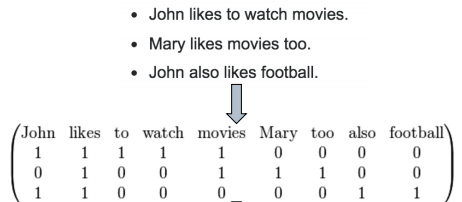
| БрМЭЦМі: |
ЮФеТНщЩмСЫЛњЦїбЇЯАЬиеїЙЄГЬЙЄзїСїГЬжаЪ§ОнДІРэЁЂЬиеїДІРэЁЂФЃаЭбЁдёЁЂНЛВцбщжЄвдМАбАевзюМбГЌВЮЪ§ЕФЯрЙиФкШнЁЃ
БОЮФРДздгкcnblogsЃЌгЩЛ№СњЙћШэМўLucaБрМЁЂЭЦМіЁЃ |
|
ЧАбд
ЬиеїЪЧЪ§ОнжаГщШЁГіРДЕФЖдНсЙћдЄВтгагУЕФаХЯЂЃЌПЩвдЪЧЮФБОЛђепЪ§ОнЁЃЬиеїЙЄГЬЪЧЪЙгУзЈвЕБГОАжЊЪЖКЭММЧЩДІРэЪ§ОнЃЌЪЙЕУЬиеїФмдкЛњЦїбЇЯАЫуЗЈЩЯЗЂЛгИќКУЕФзїгУЕФЙ§ГЬЁЃЙ§ГЬАќКЌСЫЬиеїЬсШЁЁЂЬиеїЙЙНЈЁЂЬиеїбЁдёЕШФЃПщЁЃ
ЬиеїЙЄГЬЕФФПЕФЪЧЩИбЁГіИќКУЕФЬиеїЃЌЛёШЁИќКУЕФбЕСЗЪ§ОнЁЃвђЮЊКУЕФЬиеїОпгаИќЧПЕФСщЛюадЃЌПЩвдгУМђЕЅЕФФЃаЭзібЕСЗЃЌИќПЩвдЕУЕНгХауЕФНсЙћЁЃЁАЙЄгћЩЦЦфЪТЃЌБиЯШРћЦфЦїЁБЃЌЬиеїЙЄГЬПЩвдРэНтЮЊРћЦфЦїЕФЙ§ГЬЁЃЛЅСЊЭјЙЋЫОРяДѓВПЗжИДдгЕФФЃаЭЖМЪЧМЋЩйЪ§ЕФЪ§ОнПЦбЇМвдкзіЃЌДѓЖрЪ§ЙЄГЬЪІУЧзіЕФЪТЧщЛљБОЪЧдкЪ§ОнВжПтРяАсзЉЃЌВЛЖЯЕиЪ§ОнЧхЯДЃЌдйвЛИіЪЧЗжЮівЕЮёВЛЖЯЕиевЬиеїЁЃ
Р§ШчЃЌФГЙуИцВПУХЕФЪ§ОнЭкОђЙЄГЬЪІЃЌ2жмФкПЩвдЭъГЩвЛДЮЬиеїЕќДњЃЌвЛИідТзѓгвПЩвдЭъГЩФЃаЭЕФаЁгХЛЏЃЌРДЬсЩ§aucЁЃ
1. Ъ§ОнВЩМЏ / ЧхЯД / ВЩбљ
Ъ§ОнВЩМЏЃКЪ§ОнВЩМЏЧАашвЊУїШЗВЩМЏФФаЉЪ§ОнЃЌвЛАуЕФЫМТЗЮЊЃКФФаЉЪ§ОнЖдзюКѓЕФНсЙћдЄВтгаАяжњЃПЪ§ОнЮвУЧФмЙЛВЩМЏЕНТ№ЃПЯпЩЯЪЕЪБМЦЫуЕФЪБКђЛёШЁЪЧЗёПьНнЃП
ОйР§1ЃКЮвЯждквЊдЄВтгУЛЇЖдЩЬЦЗЕФЯТЕЅЧщПіЃЌЛђепЮввЊИјгУЛЇзіЩЬЦЗЭЦМіЃЌФЧЮвашвЊВЩМЏЪВУДаХЯЂФиЃП
-ЕъМвЃКЕъЦЬЕФЦРЗжЁЂЕъЦЬРрБ№ЁЁ
