| 编辑推荐: |
本文主要讲解了可视化图形+源码分析帮助大家快速深入地理解Transformer原理,希望对您的学习有所帮助。
本文来自微信公众号 猫蛋儿的小窝,作者吸金小凡,由火龙果软件刘琛编辑推荐。 |
|
一、Transformer简介
1.1、Seq2seq model
Transformer(变形金刚)简单来讲,我们可以将其看作一个seq2seq with self-attention model。我们可以这么理解,Transformer整体作为一个翻译器,输入法文的句子,模型将其翻译为英文输出。
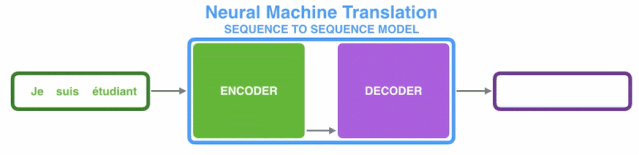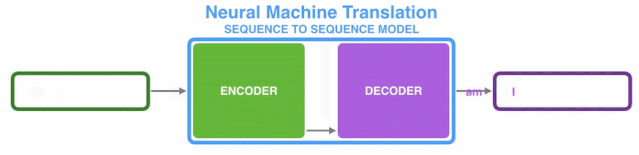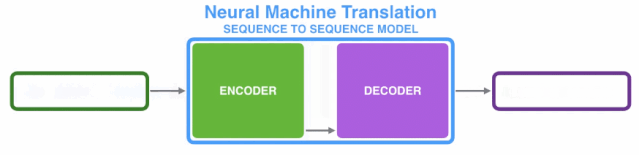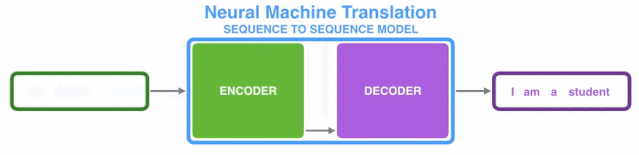
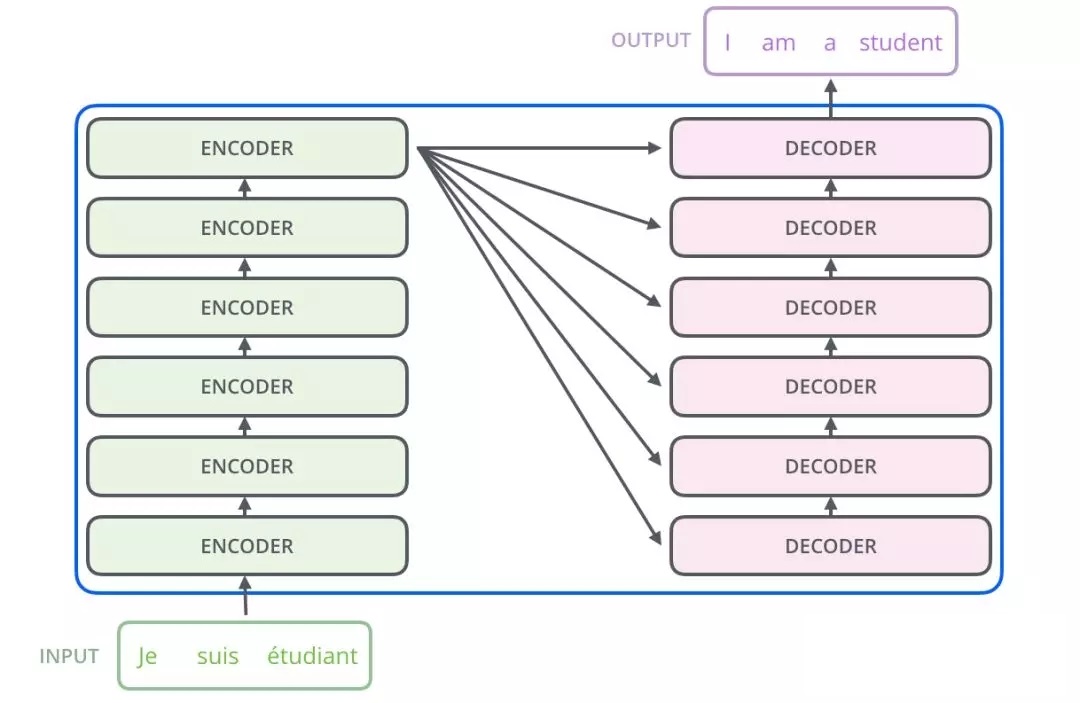
1.2、Transformer整体框架
由上图知,Transformer主要由encoder和decoder两部分组成。在Transformer的paper中,encoder和decoder均由6个encoder layer和decoder layer组成,通常我们称之为encoder block。
1.3、Transformer框架源码
我们已经知道Transformer主要由encoder和decoder两部分组成。那么代码中构建也是非常简单的,关键代码如下:
class Transformer(nn.Module):
def __init__(self):
super(Transformer, self).__init__()
# Transformer的两个组成部分
self.encoder = Encoder()
self.decoder = Decoder()
self.projection = nn.Linear(d_model, tgt_vocab_size,
bias=False) |
二、Encoder编码器
Encoder总体的构建代码如下:
class Encoder(nn.Module):
def __init__(self):
super(Encoder, self).__init__()
self.src_emb = nn.Embedding(src_vocab_size, d_model)
# 词向量embedding
self.pos_emb = nn.Embedding.from_pretrained (get_sinusoid_encoding_table
