| БрМЭЦМі: |
БОЮФРДздcnblogsЃЌЪзЯШНВНтСЫФЧОэЛ§ЩёОЭјТчИњЫќЪЧЪВУДЙиЯЕФиЃПвдМАОэЛ§ЩёОЭјТчЕФВуМЖНсЙЙЃЌЙ§ГЬжаЕФвЛаЉЮЪЬтЯъЯИНтД№ЁЃ
|
|
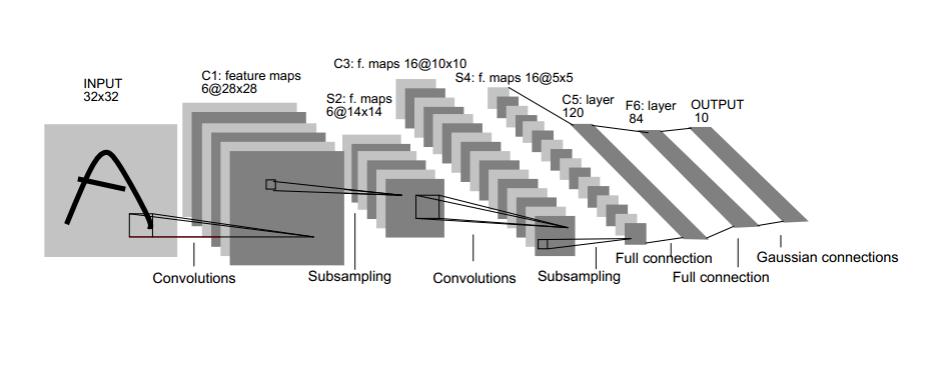
ДгЩёОЭјТчЕНОэЛ§ЩёОЭјТчЃЈCNNЃЉ ЮвУЧжЊЕРЩёОЭјТчЕФНсЙЙЪЧетбљЕФЃК
ФЧОэЛ§ЩёОЭјТчИњЫќЪЧЪВУДЙиЯЕФиЃП ЦфЪЕОэЛ§ЩёОЭјТчвРОЩЪЧВуМЖЭјТчЃЌжЛЪЧВуЕФЙІФмКЭаЮЪНзіСЫБфЛЏЃЌПЩвдЫЕЪЧДЋЭГЩёОЭјТчЕФвЛИіИФНјЁЃБШШчЯТЭМжаОЭЖрСЫаэЖрДЋЭГЩёОЭјТчУЛгаЕФВуДЮЁЃ
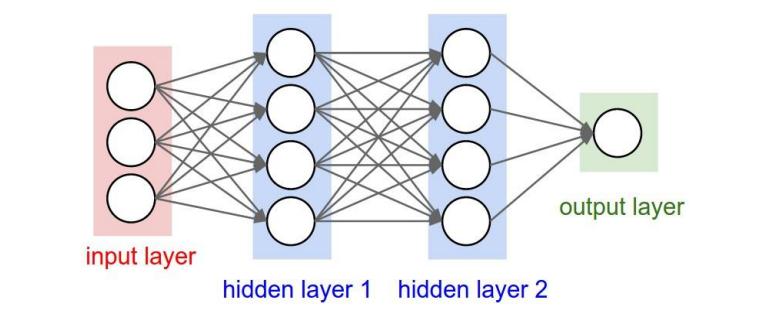
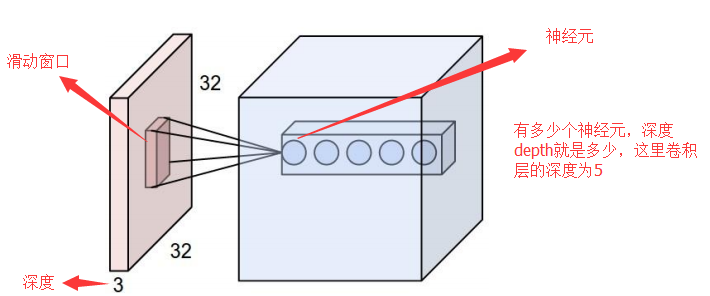
ОэЛ§ЩёОЭјТчЕФВуМЖНсЙЙ Ъ§ОнЪфШыВу/ Input layer ОэЛ§МЦЫуВу/ CONV layer ReLUМЄРјВу / ReLU layer ГиЛЏВу / Pooling layer ШЋСЌНгВу / FC layer
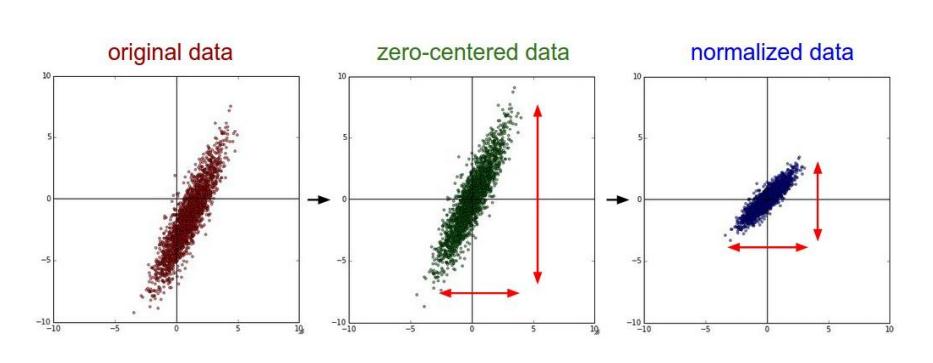
1.Ъ§ОнЪфШыВу ИУВувЊзіЕФДІРэжївЊЪЧЖддЪМЭМЯёЪ§ОнНјаадЄДІРэЃЌЦфжаАќРЈЃК ШЅОљжЕЃКАбЪфШыЪ§ОнИїИіЮЌЖШЖМжааФЛЏЮЊ0ЃЌШчЯТЭМЫљЪОЃЌЦфФПЕФОЭЪЧАббљБОЕФжааФРЛиЕНзјБъЯЕдЕуЩЯЁЃ ЙщвЛЛЏЃКЗљЖШЙщвЛЛЏЕНЭЌбљЕФЗЖЮЇЃЌШчЯТЫљЪОЃЌМДМѕЩйИїЮЌЖШЪ§ОнШЁжЕЗЖЮЇЕФВювьЖјДјРДЕФИЩШХЃЌБШШчЃЌЮвУЧгаСНИіЮЌЖШЕФЬиеїAКЭBЃЌAЗЖЮЇЪЧ0ЕН10ЃЌЖјBЗЖЮЇЪЧ0ЕН10000ЃЌШчЙћжБНгЪЙгУетСНИіЬиеїЪЧгаЮЪЬтЕФЃЌКУЕФзіЗЈОЭЪЧЙщвЛЛЏЃЌМДAКЭBЕФЪ§ОнЖМБфЮЊ0ЕН1ЕФЗЖЮЇЁЃ PCA/АзЛЏЃКгУPCAНЕЮЌЃЛАзЛЏЪЧЖдЪ§ОнИїИіЬиеїжсЩЯЕФЗљЖШЙщвЛЛЏ