-ЩЬЦЗЃКЩЬЦЗЦРЗжЁЂЙКТђШЫЪ§ЁЂбеЩЋЁЂВФжЪЁЂСьзгаЮзДЁЁ
-гУЛЇЃКРњЪЗаХЯЂЃЈЙКТђЩЬЦЗЕФзюЕЭМлзюИпМлЃЉЁЂЯћЗбФмСІЁЂЩЬЦЗЭЃСєЪБМфЁЁ
Ъ§ОнЧхЯДЃК Ъ§ОнЧхЯДвВЪЧКмживЊЕФвЛВНЃЌЛњЦїбЇЯАЫуЗЈДѓЖрЪ§ЪБКђОЭЪЧвЛИіМгЙЄЛњЦїЃЌжСгкзюКѓЕФВњЦЗШчКЮЃЌШЁОігкдВФСЯЕФКУЛЕЁЃЪ§ОнЧхЯДОЭЪЧвЊШЅГ§дрЪ§ОнЃЌБШШчФГаЉЩЬЦЗЕФЫЂЕЅЪ§ОнЁЃ
ФЧУДШчКЮХаЖЈдрЪ§ОнФиЃП
1) МђЕЅЪєадХаЖЈЃКвЛИіШЫЩэИп3Уз+ЕФШЫЃЛвЛИіШЫвЛИідТТђСЫ10wЕФЗЂПЈЁЃ
2) зщКЯЛђЭГМЦЪєадХаЖЈЃККХГЦдкУзЙњШДipвЛжБЖМЪЧДѓТНЕФаТЮХдФЖСгУЛЇЃПФувЊХаЖЈвЛИіШЫЪЧЗёЛсТђРКЧђаЌЃЌбљБОжаХЎадгУЛЇ85%ЃП
3) ВЙЦыПЩЖдгІЕФШБЪЁжЕЃКВЛПЩаХЕФбљБОЖЊЕєЃЌШБЪЁжЕМЋЖрЕФзжЖЮПМТЧВЛгУЁЃ
Ъ§ОнВЩбљЃКВЩМЏЁЂЧхЯДЙ§Ъ§ОнвдКѓЃЌе§ИКбљБОЪЧВЛОљКтЕФЃЌвЊНјааЪ§ОнВЩбљЁЃВЩбљЕФЗНЗЈгаЫцЛњВЩбљКЭЗжВуГщбљЁЃЕЋЪЧЫцЛњВЩбљЛсгавўЛМЃЌвђЮЊПЩФмФГДЮЫцЛњВЩбљЕУЕНЕФЪ§ОнКмВЛОљдШЃЌИќЖрЕФЪЧИљОнЬиеїВЩгУЗжВуГщбљЁЃЁЁЁЁ
е§ИКбљБОВЛЦНКтДІРэАьЗЈЃК
е§бљБО >> ИКбљБОЃЌЧвСПЖМЭІДѓ => downsampling
е§бљБО >> ИКбљБОЃЌСПВЛДѓ =>
ЁЁ1ЃЉВЩМЏИќЖрЕФЪ§Он
ЁЁ2ЃЉЩЯВЩбљ/oversampling(БШШчЭМЯёЪЖБ№жаЕФОЕЯёКЭа§зЊ)
ЁЁ3ЃЉаоИФЫ№ЪЇКЏЪ§/loss function (ЩшжУбљБОШЈжи)
2. ЬиеїДІРэ
2.1 Ъ§жЕаЭ
1. ЗљЖШЕїећ/ЙщвЛЛЏЃКpythonжаЛсгавЛаЉКЏЪ§БШШчpreprocessing.MinMaxScaler()НЋЗљЖШЕїећЕН
[0,1] ЧјМфЁЃ
2.ЭГМЦжЕЃКАќРЈmax, min, mean, stdЕШЁЃpythonжагУpandasПтађСаЛЏЪ§ОнКѓЃЌПЩвдЕУЕНЪ§ОнЕФЭГМЦжЕЁЃ