(src_len+1, d_model),freeze=True) # 位置向量embedding
# encoder核心操作:由n_layer个encoder block构建得到 encoder
self.layers = nn.ModuleList([EncoderLayer() for
_ in range(n_layers)]) |
EncoderLayer()负责每一个Encoder block的构建:
class EncoderLayer(nn.Module):
def __init__(self):
super(EncoderLayer, self).__init__()
self.enc_self_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet() |
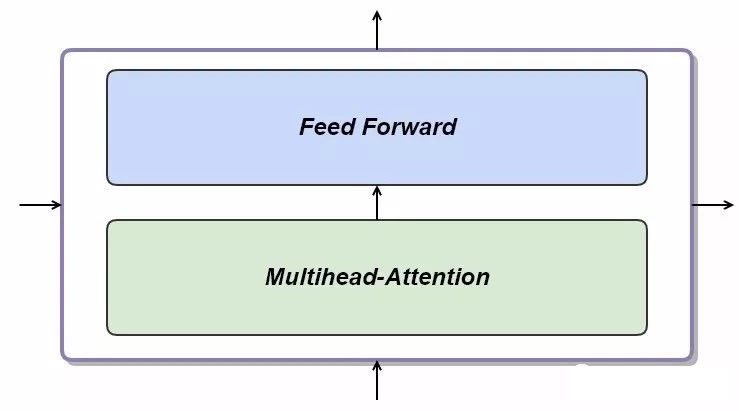
下面我们就来看一下Multi-head Attention和Feed forward的底层原理是如何实现?
2.1、Multi-head Attention
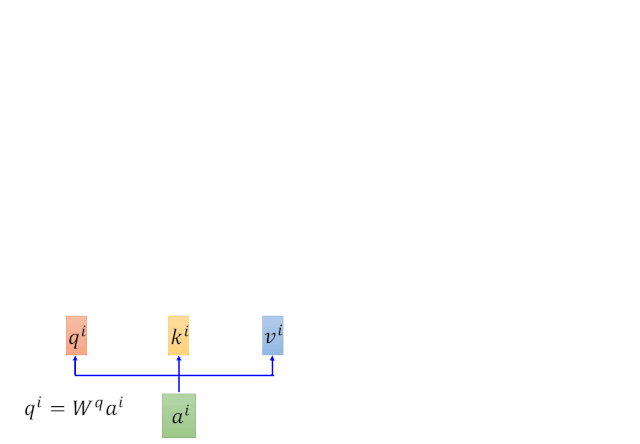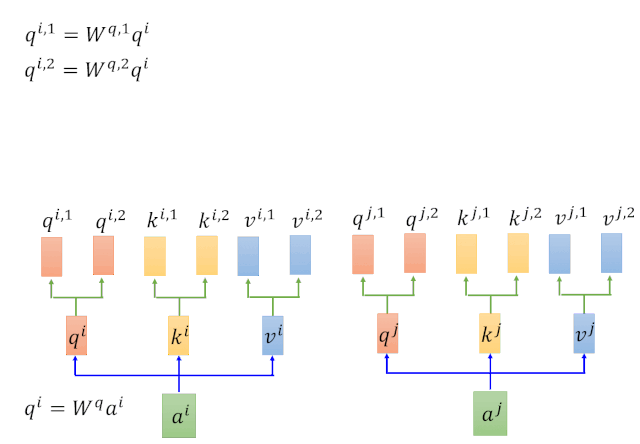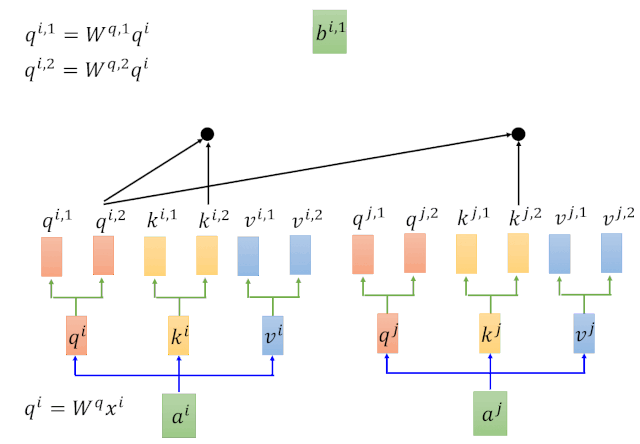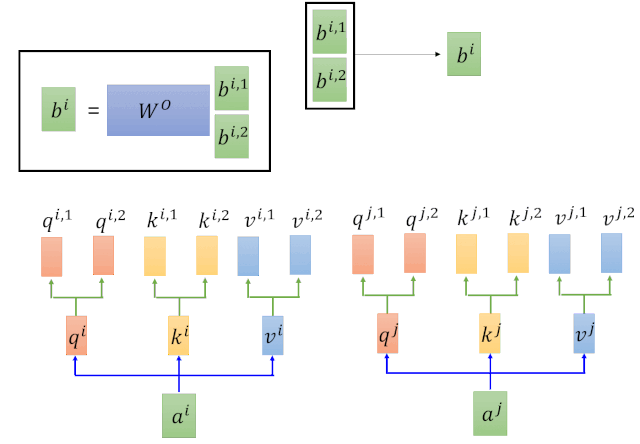
Multihead attention其实就是self-attention的n次计算,简单来讲,其实就是重复的矩阵相乘运算。因此,我们首先要搞清楚Self-attention的运算过程。
2.1.1 Self-Attention
Self-Attention本质上就是一系列矩阵运算。那么它的的计算过程是怎样的呢?我们以输入为x1对应输出为b1为例,进行说明,如下图。
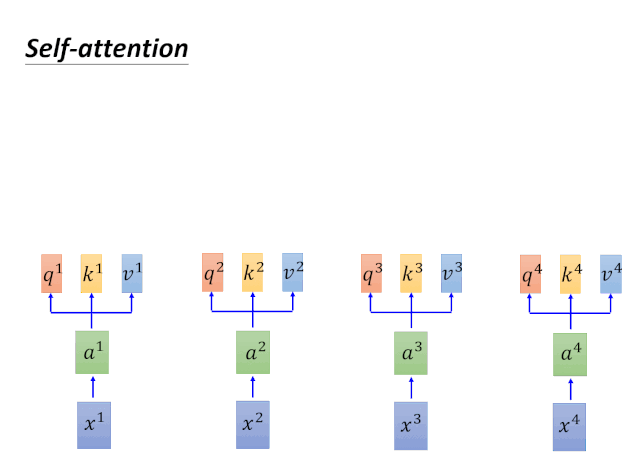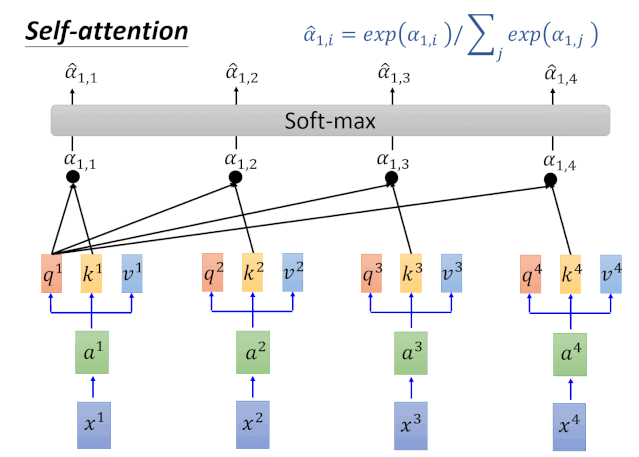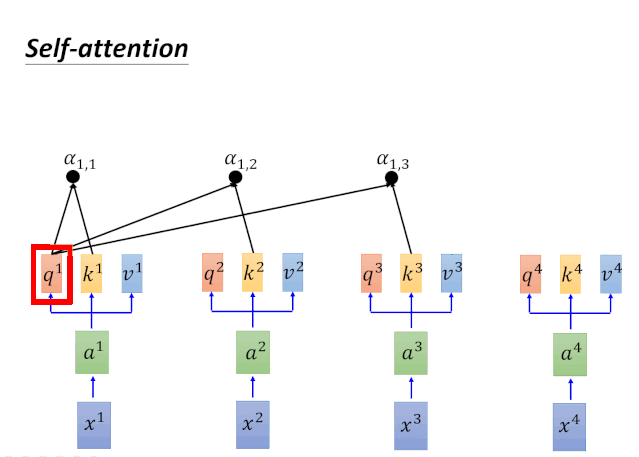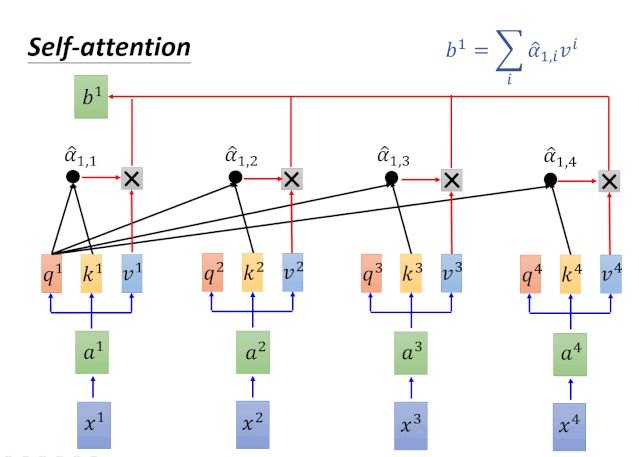
针对以上动图涉及的计算过程,我们在下图进行一一对应:
Self-Attention整体的计算过程用如下图进行归纳:
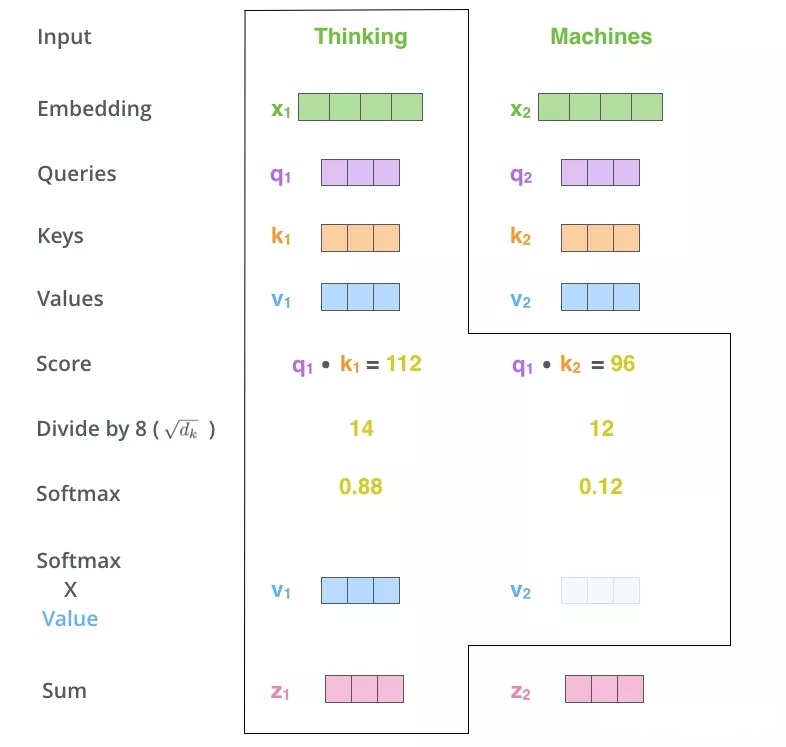
对于Self-attention机制这里就不进行细讲了,博主在前一篇发的文章中进行详细的介绍,小伙伴们可以花两分钟去读一下再回来接着往下看,Self-attention传送门:图解Bert系列之Self-Attention
