| БрМЭЦМі: |
БОЮФРДздcsdnЃЌЮФеТЯШРДОэЛ§ЩёОЭјТчКЭШЋСЌНгЩёОЭјТчЖдБШЃЌНгзХШУЮвУЧжБЙлРэНтОэЛ§ЃЌОэЛ§МЦЫуСїГЬЃЌНсКЯАИР§НјааЯрЙиЕФНщЩмЁЃ
|
|
ОэЛ§ЩёОЭјТчЃЈConvolutional Neural NetworkЃЌCNNЃЉЪЧвЛжжЧАРЁЩёОЭјТчЃЌЫќЕФШЫЙЄЩёОдЊПЩвдЯьгІвЛВПЗжИВИЧЗЖЮЇФкЕФжмЮЇЕЅдЊЃЌЖдгкДѓаЭЭМЯёДІРэгаГіЩЋБэЯжЁЃ
ЫќАќРЈОэЛ§Ву(convolutional layer)КЭГиЛЏВу(pooling layer)ЁЃ
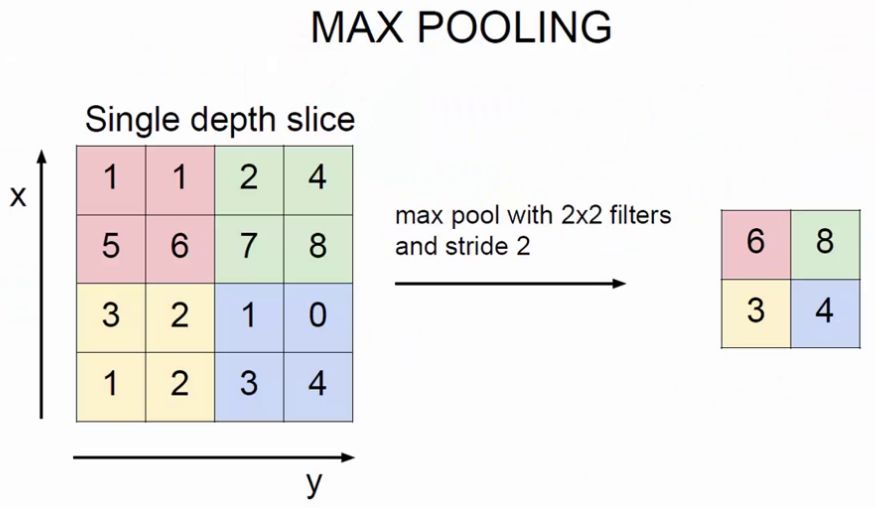
ЖдБШЃКОэЛ§ЩёОЭјТчЁЂШЋСЌНгЩёОЭјТч
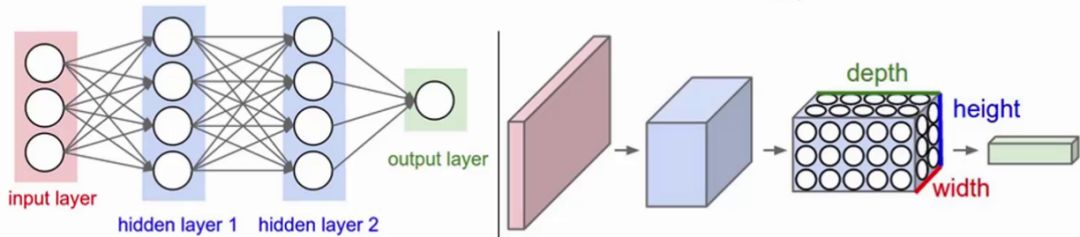
зѓЭМЃКШЋСЌНгЩёОЭјТчЃЈЦНУцЃЉЃЌзщГЩЃКЪфШыВуЁЂМЄЛюКЏЪ§ЁЂШЋСЌНгВу
гвЭМЃКОэЛ§ЩёОЭјТчЃЈСЂЬхЃЉЃЌзщГЩЃКЪфШыВуЁЂОэЛ§ВуЁЂМЄЛюКЏЪ§ЁЂГиЛЏВуЁЂШЋСЌНгВу
дкОэЛ§ЩёОЭјТчжагавЛИіживЊЕФИХФюЃКЩюЖШ
ОэЛ§Ву
ОэЛ§ЃКдкдЪМЕФЪфШыЩЯНјааЬиеїЕФЬсШЁЁЃЬиеїЬсШЁМђбджЎОЭЪЧЃЌдкдЪМЪфШыЩЯвЛИіаЁЧјгђвЛИіаЁЧјгђНјааЬиеїЕФЬсШЁЃЌЩдКѓЯИжТНВНтОэЛ§ЕФМЦЫуЙ§ГЬЁЃ
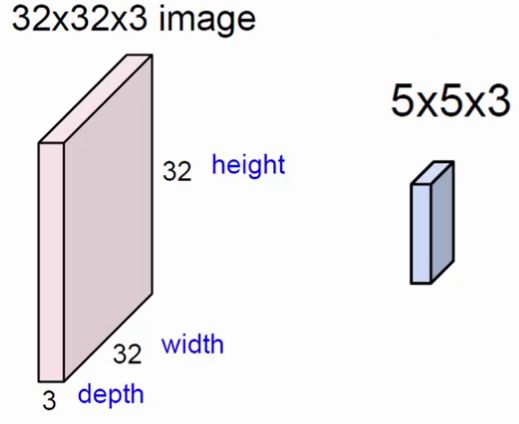
