| БрМЭЦМі: |
БОЮФРДздcsdnЃЌБОЮФжївЊНщЩмСЫФПБъМьВтЫуЗЈКЭЮяЬхЙиМќЕуМьВтЕФгІгУГЁОАвдМАЮЛжУМьВтЕФЫуЗЈЬиЕуЁЃ |
|
ФПБъМьВтЫуЗЈ
ФПБъМьВтИХФю
ФПБъМьВтетРяВћЪіСНИігІгУГЁОАЃЌ1 ЮЊЮяЬхЮЛжУМьВтЃЌ2 ЮЊЮяЬхЙиМќЕуМьВтЁЃ
1 ЮяЬхЮЛжУМьВт
ЯрБШгыЭМЦЌЗжРрЃЌФПБъМьВтЫуЗЈНсЙћвЊЧѓВЛНіЪЖБ№ГіЭМЦЌжаЕФЮяРэРрБ№ВЂЧвЪфГіЮяЬхЕФЮЛжУВЮЪ§ЁЃ
ЮяЬхЕФЮЛжУЭЈЙ§bounding boxБэЪОЁЃbounding boxжИЕФЪЧФмЙЛПђГіЮяЬхЕФОиаЮПђдкЭМЦЌжаЕФЖдгІВЮЪ§ЃЌШчЯТЭМЫљЪОЁЃ

ЭМжаКьЩЋПђЃЌОЭГЦЮЊвЛИіbounding boxЃЌbounding
boxгЩИіВЮЪ§РДУшЪі[bx,by,bh,bw] [b_x, b_y, b_h, b_w][b x
,b y ,b h ,b w ]ЃЌ Цфжа(bx,by b_x, b_yb x ,b y )ЖдгІОиаЮПђЕФжааФЕузјБъЃЌbh
b_hb h дђЖдгІОиаЮПђЕФИпЖШЃЌbw b_wb w дђЖдвЛИіОиаЮПђЕФПэЖШЁЃШчЯТЭМЫљЪОЁЃ
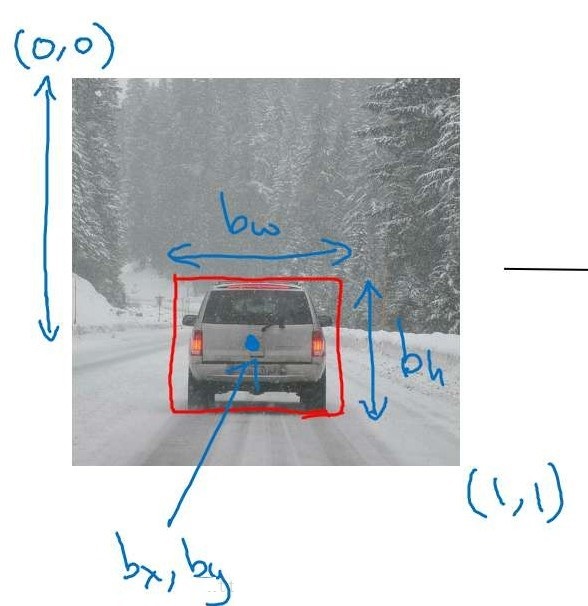
ДгЖј bx=0.5,by=0.7,bh=0.3,bw=0.4 b_x=0.5, b_y=0.7, b_h=0.3,
b_w=0.4b
НЋЭМЦЌзїЮЊФЃаЭЕФЪфШыЃЌ ЪфГіЮЊЮяЬхЕФРрБ№КЭbounding boxВЮЪ§ЁЃШчЯТЭМЫљЪОЁЃ
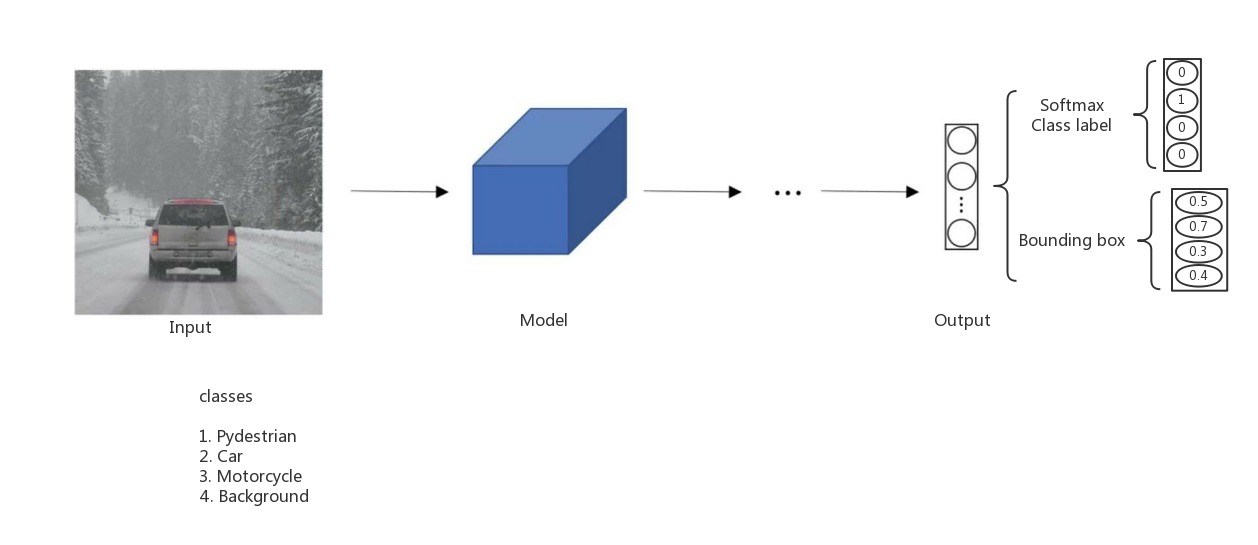
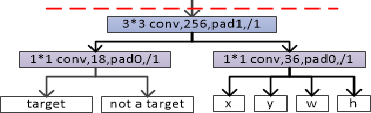
