| БрМЭЦМі: |
ЮФеТжївЊЪзЯШЖдAutoMLНјааУшЪіЃЌОйР§ЫЕУїAutoMLЕНЕздкзіЪВУД ЃЌШчКЮЪЕЯждРэЗжЮіЃЌзюКѓНщЩмAutoMLЕФгІгУГЁОА
ЁЃ
БОЮФРДздгкМђЪщЃЌгЩЛ№СњЙћШэМўAliceБрМЁЂЭЦМіЁЃ |
|
AutoMLШЋГЦЪЧautomated machine learningЃЌЯТУцгавЛЖЮAutoMLВЛЪЧЪВУДЕФУшЪіЃК

ДѓжСвтЫМЪЧЫЕВЛвЊУдаХAutoMLЃЌЫќжЛЪЧЪ§ОнПЦбЇжкЖрЙЄОпжаЕФвЛжжЃЌЖјЧвЫќвВжЛФмНтОіжкЖрЪ§ОнПЦбЇШЮЮёжаЕФФГаЉШЮЮёЁЃ
AutoMLПЩвдзіШчЯТетаЉЪТЧщЃК
1.дЄДІРэЃЈpreprocessЃЉВЂЧхРэЪ§Он
2.бЁдёВЂЙЙдьКЯЪЪЕФЬиеїЃЈfeaturesЃЉ
3.ДгЯжгаЕФФЃаЭВПМўжабЁдёКЯЪЪЕФФЃаЭНсЙЙЃЈmodel familyЃЉЃЌРрЫЦЖбЛ§ФО
4.гХЛЏФЃаЭГЌВЮЪ§ЃЈhyperparametersЃЉ
5.КѓДІРэЃЈpostprocessЃЉЛњЦїбЇЯАФЃаЭ
6.бЯИёЗжЮіФЃаЭЪфГіНсЙћ
ДгAutoMLПЩвдзіЕФетаЉЪТЧщПЩвдПДГіЃЌжСЩйеыЖдвЛаЉЬиЖЈЕФГЁОАЃЌЫќЪЧФмЙЛзіЕНШЋздЖЏЕФЃЌМДЪ§ОнЧхЯДЁЂЬиеїбЁдёЁЂНЈФЃЁЂГЌВЮгХЛЏЁЂФЃаЭЦРЙРЕШЁЃЮвУЧПЩФмЙиМќЪЧвЊжЊЕРautomlЪЪКЯФФаЉГЁОАЃЌАбЫќзіГЩЮвУЧAIЕФССЕуЃЌЖјВЛЪЧЫљгаЁЃ
дкУшЪіБОЮФЕФAutoMLжЎЧАЃЌашвЊПДМИИіИХФюЃЌМДШЫЙЄжЧФмЁЂЛњЦїбЇЯАЁЂЩюЖШЩюЖШжЎМфЕФЙиЯЕЃЌЯТЭМЪЧДгЭјЩЯевЕНЕФЃК
МђЕЅЕФЫЕЛњЦїбЇЯАЪЧЪЕЯжШЫЙЄжЧФмЕФвЛжжЪжЖЮЃЌЖјЩюЖШбЇЯАЪЧдкЛњЦїбЇЯАЕФЗЂеЙЙ§ГЬжаЃЌЗЂеЙГіРДЕФвЛИіЗжжЇЃЌЙувхЩЯНВЫќвВЪЧЛњЦїбЇЯАЃЌЕЋЪЧгЩгкЦфЪЕЯжЛњжЦКЭдРДЕФЛњЦїбЇЯАЫуЗЈгаНЯДѓЕФВЛЭЌЃЌЫљвдЗЂеЙЮЊвЛИіЖРСЂЕФСьгђЁЃЛњЦїбЇЯАКЭЩюЖШбЇЯАЖМЪЧНЈФЃЕФгааЇЙЄОпЃЌжЛЪЧЫќУЧУцЯђЕФГЁОАгаЫљВЛЭЌЁЃ
ЫљвдЃЌAutoMLвВашвЊЗжЮЊСНИіжжРрЃЌДЋЭГЕФAutoMLКЭЩюЖШAutoMLЁЃМДДЋЭГЕФA
utoMLЪЧЮЊСЫНтОіДЋЭГЛњЦїбЇЯАЕФНЈФЃЮЪЬтЃЌЫќУцЯђЕФЪЧДЋЭГЛњЦїбЇЯАЯрЙиЫуЗЈЃЌШчЯпадЛиЙщЁЂТпМЛиЙщЁЂОіВпЪїЕШЕШЁЃЖјЩюЖШAutoMLИќЖрЕФЪЧУцЯђЩюЖШбЇЯАжаЩёОЭјТчЕФНЈФЃЁЃ
БОЮФжївЊбаОПЕФОЭЪЧУцЯђЩюЖШбЇЯАСьгђЕФAutoMLЁЃ
AutoMLКЭЩёОМмЙЙЫбЫїЃЈNASЃЉЪЧЩюЖШбЇЯАСьгђЕБЧАзюШШУХЕФЛАЬтЁЃ ЫќУЧФмвдПьЫйЖјгааЇЕФЗНЪНЃЌжЛашвЊзіКмЩйЕФЙЄзїЃЌМДПЩЮЊФуЕФЛњЦїбЇЯАШЮЮёЙЙНЈКУЭјТчФЃаЭЃЌВЂЛёЕУИпОЋЖШЁЃ
МђЕЅгааЇЃЁ
Being able to go from idea to result with the least
possible delay is key to doing good research.