ЩЯЭМжаЃЌзѓЗНПщЪЧЪфШыВуЃЌГпДчЮЊ32*32ЕФ3ЭЈЕРЭМЯёЁЃгвБпЕФаЁЗНПщЪЧfilterЃЌГпДчЮЊ5*5ЃЌЩюЖШЮЊ3ЁЃНЋЪфШыВуЛЎЗжЮЊЖрИіЧјгђЃЌгУfilterетИіЙЬЖЈГпДчЕФжњЪжЃЌдкЪфШыВузідЫЫуЃЌзюжеЕУЕНвЛИіЩюЖШЮЊ1ЕФЬиеїЭМЁЃ
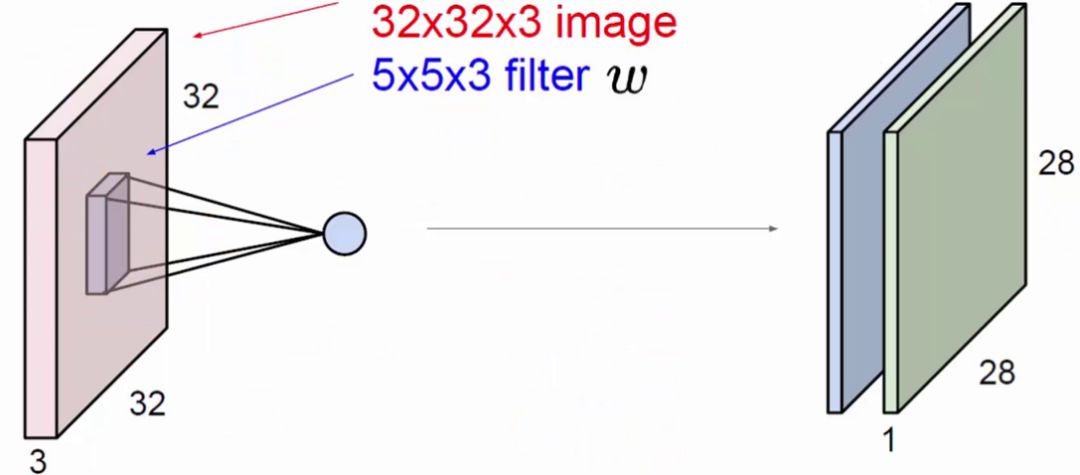
ЩЯЭМжаЃЌеЙЪОГівЛАуЪЙгУЖрИіfilterЗжБ№НјааОэЛ§ЃЌзюжеЕУЕНЖрИіЬиеїЭМЁЃ
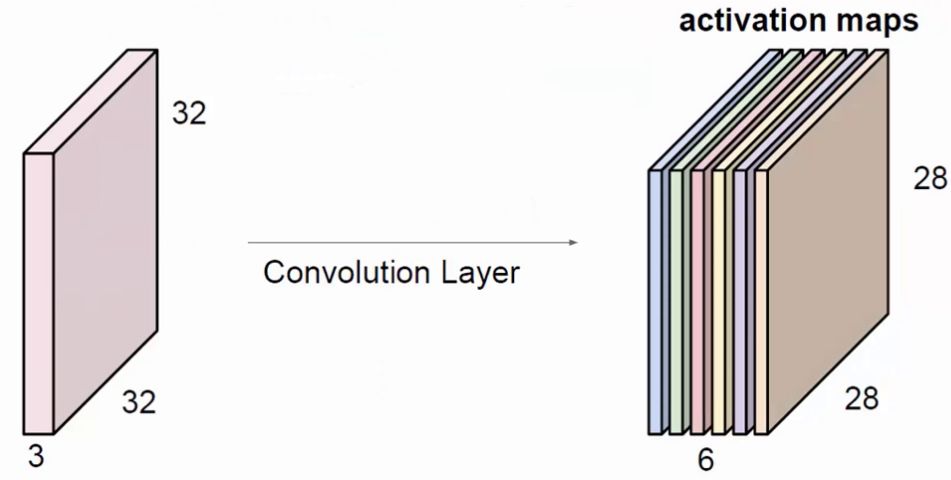
ЩЯЭМЪЙгУСЫ6ИіfilterЗжБ№ОэЛ§НјааЬиеїЬсШЁЃЌзюжеЕУЕН6ИіЬиеїЭМЁЃНЋет6ВуЕўдквЛЦ№ОЭЕУЕНСЫОэЛ§ВуЪфГіЕФНсЙћЁЃ
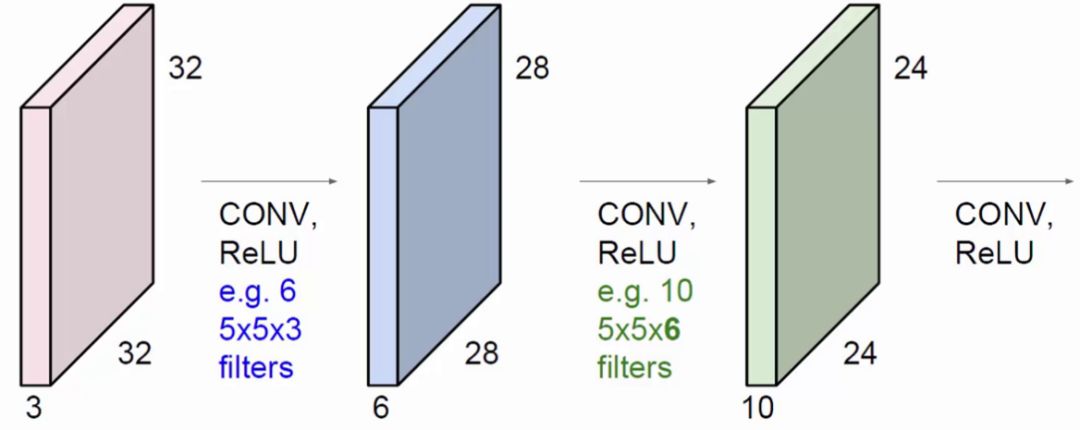
ОэЛ§ВЛНіЯогкЖддЪМЪфШыЕФОэЛ§ЁЃРЖЩЋЗНПщЪЧдкдЪМЪфШыЩЯНјааОэЛ§ВйзїЃЌЪЙгУСЫ6ИіfilterЕУЕНСЫ6ИіЬсШЁЬиеїЭМЁЃТЬЩЋЗНПщЛЙФмЖдРЖЩЋЗНПщНјааОэЛ§ВйзїЃЌЪЙгУСЫ10ИіfilterЕУЕНСЫ10ИіЬиеїЭМЁЃУПвЛИіfilterЕФЩюЖШБиаыгыЩЯвЛВуЪфШыЕФЩюЖШЯрЕШЁЃ
жБЙлРэНтОэЛ§

вдЩЯЭМЮЊР§ЃК
ЕквЛДЮОэЛ§ПЩвдЬсШЁГіЕЭВуДЮЕФЬиеїЁЃ
ЕкЖўДЮОэЛ§ПЩвдЬсШЁГіжаВуДЮЕФЬиеїЁЃ