ШЅОљжЕгыЙщвЛЛЏаЇЙћЭМЃК
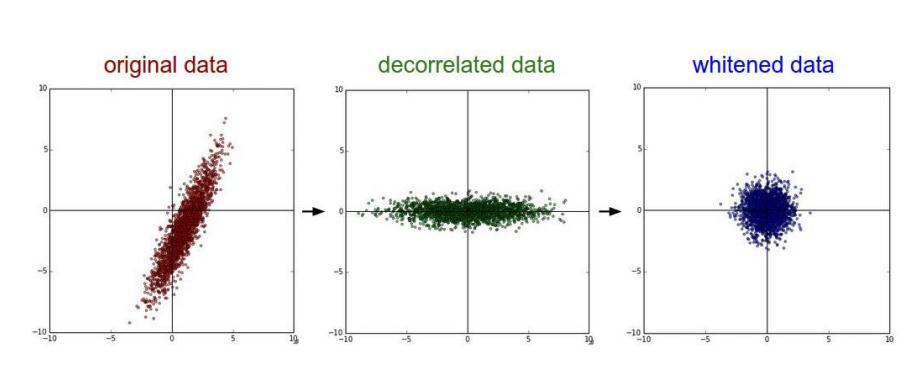
ШЅЯрЙигыАзЛЏаЇЙћЭМЃК
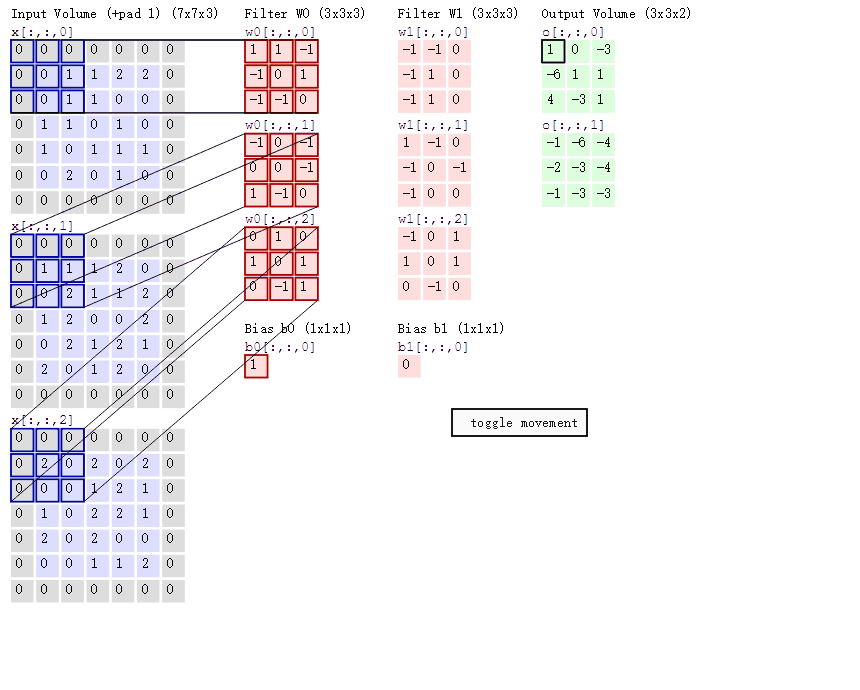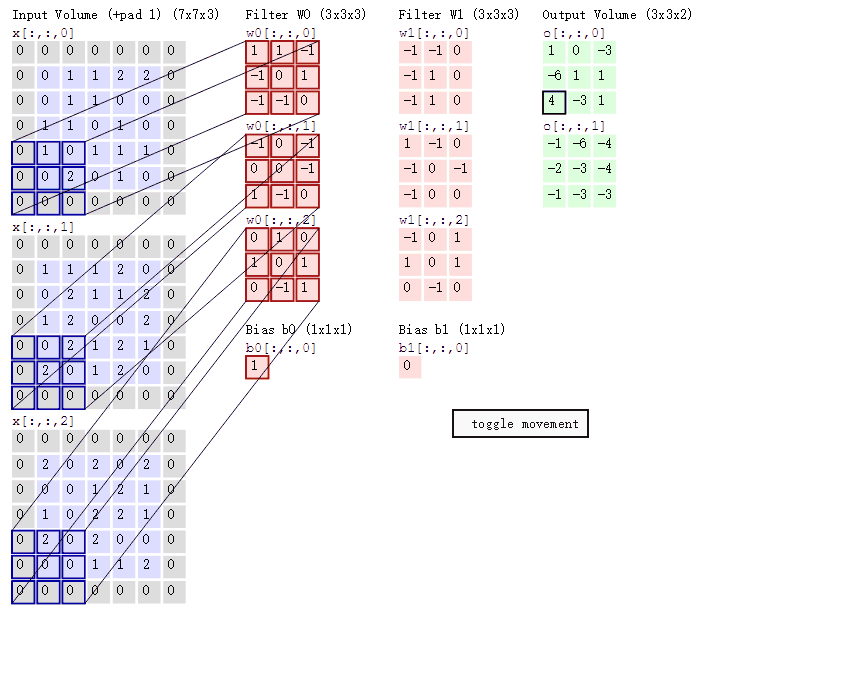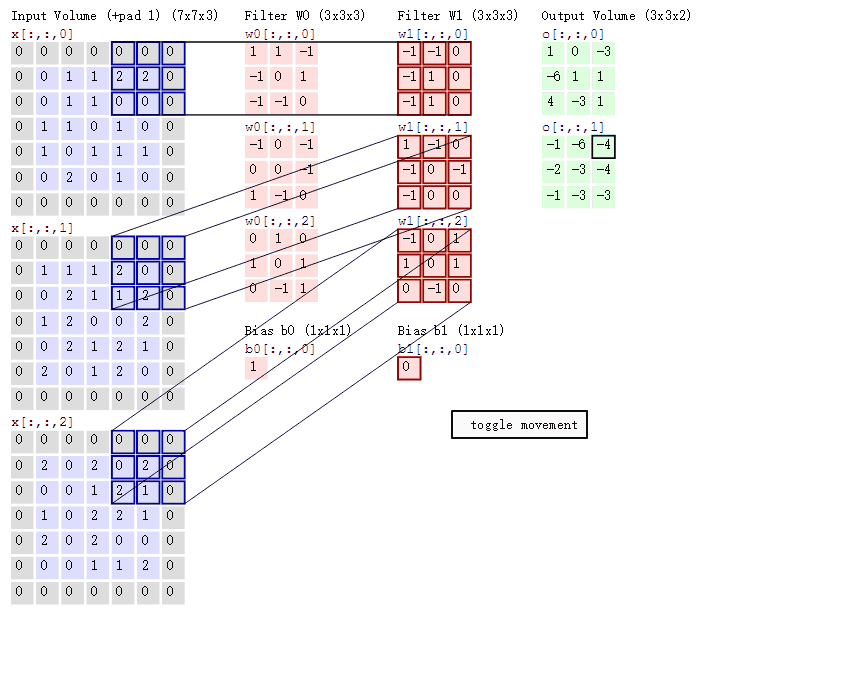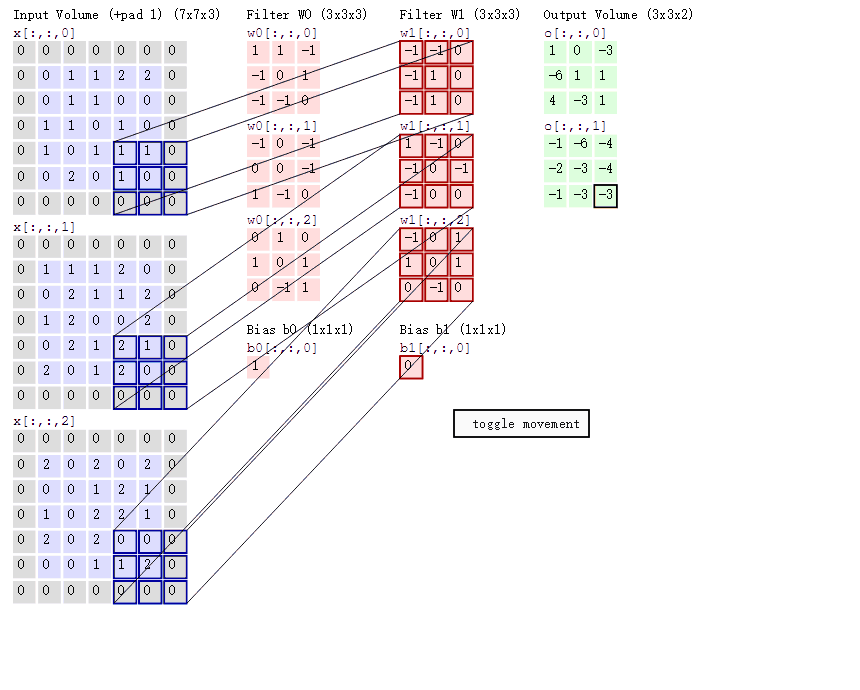
2.ОэЛ§МЦЫуВу етвЛВуОЭЪЧОэЛ§ЩёОЭјТчзюживЊЕФвЛИіВуДЮЃЌвВЪЧЁАОэЛ§ЩёОЭјТчЁБЕФУћзжРДдДЁЃ дкетИіОэЛ§ВуЃЌгаСНИіЙиМќВйзїЃК ОжВПЙиСЊЁЃУПИіЩёОдЊПДзівЛИіТЫВЈЦї(filter) ДАПк(receptive field)ЛЌЖЏЃЌ filterЖдОжВПЪ§ОнМЦЫу
ЯШНщЩмОэЛ§ВугіЕНЕФМИИіУћДЪЃК ЩюЖШ/depthЃЈНтЪЭМћЯТЭМЃЉ ВНГЄ/stride ЃЈДАПквЛДЮЛЌЖЏЕФГЄЖШЃЉ ЬюГфжЕ/zero-padding
ЬюГфжЕЪЧЪВУДФиЃПвдЯТЭМЮЊР§згЃЌБШШчгаетУДвЛИі5*5ЕФЭМЦЌЃЈвЛИіИёзгвЛИіЯёЫиЃЉЃЌЮвУЧЛЌЖЏДАПкШЁ2*2ЃЌВНГЄШЁ2ЃЌФЧУДЮвУЧЗЂЯжЛЙЪЃЯТ1ИіЯёЫиУЛЗЈЛЌЭъЃЌФЧдѕУДАьФиЃП
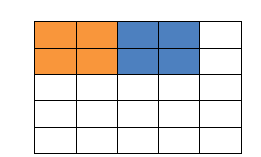
ФЧЮвУЧдкдЯШЕФОиеѓМгСЫвЛВуЬюГфжЕЃЌЪЙЕУБфГЩ6*6ЕФОиеѓЃЌФЧУДДАПкОЭПЩвдИеКУАбЫљгаЯёЫиБщРњЭъЁЃетОЭЪЧЬюГфжЕЕФзїгУЁЃ
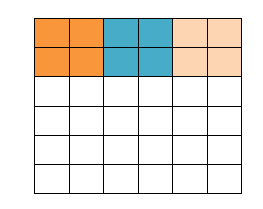
ОэЛ§ЕФМЦЫуЃЈзЂвтЃЌЯТУцРЖЩЋОиеѓжмЮЇгавЛШІЛвЩЋЕФПђЃЌФЧаЉОЭЪЧЩЯУцЫљЫЕЕНЕФЬюГфжЕЃЉ
