| БрМЭЦМі: |
БОЮФРДздМђЪщЃЌЮФеТжївЊНВНтСЫCNNЕФЛљБОИХФюЃЌгЩЪВУДНсЙЙзщГЩЕФЃЌОэЛ§ЩёОЭјТч
VS. ДЋЭГЩёОЭјТчЯрЙиФкШнЁЃ
|
|
ГѕЪЖОэЛ§ЩёОЭјТчЃЈCNNЃЉ
ДгНёЬьЦ№ЃЌе§ЪНПЊЪМНВНтОэЛ§ЩёОЭјТчЁЃетЪЧвЛжждјОШУЮвЮоТлШчКЮвВЮоЗЈХЊУїАзЕФЖЋЮїЃЌжївЊЪЧУћзжОЭЬЋЁАИпМЖЁБСЫЃЌЭјЩЯЕФИїжжИїбљЕФЮФеТРДНщЩмЁАЪВУДЪЧОэЛ§ЁБгШЮЊШУШЫЪмВЛСЫЁЃ
вЛЁЂв§згЁЊЁЊЁЊЁЊБпНчМьВт
ЮвУЧРДПДвЛИізюМђЕЅЕФР§згЃКЁАБпНчМьВтЃЈedge detectionЃЉЁБЃЌМйЩшЮвУЧгаетбљЕФвЛеХЭМЦЌЃЌДѓаЁ8ЁС8ЃК
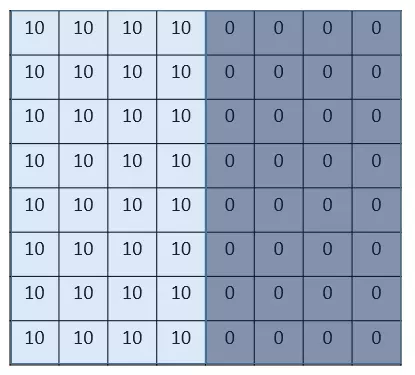
ЭМЦЌжаЕФЪ§зжДњБэИУЮЛжУЕФЯёЫижЕЃЌЮвУЧжЊЕРЃЌЯёЫижЕдНДѓЃЌбеЩЋдНССЃЌЫљвдЮЊСЫЪОвтЃЌЮвУЧАбгвБпаЁЯёЫиЕФЕиЗНЛГЩЩюЩЋЁЃЭМЕФжаМфСНИібеЩЋЕФЗжНчЯпОЭЪЧЮвУЧвЊМьВтЕФБпНчЁЃ
дѕУДМьВтетИіБпНчФиЃПЮвУЧПЩвдЩшМЦетбљЕФвЛИі ТЫВЈЦїЃЈfilterЃЌвВГЦЮЊkernelЃЉЃЌДѓаЁ3ЁС3ЃК
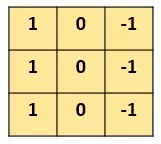
filter
ШЛКѓЃЌЮвУЧгУетИіfilterЃЌЭљЮвУЧЕФЭМЦЌЩЯЁАИЧЁБЃЌИВИЧвЛПщИњfilterвЛбљДѓЕФЧјгђжЎКѓЃЌЖдгІдЊЫиЯрГЫЃЌШЛКѓЧѓКЭЁЃМЦЫувЛИіЧјгђжЎКѓЃЌОЭЯђЦфЫћЧјгђХВЖЏЃЌНгзХМЦЫуЃЌжБЕНАбдЭМЦЌЕФУПвЛИіНЧТфЖМИВИЧЕНСЫЮЊжЙЁЃетИіЙ§ГЬОЭЪЧ
ЁАОэЛ§ЁБЁЃ
ЃЈЮвУЧВЛгУЙмОэЛ§дкЪ§бЇЩЯЕНЕзЪЧжИЪВУДдЫЫуЃЌЮвУЧжЛгУжЊЕРдкCNNжаЪЧдѕУДМЦЫуЕФЁЃЃЉ
етРяЕФЁАХВЖЏЁБЃЌОЭЩцМАЕНвЛИіВНГЄСЫЃЌМйШчЮвУЧЕФВНГЄЪЧ1ЃЌФЧУДИВИЧСЫвЛИіЕиЗНжЎКѓЃЌОЭХВвЛИёЃЌШнвзжЊЕРЃЌзмЙВПЩвдИВИЧ6ЁС6ИіВЛЭЌЕФЧјгђЁЃ
ФЧУДЃЌЮвУЧНЋет6ЁС6ИіЧјгђЕФОэЛ§НсЙћЃЌЦДГЩвЛИіОиеѓЃК
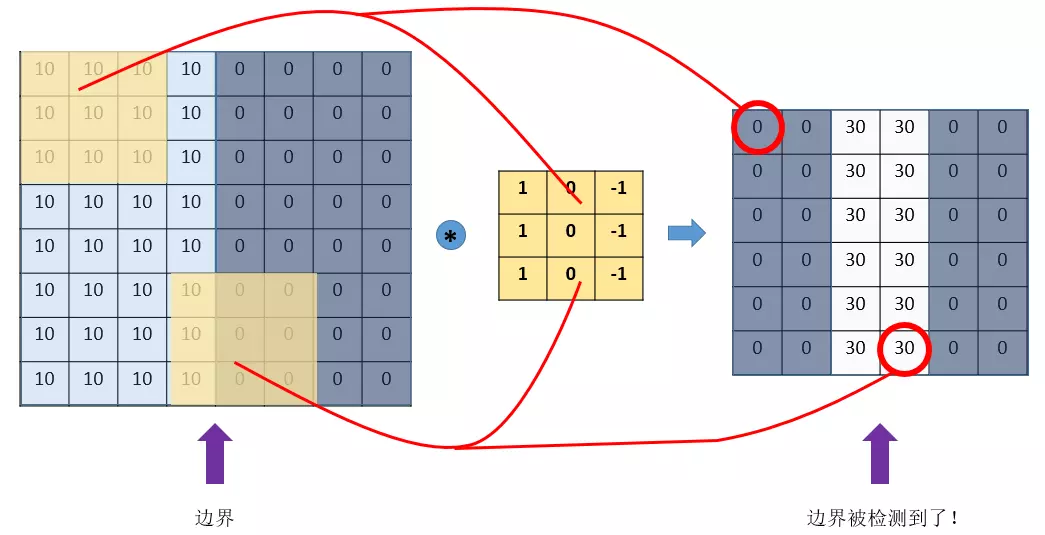
БпНчМьВт
кРЃПЃЁЗЂЯжСЫЪВУДЃП
етИіЭМЦЌЃЌжаМфбеЩЋЧГЃЌСНБпбеЩЋЩюЃЌетЫЕУїдлУЧЕФдЭМЦЌжаМфЕФБпНчЃЌдкетРяБЛЗДгГГіРДСЫ!
