| 编辑推荐: |
本文我们通过提出一个基于双层学习的预测控制框架来寻求自动驾驶混合动力汽车(HEV)能效的提高。高层通过使用隐马尔可夫链和高斯分布来模拟人类驾驶员的行为,希望对您的学习有所帮助。
本文来自电子发烧友,由火龙果软件Delores编辑推荐 |
|
1介绍
如今,道路上车辆越来越多,道路运输系统变得越来越繁忙。为了使交通和移动更加智能化和高效,自动驾驶汽车被认为是有前途的解决方案。随着外部传感、运动规划和车辆控制等方面取得显著的成果,自动驾驶汽车的自主创新能够很好地帮助车辆在预先设定的场景下独立运行。
通常,自动驾驶车辆中的系统架构由三个主要处理模块组成,参见图1作为图示[2]。传感器和数字地图提供的数据在感知和定位模块中进行,以呈现驾驶情况的代表性特征;运动规划模块旨在根据给定的传感器和地图信息生成适当的决策策略并得出最佳轨迹;轨迹控制器模块的目的是计算处理加速和转向的具体控制动作,以维持现有的轨迹[ 3 ]。
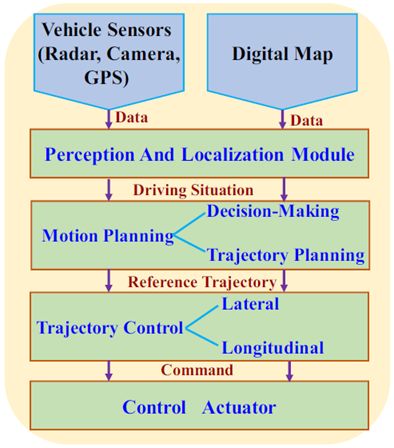
图1.通用自动驾驶汽车的系统架构[2]
决策和路径规划是自动驾驶汽车的关键技术。为了讨论轨迹生成步骤,目前已经提出了几种技术。例如,提出了一种名为“逐个学习”的数据驱动控制框架,用于从历史驾驶数据中训练控制器以将车辆作为人类驾驶员来操作。具体来说,人工神经网络( ANN ) [ 4 ]和逆最优控制[ 5 ]已经被用于再现自动驾驶车辆中的人类驾驶行为。然而,当历史数据集中没有当前驾驶情况时,车辆无法平稳运行。作为替代方案,模型预测控制(MPC)[6]用于预测驾驶员行为并在成本函数中实施多个约束,驾驶状态预测的精度决定了MPC方法的控制性能[7]。自动驾驶和人类驾驶员之间的最大区别是能否确保乘客的安全和舒适。如何创建可行、安全和舒适的参考轨迹仍然是一个严峻的挑战。
在这项工作中,为自动驾驶混合动力电动汽车(HEV)开发了基于强化学习的预测控制框架。提出的方法是双层的,高层是一个类似人类的驾驶模型,它可以生成约束。底层是基于强化学习( RL )的控制器,能够提高自动驾驶混合动力汽车的能效。所提出的框架被验证用于汽车跟随模型中的纵向控制。结果表明,该方法能够重现人类驾驶员的驾驶风格,提高燃油经济性。
这项工作的贡献包含两个方面。首先是适应训练数据集中不存在的当前驾驶情况。提出诱导矩阵范数(IMN)来比较当前和历史驾驶数据之间的差异并扩展训练数据集;其次是将轨迹生成步骤与自动驾驶HEV的能量效率改进相结合。基于从高层获得的参考轨迹,基于RL的控制器在成本函数中实施电池和燃料消耗约束以促进燃料经济性。