етРяЮвУЧМйЩшЕФЪЧвЛИіЭМЦЌжажИЖЈЮЊвЛИіЮяЬхЕФРрБ№МАЮЛжУЁЃ
ЮтЖїДяРЯЪІЕФПЮГЬжаетбљЖЈвхФЃаЭЪфГіy=[pc,bx,by,bh,bw,c1,c2,c3]T \hat{y}=[p_c,
b_x, b_y, b_h, b_w, c_1, c_2, c_3]^T
y=[pc,bx,by,bh,bw,c1,c2,c3]T \hat{y}=[p_c, b_x, b_y,
b_h, b_w, c_1, c_2, c_3]^T
ЦфжаЃЌpc p_cp ЮЊЭМжагаЮяЬхЕФИХТЪ;
[bx,by,bh,bw] [b_x, b_y, b_h, b_w][b
]дђЪЧЖдгІЮяЬхЕФЮЛжУ(bounding box)ВЮЪ§;
c1,c2,c3 c_1, c_2, c_3c дђЪЧЖдгІФФИіЮяЬхЕФclassЁЃЩйвЛИіc4
c_4c ЪЧвђЮЊc1,c2,c3 c_1, c_2, c_3c ОљЮЊ0ЪБЃЌдђc4=1 c_4=1c
2 ЮяЬхЙиМќЕуМьВт(landmark detection)
ЮяЬхЙиМќЕуМьВтЕФгІгУГЁОАгаЃЌШЫСГЙиМќЕу(блОІЁЂБЧзгЁЂзьМАСГЕФБпдЕЕу)ЕФМьВтЃЌШЫЬхзЫЬЌМьВт(ЭЗЃЌ ИьВВМАЭШЕФИїИіЙиМќЕуЕФМьВт)ЃЌЛЙгаБШШчЬьГиЕФвТЗўЙиМќЕуМьВтЕШЖМЪЧЪєгкетИіЗЖГыЕФгІгУГЁОАЁЃ
ЪфШыЮЊЭМЦЌЃЌЪфГідђЪЧетвЛЯЕСаЙиМќЕуЕФзјБъЮЛжУ[[l1x,l1y],[l2x,l2y],...,[lnx,lny]]
[[l_{1x},l_{1y}], [l_{2x},l_{2y}], ... , [l_{nx},l_{ny}]][[l
МДlandmarkЁЃ


ЮяЬхЮЛжУМьВтЫуЗЈ
БОЮФжЛЪЧДѓжТНщЩмЮЛжУМьВтЕФЫуЗЈЬиЕуЁЃ
ЦфЪЕRCNN, Fast-rcnn, SPP-net, Faster-rcnnЖМПЩвдЗжЮЊСНИіжївЊВПЗжЃК1.
