| БрМЭЦМі: |
БОЮФРДздВЉПЭдАЃЌБОЮФЪзЯШНщЩмСЫЛЅСЊЭјНчгыЛњЦїбЇЯАДѓХЃНсКЯЕФЧїЪЦЃЌвдМАЪЙгУЛњЦїбЇЯАЕФЯрЙигІгУЁЃ |
|
в§Тл
дкБОЦЊЮФеТжаЃЌЮвНЋЖдЛњЦїбЇЯАзіИіИХвЊЕФНщЩмЁЃБОЮФЕФФПЕФЪЧФмШУМДБуШЋШЛВЛСЫНтЛњЦїбЇЯАЕФШЫвВФмСЫНтЛњЦїбЇЯАЁЃЖјЧвЩЯЪжЯрЙиЕФЪЕМљЁЃетЦЊЮФЕЕвВЫуЪЧ
EasyPRПЊЗЂЕФЗЌЭтЦЊЁЃДгетРящ_ЪМЁЃБиаыЖдЛњЦїбЇЯАСЫНтВХИЩНјвЛВННщЩмEasyPRЕФФкКЫЁЃЕБШЛЃЌБОЮФвВУцЖдвЛАуЖСепЁЃВЛЛсЖддФЖСгаЯрЙиЕФЧАЬсвЊЧѓЁЃ
дкНјШые§ЬтЧАЁЃЮвЯыЖСепаФжаПЩФмЛсгавЛИівЩЛѓЃКЛњЦїбЇЯАгаЪВУДживЊадЃЌвджСгквЊдФЖСЭъетЦЊЗЧГЃГЄЕФЮФеТФиЃП
ЮвВЂВЛжБНгЛиД№етИіЮЪЬтЧАЁЃ
ЯрЗДЃЌЮвЯыЧыДѓМвПДСНеХЭМ
ЯТЭМЪЧЭМвЛЃК

ЭМ1 ЛњЦїбЇЯАНчЕФжДХЃЖњепгыЛЅСЊЭјНчЕФДѓіљЕФСЊві
етЗљЭМЩЯЩЯЕФШ§ШЫЪЧЕБНёЛњЦїбЇЯАНчЕФжДХЃЖњепЁЃ
жаМфЕФЪЧGeoffrey Hinton, МгФУДѓЖрТзЖрДѓбЇЕФНЬЪкЁЃШчНёБЛЦИЮЊЁАGoogleДѓФдЁБЕФИКд№ШЫЁЃ
гвБпЕФЪЧYann LeCun, ХІдМДѓбЇНЬЪкЃЌШчНёЪЧFacebookШЫЙЄжЧФмЪЕбщЪвЕФжїШЮЁЃ
ЖјзѓБпЕФДѓМвЖМЗЧГЃЪьЯЄЃЌAndrew NgЁЃжаЮФУћЮтЖїДяЃЌЫЙЬЙИЃДѓбЇИБНЬЪкЃЌШчНёвВЪЧЁААйЖШДѓФдЁБЕФИКд№ШЫгыАйЖШЪзЯЏПЦбЇМвЁЃ
етШ§ЮЛЖМЪЧблЯТвЕНчжЫЪжПЩШШЕФДѓХЃЃЌБЛЛЅСЊЭјНчДѓіљЧѓЯЭШєПЪЕФЦИ ЧыЃЌзуМћЫћУЧЕФживЊадЁЃЖјЫћУЧЕФбаОПЗНЯђЃЌдђШЋВПЖМЪЧЛњЦїбЇЯАЕФзгРрЈCЩюЖШбЇЯАЁЃ
ЯТЭМЪЧЭМЖўЃК

ЭМ2 гявєжњЪжВњЦЗ
етЗљЭМЩЯУшаДа№ЪіЕФЪЧЪВУДЃПWindows PhoneЩЯЕФгявєжњЪжCortanaЃЌУћзжРДдДгкЁЖЙтЛЗЁЗжаЪПЙйГЄЕФжњЪжЁЃЯрБШЦфЫќОКељЖдЪжЃЌЮЂШэЗЧГЃГйВХЭЦГіетИіЗўЮёЁЃCortanaБГКѓЕФКЫаФММЪѕЪЧ
ЪВУДЃЌЮЊЪВУДЫќФмЙЛЬ§ЖЎШЫЕФгявєЃПЦфЪЕЃЌетИіММЪѕе§ЪЧЛњЦїбЇЯАЁЃЛњЦїбЇЯАЪЧШЋВПгявєжњЪжВњЦЗ(АќРЈAppleЕФsiriгыGoogleЕФNow)ФмЙЛИњШЫНЛЛЅЕФЙиМќММЪѕЁЃ
ЭЈЙ§ЩЯУцСНЭМЃЌЮвЯраХДѓМвФмЙЛПДГіЛњЦїбЇЯАЫЦКѕЪЧвЛИіЗЧГЃживЊЕФЃЌгаЗЧГЃЖрЮДжЊЬиадЕФММЪѕЁЃбЇЯАЫќЫЦКѕЪЧвЛМўгаШЄЕФШЮЮёЁЃЪЕМЪЩЯЁЃбЇЯАЛњЦїбЇЯАВЛНіФмЙЛАяжњЮвУЧСЫНтЛЅСЊЭјНчзюаТЕФЧїЪЦЃЌЭЌвЛЪБКђвВФмЙЛжЊЕРАщЫцЮвУЧЕФБуРћЗўЮёЕФЪЕЯжММЪѕЁЃ
ЛњЦїбЇЯАЪЧЪВУДЃЌЮЊЪВУДЫќФмгаетУДДѓЕФФЇСІЃЌетаЉЮЪЬте§ЪЧБОЮФвЊЛиД№ЕФЁЃ
ЭЌвЛЪБКђЃЌБОЮФНазіЁАДгЛњЦїбЇЯАЬИЦ№ЁБЁЃвђДЫЛсвдТўЬИЕФаЮЪННщЩмИњЛњЦїбЇЯАЯрЙиЕФШЋВПФкШнЃЌАќРЈбЇПЦ(ШчЪ§ОнЭкОђЁЂМЦЫуЛњЪгОѕЕШ)ЃЌЫуЗЈ(ЩёОЭјТчЃЌsvm)ЕШЕШЁЃ
вЛИіЙЪЪТЫЕУїЪВУДЪЧЛњЦїбЇЯА
ЛњЦїбЇЯАетИіДЪЪЧШУШЫвЩЛѓЕФЁЃЪзЯШЫќЪЧгЂЮФУћГЦMachine Learning(МђГЦML)ЕФжБвыЁЃдкМЦЫуНчMachineвЛАужИМЦЫуЛњЁЃ
етИіУћзжЪЙгУСЫФтШЫЕФЪжЗЈЁЃЫЕУїСЫетУХММЪѕЪЧШУЛњЦїЁАбЇЯАЁБЕФММЪѕЁЃПЩЪЧМЦЫуЛњЪЧЫРЕФЃЌдѕУДПЩФмЯёШЫРрвЛбљЁАбЇЯАЁБФиЃП
ДЋЭГЩЯМйЩшЮвУЧЯыШУМЦЫуЛњЙЄзїЃЌЮвУЧИјЫќвЛДЎжИСюЃЌШЛКѓЫќзёееетИіжИСювЛВНВНдЫааЯТШЅЁЃ
гавђгаЙћЃЌЗЧГЃУїАзЁЃЕЋетжжЗНЪНдкЛњЦїбЇЯАжаааВЛЭЈЁЃ
ЛњЦїбЇЯАИљБОВЛНгЪмФуЪфШыЕФжИСюЃЌЯрЗДЃЌЫќНгЪмФуЪфШыЕФЪ§Он! вВОЭЪЧЫЕЃЌЛњЦїбЇЯАЪЧвЛжжШУМЦЫуЛњРћгУЪ§ОнЖјВЛЪЧжИСюРДНјааИїжжЙЄзїЕФЗНЗЈЁЃетЬ§Ц№РДЗЧГЃВЛПЩЫМвщЃЌЕЋНсЙћЩЯШДЪЧЗЧГЃПЩааЕФЁЃЁАЭГМЦЁБЫМЯыНЋдкФубЇЯАЁАЛњ
ЦїбЇЯАЁБЯрЙиРэФюЪБЮоЪБЮоПЬВЛАщЫцЃЌЯрЙиЖјВЛЪЧвђЙћЕФИХФюНЋЪЧжЇГХЛњЦїбЇЯАФмЙЛЙЄзїЕФКЫаФИХФюЁЃФуЛсЕпИВЖдФудјОШЋВПГЬађжаНЈСЂЕФвђЙћЮоДІВЛдкЕФИљБОРэ
ФюЁЃ
вдЯТЮвЭЈЙ§вЛИіЙЪЪТРДМђЕЅЕиВћУїЪВУДЪЧЛњЦїбЇЯАЁЃетИіЙЪЪТБШн^ЪЪКЯгУдкжЊКѕЩЯзїЮЊвЛИіИХФюЕФВћУїЁЃдкетРяЃЌетИіЙЪЪТУЛгаеЙПЊЁЃЕЋЯрЙиФкШнгыКЫаФЪЧДц
дкЕФЁЃ
МйЩшФуЯыМђЕЅЕФСЫНтвЛЯТЪВУДЪЧЛњЦїбЇЯАЃЌФЧУДПДЭъетИіЙЪЪТОЭзуЙЛСЫЁЃ
МйЩшФуЯыСЫНтЛњЦїбЇЯАЕФКмЖрЦфЫќжЊЪЖвдМАгыЫќЙиСЊНєУмЕФЕБДњММЪѕЃЌФЧУДЧыФуМЬајЭљЯТ ПДЁЃКѓУцгаКмЖрЦфЫќЕФЗсИЛЕФФкШнЁЃ
етИібљР§РДдДгкЮвецЪЕЕФЩњЛюОбщЃЌЮвдкЫМПМетИіЮЪЬтЕФЪБКђЭЛШЛЗЂЯжЫќЕФЙ§ГЬФмЙЛБЛРЉГфЛЏЮЊвЛИіЭъећЕФЛњЦїбЇЯАЕФЙ§ГЬЃЌвђДЫЮвОіЖЈЪЙгУетИібљР§зїЮЊШЋВПНщЩмЕФщ_ЪМЁЃетИіЙЪЪТГЦЮЊЁАЕШШЫЮЪЬтЁБЁЃ
ЮвЯраХДѓМвЖМгаИњБ№ШЫЯрдМЃЌШЛКѓЕШШЫЕФОРњЁЃЯжЪЕжаВЛЪЧУПвЛИіШЫЖМФЧУДЪиЪБЕФЃЌгкЪЧЕБФуХіЕНвЛаЉАЎГйЕНЕФШЫЃЌФуЕФЪБМфВЛПЩБмУтЕФвЊРЫЗбЁЃ
ЮвОЭХіЕНЙ§етжжвЛИібљР§ЁЃ
ЖдЮвЕФвЛИіХѓгбаЁYЖјбдЃЌЫћОЭВЛЪЧФЧУДЪиЪБЃЌзюГЃМћЕФБэЯжЪЧЫћГЃГЃГйЕНЁЃЕБгавЛДЮЮвИњЫћдМКУ3ЕужгдкФГИіТѓЕБРЭМћУцЪБЃЌдкЮвГіУХЕФФЧвЛПЬЮвЭЛШЛЯыЕНвЛИіЮЪЬтЃКЮвШчНёГіЗЂКЯЪЪУДЃПЮвЛсВЛЛсгжЕНСЫЕиЕуКѓЁЃЛЈЩЯ30ЗжжгШЅЕШЫћЃПЮвОіЖЈёШЁвЛИіВпТдНтОіЮЪЬтЁЃ
вЊЯыНтОіЮЪЬтЃЌгаКУМИжжЗНЗЈЁЃ
ЕквЛжжЗНЗЈЪЧёгУжЊЪЖЃКЮвЫббАФмЙЛНтОіЮЪЬтЕФжЊЪЖЁЃЕЋЗЧГЃвХКЖЁЃУЛгаШЫЛсАбдѕбљЕШШЫетИіЮЪЬтзїЮЊжЊЪЖДЋЪкЃЌвђДЫ
ЮвВЛПЩФмевЕНвбгаЕФжЊЪЖФмЙЛНтОіЮЪЬтЁЃ
СэЭтвЛжжЗНЗЈЪЧЮЪЫћШЫЃКЮвШЅбЏЮЪЫћШЫЛёЕУНтОіЮЪЬтЕФФмСІЁЃПЩЪЧЯрЭЌЕФЃЌетИіЮЪЬтУЛгаШЫФмЙЛНтД№ЃЌгЩгкПЩФмУЛШЫХіЩЯИњЮввЛбљЕФЧщПіЁЃ
ЕкШ§жжЗНЗЈЪЧзМдђЗЈЃКЮвЮЪздМКЕФФкаФЃЌЮвгаЗёЩшСЂЙ§ЪВУДзМдђШЅУцЖдетИіЮЪЬтЃПБШШчЃЌВЛЙмБ№ШЫдѕбљЃЌЮвЖМЛсЪиЪБЕНДяЁЃЕЋЮвВЛЪЧИіЫРАхЕФ
ШЫЁЃЮвУЛгаЩшСЂЙ§етжжЙцдђЁЃ
ЦфЪЕЃЌЮвЯраХгажжЗНЗЈБШвдЩЯШ§жжЖМКЯЪЪЁЃЮвАбЙ§ЭљИњаЁYЯрдМЕФОРњдкФдКЃжажиЯжвЛЯТЃЌПДПДИњЫћЯрдМЕФДЮЪ§жаЃЌГйЕНеМСЫЖрДѓЕФБШР§ЁЃЖјЮвРћгУетРДдЄ
yЫћетДЮГйЕНЕФПЩФмадЁЃМйЩшетИіжЕГЌГіСЫЮваФРяЕФФГИіНчЯоЃЌФЧЮвбЁдёЕШвЛЛсдйГіЗЂЁЃ
МйЩшЮвИњаЁYдМЙ§5ДЮЃЌЫћГйЕНЕФДЮЪ§ЪЧ1ДЮЃЌФЧУДЫћАДЪБЕНЕФБШР§ЮЊ 80%ЃЌЮваФжаЕФуажЕЮЊ70%ЃЌЮвОѕЕУетДЮаЁYгІИУВЛЛсГйЕНЃЌвђДЫЮвАДЪБГіУХЁЃМйЩшаЁYдк5ДЮГйЕНЕФДЮЪ§жаеМСЫ4ДЮЁЃвВОЭЪЧЫћАДЪБЕНДяЕФБШР§ЮЊ20%ЃЌгЩ
гкетИіжЕЕЭгкЮвЕФуажЕЁЃвђДЫЮвбЁдёЭЦГйГіУХЕФЪБМфЁЃетжжЗНЗЈДгЫќЕФРћгУВуУцРДПДЃЌгжГЦЮЊОбщЗЈЁЃдкОбщЗЈЕФЫМПМЙ§ГЬжаЁЃЮвЦфЪЕРћгУСЫвдЭљШЋВПЯрдМЕФЪ§