本文的其余部分组织如下,第Ⅱ节介绍了更高级别的驱动程序建模方法,第III节描述了混合动力汽车动力总成的低级RL控制器,第Ⅳ节给出了模拟结果,第V节总结了论文。
2.高层:驾驶员建模
本节展示了高层类人驾驶模型。首先,定义汽车跟随模型中的参数;然后,介绍了驾驶员模型的训练方法;最后,描述了未来加速度的预测过程。
A.汽车跟随模型
在汽车跟随模型中,自动驾驶HEV被命名为目标车辆,前方自动驾驶HEV被称为前方车辆。定义δt= [dt,vt]是时刻t的目标车辆的状态,其中dt和vt分别是纵向位置和速度,类似地,δft= [dft,vft]是在时刻t的前方车辆的状态,时刻t的行驶状况由特征ωt= [drt,vrt,vt]表示,其中drt = dft-d是相对距离,vrt = vft-v是相对速度。
在高层上,驾驶员模型旨在生成一个加速度序列At = [ At,…,At + N - 1 ],以指导目标车辆的运行,N = T /△T表示总时间步长,T是预测的时间间隔,而△T是驾驶员模型的采样时间。基于该加速序列,基于RL的控制器用于导出底层的自动驾驶HEV的功率分配控制策略。
B.驾驶员模型训练
基于历史驾驶数据ω1 : t = [ω1,…,ωt ),驾驶员模型的目标是预测接近人类驾驶员实际操作的加速度序列。对于真实的驾驶数据,人类驾驶员的控制策略被建模为隐马尔科夫链( HMC ),其中mt∈{ 1,…M }是用于复制人类驾驶员演示的加速度命令。在时刻t的隐模式,ot = [ωt,at ]是时刻t的观察向量,包括驾驶情况和加速度。
对于HMC,隐藏模式通过概率分布与观测相关,如下所示
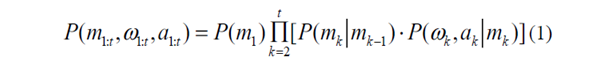
其中假设转移概率P(ωk,ak | mk)符合高斯分布。特别地,HMC模型的参数包括初始分布P ( m1 )、总隐藏模式M、转移概率πij意味着从第I模式到第j模式的转移,以及高斯分布的协方差和平均矩阵。期望最大化算法和贝叶斯信息准则被用来从历史驾驶数据[ 8 ]中学习这些参数。
C.当前加速度的计算
高斯混合回归用于计算当前加速度,给出行驶情况序列ω1 : t,如下[ 3 ]
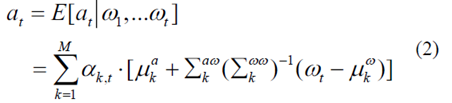
其中
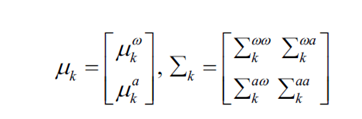
αk,t表示混合系数,并且被计算为处于模式mt = k的概率[3]
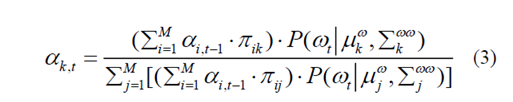
D.预测未来加速度