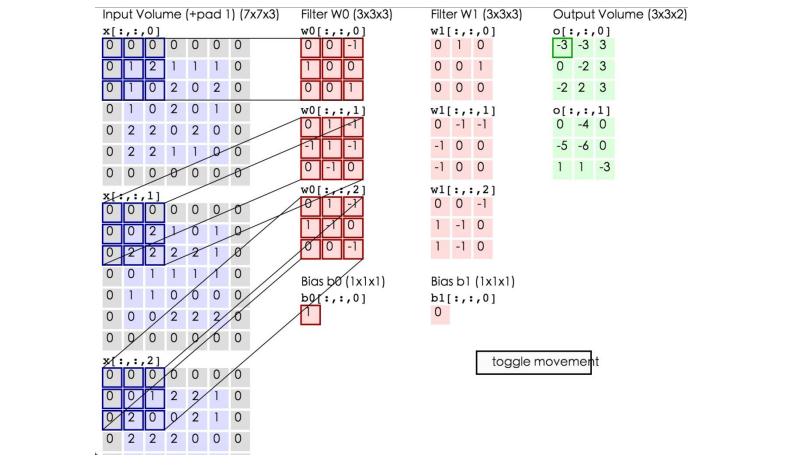
етРяЕФРЖЩЋОиеѓОЭЪЧЪфШыЕФЭМЯёЃЌЗлЩЋОиеѓОЭЪЧОэЛ§ВуЕФЩёОдЊЃЌетРяБэЪОСЫгаСНИіЩёОдЊЃЈw0,w1ЃЉЁЃТЬЩЋОиеѓОЭЪЧОЙ§ОэЛ§дЫЫуКѓЕФЪфГіОиеѓЃЌетРяЕФВНГЄЩшжУЮЊ2ЁЃ
.png)
РЖЩЋЕФОиеѓ(ЪфШыЭМЯё)ЖдЗлЩЋЕФОиеѓЃЈfilterЃЉНјааОиеѓФкЛ§МЦЫуВЂНЋШ§ИіФкЛ§дЫЫуЕФНсЙћгыЦЋжУжЕbЯрМгЃЈБШШчЩЯУцЭМЕФМЦЫуЃК2+ЃЈ-2+1-2ЃЉ+ЃЈ1-2-2ЃЉ
+ 1= 2 - 3 - 3 + 1 = -3ЃЉЃЌМЦЫуКѓЕФжЕОЭЪЧТЬПђОиеѓЕФвЛИідЊЫиЁЃ
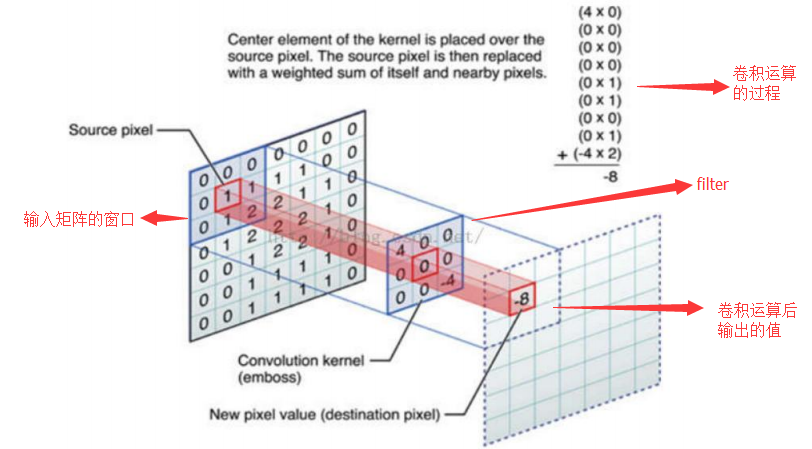
ЯТУцЕФЖЏЬЌЭМаЮЯѓЕиеЙЪОСЫОэЛ§ВуЕФМЦЫуЙ§ГЬЃК
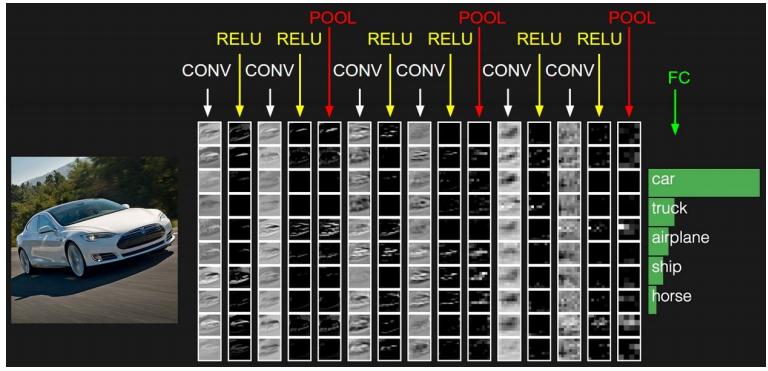
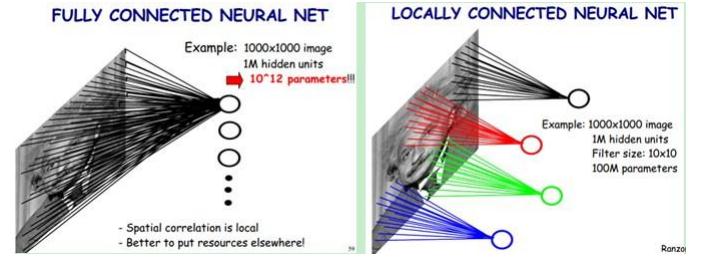
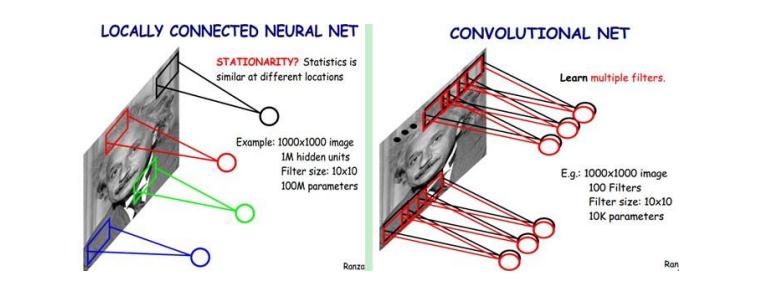
ВЮЪ§ЙВЯэЛњжЦ дкОэЛ§ВужаУПИіЩёОдЊСЌНгЪ§ОнДАЕФШЈжиЪЧЙЬЖЈЕФЃЌУПИіЩёОдЊжЛЙизЂвЛИіЬиадЁЃЩёОдЊОЭЪЧЭМЯёДІРэжаЕФТЫВЈЦїЃЌБШШчБпдЕМьВтзЈгУЕФSobelТЫВЈЦїЃЌМДОэЛ§ВуЕФУПИіТЫВЈЦїЖМЛсгаздМКЫљЙизЂвЛИіЭМЯёЬиеїЃЌБШШчДЙжББпдЕЃЌЫЎЦНБпдЕЃЌбеЩЋЃЌЮЦРэЕШЕШЃЌетаЉЫљгаЩёОдЊМгЦ№РДОЭКУБШОЭЪЧећеХЭМЯёЕФЬиеїЬсШЁЦїМЏКЯЁЃ ашвЊЙРЫуЕФШЈжиИіЪ§МѕЩй: AlexNet 1вк => 3.5w вЛзщЙЬЖЈЕФШЈжиКЭВЛЭЌДАПкФкЪ§ОнзіФкЛ§: ОэЛ§

3.МЄРјВу
АбОэЛ§ВуЪфГіНсЙћзіЗЧЯпадгГЩфЁЃ