3.РыЩЂЛЏЃКАбСЌајжЕзЊГЩЗЧЯпадЪ§ОнЁЃР§ШчЕчЩЬЛсгаИїжжСЌајЕФМлИёБэЃЌДг0.03ЕН100дЊЃЌМйШчвдвЛдЊЧЎЕФМфОрЗжИюГЩ99ИіЧјМфЃЌгУ99ЮЌЕФЯђСПДњБэУПвЛИіМлИёЫљДІЕФЧјМфЃЌ1.2дЊКЭ1.6дЊЕФЯђСПЖМЪЧ
[0,1,0,Ё,0]ЁЃpd.cut() ПЩвджБНгАбЪ§ОнЗжГЩШєИЩЖЮЁЃ
4.жљзДЗжВМЃКРыЩЂЛЏКѓЭГМЦУПИіЧјМфЕФИіЪ§зіжљзДЭМЁЃ
2.2 РрБ№аЭ
РрБ№аЭвЛАуЪЧЮФБОаХЯЂЃЌБШШчбеЩЋЪЧКьЩЋЁЂЛЦЩЋЛЙЪЧРЖЩЋЃЌЮвУЧДцДЂЪ§ОнЕФЪБКђОЭашвЊЯШДІРэЪ§ОнЁЃДІРэЗНЗЈгаЃК
1. one-hotБрТыЃЌБрТыКѓЕУЕНбЦБфСПЁЃЭГМЦетИіЬиеїЩЯгаЖрЩйРрЃЌОЭЩшжУМИЮЌЕФЯђСПЃЌpd.get_dummies()ПЩвдНјааone-hotБрТыЁЃ
ЃВ. HashБрТыГЩДЪЯђСПЃК
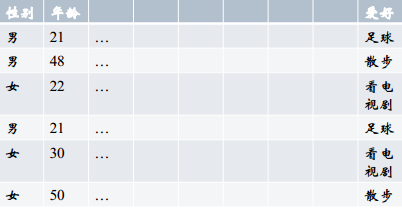
ЃГ. HistogramгГЩфЃКАбУПвЛСаЕФЬиеїФУГіРДЃЌИљОнtargetФкШнзіЭГМЦЃЌАбtargetжаЕФУПИіФкШнЖдгІЕФАйЗжБШЬюЕНЖдгІЕФЯђСПЕФЮЛжУЁЃгХЕуЪЧАбСНИіЬиеїСЊЯЕЦ№РДЁЃ
ЩЯБэжаЃЌЮвУЧРДЭГМЦЁАадБ№гыАЎКУЕФЙиЯЕЁБЃЌадБ№гаЁАФаЁБЁЂЁАХЎЁБЃЌАЎКУгаШ§жжЃЌБэЪОГЩЯђСП
[ЩЂВНЁЂзуЧђЁЂПДЕчЪгОч]ЃЌЗжБ№МЦЫуФаадКЭХЎаджаУПИіАЎКУЕФБШР§ЕУЕНЃКФа[1/3, 2/3, 0]ЃЌХЎ[0,
1/3, 2/3]ЁЃМДЗДгГСЫСНИіЬиеїЕФЙиЯЕЁЃ
2.3 ЪБМфаЭ
ЪБМфаЭЬиеїЕФгУДІЬиБ№ДѓЃЌМШПЩвдПДзіСЌајжЕЃЈГжајЪБМфЁЂМфИєЪБМфЃЉЃЌвВПЩвдПДзіРыЩЂжЕЃЈаЧЦкМИЁЂМИдТЗнЃЉЁЃ
СЌајжЕ
ЁЁЁЁa) ГжајЪБМф(ЕЅвГфЏРРЪБГЄ)
ЁЁЁЁb) МфИєЪБМф(ЩЯДЮЙКТђ/ЕуЛїРыЯждкЕФЪБМф)
РыЩЂжЕ
ЁЁЁЁa) вЛЬьжаФФИіЪБМфЖЮ(hour_0-23)
ЁЁЁЁb) вЛжмжааЧЦкМИ(week_monday...)