ДгЩЯУцетИіР§згжаЃЌЮвУЧЗЂЯжЃЌЮвУЧПЩвдЭЈЙ§ЩшМЦЬиЖЈЕФfilterЃЌШУЫќШЅИњЭМЦЌзіОэЛ§ЃЌОЭПЩвдЪЖБ№ГіЭМЦЌжаЕФФГаЉЬиеїЃЌБШШчБпНчЁЃ
ЩЯУцЕФР§згЪЧМьВтЪњжББпНчЃЌЮвУЧвВПЩвдЩшМЦГіМьВтЫЎЦНБпНчЕФЃЌжЛгУАбИеИеЕФfilterа§зЊ90ЁуМДПЩЁЃЖдгкЦфЫћЕФЬиеїЃЌРэТлЩЯжЛвЊЮвУЧОЙ§ОЋЯИЕФЩшМЦЃЌзмЪЧПЩвдЩшМЦГіКЯЪЪЕФfilterЕФЁЃ
ЮвУЧЕФCNNЃЈconvolutional neural networkЃЉЃЌжївЊОЭЪЧЭЈЙ§вЛИіИіЕФfilterЃЌВЛЖЯЕиЬсШЁЬиеїЃЌДгОжВПЕФЬиеїЕНзмЬхЕФЬиеїЃЌДгЖјНјааЭМЯёЪЖБ№ЕШЕШЙІФмЁЃ
ФЧУДЮЪЬтРДСЫЃЌЮвУЧдѕУДПЩФмШЅЩшМЦетУДЖрИїжжИїбљЕФfilterбНЃПЪзЯШЃЌЮвУЧЖМВЛвЛЖЈЧхГўЖдгквЛДѓЭЦЭМЦЌЃЌЮвУЧашвЊЪЖБ№ФФаЉЬиеїЃЌЦфДЮЃЌОЭЫужЊЕРСЫгаФФаЉЬиеїЃЌЯыецЕФШЅЩшМЦГіЖдгІЕФfilterЃЌПжХТвВВЂЗЧвзЪТЃЌвЊжЊЕРЃЌЬиеїЕФЪ§СППЩФмЪЧГЩЧЇЩЯЭђЕФЁЃ
ЦфЪЕбЇЙ§ЩёОЭјТчжЎКѓЃЌЮвУЧОЭжЊЕРЃЌетаЉfilterЃЌИљБООЭВЛгУЮвУЧШЅЩшМЦЃЌУПИіfilterжаЕФИїИіЪ§зжЃЌВЛОЭЪЧВЮЪ§Т№ЃЌЮвУЧПЩвдЭЈЙ§ДѓСПЕФЪ§ОнЃЌРД
ШУЛњЦїздМКШЅЁАбЇЯАЁБетаЉВЮЪ§ТяЁЃетЃЌОЭЪЧCNNЕФдРэЁЃ
ЖўЁЂCNNЕФЛљБОИХФю
1.padding ЬюАз
ДгЩЯУцЕФв§згжаЃЌЮвУЧПЩвджЊЕРЃЌдЭМЯёдкОЙ§filterОэЛ§жЎКѓЃЌБфаЁСЫЃЌДг(8,8)БфГЩСЫ(6,6)ЁЃМйЩшЮвУЧдйОэвЛДЮЃЌФЧДѓаЁОЭБфГЩСЫ(4,4)СЫЁЃ