2.1.2 Multihead-Attention
我们还是先来看代码:
class MultiHeadAttention(nn.Module):
def __init__(self):
super(MultiHeadAttention, self).__init__()
self.W_Q = nn.Linear(d_model, d_k * n_heads)
self.W_K = nn.Linear(d_model, d_k * n_heads)
self.W_V = nn.Linear(d_model, d_v * n_heads)
def forward(self, Q, K, V, attn_mask):
# q: [batch_size x len_q x d_model], k: [batch_size
x len_k x d_model],
v: [batch_size x len_k x d_model]
residual, batch_size = Q, Q.size(0)
# (B, S, D) -proj-> (B, S, D) -split-> (B,
S, H, W) -trans-> (B, H, S, W)
q_s = self.W_Q(Q).view(batch_size, -1, n_heads,
d_k).transpose(1,2)
# q_s: [batch_size x n_heads
x len_q x d_k]
k_s = self.W_K(K).view(batch_size, -1, n_heads,
d_k).transpose(1,2)
# k_s: [batch_size x n_heads
x len_k x d_k]
v_s = self.W_V(V).view(batch_size, -1, n_heads,
d_v).transpose(1,2)
# v_s: [batch_size x n_heads
x len_k x d_v]
attn_mask = attn_mask.unsqueeze(1).repeat(1,
n_heads, 1, 1) # attn_mask : [batch_size x n_heads
x len_q x len_k]
# context: [batch_size x n_heads x len_q x
d_v], attn: [batch_size x n_heads x len_q(=len_k)
x len_k(=len_q)]
context, attn = ScaledDotProductAttention()(q_s,
k_s, v_s, attn_mask)