ЁЁЁЁc) вЛФъжаФФИіаЧЦк
ЁЁЁЁd) вЛФъжаФФИіМОЖШ
ЁЁЁЁe) ЙЄзїШе/жмФЉ
Ъ§ОнЭкОђжаОГЃЛсгУЪБМфзїЮЊживЊЬиеїЃЌБШШчЕчЩЬПЩвдЗжЮіНкМйШеКЭЙКЮяЕФЙиЯЕЃЌвЛЬьжагУЛЇЯВКУЕФЙКЮяЪБМфЕШЁЃ
2.4 ЮФБОаЭ
ЃБ. ДЪДќЃКЮФБОЪ§ОндЄДІРэКѓЃЌШЅЕєЭЃгУДЪЃЌЪЃЯТЕФДЪзщГЩЕФlistЃЌдкДЪПтжаЕФгГЩфЯЁЪшЯђСПЁЃPythonжагУCountVectorizerДІРэДЪДќЃЎ
ЃВ. АбДЪДќжаЕФДЪРЉГфЕНn-gramЃКn-gramДњБэnИіДЪЕФзщКЯЁЃБШШчЁАЮвЯВЛЖФуЁБЁЂЁАФуЯВЛЖЮвЁБетСНОфЛАШчЙћгУДЪДќБэЪОЕФЛАЃЌЗжДЪКѓАќКЌЯрЭЌЕФШ§ИіДЪЃЌзщГЩвЛбљЕФЯђСПЃКЁАЮв
ЯВЛЖ ФуЁБЁЃЯдШЛСНОфЛАВЛЪЧЭЌвЛИівтЫМЃЌгУn-gramПЩвдНтОіетИіЮЪЬтЁЃШчЙћгУ2-gramЃЌФЧУДЁАЮвЯВЛЖФуЁБЕФЯђСПжаЛсМгЩЯЁАЮвЯВЛЖЁБКЭЁАЯВЛЖФуЁБЃЌЁАФуЯВЛЖЮвЁБЕФЯђСПжаЛсМгЩЯЁАФуЯВЛЖЁБКЭЁАЯВЛЖЮвЁБЁЃетбљОЭЧјЗжПЊРДСЫЁЃ
ЃГ. ЪЙгУTF-IDFЬиеїЃКTF-IDFЪЧвЛжжЭГМЦЗНЗЈЃЌгУвдЦРЙРвЛзжДЪЖдгквЛИіЮФМўМЏЛђвЛИігяСЯПтжаЕФЦфжавЛЗнЮФМўЕФживЊГЬЖШЁЃзжДЪЕФживЊадЫцзХЫќдкЮФМўжаГіЯжЕФДЮЪ§ГЩе§БШдіМгЃЌЕЋЭЌЪБЛсЫцзХЫќдкгяСЯПтжаГіЯжЕФЦЕТЪГЩЗДБШЯТНЕЁЃTF(t)
= (ДЪtдкЕБЧАЮФжаГіЯжДЮЪ§) / (tдкШЋВПЮФЕЕжаГіЯжДЮЪ§)ЃЌIDF(t) = ln(змЮФЕЕЪ§/
КЌtЕФЮФЕЕЪ§)ЃЌTF-IDFШЈжи = TF(t) * IDF(t)ЁЃздШЛгябдДІРэжаОГЃЛсгУЕНЁЃ
2.5 ЭГМЦаЭ
МгМѕЦНОљЃКЩЬЦЗМлИёИпгкЦНОљМлИёЖрЩйЃЌгУЛЇдкФГИіЦЗРрЯТЯћЗбГЌЙ§ЦНОљгУЛЇЖрЩйЃЌгУЛЇСЌајЕЧТМЬьЪ§ГЌЙ§ЦНОљЖрЩй...