当前的行驶状况ωt= [drt,vrt,vt],当前的加速度at和离散时间△t是先前已知的,可以通过假设前方车辆的速度恒定来计算未来的行驶状况。
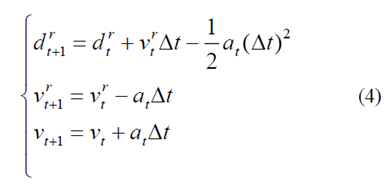
简单来说,Eq.(4)可以重新表述为状态空间方程
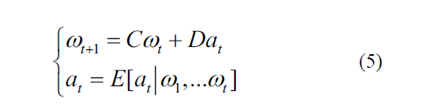
最后,可以通过迭代以下表达式来导出预测范围T上的未来加速序列
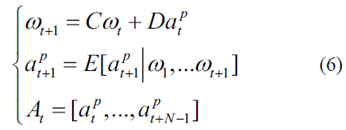
3.底层:RL控制器
本节介绍了基于RL的节油控制器。首先,计算加速度序列的转移概率矩阵(TPM);然后,提出诱导矩阵范数(IMN)来评估历史和当前加速度数据之间的差异;此外,制定了自主HEV的能效改进问题的成本函数;最后,构造了RL方法框架,利用Q学习算法搜索最优控制策略。
A.加速序列的TPM
加速序列被视为有限马尔可夫链(MC),其转移概率通过统计方法计算为
其中Nik,j是从车辆速度vk发生从ai到aj的转换的次数,Nik是从车速vk的ai开始的总转换计数,k是离散时间步长,N是离散加速指数。加速序列的TPM P填充有元素pik,j。历史和当前加速序列的TPM分别表示为P1和P2。
B.诱导矩阵范数
当历史驾驶数据集不包含当前驾驶情况时,高层的驾驶员模型不能生成有效的加速命令来指导自主HEV的操作。因此,引入诱导矩阵范数(IMN)来量化历史和当前加速度序列的TPM差异
其中sup描绘了标量的上确界,x是N×1维非零矢量。方程式中的二阶范数。为了方便计算,可以将(8)重新表述为以下表达式
其中PT表示矩阵P的转置,并且λi(P)表示对于i = 1,...,N的矩阵P的特征值。注意,IMN越接近零,TPM P1与P2越相似。
C.能源效率的成本函数
自动驾驶HEV的能效改进的目标是在部件的约束下搜索最优控制,以提高燃料经济性,同时保持有限预测范围内的电荷维持约束为
其中mf是燃料消耗率,SOC是电池的充电状态,θ是限制SOC终端值的大的正加权因子,而SOCref是满足电荷维持约束的预定因子[9]。表1列出了自动驾驶HEV的主要部件参数。
D.RL方法
预测加速度序列和车辆参数的TPM是用于最优控制计算的RL方法的输入。在RL构造中,学习代理与随机环境交互。交互被建模为五元组(S,A,P,R,β),其中S和A是状态变量和控制动作集,P代表功率请求的TPM,R代表奖励集合,β∈(0,1)表示折扣因子。
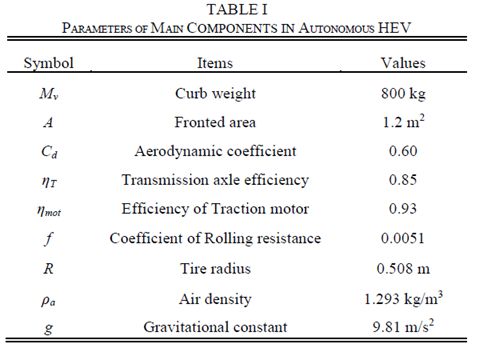
