| БрМЭЦМі: |
|
БОЮФРДздweixinЃЌБОЮФНщЩмСЫR-CNN
ЛљБОНсЙЙКЭдРэЃЌYOLOЕФЛљБОдРэЃЌЭЦРэЙ§ГЬЃЌМЦЫу lossвдМАОпЬхЪЕгУЙ§ГЬЕШЁЃ
|
|
в§Шы
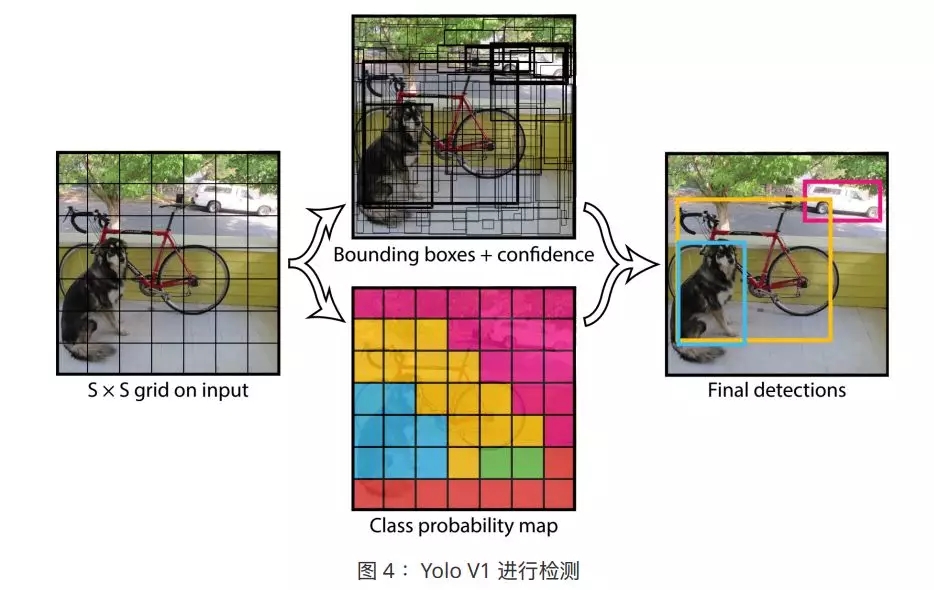
ФПБъМьВтЫуЗЈЪЧМЦЫуЛњЪгОѕШ§ДѓЛљДЁШЮЮёжЎвЛЃЌЦфАќРЈФПБъЖЈЮЛКЭФПБъЗжРрСНВПЗжЁЃ
дк yolo ЯЕСаГіРДжЎЧАЃЌжїСїЕФзіЗЈЪЧЗжЖЮЪНЕФ R-CNN ЯЕСаЃЌжївЊАќРЈ R-CNNЁЂFast
R-CNNЁЂFaster R-CNNЁЂMask R-CNN ЕШЁЃ
R-CNN ЛљБОНсЙЙКЭдРэ
R-CNN ЕФЛљБОНсЙЙШчЯТЭМЫљЪОЃК
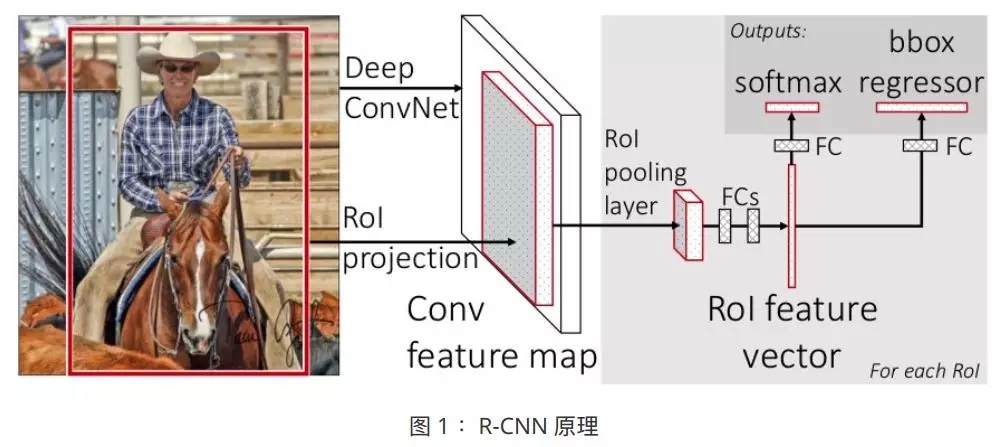
R-CNN жївЊЗжЮЊКђбЁЧјЬсШЁКЭКђбЁЧјЗжРрСНИіНзЖЮЃЌВЂЧвСННзЖЮЗжПЊбЕСЗЁЃЦфжївЊЫМЯыШчЯТЁЃ
ЪзЯШЭЈЙ§бЁдёадЫбЫїЃЈSelective SearchЃЉЖдЪфШыНјааГЌЯёЫиКЯВЂЃЌВњЩњЛљДЁЕФзгЧјгђЁЃШЛКѓНЋаЁЕФзгЧјгђВЛЖЯКЯВЂГЩДѓЧјгђЃЌВЂДгжаевГіПЩФмДцдкЮяЬхЕФЧјгђЃЌетИіЙ§ГЬМДКђбЁЧјЬсШЁЃЈRegion
ProposalЃЉЁЃ
ЬсШЁГіАќКЌФПБъЕФКђбЁЧјжЎКѓЃЌашвЊЖдЦфНјааЗжРрЃЌХаЖЈФПБъЪєгкФФвЛРрЁЃПЩвдЭЈЙ§ SVM Лђ CNN ЕШЫуЗЈНјааЗжРрЁЃ
R-CNN ЕФВЛзугыИФНј
SPP КЭ ROI
вЊЪЕЯжНЯЮЊЪЕгУЕФ R-CNN ЭјТчЃЌЭљЭљашвЊЖдЪфШыбљеХЬсШЁЩЯЧЇИіКђбЁЧјЃЌВЂЖдУПИіКђбЁЧјНјаавЛДЮЗжРрдЫЫуЁЃгкЪЧЃЌКѓајГіЯжПеМфН№зжЫўГиЛЏЃЈSPPЃЉ
КЭ region of interestЃЈ`ROIЃЉЕШЗНЪННјааИФНјЁЃ
ЦфЛљБОЫМЯыЪЧЃЌЪфШыЭМЦЌжаЕФФПБъЧјгђЃЌОЙ§ CNN КѓЃЌЕУЕНЕФЬиеїЭМжаЃЌЭљЭљвВДцдкзХЖдгІЕФФПБъЧјгђЃЌДЫМД
ROIЁЃКѓајЖдИУЬиеїЭМЃЈЖржжГпЖШЃЉЩЯЕФ ROI НјааЗжРрЃЌДЫМД SPPЁЃ
ЭЈЙ§етжжЗНЪНЃЌПЩвдЙВгУЬиеїЬсШЁВПЗжЃЌжЛЖдзюКѓЕФЬиеїЭМНјааКђбЁЧјЬсШЁКЭЗжРрЁЃетбљОЭПЩвдМЋДѓЕиМѕЩйзмЕФМЦЫуСПЃЌВЂЬсЩ§адФмЁЃ
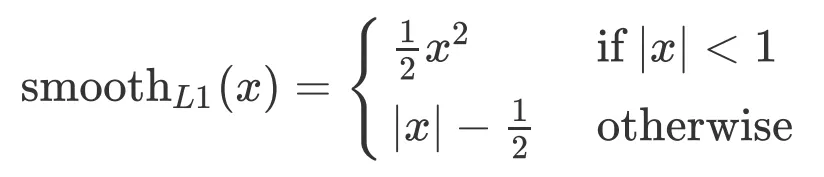
Fast R-CNN
ЕЋЪЧЃЌSPP КЭ ROI ЗНЪНЃЌШдОЩашвЊЗжЖЮбЕСЗЁЃЦфВЛНіТщЗГЃЌЭЌЪБЛЙЗжИюСЫ bounding box