ЗжЮЛЯпЃКЩЬЦЗЪєгкЪлГіЩЬЦЗМлИёЕФЖрЩйЗжЮЛЯпДІ
ДЮађаЭЃКХХдкЕкМИЮЛ
БШР§РрЃКЕчЩЬжаЃЌКУ/жа/ВюЦРБШР§ЃЌФувбГЌЙ§ШЋЙњАйЗжжЎЁЕФЭЌбЇ
ЁЁЁЁ
2.6 зщКЯЬиеї
1. ЦДНгаЭЃКМђЕЅЕФзщКЯЬиеїЁЃР§ШчЭкОђгУЛЇЖдФГжжРраЭЕФЯВАЎЃЌЖдгУЛЇКЭРраЭзіЦДНгЁЃе§ИКШЈжиЃЌДњБэЯВЛЖЛђВЛЯВЛЖФГжжРраЭЁЃ
- user_id&&category: 10001&&ХЎШЙ
10002&&ФаЪПХЃза
- user_id&&style: 10001&&РйЫП
10002&&ШЋУоЁЁ
2. ФЃаЭЬиеїзщКЯЃК
- гУGBDTВњГіЬиеїзщКЯТЗОЖ
- зщКЯЬиеїКЭдЪМЬиеївЛЦ№ЗХНјLRбЕСЗ
3. ЬиеїбЁдё
ЬиеїбЁдёЃЌОЭЪЧДгЖрИіЬиеїжаЃЌЬєбЁГівЛаЉЖдНсЙћдЄВтзюгагУЕФЬиеїЁЃвђЮЊдЪМЕФЬиеїжаПЩФмЛсгаШпгрКЭдыЩљЁЃ
ЬиеїбЁдёКЭНЕЮЌгаЪВУДЧјБ№ФиЃПЧАепжЛЬпЕєдБОЬиеїРяКЭНсЙћдЄВтЙиЯЕВЛДѓЕФЃЌ
КѓепзіЬиеїЕФМЦЫузщКЯЙЙГЩаТЬиеїЁЃ
3.1 Й§ТЫаЭ
- ЗНЗЈЃК? ЦРЙРЕЅИіЬиеїКЭНсЙћжЕжЎМфЕФЯрЙиГЬЖШЃЌ ХХађСєЯТTopЯрЙиЕФЬиеїВПЗжЁЃ
- ЦРМлЗНЪНЃКPearsonЯрЙиЯЕЪ§ЃЌ ЛЅаХЯЂЃЌ ОрРыЯрЙиЖШЁЃ
- ШБЕуЃКжЛЦРЙРСЫЕЅИіЬиеїЖдНсЙћЕФгАЯьЃЌУЛгаПМТЧЕНЬиеїжЎМфЕФЙиСЊзїгУЃЌ
ПЩФмАбгагУЕФЙиСЊЬиеїЮѓЬпЕєЁЃвђДЫЙЄвЕНчЪЙгУБШНЯЩйЁЃ
- pythonАќЃКSelectKBestжИЖЈЙ§ТЫИіЪ§ЁЂSelectPercentileжИЖЈЙ§ТЫАйЗжБШЁЃ
3.2 АќЙќаЭ
- ЗНЗЈЃКАбЬиеїбЁдёПДзівЛИіЬиеїзгМЏЫбЫїЮЪЬтЃЌ ЩИбЁИїжжЬиеїзгМЏЃЌ
гУФЃаЭЦРЙРаЇЙћЁЃ
- ЕфаЭЫуЗЈЃКЁАЕнЙщЬиеїЩОГ§ЫуЗЈЁБЁЃ
- гІгУдкТпМЛиЙщЕФЙ§ГЬЃКгУШЋСПЬиеїХмвЛИіФЃаЭЃЛИљОнЯпадФЃаЭЕФЯЕЪ§(ЬхЯжЯрЙиад)ЃЌЩОЕє5-10%ЕФШѕЬиеїЃЌЙлВьзМШЗТЪ/aucЕФБфЛЏЃЛж№ВННјааЃЌ