CNNВЩгУЕФМЄРјКЏЪ§вЛАуЮЊReLU(The Rectified Linear Unit/аое§ЯпадЕЅдЊ)ЃЌЫќЕФЬиЕуЪЧЪеСВПьЃЌЧѓЬнЖШМђЕЅЃЌЕЋНЯДрШѕЃЌЭМЯёШчЯТЁЃ
МЄРјВуЕФЪЕМљОбщЃК ЂйВЛвЊгУsigmoidЃЁВЛвЊгУsigmoidЃЁВЛвЊгУsigmoidЃЁ Ђк ЪзЯШЪдRELUЃЌвђЮЊПьЃЌЕЋвЊаЁаФЕу Ђл ШчЙћ2ЪЇаЇЃЌЧыгУLeaky ReLUЛђепMaxout Ђм ФГаЉЧщПіЯТtanhЕЙЪЧгаВЛДэЕФНсЙћЃЌЕЋЪЧКмЩй
4.ГиЛЏВу ГиЛЏВуМадкСЌајЕФОэЛ§ВужаМфЃЌ гУгкбЙЫѕЪ§ОнКЭВЮЪ§ЕФСПЃЌМѕаЁЙ§ФтКЯЁЃ МђЖјбджЎЃЌШчЙћЪфШыЪЧЭМЯёЕФЛАЃЌФЧУДГиЛЏВуЕФзюжївЊзїгУОЭЪЧбЙЫѕЭМЯёЁЃ
етРядйеЙПЊа№ЪіГиЛЏВуЕФОпЬхзїгУЁЃ
1. ЬиеїВЛБфадЃЌвВОЭЪЧЮвУЧдкЭМЯёДІРэжаОГЃЬсЕНЕФЬиеїЕФГпЖШВЛБфадЃЌГиЛЏВйзїОЭЪЧЭМЯёЕФresizeЃЌЦНЪБвЛеХЙЗЕФЭМЯёБЛЫѕаЁСЫвЛБЖЮвУЧЛЙФмШЯГіетЪЧвЛеХЙЗЕФееЦЌЃЌетЫЕУїетеХЭМЯёжаШдБЃСєзХЙЗзюживЊЕФЬиеїЃЌЮвУЧвЛПДОЭФмХаЖЯЭМЯёжаЛЕФЪЧвЛжЛЙЗЃЌЭМЯёбЙЫѕЪБШЅЕєЕФаХЯЂжЛЪЧвЛаЉЮоЙиНєвЊЕФаХЯЂЃЌЖјСєЯТЕФаХЯЂдђЪЧОпгаГпЖШВЛБфадЕФЬиеїЃЌЪЧзюФмБэДяЭМЯёЕФЬиеїЁЃ
2. ЬиеїНЕЮЌЃЌЮвУЧжЊЕРвЛЗљЭМЯёКЌгаЕФаХЯЂЪЧКмДѓЕФЃЌЬиеївВКмЖрЃЌЕЋЪЧгааЉаХЯЂЖдгкЮвУЧзіЭМЯёШЮЮёЪБУЛгаЬЋЖргУЭОЛђепгажиИДЃЌЮвУЧПЩвдАбетРрШпграХЯЂШЅГ§ЃЌАбзюживЊЕФЬиеїГщШЁГіРДЃЌетвВЪЧГиЛЏВйзїЕФвЛДѓзїгУЁЃ
3. дквЛЖЈГЬЖШЩЯЗРжЙЙ§ФтКЯЃЌИќЗНБугХЛЏЁЃ
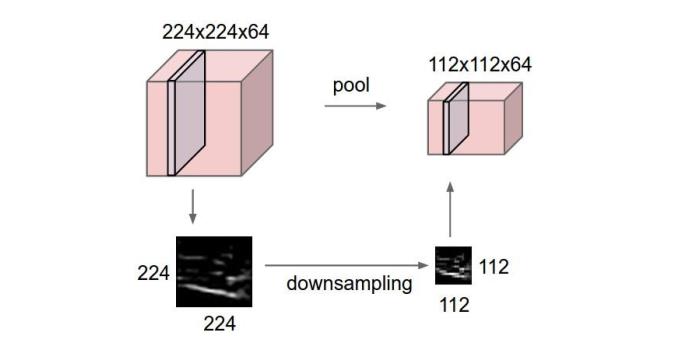