НЋЯыЗЈПьЫйЪЕЯжЃЈБфГЩНсЙћЃЉЪЧгХаубаОПЕФЙиМќЁЃ
AutoMLЭъШЋИФБфСЫећИіЛњЦїбЇЯАСьгђЕФгЮЯЗЙцдђЃЌвђЮЊЖдгкаэЖргІгУГЬађЃЌВЛашвЊзЈвЕММФмКЭжЊЪЖЁЃ аэЖрЙЋЫОжЛашвЊЩюЖШЭјТчРДЭъГЩИќМђЕЅЕФШЮЮёЃЌР§ШчЭМЯёЗжРрЁЃ
ФЧУДЫћУЧВЂВЛашвЊЙЭгУвЛаЉШЫЙЄжЧФмзЈМвЃЌЫћУЧжЛашвЊФмЙЛЪ§ОнзщжЏКУЃЌШЛКѓНЛгЩAutoMLРДЭъГЩМДПЩЁЃ
ДгЩЯУцетЖЮЛАПЩвдПДГіЃЌAutoMLВЂВЛЪЧЭђФмЕФЃЌВЂВЛЪЧЫљгаЕФЛњЦїбЇЯАЮЪЬтЖМФмНЛгЩЫќРДЭъГЩЃЌЫќЪЧеыЖдЬиЖЈСьгђЫљЬсЙЉЕФздЖЏЛЏНтОіЗНАИЃЌвдНЕЕЭЦеЭЈЙЋЫОЪЙгУЛњЦїбЇЯАЕФУХМїМАГЩБОЁЃ
AutoMLЪЧФПЧАБШНЯШШУХЕФвЛИібаОПСьгђЃЌжївЊгІгУгкЭМЯёЪЖБ№ЃЌЕЋдкЦфЫќСьгђгІгУЕФНЯЩйЁЃ
ЯТУцЪЧЪЙгУAuto-KerasЪЕЯжmnistЕФвЛИіР§згЃЌгУЫќРДПДПДAutoMLЕНЕздкзіЪВУДЁЃ
1. Auto Keras
ЫќЪЧAutoMLЕФвЛИіЪЕЯжЙЄОпАќЃЌgoogleвВгаздМКЕФautomlЃЌЕЋЪЧФЧИівЊЪеЗбЃЌЮвОЭДгетИізХЪжЃЌЯШПДПДAutoMLФмзіЪВУДЃЌКѓЦкдйШЅЩюШыСЫНтЦфЪЕЯждРэМАЛњжЦЁЃ
ВЛГівтЭтЕФЧщПіЯТЃЌАВзАauto kerasжЛашвЊвЛааУќСюМДПЩЃКpip3 install autokerasЃЌШчЙћГіЯжвьГЃЧщПіЃЌБШШчШБЩйвРРЕАќЃЌАДеевьГЃЬсЪОВЙзАЩЯМДПЩЁЃ
ЯТУцЪЧвЛИіЪЙгУauto kerasБраДЕФЪжаДЪ§зжЪЖБ№mnistЕФдДТыЃК
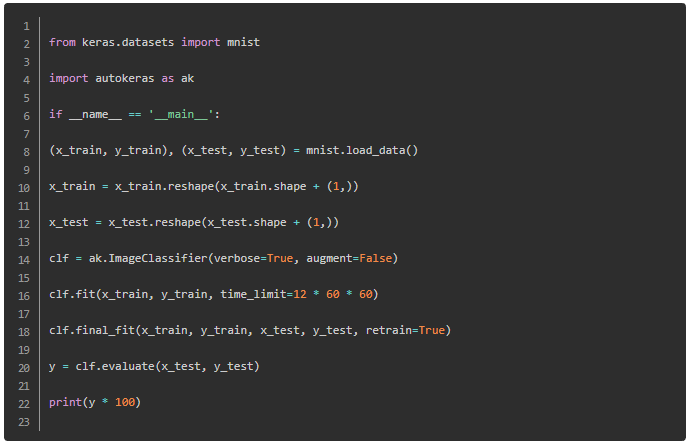
ДгЩЯУцЕФДњТыПЩвдПДГіЫќЕФаДЗЈЗЧГЃМђЕЅЃЌвЛАуЪЙгУtensorflowЙЙНЈвЛИіmnistЕФЩёОЭјТчФЃаЭЃЌПЩФмашвЊвЛСНАйааДњТыЃЌжаМфЩцМАЕНИїИіЪфШыЪфГіВуЕФЙЙдьЃЛЖјЪЙгУauto
kerasжЛашвЊБраДМИааДњТыЃЌЫќЕФаДЗЈгаЕуРрЫЦЛњЦїбЇЯАЙЄОпАќscikit-learnЃЌЭъШЋвўВиСЫИДдгЕФЩёОЭјТчЙЙНЈЙ§ГЬЁЃ
ЕЋЪЧЮвУЧПЩвдДгетЖЮДњТыЕФдЫааШежОжаПДЕНЫќДѓИХдкзіЪВУДЃК
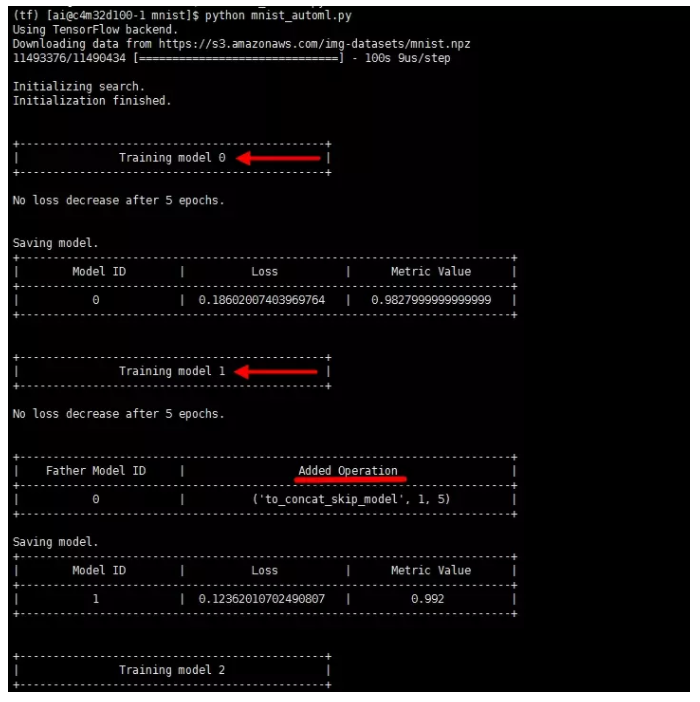
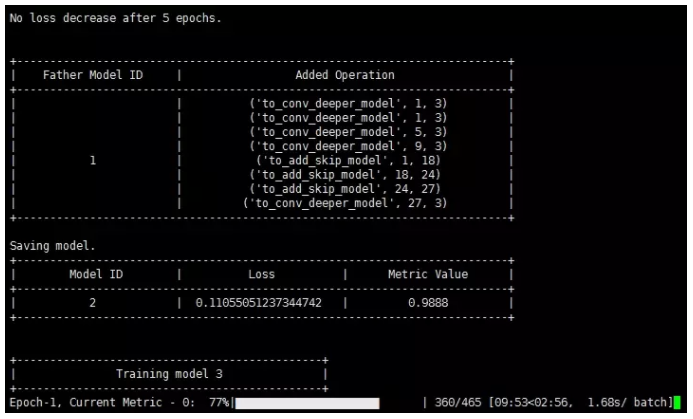
ЭјТчНсЙЙЕФЙЙНЈЙ§ГЬЪЧздЖЏЕФ
бЕСЗЙ§ГЬЪЧздЖЏЕФ
ЫќЙЙдьСЫВЛжЙвЛИіЭјТчФЃаЭЃЌУПИіФЃаЭЫќЖМЛсбЕСЗвЛЗЌ
КѓвЛИіФЃаЭЫЦКѕЪЧдкЧАвЛИіФЃаЭЕФЛљДЁЩЯзіСЫвЛаЉЕїећЃЌМЬГаСЫЧАвЛИіФЃаЭЃЌВЂЧвЛсМгвЛаЉВйзїЃЈЕїећЭјТчНсЙЙЃЉ
ЕїећЕФвРОнгаПЩФмЪЧШежОжаЕФlossвдМАmetric valueЕШЃЌжївЊгІИУЛЙЪЧЫќгаздМКФкВПИФБфИїжжЭјТчНсЙЙЕФЫуЗЈЁЃЃЈЦфЪЕОЭЪЧENASЫуЗЈЃЉ
ЯТУцЪЧautokerasЙйЭјЩЯЕФвЛЖЮЫЕУїЃК
Auto-Keras provides functions to automatically search
for architecture and hyperparameters of deep learning
models.