ОнЁЃвђДЫвВФмЙЛГЦжЎЮЊвРОнЪ§ОнзіЕФЭЦЖЯЁЃ
вРОнЪ§ОнЫљзіЕФЭЦЖЯИњЛњЦїбЇЯАЕФЫМЯыИљБОЩЯЪЧвЛжТЕФЁЃ
ИеВХЕФЫМПМЙ§ГЬЮвНіНіПМТЧЁАЦЕДЮЁБетжжЪєадЁЃдкецЪЕЕФЛњЦїбЇЯАжаЃЌетПЩФмЖМВЛЫуЪЧвЛИігІгУЁЃ
вЛАуЕФЛњЦїбЇЯАФЃаЭжСЩйПМТЧСНИіСПЃКвЛИіЪЧвђБфСПЃЌвВОЭЪЧ ЮвУЧЯЃЭћдЄyЕФНсЙћЃЌдкетИібљР§РяОЭЪЧаЁYГйЕНгыЗёЕФЭЦЖЯЁЃЛЙгавЛИіЪЧздБфСПЃЌвВОЭЪЧгУРДдЄyаЁYЪЧЗёГйЕНЕФСПЁЃ
МйЩшЮвАбЪБМфзїЮЊздБфСПЃЌЦЉШчЮвЗЂЯжаЁYЫљ гаГйЕНЕФШезгЛљБОЖМЪЧаЧЦкЮхЃЌЖјдкЗЧаЧЦкЮхЧщПіЯТЫћЛљБОВЛГйЕНЁЃгкЪЧЮвФмЙЛНЈСЂвЛИіФЃаЭЃЌРДФЃФтаЁYГйЕНгыЗёИњШезгЪЧЗёЪЧаЧЦкЮхЕФИХТЪЁЃ
МћЯТЭМЃК
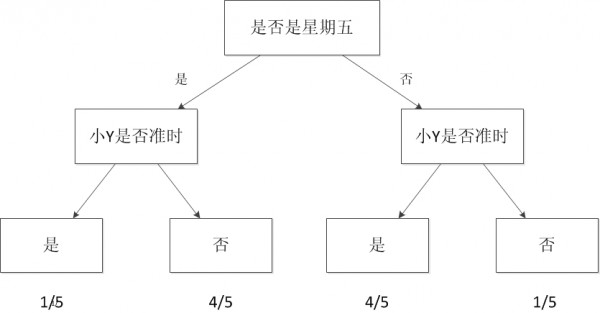
етжжЭМОЭЪЧвЛИізюМђЕЅЕФЛњЦїбЇЯАФЃаЭЁЃГЦжЎЮЊОіВпЪїЁЃ
ЕБЮвУЧПМТЧЕФздБфСПНіНігавЛИіЪБЃЌЧщПіНЯЮЊМђЕЅЁЃМйЩшАбЮвУЧЕФздБфСПдйЬэМгвЛИіЁЃБШШчаЁYГйЕНЕФВПЗжЧщПіЪБЪЧдкЫћПЊГЕЙ§РДЕФЪБКђ(ФуФмЙЛРэНтЮЊЫћПЊГЕЫЎЦННЯГєЃЌЛђепТЗНЯЖТ)ЁЃгкЪЧЮвФмЙЛЙиСЊПМТЧетаЉаХЯЂЁЃНЈСЂвЛИіИќИДдгЕФФЃаЭЁЃетИіФЃаЭАќРЈСНИіздБфСПгывЛИівђБфСПЁЃ
дйИќИДдгвЛЕуЃЌаЁYЕФГйЕНИњЬьЦјвВгавЛЖЈЕФдвђЃЌБШР§ШчвдЯТгъЕФЪБКђЃЌетЪБКђЮваывЊПМТЧШ§ИіздБфСПЁЃ
МйЩшЮвЯЃЭћФмЙЛдЄyаЁYГйЕНЕФЯъЯИЪБМфЃЌЮвФмЙЛАбЫћУПДЮГйЕНЕФЪБМфИњгъСПЕФДѓаЁвдМАЧАУцПМТЧЕФздБфСПЭГвЛНЈСЂвЛИіФЃаЭЁЃгкЪЧЮвЕФФЃаЭФмЙЛдЄyжЕЃЌР§
ШчЫћДѓИХЛсГйЕНМИЗжжгЁЃ
етбљФмЙЛАяжњЮвИќКУЕФЙцЛЎЮвГіУХЕФЪБМфЁЃ
дкетжжЧщПіЯТЃЌОіВпЪїОЭЮоЗЈЗЧГЃКУЕижЇГХСЫЃЌгЩгкОіВпЪїНіНіФмдЄyРыЩЂжЕЁЃ
ЮвУЧФмЙЛгУНк2Ыљ НщЩмЕФЯпаЭЛиЙщЗНЗЈНЈСЂетИіФЃаЭЁЃ
МйЩшЮвАбетаЉНЈСЂФЃаЭЕФЙ§ГЬНЛИјЕчФдЁЃ
БШЗНАбШЋВПЕФздБфСПКЭвђБфСПЪфШыЁЃШЛКѓШУМЦЫуЛњАяЮвЩњГЩвЛИіФЃаЭЃЌЭЌвЛЪБКђШУМЦЫуЛњвРОнЮвЕБЧАЕФЧщПіЃЌИјГіЮвЪЧЗёаывЊГйГіУХЃЌаывЊГйМИЗжжгЕФНЈвщЁЃ
ФЧУДМЦЫуЛњдЫааетаЉИЈжњОіВпЕФЙ§ГЬОЭЪЧЛњЦїбЇЯАЕФЙ§ГЬЁЃ
ЛњЦїбЇЯАЗНЗЈЪЧМЦЫуЛњРћгУвбгаЕФЪ§Он(Общ)ЁЃЕУГіСЫФГжжФЃаЭ(ГйЕНЕФЙцТЩ)ЃЌВЂРћгУДЫФЃаЭдЄyЮДРД(ЪЧЗёГйЕН)ЕФвЛжжЗНЗЈЁЃ
ЭЈЙ§ЩЯУцЕФЗжЮіЃЌФмЙЛПДГіЛњЦїбЇЯАгыШЫРрЫМПМЕФОбщЙ§ГЬЪЧЯрЫЦЕФЃЌжЛЪЧЫќФмПМТЧКмЖрЦфЫќЕФЧщПіЁЃдЫааИќМгИДдгЕФМЦЫуЁЃЦфЪЕЁЃЛњЦїбЇЯАЕФвЛИіжївЊФПЕФОЭ
ЪЧАбШЫРрЫМПМЙщФЩОбщЕФЙ§ГЬзЊЛЏЮЊМЦЫуЛњЭЈЙ§ЖдЪ§ОнЕФДІРэМЦЫуЕУГіФЃаЭЕФЙ§ГЬЁЃОЙ§МЦЫуЛњЕУГіЕФФЃаЭФмЙЛвдНќЫЦгкШЫЕФЗНЪННтОіЗЧГЃЖрСщЛюИДдгЕФЮЪЬтЁЃ
вдЯТЃЌЮвЛсщ_ЪМЖдЛњЦїбЇЯАЕФе§ЪННщЩмЁЃАќРЈЖЈвхЁЂЗЖЮЇЁЃЗНЗЈЁЂгІгУЕШЕШЃЌЖМгаЫљАќРЈЁЃ
ЛњЦїбЇЯАЕФЖЈвх
ДгЙувхЩЯРДЫЕЃЌЛњЦїбЇЯАЪЧвЛжжФмЙЛИГгшЛњЦїбЇЯАЕФФмСІвдДЫШУЫќЭъБЯжБНгБрГЬЮоЗЈЭъБЯЕФЙІФмЕФЗНЗЈЁЃЕЋДгЪЕМљЕФвтвхЩЯРДЫЕЁЃЛњЦїбЇЯАЪЧвЛжжЭЈЙ§РћгУЪ§ОнЁЃбЕСЗГіФЃаЭЃЌШЛКѓЪЙгУФЃаЭдЄyЕФвЛжжЗНЗЈЁЃ
ШУЮвУЧЯъЯИПДвЛИібљР§ЁЃ
ЭМ4 ЗПМлЕФбљР§
ФУЙњУёЛАЬтЕФЗПзгРДЫЕЁЃШчНёЮвЪжРягавЛЖАЗПзгаывЊЪлТєЃЌЮвгІИУИјЫќБъЩЯЖрДѓЕФМлИёЃПЗПзгЕФУцЛ§ЪЧ100ЦНЗНУзЃЌМлИёЪЧ100ЭђЁЃ120ЭђЁЃЛЙЪЧ140ЭђЃП
ЗЧГЃЯдШЛЃЌЮвЯЃЭћЛёЕУЗПМлгыУцЛ§ЕФФГжжЙцТЩЁЃ
ФЧУДЮвИУдѕбљЛёЕУетИіЙцТЩЃПгУБЈжНЩЯЕФЗПМлЦНОљЪ§ОнУДЃПЛЙЪЧ
ЂПМБ№ШЫУцЛ§ЯрЫЦЕФЃПВЛЙмФФжжЃЌЫЦКѕЖМВЂЗЧЬЋППЦзЁЃ
ЮвШчНёЯЃЭћЛёЕУвЛИіКЯРэЕФЃЌЖјЧвФмЙЛзюДѓГЬЖШЕФЗДгГУцЛ§гыЗПМлЙиЯЕЕФЙцТЩЁЃгкЪЧЮвЕїВщСЫжмБпгыЮвЗПаЭЯрЫЦЕФвЛаЉЗПзгЃЌЛёЕУвЛзщЪ§ОнЁЃетзщЪ§ОнжаАќРЈСЫДѓДѓаЁаЁЗПзгЕФУцЛ§гыМлИёЁЃМйЩшЮвФмДгетзщЪ§ОнжаевГіУцЛ§гыМлИёЕФЙцТЩЃЌФЧУДЮвОЭФмЙЛЕУГіЗПзгЕФМлИёЁЃ
ЖдЙцТЩЕФбАевЗЧГЃeasyЃЌФтКЯГівЛЬѕжБЯпЃЌШУЫќЁАДЉЙ§ЁБШЋВПЕФЕуЃЌЖјЧвгыИїИіЕуЕФОрРыОЁПЩФмЕФаЁЁЃ
ЭЈЙ§етЬѕжБЯпЁЃЮвЛёЕУСЫвЛИіФмЙЛзюМбЗДгГЗПМлгыУцЛ§ЙцТЩЕФЙцТЩЁЃетЬѕжБЯпЭЌвЛЪБКђвВЪЧвЛИіЯТЪНЫљБэУїЕФКЏЪ§ЃК
ЗПМл = УцЛ§ * a + b
ЩЯЪіжаЕФaЁЂbЖМЪЧжБЯпЕФ
ЂЪ§ЁЃЛёЕУетаЉ
ЂЪ§вдКѓЁЃЮвОЭФмЙЛМЦЫуГіЗПзгЕФМлИёЁЃ
МйЩшa = 0.75,b = 50ЃЌдђЗПМл = 100 * 0.75 + 50 = 125ЭђЁЃетИіНсЙћгыЮвЧАУцЫљСаЕФ100ЭђЁЃ120ЭђЃЌ140ЭђЖМВЛвЛбљЁЃ
гЩгкетЬѕжБЯпзлКЯПМТЧСЫДѓВПЗжЕФЧщПіЃЌвђДЫДгЁАЭГМЦЁБвтвхЩЯРДЫЕЃЌетЪЧвЛИізюКЯРэЕФдЄyЁЃ
дкЧѓНтЙ§ГЬжаЭИТЖГіСЫСНИіаХЯЂЃК
1.ЗПМлФЃаЭЪЧвРОнФтКЯЕФКЏЪ§РраЭОіЖЈЕФЁЃ
МйЩшЪЧжБЯпЃЌФЧУДФтКЯГіЕФОЭЪЧжБЯпЗНГЬЁЃМйЩшЪЧЦфЫќРраЭЕФЯпЃЌБШШчХзЮяЯпЃЌФЧУДФтКЯГіЕФОЭЪЧХзЮяЯпЗНГЬЁЃ
ЛњЦїбЇЯАгажкЖрЫуЗЈЁЃвЛаЉЧПСІЫуЗЈФмЙЛФтКЯГіИДдгЕФЗЧЯпадФЃаЭЃЌгУРДЗДгГвЛаЉВЛЪЧжБЯпЫљФмБэДяЕФЧщПіЁЃ
2.МйЩшЮвЕФЪ§ОндНЖрЁЃЮвЕФФЃаЭОЭдНФмЙЛПМТЧЕНдНЖрЕФЧщПіЃЌгЩДЫЖдгкаТЧщПіЕФдЄyаЇЙћПЩФмОЭдНКУЁЃ
етЪЧЛњЦїбЇЯАНчЁАЪ§ОнЮЊЭѕЁБЫМЯыЕФвЛИіЬхЯжЁЃвЛАуРДЫЕ(ВЛЪЧОјЖд)ЃЌЪ§ОндНЖрЁЃзюКѓЛњЦїбЇЯАЩњГЩЕФФЃаЭдЄyЕФаЇЙћдНКУЁЃ
ЭЈЙ§ЮвФтКЯжБЯпЕФЙ§ГЬЃЌЮвУЧФмЙЛЖдЛњЦїбЇЯАЙ§ГЬзівЛИіЭъећЕФЛиЯыЁЃ
ЪзЯШЃЌЮвУЧаывЊдкМЦЫуЛњжаДцДЂРњЪЗЕФЪ§ОнЁЃНгзХЃЌЮвУЧНЋетаЉ Ъ§ОнЭЈЙ§ЛњЦїбЇЯАЫуЗЈНјааДІРэЃЌетИіЙ§ГЬдкЛњЦїбЇЯАжаНазіЁАбЕСЗЁБЃЌДІРэЕФНсЙћФмЙЛБЛЮвУЧгУРДЖдаТЕФЪ§ОнНјаадЄyЃЌетИіНсЙћвЛАуГЦжЎЮЊЁАФЃаЭЁБЁЃЖдаТЪ§Он
ЕФдЄyЙ§ГЬдкЛњЦїбЇЯАжаНазіЁАдЄyЁБЁЃЁАбЕСЗЁБгыЁАдЄyЁБЪЧЛњЦїбЇЯАЕФСНИіЙ§ГЬЃЌЁАФЃаЭЁБдђЪЧЙ§ГЬЕФжаМфЪфГіНсЙћЁЃЁАбЕСЗЁБВњЩњЁАФЃаЭЁБЃЌЁАФЃаЭЁБжИЕМ
ЁАдЄyЁБЁЃ
ШУЮвУЧАбЛњЦїбЇЯАЕФЙ§ГЬгыШЫРрЖдРњЪЗОбщЙщФЩЕФЙ§ГЬзіИіБШЖдЁЃ
ЭМ5 ЛњЦїбЇЯАгыШЫРрЫМПМЕФРрБШ
ШЫРрдкГЩГЄЁЂЩњЛюЙ§ГЬжаЛ§РлСЫЗЧГЃЖрЕФРњЪЗгыОбщЁЃШЫРрЖЈЦкЕиЖдетаЉОбщНјааЁАЙщФЩЁБЃЌЛёЕУСЫЩњЛюЕФЁАЙцТЩЁБЁЃЕБШЫРргіЕНЮДжЊЕФЮЪЬтЛђепаывЊЖдЮДРДНјааЁАВТyЁБЕФЪБКђЃЌШЫРрЪЙгУетаЉЁАЙцТЩЁБЁЃЖдЮДжЊЮЪЬтгыЮДРДНјааЁАВТyЁБЃЌДгЖјжИЕМздМКЕФЩњЛюКЭЙЄзїЁЃ