ГиЛЏВугУЕФЗНЗЈгаMax pooling КЭ average poolingЃЌЖјЪЕМЪгУЕФНЯЖрЕФЪЧMax
poolingЁЃ
етРяОЭЫЕвЛЯТMax poolingЃЌЦфЪЕЫМЯыЗЧГЃМђЕЅЁЃ
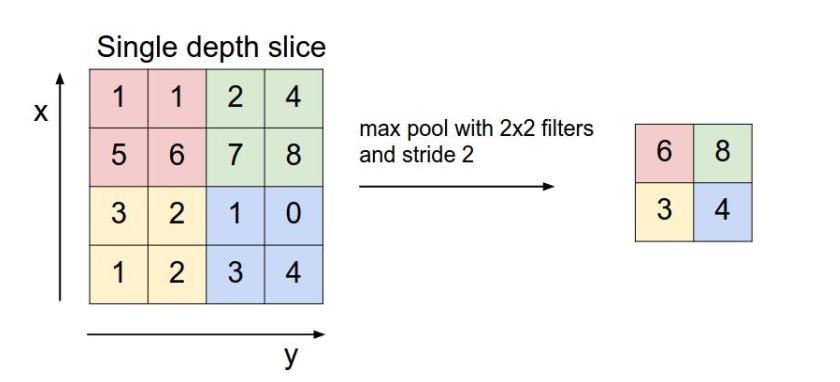
ЖдгкУПИі2*2ЕФДАПкбЁГізюДѓЕФЪ§зїЮЊЪфГіОиеѓЕФЯргІдЊЫиЕФжЕЃЌБШШчЪфШыОиеѓЕквЛИі2*2ДАПкжазюДѓЕФЪ§ЪЧ6ЃЌФЧУДЪфГіОиеѓЕФЕквЛИідЊЫиОЭЪЧ6ЃЌШчДЫРрЭЦЁЃ
5.ШЋСЌНгВу
СНВужЎМфЫљгаЩёОдЊЖМгаШЈжиСЌНгЃЌЭЈГЃШЋСЌНгВудкОэЛ§ЩёОЭјТчЮВВПЁЃвВОЭЪЧИњДЋЭГЕФЩёОЭјТчЩёОдЊЕФСЌНгЗНЪНЪЧвЛбљЕФЃК
вЛАуCNNНсЙЙвРДЮЮЊ 1. INPUT 2. [[CONV -> RELU]*N -> POOL?]*M 3. [FC -> RELU]*K 4. FC
ОэЛ§ЩёОЭјТчжЎбЕСЗЫуЗЈ 1. ЭЌвЛАуЛњЦїбЇЯАЫуЗЈЃЌЯШЖЈвхLoss functionЃЌКтСПКЭЪЕМЪНсЙћжЎМфВюОрЁЃ 2. евЕНзюаЁЛЏЫ№ЪЇКЏЪ§ЕФWКЭbЃЌ CNNжагУЕФЫуЗЈЪЧSGDЃЈЫцЛњЬнЖШЯТНЕЃЉЁЃ
ОэЛ§ЩёОЭјТчжЎгХШБЕу гХЕу ЙВЯэОэЛ§КЫЃЌЖдИпЮЌЪ§ОнДІРэЮобЙСІ ЮоашЪжЖЏбЁШЁЬиеїЃЌбЕСЗКУШЈжиЃЌМДЕУЬиеїЗжРраЇЙћКУ ШБЕу ашвЊЕїВЮЃЌашвЊДѓбљБОСПЃЌбЕСЗзюКУвЊGPU ЮяРэКЌвхВЛУїШЗЃЈвВОЭЫЕЃЌЮвУЧВЂВЛжЊЕРУЛИіОэЛ§ВуЕНЕзЬсШЁЕНЕФЪЧЪВУДЬиеїЃЌЖјЧвЩёОЭјТчБОЩэОЭЪЧвЛжжФбвдНтЪЭЕФЁАКкЯфФЃаЭЁБЃЉ