ЛиЙщбЕСЗгыЗжРрЭјТчЕФбЕСЗЁЃетЪЙЕУећИіКЏЪ§ЕФгХЛЏЙ§ГЬВЛвЛжТЃЌДгЖјЯожЦСЫИќИпОЋЖШЕФПЩФмЁЃ
гкЪЧЃЌдйДЮЖдЦфНјааИФНјЃК
1.Нјаа ROI ЬиеїЬсШЁжЎКѓЃЌНЋСНжжЫ№ЪЇНјааКЯВЂЃЌЭГвЛбЕСЗЁЃетбљЯрЖдвзгкбЕСЗЃЌЧваЇТЪИќИп
2.НЋ SPP ЛЛзі ROI Pooling
3.Ждгк bounding box ВПЗжЕФ lossЃЌЪЙгУ Smooth l1 КЏЪ§ЃЌПЩвдЬсЩ§ЮШЖЈад
Faster R-CNN
дк Fast R-CNN жаЃЌЖд ROI ЖјЗЧдЭМЕФКђбЁЧјНјааЗжРрЃЌЬсЩ§ЫйЖШЁЃвђДЫЃЌЯТвЛВНПЩвдЖдКђбЁЧјЬсШЁВПЗжНјаагХЛЏЃЌЬсЩ§адФмЁЃ
вђДЫЃЌдк Faster R-CNN жаЃЌВЛдйЖддЭМНјааКђбЁЧјЬсШЁЃЌЖјЪЧжБНгЖдОЙ§ CNN КѓЕФЬиеїЭМНјааКђбЁЧјЬсШЁЃЌетВПЗжЭјТчЃЌМД
Region Proposal NetworksЃЈRPNЃЉЁЃ
жЎКѓЃЌНЋКђбЁЧјЗжБ№ЫЭШыСНИізгЭјТчЃЌЗжБ№гУгыМЦЫу bounding box ЕФзјБъКЭКђбЁЧјЕФРрБ№ЁЃШчЭМ
1 ЫљЪОЁЃ
ЭЈЙ§етжжЗНЪНЃЌПЩвдНјвЛВНМѕЩйМЦЫуСПЃЌКЯВЂСНИіНзЖЮЃЌВЂЬсЩ§ОЋЖШЁЃ
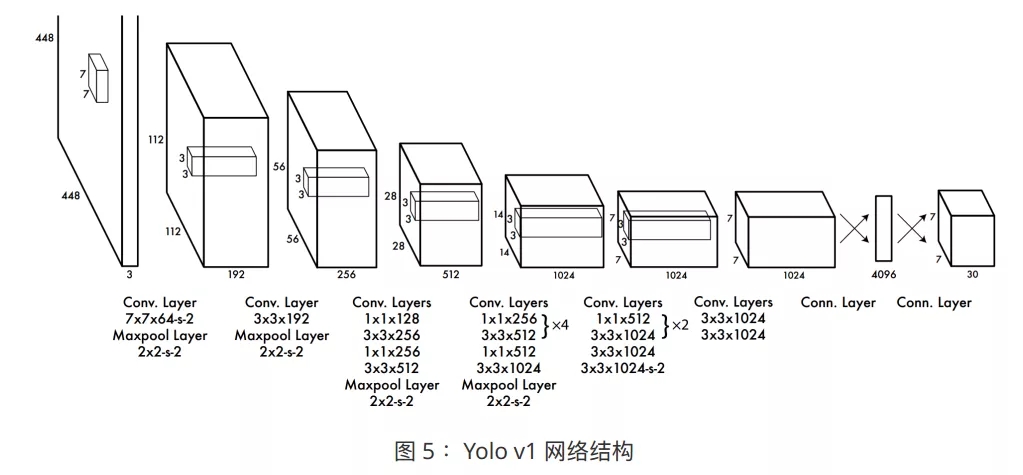
YOLO V1
жївЊЙБЯзКЭгХЪЦ
ЫфШЛ Fast R-CNN вбОЯрЕБгХауЃЌЕЋЪЧЦфШдОЩВЛЪЧеце§втвхЩЯЕФвЛЬхЪНФПБъМьВтЭјТчЃЌЦфадФмШдгаЬсЩ§ЕФПеМфЁЃ
еыЖд R-CNN ЯЕСаЕФЗжЖЮЪНЩшМЦЕФЮЪЬтЃЌYOLO ЬсГівЛжжШЋаТЕФ loss МЦЫуЗНЪНЃЌжиаТЖЈвхСЫФПБъМьВтЮЪЬтЃЌНЋЦфЖЈвхЮЊЛиЙщЮЪЬтНјаабЕСЗЃЌЭЌЪБНјааЖЈЮЛКЭЗжРрЕФбЇЯАЁЃ
YOLO ЕФКЫаФЃЌдкгкЦфЫ№ЪЇКЏЪ§ЕФЩшМЦЁЃЦфвЛЬхЪНМмЙЙЩшМЦЃЌМЦЫуСПИќЩйЃЌЫйЖШИќПьЃЌвзгкгХЛЏЃЌЧвТњзуЪЕЪБМьВтЕФашЧѓЁЃ
YOLO V1 ОпгавдЯТгХЪЦЃК
1.ЫйЖШМЋПьЃЌвзгкгХЛЏЃКжЛашЖСШЁвЛДЮЭМЯёЃЌОЭПЩНјааЖЫЖдЖЫгХЛЏЃЌПЩТњзуЪЕЪБашЧѓ
2.БГОАЮѓЪЖБ№ТЪЕЭЃКЖдШЋЭМНјааОэЛ§бЇЯАЃЌзлКЯПМТЧСЫШЋЭМЕФЩЯЯТЮФаХЯЂ
3.ЗКЛЏадФмКУЃКвВЪЧгЩгкзлКЯПМТЧСЫЭМЦЌШЋОжЃЌвђДЫФмЙЛИќКУЕибЇЯАЪ§ОнМЏЕФБОжЪБэДяЃЌЗКЛЏадФмИќКУ
4.ЪЖБ№ОЋЖШИп
ЕБШЛЃЌЯрНЯгк Faster R-CNN ЃЌYOLO v1 ДцдкУїЯдВЛзуЃК
1.ЖЈЮЛОЋЖШВЛЙЛЃЌгШЦфЪЧаЁФПБъ