етбљгаЩЖЮЪЬтФиЃП
жївЊгаСНИіЮЪЬтЃК
УПДЮОэЛ§ЃЌЭМЯёЖМЫѕаЁЃЌетбљОэВЛСЫМИДЮОЭУЛСЫЃЛ
ЯрБШгкЭМЦЌжаМфЕФЕуЃЌЭМЦЌБпдЕЕФЕудкОэЛ§жаБЛМЦЫуЕФДЮЪ§КмЩйЁЃетбљЕФЛАЃЌБпдЕЕФаХЯЂОЭвзгкЖЊЪЇЁЃ
ЮЊСЫНтОіетИіЮЪЬтЃЌЮвУЧПЩвдВЩгУpaddingЕФЗНЗЈЁЃЮвУЧУПДЮОэЛ§ЧАЃЌЯШИјЭМЦЌжмЮЇЖМВЙвЛШІПеАзЃЌШУОэЛ§жЎКѓЭМЦЌИњдРДвЛбљДѓЃЌЭЌЪБЃЌдРДЕФБпдЕвВБЛМЦЫуСЫИќЖрДЮЁЃ
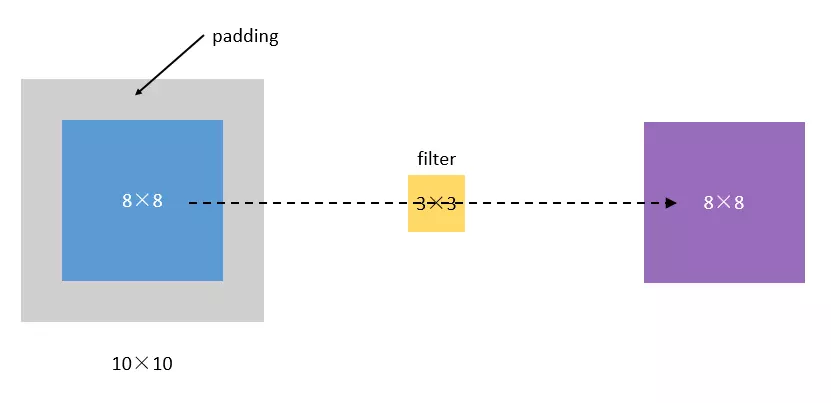
padding
БШШчЃЌЮвУЧАб(8,8)ЕФЭМЦЌИјВЙГЩ(10,10)ЃЌФЧУДОЙ§(3,3)ЕФfilterжЎКѓЃЌОЭЪЧ(8,8)ЃЌУЛгаБфЁЃ
ЮвУЧАбЩЯУцетжжЁАШУОэЛ§жЎКѓЕФДѓаЁВЛБфЁБЕФpaddingЗНЪНЃЌГЦЮЊ ЁАSameЁБЗНЪНЃЌ
АбВЛОЙ§ШЮКЮЬюАзЕФЃЌГЦЮЊ ЁАValidЁБЗНЪНЁЃетИіЪЧЮвУЧдкЪЙгУвЛаЉПђМмЕФЪБКђЃЌашвЊЩшжУЕФГЌВЮЪ§ЁЃ
2.stride ВНГЄ
ЧАУцЮвУЧЫљНщЩмЕФОэЛ§ЃЌЖМЪЧФЌШЯВНГЄЪЧ1ЃЌЕЋЪЕМЪЩЯЃЌЮвУЧПЩвдЩшжУВНГЄЮЊЦфЫћЕФжЕЁЃ
БШШчЃЌЖдгк(8,8)ЕФЪфШыЃЌЮвУЧгУ(3,3)ЕФfilterЃЌ
ШчЙћstride=1ЃЌдђЪфГіЮЊ(6,6);
ШчЙћstride=2ЃЌдђЪфГіЮЊ(3,3);ЃЈетРяР§згОйЕУВЛДѓКУЃЌГ§ВЛЖЯОЭЯђЯТШЁећЃЉ
3.pooling ГиЛЏ
етИіpoolingЃЌЪЧЮЊСЫЬсШЁвЛЖЈЧјгђЕФжївЊЬиеїЃЌВЂМѕЩйВЮЪ§Ъ§СПЃЌЗРжЙФЃаЭЙ§ФтКЯЁЃ
БШШчЯТУцЕФMaxPoolingЃЌВЩгУСЫвЛИі2ЁС2ЕФДАПкЃЌВЂШЁstride=2ЃК