控制策略ψ是控制命令a的分布。有限预期折现和累积奖励总结为最优值函数
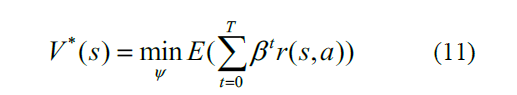
为了在每个时刻推导出最佳控制动作,Eq.(11)递归地重新表述为
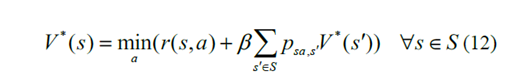
其中psa,s'表示使用动作a从状态s到状态s'的转换概率。基于方程式中的最优值函数确定最优控制策略。(12)
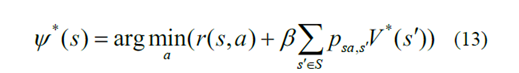
此外,动作值函数及其相应的最优度量描述如下[10]
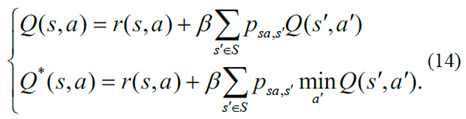
最后,Q学习算法中的动作值函数的更新标准由表示
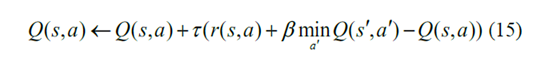

4.模拟结果与讨论
本节将对所提出的基于学习的预测控制框架进行评估。首先,讨论了加速序列预测的驱动模型的性能。此外,说明了基于RL的燃料节省策略的控制有效性。
A.验证驾驶员模型
第II节中描述的驾驶员模型用于预测不同驾驶情况下的加速序列。均方误差(MSE)用于量化预测加速序列和实际加速序列之间的差异。图2和图3示出了两个实际加速序列及其对于两个驾驶情况A和B的预测值。对于图2,假设自主HEV的当前驾驶风格存在于历史驾驶数据集中。相反,图3中的当前驾驶风格在训练数据中不存在。
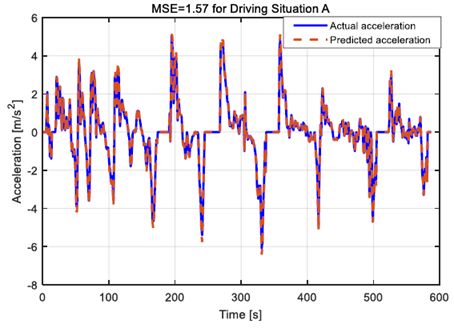
图2.情况A的预测和实际加速度序列。
很明显,加速度序列的预测值非常接近图2中驾驶情况A的实际值。这表明,当历史驾驶数据集预先遍历当前驾驶情况A时,驾驶员模型可以达到极好的精度。然而,当当前驾驶状况B在训练数据中缺失时,驾驶员模型不能为自动驾驶HEV操作提供准确的指导,参见图3作为说明。图2中的MSE等于1.57,这在预测可用性方面优于图3中的MSE = 4.43。
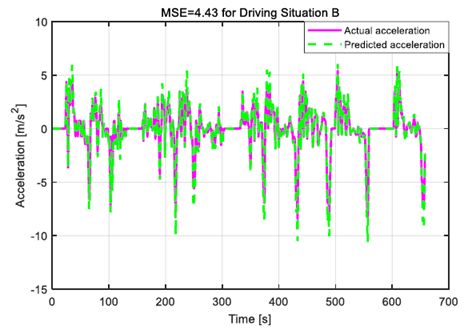
图3.情况b的预测和实际加速度序列
B.RL控制器的验证
基于历史和当前加速度序列,第III - A节中描述的TPM的计算过程被用于计算驾驶情况A和b中的加速度TPM。IMN被用于量化这两个序列之间的差异。因为IMN值超过预定阈值,这意味着当前驾驶情况不同于历史驾驶数据,因此预测加速度不精确。相反,较小的IMN值意味着从历史数据中学习的预测加速度序列可能是准确的。