жБжСзМШЗТЪ/aucГіЯжДѓЕФЯТЛЌЭЃжЙЁЃ
- pythonАќЃКRFE
ЁЁЁЁ
3.3 ЧЖШыаЭ
- ЗНЗЈЃКИљОнФЃаЭРДЗжЮіЬиеїЕФживЊадЃЌзюГЃМћЕФЗНЪНЮЊгУе§дђЛЏЗНЪНРДзіЬиеїбЁдёЁЃ
- ОйР§ЃКзюдчдкЕчЩЬгУLRзіCTRдЄЙРЃЌ дк3-5вкЮЌЕФЯЕЪ§ЬиеїЩЯгУL1е§дђЛЏЕФLRФЃаЭЁЃЩЯвЛЦЊНщЩмСЫL1е§дђЛЏгаНиЖЯзїгУЃЌЪЃгр2-3ЧЇЭђЕФfeatureЃЌ
втЮЖзХЦфЫћЕФfeatureживЊЖШВЛЙЛЁЃ
- pythonАќЃКfeature_selection.SelectFromModelбЁГіШЈжиВЛЮЊ0ЕФЬиеїЁЃ
ЪзЯШПДЯТзмЭМЃК
4.ФЃаЭбЁдёЃК
1ЃЉНЛВцбщжЄ
НЛВцбщжЄМЏзіВЮЪ§/ФЃаЭбЁдё
ВтЪдМЏжЛзіФЃаЭаЇЙћЦРЙР
2ЃЉKелНЛВцбщжЄЃК
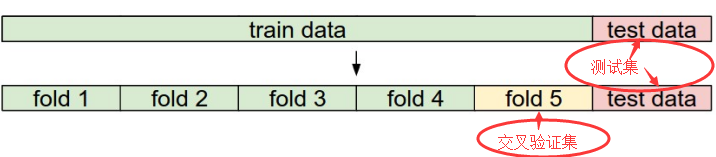
дкPythonжагаетбљЕФКЏЪ§гУгкдкНЛВцбщжЄЙ§ГЬжаЖдВЮЪ§ЕФбЁдё
5.ФЃаЭЕФзДЬЌ
a. Й§ФтКЯЃКЙ§ФтКЯЃЈoverfittingЃЉЪЧжИдкФЃаЭВЮЪ§ФтКЯЙ§ГЬжаЕФЮЪЬтЃЌгЩгкбЕСЗЪ§ОнАќКЌГщбљЮѓВюЃЌбЕСЗЪБЃЌИДдгЕФФЃаЭНЋГщбљЮѓВювВПМТЧдкФкЃЌНЋГщбљЮѓВювВНјааСЫКмКУЕФФтКЯЁЃ
b. ЧЗФтКЯ ЃКФЃаЭдкбЕСЗЙ§ГЬжаУЛгабЕСЗГфЗжЃЌЕМжТФЃаЭКмКУЕФБэЯжГіЪ§ОндгааджЪЁЃ
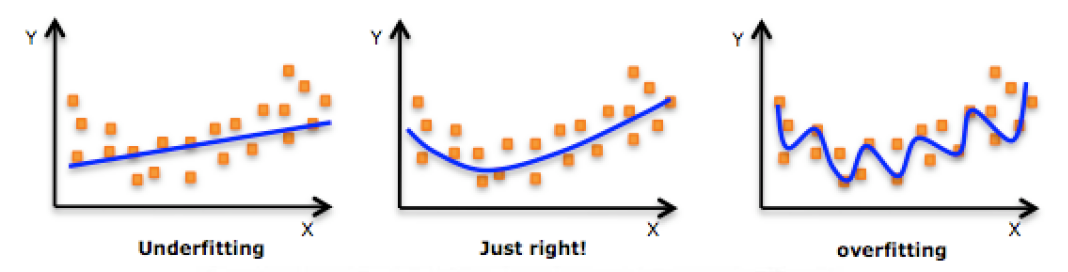
ФЃаЭзДЬЌбщжЄЙЄОпЃКбЇЯАЧњЯп
ЭЈЙ§дкИјЖЈбЕСЗбљБОдіМгЕФЪБКђЃЌВтЪдЛњКЭбЕСЗМЏжазМШЗТЪЕФБфЛЏЧїЪЦПЩвдПДЕНЯждкФЃаЭЕФзДЬЌЁЃ
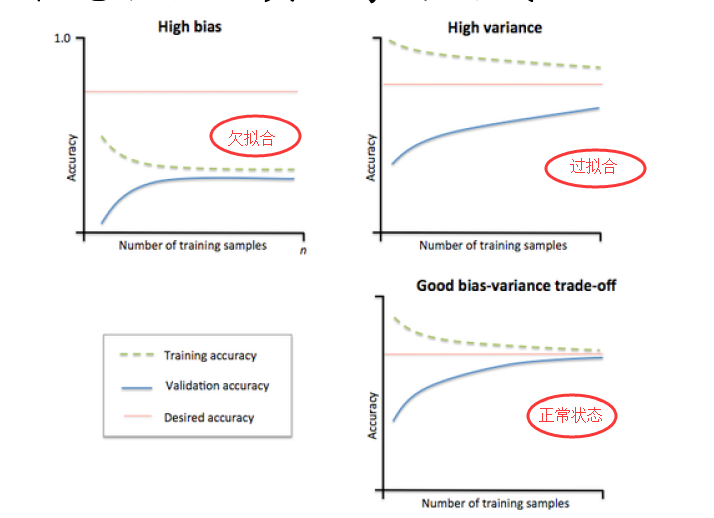
дѕУДЗРжЙЙ§ФтКЯФиЃП
ЛёШЁИќЖрЪ§Он: ШУФЃаЭЁИПДМћЁЙОЁПЩФмЖрЕФЁИР§ЭтЧщПіЁЙЃЌЫќОЭЛсВЛЖЯаое§здМКЃЌДгЖјЕУЕНИќКУЕФНсЙћЃЛ