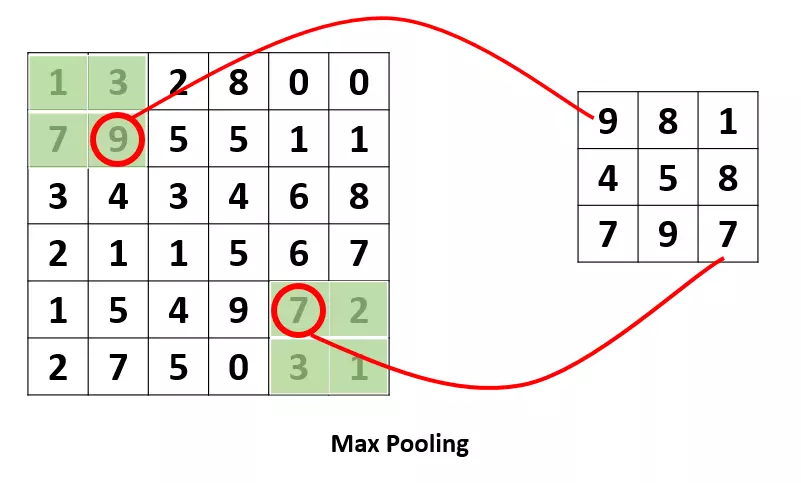
Maxpooling
Г§СЫMaxPooling,ЛЙгаAveragePoolingЃЌЙЫУћЫМвхОЭЪЧШЁФЧИіЧјгђЕФЦНОљжЕЁЃ
4.ЖдЖрЭЈЕРЃЈchannelsЃЉЭМЦЌЕФОэЛ§
етИіашвЊЕЅЖРЬсвЛЯТЁЃВЪЩЋЭМЯёЃЌвЛАуЖМЪЧRGBШ§ИіЭЈЕРЃЈchannelЃЉЕФЃЌвђДЫЪфШыЪ§ОнЕФЮЌЖШвЛАугаШ§ИіЃКЃЈГЄЃЌПэЃЌЭЈЕРЃЉЁЃ
БШШчвЛИі28ЁС28ЕФRGBЭМЦЌЃЌЮЌЖШОЭЪЧ(28,28,3)ЁЃ
ЧАУцЕФв§згжаЃЌЪфШыЭМЦЌЪЧ2ЮЌЕФ(8,8)ЃЌfilterЪЧ(3,3)ЃЌЪфГівВЪЧ2ЮЌЕФ(6,6)ЁЃ
ШчЙћЪфШыЭМЦЌЪЧШ§ЮЌЕФФиЃЈМДдіЖрСЫвЛИіchannelsЃЉЃЌБШШчЪЧ(8,8,3)ЃЌетИіЪБКђЃЌЮвУЧЕФfilterЕФЮЌЖШОЭвЊБфГЩ(3,3,3)СЫЃЌЫќЕФ
зюКѓвЛЮЌвЊИњЪфШыЕФchannelЮЌЖШвЛжТЁЃ
етИіЪБКђЕФОэЛ§ЃЌЪЧШ§ИіchannelЕФЫљгадЊЫиЖдгІЯрГЫКѓЧѓКЭЃЌвВОЭЪЧжЎЧАЪЧ9ИіГЫЛ§ЕФКЭЃЌЯждкЪЧ27ИіГЫЛ§ЕФКЭЁЃвђДЫЃЌЪфГіЕФЮЌЖШВЂВЛЛсБфЛЏЁЃЛЙЪЧ(6,6)ЁЃ
ЕЋЪЧЃЌвЛАуЧщПіЯТЃЌЮвУЧЛс ЪЙгУЖрСЫfiltersЭЌЪБОэЛ§ЃЌБШШчЃЌШчЙћЮвУЧЭЌЪБЪЙгУ4ИіfilterЕФЛАЃЌФЧУД
ЪфГіЕФЮЌЖШдђЛсБфЮЊ(6,6,4)ЁЃ
ЮвЬиЕиЛСЫЯТУцетИіЭМЃЌРДеЙЪОЩЯУцЕФЙ§ГЬЃК
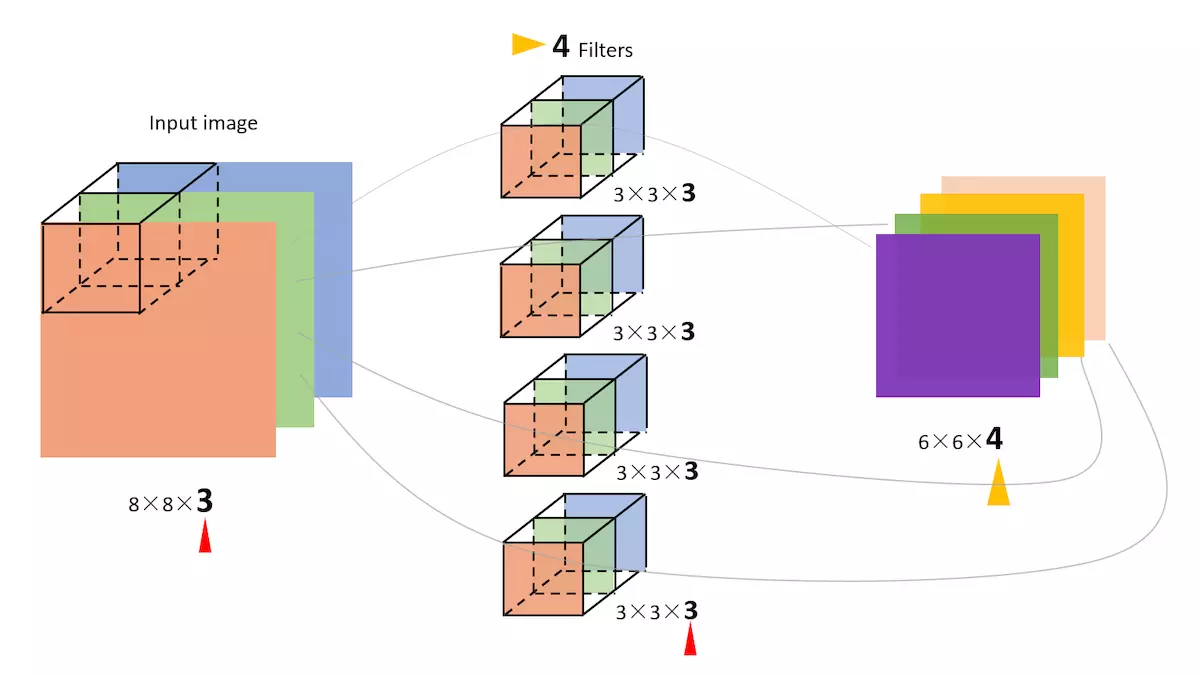
ЭЌЪБга4Иіfilter
ЭМжаЕФЪфШыЭМЯёЪЧ(8,8,3)ЃЌfilterга4ИіЃЌДѓаЁОљЮЊ(3,3,3)ЃЌЕУЕНЕФЪфГіЮЊ(6,6,4)ЁЃ