вВОЭЪЧЫЕAuto-KerasЬсЙЉСЫвЛаЉЙЄОпАќЃЌПЩвдздЖЏЫбЫїЩёОЭјТчНсЙЙЃЌвдМАздЖЏНјааЩюЖШбЇЯАФЃаЭЕФГЌВЮЪ§ЕїећЁЃ
ДгЖдauto kerasЕФГѕВНСЫНтЃЌПЩвдПДГіAutoMLЭЈЙ§здМКЕФвЛЬзЫуЗЈЃЌАбЙЙНЈЭјТчНсЙЙЁЂЕїећЭјТчНсЙЙЁЂЕїећГЌВЮЪ§ЁЂФЃаЭЦРЙРЕШЕШЙ§ГЬШЋВПЗтзАЦ№РДСЫЃЌШЋВПздЖЏЛЏЭъГЩЁЃНЋдРДПЩФмКСЮоФПЕФЕФНсЙЙЕїећЁЂВЮЪ§ЕїећЃЌЭЈЙ§ПЦбЇЛЏЕФЫуЗЈБфГЩНсЙЙгаађЕФЕїећЃЌНЕЕЭСЫЛњЦїбЇЯАЕФУХМїЃЌЫѕЖЬСЫећИіНЈФЃЙ§ГЬЁЃ
2. ЦфЫќAutoMLВњЦЗЃЈЙЄОпАќЃЉ
2.1 AutoWEKA
ЫќЪЧЛљгкWEKAЕФвЛжжAutoMLЪЕЯжЃЌWEKAКУЯёЪЧвЛИіРЯХЦЕФЪ§ОнЭкОђЙЄОпЁЃAutoWEKAОЭЪЧеыЖдWEKAЕФздЖЏФЃаЭбЁдёКЭГЌВЮЪ§гХЛЏЁЃЛљгкJavaЕФЁЃ
2.2 Auto-sklearn
Лљгкscikit-learnЕФAutoMLЪЕЯжЃЌЫќжївЊвВЪЧЩЯУцЬсЕНЕФЃЌеыЖдДЋЭГЛњЦїбЇЯАЖјбдЕФздЖЏНЈФЃЁЃ
ИУЙЄОпАќЪЙгУ15ИіЗжРрЦїЃЌ14ИіЬиеїдЄДІРэЗНЗЈКЭ4ИіЪ§ОндЄДІРэЗНЗЈЃЌВњЩњОпга110ИіГЌВЮЪ§ЕФНсЙЙЛЏМйЩшПеМфЁЃ
ЫќЕФЛљБОдРэПЩвдЭЈЙ§ЯТЭМПДИіДѓИХЃК

КЫаФЫМЯыЪЧЪЙгУБДвЖЫЙгХЛЏЃЁ
2.3 H2O AutoML
ЫќЪЧЛљгкH2OЦНЬЈЕФвЛИіAutoMLЪЕЯжЃЌИУЦНЬЈжївЊУцЯђДЋЭГЛњЦїбЇЯАЫуЗЈЃЌЕЋЪЧвВАќКЌСЫМђЕЅЕФЩюЖШбЇЯАЭјТчФЃаЭЃЌБШШчDNNЁЃ
етЪЧвЛИіЗЧГЃКУЕФЛњЦїбЇЯАЦНЬЈЃЌЫќзлКЯСЫЛњЦїбЇЯАЫуЗЈЁЂЩюЖШбЇЯАЫуЗЈЁЂЪ§ОнЗжЮіЁЂЪ§ОнПЩЪгЛЏЁЂздЖЏГЌВЮЫбЫїЁЂвдМАЖржжбЕСЗжИБъПЩЪгЛЏЕШЃЌЮЊгУЛЇЬсЙЉСЫвЛЬзЭъећЕФШЫЙЄжЧФмНтОіЗНАИЁЃ
2.4 Google Cloud AutoML
ЙШИшЕФAutoMLЪЧвЛИіаТаЫЕФЃЈalphaНзЖЮЃЉдЦМЦЫуЛњбЇЯАЙЄОпШэМўЬзМўЁЃ ЫќЛљгкЙШИшзюЯШНјЕФЭМЯёЪЖБ№баОПЃЌГЦЮЊЩёОМмЙЙЫбЫїЃЈNASЃЉЁЃNASЛљБОЩЯЪЧвЛжжЫуЗЈЃЌИљОнФњЕФЬиЖЈЪ§ОнМЏЃЌЫбЫїзюМбЩёОЭјТчвддкИУЪ§ОнМЏЩЯжДааЬиЖЈШЮЮёЁЃ
Google AutoMLЪЧвЛЬзЛњЦїбЇЯАЙЄОпЃЌПЩвдЧсЫЩХрбЕИпадФмЩюЖШЭјТчЃЌЮоашгУЛЇеЦЮеЩюЖШбЇЯАЛђAIжЊЪЖ;
ЫљгаФуашвЊЕФЪЧБъМЧЪ§ОнЃЁ GoogleНЋЪЙгУNASЮЊФњЕФЬиЖЈЪ§ОнМЏКЭШЮЮёевЕНзюМбЭјТчЁЃВЂЧвЭЈЙ§AutoMLЫљевЕНЕФзюМбЭјТчвЛАуЧщПіЯТвЊдЖдЖКУгкШЫЙЄЩшМЦЕФЩёОЭјТчЃЁ
ЯТЭМЪЧGoogle Cloud's AutoML pipelineЃК
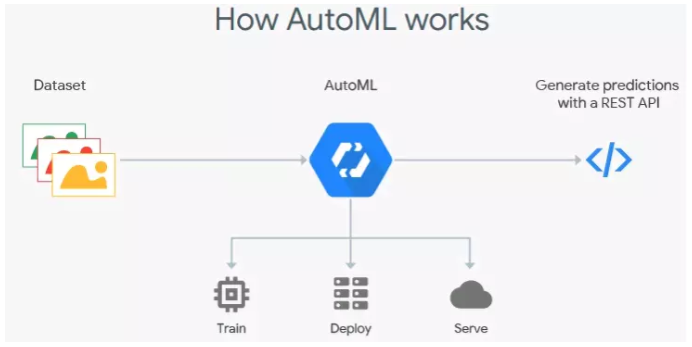
ВЛЙ§GoogleЕФетИіЪЧвЊЪеЗбЕФЃЌЖјЧвЛЙКмЙѓЃЁ
3. AutoMLЪЕЯждРэЗжЮі
ИљОнThomas ElskenЕФТлЮФНщЩмЃЌAutoMLжївЊАќКЌШ§ДѓСьгђЃК
NASЃКNeural Architecture SearchЃЌЩёОЭјТчНсЙЙЫбЫїЃЌМДашвЊЭЈЙ§ФГжжНсЙЙМАЫуЗЈЃЌЪЕЯжЩёОЭјТчНсЙЙЕФздЖЏЩњГЩЁЃ