ЕкШ§ДЮОэЛ§ПЩвдЬсШЁГіИпВуДЮЕФЬиеїЁЃ
ЬиеїЪЧВЛЖЯНјааЬсШЁКЭбЙЫѕЕФЃЌзюжеФмЕУЕНБШНЯИпВуДЮЬиеїЃЌМђбджЎОЭЪЧЖддЪНЬиеївЛВНгжвЛВНЕФХЈЫѕЃЌзюжеЕУЕНЕФЬиеїИќПЩППЁЃРћгУзюКѓвЛВуЬиеїПЩвдзіИїжжШЮЮёЃКБШШчЗжРрЁЂЛиЙщЕШЁЃ
ОэЛ§МЦЫуСїГЬ
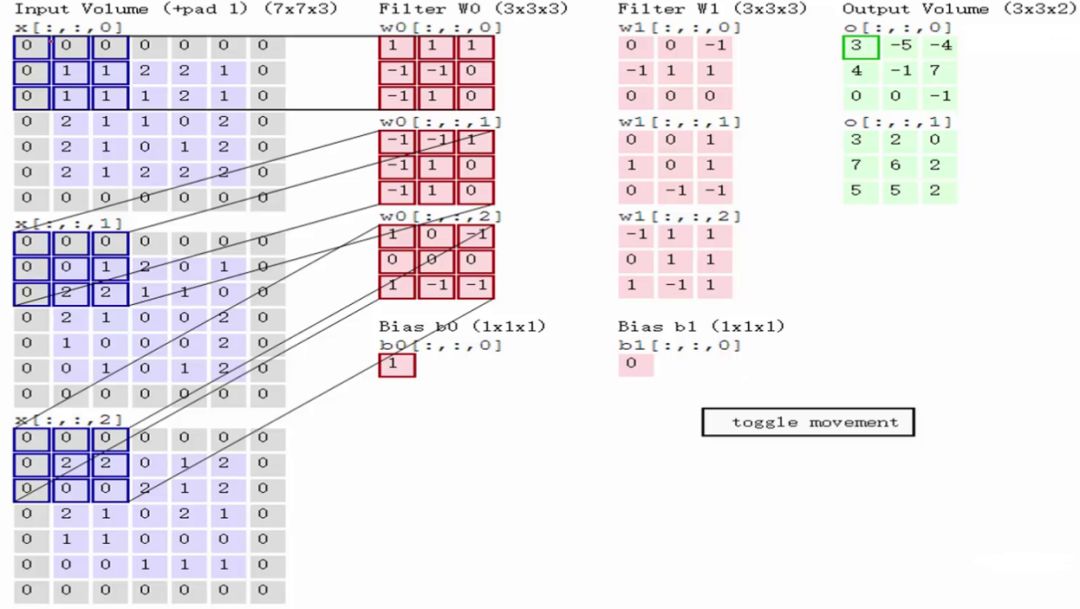
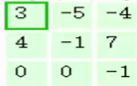
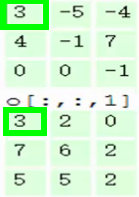
зѓЧјгђЕФШ§ИіДѓОиеѓЪЧдЪНЭМЯёЕФЪфШыЃЌRGBШ§ИіЭЈЕРгУШ§ИіОиеѓБэЪОЃЌДѓаЁЮЊ7*7*3ЁЃ
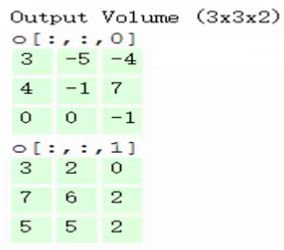
Filter W0БэЪО1ИіfilterжњЪжЃЌГпДчЮЊ3*3ЃЌЩюЖШЮЊ3ЃЈШ§ИіОиеѓЃЉЃЛFilter W1вВБэЪО1ИіfilterжњЪжЁЃвђЮЊОэЛ§жаЮвУЧгУСЫ2ИіfilterЃЌвђДЫИУОэЛ§ВуНсЙћЕФЪфГіЩюЖШЮЊ2ЃЈТЬЩЋОиеѓга2ИіЃЉЁЃ
Bias b0ЪЧFilter W0ЕФЦЋжУЯюЃЌBias b1ЪЧFilter W1ЕФЦЋжУЯюЁЃ
OutPutЪЧОэЛ§КѓЕФЪфГіЃЌГпДчЮЊ3*3ЃЌЩюЖШЮЊ2ЁЃ
МЦЫуЙ§ГЬЃК
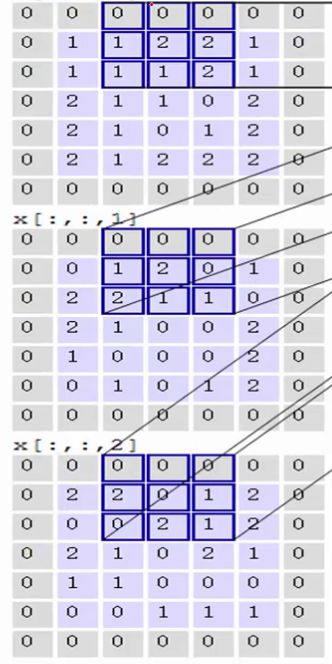