2.ЖдУмМЏФПБъЕФЪЖБ№ДцдкВЛзу
3.вьГЃПэГЄБШЕФФПБъЪЖБ№ВЛМб
ЛљБОдРэ
ЩюЖШбЇЯАШЮЮёжаЃЌКЯРэЕФФПБъЩшЖЈЃЌЪЧГЩЙІЕФЙиМќвђЫижЎвЛЁЃ
Anchor box ЕФЩшМЦ
дк R-CNN ЯЕСажаЃЌашвЊЯШЬсШЁКђбЁЧјЃЌШЛКѓдйНЋКђбЁЧјНјааЛиЙщЮЂЕїЃЌЪЙжЎИќНгНќ groung truthЁЃЖј
YOLO жБНгНЋЦфКЯВЂЮЊвЛВНЃЌМДЃКЛиЙщЁЃЕЋЪЧЃЌYOLO БЃСєСЫКђбЁЧјЕФЫМЯыЃЌжЛЪЧНЋЦфбнБфЮЊСЫ anchor
boxЁЃ
дк YOLO V1 жаЃЌЪзЯШЩшЖЈ B ИіВЛЭЌГпДчЃЌПэГЄБШЕФ anchor boxЁЃШЛКѓНЋУПеХЭМЦЌЛЎЗжГЩSЁСSЕФИёЕуЃЌУПИіИёЕуЖдгІга
B Иі anchor boxЃЌЙВSЁСSЁСBИі anchor boxЃЌЦфДжТдЕФИВИЧСЫећеХЭМЦЌЁЃ
ЖдгкУПеХЭМЦЌЃЌОљДцдкГѕЪМЕФSЁСSЁСB Иі anchor boxЃЌзїЮЊГѕЪМ bounding boxЁЃЯждкашвЊзіЕФЪЧЃЌЭЈЙ§бЇЯАЃЌВЛЖЯХаЖЈФФаЉ
bounding box ФкДцдкФПБъЃЌДцдкЪВУДбљЕФФПБъЃЌЭЌЪБВЛЖЯЕїећПЩФмДцдкФПБъЕФ bounding
box ЕФПэГЄБШКЭГпДчЃЌЪЙжЎгы ground truth ИќНгНќЁЃ
ФЧУДЃЌground truth гжЪЧШчКЮЖЈвхЕФФиЃП
Ground truth ЕФЩњГЩ
ФПБъМьВтШЮЮёЃЌЪзЯШашвЊзіЕФЪЧХаЖЈЪЧЗёАќКЌФПБъЃЌШЛКѓВХЪЧХаЖЈФПБъЕФЮЛжУвдМАРрБ№ЁЃ
вдЯТЭМЮЊР§ЃЌЯъЯИНВНтДгвЛеХЭМЦЌЃЌЩњГЩ ground truth ЕФЙ§ГЬЁЃ

confidence score
ШчЩЯЭМЫљЪОЃЌЪзЯШвЊзіЕФЃЌОЭЪЧХаЖЈФФаЉ bounding box ФкАќКЌФПБъЁЃЮвУЧПЩвдЭЈЙ§вЛИіжУаХЖШЕУЗж
confidence scoreЃЌРДХаЖЈФГИі bounding box ФкЪЧЗёАќКЌФПБъЁЃ
ЖдгкЩЯЭМЃЌЮвУЧЩшЖЈФПБъжааФЫљдкЕФИёЕуЃЌАќКЌФПБъЁЃЯдШЛЃЌЖдгкЭМЦЌжаФПБъЕФ ground truthЃЌИУжЕЮЊ
1ЁЃ
зјБъжЕЛЛЫу
ЖдгкВЛАќКЌФПБъЕФ anchor boxЃЌВЛгУМЦЫуЦфзјБъЁЃЖдгкАќКЌФПБъЕФ anchor boxЃЌашвЊЛёШЁЦфзјБъЁЃ
дк yolo жаЃЌЭЈЙ§жааФЮЛжУКЭГпДчБэЪОзјБъЃЌМДЃК(x,y,w,h)
ЭМЦЌЕФ label гы groung truth жЎМфЃЌЭЈЙ§ШчЯТЗНЪНЛЛЫуЁЃ
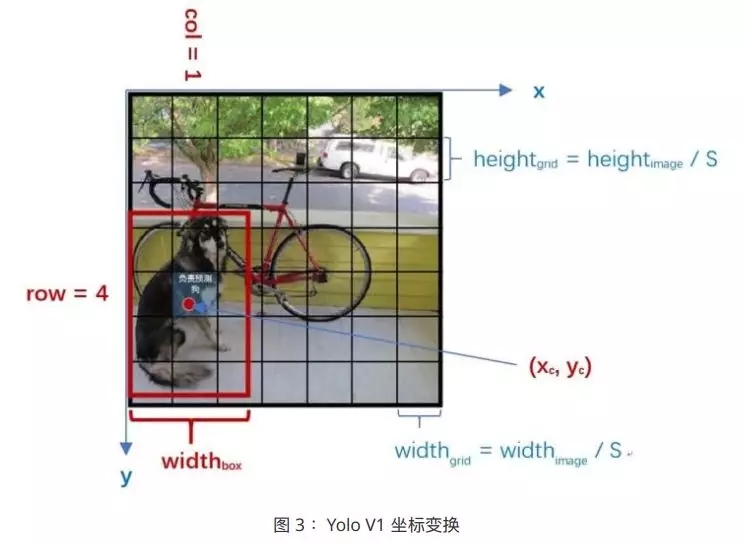