Hyper-parameter optimizationЃКГЌВЮЪ§гХЛЏЃЌеыЖдЩёОЭјТчжаЕФГЌВЮЪ§НјааздЖЏгХЛЏЁЃ
meta-learningЃКдЊбЇЯАЃЌЛђепНаlearning to learnЃЌМДбЇЛсбЇЯАЁЃ
3.1 NAS
Neural Architecture SearchЃЈNASЃЉЃЌМДЩёОЭјТчНсЙЙЫбЫїММЪѕЃЌЭЈЙ§ФГжжНсЙЙМАЫуЗЈЃЌЪЕЯжЩёОЭјТчНсЙЙЕФздЖЏЩњГЩЃЌЫќжївЊАќКЌЫбЫїПеМфЃЌвдМАЫбЫїВпТдЁЂадФмЦРЙРВпТдЕШМИИіЮЌЖШЕФжЊЪЖЁЃ
3.1.1 ЫбЫїПеМф
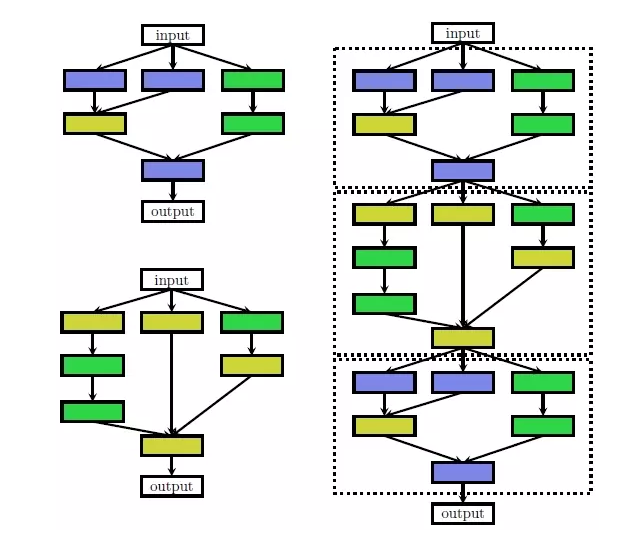
ПЩвдМђЕЅРэНтЮЊЛљгквЛЖЈЕФЧАЬсКЭМйЩшЃЌВЂИљОнвбгаЕФОбщЃЌдЄжУвЛаЉЭјТчНсЙЙЕЅдЊЃЌОЭЯёЖбЛ§ФОвЛбљЃЌдЄЯШЬсЙЉСЫИїжжИїбљЕФЛ§ФОЃЌзюжеЕФЭјТчНсЙЙОЭЪЧЭЈЙ§ЫбЫїПеМфжаЕФетаЉдЪМЛ§ФОзщКЯГЩЕФЁЃ
вВе§ЪЧвђЮЊШчДЫЃЌЭЈЙ§етжжФЃЪНЩњГЩЕФзюжеЭјТчНсЙЙЦфЪЕжЛЪЧдкИјЖЈЕФЫбЫїПеМфжаВщеваЇЙћзюгХЕФФЃаЭНсЙЙЖјвбЃЌЛњЦїжЛЪЧбизХШЫРрЩшМЦКУЕФЫуЗЈЃЌвРОнФГаЉЦРЙРжИБъЃЌЭЈЙ§ВЛЖЯЕФВтЪдДгЖјЩњГЩвЛИіБШНЯЭъУРЕФЭјТчНсЙЙЁЃ
ОјДѓВПЗжЛњЦїбЇЯАЖМВЛЪЧШЫЙЄжЧФмЃЌМЦЫуЛњВЂВЛЪЧецЕФОпгажЧФмСЫЃЌвВВЛЛсЮодЕЮоЙЪЛёЕУМШЖЈФПБъвдЭтЕФФмСІЁЃ
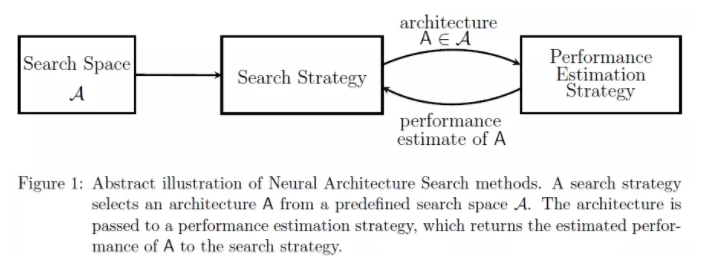
ЯТЭМЪЧЖдЫбЫїПеМфвдМАПеМфжаИїЕЅдЊжЎМфЙиЯЕЕФвЛИіЫЕУїЃК
NASЫуЗЈЫљЩњГЩЕФЭјТчНсЙЙЪЧЛљгкетбљЕФвЛИіЧАЬсЃКЫќШЯЮЊвЛИіДѓЕФЩёОЭјТчНсЙЙЪЧгЩКмЖраЁЕФЁЂжиИДЕФЕЅдЊЫљзщГЩЕФЁЃЮвУЧдкЙЙНЈећИіЩёОЭјТчЪБЃЌжЛашвЊеыЖдетаЉаЁЕФЕЅдЊНјааЫбЫїЃЌЖјВЛЪЧУПДЮеыЖдећИіЭјТчНсЙЙНјааЫбЫїЁЃ
ШчЩЯЭМзѓВрЩЯЯТСНеХЭМЫљЪОЃЌNASНЋетжжзюаЁЕФзщМўГЦжЎЮЊcellsЛђblocksЃЌгаСНжжРраЭЕФЕЅдЊЃЌвЛжжЪЧЮЌГжЮЌЖШЕФе§ГЃЕЅдЊ(normal
cell)ЃЌвЛжжЪЧНЕЕЭЮЌЖШЕФЛЙд/НЕЕЭЕЅдЊ(reduction cell)ЃЌШЛКѓЭЈЙ§вддЄЖЈвхЕФЗНЪНЖбЕўетаЉЕЅдЊРДЙЙНЈзюжеЕФЭјТчМмЙЙЃЈгвЩЯЭМгвВрВПЗжЃЉЁЃ
КЮЮЊЮЌГжЮЌЖШЕФЕЅдЊЃЌКЮЮЊНЕЕЭЮЌЖШЕФЕЅдЊЃЌетВПЗжЮвУЛгаПДУїАзЁЃ
вдЭМЯёЪЖБ№ЮЊР§ЃЌдкGoogleЕФNASNetЭјТчжаЃЌОЭНЋЭМЯёЪЖБ№ЭјТчЗжГЩШчЯТетаЉЕЅдЊЃЈЛђПщЃЉЃК

ПЩвдПДГіетЪЧЛљгкШЫРрдкЭМЯёЪЖБ№СьгђЕФЧАЦкбаОПОбщЕФЃЌЫќдЄжУСЫКмЖрПщЃЌШчИїжжЮЌЖШЕФОэЛ§ВуЃЌИїжжЮЌЖШЕФГиЛЏВуЕШЃЌетЦфжаЛЙЛсЩцМАЕНЕФаЉСЌНгКЏЪ§ЃЈМЄЛюКЏЪ§ЃЉЁЃ
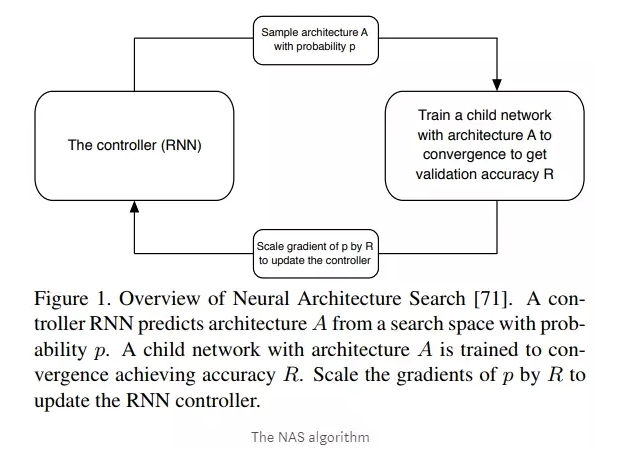
НгЯТРДвЊзіЕФЪТЧщОЭЯёЖбЛ§ФОвЛбљЃЌЦДзАГіИїжжИїбљЕФЭјТчНсЙЙЃЌВЂЖдетаЉНсЙЙНјаабЕСЗЦРЙРЃЌЪЙгУ`RNN``ЭјТчзіЮЊПижЦЦїЃЌРДВЛЖЯЕФжиИДетИіЙ§ГЬЃЌжБНгбЕСЗГіТњвтЕФЭјТчНсЙЙЁЃШчЯТЭМЫљЪОЃК
3.1.2 ЫбЫїВпТд