ОэЛ§ЩёОЭјТчжЎЕфаЭCNN LeNetЃЌетЪЧзюдчгУгкЪ§зжЪЖБ№ЕФCNN AlexNetЃЌ 2012 ILSVRCБШШќдЖГЌЕк2УћЕФCNNЃЌБШ LeNetИќЩюЃЌгУЖрВуаЁОэЛ§ВуЕўМгЬцЛЛЕЅДѓОэЛ§ВуЁЃ ZF NetЃЌ 2013 ILSVRCБШШќЙкОќ GoogLeNetЃЌ 2014 ILSVRCБШШќЙкОќ VGGNetЃЌ 2014 ILSVRCБШШќжаЕФФЃаЭЃЌЭМЯёЪЖБ№ТдВюгкGoogLeNetЃЌЕЋЪЧдкКмЖрЭМЯёзЊЛЏбЇЯАЮЪЬт(БШШчobject
detection)ЩЯаЇЙћЦцКУ
ОэЛ§ЩёОЭјТчжЎ fine-tuning КЮЮНfine-tuningЃП fine-tuningОЭЪЧЪЙгУвбгУгкЦфЫћФПБъЁЂдЄбЕСЗКУФЃаЭЕФШЈжиЛђепВПЗжШЈжиЃЌзїЮЊГѕЪМжЕПЊЪМбЕСЗЁЃ
ФЧЮЊЪВУДЮвУЧВЛгУЫцЛњбЁШЁбЁМИИіЪ§зїЮЊШЈжиГѕЪМжЕЃПдвђКмМђЕЅЃЌЕквЛЃЌздМКДгЭЗбЕСЗОэЛ§ЩёОЭјТчШнвзГіЯжЮЪЬтЃЛЕкЖўЃЌfine-tuningФмКмПьЪеСВЕНвЛИіНЯРэЯыЕФзДЬЌЃЌЪЁЪБгжЪЁаФЁЃ
ФЧfine-tuningЕФОпЬхзіЗЈЪЧЃП ИДгУЯрЭЌВуЕФШЈжиЃЌаТЖЈвхВуШЁЫцЛњШЈжиГѕЪМжЕ ЕїДѓаТЖЈвхВуЕФЕФбЇЯАТЪЃЌЕїаЁИДгУВубЇЯАТЪ
ОэЛ§ЩёОЭјТчЕФГЃгУПђМм
Caffe дДгкBerkeleyЕФжїСїCVЙЄОпАќЃЌжЇГжC++,python,matlab Model ZooжагаДѓСПдЄбЕСЗКУЕФФЃаЭЙЉЪЙгУ Torch FacebookгУЕФОэЛ§ЩёОЭјТчЙЄОпАќ ЭЈЙ§ЪБгђОэЛ§ЕФБОЕиНгПкЃЌЪЙгУЗЧГЃжБЙл ЖЈвхаТЭјТчВуМђЕЅ TensorFlow GoogleЕФЩюЖШбЇЯАПђМм TensorBoardПЩЪгЛЏКмЗНБу Ъ§ОнКЭФЃаЭВЂааЛЏКУЃЌЫйЖШПь
змНс ОэЛ§ЭјТчдкБОжЪЩЯЪЧвЛжжЪфШыЕНЪфГіЕФгГЩфЃЌЫќФмЙЛбЇЯАДѓСПЕФЪфШыгыЪфГіжЎМфЕФгГЩфЙиЯЕЃЌЖјВЛашвЊШЮКЮЪфШыКЭЪфГіжЎМфЕФОЋШЗЕФЪ§бЇБэДяЪНЃЌжЛвЊгУвбжЊЕФФЃЪНЖдОэЛ§ЭјТчМгвдбЕСЗЃЌЭјТчОЭОпгаЪфШыЪфГіЖджЎМфЕФгГЩфФмСІЁЃ