ЛњЦїбЇЯАжаЕФЁАбЕСЗЁБгыЁАдЄyЁБЙ§ГЬФмЙЛЯргІЕНШЫРрЕФЁАЙщФЩЁБКЭЁАВТyЁБЙ§ГЬЁЃЭЈЙ§етжжЯргІЃЌЮвУЧФмЙЛЗЂЯжЃЌЛњЦїбЇЯАЕФЫМЯыВЂВЛИДдгЁЃНіНіЪЧЖдШЫ
РрдкЩњЛюжабЇЯАГЩГЄЕФвЛИіФЃФтЁЃгЩгкЛњЦїбЇЯАВЛЪЧЛљгкБрГЬаЮГЩЕФНсЙћЁЃвђДЫЫќЕФДІРэЙ§ГЬВЛЪЧвђЙћЕФТпМЃЌЖјЪЧЭЈЙ§ЙщФЩЫМЯыЕУГіЕФЯрЙиадНсТлЁЃ
етвВФмЙЛСЊЯыЕНШЫРрЮЊЪВУДвЊбЇЯАРњЪЗЃЌРњЪЗЪЕМЪЩЯЪЧШЫРрЙ§ЭљОбщЕФзмНсЁЃ
гаОфЛАЫЕЕУЗЧГЃКУЁЃЁАРњЪЗЭљЭљВЛвЛбљЁЃЕЋРњЪЗзмЪЧОЊШЫЕФЯрЫЦЁБЁЃ
ЭЈЙ§бЇЯАРњ ЪЗЁЃЮвУЧДгРњЪЗжаЙщФЩГіШЫЩњгыЙњМвЕФЙцТЩЃЌДгЖјжИЕМЮвУЧЕФЯТвЛВНЙЄзїЃЌетЪЧОпгаФЊДѓМлжЕЕФЁЃ
ЕБДњвЛаЉШЫКіЪгСЫРњЪЗЕФБОРДМлжЕЃЌЖјЪЧАбЦфзїЮЊвЛжжаћбяЙІМЈЕФ ЪжЖЮЃЌетЦфЪЕЪЧЖдРњЪЗецЪЕМлжЕЕФвЛжжЮѓгУЁЃ
ЛњЦїбЇЯАЕФЗЖЮЇ
ЩЯЮФЫфШЛЫЕУїСЫЛњЦїбЇЯАЪЧЪВУДЃЌПЩЪЧВЂУЛгаИјГіЛњЦїбЇЯАЕФЗЖЮЇЁЃ
ЦфЪЕЃЌЛњЦїбЇЯАИњФЃЪНЪЖБ№ЃЌЭГМЦбЇЯАЁЃЪ§ОнЭкОђЁЃМЦЫуЛњЪгОѕЃЌгявєЪЖБ№ЃЌздШЛгябдДІРэЕШСьгђгазХЗЧГЃЩюЕФСЊЯЕЁЃ
ДгЗЖЮЇЩЯРДЫЕЁЃЛњЦїбЇЯАИњФЃЪНЪЖБ№ЃЌЭГМЦбЇЯАЁЃЪ§ОнЭкОђЪЧЯрЫЦЕФЁЃЭЌвЛЪБКђЃЌЛњЦїбЇЯАгыЦфЫќСьгђЕФДІРэММЪѕЕФНсКЯЁЃаЮГЩСЫМЦЫуЛњЪгОѕЁЂгявєЪЖБ№ЁЂздШЛгя
бдДІРэЕШНЛВцбЇПЦЁЃвђДЫЃЌвЛАуЫЕЪ§ОнЭкОђЪБЃЌФмЙЛЕШЭЌгкЫЕЛњЦїбЇЯАЁЃЭЌвЛЪБКђЁЃЮвУЧбАГЃЫљЫЕЕФЛњЦїбЇЯАгІгУЁЃгІИУЪЧЭЈгУЕФЃЌВЛНіНіОжЯодкНсЙЙЛЏЪ§ОнЃЌЛЙгаЭМ
ЯёЃЌвєЦЕЕШгІгУЁЃ
дкетНкЖдЛњЦїбЇЯАетаЉЯрЙиСьгђЕФНщЩмгажњгкЮвУЧРэЧхЛњЦїбЇЯАЕФгІгУГЁОАгыбаОПЗЖЮЇЁЃИќКУЕФРэНтКѓУцЕФЫуЗЈгыгІгУВуДЮЁЃ
ЯТЭМЪЧЛњЦїбЇЯАЫљЧЃГЖЕФвЛаЉЯрЙиЗЖЮЇЕФбЇПЦгыбаОПСьгђЁЃ

ФЃЪНЪЖБ№
ФЃЪНЪЖБ№=ЛњЦїбЇЯА
СНепЕФжївЊВюБ№дкгкЧАепЪЧДгЙЄвЕНчЗЂеЙЦ№РДЕФИХФюЁЃКѓепдђжївЊдДздМЦЫуЛњбЇПЦЁЃдкжјУћЕФ ЁЖPattern
Recognition And Machine LearningЁЗетБОЪщжаЃЌChristopher
M. BishopдкПЊЭЗЪЧетбљЫЕЕФЁАФЃЪНЪЖБ№дДздЙЄвЕНчЃЌЖјЛњЦїбЇЯАРДздгкМЦЫуЛњбЇПЦЁЃ
жЛЪЧЃЌЫќУЧжаЕФЛюЖЏФмЙЛБЛЪгЮЊЭЌвЛИіСьгђЕФСНИіЗНУцЃЌЭЌвЛЪБКђдкЙ§ШЅЕФ10 ФъМфЃЌЫќУЧЖМгаСЫГЄзуЕФЗЂеЙЁБЁЃ
Ъ§ОнЭкОђ
Ъ§ОнЭкОђ=ЛњЦїбЇЯА+Ъ§ОнПт
етМИФъЪ§ОнЭкОђЕФИХФюЪЕдкЪЧЬЋЖњЪьФмЯъЁЃВюЕуЖљЕШЭЌгкГДзїЁЃ
ЕЋЗВЫЕЪ§ОнЭкОђЖМЛсДЕаъ Ъ§ОнЭкОђдѕбљдѕбљЁЃБШШчДгЪ§ОнжаЭкГіН№згЃЌвдМАНЋЗЯЦњЕФЪ§ОнзЊЛЏЮЊМлжЕЕШЕШЁЃПЩЪЧЃЌЮвЫфШЛПЩФмЛсЭкГіН№згЁЃЕЋЮввВПЩФмЭкЕФЪЧЁАЪЏЭЗЁБАЁЁЃ
етИіЫЕЗЈЕФвтЫМ ЪЧЁЃЪ§ОнЭкОђНіНіЪЧвЛжжЫМПМЗНЪНЁЃИцЫпЮвУЧгІИУГЂЪдДгЪ§ОнжаЭкОђГіжЊЪЖЁЃЕЋВЛЪЧУПвЛИіЪ§ОнЖМФмЭкОђГіН№згЕФЃЌЫљвдВЛвЊЩёЛАЫќЁЃвЛИіЯЕЭГОјЖдВЛЛсгЩгкЩЯСЫвЛИі
Ъ§ОнЭкОђФЃПщОЭБфЕУЮоЫљВЛФм(етЪЧIBMзюЯВЛЖДЕаъЕФ)ЁЃЧЁЧЁЯрЗДЃЌвЛИігЕгаЪ§ОнЭкОђЫМЮЌЕФШЫдБВХЪЧЙиМќЁЃЖјЧвЫћЛЙБиаыЖдЪ§ОнгаЩюПЬЕФШЯЪЖЃЌетбљВХПЩФмДг
Ъ§ОнжаЕМГіФЃЪНжИв§вЕЮёЕФИФЩЦЁЃДѓВПЗжЪ§ОнЭкОђжаЕФЫуЗЈЪЧЛњЦїбЇЯАЕФЫуЗЈдкЪ§ОнПтжаЕФгХЛЏЁЃ
ЭГМЦбЇЯА
ЭГМЦбЇЯАНќЫЦЕШгкЛњЦїбЇЯА
ЭГМЦбЇЯАЪЧИігыЛњЦїбЇЯАИпЖШжиЕўЕФбЇПЦЁЃгЩгкЛњЦїбЇЯАжаЕФДѓЖрЪ§ЗНЗЈРДздЭГМЦбЇЃЌЩѕ жСФмЙЛОѕЕУЁЃЭГМЦбЇЕФЗЂеЙДйНјЛњЦїбЇЯАЕФЗБШйВ§ЪЂЁЃБШШчжјУћЕФжЇГжЯђСПЛњЫуЗЈЃЌОЭЪЧдДздЭГМЦбЇПЦЁЃПЩЪЧдкФГжжГЬЖШЩЯСНепЪЧгаЗжБ№ЕФЃЌетИіЗжБ№дкгкЃКЭГМЦбЇ
ЯАепжиЕуЙизЂЕФЪЧЭГМЦФЃаЭЕФЗЂеЙгыгХЛЏЃЌЦЋЪ§бЇЃЌЖјЛњЦїбЇЯАепИќЙизЂЕФЪЧФмЙЛНтОіЮЪЬтЃЌЦЋЪЕМљЃЌвђДЫЛњЦїбЇЯАбаОПепЛсжиЕубаОПбЇЯАЫуЗЈдкМЦЫуЛњЩЯдЫааЕФаЇ
ТЪгызМШЗадЕФЬсЩ§ЁЃ
МЦЫуЛњЪгОѕ
МЦЫуЛњЪгОѕ=ЭМЯёДІРэ+ЛњЦїбЇЯА
ЭМЯёДІРэММЪѕгУгкНЋЭМЯёДІРэЮЊЪЪКЯНјШыЛњЦїбЇЯАФЃаЭжаЕФЪфШыЃЌЛњЦїбЇЯАдђИКд№ ДгЭМЯёжаЪЖБ№ГіЯрЙиЕФФЃЪНЁЃ
МЦЫуЛњЪгОѕЯрЙиЕФгІгУЗЧГЃЕФЖрЁЃБШШчАйЖШЪЖЭМЁЂЪжаДзжЗћЪЖБ№ЁЂГЕХЦЪЖБ№ЕШЕШгІгУЁЃетИіСьгђЪЧгІгУЧАОАЗЧГЃЛ№ШШЕФЁЃЭЌвЛЪБКђвВЪЧбаОП
ЕФШШУХЗНЯђЁЃЫцзХЛњЦїбЇЯАЕФаТСьгђЩюЖШбЇЯАЕФЗЂеЙЃЌДѓДѓДйНјСЫМЦЫуЛњЭМЯёЪЖБ№ЕФаЇЙћЁЃвђДЫЮДРДМЦЫуЛњЪгОѕНчЕФЗЂеЙЧАОАВЛПЩЙРСПЁЃ
гявєЪЖБ№
гявєЪЖБ№=гявєДІРэ+ЛњЦїбЇЯА
гявєЪЖБ№ОЭЪЧвєЦЕДІРэММЪѕгыЛњЦїбЇЯАЕФНсКЯЁЃгявєЪЖБ№ММЪѕвЛАуВЛЛсЕЅЖРЪЙгУЃЌЭЈГЃЛсНсКЯздШЛгябдДІРэЕФЯрЙиММЪѕЁЃблЯТЕФЯрЙигІгУгаЦЛЙћЕФгявєжњЪжsiriЕШЁЃ
здШЛгябдДІРэ
здШЛгябдДІРэ=ЮФБОДІРэ+ЛњЦїбЇЯА
здШЛгябдДІРэММЪѕжївЊЪЧШУЛњЦїРэНтШЫРрЕФгябдЕФвЛУХСьгђЁЃ
дкздШЛгябдДІРэММ ЪѕжаЃЌДѓСПЪЙгУСЫБрвыдРэЯрЙиЕФММЪѕЃЌБШШчДЪЗЈЗжЮіЃЌгяЗЈЗжЮіЕШЕШЃЌГ§ДЫжЎЭтЃЌдкРэНтетИіВуУцЃЌдђЪЙгУСЫгявхРэНтЃЌЛњЦїбЇЯАЕШММЪѕЁЃзїЮЊЮЈвЛгЩШЫРрздЩэДД
дьЕФЗћКХЃЌздШЛгябдДІРэвЛжБЪЧЛњЦїбЇЯАНчВЛЖЯбаОПЕФЗНЯђЁЃвРееАйЖШЛњЦїбЇЯАзЈМвгрПЕФЫЕЗЈЁАЬ§гыПДЃЌЫЕАзСЫОЭЪЧАЂУЈКЭАЂЙЗЖМЛсЕФЁЃЖјНіНігагябдВХЪЧШЫРрЖРга
ЕФЁБЁЃдѕбљРћгУЛњЦїбЇЯАММЪѕНјааздШЛгябдЕФЕФЩюЖШРэНтЁЃвЛжБЪЧЙЄвЕКЭбЇЪѕНчЙизЂЕФНЙЕуЁЃ
ФмЙЛПДГіЛњЦїбЇЯАдкжкЖрСьгђЕФЭтбгКЭгІгУЁЃЛњЦїбЇЯАММЪѕЕФЗЂеЙДйЪЙСЫЗЧГЃЖржЧФмСьгђЕФНјВНЃЌИФЩЦзХЮвУЧЕФЩњЛюЁЃ
ЛњЦїбЇЯАЕФЗНЗЈ
ЭЈЙ§ЩЯНкЕФНщЩмЮвУЧжЊЯўСЫЛњЦїбЇЯАЕФДѓжТЗЖЮЇЃЌФЧУДЛњЦїбЇЯАРяУцЕНЕзгаЖрЩйОЕфЕФЫуЗЈФиЃПдкетИіВПЗжЮвЛсМђвЊНщЩмвЛЯТЛњЦїбЇЯАжаЕФОЕфДњБэЗНЗЈЁЃетВПЗжНщЩмЕФжиЕуЪЧетаЉЗНЗЈФкКЕФЫМЯыЁЃЪ§бЇгыЪЕМљЯИНкВЛЛсдкетЬжТлЁЃ
ЛиЙщЫуЗЈ
дкДѓВПЗжЛњЦїбЇЯАПЮГЬжаЁЃЛиЙщЫуЗЈЖМЪЧНщЩмЕФЕквЛИіЫуЗЈЁЃ
двђгаСНИіЃК
вЛ.ЛиЙщЫуЗЈБШн^МђЕЅЁЃНщЩмЫќФмЙЛШУШЫЦНЛЌЕиДгЭГМЦбЇЧЈвЦЕНЛњЦїбЇЯАжаЁЃ
Жў. ЛиЙщЫуЗЈЪЧКѓУцШєИЩЧПДѓЫуЗЈЕФЛљЪЏЁЃМйЩшВЛРэНтЛиЙщЫуЗЈЁЃЮоЗЈбЇЯАФЧаЉЧПДѓЕФЫуЗЈЁЃЛиЙщЫуЗЈгаСНИіживЊЕФзгРрЃКМДЯпадЛиЙщКЭТпМЛиЙщЁЃ