ЮвОѕЕУетИіЭМвбОЛЕФКмЧхЮњСЫЃЌЖјЧвИјГіСЫ3КЭ4етИіСНИіЙиМќЪ§зжЪЧдѕУДРДЕФЃЌЫљвдЮвОЭВЛЊрТСЫЃЈетИіЭМЛСЫЮвЦ№Ты40ЗжжгЃЉЁЃ
ЦфЪЕЃЌШчЙћЬзгУЮвУЧЧАУцбЇЙ§ЕФЩёОЭјТчЕФЗћКХРДПДД§CNNЕФЛАЃЌ
ЮвУЧЕФЪфШыЭМЦЌОЭЪЧXЃЌshape=(8,8,3);
4ИіfiltersЦфЪЕОЭЪЧЕквЛВуЩёН№ЭјТчЕФВЮЪ§W1,ЃЌshape=(3,3,3,4),етИі4ЪЧжИга4Иіfilters;
ЮвУЧЕФЪфГіЃЌОЭЪЧZ1ЃЌshape=(6,6,4);
КѓУцЦфЪЕЛЙгІИУгавЛИіМЄЛюКЏЪ§ЃЌБШШчreluЃЌОЙ§МЄЛюКѓЃЌZ1БфЮЊA1ЃЌshape=(6,6,4);
ЫљвдЃЌдкЧАУцЕФЭМжаЃЌЮвМгвЛИіМЄЛюКЏЪ§ЃЌИјЖдгІЕФВПЗжБъЩЯЗћКХЃЌОЭЪЧетбљЕФЃК
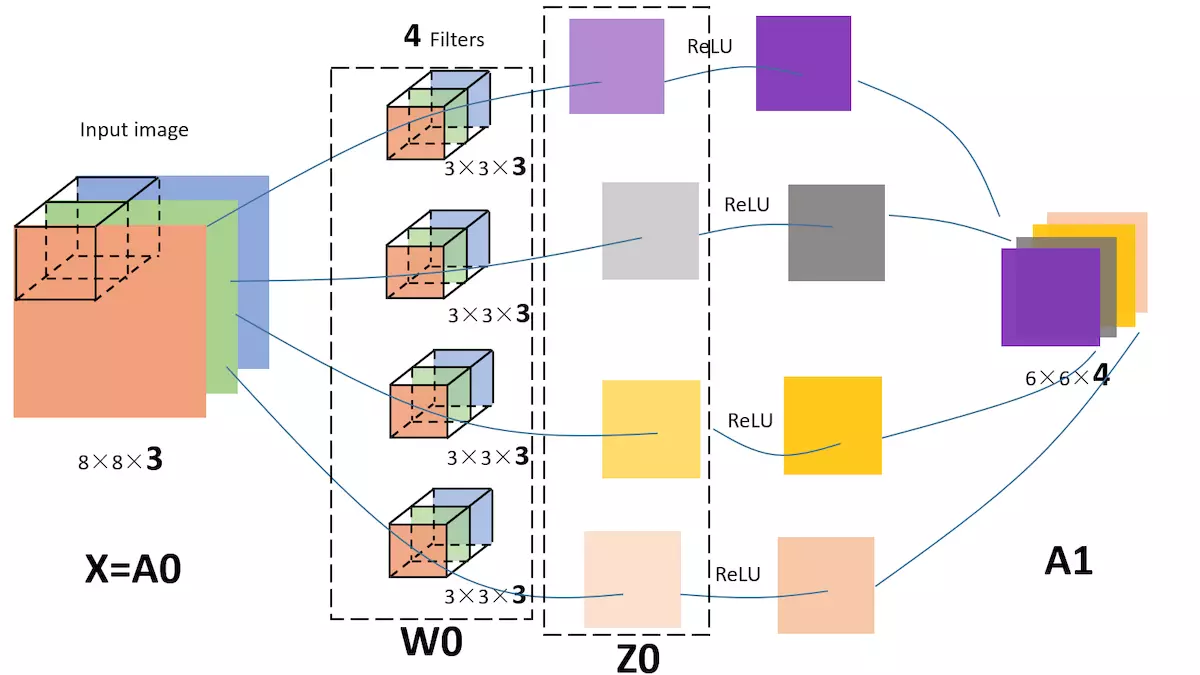
ХЛаФСЄбЊЛЕФКУЭМЦЌЃЌжЕЕУЪеВи
Ш§ЁЂCNNЕФНсЙЙзщГЩ
ЩЯУцЮвУЧвбОжЊЕРСЫОэЛ§ЃЈconvolutionЃЉЁЂГиЛЏЃЈpoolingЃЉвдМАЬюАзЃЈpaddingЃЉЪЧдѕУДНјааЕФЃЌНгЯТРДЮвУЧОЭРДПДПДCNNЕФећЬхНсЙЙЃЌЫќАќКЌСЫ3жжВуЃЈlayerЃЉЃК
1. Convolutional layerЃЈОэЛ§Ву--CONVЃЉ
гЩТЫВЈЦїfiltersКЭМЄЛюКЏЪ§ЙЙГЩЁЃ
вЛАувЊЩшжУЕФГЌВЮЪ§АќРЈfiltersЕФЪ§СПЁЂДѓаЁЁЂВНГЄЃЌвдМАpaddingЪЧЁАvalidЁБЛЙЪЧЁАsameЁБЁЃЕБШЛЃЌЛЙАќРЈбЁдёЪВУДМЄЛюКЏЪ§ЁЃ
2. Pooling layer ЃЈГиЛЏВу--POOLЃЉ
етРяРяУцУЛгаВЮЪ§ашвЊЮвУЧбЇЯАЃЌвђЮЊетРяРяУцЕФВЮЪ§ЖМЪЧЮвУЧЩшжУКУСЫЃЌвЊУДЪЧMaxpoolingЃЌвЊУДЪЧAveragepoolingЁЃ