ЫбЫїВпТдЯъЯИЫЕУїСЫШчКЮЬНЫїЫбЫїПеМфЃЌЫќЮЇШЦзХОЕфЕФЬНЫї-РћгУШЈКтЮЪЬтЃЌвЛЗНУцЯЃЭћФмОЁПьевЕНадФмСМКУЕФМмЙЙЃЌСэвЛЗНУцЃЌвВашвЊНтОіШчКЮБмУтЙ§дчЪеСВЕНДЮгХМмЙЙЧјгђЁЃ
КЮЮЊЬНЫї-РћгУЮЪЬтЃПЭјЩЯевЕНЕФвЛИіР§згЃК
МйЩшФуМвИННќгаЪЎИіВЭЙнЃЌЕНФПЧАЮЊжЙЃЌФудкАЫМвВЭЙнГдЙ§ЗЙЃЌжЊЕРетАЫМвВЭЙнжазюКУГдЕФВЭЙнПЩвдДђ8ЗжЃЌЪЃЯТЕФВЭЙнвВаэЛсгіЕНПкЮЖПЩвдДђ10ЗжЕФЃЌвВПЩФмжЛга2ЗжЃЌШчЙћЮЊСЫГдЕНПкЮЖзюКУЕФВЭЙнЃЌЯТвЛДЮГдЗЙФуЛсШЅФФРяЃП
ЫљЮНЬНЫїЃКЪЧжИзіФувдЧАДгРДУЛгазіЙ§ЕФЪТЧщЃЌвдЦкЭћЛёЕУИќИпЕФЛиБЈЁЃЫљЮНРћгУЃКЪЧжИзіФуЕБЧАжЊЕРЕФФмВњЩњзюДѓЛиБЈЕФЪТЧщЁЃФЧУДЃЌФуЕНЕзИУШЅФФМвФиЃПетОЭЪЧЬНЫї-РћгУРЇОГЁЃ
ЫбЫїВпТдЖЈвхСЫЪЙгУдѕбљЕФЫуЗЈПЩвдПьЫйЁЂзМШЗевЕНзюгХЕФЭјТчНсЙЙВЮЪ§ХфжУЁЃГЃМћЕФЫбЫїЗНЗЈАќРЈЃКЫцЛњЫбЫї(random
search)ЁЂБДвЖЫЙгХЛЏ(Bayesian optimization)ЁЂНјЛЏЫуЗЈ(evolutionary
methods)ЁЂЧПЛЏбЇЯА(reinforcement learning [RL])ЁЂЛљгкЬнЖШЕФЫуЗЈ(gradient-based
methods)ЁЃЦфжаЃЌ2017 ФъЙШИшДѓФдЕФФЧЦЊЧПЛЏбЇЯАЫбЫїЗНЗЈНЋетвЛбаОПДјГЩСЫбаОПШШЕуЃЌКѓРД UberЁЂSentientЁЂOpenAIЁЂDeepmind
ЕШЙЋЫОКЭбаОПЛњЙЙгУНјЛЏЫуЗЈЖдетвЛЮЪЬтНјааСЫбаОПЃЌетИі task ЫуЪЧНјЛЏЫуЗЈвЛДѓШШЕугІгУЁЃ
зЂЃКЙњФкгаКмЖрМвЙЋЫОдкзі AutoMLЃЌЦфжагУЕНЕФвЛжжжїСїЫбЫїЫуЗЈЪЧНјЛЏЫуЗЈЁЃ
ЫуЗЈЕФбнНјРњЪЗ
дк2000ФъвдЧАЃЌНјЛЏЫуЗЈБЛгУдкСЫИФНјЩёОЭјТчНсЙЙЕФИїжжбаОПЩЯЁЃгУНјЛЏЫуЗЈЖдЩёОЭјТчГЌВЮЪ§НјаагХЛЏЪЧвЛжжКмЙХРЯЁЂКмОЕфЕФНтОіЗНАИЃЌ90
ФъДњЕФбЇепгУНјЛЏЫуЗЈЭЌЪБгХЛЏЭјТчНсЙЙВЮЪ§КЭИїВужЎМфЕФШЈжиЃЌвђЮЊЕБЪБЕФЭјТчЙцФЃЗЧГЃаЁЃЌЫљвдЛЙФмНтОіЃЌЕЋКѓајЩюЖШбЇЯАФЃаЭЭјТчЙцФЃЖМЗЧГЃДѓЃЌЮоЗЈжБНггХЛЏЁЃ
Дг2013ФъЃЌБДвЖЫЙгХЛЏвВдкжЎКѓЛёЕУСЫвЛаЉГЩЙІЃЌвдМА2015Фъдкcifar10ЩЯЭЈЙ§ИУЫуЗЈЩњГЩЕФЭјТчНсЙЙЪзДЮГЌЙ§ШЫРрзЈМвЩшМЦЕФЁЃ
2017ФъЃЌЪЙгУЧПЛЏбЇЯАЫуЗЈЃЌдкcifar10КЭPennЩЯЛёЕУСЫОоДѓЕФГЩЙІЃЌвВЪЧДгетЪБПЊЪМЃЌNASПЊЪМБфГЩЛњЦїбЇЯАжаЕФШШУХбаОПЛАЬтЁЃЕЋЪЧЕБЪБЪЧЪЙгУ800ИіGPUЃЌХмСЫШ§ЫФжмВХХмЭъЕФЁЃДгФЧвдКѓЃЌПЊЪМгадНРДдНЖрЕФШЫбаОПШчКЮЬсИпNASЫуЗЈЕФадФмЁЃЦфжазюГіУћЕФОЭЪЧENASЫуЗЈЁЃ
Esteban Realдк2018ФъжїЕМСЫвЛЯюбаОПЃЌМДбаОПЧПЛЏбЇЯАЁЂНјЛЏЫуЗЈЁЂЫцЛњЫбЫїШ§епЕФгХСгЃЌжївЊЪЧбаОПШ§епдкcifar10ЩЯЕФБэЯжЁЃзюжебаОПНсЙћБэУїЃЌЧПЛЏбЇЯАКЭНјЛЏЫуЗЈвЊгХгкЫцЛњЫбЫїЃЌСэЭтдкЭјТчЙцФЃаЁЕФЧщПіЯТЃЌНјЛЏЫуЗЈБэЯжЪЧзюКУЕФЁЃ