ЯпадЛиЙщОЭЪЧЮвУЧЧАУцЫЕЙ§ЕФЗПМлЧѓНтЮЪЬтЁЃдѕбљФтКЯГівЛЬѕжБЯпзюМбЦЅХфЮвШЋВПЕФЪ§ОнЃПвЛАуЪЙгУЁАзюаЁЖўГЫЗЈЁБРДЧѓНтЁЃ
ЁАзюаЁЖўГЫЗЈЁБЕФЫМЯыЪЧетбљ ЕФЃЌМйЩшЮвУЧФтКЯГіЕФжБЯпДњБэЪ§ОнЕФецЪЕжЕЁЃЖјЙлyЕНЕФЪ§ОнДњБэгЕгаЮѓВюЕФжЕЁЃЮЊСЫОЁПЩФмМѕаЁЮѓВюЕФгАЯьЃЌаывЊЧѓНтвЛЬѕжБЯпЪЙШЋВПЮѓВюЕФЦНЗНКЭзюаЁЁЃзюаЁ
ЖўГЫЗЈНЋзюгХЮЪЬтзЊЛЏЮЊЧѓКЏЪ§МЋжЕЮЪЬтЁЃКЏЪ§МЋжЕдкЪ§бЇЩЯЮвУЧЭЈГЃЛсёгУЧѓЕМЪ§ЮЊ0ЕФЗНЗЈЁЃ
ЕЋетжжзіЗЈВЂВЛЪЪКЯМЦЫуЛњЃЌПЩФмЧѓНтВЛГіРДЁЃвВПЩФмМЦЫуСПЬЋ ДѓЁЃ
МЦЫуЛњПЦбЇНчзЈУХгавЛИібЇПЦНаЁАЪ§жЕМЦЫуЁБЃЌзЈУХгУРДЬсЩ§МЦЫуЛњНјааИїРрМЦЫуЪБЕФзМШЗадКЭаЇТЪЮЪЬтЁЃ
БШШчЃЌжјУћЕФЁАЬнЖШЯТНЕЁБвдМАЁАХЃЖйЗЈЁБОЭЪЧЪ§ жЕМЦЫужаЕФОЕфЫуЗЈЁЃвВЗЧГЃЪЪКЯРДДІРэЧѓНтКЏЪ§МЋжЕЕФЮЪЬтЁЃЬнЖШЯТНЕЗЈЪЧНтОіЛиЙщФЃаЭжазюМђЕЅЧвгааЇЕФЗНЗЈжЎжаЕФвЛИіЁЃ
ДгбЯИёвтвхЩЯРДЫЕЃЌгЩгкКѓЮФжаЕФЩёОЭјТч КЭЭЦМіЫуЗЈжаЖМгаЯпадЛиЙщЕФвђзгЃЌвђДЫЬнЖШЯТНЕЗЈдкКѓУцЕФЫуЗЈЪЕЯжжавВгагІгУЁЃ
ТпМЛиЙщЪЧвЛжжгыЯпадЛиЙщЗЧГЃЯрЫЦЕФЫуЗЈЁЃПЩЪЧЁЃДгБОжЪЩЯНВЃЌЯпаЭЛиЙщДІРэЕФЮЪЬтРраЭгыТпМЛиЙщВЛвЛжТЁЃЯпадЛиЙщДІРэЕФЪЧЪ§жЕЮЪЬтЃЌвВОЭЪЧзюКѓдЄy
ГіЕФНсЙћЪЧЪ§зжЁЃБШШчЗПМлЁЃЖјТпМЛиЙщЪєгкЗжРрЫуЗЈЃЌвВОЭЪЧЫЕЃЌТпМЛиЙщдЄyНсЙћЪЧРыЩЂЕФЗжРрЁЃБШШчЭЦЖЯетЗтгЪМўЪЧЗёЪЧРЌЛјгЪМўЃЌвдМАгУЛЇЪЧЗёЛсЕуЛїДЫЙу
ИцЕШЕШЁЃ
ЪЕЯжЗНУцЕФЛАЁЃТпМЛиЙщНіНіЪЧЖдЖдЯпадЛиЙщЕФМЦЫуНсЙћМгЩЯСЫвЛИіSigmoidКЏЪ§ЃЌНЋЪ§жЕНсЙћзЊЛЏЮЊСЫ0ЕН1жЎМфЕФИХТЪ(SigmoidКЏЪ§ЕФЭМЯё
вЛАуРДЫЕВЂВЛжБЙлЃЌФуНіНіаывЊРэНтЖдЪ§жЕдНДѓЃЌКЏЪ§дНБЦНќ1ЃЌЪ§жЕдНаЁЁЃКЏЪ§дНБЦНќ0)ЃЌНгзХЮвУЧвРОнетИіИХТЪФмЙЛзідЄyЃЌБШШчИХТЪДѓгк0.5ЃЌдђетЗтгЪМў
ОЭЪЧРЌЛјгЪМўЃЌЛђепжзСіЪЧЗёЪЧЖёадЕФЕШЕШЁЃ
ДгжБЙлЩЯРДЫЕЃЌТпМЛиЙщЪЧЛГіСЫвЛЬѕЗжРрЯп
МћЯТЭМ 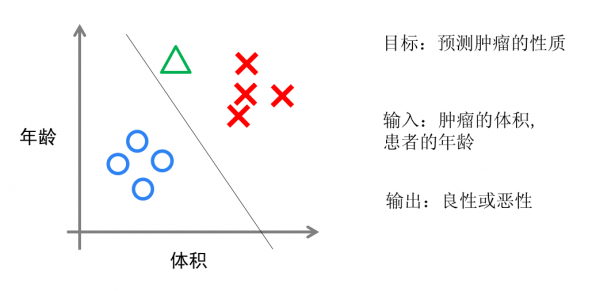
ЭМ7 ТпМЛиЙщЕФжБЙлНтЪЭ
МйЩшЮвУЧгавЛзщжзСіЛМепЕФЪ§ОнЃЌетаЉЛМепЕФжзСіжагааЉЪЧСМадЕФ(ЭМжаЕФРЖЩЋЕу)ЁЃгааЉЪЧЖёадЕФ(ЭМжаЕФКьЩЋЕу)ЁЃетРяжзСіЕФКьРЖЩЋФмЙЛБЛГЦзїЪ§ОнЕФ
ЁАБъЧЉЁБЁЃ
ЭЌвЛЪБКђУПвЛИіЪ§ОнАќРЈСНИіЁАЬиеїЁБЃКЛМепЕФФъСфгыжзСіЕФДѓаЁЁЃЮвУЧНЋетСНИіЬиеїгыБъЧЉгГЩфЕНетИіЖўЮЌПеМфЩЯЁЃаЮГЩСЫЮвЩЯЭМЕФЪ§ОнЁЃ
ЕБЮвгавЛИіТЬЩЋЕФЕуЪБЃЌЮвИУЭЦЖЯетИіжзСіЪЧЖёадЕФЛЙЪЧСМадЕФФиЃПвРОнКьРЖЕуЮвУЧбЕСЗГіСЫвЛИіТпМЛиЙщФЃаЭЁЃвВОЭЪЧЭМжаЕФЗжРрЯпЁЃетЪБЃЌвРОнТЬЕуГіШчНёЗжРрЯпЕФзѓШЃЌвђДЫЮвУЧЭЦЖЯЫќЕФБъЧЉгІИУЪЧКьЩЋЃЌвВОЭЪЧЫЕЪєгкЖёаджзСіЁЃ
ТпМЛиЙщЫуЗЈЛЎГіЕФЗжРрЯпЛљБОЖМЪЧЯпадЕФ(вВгаЛЎГіЗЧЯпадЗжРрЯпЕФТпМЛиЙщЃЌжЛЪЧФЧбљЕФФЃаЭдкДІРэЪ§ОнСПНЯДѓЕФЪБКђаЇТЪЛсЗЧГЃЕЭ)ЁЃетвтЮЖзХЕБСНРржЎ
МфЕФНчЯпВЛЪЧЯпадЪБЁЃТпМЛиЙщЕФБэДяФмСІОЭВЛзуЁЃ
вдЯТЕФСНИіЫуЗЈЪЧЛњЦїбЇЯАНчзюЧПДѓЧвживЊЕФЫуЗЈЁЃЖМФмЙЛФтКЯГіЗЧЯпадЕФЗжРрЯпЁЃ
ЩёОЭјТч
ЩёОЭјТч(вВГЦжЎЮЊШЫЙЄЩёОЭјТчЁЃANN)ЫуЗЈЪЧ80ФъДњЛњЦїбЇЯАНчЗЧГЃСїааЕФЫуЗЈЃЌжЛЪЧдк90ФъДњжаЭОЫЅТфЁЃШчНёЁЃаЏзХЁАЩюЖШбЇЯАЁБжЎЪЦЁЃЩёОЭјТчжизАЙщРДЁЃгжвЛДЮГЩЮЊзюЧПДѓЕФЛњЦїбЇЯАЫуЗЈжЎжаЕФвЛИіЁЃ
ЩёОЭјТчЕФЕЎЩњЦ№дДгкЖдДѓФдЙЄзїЛњРэЕФбаОПЁЃ
дчЦкЩњЮяНчбЇепУЧЪЙгУЩёОЭјТчРДФЃФтДѓФдЁЃЛњЦїбЇЯАЕФбЇепУЧЪЙгУЩёОЭјТчНјааЛњЦїбЇЯАЕФЪЕбщЁЃЗЂШчНёЪг
ОѕгыгявєЕФЪЖБ№ЩЯаЇЙћЖМЯрЕБКУЁЃдкBPЫуЗЈ(МгЫйЩёОЭјТчбЕСЗЙ§ГЬЕФЪ§жЕЫуЗЈ)ЕЎЩњвдКѓЃЌЩёОЭјТчЕФЗЂеЙНјШыСЫвЛИіШШГБЁЃBPЫуЗЈЕФЗЂУїШЫжЎжаЕФвЛИіЪЧЧАУцНщЩм
ЕФЛњЦїбЇЯАДѓХЃGeoffrey Hinton(ЭМ1жаЕФжаМфеп)ЁЃ
ЯъЯИЫЕРДЃЌЩёОЭјТчЕФбЇЯАЛњРэЪЧЪВУДЃПМђЕЅРДЫЕЃЌОЭЪЧЗжНтгыећКЯЁЃдкжјУћЕФHubel-WieselЪдбщжаЃЌбЇепУЧбаОПУЈЕФЪгОѕЗжЮіЛњРэЪЧетжжЁЃ
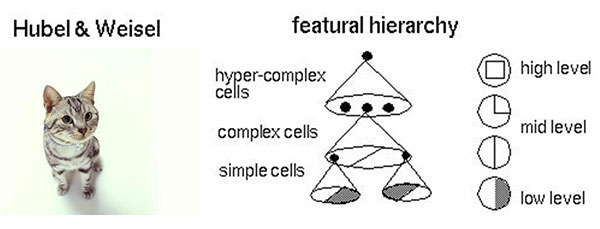
ЭМ8 Hubel-WieselЪдбщгыДѓФдЪгОѕЛњРэ
БШЗНЫЕЁЃвЛИіе§ЗНаЮЃЌЗжНтЮЊЫФИіелЯпНјШыЪгОѕДІРэЕФЯТвЛВужаЁЃЫФИіЩёОдЊЗжБ№ДІРэвЛИіелЯпЁЃУПвЛИіелЯпдйМЬајБЛЗжНтЮЊСНЬѕжБЯпЁЃУПЬѕжБЯпдйБЛЗжНтЮЊКк
АзСНИіУцЁЃгкЪЧЃЌвЛИіИДдгЕФЭМЯёБфГЩСЫДѓСПЕФЯИНкНјШыЩёОдЊЃЌЩёОдЊДІРэвдКѓдйНјааећКЯЃЌзюКѓЕУГіСЫПДЕНЕФЪЧе§ЗНаЮЕФНсТлЁЃ
етОЭЪЧДѓФдЪгОѕЪЖБ№ЕФЛњРэЃЌвВ ЪЧЩёОЭјТчЙЄзїЕФЛњРэЁЃ
ШУЮвУЧПДвЛИіМђЕЅЕФЩёОЭјТчЕФТпММмЙЙЁЃдкетИіЭјТчжаЁЃЗжГЩЪфШыВуЃЌвўВиВуЃЌКЭЪфГіВуЁЃ
ЪфШыВуИКд№НгЪеаХКХЁЃвўВиВуИКд№ЖдЪ§ОнЕФЗжНтгыДІРэЃЌзюКѓЕФ НсЙћБЛећКЯЕНЪфГіВуЁЃ
УПВужаЕФвЛИідВДњБэвЛИіДІРэЕЅдЊЁЃФмЙЛОѕЕУЪЧФЃФтСЫвЛИіЩёОдЊЃЌШєИЩИіДІРэЕЅдЊзщГЩСЫвЛИіВуЃЌШєИЩИіВудйзщГЩСЫвЛИіЭјТчЁЃвВОЭЪЧЁБЩё
ОЭјТчЁБЁЃ
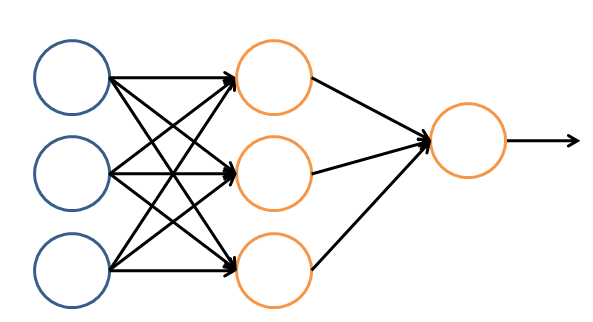
ЭМ9 ЩёОЭјТчЕФТпММмЙЙ
дкЩёОЭјТчжаЃЌУПвЛИіДІРэЕЅдЊЦфЪЕОЭЪЧвЛИіТпМЛиЙщФЃаЭЁЃТпМЛиЙщФЃаЭНгЪеЩЯВуЕФЪфШыЃЌАбФЃаЭЕФдЄyНсЙћзїЮЊЪфГіДЋЪфЕНЯТвЛИіВуДЮЁЃЭЈЙ§етжжЙ§ГЬЁЃЩёОЭјТчФмЙЛЭъБЯЗЧГЃИДдгЕФЗЧЯпадЗжРрЁЃ
ЯТЭМЛсбнЪОЩёОЭјТчдкЭМЯёЪЖБ№СьгђЕФвЛИіжјУћгІгУЁЃетИіГЬађНазіLeNetЁЃЪЧвЛИіЛљгкЖрИівўВуЙЙНЈЕФЩёОЭјТчЁЃ
ЭЈЙ§LeNetФмЙЛЪЖБ№ЖржжЪжаДЪ§зжЃЌЖјЧвДяЕНЗЧГЃИпЕФЪЖБ№ОЋЖШгыгЕгаНЯКУЕФТГАєадЁЃ
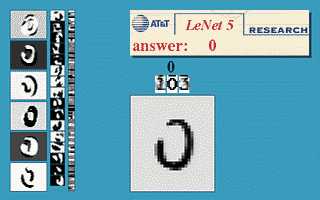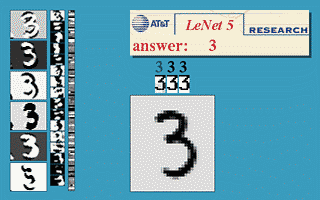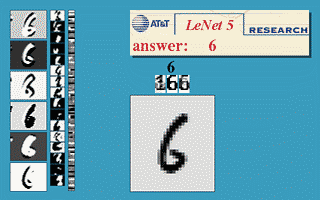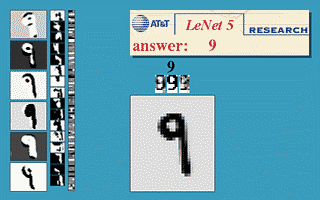
ЭМ10 LeNetЕФаЇЙћеЙЪО
гвЯТЗНЕФЗНаЮжаЯдЪОЕФЪЧЪфШыМЦЫуЛњЕФЭМЯёЁЃЗНаЮЩЯЗНЕФКьЩЋзжбљЁАanswerЁБКѓУцЯдЪОЕФЪЧМЦЫуЛњЕФЪфГіЁЃ
зѓБпЕФШ§ЬѕЪњжБЕФЭМЯёСаЯдЪОЕФЪЧЩёОЭјТч жаШ§ИівўВиВуЕФЪфГіЃЌФмЙЛПДГіЁЃЫцзХВуДЮЕФВЛЖЯЩюШыЁЃдНЩюЕФВуДЮДІРэЕФЯИНкдНЕЭЁЃБШШчВу3ЛљБОДІРэЕФЖМвбОЪЧЯпЕФЯИНкСЫЁЃ