ЪфШыЪЧЙЬЖЈЕФЃЌfilterЪЧжИЖЈЕФЃЌвђДЫМЦЫуОЭЪЧШчКЮЕУЕНТЬЩЋОиеѓЁЃЕквЛВНЃЌдкЪфШыОиеѓЩЯгавЛИіКЭfilterЯрЭЌГпДчЕФЛЌДАЃЌШЛКѓЪфШыОиеѓЕФдкЛЌДАРяЕФВПЗжгыfilterОиеѓЖдгІЮЛжУЯрГЫЃК
МД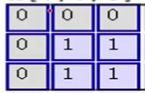 гы гы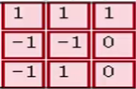 ЖдгІЮЛжУЯрГЫКѓЧѓКЭЃЌНсЙћЮЊ0 ЖдгІЮЛжУЯрГЫКѓЧѓКЭЃЌНсЙћЮЊ0
МД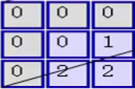 гы гы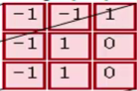 ЖдгІЮЛжУЯрГЫКѓЧѓКЭЃЌНсЙћЮЊ2 ЖдгІЮЛжУЯрГЫКѓЧѓКЭЃЌНсЙћЮЊ2
МД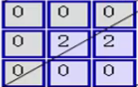 гы гы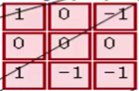 ЖдгІЮЛжУЯрГЫКѓЧѓКЭЃЌНсЙћЮЊ0 ЖдгІЮЛжУЯрГЫКѓЧѓКЭЃЌНсЙћЮЊ0
ЕкЖўВНЃЌНЋ3ИіОиеѓВњЩњЕФНсЙћЧѓКЭЃЌВЂМгЩЯЦЋжУЯюЃЌМД0+2+0+1=3ЃЌвђДЫОЭЕУЕНСЫЪфГіОиеѓЕФзѓЩЯНЧЕФ3ЃК
ЕкШ§ВНЃЌШУУПвЛИіfilterЖМжДааетбљЕФВйзїЃЌБфПЩЕУЕНЕквЛИідЊЫиЃК
ЕкЫФВНЃЌЛЌЖЏДАПк2ИіВНГЄЃЌжиИДжЎЧАВНжшНјааМЦЫу
ЕкЮхВНЃЌзюжеПЩвдЕУЕНЃЌдк2ИіfilterЯТЃЌОэЛ§КѓЩњГЩЕФЩюЖШЮЊ2ЕФЪфГіНсЙћЃК