БДвЖЫЙгХЛЏдкГЌВЮЪ§гХЛЏЮЪЬтЩЯЪЧзюЮЊСїааЕФЃЌЕЋЪЧКмЩйгаНЋЦфгІгУгкNASЩЯЃЌжївЊЪЧвђЮЊЕфаЭЕФБДвЖЫЙгХЛЏЙЄОпАќЪЧЛљгкИпЫЙЙ§ГЬВЂзЈзЂгкЕЭЮЌСЌајгХЛЏЮЪЬтЁЃ
дкЗжВуЫбЫїСьгђЃЌБШШчНсКЯНјЛЏЛђепЛљгкЫГађФЃаЭЕФгХЛЏЃЌУЩЬиПЈТхЪїЫбЫї(Monte Carlo Tree
Search)вВЪЧбаОПЗНЯђжЎвЛЁЃ
3.1.3 адФмЦРЙРВпТд
NASЕФФПБъОЭЪЧбАевдкЮДжЊЪ§ОнМЏЩЯгаКмКУдЄВтадФмЕФЭјТчНсЙЙФЃаЭЃЌадФмЦРЙРФЃПщОЭЪЧгУРДЦРЙРетаЉЩњГЩЕФЭјТчНсЙЙЕФадФмЁЃЖјвЛжжзюМђЕЅЕФадФмЦРЙРЗНЗЈЃЌОЭЪЧеыЖдИУЭјТчНсЙЙЃЌЪЙгУЪ§ОнМЏНјаавЛДЮБъзМЕФбЕСЗКЭбщжЄЃЌДгЖјЦРЙРЦфадФмЁЃЕЋЪЧетжжзюМђЕЅЕФЗНЗЈЃЌЛсДјРДАКЙѓЕФМЦЫуПЊЯњвдМАЪБМфПЊЯњЃЌДгЖјНјвЛВНЯожЦЮвУЧФмЬНЫїЕНЕФЭјТчНсЙЙЪ§СПЁЃ
вђДЫЃЌзюНќЕФаэЖрбаОПЖММЏжадкПЊЗЂНЕЕЭетаЉадФмЦРЙРГЩБОЕФЗНЗЈЩЯЁЃ
адФмЦРЙРВпТджаЃЌгавЛжжАьЗЈЪЧЛљгкЕЭБЃецЕФВпТдЃЌБШШчИќЖЬЕФбЕСЗЪБМфЁЂЪЙгУИќЩйЕФбЕСЗМЏЁЂЪЙгУИќЕЭЕФЭМЦЌЗжБцТЪЁЂЛђепУПВужаЪЙгУИќЩйЕФЙ§ТЫЦї(filter)ЃЌетжжзїЗЈЛсДѓДѓЕФНЕЕЭбЕСЗПЊЯњЃЌЕЋЪЧвВЛсДјРДвЛаЉжИБъЩЯЕФЦЋВюЃЌВЛЙ§етжжЦЋВюЖдзюжеНсЙћгАЯьВЛДѓЁЃ
ЛЙгавЛжжВпТдЪЧЛљгкЭЦЖЯЗЈЃЌБШШчбЇЯАЧњЯпЭЦЖЯЗЈЃЌетжжЫМТЗЕФКЫаФЫМЯыЪЧНЈвщЭЦЖЯГѕЪМбЇЯАЧњЯпВЂжежЙФЧаЉдЄВтБэЯжВЛМбЕФЧњЯпЃЌвдМгПьМмЙЙЫбЫїЙ§ГЬЁЃЛЙгавЛжжЭЦЖЯЗЈЪЧЛљгкДњРэФЃаЭЕФЭЦЖЯЃЌМДЭЈЙ§аЁЕФЭјТчФЃаЭЕФадФмБэЯжЭЦЖЯГізюжеЕФЭјТчФЃаЭЁЃ
ЛЙгавЛжжВпТдЪЧЪЧЛљгкШЈжиВЮЪ§ЧЈвЦЕФЃЌМДНЋвЛИівбОбЕСЗКУЕФФЃаЭВЮЪ§жБНггІгУгкЕБЧАЭјТчНсЙЙЃЌЕБЧАЭјТчФЃаЭОЭЯрЕБгкдквЛИіИпЦ№ЕуЕФЧщПіЯТНјаабЇЯАЃЌПЩвдДѓДѓЫѕЖЬбЕСЗЪБМфЁЃ
ЛЙгавЛжжВпТдНаOne-ShotМмЙЙЫбЫїЃЌдРэУЛгаПДУїАзЁЃЭјЩЯНтЪЭЪЧетжжЗНЗЈНЋЫљгаМмЙЙЪгзївЛИі one-shot
ФЃаЭЃЈГЌЭМЃЉЕФзгЭМЃЌзгЭМжЎМфЭЈЙ§ГЌЭМЕФБпРДЙВЯэШЈжиЁЃ
3.1.4 NASЮДРДЕФЗНЯђ
ФПЧАОјДѓЖрЪ§ОлНЙдкNASЩЯЕФбаОПЖМЪЧеыЖдЭМЯёЗжРрЕФЁЃдкЦфЫќСьгђШдШЛгІгУНЯЩйЃЌШчгябдНЈФЃЁЂвєРжНЈФЃЁЂЭМЯёаоИДЁЂЭјТчбЙЫѕЁЂгявхЗжИюЕШЁЃ
СэЭтОЭNASЕФЪЕЯждРэЖјбдЃЌЦфЫбЫїПеМфЪЧЭъШЋЛљгкШЫРрОбщЕФЃЌБШШчеыЖдЭМЯёЗжРрСьгђЃЌЮвУЧИјЫбЫїПеМфЖЈвхСЫКмЖрЕЅдЊЃЌШчОэЛ§ВуЁЂГиЛЏВуЕШЃЌЖјетаЉЛљБОжЛФмеыЖдЭМЯёСьгђЃЌЮвУЧЮоЗЈНЋЦфгІгУЕНЦфЫќСьгђжаЃЌетжжЭјТчНсЙЙЕФЫбЫїЃЌзюжевВЛсБЛЯожЦдкетаЉдЄЖЈвхКУЕФЕЅдЊжЎжаЁЃNASЮДРДЕФвЛИібаОПЗНЯђОЭЪЧЖЈвхвЛИіИќЭЈгУЁЂИќПЩРЉеЙЕФЫбЫїПеМфЁЃ