ашвЊжИЖЈЕФГЌВЮЪ§ЃЌАќРЈЪЧMaxЛЙЪЧaverageЃЌДАПкДѓаЁвдМАВНГЄЁЃ
ЭЈГЃЃЌЮвУЧЪЙгУЕФБШНЯЖрЕФЪЧMaxpooling,ЖјЧввЛАуШЁДѓаЁЮЊ(2,2)ВНГЄЮЊ2ЕФfilterЃЌетбљЃЌОЙ§poolingжЎКѓЃЌЪфШыЕФГЄПэЖМЛсЫѕаЁ2БЖЃЌchannelsВЛБфЁЃ
3. Fully Connected layerЃЈШЋСЌНгВу--FCЃЉ
етИіЧАУцУЛгаНВЃЌЪЧвђЮЊетИіОЭЪЧЮвУЧзюЪьЯЄЕФМвЛяЃЌОЭЪЧЮвУЧжЎЧАбЇЕФЩёОЭјТчжаЕФФЧжжзюЦеЭЈЕФВуЃЌОЭЪЧвЛХХЩёОдЊЁЃвђЮЊетвЛВуЪЧУПвЛИіЕЅдЊЖМКЭЧАвЛВуЕФУПвЛИіЕЅдЊЯрСЌНгЃЌЫљвдГЦжЎЮЊЁАШЋСЌНгЁБЁЃ
етРявЊжИЖЈЕФГЌВЮЪ§ЃЌЮоЗЧОЭЪЧЩёОдЊЕФЪ§СПЃЌвдМАМЄЛюКЏЪ§ЁЃ
НгЯТРДЃЌЮвУЧЫцБуПДвЛИіCNNЕФФЃбљЃЌРДЛёШЁЖдCNNЕФвЛаЉИаадШЯЪЖЃК
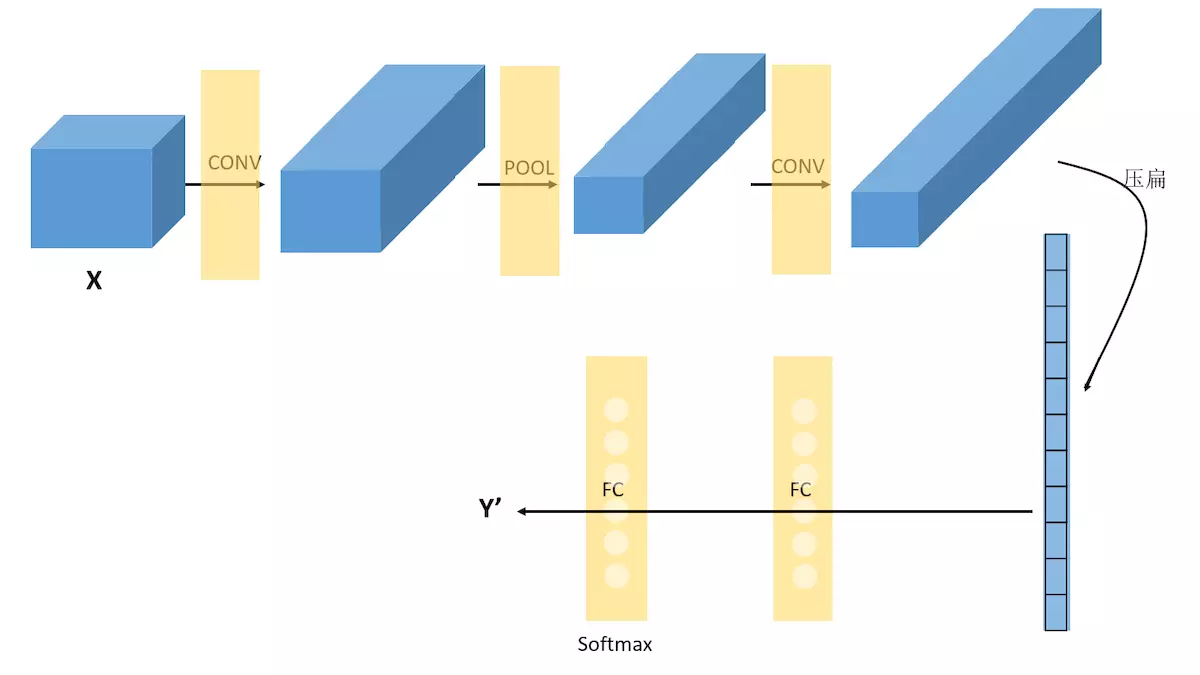
вЛИіCNNЕФР§зг
ЩЯУцетИіCNNЪЧЮвЫцБуХФФдУХЯыЕФвЛИіЁЃЫќЕФНсЙЙПЩвдгУЃК
X-->CONV(relu)-->MAXPOOL-->CONV(relu)-->FC(relu)-->FC(softmax)-->Y
РДБэЪОЁЃ
етРяашвЊЫЕУїЕФЪЧЃЌдкОЙ§Ъ§ДЮОэЛ§КЭГиЛЏжЎКѓЃЌЮвУЧ зюКѓЛсЯШНЋЖрЮЌЕФЪ§ОнНјааЁАБтЦНЛЏЁБЃЌвВОЭЪЧАб (height,width,channel)ЕФЪ§ОнбЙЫѕГЩГЄЖШЮЊ
height ЁС width ЁС channel ЕФвЛЮЌЪ§зщЃЌШЛКѓдйгы FCВуСЌНгЃЌетжЎКѓОЭИњЦеЭЈЕФЩёОЭјТчЮовьСЫЁЃ