CNNвЛИіЗЧГЃживЊЕФЬиЕуОЭЪЧЭЗжиНХЧсЃЈдНЭљЪфШыШЈжЕдНаЁЃЌдНЭљЪфГіШЈжЕдНЖрЃЉЃЌГЪЯжГівЛИіЕЙШ§НЧЕФаЮЬЌЃЌетОЭКмКУЕиБмУтСЫBPЩёОЭјТчжаЗДЯђДЋВЅЕФЪБКђЬнЖШЫ№ЪЇЕУЬЋПьЁЃ
ОэЛ§ЩёОЭјТчCNNжївЊгУРДЪЖБ№ЮЛвЦЁЂЫѕЗХМАЦфЫћаЮЪНХЄЧњВЛБфадЕФЖўЮЌЭМаЮЁЃгЩгкCNNЕФЬиеїМьВтВуЭЈЙ§бЕСЗЪ§ОнНјаабЇЯАЃЌЫљвддкЪЙгУCNNЪБЃЌБмУтСЫЯдЪНЕФЬиеїГщШЁЃЌЖјвўЪНЕиДгбЕСЗЪ§ОнжаНјаабЇЯАЃЛдйепгЩгкЭЌвЛЬиеїгГЩфУцЩЯЕФЩёОдЊШЈжЕЯрЭЌЃЌЫљвдЭјТчПЩвдВЂаабЇЯАЃЌетвВЪЧОэЛ§ЭјТчЯрЖдгкЩёОдЊБЫДЫЯрСЌЭјТчЕФвЛДѓгХЪЦЁЃОэЛ§ЩёОЭјТчвдЦфОжВПШЈжЕЙВЯэЕФЬиЪтНсЙЙдкгявєЪЖБ№КЭЭМЯёДІРэЗНУцгазХЖРЬиЕФгХдНадЃЌЦфВМОжИќНгНќгкЪЕМЪЕФЩњЮяЩёОЭјТчЃЌШЈжЕЙВЯэНЕЕЭСЫЭјТчЕФИДдгадЃЌЬиБ№ЪЧЖрЮЌЪфШыЯђСПЕФЭМЯёПЩвджБНгЪфШыЭјТчетвЛЬиЕуБмУтСЫЬиеїЬсШЁКЭЗжРрЙ§ГЬжаЪ§ОнжиНЈЕФИДдгЖШЁЃ
вдЯТЪЧЮвздМКдкбЇЯАCNNЕФЪБКђгіЕНЕФвЛаЉРЇЛѓЃЌвдМАВщдФвЛаЉзЪСЯКѓЕУЕНЕФвЛаЉД№АИЁЃ
ЕквЛИіЮЪЬтЃКЮЊЪВУДВЛгУBPЩёОЭјТчШЅзіФиЃП 1.ШЋСЌНгЃЌШЈжЕЬЋЖрЃЌашвЊКмЖрбљБОШЅбЕСЗЃЌМЦЫуРЇФб гІЖджЎЕРЃКМѕЩйШЈжЕЕФГЂЪдЃЌОжВПСЌНгЃЌШЈжЕЙВЯэ