3.1.5 NASЕФбнНј
гЩгкNASУПДЮЫбЫїЭјТчНсЙЙЖМашвЊЖдЦфНјаавЛДЮбЕСЗЃЌдкGoogleЕФNASNetЭјТчЩЯЃЌашвЊЪЙгУ450ПщGPUбЕСЗ3ЕН4ЬьЃЌетжжАКЙѓЕФПЊЯњзЂЖЈаЁЙЋЫОЪЧЯћЗбВЛЦ№ЕФЁЃ
Efficient Neural Architecture Search (ENAS)ЃЌЪЧФПЧАБШНЯГіУћЕФвЛжжnasМгЧПАцЫуЗЈЁЃЫќЕФРэТлЛљДЁОЭЪЧЧЈвЦбЇЯАКЭШЈжиЙВЯэЃЌENASЫуЗЈЧПжЦЫљгаФЃаЭЙВЯэШЈжиЃЌЖјВЛЪЧДгЭЗПЊЪМбЕСЗЕНЪеСВЁЃ
ЮвУЧжЎЧАдкжЎЧАФЃаЭжаГЂЪдЙ§ЕФШЮКЮПщЖМНЋЪЙгУжЎЧАбЇЙ§ЕФШЈжиЁЃ вђДЫЃЌЮвУЧУПДЮХрбЕаТФЃаЭЪБЖМЛсНјаазЊвЦбЇЯАЃЌЪеСВЫйЖШИќПьЃЁ
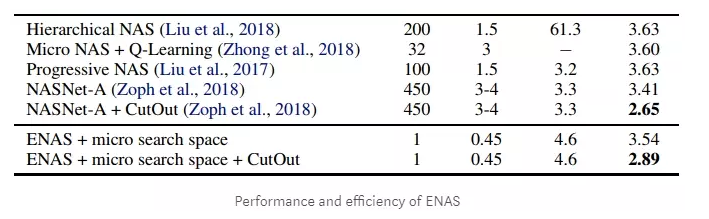
ШчЩЯЭМЫљЪОЃЌБОРДашвЊ450ПщGPUПЈХм3ЃЌ4ЬьЕФФЃаЭЃЌдкЪЙгУСЫENASжЎКѓЃЌжЛашвЊвЛПщ1080Ti
GPUЃЌХмАыЬьМДПЩЁЃ
ЮвУЧзюЩЯУцЕФР§згжаЃЌauto kerasОЭЪЧЪЙгУСЫenasЕФЫуЗЈЁЃ
3.2 Hyper-parameter optimization
ГЌВЮЪ§гХЛЏЃЌВЂВЛЪЧзюНќВХЗЂеЙЦ№РДЕФЃЌЫќвЛжБАщЫцзХЛњЦїбЇЯАКЭЩюЖШбЇЯАЁЃМИКѕУПвЛжжЫуЗЈЃЌЖМЛсЩцМАЕНИїжжИїбљЕФГЌВЮЪ§ЃЌетаЉГЌВЮЪ§ЩшжУЕФКУЛЕжБНгОіЖЈСЫНЈФЃСЫаЇТЪвдМАаЇЙћЁЃЖјЪЕМЪНЈФЃЙ§ГЬжаЃЌКмЖрЧщПіЯТОЭЪЧЦООбщНјааЩшжУЃЌЛђепНјааДѓСПЕФЪдДэЁЂЗДИДбЕСЗЁЃ
ГЌВЮЪ§гХЛЏОЭЪЧЭЈЙ§ЫуЗЈВуУцЃЌНЋГЌВЮЪ§ЕФЩшжУНЛИјМЦЫуЛњШЅЫбЫїЛёЕУЁЃБШНЯСїааЕФЫуЗЈжївЊгаЃКБДвЖЫЙгХЛЏЁЂЫцЛњЫбЫїЁЂЭјИёЫбЫїЁЃ
етЦфжазюгаУћЕФгІИУОЭЪЧБДвЖЫЙгХЛЏЫуЗЈСЫЃЌБДвЖЫЙгХЛЏЪЧвЛжжНќЫЦБЦНќЕФЗНЗЈЃЌгУИїжжДњРэКЏЪ§РДФтКЯГЌВЮЪ§гыФЃаЭЦРМлжЎМфЕФЙиЯЕЃЌШЛКѓбЁдёгаЯЃЭћЕФГЌВЮЪ§зщКЯНјааЕќДњЃЌзюКѓЕУГіаЇЙћзюКУЕФГЌВЮЪ§зщКЯЁЃДњРэКЏЪ§жаБШНЯгаУћЕФОЭЪЧИпЫЙКЏЪ§ЁЃ
БДвЖЫЙгХЛЏЕФКЫаФЫМЯыЪЧЃЌЭЈЙ§гУЛЇИјЖЈЕФСНИіXжЕвдМАЖдгІЕФYжЕЃЌФтКЯвЛИіИпЫЙКЏЪ§ЃЌШЛКѓИљОнЗхжЕевЯТвЛИіПЩФмЕФxжЕЃЌЦфЪЕИјЮвЕФИаОѕвВЪЧЯЙВТЃЌВЛЙ§ВТЕФБШНЯЬхУцЁЃ
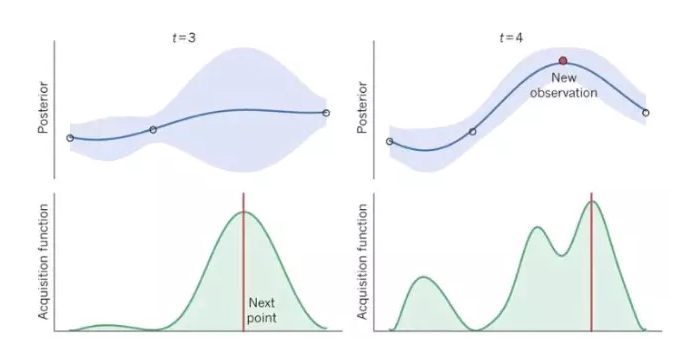
ЦфЫќСНжжГЌВЮгХЛЏЫуЗЈОЭБШНЯМђЕЅСЫЃЌЫцЛњЫбЫїОЭЪЧЯЙВТЃЌИјМЦЫуЛњвЛИіВЮЪ§ШЁжЕЕФЗЖЮЇЃЌШУМЦЫуЛњШЅЯЙВТВЂВЛЖЯГЂЪдЃЛЭјИёЫбЫїИќМђЕЅЃЌгУЛЇЯШЯЙВТКУМИИіШЁжЕЃЌШЛКѓШУМЦЫуЛњШЅГЂЪдЁЃ
3.3 Meta-Learning
ЩаЮДбаОПЁЃ
3.4 ЫуЗЈЯрЙи
3.4.1 ЧПЛЏбЇЯА
ЧПЛЏбЇЯАЪЧвЛжжЗЧГЃгавтЫМЕФЗЖЪНЃЌМИКѕжЛвЊПЩвдЬсСЖГіЧПЛЏбЇЯАЫФвЊЫиЃЌдЮЪЬтОЭПЩвдгУЧПЛЏбЇЯАРДЧѓНтЁЃ
дк NAS ШЮЮёжаЃЌНЋМмЙЙЕФЩњГЩПДГЩЪЧвЛИі agent дкбЁдё actionЃЌreward ЪЧЭЈЙ§вЛИіВтЪдМЏЩЯЕФаЇЙћдЄВтКЏЪ§РДЛёЕУЃЈетИіКЏЪ§РрЫЦгкЙЄГЬгХЛЏЮЪЬтжаЕФ