图4和图5示出了分别对应于图2和图3中的两种驾驶情况的不同车速水平下的IMN值。这两个数字表明,IMN值超过预定义阈值的时间不同。为了处理历史驾驶数据中不存在当前驾驶情况B的情况,当IMN值超过阈值时,该驾驶数据将被添加到训练数据集中。通过这样做,历史驾驶数据集能够准确预测人类驾驶员在相同驾驶情况下的行为。
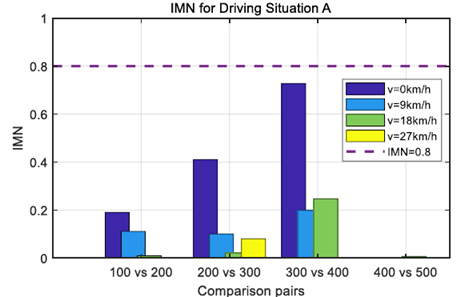
图4.驾驶情况a的不同速度水平下的IMN值
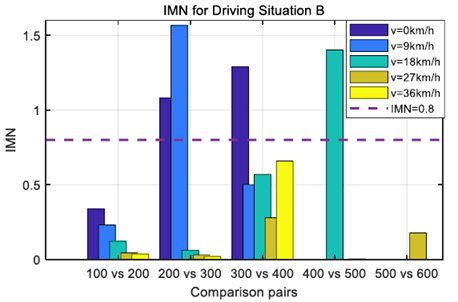
图5.驾驶情况b的不同速度水平下的IMN值
未来加速序列的精确TPM被进一步用于使用RL技术导出燃料节省控制。图6描绘了没有预测加速度信息的公共RL和具有该信息的预测RL的SOC轨迹。注意到在这两种驾驶情况下,SOC轨迹有很大的不同。这是由未来加速序列的TPM决定的自适应控制造成的。对于驾驶情况B,由于基于IMN值的驾驶数据的扩展过程,预测RL也优于普通RL。
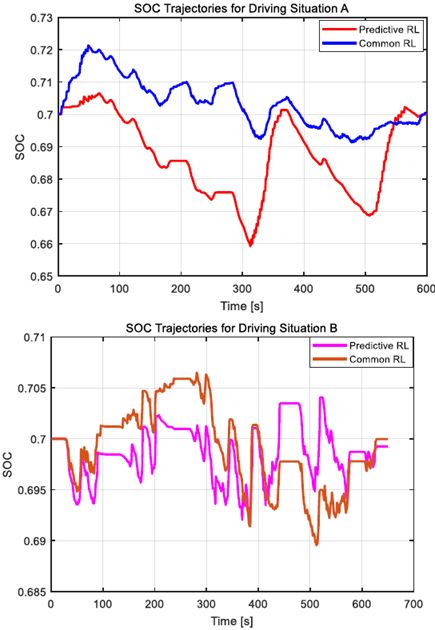
图6.两种情况下的共同SOC和预测RL的SOC轨迹
此外,图7示出了在多个燃料节省控制中发动机的工作区域。与普通RL控制相比,所提出的预测RL控制下的发动机工作区域更频繁地位于较低燃料消耗区域。这意味着与普通RL技术相比,预测RL方法可以实现更高的燃料经济性。
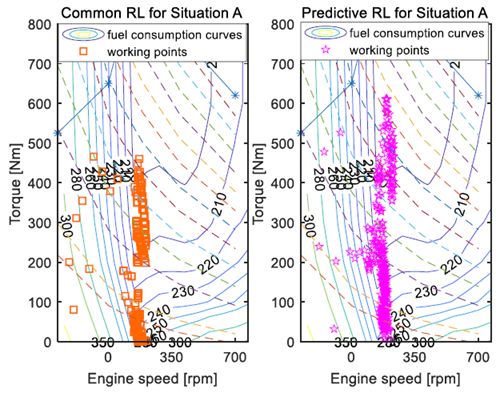
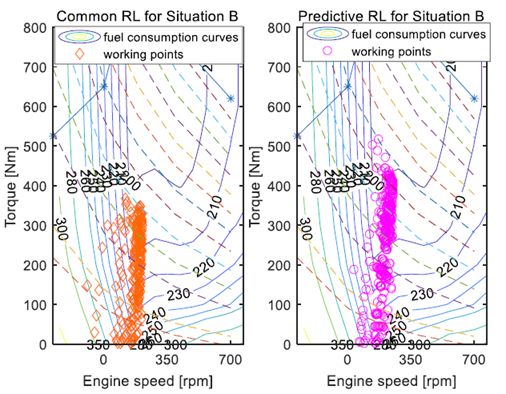
图7.两种情况下发动机工作点的共性和预测性RL。
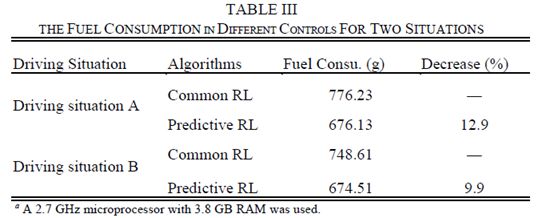
表III描述了在这两种用于驾驶情况A和b的方法中SOC校正后的燃料消耗。显然,预测RL控制下的燃料消耗低于普通RL控制下的燃料消耗。预测的加速序列使得基于RL的控制更加适应未来的驾驶情况,这有助于提高燃油经济性。
5.结论
在本文中,我们通过提出一个基于双层学习的预测控制框架来寻求自动驾驶混合动力汽车(HEV)能效的提高。高层通过使用隐马尔可夫链和高斯分布来模拟人类驾驶员的行为;底层是基于强化学习的控制器,旨在提高自动驾驶混合动力汽车的能效,所提出的框架被验证用于汽车跟随模型中的纵向控制。模拟结果表明,所提出的驾驶员模型能够利用诱导矩阵范数准确预测未来的加速度序列。试验还证明,基于未来加速序列TPM的预测RL控制与普通RL控制相比,可以实现更高的燃油经济性。未来的工作包括将提议的控制框架应用到实时应用中,并使用RL方法制定驾驶员模型来处理换道决策。
|