ОэЛ§ЩёОЭјТчгаСНжжЩёЦїПЩвдНЕЕЭВЮЪ§Ъ§ФПЁЃ ЕквЛжжЩёЦїНазіОжВПИажЊвАЃЌвЛАуШЯЮЊШЫЖдЭтНчЕФШЯжЊЪЧДгОжВПЕНШЋОжЕФЃЌЖјЭМЯёЕФПеМфСЊЯЕвВЪЧОжВПЕФЯёЫиСЊЯЕНЯЮЊНєУмЃЌЖјОрРыНЯдЖЕФЯёЫиЯрЙиаддђНЯШѕЁЃвђЖјЃЌУПИіЩёОдЊЦфЪЕУЛгаБивЊЖдШЋОжЭМЯёНјааИажЊЃЌжЛашвЊЖдОжВПНјааИажЊЃЌШЛКѓдкИќИпВуНЋОжВПЕФаХЯЂзлКЯЦ№РДОЭЕУЕНСЫШЋОжЕФаХЯЂЁЃ ЕкЖўМЖЩёЦїЃЌМДШЈжЕЙВЯэЁЃ
2.БпдЕЙ§ЖЩВЛЦНЛЌ гІЖджЎЕРЃКВЩбљДАПкБЫДЫжиЕў
ЕкЖўИіЮЪЬтЃКLeNetРяЕФвўВуЕФЩёОдЊИіЪ§дѕУДШЗЖЈФиЃП ЫќКЭдЭМЯёЃЌвВОЭЪЧЪфШыЕФДѓаЁЃЈЩёОдЊИіЪ§ЃЉЁЂТЫВЈЦїЕФДѓаЁКЭТЫВЈЦїдкЭМЯёжаЕФЛЌЖЏВНГЄЖМгаЙиЃЁ
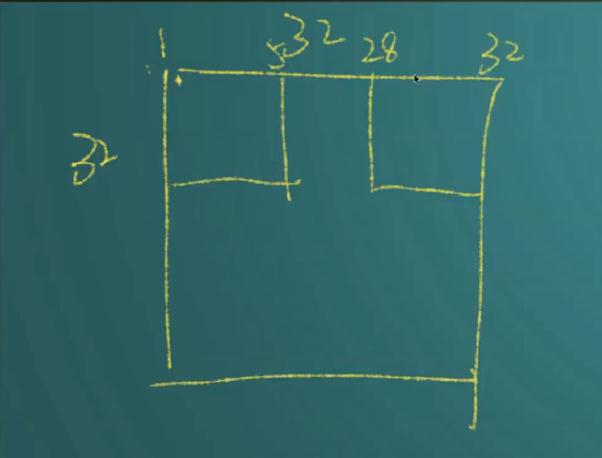
LeNet-5ЙВга7ВуЃЌВЛАќКЌЪфШыЃЌУПВуЖМАќКЌПЩбЕСЗВЮЪ§ЃЈСЌНгШЈжиЃЉЁЃЪфШыЭМЯёЮЊ32*32ДѓаЁЁЃ
Р§ШчЃЌЮвЕФЭМЯёЪЧ1000x1000ЯёЫиЃЌЖјТЫВЈЦїДѓаЁЪЧ10x10ЃЌМйЩшТЫВЈЦїУЛгажиЕўЃЌвВОЭЪЧВНГЄЮЊ10ЃЌетбљвўВуЕФЩёОдЊИіЪ§ОЭЪЧ(1000x1000
)/ (10x10)=100x100ИіЩёОдЊСЫЁЃ
ФЧжиЕўСЫдѕУДЫуЃПБШШчЩЯУцЭМЕФC2жа28*28ЪЧШчКЮЕУРДЕФЃПетРяЕФВНГЄОЭЪЧ1ЃЌДАПкДѓаЁЪЧ5*5ЃЌЫљвдДАПкЛЌЖЏПЯЖЈЗЂЩњСЫжиЕўЁЃЯТЭМНтЪЭСЫ28ЕФгЩРДЁЃ
ЕкШ§ИіЮЪЬтЃКS2ВуЪЧвЛИіЯТВЩбљВуЪЧИЩТягУЕФЃПЮЊЪВУДЪЧЯТВЩбљЃП вВОЭЪЧЩЯУцЫљЫЕЕФГиЛЏВуЃЌжЛЪЧНаЗЈВЛЭЌЖјвбЁЃетВуРћгУЭМЯёОжВПЯрЙиадЕФдРэЃЌЖдЭМЯёНјаазгГщбљЃЌПЩвдМѕЩйЪ§ОнДІРэСПЭЌЪББЃСєгагУаХЯЂЃЌЯрЕБгкЭМЯёбЙЫѕЁЃ
|