ШчЩЯЭМЫљЪОЃЌЙЗЙЗЕФдЪМзјБъЃЈlabelЃЉЮЊ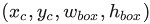 ЁЃЯждкашвЊНЋЦфБфЛЛЮЊ ground truthЁЃ ЁЃЯждкашвЊНЋЦфБфЛЛЮЊ ground truthЁЃ
x,yБэЪОФПБъжааФОрРыЖдгІИёЕуБпНчЃЈзѓЩЯНЧЃЉЕФЮЛжУЃЌЪ§жЕЯрЖдгкИёЕуЕЅдЊГпДчНјааЙ§ЙщвЛЛЏЁЃw,hЮЊФПБъБпПђЕФГпДчЃЌЯрЖдгкећЭМГпДчНјааЙ§ЙщвЛЛЏЁЃ
вђДЫЃЌЩЯЭМЙЗЙЗЕФзјБъЖдгІЕФ ground truth МЦЫуЗНЪНЮЊЃЈУПИіИёЕуГпДчЮЊ 1ЃЉЃК

РрБ№ИХТЪ
ФПБъЮЛжУЖЈвхЭъБЯКѓЃЌашвЊЖЈвхФПБъЕФРрБ№ЖдгІЕФ ground truthЁЃдк YOLO V1 жаЃЌДцдкШчЯТЩшЖЈЃК
УПИіИёЕузюЖржЛФмдЄВтвЛИіФПБъЃЌМДЪЙЪЧЙВга B Иі anchor boxЃЌвђДЫзюЖржЛФмАќКЌвЛИіРрБ№ЁЃ
етвЛЩшЖЈЃЌНЋЛсЕМжТЃЌЖдгкУмМЏЕФФПБъЃЌYOLO ЕФБэЯжНЯВюЁЃ
ЖдгкУПИіФПБъЃЈУПИіИёЕуФкжЛдЪаэДцдквЛИіЃЉЃЌЦфЖдгІЕФРрБ№ ground truth ЮЊ one-hot
БрТыЁЃ
гГЩфЕН bounding box
гЩгкУПеХЭМЦЌГѕЪМЖдгІSЁСSЁСBИі bounding boxЃЌвђДЫашвЊНЋЩЯУцЕФ ground truth
НјаагГЩфЃЌЪЙжЎгы bounding box ГпДчЖдгІвЛжТЃЌВХФмНјааБШНЯЃЌМЦЫуЮѓВюЃЌНјаагХЛЏЁЃВНжшШчЯТЃК
1.ГѕЪМЛЏУПИіИёЕуЩЯЕФ bounding box ЮЊ 0
2.ЖдгкДцдкФПБъЕФИёЕуЃЌНЋгк ground truth жЎМф IOU зюДѓЕФ bounding box
ЖдгІЕФ confidence score ЬюГфЮЊ 1ЃЌБэЪОАќКЌФПБъ
3.НЋАќКЌФПБъЕФ bounding box ЃЌЬюГфЖдгІЕФЕФ ground box ЕФзјБъКЭРрБ№жЕ
ЕНетРяЃЌОЭДг label ЃЌЕУЕНСЫгУгкБШНЯЕФ targetЁЃ
ЭЦРэЙ§ГЬ
ЭЦРэЙ§ГЬНЯЮЊМђЕЅЃЌЪфШыЭМЦЌЃЌЕУЕНвЛИіГпДчЮЊ SЁСSЕФЬиеїЭМЃЌЭЈЕРЪ§ЮЊBЁСЃЈ1+4ЃЉ+CЃЌЦфжаЃЌB
ЮЊУПИіИёЕуЕФ bounding box Ъ§ФПЃЌC ЮЊЕНдЄВтЕФФПБъРрБ№Ъ§ЃЌ1 КЭ 4 ЗжБ№БэЪОАќКЌФПБъЕФжУаХЖШКЭЖдгІЕФзјБъЁЃ
гЩгкУПИіИёЕужЛИКд№дЄВтвЛИіФПБъЃЌвђДЫжЛашвЊАќКЌвЛИіРрБ№ЯђСПМДПЩЁЃ
дкдТлЮФжаЃЌS=7ЃЌB=2ЃЌC=20ЃЌвђДЫзюКѓЪфГіГпДчЮЊ7ЁС7ЁС30 ЁЃ
МЦЫу loss
