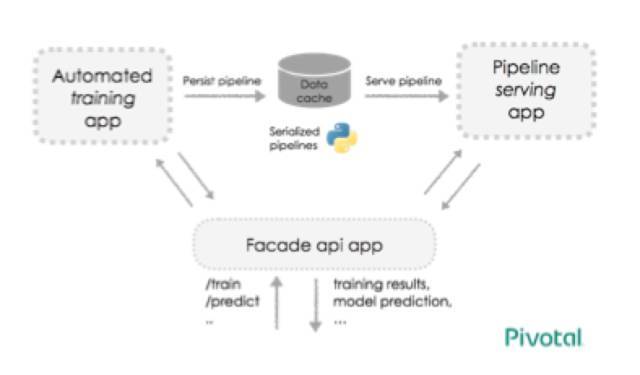
ПЩРЉеЙЕФбЕСЗКЭФЃаЭЬсЙЉМмЙЙ
змНс
AutoMLвбОПЩвдМгШыЕНЪ§ОнПЦбЇЙЄзїСїГЬжаЃЌДњЬцаЇТЪВЛИпЕФЭјИёЫбЫїКЭШпГЄЕЅЕїЕФФЃаЭПЊЗЂСїГЬЁЃгыДЋЭГЗНЗЈЯрБШЃЌAutoMLЭЈГЃПЩвдИФНјФЃаЭадФмЃЌЭЌЪБЮЊЙЙНЈгБЕФНЈФЃЙмЕРЬсЙЉЫМТЗЁЃздЖЏЛЏЕФЬиеїЙЄГЬЪЧвЛИіБШНЯФбвдеЦЮеЕФЮЪЬтЃЌЕЋдквЛаЉгУР§жаЃЌПЩвдРћгУвЛаЉгааЇЕФЙЄОпЁЃЮвеЙЪОСЫШчКЮРћгУПЊдДЕФAutoMLЙЄОпЃЌвдМАШчКЮНЋПЩРЉеЙЕФздЖЏЛЏЬиеїЙЄГЬКЭФЃаЭЙЙНЈЙмЕРЗХШыдЦжаЁЃ |