ЫМПМЃК
ЂйЮЊЪВУДУПДЮЛЌЖЏЪЧ2ИіИёзгЃП

ЛЌЖЏЕФВНГЄНаstrideМЧЮЊSЁЃSдНаЁЃЌЬсШЁЕФЬиеїдНЖрЃЌЕЋЪЧSвЛАуВЛШЁ1ЃЌжївЊПМТЧЪБМфаЇТЪЕФЮЪЬтЁЃSвВВЛФмЬЋДѓЃЌЗёдђЛсТЉЕєЭМЯёЩЯЕФаХЯЂЁЃ
ЂкгЩгкfilterЕФБпГЄДѓгкSЃЌЛсдьГЩУПДЮвЦЖЏЛЌДАКѓгаНЛМЏВПЗжЃЌНЛМЏВПЗжвтЮЖзХЖрДЮЬсШЁЬиеїЃЌгШЦфБэЯждкЭМЯёЕФжаМфЧјгђЬсШЁДЮЪ§НЯЖрЃЌБпдЕВПЗжЬсШЁДЮЪ§НЯЩйЃЌдѕУДАьЃП
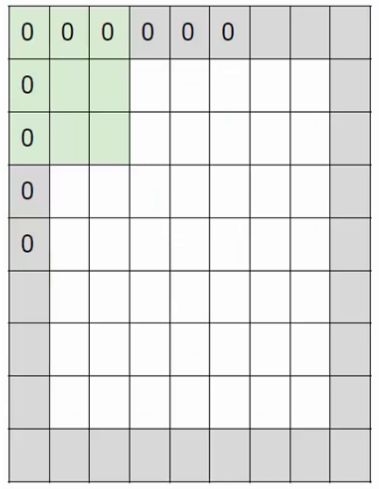
вЛАуЗНЗЈЪЧдкЭМЯёЭтЮЇМгвЛШІ0ЃЌЯИаФЕФЭЌбЇПЩФмвбОзЂвтЕНСЫЃЌдкбнЪОАИР§жавбОМгЩЯетвЛШІ0СЫЃЌМД+pad
1ЁЃ +pad nБэЪОМгnШІ0.

ЂлвЛДЮОэЛ§КѓЕФЪфГіЬиеїЭМЕФГпДчЪЧЖрЩйФиЃП
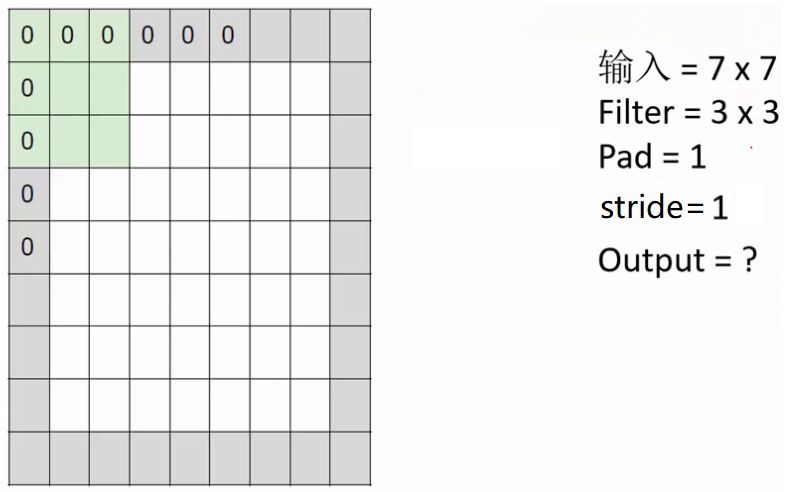
ЧыМЦЫуЩЯЭМжаOutput=ЃП
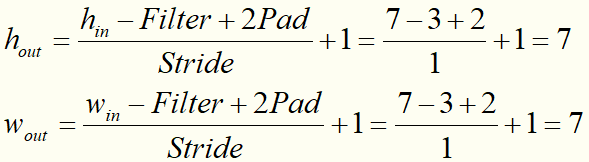
зЂвтЃКдквЛВуОэЛ§ВйзїРяПЩвдгаЖрИіfilterЃЌЫћУЧЪЧГпДчБиаыЯрЭЌЁЃ

ОэЛ§ВЮЪ§ЙВЯэддђ

дкОэЛ§ЩёОЭјТчжаЃЌгавЛИіЗЧГЃживЊЕФЬиадЃКШЈжЕЙВЯэЁЃ