ЖдгкУПеХЭМЦЌЃЌДѓЖрЪ§ИёЕуЕЅдЊВЛАќКЌФПБъЃЌЦфЖдгІЕФжУаХЖШЕУЗжЮЊ 0ЁЃетжжФПБъДцдкгыЗёЕФЪЇКтЃЌНЋЛсгАЯьзюКѓ
loss ЕФМЦЫуЃЌДгЖјгАЯьАќКЌФПБъЕФИёЕуЕЅдЊЕФЬнЖШЃЌЕМжТФЃаЭВЛЮШЖЈЃЌбЕСЗШнвзЙ§дчЪеСВЁЃ
вђДЫЃЌЮвУЧдіМг bounding box зјБъЖдгІЕФ lossЃЌЭЌЪБЖдгкВЛАќКЌФПБъЕФ boxЃЌНЕЕЭЦфжУаХЖШЖдгІЕФ
lossЁЃЮвУЧгУ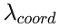 КЭ КЭ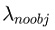
РДЪЕЯжетвЛЙІФмЃЌЧвЃК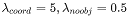 ЁЃ ЁЃ
ЭЌЪБЃЌsum-squared error ЛЙЛсЭЌЕШПДД§ large boxes КЭ small boxes
ЕФ loss ЁЃЖјЭЌЕШЕФ loss Ждгк large boxes КЭ small boxes ЕФгАЯьЪЧВЛЭЌЕФЁЃ
ЮЊСЫМѕЛКетжжПеМфЩЯЕФВЛОљКтЃЌЮвУЧбЁдёдЄВт w КЭ h ЕФЦНЗНИљЃЌПЩвдНЕЕЭетжжУєИаЖШЕФВювьЃЌЪЙЕУНЯДѓЕФЖдЯѓКЭНЯаЁЕФЖдЯѓдкГпДчЮѓВюЩЯгаЯрЫЦЕФШЈжиЁЃ
злЩЯЫљЪіЃЌЭъећЕФ loss МЦЫуЗНЪНШчЯТЫљЪОЃК
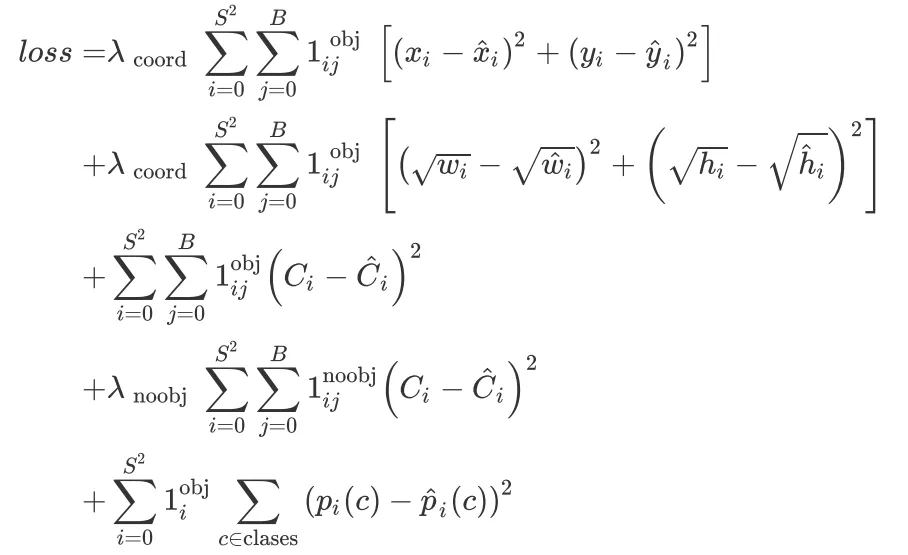
ЦфжаЃЈвд ground truth ЮЊХаЖЈвРОнЃЉЃК
 БэЪОЪЧЗёИёЕуЕЅдЊiжаАќКЌФПБъЃЛ БэЪОЪЧЗёИёЕуЕЅдЊiжаАќКЌФПБъЃЛ
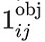 БэЪОИёЕуЕЅдЊiжаЃЌЕкjИідЄВтЕФ bounding box АќКЌФПБъ БэЪОИёЕуЕЅдЊiжаЃЌЕкjИідЄВтЕФ bounding box АќКЌФПБъ
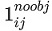 втЫМЪЧЭјИё i ЕФЕк j Иі bounding box жаВЛДцдкЖдЯѓ втЫМЪЧЭјИё i ЕФЕк j Иі bounding box жаВЛДцдкЖдЯѓ
вђДЫЃЌЩЯУцЕФ loss жаЃК
ЕквЛааБэЪОЃКЕБЕк i ИіИёЕужаЕк j Иі box жаДцдкФПБъ (IOU
БШНЯДѓЕФ bounding box) ЪБЃЌЦфзјБъЮѓВю
ЙЋЪОЕФЕкЖўааБэЪОЃКЕк i ИіИёЕужаЕк j Иі box жаДцдкФПБъЪБЃЌЦфГпДчЮѓВю
ЙЋЪОЕФЕкШ§ааБэЪОЃКЕк i ИіИёЕужаЕк j Иі box жаДцдкФПБъЪБЃЌЦфжУаХЖШЮѓВю
ЙЋЪОЕФЕкЫФааБэЪОЃКЕк i ИіИёЕужаЕк j Иі box жаВЛДцдкФПБъЪБЃЌЦфжУаХЖШЮѓВю