a)ДгЪ§ОндДЭЗВЩМЏИќЖрЪ§Он
b) ЭЈЙ§вЛЖЈЙцдђРЉГфЪ§ОнМЏЃЌШчМгШыЫцЛњдыЩљЃЌЭМЕФа§зЊЦНвЦЫѕЗХ
c) ВЩбљММЪѕ
МѕаЁФЃаЭЕФИДдгЖШЃКМѕЩйЪ§ЕФПУЪїЃЌЭјТчВуЪ§ЕШЃЛ
МѕЩйбЕСЗЪБМф Early stoppingЃКЬсЧАжежЙЃЈЕБбщжЄМЏЩЯЕФаЇЙћБфВюЕФЪБКђЃЉЃЛ
МгШые§дђЯю / діДѓе§дђЛЏЯЕЪ§ЃКетРрЗНЗЈжБНгНЋШЈжЕЕФДѓаЁМгШыЕН Cost РяЃЌдкбЕСЗЕФЪБКђЯожЦШЈжЕБфДѓЃЛ
ЪЙгУМЏГЩбЇЯАЃКзлКЯЖрИібЇЯАЦїЕФНсЙћЃЛ
DropoutЃКРрЫЦгкМЏГЩбЇЯАЃЌЪЧЕФЭјТчНсЙЙЗЂЩњСЫИФБф
дѕбљЗРжЙЧЗФтКЯЃП ЃЈвЛАуКмЩйГіЯжЃЉ
евИќЖрЕФЬиеї
МѕаЁе§дђЛЏЯЕЪ§
6.ФЃаЭЗжЮі
1ЃЉЯпЯТФЃаЭШЈжиЗжЮіЃКЯпадЛђепЯпадkernelЕФmodel
Linear Regression
Logistic Regression
LinearSVM
2ЃЉЖдШЈжиОјЖджЕИп/ЕЭЕФЬиеї
зіИќЯИЛЏЕФЙЄзї
ЬиеїзщКЯ
3ЃЉ Bad-caseЗжЮіЁЁЁЁ
ЗжРрЮЪЬт
ФФаЉбЕСЗбљБОЗжДэСЫЃП
ЮвУЧФФВПЗжЬиеїЪЙЕУЫќзіСЫетИіХаЖЈЃП
етаЉbad casesгаУЛгаЙВад
ЪЧЗёгаЛЙУЛЭкОђЕФЬиад
ЛиЙщЮЪЬт
ФФаЉбљБОдЄВтНсЙћВюОрДѓЃЌЮЊЪВУДЃП
7.ФЃаЭШкКЯ
1ЃЉЦНОљЗЈ
1. МђЕЅЦНОљЗЈЃЈsimple averagingЃЉ
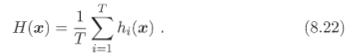
2. МгШЈЦНОљЗЈЃЈweighted averagingЃЉ
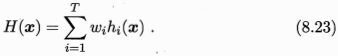
зЂвтЃКБиаыЪЙгУЗЧИКШЈжиВХФмШЗБЃМЏГЩадФмгХгкЕЅвЛзюМбИіЬхбЇЯАЦїЃЌвђДЫдкМЏГЩбЇЯАжавЛАуЖдбЇЯАЦїЕФШЈжиЗЈвдЗЧИКдМЪјЁЃ