region proposal ЬсШЁregionsЃЛЖјYOLOМАSSDдђЭЈЙ§ЗжИёМАanchorЕФЗНЗЈРДДњЬцДѓХњСПЕФregionsЃЌЯрБШYOLOМАSSDМЦЫуСПаЁЃЌДгЖјПьвЛаЉЁЃ
НгЯТРДСаГіУПИіЭјТчЕФжївЊЬиЕуЁЃ
RCNNНщЩм
ЯрЙиИХФюНщЩмЃК
regionsОЭЪЧДгдЭМЯёЩЯНиШЁЕФгаПЩФмАќКЌЮяЬхЕФЭМЯёЧјгђМЏКЯЁЃ
bounding boxЪЧжИАќКЌЮяЬхЕФОиаЮПђЁЃЮФжаЧАУцгаНщЩмЁЃ
IOU(Intersection over Union)гУРДКтСПСНИіregionsжЎМфЕФжиЕўЖШЁЃЩЯЭМЁЃ
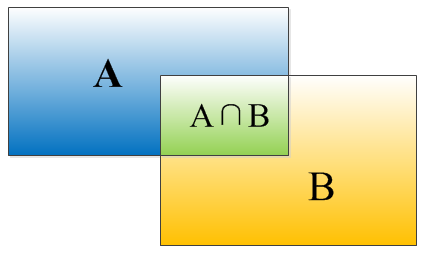
ОиаЮПђAЁЂBЕФвЛИіжиКЯЖШIOUМЦЫуЙЋЪНЮЊЃК
IOU=(AЁЩB)/(AЁШB)
ОЭЪЧОиаЮПђAЁЂBЕФжиЕўУцЛ§еМAЁЂBВЂМЏЕФУцЛ§БШР§:
IOU=SI/(SA+SB-SI)
NMS(МЋДѓжЕвжжЦ)ЪЧЬєГіВЛЭЌРржаЕФзюДѓжЕЃЌЩсЦњЯрНќЕФЕЋЪЧВЛЪЧМЋДѓЕФжЕЁЃ
дкФПБъЪЖБ№жаЃЌгУгкзюКѓЕФbounding boxЩИбЁЁЃОЙ§SVMХаБ№ЕФbounding boxesЃЌАќКЌСЫЫљгаРрБ№ЕФbounding
boxesЃЌЭЈЙ§NMSЪЕЯжЃЌзюКѓСєЯТВЛЭЌРрЕФзюгХЕФbounding boxЁЃЯъЯИЕФЪЕЯждРэВЮПМВЉПЭ
RCNNНсЙЙжївЊВНжшЃК
ЭМЯёЖдгІЕФКђбЁЧјгђ(1K~2KИі)ЩњГЩЃЛ
КђбЁЧјгђЕФЬиеїЬсШЁЃЛ
ЬиеїЗжРр(SVM)ЃЛСєЯТАќКЌЮяЬхЕФregionsЃЌДгЖјзїЮЊbounding boxesЁЃ
bounding boxЩИбЁЃЌВЂаое§ЁЃ
ИїЛЗНкЪЙгУММЪѕЃК
КђбЁЧјгђЩњГЩ
ЪЙгУSelective SearchЩњГЩЭМЯёЕФКђбЁЧјгђЁЃ
ДѓЬхдРэЃК
ЪЧвЛжжЭМЯёЗжИёЕФЪжЖЮЃЌЭЈЙ§КЯВЂЯрЫЦбеЩЋЛђЮФРэЧвЯрСкЕФЧјгђЃЌЪЕЯжЭМЯёЗжИюЃЌНЋзюКѓЕФЧјгђШЅжиЪфГіЁЃSelective
SearchдДТыЕижЗЁЃ
ЬиеїЬсШЁ
ЪЙгУбЕСЗКУЕФЩёОЭјТчЬсШЁregionsЬиеїЁЃ
RCNNбЕСЗЬиеїжївЊОЙ§2ИіНзЖЮЃК
Pre-trainЃК