context = context.transpose(1, 2).contiguous().view(batch_size,
-1, n_heads * d_v) # context: [batch_size x
len_q x n_heads * d_v]
output = nn.Linear(n_heads * d_v, d_model)(context)
return nn.LayerNorm(d_model)(output + residual),
attn # output: [batch_size x len_q x d_model]
|
这里的Transformer是对self-attention做了一个2次的矩阵相乘。理解了Self-attention之后,Multihead attention理解起来是分分钟撒撒水啦。
通过对以上计算步骤的反复迭代,得到Q、K、V三个矩阵。

2.1.3 Position Vector位置向量
模型理解一个句子有两个要素:一是单词的含义,二是单词在句中所处的位置。
在Self-attention中每个单词向量经过计算之后的输出都受到整句的影响,Q、K、V的矩阵运算也都是并行运算,但单词间的顺序信息却被丢失了。因此Google团队在Transformer中使用Position位置向量解决这个问题。
每个单词的嵌入向量会学习单词的含义,所以我们需要输入一些信息,让神经网络知道单词在句中所处的位置。利用我们熟悉的sin、cos三角函数创建位置特异性常量来解决这类问题:
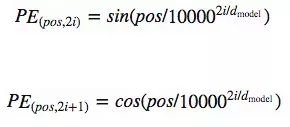
其中,在给词向量添加位置编码之前,我们要扩大词向量的数值,目的是让位置编码相对较小。这意味着向词向量添加位置编码时,词向量的原始含义不会丢失。
注释:位置编码矩阵是一个常量,它的值可以用上面的算式计算出来。把常量嵌入矩阵,然后每个嵌入的单词会根据它所处的位置发生特定转变。

利用Pytorch进行实现:
def get_sinusoid_encoding_table(n_position, d_model):
def cal_angle(position, hid_idx):
return position / np.power(10000, 2 * (hid_idx
// 2) / d_model)
def get_posi_angle_vec(position):
return [cal_angle(position, hid_j) for hid_j in
range (d_model)]
sinusoid_table = np.array([get_posi_angle_vec(pos_i)
for pos_i in range(n_position)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:,