ЙЋЪОЕФЕкЮхааБэЪОЃКЕк i ИіИёЕужаДцдкФПБъЪБЃЌЦфРрБ№ХаЖЈЮѓВю
ЪЕгУЙ§ГЬ
дкЪЕМЪЪЙгУжаЃЌашвЊдЄВтЪЕМЪЕФБпПђКЭРрБ№ЁЃЭЈГЃЃЌПЩФмДцдкЖрИі bounding box дЄВтвЛИіФПБъЃЌДцдкШпгрЃЌашвЊЪЙгУЗЧМЋДѓвжжЦЃЈMNSЃЉРДЬоГ§Шпгр
bounding boxЁЃЦфКЫаФЫМЯыЪЧЃКбЁдёжУаХЖШЕУЗжзюИпЕФзїЮЊЪфГіЃЌШЅЕєгыИУЪфГіжиЕўНЯИпЕФдЄВтПђЃЌВЛЖЯжиИДетвЛЙ§ГЬжБЕНДІРэЭъЫљгаБИбЁПђЃЈЙВ
SЁСSЁСBИіЃЉЁЃ
ОпЬхВНжшШчЯТЫљЪОЃК
1. Й§ТЫЕє confidence score ЕЭгкуажЕЕФ bounding box
2. БщРњУПвЛИіРрБ№
1. евЕНжУаХЖШзюИпЕФ bounding boxЃЌНЋЦфвЦЖЏЕНЪфГіСаБэ
2. ЖдУПИі Score ВЛЮЊ 0 ЕФКђбЁЖдЯѓЃЌМЦЫуЦфгыЩЯУцЪфГіЖдЯѓЕФ bounding box
ЕФ IOU
3. ИљОндЄЯШЩшжУЕФ IOU уажЕЃЌЫљгаИпгкИУуажЕЃЈжиЕўЖШНЯИпЃЉЕФКђбЁЖдЯѓХХГ§Еє
4. ЕБЪЃгрСаБэЮЊ Null ЪБЃЌ дђБэЪОИУРрБ№ЩОбЁЭъБЯЃЌМЬајЯТвЛИіРрБ№ЕФ NMS
3. ЪфГіСаБэМДЮЊдЄВтЕФЖдЯѓ
ЭјТчНсЙЙ
Yolo V2
жївЊЙБЯз
Yolo V2 ЕФжївЊЙБЯздкгкЃК
1. РћгУ wordTree ЩшМЦЃЌГфЗжРћгУЗжРрЪ§ОнМЏЃЌУжВЙФПБъЪЖБ№РрБ№Ъ§ФПЕФВЛзу
2. жиаТЩшМЦЛљДЁЭјТч darknet-19ЃЌЪфШыГпДчПЩБфЃЌДгЖјдкЭЌвЛЬзФЃаЭЩЯЃЌЬсЙЉЫйЖШКЭОЋЖШжЎМфЕФЧаЛЛ
3. жиаТЩшМЦ anchor box КЭзјБъБфЛЛИёЪНЃЌЪЙЕФЪнСГИќПьЃЌОЋЖШИќИп
ЙиМќИФНј
етЦЊТлЮФНјааСЫНЯЖрЕФИФНјгХЛЏЃЌжївЊЗжЮЊаТЩшМЦЕФЛљДЁЭјТч darknet-19ЃЌвдМАаТЩшМЦ anchor
box ЕШЁЃжСгкЦфЫћИФНјЃЌЯъМћТлЮФЁЃ
жиаТЖЈвх Anchor box
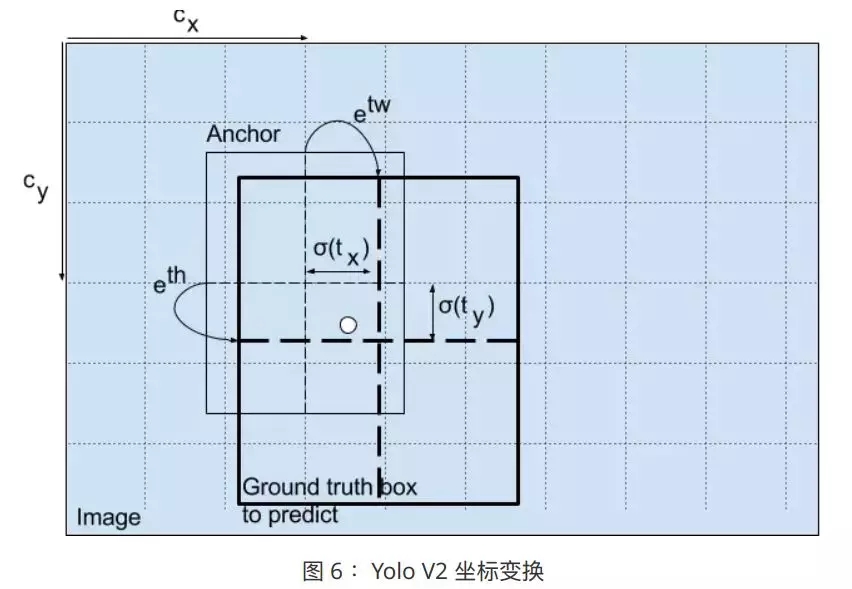
дк Yolo V2 жаЃЌЪфШыГпДчБфЮЊ416ЁС416ЃЌЭјТчећЬхЫѕЗХБЖЪ§ЮЊ 13ЃЌзюКѓЕУЕНГпДчЮЊ13ЁС13ЕФЬиеїЭМЃЌВЂдкИФГпДчЩЯНјааЭЦРэдЄВтЁЃ
ДЫЭтЃЌНЯЮЊживЊЕФЪЧЃЌv2 жаЃЌУПИі bounding box ИКд№дЄВтвЛИіФПБъЃЌвђДЫвЛИіИёЕуФкПЩвддЄВтЖрИіФПБъЃЌНтОіСЫУмМЏФПБъЕФдЄВтЮЪЬтЁЃ