LeNetЕФЗЂУїШЫОЭЪЧЧАЮФНщЩм Й§ЕФЛњЦїбЇЯАЕФДѓХЃYann LeCun(ЭМ1гвеп)ЁЃ
НјШы90ФъДњЃЌЩёОЭјТчЕФЗЂеЙНјШыСЫвЛИіЦПОБЦкЁЃЦфжївЊдвђЪЧЫфШЛгаBPЫуЗЈЕФМгЫйЃЌЩёОЭјТчЕФбЕСЗЙ§ГЬШдШЛЗЧГЃРЇФбЁЃ
вђДЫ90ФъДњКѓЦкжЇГжЯђСПЛњ(SVM)ЫуЗЈДњЬцСЫЩёОЭјТчЕФЕиЮЛЁЃ
SVMЃЈжЇГжЯђСПЛњЃЉ
жЇГжЯђСПЛњЫуЗЈЪЧЕЎЩњгкЭГМЦбЇЯАНчЃЌЭЌвЛЪБКђдкЛњЦїбЇЯАНчДѓЗХЙтВЪЕФОЕфЫуЗЈЁЃ
жЇГжЯђСПЛњЫуЗЈДгФГжжвтвхЩЯРДЫЕЪЧТпМЛиЙщЫуЗЈЕФЧПЛЏЃКЭЈЙ§ИјгшТпМЛиЙщЫуЗЈИќбЯИёЕФгХЛЏЬѕМўЃЌжЇГжЯђСПЛњЫуЗЈФмЙЛЛёЕУБШТпМЛиЙщИќКУЕФЗжРрНчЯпЁЃПЩЪЧМйЩшУЛгаФГРрКЏЪ§ММЪѕЃЌдђжЇГжЯђСПЛњЫуЗЈзюЖрЫуЪЧвЛжжИќКУЕФЯпадЗжРрММЪѕЁЃ
ПЩЪЧЃЌЭЈЙ§ИњИпЫЙЁАКЫЁБЕФНсКЯЃЌжЇГжЯђСПЛњФмЙЛБэДяГіЗЧГЃИДдгЕФЗжРрНчЯпЃЌДгЖјДяГЩЗЧГЃКУЕФЕФЗжРраЇЙћЁЃ
ЁАКЫЁБЦфЪЕОЭЪЧвЛжжЬиЪтЕФКЏЪ§ЃЌзюЕфаЭЕФЬиеїОЭЪЧФмЙЛНЋЕЭЮЌЕФПеМфгГЩфЕНИпЮЌЕФПеМфЁЃ
БШР§ШчвдЯТЭМЫљПДЕНЕФЃК 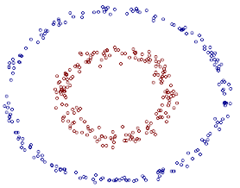
ЭМ11 жЇГжЯђСПЛњЭМР§
ЮвУЧдѕбљдкЖўЮЌЦНУцЛЎЗжГівЛИідВаЮЕФЗжРрНчЯпЃПдкЖўЮЌЦНУцПЩФмЛсЗЧГЃРЇФбЁЃПЩЪЧЭЈЙ§ЁАКЫЁБФмЙЛНЋЖўЮЌПеМфгГЩфЕНШ§ЮЌПеМфЃЌШЛКѓЪЙгУвЛИіЯпадЦНУцОЭФмЙЛ
ДяГЩЯрЫЦаЇЙћЁЃвВОЭЪЧЫЕЁЃЖўЮЌЦНУцЛЎЗжГіЕФЗЧЯпадЗжРрНчЯпФмЙЛЕШМлгкШ§ЮЌЦНУцЕФЯпадЗжРрНчЯпЁЃгкЪЧЁЃЮвУЧФмЙЛЭЈЙ§дкШ§ЮЌПеМфжаНјааМђЕЅЕФЯпадЛЎЗжОЭФмЙЛДя
ЕНдкЖўЮЌЦНУцжаЕФЗЧЯпадЛЎЗжаЇЙћЁЃ 
ЭМ12 Ш§ЮЌПеМфЕФЗжИю
жЇГжЯђСПЛњЪЧвЛжжЪ§бЇГЩЗжЗЧГЃХЈЕФЛњЦїбЇЯАЫуЗЈЃЈЯрЖдЕФЃЌЩёОЭјТчдђгаЩњЮяПЦбЇГЩЗжЃЉЁЃдкЫуЗЈЕФКЫаФВНжшжаЁЃгавЛВНжЄУїЃЌМДНЋЪ§ОнДгЕЭЮЌгГЩфЕНИпЮЌВЛ
ЛсДјРДзюКѓМЦЫуИДдгадЕФЬсЩ§ЁЃгкЪЧЃЌЭЈЙ§жЇГжЯђСПЛњЫуЗЈЃЌМШФмЙЛБЃГжМЦЫуаЇТЪЃЌгжФмЙЛЛёЕУЗЧГЃКУЕФЗжРраЇЙћЁЃвђДЫжЇГжЯђСПЛњдк90ФъДњКѓЦквЛжБеМСьзХЛњЦї
бЇЯАжазюКЫаФЕФЕиЮЛЃЌЛљБОДњЬцСЫЩёОЭјТчЫуЗЈЁЃжБЕНШчНёЩёОЭјТчНшзХЩюЖШбЇЯАгжвЛДЮаЫЦ№ЁЃСНепжЎМфВХгжЗЂЩњСЫЮЂУюЕФЦНКтзЊБфЁЃ
ОлРрЫуЗЈ
ЧАУцЕФЫуЗЈжаЕФвЛИіЯджјЬиеїОЭЪЧЮвЕФбЕСЗЪ§ОнжаАќРЈСЫБъЧЉЃЌбЕСЗГіЕФФЃаЭФмЙЛЖдЦфЫќЮДжЊЪ§ОндЄyБъЧЉЁЃдквдЯТЕФЫуЗЈжаЁЃбЕСЗЪ§ОнЖМЪЧВЛКЌБъЧЉЕФЃЌЖј
ЫуЗЈЕФФПЕФдђЪЧЭЈЙ§бЕСЗЁЃВТyГіетаЉЪ§ОнЕФБъЧЉЁЃ
етРрЫуЗЈгавЛИіЭГГЦЃЌМДЮоМрЖНЫуЗЈ(ЧАУцгаБъЧЉЕФЪ§ОнЕФЫуЗЈдђЪЧгаМрЖНЫуЗЈ)ЁЃ
ЮоМрЖНЫуЗЈжазюЕфаЭЕФДњБэ ОЭЪЧОлРрЫуЗЈЁЃ
ШУЮвУЧЛЙЪЧФУвЛИіЖўЮЌЕФЪ§ОнРДЫЕЃЌФГвЛИіЪ§ОнАќРЈСНИіЬиеїЁЃЮвЯЃЭћЭЈЙ§ОлРрЫуЗЈЁЃИјЫћУЧжаВЛЭЌЕФжжРрДђЩЯБъЧЉЃЌЮвИУдѕУДзіФиЃПМђЕЅРДЫЕЁЃОлРрЫуЗЈОЭЪЧМЦЫужжШКжаЕФОрРыЁЃвРОнОрРыЕФдЖНќНЋЪ§ОнЛЎЗжЮЊЖрИізхШКЁЃ
ОлРрЫуЗЈжазюЕфаЭЕФДњБэОЭЪЧK-MeansЫуЗЈЁЃ
НЕЮЌЫуЗЈ
НЕЮЌЫуЗЈвВЪЧвЛжжЮоМрЖНбЇЯАЫуЗЈЃЌЦфжївЊЬиеїЪЧНЋЪ§ОнДгИпЮЌНЕЕЭЕНЕЭЮЌВуДЮЁЃдкетРяЃЌЮЌЖШЦфЪЕБэЪОЕФЪЧЪ§ОнЕФЬиеїСПЕФДѓаЁЃЌБШШчЃЌЗПМлАќРЈЗПзгЕФ
ГЄЁЂПэЁЂУцЛ§гыЗПМфЪ§СПЫФИіЬиеїЁЃвВОЭЪЧЮЌЖШЮЊ4ЮЌЕФЪ§ОнЁЃФмЙЛПДГіРДЁЃГЄгыПэЦфЪЕгыУцЛ§БэЪОЕФаХЯЂжиЕўСЫЃЌБШШчУцЛ§=ГЄ
ЁС ПэЁЃЭЈЙ§НЕЮЌЫуЗЈЮвУЧОЭФмЙЛШЅГ§ШпграХЯЂЃЌНЋЬиеїНЕЕЭЮЊУцЛ§гыЗПМфЪ§СПСНИіЬиеїЃЌМДДг4ЮЌЕФЪ§ОнбЙЫѕЕН2ЮЌЁЃ
гкЪЧЮвУЧНЋЪ§ОнДгИпЮЌНЕЕЭЕНЕЭЮЌЃЌВЛНіРћгкБэ ЪОЁЃЭЌвЛЪБКђдкМЦЫуЩЯвВФмДјРДМгЫйЁЃ
ИеВХЫЕЕФНЕЮЌЙ§ГЬжаНЕЕЭЕФЮЌЖШЪєгкШтблПЩЪгЕФВуДЮЁЃЭЌвЛЪБКђбЙЫѕвВВЛЛсДјРДаХЯЂЕФЫ№ЪЇ(гЩгкаХЯЂШпгрСЫ)ЁЃ
МйЩшШтблВЛПЩЪгЃЌЛђепУЛгаШпгрЕФЬиеїЁЃНЕЮЌЫу ЗЈвВФмЙЄзїЁЃжЛЪЧетбљЛсДјРДвЛаЉаХЯЂЕФЫ№ЪЇЁЃПЩЪЧЃЌНЕЮЌЫуЗЈФмЙЛДгЪ§бЇЩЯжЄУїЁЃДгИпЮЌбЙЫѕЕНЕФЕЭЮЌжазюДѓГЬЖШЕиБЃСєСЫЪ§ОнЕФаХЯЂЁЃвђДЫЁЃЪЙгУНЕЮЌЫуЗЈШдШЛ
гаЗЧГЃЖрЕФгХЕуЁЃ
НЕЮЌЫуЗЈЕФжївЊзїгУЪЧбЙЫѕЪ§ОнгыЬсЩ§ЛњЦїбЇЯАЦфЫќЫуЗЈЕФаЇТЪЁЃЭЈЙ§НЕЮЌЫуЗЈЁЃФмЙЛНЋОпгаМИЧЇИіЬиеїЕФЪ§ОнбЙЫѕжСШєИЩИіЬиеїЁЃСэЭтЁЃНЕЮЌЫуЗЈЕФЛЙгавЛИі
гХЕуЪЧЪ§ОнЕФПЩЪгЛЏЃЌБШШчНЋ5ЮЌЕФЪ§ОнбЙЫѕжС2ЮЌЁЃШЛКѓФмЙЛгУЖўЮЌЦНУцРДПЩЪгЁЃНЕЮЌЫуЗЈЕФжївЊДњБэЪЧPCAЫуЗЈ(МДжїГЩЗжЗжЮіЫуЗЈ)ЁЃ
ЭЦМіЫуЗЈ
ЭЦМіЫуЗЈЪЧблЯТвЕНчЗЧГЃЛ№ЕФвЛжжЫуЗЈЃЌдкЕчЩЬНчЃЌШчбЧТэбЗЃЌЬьУЈЃЌОЉЖЋЕШЕУЕНСЫЙуЗКЕФдЫгУЁЃЭЦМіЫуЗЈЕФжївЊЬиеїОЭЪЧФмЙЛздМКжїЖЏЯђгУЛЇЭЦМіЫћУЧзюИааЫШЄЕФЖЋЮїЃЌДгЖјЬэМгЙКТђТЪЃЌЬсЩ§аЇвцЁЃЭЦМіЫуЗЈгаСНИіЛљБОЕФРрБ№ЃК
вЛРрЪЧЛљгкЮяЦЗФкШнЕФЭЦМіЃЌЪЧНЋгыгУЛЇЙКТђЕФФкШнНќЫЦЕФЮяЦЗЭЦМіИјгУЛЇЁЃетжжЧАЬсЪЧУПвЛИіЮяЦЗЖМЕУгаШєИЩИіБъЧЉЃЌвђДЫВХИЩЙЛевГігыгУЛЇЙКТђЮяЦЗЯрЫЦЕФЮяЦЗЃЌетбљЭЦМіЕФгХЕуЪЧЙиСЊГЬЖШНЯДѓЃЌПЩЪЧгЩгкУПвЛИіЮяЦЗЖМаывЊЬљБъЧЉЁЃвђДЫЙЄзїСПНЯДѓЁЃ
ЛЙгавЛРрЪЧЛљгкгУЛЇЯрЫЦЖШЕФЭЦМіЁЃдђЪЧНЋгыФПБъгУЛЇаЫШЄЯрЭЌЕФЦфЫќгУЛЇЙКТђЕФЖЋЮїЭЦМіИјФПБъгУЛЇЃЌБШШчаЁAРњЪЗЩЯТђСЫЮяЦЗBКЭCЃЌОЙ§ЫуЗЈЗжЮіЁЃЗЂЯжЛЙгавЛИігыаЁAНќЫЦЕФгУЛЇаЁDЙКТђСЫЮяЦЗEЃЌгкЪЧНЋЮяЦЗEЭЦМіИјаЁAЁЃ
СНРрЭЦМіЖМгаИїздЕФгХШБЕуЃЌдквЛАуЕФЕчЩЬгІгУжаЃЌЭЈГЃЪЧСНРрЛьКЯЪЙгУЁЃ
ЭЦМіЫуЗЈжазюгаУћЕФЫуЗЈОЭЪЧаЭЌЙ§ТЫЫуЗЈЁЃ
ЦфЫќ
Г§СЫвдЩЯЫуЗЈжЎЭтЃЌЛњЦїбЇЯАНчЛЙгаЦфЫќЕФШчИпЫЙХаБ№ЁЃЦгЫиБДвЖЫЙЁЃОіВпЪїЕШЕШЫуЗЈЁЃПЩЪЧЩЯУцСаЕФСљИіЫуЗЈЪЧЪЙгУзюЖрЃЌгАЯьзюЙуЁЃжжРрзюШЋЕФЕфаЭЁЃ
ЛњЦїбЇЯАНчЕФвЛИіЬиЩЋОЭЪЧЫуЗЈжкЖрЃЌЗЂеЙАйЛЈЦыЗХЁЃ
вдЯТзівЛИізмНсЁЃвРеебЕСЗЕФЪ§ОнгаЮоБъЧЉЃЌФмЙЛНЋЩЯУцЫуЗЈЗжЮЊМрЖНбЇЯАЫуЗЈКЭЮоМрЖНбЇЯАЫуЗЈЃЌЕЋЭЦМіЫуЗЈНЯЮЊЬиЪтЃЌМШВЛЪєгкМрЖНбЇЯАЃЌвВВЛЪєгкЗЧМрЖНбЇЯАЃЌЪЧЕЅЖРЕФвЛРрЁЃ
МрЖНбЇЯАЫуЗЈЃКЯпадЛиЙщЃЌТпМЛиЙщЁЃЩёОЭјТчЃЌSVM
ЮоМрЖНбЇЯАЫуЗЈЃКОлРрЫуЗЈЁЃНЕЮЌЫуЗЈ
ЬиЪтЫуЗЈЃКЭЦМіЫуЗЈ
Г§СЫетаЉЫуЗЈвдЭтЃЌгавЛаЉЫуЗЈЕФУћзждкЛњЦїбЇЯАСьгђжавВГЃГЃГіЯжЁЃЕЋЫћУЧБОЩэВЂВЛЫуЪЧвЛИіЛњЦїбЇЯАЫуЗЈЃЌЖјЪЧЮЊСЫНтОіФГИізгЮЪЬтЖјЕЎЩњЕФЁЃФуФмЙЛРэ