0::2]) # dim 2i
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:,
1::2]) # dim 2i+1
return torch.FloatTensor(sinusoid_table) |
2.2、Feed Forward 前馈神经网络
终于到了encoder的最后一小部分,理解了以上部分,这里的神经网络非常简单了,通过激活函数Relu做一个非线性变换(),然后归一化操作(对应代码中的LayerNorm函数),得到encoder最终的输出结果。
class PoswiseFeedForwardNet(nn.Module):
def __init__(self):
super(PoswiseFeedForwardNet, self).__init__()
self.conv1 = nn.Conv1d(in_channels=d_model, out_channels=d_ff,
kernel_size=1)
self.conv2 = nn.Conv1d(in_channels=d_ff, out_channels=d_model,
kernel_size=1)
def forward(self, inputs):
residual = inputs # inputs : [batch_size, len_q,
d_model]
output = nn.ReLU()(self.conv1(inputs.transpose
(1, 2)))
output = self.conv2(output).transpose(1, 2)
return nn.LayerNorm(d_model)(output + residual) |
三、Decoder解码器
我们再来回顾一下Transformer的整体结构:
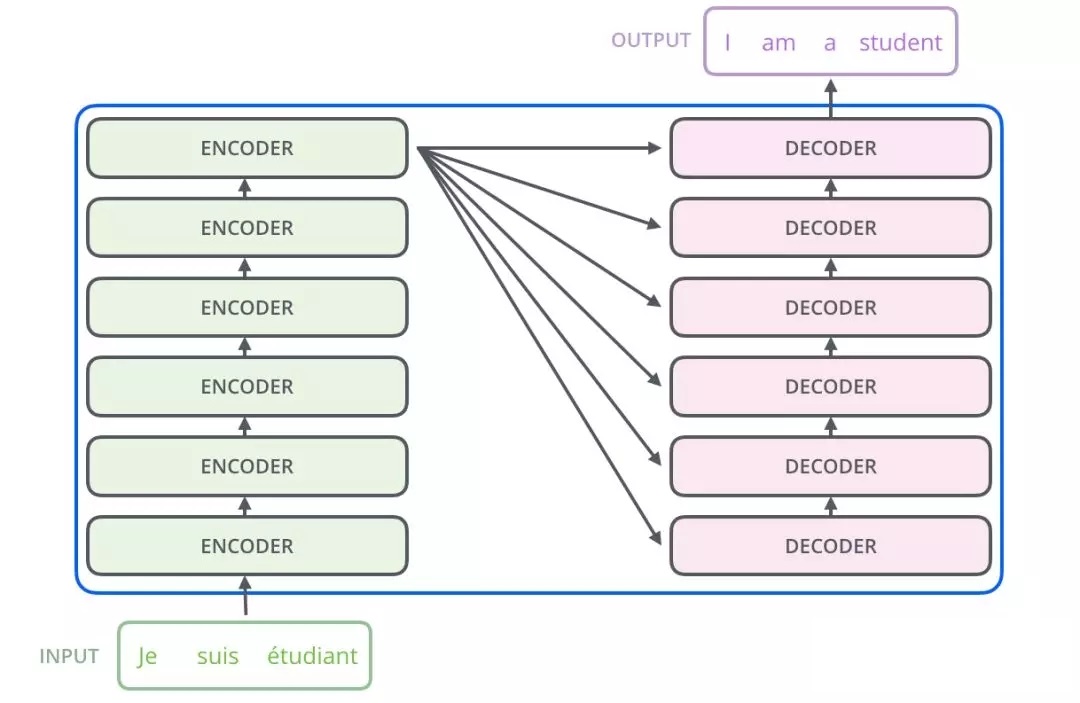
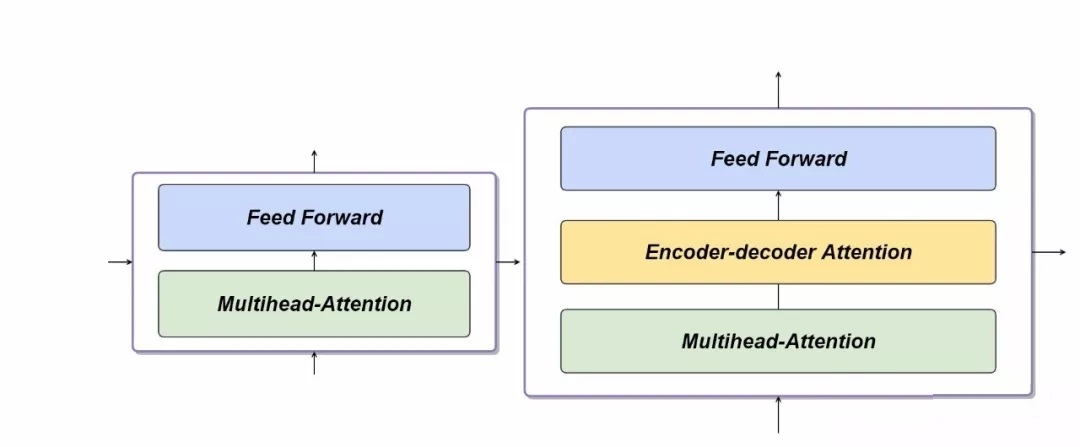
Decoder与Encoder不同的是,额外多加了一层Encoder-Decoder Attention的运算,具体介绍如下。
3.1、Encoder-decoder attention
Decoder包括6个decoder block,每一个decoder block由三部分组成,除了decoder block包含的两层以外,多了一层encoder-decoder attention。也就是说,除了decoder本身的输入,encoder的输出也作为decoder输入的一部分进行运算。从代码DecoderLayer()中第5行可以体现出来。