ДЫЭтЃЌВЛдйЭЈЙ§ЪжЙЄбЁдё anchor boxЃЌЖјЪЧеыЖдЬиЖЈЪ§ОнМЏЃЌЭЈЙ§ k-means ЫуЗЈНјаабЁдёЃЌЯъМћТлЮФЁЃ
зјБъБфЛЛЗНЪН
дк yolo v1 жаЃЌЪЙгУШЋСЌНгВуРДжБНгдЄВтФПБъЕФ bounding box ЕФзјБъЁЃбЕСЗЙ§ГЬВЛЙЛЮШЖЈЃЌжївЊРДздЃЈx,yЃЉЕФдЄВтЁЃ
Жјдк Faster R-CNN жаЃЌЪЙгУШЋОэЛ§ЭјТч RPN РДдЄВт bounding box ЯрЖдгк
anchor box ЕФзјБъЕФЦЋвЦСПЁЃгЩгкдЄВтЭјТчЪЧОэЛ§ЭјТчЃЌвђДЫ PRN дк feature map
ЭјТчЕФУПИіЮЛжУдЄВтетаЉ offsetЁЃ
ЯрБШгкжБНгдЄВтзјБъЃЌдЄВт offset ИќМђЕЅЃЌЮѓВюИќаЁЃЌПЩвдМђЛЏЮЪЬтЃЌЪЙЕУЭјТчИќШнвзбЇЯАЁЃ
дЪМЗНАИжаЃЌдЄВтжЕ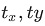 КЭ(x,y)жЎМфЃЌМЦЫуЗНЪНШчЯТЃК КЭ(x,y)жЎМфЃЌМЦЫуЗНЪНШчЯТЃК
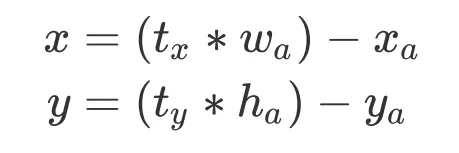
ИУЗНЪНЯТЃЌЖдзјБъУЛгаЯожЦЃЌвђДЫдЄВтЕФ bounding box ПЩФмГіЯждкШЮвтЮЛжУЃЌЕМжТбЕСЗВЛЮШЖЈЁЃвђДЫЃЌдк
V2 ФкИФЮЊдЄВтЦЋвЦСПЃЌЦфМЦЫуЗНЪНШчЯТЫљЪО:
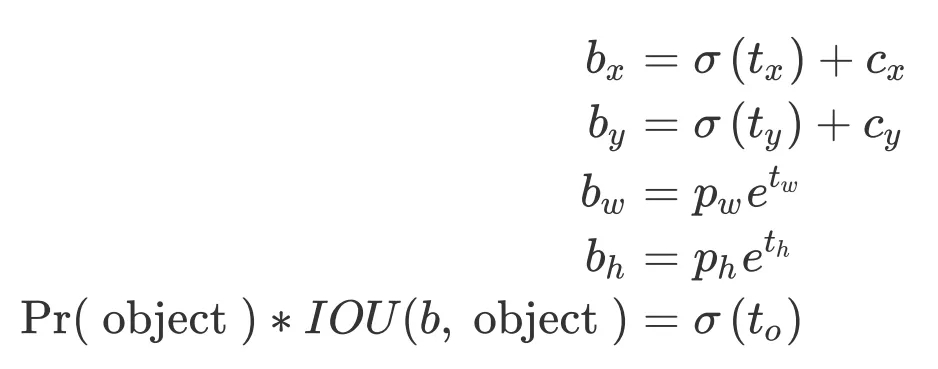
ЦфжаЃЌ БэЪОИёЕуЕЅдЊЯрЖдгкЭМЯёзѓЩЯНЧЕФзјБъЃЛ БэЪОИёЕуЕЅдЊЯрЖдгкЭМЯёзѓЩЯНЧЕФзјБъЃЛ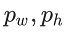 БэЪОЯШбщПђЕФГпДч (bounding box prior)ЃЌдЄВтжЕЮЊ БэЪОЯШбщПђЕФГпДч (bounding box prior)ЃЌдЄВтжЕЮЊ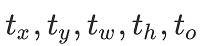 ЁЃ ЁЃ
ЖдгкдЄВтЕФ bbox ЕФжааФЃЌашвЊбЙЫѕЕН 0-1 жЎМфЃЌдйМгЩЯ anchor
ЯрЖдгкgrid дк x КЭ y ЗНЯђЩЯЕФЦЋвЦЁЃетвЛЕуЃЌКЭ yolo v1 ЪЧвЛжТЕФ
ЖдгкдЄВтЕФ bbox ЕФПэИпЃЌетИіКЭ faster RCNN вЛбљЃЌЪЧЯрЖдгк
anchor ПэИпЕФвЛИіЗХЫѕЁЃexp(w) КЭ exp(h) ЗжБ№ЖдгІСЫПэИпЕФЗХЫѕвђзг
ЖдгкдЄВтЕФ bbox ЕФжУаХЖШЃЌдђашвЊгУ sigmoid бЙЫѕЕН
0-1 жЎМфЁЃетИіКмКЯРэЃЌвђЮЊжУаХЖШОЭЪЧвЊ0-1жЎМфЁЃ
ЖдгкдЄВтЕФУПИіРрБ№ЃЌвВЪЧгУФу sigmoid бЙЫѕЕН0-1жЎМфЁЃетЪЧвђЮЊРрБ№ИХТЪЪЧдк0-1жЎМф