НтЫћУЧЮЊвдЩЯЫуЗЈЕФзгЫуЗЈЃЌгУгкДѓЗљЖШЬсИпбЕСЗЙ§ГЬЁЃ
ЕБжаЕФДњБэгаЃКЬнЖШЯТНЕЗЈЁЃжївЊдЫгУдкЯпаЭЛиЙщЁЃТпМЛиЙщЁЃЩёОЭјТчЃЌЭЦМіЫуЗЈжаЃЛХЃЖйЗЈЁЃжївЊдЫгУ дкЯпаЭЛиЙщжаЁЃBPЫуЗЈЁЃжївЊдЫгУдкЩёОЭјТчжаЁЃSMOЫуЗЈЃЌжївЊдЫгУдкSVMжаЁЃ
ЛњЦїбЇЯАЕФгІгУЈCДѓЪ§Он
ЫЕЭъЛњЦїбЇЯАЕФЗНЗЈЃЌвдЯТвЊЬИвЛЬИЛњЦїбЇЯАЕФгІгУСЫЁЃ
ЮовЩЃЌдк2010ФъдјОЃЌЛњЦїбЇЯАЕФгІгУдкФГаЉЬиЖЈСьгђЗЂЛгСЫОоДѓЕФзїгУЃЌШчГЕХЦЪЖБ№ЃЌЭјТчЙЅ ЛїЗРЗЖЃЌЪжаДзжЗћЪЖБ№ЕШЕШЁЃПЩЪЧЁЃДг2010ФъвдКѓЃЌЫцзХДѓЪ§ОнИХФюЕФаЫЦ№ЃЌЛњЦїбЇЯАДѓСПЕФгІгУЖМгыДѓЪ§ОнИпЖШёюКЯЁЃВюЕуЖљФмЙЛОѕЕУДѓЪ§ОнЪЧЛњЦїбЇЯАгІгУЕФ
зюМбГЁОАЁЃ
ЦЉШчЃЌЕЋЗВФуФмевЕНЕФНщЩмДѓЪ§ОнФЇСІЕФЮФеТЁЃЖМЛсЫЕДѓЪ§ОндѕбљзМШЗзМШЗдЄyЕНСЫФГаЉЪТЁЃ
БШШчОЕфЕФGoogleРћгУДѓЪ§ОндЄyСЫH1N1дкУРЙњФГаЁеђЕФБЌЗЂЁЃ
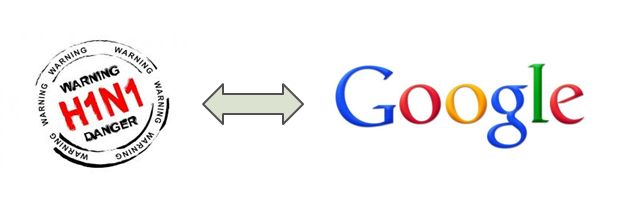
ЭМ13 GoogleГЩЙІдЄyH1N1
АйЖШдЄy2014ФъЪРНчБЁЃДгЬдЬШќЕНОіШќШЋВПдЄyе§ШЗЁЃ
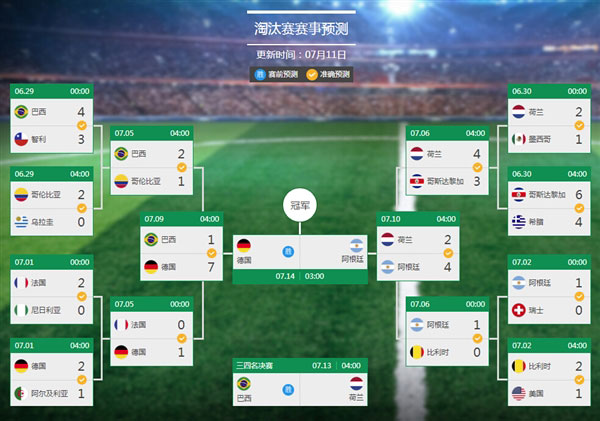
ЭМ14 АйЖШЪРНчБГЩЙІдЄyСЫШЋВПБШШќНсЙћ
етаЉЪЕдкЬЋЦцУюСЫЁЃФЧУДЕНЕзЪЧЪВУДдвђЕМжТДѓЪ§ОнОпгаетаЉФЇСІЕФФиЃПМђЕЅРДЫЕЃЌОЭЪЧЛњЦїбЇЯАММЪѕЁЃе§ЪЧЛљгкЛњЦїбЇЯАММЪѕЕФгІгУЃЌЪ§ОнВХИЩЗЂЛгЦфФЇСІЁЃ
ДѓЪ§ОнЕФКЫаФЪЧРћгУЪ§ОнЕФМлжЕЃЌЛњЦїбЇЯАЪЧРћгУЪ§ОнМлжЕЕФЙиМќММЪѕЃЌЖдгкДѓЪ§ОнЖјбдЃЌЛњЦїбЇЯАЪЧВЛПЩЛђШБЕФЁЃЯрЗДЁЃЖдгкЛњЦїбЇЯАЖјбдЁЃдНЖрЕФЪ§ОнЛс
дН ПЩФмЬсЩ§ФЃаЭЕФОЋШЗадЃЌЭЌвЛЪБКђЃЌИДдгЕФЛњЦїбЇЯАЫуЗЈЕФМЦЫуЪБМфвВЦШЧааывЊЗжВМЪНМЦЫугыФкДцМЦЫуетжжЙиМќММЪѕЁЃвђДЫЃЌЛњЦїбЇЯАЕФаЫЭњвВРыВЛПЊДѓЪ§ОнЕФАяжњЁЃ
ДѓЪ§ОнгыЛњЦїбЇЯАСНепЪЧЛЅЯрДйНјЃЌЯрвРЯрДцЕФЙиЯЕЁЃ
ЛњЦїбЇЯАгыДѓЪ§ОнНєУмСЊЯЕЁЃ
ПЩЪЧЃЌБиаыЧхабЕФШЯЪЖЕНЁЃДѓЪ§ОнВЂВЛЕШЭЌгкЛњЦїбЇЯАЃЌЭЌРэЁЃЛњЦїбЇЯАвВВЛЕШЭЌгкДѓЪ§ОнЁЃДѓЪ§ОнжаАќРЈгаЗжВМЪНМЦЫуЃЌФкДцЪ§ОнПтЃЌЖрЮЌЗжЮіЕШЕШЖржжММЪѕЁЃЕЅДгЗжЮіЗНЗЈРДПДЃЌДѓЪ§ОнвВАќРЈвдЯТЫФжжЗжЮіЗНЗЈЃК
1.ДѓЪ§ОнЃЌаЁЗжЮіЃКМДЪ§ОнВжПтСьгђЕФOLAPЗжЮіЫМТЗЁЃвВОЭЪЧЖрЮЌЗжЮіЫМЯыЁЃ
2.ДѓЪ§ОнЁЃДѓЗжЮіЃКетИіДњБэЕФОЭЪЧЪ§ОнЭкОђгыЛњЦїбЇЯАЗжЮіЗЈЁЃ
3.СїЪНЗжЮіЃКетИіжївЊжИЕФЪЧЪТМўЧ§ЖЏМмЙЙЁЃ
4.ВщбЏЗжЮіЃКОЕфДњБэЪЧNoSQLЪ§ОнПтЁЃ
вВОЭЪЧЫЕЃЌЛњЦїбЇЯАНіНіЪЧДѓЪ§ОнЗжЮіжаЕФвЛжжЖјвбЁЃЫфШЛЛњЦїбЇЯАЕФвЛаЉНсЙћОпгаЗЧГЃДѓЕФФЇСІЁЃдкФГжжГЁКЯЯТЪЧДѓЪ§ОнМлжЕзюКУЕФЫЕУїЁЃ
ЕЋетВЂВЛДњБэЛњЦїбЇЯАЪЧДѓЪ§ОнЯТЕФЮЈвЛЕФЗжЮіЗНЗЈЁЃ
ЛњЦїбЇЯАгыДѓЪ§ОнЕФНсКЯВњЩњСЫОоДѓЕФМлжЕЁЃЛљгкЛњЦїбЇЯАММЪѕЕФЗЂеЙЁЃЪ§ОнФмЙЛЁАдЄyЁБЁЃЖдШЫРрЖјбдЃЌЛ§РлЕФОбщдНЗсИЛЃЌдФРњвВЙуЗКЃЌЖдЮДРДЕФЭЦЖЯдН
зМШЗЁЃБШШчГЃЫЕЕФЁАОбщЗсИЛЁБЕФШЫБШЁАГѕГіУЉТЎЁБЕФаЁЛязгИќгаЙЄзїЩЯЕФгХЪЦЃЌОЭдкгкОбщЗсИЛЕФШЫЛёЕУЕФЙцТЩБШЫћШЫИќзМШЗЁЃ
ЖјдкЛњЦїбЇЯАСьгђЁЃвРОнжјУћЕФвЛ ИіЪЕбщЁЃгааЇЕФжЄЪЕСЫЛњЦїбЇЯАНчвЛИіРэТлЃКМДЛњЦїбЇЯАФЃаЭЕФЪ§ОндНЖрЃЌЛњЦїбЇЯАЕФдЄyЕФаЇТЪОЭдНКУЁЃ
МћЯТЭМЃК
ЭМ15 ЛњЦїбЇЯАзМШЗТЪгыЪ§ОнЕФЙиЯЕ
ЭЈЙ§етеХЭМФмЙЛПДГіЃЌИїжжВЛЭЌЫуЗЈдкЪфШыЕФЪ§ОнСПДяЕНвЛЖЈМЖЪ§КѓЃЌЖМгаЯрНќЕФИпОЋШЗЖШЁЃгкЪЧЕЎЩњСЫЛњЦїбЇЯАНчЕФУћбдЃКГЩЙІЕФЛњЦїбЇЯАгІгУВЛЪЧгЕгазюКУЕФЫуЗЈЃЌЖјЪЧгЕгазюЖрЕФЪ§ОнЁЃ
дкДѓЪ§ОнЕФЪБДњЁЃгаКУЖргХЪЦДйЪЙЛњЦїбЇЯАФмЙЛгІгУИќЙуЗКЁЃ
БШШчЫцзХЮяСЊЭјКЭвЦЖЏЩшБИЕФЗЂеЙЁЃЮвУЧгЕгаЕФЪ§ОндНРДдНЖрЃЌжжРрвВАќРЈЭМЦЌЁЂЮФБОЁЂЪгЦЕЕШ ЗЧНсЙЙЛЏЪ§ОнЃЌетЪЙЕУЛњЦїбЇЯАФЃаЭФмЙЛЛёЕУдНРДдНЖрЕФЪ§ОнЁЃ
ЭЌвЛЪБКђДѓЪ§ОнММЪѕжаЕФЗжВМЪНМЦЫуMap-ReduceЪЙЕУЛњЦїбЇЯАЕФЫйЖШдНРДдНПьЃЌФмЙЛИќЗНБуЕФ ЪЙгУЁЃжжжжгХЪЦЪЙЕУдкДѓЪ§ОнЪБДњЃЌЛњЦїбЇЯАЕФгХЪЦФмЙЛЕУЕНзюМбЕФЗЂЛгЁЃ
ЛњЦїбЇЯАЕФзгРрЈCЩюЖШбЇЯА
НќРДЃЌЛњЦїбЇЯАЕФЗЂеЙВњЩњСЫвЛИіаТЕФЗНЯђЃЌМДЁАЩюЖШбЇЯАЁБЁЃ
ЫфШЛЩюЖШбЇЯАетЫФзжЬ§Ц№РДЦФЮЊИпДѓЩЯЁЃЕЋЦфРэФюШДЗЧГЃeasyЃЌОЭЪЧДЋЭГЕФЩёОЭјТчЗЂеЙЕНСЫЖрвўВиВуЕФЧщПіЁЃ
дкЩЯЮФНщЩмЙ§ЃЌздДг90ФъДњвдКѓЃЌЩёОЭјТчвбОЯћМХСЫвЛЖЮЪБМфЁЃПЩЪЧBPЫуЗЈЕФЗЂУїШЫGeoffrey
HintonвЛжБУЛгаЗХЦњЖдЩёОЭјТчЕФбаОПЁЃгЩгкЩёОЭјТчдквўВиВуРЉДѓЕНСНИівдЩЯЁЃЦфбЕСЗЫйЖШОЭЛсЗЧГЃТ§ЃЌвђДЫгагУадвЛжБЕЭгкжЇГжЯђСПЛњЁЃ
2006 ФъЃЌGeoffrey HintonдкПЦбЇдгжОЁЖScienceЁЗЩЯЗЂБэСЫвЛЦЊЮФеТЃЌТлжЄСЫСНИіЙлЕуЃК
1.ЖрвўВуЕФЩёОЭјТчОпгагХвьЕФЬиеїбЇЯАФмСІЃЌбЇЯАЕУЕНЕФЬиеїЖдЪ§ОнгаИќБОжЪЕФПЬЛЁЃДгЖјгаРћгкПЩЪгЛЏЛђЗжРрЁЃ
2.ЩюЖШЩёОЭјТчдкбЕСЗЩЯЕФФбЖШЃЌФмЙЛЭЈЙ§ЁАж№ВуГѕЪМЛЏЁБ РДгааЇПЫЗўЁЃ

ЭЈЙ§етжжЗЂЯжЃЌВЛНіЙЅПЫСЫЩёОЭјТчдкМЦЫуЩЯЕФФбЖШЃЌЭЌвЛЪБКђвВЫЕУїСЫЩюВуЩёОЭјТчдкбЇЯАЩЯЕФгХвьадЁЃДгДЫЃЌЩёОЭјТчгжвЛДЮГЩЮЊСЫЛњЦїбЇЯАНчжаЕФжїСїЧПДѓбЇЯАММЪѕЁЃЭЌвЛЪБКђЁЃОпгаЖрИівўВиВуЕФЩёОЭјТчБЛГЦЮЊЩюЖШЩёОЭјТчЁЃЛљгкЩюЖШЩёОЭјТчЕФбЇЯАбаОПГЦжЎЮЊЩюЖШбЇЯАЁЃ
гЩгкЩюЖШбЇЯАЕФживЊаджЪЃЌдкИїЗНУцЖМШЁЕУМЋДѓЕФЙизЂЃЌвРееЪБМфжсХХађЃЌгавдЯТЫФИіБъжОадЪТМўжЕЕУвЛЫЕЃК
2012Фъ6дТЁЃЁЖХІдМЪББЈЁЗХћТЖСЫGoogle BrainЯюФПЁЃетИіЯюФПЪЧгЩAndrew
NgКЭMap-ReduceЗЂУїШЫJeff DeanЙВЭЌжїЕМЁЃгУ16000ИіCPU CoreЕФВЂааМЦЫуЦНЬЈбЕСЗвЛжжГЦЮЊЁАЩюВуЩёОЭјТчЁБЕФЛњЦїбЇЯАФЃаЭЁЃдкгявєЪЖБ№КЭЭМЯёЪЖБ№ЕШСьгђЛёЕУСЫОоДѓЕФГЩЙІЁЃAndrew
NgОЭЪЧЮФеТщ_ЪМЫљНщЩмЕФЛњЦїбЇЯАЕФДѓХЃ(ЭМ1жагвеп)ЁЃ
2012Фъ11дТЃЌЮЂШэдкжаЙњЬьНђЕФвЛДЮЛюЖЏЩЯЙЋПЊбнЪОСЫвЛИіШЋздМКжїЖЏЕФЭЌЩљДЋвыЯЕЭГЃЌНВбнепгУгЂЮФбнНВЁЃКѓЬЈЕФМЦЫуЛњвЛЦјКЧГЩздМКжїЖЏЭъБЯгявєЪЖБ№ЁЂгЂжаЛњЦїЗвыЁЃвдМАжаЮФгявєКЯГЩЁЃаЇЙћЗЧГЃСїГЉЃЌЕБжажЇГХЕФЙиМќММЪѕЪЧЩюЖШбЇЯАЃЛ