ЪЙгУILVCR 2012Ъ§ОнМЏМАМђЛЏАцЕФHinton 2012ФъдкImage NetЩЯЕФЗжРрЭјТчРДНјаадЄбЕСЗЁЃ(ШЋСЌНгВуЬсШЁЬиеї4096ЮЌЃЌдйЪЙгУШЋСЌНг(4096->1000)ЪЕЯж1000РрЗжРр)ЁЃ
Fine-tune:
ЬцЛЛPre-trainЕФзюКѓЪфГіВуЃЌЛЛЮЊ(4096->21)21ЗжРрЕФЪфГіВуЃЌЪЙгУЪ§ОнМЏPASCAL
VOC 2007РДбЕСЗЭјТчЁЃДЫДІбЕСЗЕФе§ИКбљБОЕФБъЖЈЃКIOU>0.5дђЮЊе§бљБОЁЃ
ЬиеїЗжРр
ЪЙгУвЛЯЕСаSVMРДЗжРрОЙ§ЭјТчЬсШЁЕНЕФЬиеїЃЌSVMИіЪ§ЕШгквЊБъГіЕФЮяжжЪ§ЁЃВЂЧвЪЙгУСЫhard negative
miningЁЃ
SVMбЕСЗЪБЃЌе§ИКбљБОБъЖЈЃКIOU>0.3дђЮЊе§бљБОЁЃ
дкВтЪдЪБЃЌSVMЪфГіЮЊе§ЕФregionsзїЮЊД§ЩИбЁЕФbounding boxesЁЃ
bounding boxЩИбЁ
ЪЙгУМЋДѓжЕвжжЦ(NMS)ЁЃЩИбЁЕУЕНУПвЛРрЖдгІЕФзюгХЕФbounding boxЁЃ
зюКѓЭЈЙ§bounding boxЛиЙщОЋЯИгХЛЏbounding boxЁЃ
bounding boxЛиЙщОЭЪЧЭЈЙ§ЩёОЭјТчФтКЯЦНвЦКЭЗХЫѕСНИіКЏЪ§ЃЌЪЙгУетСНИіКЏЪ§ЪЙИќМгФтКЯецЪЕЕФЮЛжУЧјгђЁЃlossОЭЪЧдЪМboxгыФПБъboxжЎМфЕФОрРыЁЃ
RCNNЭјТчЕФШБЕу
бЕСЗашвЊМИИіНзЖЮЃЛ
SSЕУЕНЕФregionsЪЧВЛЭЌГпДчЕФЁЃВЛЭЌГпДчЕФregionsашвЊОЙ§ЃЌВУМєМАЗХЫѕЕНЯрЭЌЕФГпДчЃЌетбљЛсЪЙвЛаЉФкШнЖЊЪЇЁЃ
УПИіregionЕФЖМашвЊОЙ§ФЃаЭШЅЬсШЁЃЌВЂДцЗХжСДХХЬЃЛ
SPP-netНщЩм
SPP-net(Spatial Pyramid Pooling) ЬсГіжївЊНсЙЙЃК
ЬсГіН№зжЫўНсЙЙЃЌЪЙФЃаЭПЩвдДІРэВЛЭЌГпДчЕФЪфШыЁЃ
ЪЙгУregionsЕНЬиеїВужЎМфЕФгГЩфЃЌДгЖјЪЕЯжжЛЬсШЁвЛДЮЭъГЩЕФЭМЯёЃЌregionsЬиеїЭЈЙ§гГЩфЙиЯЕРДЛёШЁЁЃ
SPP-netЕФШБЕуЃК