ПЩвдДгЭМжаПДЕНЃЌЫцзХЭјТчЕФЩюШыЃЌЮвУЧЕФЭМЯёЃЈбЯИёРДЫЕжаМфЕФФЧаЉВЛФмНаЭМЯёСЫЃЌЕЋЪЧЮЊСЫЗНБуЃЌЛЙЪЧетбљЫЕАЩЃЉдНРДдНаЁЃЌЕЋЪЧchannelsШДдНРДдНДѓСЫЁЃдкЭМжаЕФБэЪООЭЪЧГЄЗНЬхУцЖдЮвУЧЕФУцЛ§дНРДдНаЁЃЌЕЋЪЧГЄЖШШДдНРДдНГЄСЫЁЃ
ЫФЁЂОэЛ§ЩёОЭјТч VS. ДЋЭГЩёОЭјТч
ЦфЪЕЯждкЛиЙ§ЭЗРДПДЃЌCNNИњЮвУЧжЎЧАбЇЯАЕФЩёОЭјТчЃЌвВУЛгаКмДѓЕФВюБ№ЁЃ
ДЋЭГЕФЩёОЭјТчЃЌЦфЪЕОЭЪЧЖрИіFCВуЕўМгЦ№РДЁЃ
CNNЃЌЮоЗЧОЭЪЧАбFCИФГЩСЫCONVКЭPOOLЃЌОЭЪЧАбДЋЭГЕФгЩвЛИіИіЩёОдЊзщГЩЕФlayerЃЌБфГЩСЫгЩfiltersзщГЩЕФlayerЁЃ
ФЧУДЃЌЮЊЪВУДвЊетбљБфЃПгаЪВУДКУДІЃП
ОпЬхЫЕРДгаСНЕуЃК
1.ВЮЪ§ЙВЯэЛњжЦЃЈparameters sharingЃЉ
ЮвУЧЖдБШвЛЯТДЋЭГЩёОЭјТчЕФВуКЭгЩfiltersЙЙГЩЕФCONVВуЃК
МйЩшЮвУЧЕФЭМЯёЪЧ8ЁС8ДѓаЁЃЌвВОЭЪЧ64ИіЯёЫиЃЌМйЩшЮвУЧгУвЛИіга9ИіЕЅдЊЕФШЋСЌНгВуЃК
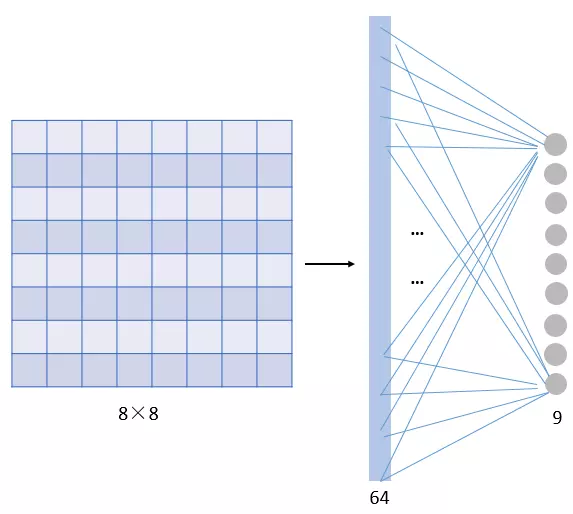
ЪЙгУШЋСЌНг
ФЧетвЛВуЮвУЧашвЊЖрЩйИіВЮЪ§ФиЃПашвЊ 64ЁС9 = 576ИіВЮЪ§ЃЈЯШВЛПМТЧЦЋжУЯюbЃЉЁЃвђЮЊУПвЛИіСДНгЖМашвЊвЛИіШЈжиwЁЃ
ФЧЮвУЧПДПД ЭЌбљга9ИіЕЅдЊЕФfilterЪЧдѕУДбљЕФЃК
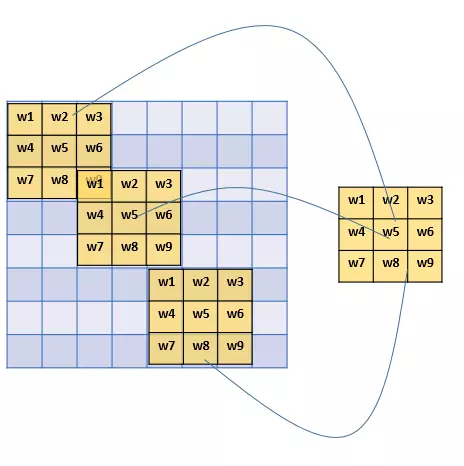
ЪЙгУfilter
ЦфЪЕВЛгУПДОЭжЊЕРЃЌгаМИИіЕЅдЊОЭМИИіВЮЪ§ЃЌЫљвдзмЙВОЭ9ИіВЮЪ§ЃЁ