2013Фъ1дТЁЃдкАйЖШЕФФъЛсЩЯЁЃДДЪМШЫМцCEOРюбхКъИпЕїаћВМвЊГЩСЂАйЖШбаОПдКЃЌЕБжаЕквЛИіжиЕуЗНЯђОЭЪЧЩюЖШбЇЯАЃЌВЂЮЊДЫЖјГЩСЂЩюЖШбЇЯАбаОПдК(IDL)ЁЃ

ЭМ17 ЩюЖШбЇЯАЕФЗЂеЙШШГБ
ЮФеТПЊЭЗЫљСаЕФШ§ЮЛЛњЦїбЇЯАЕФДѓХЃЃЌВЛНіЖМЪЧЛњЦїбЇЯАНчЕФзЈМвЃЌИќЪЧЩюЖШбЇЯАбаОПСьгђЕФЯШЧ§ЁЃвђДЫЃЌЪЙЫћУЧЕЃШЮИїИіДѓаЭЛЅСЊЭјЙЋЫОММЪѕеЦЖцепЕФдвђВЛНідкгкЫћУЧЕФММЪѕЪЕСІЃЌИќдкгкЫћУЧбаОПЕФСьгђЪЧЧАОАЮоЯоЕФЩюЖШбЇЯАММЪѕЁЃ
блЯТвЕНчКмЖрЕФЭМЯёЪЖБ№ММЪѕгыгявєЪЖБ№ММЪѕЕФНјВНЖМдДгкЩюЖШбЇЯАЕФЗЂеЙЁЃГ§СЫБОЮФПЊЭЗЫљЬсЕФCortanaЕШгявєжњЪжЃЌЛЙАќРЈвЛаЉЭМЯёЪЖБ№гІгУЁЃЕБжаЕфаЭЕФДњБэОЭЪЧЯТЭМЕФАйЖШЪЖЭМЙІФмЁЃ
ЭМ18 АйЖШЪЖЭМ
ЩюЖШбЇЯАЪєгкЛњЦїбЇЯАЕФзгРрЁЃЛљгкЩюЖШбЇЯАЕФЗЂеЙМЋДѓЕФДйНјСЫЛњЦїбЇЯАЕФЕиЮЛЬсИпЁЃИќНјвЛВНЕиЃЌЭЦЖЏСЫвЕНчЖдЛњЦїбЇЯАИИРрШЫЙЄжЧФмУЮЯыЕФдйДЮжиЪгЁЃ
ЛњЦїбЇЯАЕФИИРрЈCШЫЙЄжЧФм
ШЫЙЄжЧФмЪЧЛњЦїбЇЯАЕФИИРрЁЃЩюЖШбЇЯАдђЪЧЛњЦїбЇЯАЕФзгРрЁЃ
МйЩшАбШ§епЕФЙиЯЕгУЭМРДБэУїЕФЛАЃЌдђЪЧЯТЭМЃК
ЭМ19 ЩюЖШбЇЯАЁЂЛњЦїбЇЯАЁЂШЫЙЄжЧФмШ§епЙиЯЕ
КСЮовЩЮЪЃЌШЫЙЄжЧФм(AI)ЪЧШЫРрЫљФмЯыЯѓЕФПЦММНчзюЭЛЦЦадЕФЗЂУїСЫЃЌФГжжвтвхЩЯРДЫЕЁЃШЫЙЄжЧФмОЭЯёгЮЯЗзюжеЛУЯыЕФУћзжвЛбљЃЌЪЧШЫРрЖдгкПЦММНчЕФзю
жеУЮЯыЁЃДг50ФъДњЬсГіШЫЙЄжЧФмЕФРэФювдКѓЃЌПЦММНчЃЌВњвЕНчВЛЖЯдкЬНЫїЃЌбаОПЁЃетЖЮЪБМфИїжжаЁЫЕЁЂЕчгАЖМдквдИїжжЗНЪНеЙЯжЖдгкШЫЙЄжЧФмЕФЯыЯѓЁЃШЫРрФмЙЛЗЂ
УїЯрЫЦгкШЫРрЕФЛњЦїЃЌетЪЧЖрУДЮАДѓЕФвЛжжРэФюЁЃЕЋЦфЪЕЁЃздДг50ФъДњвдКѓЃЌШЫЙЄжЧФмЕФЗЂеЙОЭПФПФХіХіЁЃЮДгаМћЕНзуЙЛе№КГЕФПЦбЇММЪѕЕФНјВНЁЃ
змНсЦ№РДЁЃШЫЙЄжЧФмЕФЗЂеЙОРњСЫР§ШчвдЯТШєИЩНзЖЮЃЌДгдчЦкЕФТпМЭЦРэЃЌЕНжаЦкЕФзЈМвЯЕЭГЁЃетаЉПЦбаНјВНШЗЪЕЪЙЮвУЧРыЛњЦїЕФжЧФмгаЕуНгНќСЫЃЌЕЋЛЙгавЛДѓЖЮ
ОрРыЁЃжБЕНЛњЦїбЇЯАЕЎЩњвдКѓЁЃШЫЙЄжЧФмНчИаОѕзюжеевЖдСЫЗНЯђЁЃ
ЛљгкЛњЦїбЇЯАЕФЭМЯёЪЖБ№КЭгявєЪЖБ№дкФГаЉДЙжБСьгђДяЕНСЫИњШЫЯрцЧУРЕФГЬЖШЁЃЛњЦїбЇЯАЪЙШЫРрЕк вЛДЮШчДЫНгНќШЫЙЄжЧФмЕФУЮЯыЁЃ
ЦфЪЕЃЌМйЩшЮвУЧАбШЫЙЄжЧФмЯрЙиЕФММЪѕвдМАЦфЫќвЕНчЕФММЪѕзівЛИіРрБШЁЃОЭФмЙЛЗЂЯжЛњЦїбЇЯАдкШЫЙЄжЧФмжаЕФживЊЕиЮЛВЛЪЧУЛгаРэгЩЕФЁЃ
ШЫРрВюБ№гкЦфЫќЮяЬхЁЃжВЮяЃЌЖЏЮяЕФзюжївЊВюБ№ЃЌзїепОѕЕУЪЧЁАжЧЛлЁБЁЃЖјжЧЛлЕФзюМбЬхЯжЪЧЪВУДЃП
ЪЧМЦЫуФмСІУДЃЌгІИУВЛЪЧЁЃаФЫуЫйЖШПьЕФШЫЮвУЧвЛАуГЦжЎЮЊЬьВХЁЃ
ЪЧЗДгІФмСІУДЃЌвВВЛЪЧЃЌЗДгІПьЕФШЫЮвУЧГЦжЎЮЊСщУєЁЃ
ЪЧМЧвфФмСІУДЃЌвВВЛЪЧЃЌМЧвфКУЕФШЫЮвУЧвЛАуГЦжЎЮЊЙ§ФПВЛЭќЁЃ
ЪЧЭЦРэФмСІУДЁЃетжжШЫЮвЛђаэЛсГЦЫћжЧСІЗЧГЃИпЃЌЯрЫЦЁАИЃЖћФІЫЙЁБЃЌЕЋВЛЛсГЦЫћгЕгажЧЛлЁЃ
ЪЧжЊЪЖФмСІУДЃЌетжжШЫЮвУЧГЦжЎЮЊВЉЮХЙуЃЌвВВЛЛсГЦЫћгЕгажЧЛлЁЃ
ЯыЯыПДЮвУЧвЛАуаЮШнЫгаДѓжЧЛлЃПЪЅШЫЃЌжюШчзЏзгЃЌРЯзгЕШЁЃжЧЛлЪЧЖдЩњЛюЕФИаЮђЁЃЪЧЖдШЫЩњЕФЛ§ЕэгыЫМПМЃЌетгыЮвУЧЛњЦїбЇЯАЕФЫМЯыКЮЦфЯрЫЦЃПЭЈЙ§ОбщЛёШЁЙцТЩЃЌжИЕМШЫЩњгыЮДРДЁЃ
УЛгаОбщОЭУЛгажЧЛлЁЃ
етРяаДЭМЦЌУшаДа№Ъі

ЭМ20 ЛњЦїбЇЯАгыжЧЛл
ФЧУДЃЌДгМЦЫуЛњРДПДЃЌвдЩЯЕФжжжжФмСІЖМгажжжжММЪѕШЅгІЖдЁЃ
БШШчМЦЫуФмСІЮвУЧгаЗжВМЪНМЦЫуЁЃЗДгІФмСІЮвУЧгаЪТМўЧ§ЖЏМмЙЙЃЌМьЫїФмСІЮвУЧгаЫбЫїв§ЧцЃЌжЊЪЖДцДЂФмСІЮвУЧгаЪ§ОнВжПтЃЌТпМЭЦРэФмСІЮвУЧгазЈМвЯЕЭГЃЌПЩЪЧЃЌЮЈгаЯргІжЧЛлжазюЯджјЬиеїЕФЙщФЩгыИаЮђФмСІЁЃНіНігаЛњЦїбЇЯАгыжЎЯргІЁЃетвВЪЧЛњЦїбЇЯАФмСІзюФмБэеїжЧЛлЕФИљБОдвђЁЃ
ШУЮвУЧдйПДвЛЯТЛњЦїШЫЕФжЦдьЃЌдкЮвУЧОпгаСЫЧПДѓЕФМЦЫуЃЌКЃСПЕФДцДЂЃЌИпЫйЕФМьЫїЁЃбИЫйЕФЗДгІЃЌгХауЕФТпМЭЦРэКѓЮвУЧМйЩшдйХфКЯЩЯвЛИіЧПДѓЕФжЧЛлДѓФдЃЌвЛИіеце§втвхЩЯЕФШЫЙЄжЧФмЛђаэОЭЛсЕЎЩњЃЌетвВЪЧЮЊЪВУДЫЕдкЛњЦїбЇЯАИпЫйЗЂеЙЕФШчНёЃЌШЫЙЄжЧФмПЩФмВЛдйЪЧУЮЯыЕФдвђЁЃ
ШЫЙЄжЧФмЕФЗЂеЙПЩФмВЛНіШЁОігкЛњЦїбЇЯАЁЃИќШЁОігкЧАУцЫљНщЩмЕФЩюЖШбЇЯАЃЌЩюЖШбЇЯАММЪѕгЩгкЩюЖШФЃФтСЫШЫРрДѓФдЕФЙЙГЩЃЌдкЪгОѕЪЖБ№гыгявєЪЖБ№ЩЯЯджјад
ЕФЭЛЦЦСЫдгаЛњЦїбЇЯАММЪѕЕФНчЯоЃЌвђДЫМЋгаПЩФмЪЧеце§ЪЕЯжШЫЙЄжЧФмУЮЯыЕФЙиМќММЪѕЁЃВЛЙмЪЧЙШИшДѓФдЛЙЪЧАйЖШДѓФдЃЌЖМЪЧЭЈЙ§КЃСПВуДЮЕФЩюЖШбЇЯАЭјТчЫљЙЙГЩ
ЕФЁЃ
ЛђаэНшжњгкЩюЖШбЇЯАММЪѕЃЌдкВЛдЖЕФНЋРДЃЌвЛИіОпгаШЫРржЧФмЕФМЦЫуЛњецЕФгаПЩФмЪЕЯжЁЃ
зюКѓдйЫЕвЛЯТЬтЭтЛАЁЃгЩгкШЫЙЄжЧФмНшжњгкЩюЖШбЇЯАММЪѕЕФИпЫйЗЂеЙЁЃвбОдкФГаЉЕиЗНв§Ц№СЫДЋЭГММЪѕНчДяШЫЕФЕЃгЧЁЃецЪЕЪРНчЕФЁАИжЬњЯРЁБЁЃЬиЫЙРCEO
ТэЫЙПЫОЭЪЧЕБжажЎжаЕФвЛИіЁЃ
НќЦкТэЫЙПЫдк
ЂМгMITЬжТлЛсЪБЁЃОЭБэДяСЫЖдгкШЫЙЄжЧФмЕФЕЃгЧЁЃЁАШЫЙЄжЧФмЕФбаОПОЭЯрЫЦгкейЛНЖёФЇЁЃЮвУЧБиаыдкФГаЉЕиЗНМгЧПзЂвтЁЃЁБ

ЭМ21 ТэЫЙПЫгыШЫЙЄжЧФм
ЫфШЛТэЫЙПЫЕФВйаФгааЉЮЃбдЫЪЬ§ЁЃПЩЪЧТэЫЙПЫЕФЭЦРэВЛЮоЕРРэЁЃ
ЁАМйЩшШЫЙЄжЧФмЯывЊЯћГ§РЌЛјгЪМўЕФЛАЁЃПЩФмЫќзюКѓЕФОіЖЈОЭЪЧЯћУ№ШЫРрЁЃЁБТэЫЙПЫОѕЕУдЄЗР ДЫРрЯжЯѓЕФЗНЗЈЪЧв§ШыеўИЎЕФМрЙмЁЃдкетРязїепЕФЙлЕугыТэЫЙПЫЯрЫЦЃЌдкШЫЙЄжЧФмЕЎЩњжЎГѕОЭИјЦфМгЩЯШєИЩЙцдђЯожЦПЩФмгааЇЃЌвВОЭЪЧВЛгІИУЪЙгУЕЅДПЕФЛњЦїбЇЯАЃЌ
ЖјгІИУЪЧЛњЦїбЇЯАгыЙцдђв§ЧцЕШЯЕЭГЕФзлКЯФмЙЛНЯКУЕФНтОіетРрЮЪЬтЁЃгЩгкМйЩшбЇЯАУЛгаЯожЦЃЌМЋгаПЩФмНјШыФГИіЮѓЧјЃЌБиаывЊМгЩЯФГаЉв§ЕМЁЃе§ШчШЫРрЩчЛсжаЃЌЗЈ
ТЩОЭЪЧвЛИізюКУЕФЙцдђЃЌЩБШЫепЫРОЭЪЧЖдгкШЫРрдкЬНЫїЬсИпЩњВњСІЪБВЛПЩгтдНЕФНчЯоЁЃ
дкетРяЃЌБиаыЬсвЛЯТетРяЕФЙцдђгыЛњЦїбЇЯАв§ГіЕФЙцТЩЕФВЛЭЌЃЌЙцТЩВЛЪЧвЛИібЯИёвтвхЕФзМдђЃЌЦфДњБэЕФКмЖрЦфЫќЪЧИХТЪЩЯЕФжИЕМЁЃЖјЙцдђдђЪЧЩёЪЅВЛПЩЧжЗИЃЌВЛПЩИФЖЏЕФЁЃЙцТЩФмЙЛЕїећЁЃЕЋЙцдђЪЧВЛФмИФБфЕФЁЃгааЇЕФНсКЯЙцТЩгыЙцдђЕФЬиЕуЃЌФмЙЛв§ЕМГівЛИіКЯРэЕФЁЃПЩПиЕФбЇЯАаЭШЫЙЄжЧФмЁЃ
ЛњЦїбЇЯАЕФЫМПМЈCМЦЫуЛњЕФЧБвтЪЖ
зюКѓЁЃзїепЯыЬИвЛЬИЙигкЛњЦїбЇЯАЕФвЛаЉЫМПМЁЃ
жївЊЪЧзїепдкШеГЃЩњЛюзмНсГіРДЕФвЛаЉИаЮђЁЃ