ЫљЮНЕФШЈжЕЙВЯэОЭЪЧЫЕЃЌИјвЛеХЪфШыЭМЦЌЃЌгУвЛИіfilterШЅЩЈетеХЭМЃЌfilterРяУцЕФЪ§ОЭНаШЈжиЃЌетеХЭМУПИіЮЛжУЪЧБЛЭЌбљЕФfilterЩЈЕФЃЌЫљвдШЈжиЪЧвЛбљЕФЃЌвВОЭЪЧЙВЯэЁЃ
ГиЛЏВу
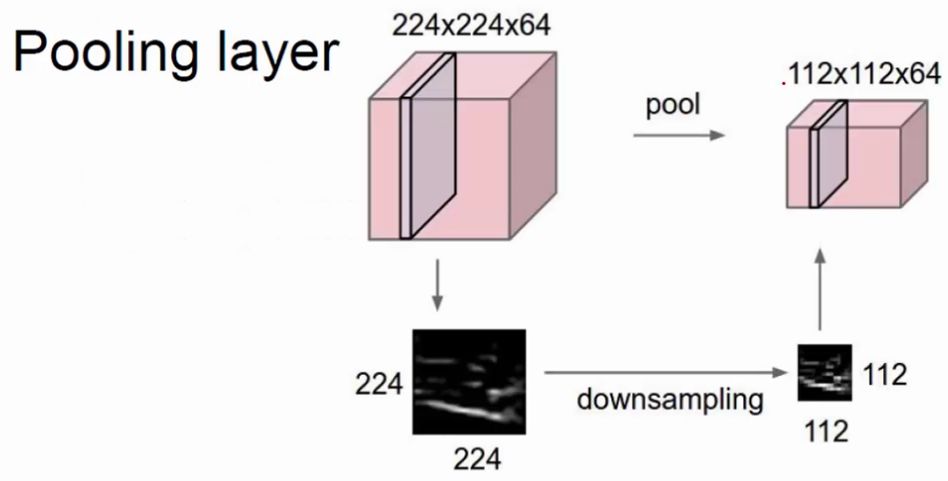
ЩЯЭМЯдЪОЃЌГиЛЏОЭЪЧЖдЬиеїЭМНјааЬиеїбЙЫѕЃЌГиЛЏвВНазіЯТВЩбљЁЃбЁдёдРДФГИіЧјгђЕФmaxЛђmeanДњЬцФЧИіЧјгђЃЌећЬхОЭХЈЫѕСЫЁЃЯТУцбнЪОвЛЯТpoolingВйзїЃЌашвЊжЦЖЈвЛИіfilterЕФГпДчЁЂstrideЁЂpoolingЗНЪНЃЈmaxЛђmeanЃЉЃК
ОэЛ§ЩёОЭјТчЕФзщГЩ

ОэЛ§ЁЊЁЊМЄЛюЁЊЁЊОэЛ§ЁЊЁЊМЄЛюЁЊЁЊГиЛЏЁЊЁЊ......ЁЊЁЊГиЛЏЁЊЁЊШЋСЌНгЁЊЁЊЗжРрЛђЛиЙщ
ЧАЯђДЋВЅгыЗДЯђДЋВЅ
жЎЧАвбОНВНтСЫОэЛ§ВуЧАЯђДЋВЅЙ§ГЬЃЌетРяЭЈЙ§вЛеХЭМдйЛиЙЫвЛЯТЃК
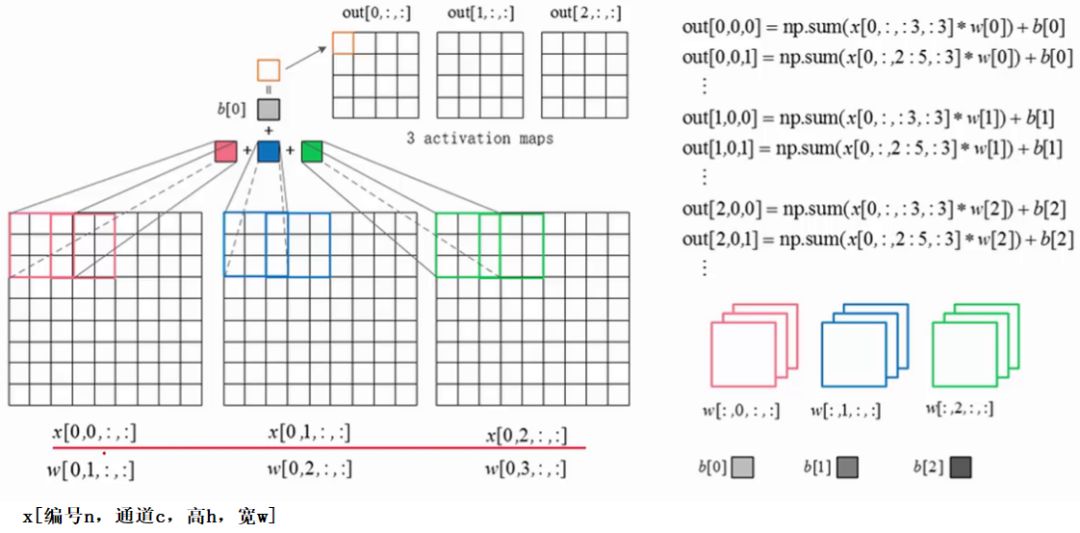
ЯТУцНВНтОэЛ§ВуЕФЗДЯђДЋВЅЙ§ГЬЃК
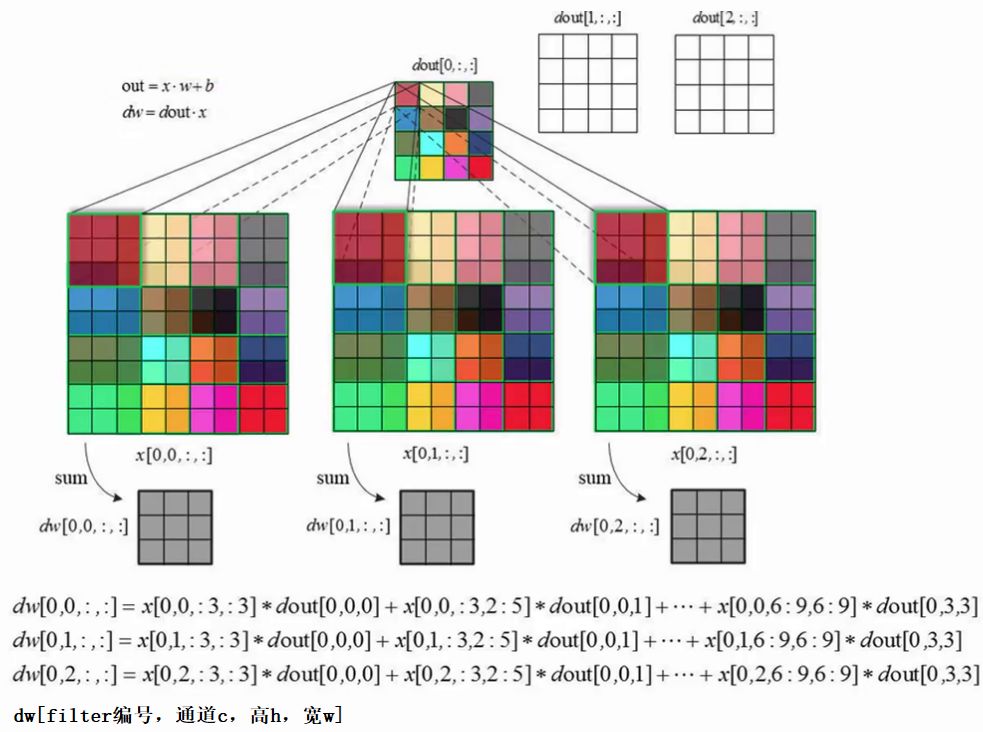
ЗДЯђДЋВЅЕФФПЕФЃКИќаТВЮЪ§wЁЃвђДЫвЊЯШЫуГіdJ/dwЁЃМйЩшЩЯвЛВуЛсДЋЙ§РДвЛИіЬнЖШdJ/doutЃЌИљОнСДЪНЧѓЕМЗЈдђЃЌвђДЫdJ/dw