surrogate modelЃЌМДДњРэФЃаЭЃЉЁЃетРрЙЄзїећЬхЕФПђМмЖМЪЧЛљгкДЫЃЌВЛЭЌЕФЕудкгкВпТдБэЪОКЭгХЛЏЫуЗЈЁЃ
3.4.2 НјЛЏЫуЗЈ
НјЛЏЫуЗЈЪЧвЛДѓРрЫуЗЈЃЌДѓИХЕФПђМмвВЛљБОРрЫЦЃЌЯШЫцЛњЩњГЩвЛИіжжШКЃЈN зщНтЃЉЃЌПЊЪМбЛЗвдЯТМИИіВНжшЃКбЁдёЁЂНЛВцЁЂБфвьЃЌжБЕНТњзузюжеЬѕМўЁЃзюНќМИФъСїаавЛжжЛљгкИХТЪФЃаЭЕФНјЛЏЫуЗЈ
EDA (Estimation Distribution of Algorithm)ЃЌЛљБОЕФЫМТЗРрЫЦвХДЋЫуЗЈЃЌВЛЭЌЕФЪЧУЛгаНЛВцЁЂБфвьЕФЛЗНкЃЌЖјЪЧЭЈЙ§
learning ЕУЕНвЛИіИХТЪФЃаЭЃЌгЩИХТЪФЃаЭРД sample ЯТвЛВНЕФжжШКЁЃ
гУНјЛЏЫуЗЈЖдЩёОЭјТчГЌВЮЪ§НјаагХЛЏЪЧвЛжжКмЙХРЯЁЂКмОЕфЕФНтОіЗНАИЃЌ90 ФъДњЕФбЇепгУНјЛЏЫуЗЈЭЌЪБгХЛЏЭјТчНсЙЙВЮЪ§КЭИїВужЎМфЕФШЈжиЃЌвђЮЊЕБЪБЕФЭјТчЙцФЃЗЧГЃаЁЃЌЫљвдЛЙФмНтОіЃЌЕЋКѓајЩюЖШбЇЯАФЃаЭЭјТчЙцФЃЖМЗЧГЃДѓЃЌЮоЗЈжБНггХЛЏЁЃ
3.4.3 БДвЖЫЙгХЛЏ
БДвЖЫЙгХЛЏЃЈBayesian OptimizationЃЉЪЧГЌВЮЪ§гХЛЏЮЪЬтЕФГЃгУЪжЖЮЃЌгШЦфЪЧеыЖдвЛаЉЕЭЮЌЕФЮЪЬтЃЌЛљгкИпЫЙЙ§ГЬЃЈGaussian
ProcessesЃЉКЭКЫЗНЗЈЃЈkernel trickЃЉЁЃЖдгкИпЮЌгХЛЏЮЪЬтЃЌвЛаЉЙЄзїШкКЯСЫЪїФЃаЭЛђепЫцЛњЩСжРДНтОіЃЌШЁЕУСЫВЛДэЕФаЇЙћЁЃ
Г§СЫГЃМћЕФШ§ДѓРрЗНЗЈЃЌвЛаЉЙЄзївВдкбаОПЗжВугХЛЏЕФЫМТЗЃЌБШШчНЋНјЛЏЫуЗЈКЭЛљгкФЃаЭЕФађСагХЛЏЗНЗЈШкКЯЦ№РДЃЌШЁИїжжЗНЗЈЕФгХЪЦЁЃReal
дк 2018 ФъЕФвЛИіЙЄзїЖдБШСЫЧПЛЏбЇЯАЁЂНјЛЏЫуЗЈКЭЫцЛњЫбЫїШ§РрЗНЗЈЃЌЧАСНжжЕФаЇЙћЛсИќКУвЛаЉЁЃ
4. AutoMLгІгУГЁОА
ЭЈЙ§ЩЯУцЕФУшЪіПЩвджЊЕРЃЌAutoMLЦфЪЕЪЧеыЖдвЛаЉБШНЯГЩЪьЕФШЫЙЄжЧФмНтОіЗНАИЃЌШчГЃЙцЛњЦїбЇЯАЃЌвдМАЭМЯёЪЖБ№ЁЂЭМЯёЗжРрЕШЃЌжївЊгУРДНтОіетРрГЁОАЯТЃЌЭјТчФЃаЭЕФздЖЏЩњГЩЃЌвдМАГЌВЮЪ§ЕФздЖЏгХЛЏЁЃ
ФПЧАЕФAutoMLВЂЩњГЩВЛСЫГЌГіШЫРрЫМЮЌвдЭтЕФФЃаЭЃЌЫќЦфЪЕжЛЪЧдкдЄЯШЩшжУКУЕФвЛЖбЛ§ФОжаЃЌАДеевЛЖЈЕФВпТдШЅДюНЈвЛИізщКЯЕФЭјТчЃЌЫљгаЕФЭјТчЕЅдЊШдШЛЪЧШЫРрЩшжУКУЕФЁЃ
НВАзСЫОЭЪЧУцЖдетаЉГЁОАЃЌПЦбЇМвУЧвбОжЊЕРШчКЮШЅзіЃЌЕЋЪЧБраДИїжжИїбљЕФЭјТчФЃаЭЁЂЕїећГЌВЮЪ§ЁЂбЕСЗЕШЃЌашвЊКФЗбДѓСПЕФЪБМфМАН№ЧЎЁЃЖјAutoMLПЩвдЭЈЙ§ПЦбЇЛЏЕФНЈФЃЫуЗЈЃЌгааЇЕФЬсИпНЈФЃаЇТЪМАжЪСПЃЌМѕЩйГЩБОЁЃЫљвдеыЖдетаЉГЁОАЪЙгУAutoMLЪЧКЯЪЪЕФЁЃ
ЖјдкгябдНЈФЃЁЂвєРжНЈФЃЁЂЭМЯёаоИДЁЂЭјТчбЙЫѕЁЂгявхЗжИюЕШСьгђЃЌгаПЩФмдкетаЉСьгђжаЃЌЛЙУЛгааЮГЩЗЧГЃгааЇЕФНтОіЗНАИЃЌФЧУДAutoMLвВОЭЮоДгЬИЦ№СЫЁЃ
|