Н№зжЫўНсЙЙЫфШЛЪЙЕУФЃаЭДІРэВЛЭЌГпДчЪфШыЕФЮЪЬтЃЌЕЋЭЌЪБЪЙФЃаЭВЛЭЌЭЌЪБбЕСЗН№зжЫўзѓВрЕФОэЛ§ВуЁЃжСгкдвђЃЌзїепИјГіЕФдвђЪЧН№зжЫўЕФpoolingВуЖдгІЕФИаЪмвАЬЋДѓЁЃБОШЫОѕЕУИаЪмвАЬЋДѓЃЌЛсЪЙЬнЖШДЋЕнВЛЮШЖЈЁЃ
ЯъЯИНсЙЙВЛзїНщЩмЁЃ
бЕСЗвРОЩашвЊМИИіНзЖЮЁЃвРОЩВЩгУSVMЪЕЯжЗжРрЁЃ
SPP-netжаММЪѕЕуНВНт
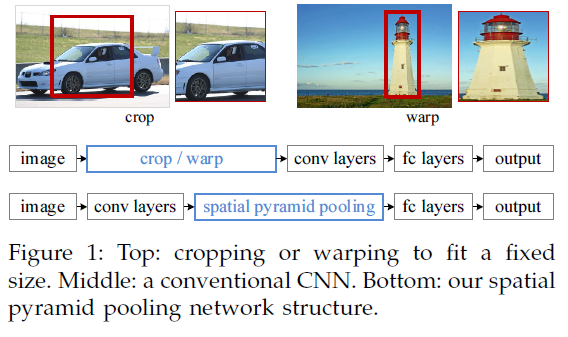
1. Н№зжЫўНВНт
ЪЕМЪдРэОЭЪЧЃЌЖдУПЭЈЕРЕФЬиеїНјааЗжПщЃЌЗжГЩ16*16, 4*4, 1*1ПщЃЌЬєГіУППщЕФзюДѓжЕЃЌЕУЕН16*16,
4*4, 1*1ЬиеїЃЌеЙПЊГЩ16*16 + 4*4 + 1*1ЮЊЯђСПЃЌЪфИјШЋСЌНгВуЁЃ
2. regionsЕНЬиеїВужЎМфЪЧШчКЮгГЩф
ЭМжаЪфШыВуРЖЩЋМгЩюВПЗжЖдгІУПвЛВуЕФЧјгђЃЌвЛИіЧјгђЖдгІОЙ§ОэЛ§/poolingКѓЕФЖдгІЧјгђГпДчМЦЫуЗНЗЈЃЌгыдЭМЬиеїОЙ§ОэЛ§/poolingКѓЕФЖдгІГпДчЯрЭЌЁЃзЂЃКНіНіЪЧНшгУетИіЭМБэЪОвЛЯТregionsЪфШыгыЦфЫћВужЎМфЕФЖдгІЙиЯЕЁЃИУЭМЪЧдвтжМдкЫЕРћгУ1x1ОэЛ§КЫЪЕЯжШЋОэЛ§ЁЃ
Fast-RCNNНщЩмЃК
Fast-RCNNгХЛЏММЪѕЕу
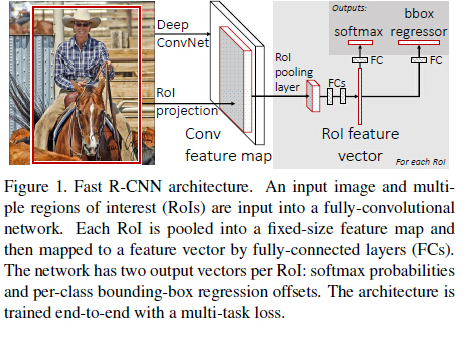
ЬсГіROI pooling layerЃЌВЩгУЕЅВуН№зжЫўНсЙЙЃЌЦфЪЕОЭЪЧдкЬиеїВужЛЪЙгУвЛИіН№зжЫўmax-poolingЃЌНјвЛВНМђЛЏСЫregionsЖдгІЬиеїВуЕФгГЩфЙиЯЕЁЃ
ЬсГіЬнЖШДЋЕнЗНЗЈЃЌЪЕЯжећИіЭјТчЭјТчНсЙЙЕФШЋВПбЕСЗЁЃ
дкСНВуШЋСЌНгжаМгШыSVDНЕЮЌЃЌМгПьбЕСЗЫйЖШЁЃ
ЪфГіЪЙгУСНИіsoftmaxЃЌвЛИігУгкclassЗжРрЃЌвЛИігУгкbounding boxЛиЙщЁЃ
Fast-RCNNгХЛЏММЪѕЕуНВНт
ROI pooling layerНВНтЃК
POI pooling layer ВуЪЧЮЛгкОэЛ§КѓЃЌШЋСЌНгжЎЧАЕФlayerЁЃ
ЪфШыЮЊОэЛ§ВуЪфГі(H*W*N)МАRИіROIдЊзщЃЌRБэЪОregionsЕФИіЪ§ЁЃУПИіROIЪЧвЛИідЊзщ(n,