= dJ/dout * dout/dw =dJ/dout * x ЁЃдкМЦЫуЛњжаЗНБуЮЊБфСПУќУћЕФдЕЙЪЃЌНЋdJ/doutМЧЮЊdoutЃЌdJ/dwМЧЮЊdwЃЌМДЭМжаЕФЧщПіЁЃКѓУцвВгУетИіМЧКХРДНВЁЃ
ЪзЯШвЊЧхГўЃКdw КЭ w ЕФГпДчЪЧвЛбљЕФЁЃвЛИіЕуГЫвдвЛИіЧјгђЛЙФмЕУЕНвЛИіЧјгђЁЃФЧУДЗДЯђДЋВЅЙ§ГЬОЭЯрЕБгкЃКгУdoutжаЕФвЛИідЊЫиГЫвдЪфШыВуЛЎДАРяЕФОиеѓБуЕУЕНвЛИіdwОиеѓЃЛШЛКѓЛЌЖЏЛЌДАЃЌМЬајЧѓЯТвЛИіdwЃЌвРДЮЯТШЅЃЌзюКѓНЋЕУЕНЕФЖрИіdwЯрМгЃЌжДаа
w = w - dw ОЭЭъГЩСЫЗДЯђДЋВЅЕФМЦЫуЁЃ
ЩЯУцЕФЗДЯђДЋВЅПЩвдИќаТвЛИіfilterжаЕФВЮЪ§ЃЌЛЙвЊЧѓЦфЫћЕФfilterЁЃ

ЯТУцгУЭМЪОРДПДвЛЯТ2жжВЛЭЌЕФpoolingЙ§ГЬЁЊЁЊГиЛЏВуЕФЧАЯђДЋВЅЃК
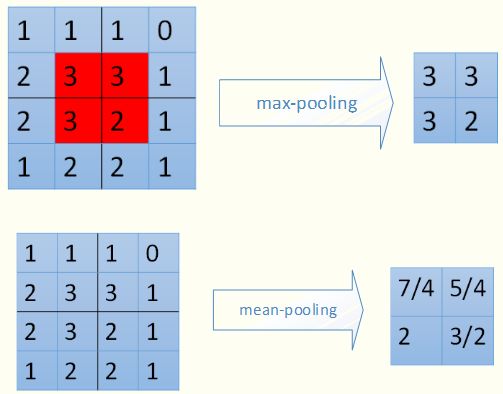
дкГиЛЏВуНјааЗДЯђДЋВЅЪБЃЌmax-poolingКЭmean-poolingЕФЗНЪНвВВЩгУВЛЭЌЕФЗНЪНЁЃ
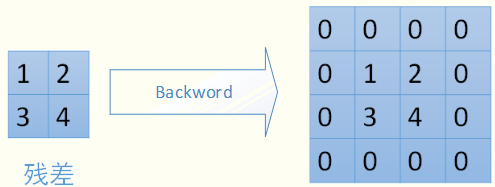
Ждгкmax-poolingЃЌдкЧАЯђМЦЫуЪБЃЌЪЧбЁШЁЕФУПИі2*2ЧјгђжаЕФзюДѓжЕЃЌетРяашвЊМЧТМЯТзюДѓжЕдкУПИіаЁЧјгђжаЕФЮЛжУЁЃдкЗДЯђДЋВЅЪБЃЌжЛгаФЧИізюДѓжЕЖдЯТвЛВугаЙБЯзЃЌЫљвдНЋВаВюДЋЕнЕНИУзюДѓжЕЕФЮЛжУЃЌЧјгђФкЦфЫћ2*2-1=3ИіЮЛжУжУСуЁЃОпЬхЙ§ГЬШчЯТЭМЃЌЦфжа4*4ОиеѓжаЗЧСуЕФЮЛжУМДЮЊЧАБпМЦЫуГіРДЕФУПИіаЁЧјгђЕФзюДѓжЕЕФЮЛжУ
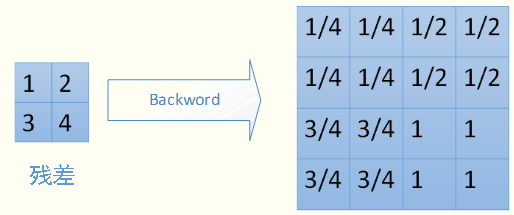
Ждгкmean-poolingЃЌЮвУЧашвЊАбВаВюЦНОљЗжГЩ2*2=4ЗнЃЌДЋЕнЕНЧАБпаЁЧјгђЕФ4ИіЕЅдЊМДПЩЁЃОпЬхЙ§ГЬШчЭМЃК
ОэЛ§ЭјТчМмЙЙЪЕР§
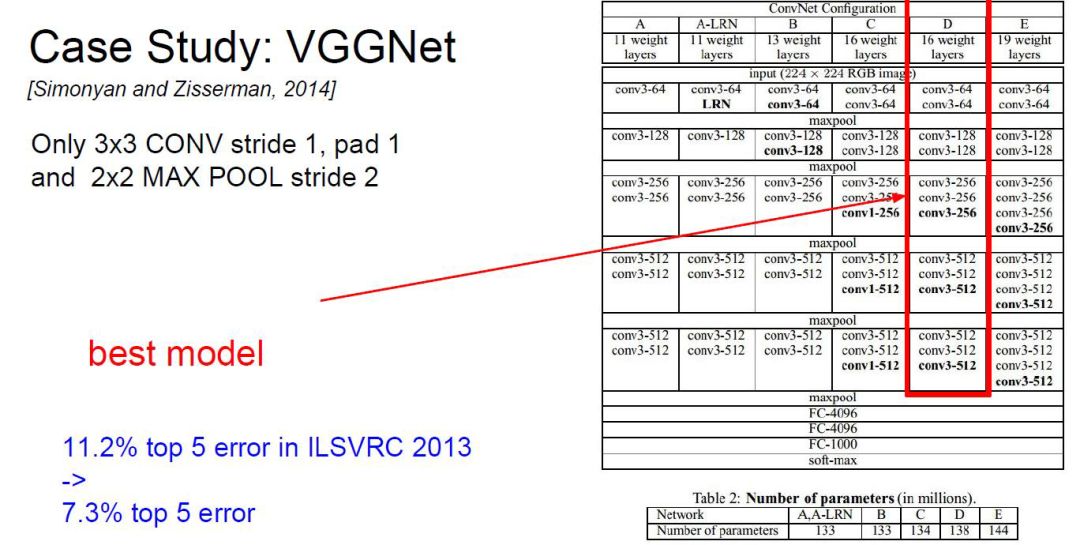
VGGNetЩюЖШИќЖрЃЌгаКмЖрОэЛ§ВуКЭГиЛЏВуЁЃвЛИіАцБОга16ВуЃЌСэвЛИіАцБОга19ВуЃЈНЯГЃгУЃЉЁЃ
VGGNetЕФЬиЕуЃК
filterжЛга3*3ЕФЃЌвтЮЖзХМЦЫуЕФЬиеїНЯЖрЃЌСЃЖШИќЯИЁЃЭЌЪБpoolingЕФВЮЪ§вВгаЙЬЖЈЁЃ
зЂвтЃКДЋЭГЕФОэЛ§ЩёОЭјТчВуЪ§дНЖрВЂвдвтЮЖзХаЇЙћИќКУЁЃЖјдк2016ФъЭЦГіСЫЩюЖШВаВюЭјТчДяЕНСЫ152ВуЁЃКѓајНВНщЩмЁЃ
ФЧУДбЕСЗвЛИіVGGNetгаЖрЩйФкДцПЊЯњФиЃП

ДгЭМПЩЕУжЊЃЌбЕСЗЙ§ГЬжавЛеХ224*224*3ЕФЭМЯёЛсга138MИіВЮЪ§ЛсеМ93MBЕФФкДцЁЃвђДЫУПИіbatchжаЭМЯёЕФЪ§ФПгІИУЪмФкДцЕФдМЪјЃЌМД
93*ЭМЯёЪ§ФП<ФкДцзмШнСПЁЃ
|