вђЮЊЃЌЖдгкВЛЭЌЕФЧјгђЃЌЮвУЧЖМЙВЯэЭЌвЛИіfilterЃЌвђДЫОЭЙВЯэетЭЌвЛзщВЮЪ§ЁЃ
етвВЪЧгаЕРРэЕФЃЌЭЈЙ§ЧАУцЕФНВНтЮвУЧжЊЕРЃЌfilterЪЧгУРДМьВтЬиеїЕФЃЌФЧвЛИіЬиеївЛАуЧщПіЯТКмПЩФмдкВЛжЙвЛИіЕиЗНГіЯжЃЌБШШчЁАЪњжББпНчЁБЃЌОЭПЩФмдквЛЗљЭМжаЖрГіГіЯжЃЌФЧУД
ЮвУЧЙВЯэЭЌвЛИіfilterВЛНіЪЧКЯРэЕФЃЌЖјЧвЪЧгІИУетУДзіЕФЁЃ
гЩДЫПЩМћЃЌВЮЪ§ЙВЯэЛњжЦЃЌШУЮвУЧЕФЭјТчЕФВЮЪ§Ъ§СПДѓДѓЕиМѕЩйЁЃетбљЃЌЮвУЧПЩвдгУНЯЩйЕФВЮЪ§ЃЌбЕСЗГіИќМгКУЕФФЃаЭЃЌЕфаЭЕФЪТАыЙІБЖЃЌЖјЧвПЩвдгааЇЕи
БмУтЙ§ФтКЯЁЃ
ЭЌбљЃЌгЩгкfilterЕФВЮЪ§ЙВЯэЃЌМДЪЙЭМЦЌНјааСЫвЛЖЈЕФЦНвЦВйзїЃЌЮвУЧеебљПЩвдЪЖБ№ГіЬиеїЃЌетНазі ЁАЦНвЦВЛБфадЁБЁЃвђДЫЃЌФЃаЭОЭИќМгЮШНЁСЫЁЃ
2.СЌНгЕФЯЁЪшадЃЈsparsity of connectionsЃЉ
гЩОэЛ§ЕФВйзїПЩжЊЃЌЪфГіЭМЯёжаЕФШЮКЮвЛИіЕЅдЊЃЌжЛИњЪфШыЭМЯёЕФвЛВПЗжгаЙиЯЕЃК
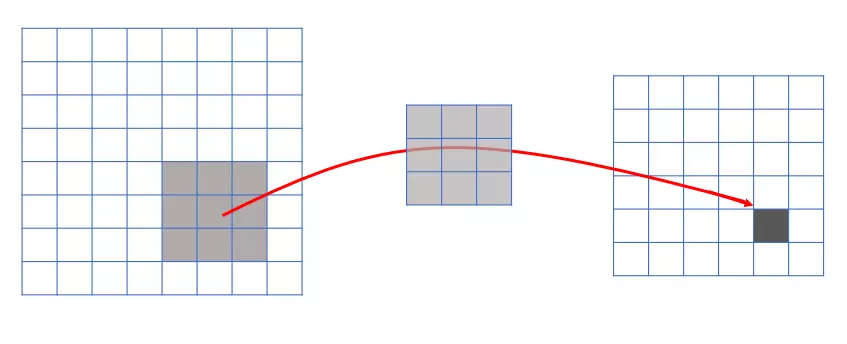
жЛИњЪфШыЕФвЛВПЗжгаЙи
ЖјДЋЭГЩёОЭјТчжаЃЌгЩгкЖМЪЧШЋСЌНгЃЌЫљвдЪфГіЕФШЮКЮвЛИіЕЅдЊЃЌЖМвЊЪмЪфШыЕФЫљгаЕФЕЅдЊЕФгАЯьЁЃетбљЮоаЮжаЛсЖдЭМЯёЕФЪЖБ№аЇЙћДѓДђелПлЁЃБШНЯЃЌУПвЛИіЧјгђЖМгаздМКЕФзЈЪєЬиеїЃЌЮвУЧВЛЯЃЭћЫќЪмЕНЦфЫћЧјгђЕФгАЯьЁЃ
е§ЪЧгЩгкЩЯУцетСНДѓгХЪЦЃЌЪЙЕУCNNГЌдНСЫДЋЭГЕФNNЃЌПЊЦєСЫЩёОЭјТчЕФаТЪБДњЁЃ
|