r, c, h, w)ЃЌnЪЧЬиеїгГЩфЕФЫїв§ЃЌnЁЪ{0, Ё ,N-1}ЃЌ(r, c)ЪЧRoIзѓЩЯНЧЕФзјБъЃЌ(h,
w)ЪЧИпгыПэЁЃ
ЪфГіЪЧmax-poolЙ§ЕФЬиеїгГЩфЃЌHЁЏ x WЁЏ x CЕФДѓаЁЃЌHЁЏЁмHЃЌWЁЏЁмWЁЃН№зжЫўЕФЕФЧаИюВЮЪ§ЃКbin-size
~ h/HЁЏ x w/WЁЏЃЌетбљОЭгаHЁЏ x WЁЏИіЃЌbinЕФДѓаЁЪЧздЪЪгІЕФЃЌШЁОігкRoIЕФДѓаЁЁЃ
Faster-RCNNНщЩмЃК
Faster-RCNNгХЛЏММЪѕЕу
ЬсГіRPN(Region Proposal Networks)ЧјгђЩњГЩЭјТчЃЌЪЙгУЩёОЭјТчЩњГЩregionsЃЌДњЬцRCNNжаЕФSelective
SearchЗНЗЈЁЃНкЪЁregions proposalЕФЪБМфЁЃЛљБОЪЕЯжend to endбЕСЗЁЃ
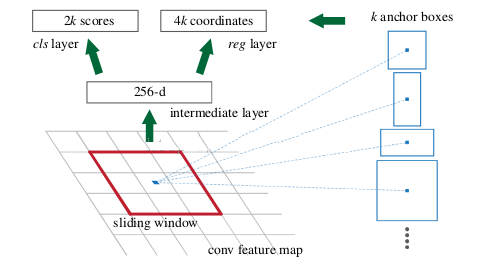
RPNДѓжТдРэНщЩмЃК
дкзюКѓЕФОэЛ§Ву(МДЬиеїЬсШЁВу)ЩЯЪЙгУЛЌЖЏДАПкРДдЄВтЁЃЪЙгУ3x3ЕФОэЛ§КЫЖдЕУЕНЕФ256ЮЌЕФЬиеїЭМНјааЛЌЖЏОэЛ§ЃЌЗжСНТЗЗжБ№ЪЙгУРћгУ1*1/ОэЛ§ЃЌзюКѓвЛТЗЪфГіЫљгаanchorsЕФФПБъКЭЗЧФПБъ(БГОА)ЕФИХТЪЃЌСэвЛТЗЪфГіanchors
boxЯрЙиЕФЫФИіВЮЪ§ЃЌАќРЈboxЕФжааФзјБъxКЭyЃЌboxПэwКЭГЄhЁЃУПДЮЛЌЖЏОэЛ§ЃЌЪфГіkИіanchorsЕФЪЧЗёАќКЌЮяЬхвдМАЮЛжУаХЯЂЁЃвђДЫзюКѓЕФRPNЕФЪфГіЪЧвЛТЗЮЊ2kЖдгІЗжРр(ЪЧЗёАќКЌЮяЬх)ЃЌСэвЛТЗЮЊ4kЖдгІanchorsЕФЮЛжУаХЯЂЁЃ
зїепВЩгУЫФВНбЕСЗЗЈЃК
1ЃЉ ЕЅЖРбЕСЗRPNЭјТчЃЌЭјТчВЮЪ§гЩдЄбЕСЗФЃаЭдиШыЃЛ
2ЃЉ ЕЅЖРбЕСЗFast-RCNNЭјТчЃЌНЋЕквЛВНRPNЕФЪфГіКђбЁЧјгђзїЮЊМьВтЭјТчЕФЪфШыЁЃОпЬхЖјбдЃЌRPNЪфГівЛИіКђбЁПђЃЌЭЈЙ§КђбЁПђНиШЁдЭМЯёЃЌВЂНЋНиШЁКѓЕФЭМЯёЭЈЙ§МИДЮconv-poolЃЌШЛКѓдйЭЈЙ§roi-poolingКЭfcдйЪфГіСНЬѕжЇТЗЃЌвЛЬѕЪЧФПБъЗжРрsoftmaxЃЌСэвЛЬѕЪЧbboxЛиЙщЁЃНижЙЕНЯждкЃЌСНИіЭјТчВЂУЛгаЙВЯэВЮЪ§ЃЌжЛЪЧЗжПЊбЕСЗСЫЃЛ
3ЃЉ дйДЮбЕСЗRPNЃЌДЫЪБЙЬЖЈЭјТчЙЋЙВВПЗжЕФВЮЪ§ЃЌжЛИќаТRPNЖРгаВПЗжЕФВЮЪ§ЃЛ
4ЃЉ ФЧRPNЕФНсЙћдйДЮЮЂЕїFast-RCNNЭјТчЃЌЙЬЖЈЭјТчЙЋЙВВПЗжЕФВЮЪ§ЃЌжЛИќаТFast-RCNNЖРгаВПЗжЕФВЮЪ§ЁЃ
YOLOЫуЗЈНщЩм
YOLOММЪѕДѓжТдРэ
НЋвЛЗљЭМЯёЗжГЩSxSИіЭјИё(grid cell)ЃЌШчЙћФГИіobjectЕФжааФ
ТфдкетИіЭјИёжаЃЌдђетИіЭјИёОЭИКд№дЄВтетИіobjectЁЃ
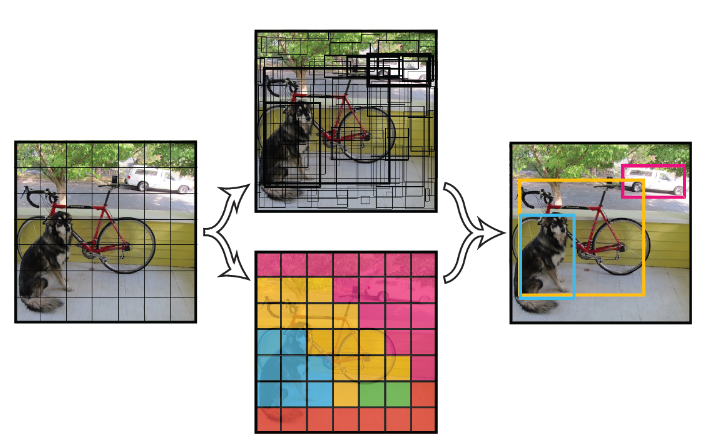
УПИіЭјИёвЊдЄВтТфдкИУЭјИёЕФЮяЬхРрБ№МАBИіbounding boxаХЯЂЃЌУПИіbounding boxдЄВтаХЯЂАќКЌздЩэЮЛжУаХЯЂ(ЫФИіБфСП)КЭconfidenceжЕЁЃ
confidenceДњБэСЫЫљдЄВтЕФboxжаКЌгаobjectЕФжУаХЖШКЭетИіboxдЄВтЕФгаЖрзМ(гыБъзЂЕФground
regionЕФIOU)СНжиаХЯЂЁЃ

ЦфжаШчЙћгаobjectТфдквЛИіgrid cellРяЃЌЕквЛЯюШЁ1ЃЌЗёдђШЁ0ЁЃ ЕкЖўЯюЪЧдЄВтЕФbounding
boxКЭЪЕМЪЕФgroundtruthжЎМфЕФIOUжЕЁЃ
УПИіbounding boxвЊдЄВт(x, y, w, h)КЭconfidenceЙВ5ИіжЕЃЌУПИіЭјИёЛЙвЊдЄВтвЛИіРрБ№аХЯЂЃЌМЧЮЊCРрЁЃдђSxSИіЭјИёЃЌУПИіЭјИёвЊдЄВтBИіbounding
boxЛЙвЊдЄВтCИіcategoriesЁЃЪфГіОЭЪЧS x S x (5*B+C)ЕФвЛИіtensorЁЃ
зЂвтЃКclassаХЯЂЪЧеыЖдУПИіЭјИёЕФЃЌconfidenceаХЯЂЪЧеыЖдУПИіbounding boxЕФЁЃ
ОйР§ЫЕУї: дкPASCAL VOCжаЃЌЭМЯёЪфШыЮЊ448x448ЃЌШЁS=7ЃЌB=2ЃЌвЛЙВга20ИіРрБ№(C=20)ЁЃдђЪфГіОЭЪЧ7x7x30ЕФвЛИіtensorЁЃ
дкtestЕФЪБКђЃЌУПИіЭјИёдЄВтЕФclassаХЯЂКЭbounding
boxдЄВтЕФconfidenceаХЯЂЯрГЫЃЌОЭЕУЕНУПИіbounding boxЕФclass-specific
confidence score:

|