зюКѓЭЈЙ§ЛЛЫуЕУЕНЕФЮЊдкЕБЧАЬиеїЭМГпДчЩЯЕФзјБъКЭГпДчЃЌашвЊГЫвдећЬхЫѕЗХвђзг(32)ЃЌЗНПЩЕУЕНдкдЭМжаЕФзјБъКЭГпДчЁЃ
етжжВЮЪ§ЛЏЕФЗНЪНЃЌЪЙЕУЩёОЭјТчИќМгЮШЖЈЁЃ
ЖрГпЖШШкКЯ
13ЁС13ЕФЪфГіЬиеїЭМЃЌПЩвдКмКУЕФдЄВтНЯДѓГпДчЕФФПБъЃЌЕЋЪЧЖдгкаЁГпДчЕФФПБъЃЌПЩФмВЂВЛЬЋКУЁЃ
вђДЫЃЌдк YOLO v2 жаЃЌГ§СЫЪЙгУ13ЁС13ЕФЬиеїЭМЃЌЛЙЪЙгУЦфжЎЧАВуГпДчЮЊ26ЁС26КЭ52ЁС52ЕФЬиеїЭМЃЌВЂНјааЖрГпЖШШкКЯЁЃВЛЭЌГпДчжЎМфЃЌЭЈЙ§ШчЯТаЮЪНЃЌНјааЬиеїШкКЯЁЃ
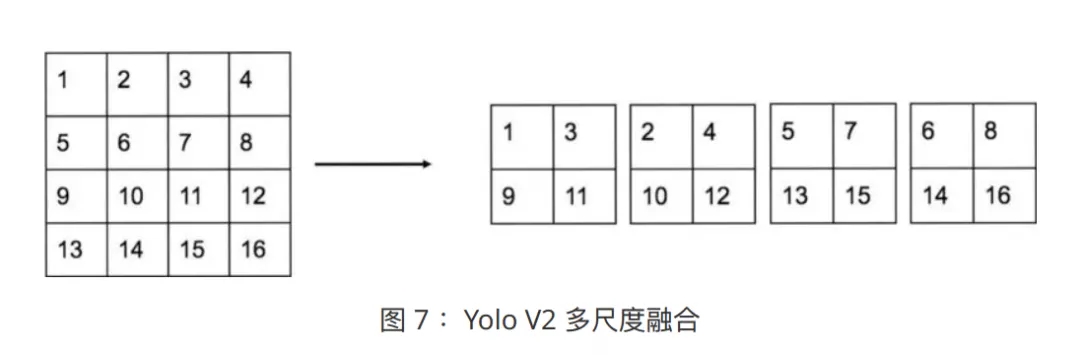
Р§ШчЃЌ26ЁС26ЁС256ЭЈЙ§етжжЗНЪНЃЌНЋБфЮЊ13ЁС13ЁС1024ЕФ tensorЁЃ
ОпЬхШкКЯаЮЪНЃЌЯъМћЭМ 9ЁЃ
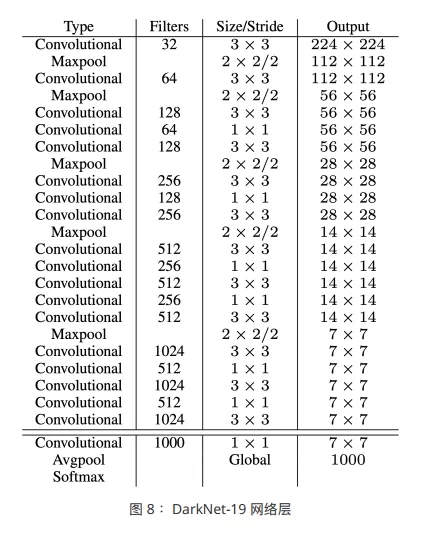
Darknet-19
ДѓЖрЪ§ detection ЯЕЭГвд VGG-16 зїЮЊЛљДЁЕФЬиеїЬсШЁЦї (base feature
extractor)ЁЃЕЋЪЧ vgg-16 НЯЮЊИДдгЃЌМЦЫуСПНЯДѓЁЃ
Yolo V2 ЪЙгУвЛИіЖЈжЦЕФЩёОЭјТчзїЮЊЬиеїЬсШЁЭјТчЃЌЫќЛљгк Googlenet МмЙЙЃЌдЫЫуСПИќаЁЃЌЫйЖШИќПьЃЌШЛЖјЦфОЋЖШЯрНЯгк
VGG-16 ТдЮЂЯТНЕЃЌГЦжЎЮЊ darknet-19ЁЃ
гы VGG ФЃаЭРрЫЦЃЌДѓЖрЪ§ЪЙгУ3ЁС3ЕФОэЛ§ВуЃЌВЂдкУПвЛДЮ pooling КѓЃЌЭЈЕРЪ§МгБЖЁЃДЫЭтЃЌЪЙгУШЋОжГиЛЏ
( GAPЃЌglobal average pooling ) РДНјаадЄВтЁЃЭЌЪБЃЌдк3ЁС3ЕФОэЛ§ВужЎМфЃЌЪЙгУ1ЁС1ЕФОэЛ§ВуРДбЙЫѕЬиеїБэДяЁЃДЫЭтЃЌЪЙгУ
batch normalization РДЮШЖЈбЕСЗЃЌМгЫйЪеСВвдМАе§дђЛЏФЃаЭЁЃ
ЭъећЕФЭјТчВуШчЯТЫљЪОЃК
Yolo V3
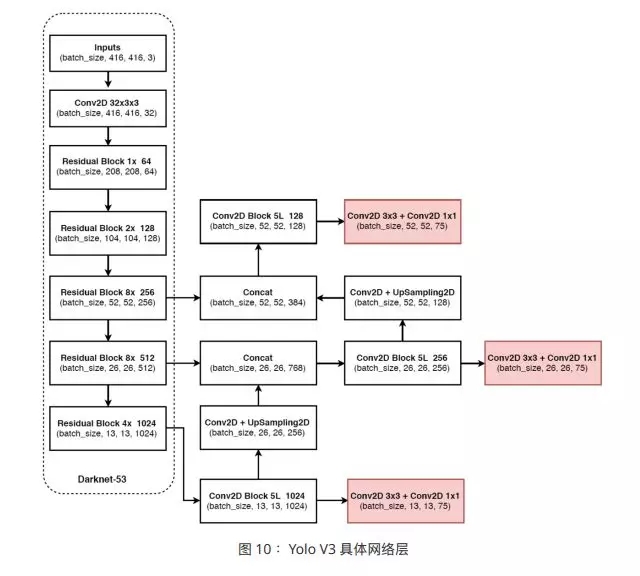
Yolo V3 жЛЪЧЖд Yolo v2 НјааСЫвЛДЮНЯаЁЕФгХЛЏЃЌжївЊЬхЯждкЭјТчНсЙЙЩЯЃЌЬсГіСЫ darknet-53
НсЙЙЃЌзїЮЊЬиеїЬсШЁЭјТчЁЃзюКѓЃЌYolo V3 дкаЁФПБъЕФЪЖБ№ЩЯИФЩЦНЯДѓЃЌЕЋЪЧжаЕШФПБъКЭДѓФПБъЕФЪЖБ№ЗНУцЃЌБэЯжТдЮЂЯТНЕЁЃ
ЭјТчНсЙЙШчЯТЫљЪОЃК

зюКѓИНЩЯвЛеХадФмБэЯжЭМЃК
|