МђЕЅЦНОљЗЈЦфЪЕЪЧМгШЈЦНОљЗЈСюw=1/TЕФЬиР§ЁЃМЏГЩбЇЯАжаЕФИїжжНсКЯЗНЗЈЦфЪЕЖМПЩвдЪгЮЊМгШЈЦНОљЗЈЕФЬиР§ЛђБфЬхЁЃМгШЈЦНОљЗЈЕФШЈживЛАуЪЧДгбЕСЗЪ§ОнжабЇЯАЖјЕУЁЃгЩгкЯжЪЕШЮЮёжабљБОВЛГфЗжЛђДцдкдыЩљЃЌЪЙЕУбЇЕУЕФШЈжиВЛЭъШЋПЩППЃЌгаЪБМгШЈЦНОљЗЈЮДБивЛЖЈгХгкМђЕЅЦНОљЗЈЁЃ
2ЃЉЭЖЦБЗЈ
ЖдЗжРрШЮЮёРДЫЕЃЌзюГЃМћЕФНсКЯВпТдЪЙгУЭЖЦБЗЈ
1. ОјЖдЖрЪ§ЭЖЦБЗЈЃЈmajority votingЃЉЃКМДШєФГБъМЧЕУЦБЙ§АыЪ§ЃЌдђдЄВтЮЊИУБъМЧЃЛЗёдђОмОјдЄВт
2. ЯрЖдЖрЪ§ЭЖЦБЗЈЃЈplurality votingЃЉЃКМДдЄВтЮЊЕУЦБзюЖрЕФБъМЧЃЌШєЭЌЪБгаЖрИіБъМЧЛёзюИпЦБЃЌдђДгжаЫцЛњбЁШЁвЛИіЁЃ
3. МгШЈЭЖЦБЗЈЃЈweighted votingЃЉЃКОјЖдЖрЪ§ЭЖЦБЗЈдкПЩППадвЊЧѓНЯИпЕФбЇЯАШЮЮёжаЪЧвЛИіКмКУЕФЛњжЦЃЌШєБиаыЬсЙЉНсЙћЃЌдђЪЙгУЯрЖдЖрЪ§ЭЖЦБЗЈЁЃ
РрБъМЧЃКЪЙгУРрБъМЧЕФЭЖЦБврГЦЁАгВЭЖЦБЁБЃЈhard votingЃЉЁЃ
РрИХТЪЃКЪЙгУРрИХТЪЕФЭЖЦБврГЦЁАШэЭЖЦБЁБЃЈsoft votingЃЉЁЃ
вдЩЯСНжжВЛФмЛьгУЃЌШєЛљбЇЯАЦїВњЩњЗжРржУаХЖШЃЌР§ШчжЇГжЯђСПЛњЕФЗжРрМфИєжЕЃЌашЪЙгУвЛаЉММЪѕШчPlattЫѕЗХЁЂЕШЗжЛиЙщЁЂЕШНјаааЃзМКѓВХФмзїЮЊРрИХТЪЪЙгУЁЃШєЛљбЇЯАЦїЕФРраЭВЛЭЌЃЌдђЦфРрИХТЪжЕВЛФмжБНгНјааБШНЯЃЌПЩНЋРрИХТЪЪфГізЊЛЏЮЊРрБъМЧЪфГіШЛКѓдйЭЖЦБЁЃ
3ЃЉStackingЃКStackingЗНЗЈЪЧжИбЕСЗвЛИіФЃаЭгУгкзщКЯЦфЫћИїИіФЃаЭЁЃЪзЯШЮвУЧЯШбЕСЗЖрИіВЛЭЌЕФФЃаЭЃЌШЛКѓАбжЎЧАбЕСЗЕФИїИіФЃаЭЕФЪфГіЮЊЪфШыРДбЕСЗвЛИіФЃаЭЃЌвдЕУЕНвЛИізюжеЕФЪфГіЁЃРэТлЩЯЃЌStackingПЩвдБэЪОЩЯУцЬсЕНЕФСНжжEnsembleЗНЗЈЃЌжЛвЊЮвУЧВЩгУКЯЪЪЕФФЃаЭзщКЯВпТдМДПЩЁЃЕЋдкЪЕМЪжаЃЌЮвУЧЭЈГЃЪЙгУlogisticЛиЙщзїЮЊзщКЯВпТдЁЃ |