在1.2节中我们知道Transformer的Encoder编码器包括6个encoder block,其中每一个encoder block主要由两部分组成,包括Multihead attention层、Feed Forward层。Encoder的输入首先经过Multihead attention层,这一层帮助encoder在输入某个单词时理解其在整个句子中的上下文语义,输出之后再送到前馈神经网络中,各层依次循环迭代。
Decoder总体的构建代码如下:
class Decoder(nn.Module):
def __init__(self):
super(Decoder, self).__init__()
self.tgt_emb = nn.Embedding(tgt_vocab_size, d_model)
self.pos_emb = nn.Embedding.from_pretrained (get_sinusoid_
encoding_ table(tgt_len+1, d_model),freeze=True)
self.layers = nn.ModuleList([DecoderLayer() for
_ in range (n_layers)]) |
DecoderLayer()负责每一个Encoder block的构建:
class DecoderLayer(nn.Module):
def __init__(self):
super(DecoderLayer, self).__init__()
self.dec_self_attn = MultiHeadAttention()
self.dec_enc_attn = MultiHeadAttention()
self.pos_ffn = PoswiseFeedForwardNet()
def forward(self, dec_inputs, enc_outputs,
dec_self_ attn_mask, dec_enc_attn_mask):
dec_outputs, dec_self_attn = self.dec_self_attn
(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
dec_outputs, dec_enc_attn = self.dec_enc_attn
(dec_outputs, enc_outputs, enc_outputs, dec_enc_attn_mask)
dec_outputs = self.pos_ffn (dec_outputs)
return dec_outputs, dec_self_attn, dec_enc_attn |
提示:
Decoder中的attention与encoder中的attention有所不同。Decoder中的attention中当前单词只受当前单词之前内容的影响,而encoder中的每个单词会受到前后内容的影响。具体是如何实现的呢?请看3.2节mask机制的讲解。
3.2、Mask机制
Masks在transformer模型主要有两个作用:
1、在编码器和解码器中:当输入为padding,注意力会是0。
2、在解码器中:预测下一个单词,避免解码器偷偷看到后面的翻译内容。
Encoder输入端生成mask很简单:
def get_attn_pad_mask(seq_q, seq_k):
# print(seq_q)
batch_size, len_q = seq_q.size()
batch_size, len_k = seq_k.size()
# eq(zero) is PAD token
pad_attn_mask = seq_k.data.eq(0).unsqueeze(1)
# batch _size x 1 x len_k(=len_q), one is masking
return pad_attn_mask.expand(batch_size, len_q,
len_k) # batch_size x len_q x len_ |
同样的,输出端也可以生成一个mask,但是会额外增加一个步骤:
目标语句(输入法语——>输出英语)作为初始值输进解码器中。decoder通过encoder的全部输出,以及目前已翻译的单词来预测下一个单词。因此,我们需要防止解码器偷看到还没预测的单词。为了达成这个目的,我们用到了subsequent_mask函数:
def get_attn_subsequent_mask(seq):
attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
subsequent_mask = np.triu(np.ones (attn_shape),
k=1)
subsequent_mask = torch.from_numpy (subsequent_mask)
.byte()
return subsequent_mask |

这样在Decoder的attention中应用mask,每一次预测都只会用到这个词之前的句子,而不受之后句子的影响
四、文末总结
通过本文我们对Transformer的来龙去脉已经搞得差不多了,是时候对Bert下手了。Bert本质上就是双向Transformer的Encoder,因此搞懂Transformer的原理对Bert模型的理解至关重要。从Self-Attention到Transformer,再到Bert可以说是环环相扣,缺一不可。
|