ЛиЯывЛЯТЮвдкНк1РяЫљЫЕЕФЙЪЪТЁЃЮвАбаЁYЙ§ЭљИњЮвЯрдМЕФОРњзіСЫвЛИіТоСаЁЃПЩЪЧетжжТоСавдЭљШЋВПОРњЕФЗНЗЈНіНігаЩйЪ§ШЫЛсетУДзіЁЃДѓВПЗжЕФШЫёгУЕФЪЧ
ИќжБНгЕФЗНЗЈЃЌМДРћгУжБОѕЁЃФЧУДЃЌжБОѕЪЧЪВУДЃПЦфЪЕжБОѕвВЪЧФудкЧБвтЪЖзДЬЌЯТЫМПМОбщКѓЕУГіЕФЙцТЩЁЃОЭЯёФуЭЈЙ§ЛњЦїбЇЯАЫуЗЈЁЃЕУЕНСЫвЛИіФЃаЭЃЌФЧУДФуЯТДЮ
НіНівЊжБНгЪЙгУМДПЩСЫЁЃФЧУДетИіЙцТЩФуЪЧЪВУДЪБКђЫМПМЕФЃППЩФмЪЧдкФуЮовтЪЖЕФЧщПіЯТЃЌБШШчЫЏОѕЃЌзпТЗЕШЧщПіЁЃетжжЪБКђЃЌДѓФдЦфЪЕвВдкФЌФЌЕизівЛаЉФуВьОѕВЛЕН
ЕФЙЄзїЁЃ
етжжжБОѕгыЧБвтЪЖЃЌЮвАбЫќгыЛЙгавЛжжШЫРрЫМПМОбщЕФЗНЪНзіСЫЧјЗжЁЃ
МйЩшвЛИіШЫЧкгкЫМПМЃЌБШШчЫћЛсУПЬьзівЛИіаЁНсЃЌЦЉШчЁАЮсШеШ§ЪЁЮсЩэЁБЁЃЛђепЫћГЃГЃгы ЭЌАщЬжТлНќЦкЙЄзїЕФЕУЪЇЃЌФЧУДЫћетжжбЕСЗФЃаЭЕФЗНЪНЪЧжБНгЕФЃЌУївтЪЖЕФЫМПМгыЙщФЩЁЃетжжаЇЙћЗЧГЃКУЁЃМЧвфадЧПЁЃЖјЧвИќФмЕУГігааЇЗДгІЯжЪЕЕФЙцТЩЁЃПЩЪЧДѓВП
ЗжЕФШЫПЩФмЗЧГЃЩйзіетжжзмНсЁЃФЧУДЫћУЧЕУГіЩњЛюжаЙцТЩЕФЗНЗЈЪЙгУЕФОЭЪЧЧБвтЪЖЗЈЁЃ
ОйвЛИізїепБОШЫЙигкЧБвтЪЖЕФбљР§ЁЃзїепБОШЫдјОУЛПЊЙ§ГЕЃЌНќЦквЛЖЮЪБМфТђСЫГЕКѓЃЌЬьЬьПЊГЕЩЯАрЁЃ
ЮвУПЬьЖМзпЙЬЖЈЕФТЗЯпЁЃгаШЄЕФЪЧЁЃдквЛщ_ЪМЕФМИЬьЃЌ ЮвЗЧГЃНєеХЕФзЂвтзХЧАЗНЕФТЗПіЃЌЖјШчНёЮввбОдкЮовтЪЖжаОЭАбГЕПЊЕНСЫФПБъЁЃетИіЙ§ГЬжаЮвЕФблОІЪЧзЂЪгзХЧАЗНЕФЁЃЮвЕФДѓФдЪЧУЛгаЫМПМЃЌПЩЪЧЮвЪжЮезХЕФЗНЯђХЬ
ЛсздМКжїЖЏЕФЕїећЗНЯђЁЃвВОЭЪЧЫЕЁЃЫцзХЮвПЊГЕДЮЪ§ЕФдіЖрЃЌЮввбОАбЮвПЊГЕЕФЖЏзїНЛИјСЫЧБвтЪЖЁЃетЪЧЗЧГЃгаШЄЕФвЛМўЪТЁЃдкетЖЮЙ§ГЬжаЃЌЮвЕФДѓФдНЋЧАЗНТЗПіЕФЭМЯё
МЧТМСЫЯТРДЃЌЭЌвЛЪБКђДѓФдвВМЧвфСЫЮвзЊЖЏЗНЯђХЬЕФЖЏзїЁЃОЙ§ДѓФдздМКЕФЧБвтЪЖЫМПМЃЌзюКѓЩњГЩЕФЧБвтЪЖФмЙЛжБНгвРОнЧАЗНЕФЭМЯёЕїећЮвЪжЕФЖЏзїЁЃ
МйЩшЮвУЧНЋЧАЗНЕФ ТМЯёНЛИјМЦЫуЛњЃЌШЛКѓШУМЦЫуЛњМЧТМгыЭМЯёЯргІЕФМнЪЛдБЕФЖЏзїЁЃ
ОЙ§вЛЖЮЪБМфЕФбЇЯАЃЌМЦЫуЛњЩњГЩЕФЛњЦїбЇЯАФЃаЭОЭФмЙЛНјааздМКжїЖЏМнЪЛСЫЁЃетЗЧГЃЦцУюЃЌВЛЪЧУДЁЃЦф ЪЕАќРЈGoogleЁЂЬиЫЙРдкФкЕФздМКжїЖЏМнЪЛЦћГЕММЪѕЕФдРэОЭЪЧетбљЁЃ
Г§СЫздМКжїЖЏМнЪЛЦћГЕвдЭтЃЌЧБвтЪЖЕФЫМЯыЛЙФмЙЛРЉеЙЕНШЫЕФНЛМЪЁЃ
ЦЉШчЫЕЗўБ№ШЫЁЃвЛИізюМбЕФЗНЗЈОЭЪЧИјЫћеЙЪОвЛаЉаХЯЂЃЌШЛКѓШУЫћздМКШЅЙщФЩЕУГіЮвУЧЯывЊЕФ НсТлЁЃетОЭКУБШдкВћЪівЛИіЙлЕуЪБЃЌгУвЛИіЪТЪЕЃЌЛђепвЛИіЙЪЪТЃЌБШДѓЖЮЕФЕРРэвЊКУЗЧГЃЖрЁЃЙХЭљНёРДЁЃЕЋЗВгХауЕФЫЕПЭЃЌЮоВЛёгУЕФЪЧетжжЗНЗЈЁЃ
ДКЧяеНЙњЪБЦкЁЃИї ЙњКЯзнСЌКсЃЌГЃГЃгаИїжжЫЕПЭШЅИњвЛЙњжЎО§НЛСїЃЌжБНгИцЫпО§жїИУзіЪВУДЃЌЮовьгкздбАЫРТЗЃЌПЩЪЧИњО§жїНВЙЪЪТЃЌЭЈЙ§етаЉЙЪЪТШУО§жїЛаШЛДѓЮђЁЃОЭЪЧвЛжже§ШЗЕФЙ§
ГЬЁЃ
етРяУцгаКмЖрНмГіЕФДњБэЃЌШчФЋзгЃЌЫеЧиЕШЕШЁЃ
ЛљБОЩЯШЋВПЕФНЛСїЙ§ГЬЃЌЪЙгУЙЪЪТЫЕУїЕФаЇЙћЖМвЊдЖЪЄгкВћЪіЕРвхжЎРрЕФаЇЙћКУЗЧГЃЖрЁЃЮЊЪВУДгУЙЪЪТЕФЗНЗЈБШЕРРэЛђепЦфЫќЕФЗНЗЈКУЗЧГЃЖрЃЌетЪЧгЩгкдкШЫГЩГЄ
ЕФЙ§ГЬЃЌОЙ§здМКЕФЫМПМЃЌвбОаЮГЩСЫЗЧГЃЖрЙцТЩгыЧБвтЪЖЁЃМйЩшФуИцЫпЕФЙцТЩгыЖдЗНЕФВЛЯрЗћЃЌЗЧГЃгаПЩФмГігкБЃЛЄЁЃЫћУЧЛсБОФмЕФОмОјФуЕФаТЙцТЩЃЌПЩЪЧМйЩшФуИњЫћ
НВвЛИіЙЪЪТЃЌДЋЕнвЛаЉаХЯЂЃЌЪфЫЭвЛаЉЪ§ОнИјЫћЃЌЫћЛсЫМПМВЂздЮвИФБфЁЃ
ЫћЕФЫМПМЙ§ГЬЪЕМЪЩЯОЭЪЧЛњЦїбЇЯАЕФЙ§ГЬЃЌЫћАбаТЕФЪ§ОнФЩШыЕНЫћЕФОЩгаЕФМЧвфгыЪ§ОнжаЁЃ ОЙ§гжвЛДЮбЕСЗЁЃ
МйЩшФуИјГіЕФЪ§ОнЕФаХЯЂСПЗЧГЃДѓЃЌДѓЕНЕїећСЫЫћЕФФЃаЭЃЌФЧУДЫћОЭЛсвРееФуЯЃЭћЕФЙцТЩШЅзіЪТЁЃгаЕФЪБКђЃЌЫћЛсБОФмЕФОмОјдЫааетИіЫМПМЙ§ГЬЁЃЕЋ
ЪЧЪ§ОнвЛЕЉЪфШыЁЃВЛЙмЫћЯЃЭћгыЗёЁЃЫћЕФДѓФдЖМЛсдкЧБвтЪЖзДЬЌЯТЫМПМЃЌЖјЧвПЩФмИФБфЫћЕФПДЗЈЁЃ
МйЩшМЦЫуЛњвВгЕгаЧБвтЪЖ(е§ШчБОВЉПЭЕФУћГЦвЛбљ)ЁЃФЧУДЛсдѕУДбљЃПЦЉШчШУМЦЫуЛњдкЙЄзїЕФЙ§ГЬжаЁЃж№НЅВњЩњСЫздЩэЕФЧБвтЪЖЁЃгкЪЧЩѕжСФмЙЛдкФуВЛаывЊИцЫпЫќзіЪВУДЪБЫќОЭЛсЭъБЯФЧМўЪТЁЃетЪЧИіЗЧГЃгавтЫМЕФЩшЯыЃЌетРяСєИјИїЮЛЖСепШЅЗЂЩЂЫМПМАЩЁЃ
змНс
НгзХвдвЛИіЁАЕШШЫЙЪЪТЁБеЙПЊЖдЛњЦїбЇЯАЕФНщЩмЁЃНщЩмжаЪзЯШЪЧЛњЦїбЇ ЯАЕФИХФюгыЖЈвхЁЃШЛКѓЪЧЛњЦїбЇЯАЕФЯрЙибЇПЦЃЌЛњЦїбЇЯАжаАќРЈЕФИїРрбЇЯАЫуЗЈЁЃНгзХНщЩмЛњЦїбЇЯАгыДѓЪ§ОнЕФЙиЯЕЁЃЛњЦїбЇЯАЕФаТзгРрЩюЖШбЇЯАЃЌзюКѓЬНЬжСЫвЛЯТ
ЛњЦїбЇЯАгыШЫЙЄжЧФмЗЂеЙЕФСЊЯЕвдМАЛњЦїбЇЯАгыЧБвтЪЖЕФЙиСЊЁЃ
ОЙ§БОЮФЕФНщЩмЃЌЯраХДѓМвЖдЛњЦїбЇЯАММЪѕгавЛЖЈЕФСЫНтЃЌБШШчЛњЦїбЇЯАЪЧЪВУДЃЌЫќЕФФкКЫЫМЯыЪЧЪВ УД(МДЭГМЦКЭЙщФЩ)ЃЌЭЈЙ§СЫНтЛњЦїбЇЯАгыШЫРрЫМПМЕФНќЫЦСЊЯЕФмЙЛжЊЯўЛњЦїбЇЯАЮЊЪВУДОпгажЧЛлФмСІЕФдвђЕШЕШЁЃ
ЦфДЮЁЃБОЮФТўЬИСЫЛњЦїбЇЯАгыЭтбгбЇПЦЕФЙиЯЕЃЌ ЛњЦїбЇЯАгыДѓЪ§ОнЯрЛЅДйНјЯрЕУвцеУЕФСЊЯЕЃЌЛњЦїбЇЯАНчзюаТЕФЩюЖШбЇЯАЕФбИУЭЗЂеЙЃЌвдМАЖдгкШЫРрЛљгкЛњЦїбЇЯАПЊЗЂжЧФмЛњЦїШЫЕФвЛжжеЙЭћгыЫМПМЃЌзюКѓзїепМђЕЅ
ЬИСЫвЛЕуЙигкШУМЦЫуЛњгЕгаЧБвтЪЖЕФЩшЯыЁЃ
ЛњЦїбЇЯАЪЧблЯТвЕНчзюЮЊAmazingгыЛ№ШШЕФвЛЯюММЪѕЃЌДгЭјЩЯЕФУПвЛДЮЬдБІЕФЙКТђЖЋЮїЃЌЕНздМКжїЖЏМнЪЛЦћГЕММЪѕЃЌвдМАЭјТчЙЅЛїЕжгљЯЕЭГЕШЕШЁЃЖМгаЛњЦї
бЇЯАЕФвђзгдкФкЃЌЭЌвЛЪБКђЛњЦїбЇЯАвВЪЧзюгаПЩФмЪЙШЫРрЭъБЯAI dreamЕФвЛЯюММЪѕЃЌИїжжШЫЙЄжЧФмблЯТЕФгІгУЃЌШчЮЂШэаЁБљСФЬьЛњЦїШЫЃЌЕНМЦЫуЛњЪгОѕММЪѕЕФНјВНЁЃЖМгаЛњЦїбЇЯАХЌСІЕФГЩЗжЁЃзїЮЊвЛУћЕБДњЕФМЦЫуЛњСьгђЕФПЊ
ЗЂЛђЙмРэШЫдБЃЌвдМАЩэДІетИіЪРНчЁЃЪЙгУепITММЪѕДјРДБуРћЕФШЫУЧЃЌзюКУЖМгІИУСЫНтвЛаЉЛњЦїбЇЯАЕФЯрЙижЊЪЖгыИХФюЁЃгЩгкетФмЙЛАяФуИќКУЕФРэНтЮЊФуДјРДФЊДѓБу
РћММЪѕЕФБГКѓдРэЃЌвдМАШУФуИќКУЕФРэНтЕБДњПЦММЕФНјГЬЁЃ
КѓМЧ
етЦЊЮФЕЕЛЈСЫзїепСНИідТЕФЪБМфЁЃзюжедк2014ФъЕФзюКѓвЛЬьЕФЧАвЛЬьЛљБОЭъБЯЁЃЭЈЙ§етЦЊЮФеТЁЃзїепЯЃЭћЖдЛњЦїбЇЯАдкЙњФкЕФЦеМАзівЛЕуЙБЯзЃЌЭЌвЛЪБКђвВЪЧ
зїепБОШЫздМКЖдгкЫљбЇЛњЦїбЇЯАжЊЪЖЕФвЛИіШкЛуЙсЭЈЃЌзмЬхЙщФЩЕФЬсИпЙ§ГЬЁЃзїепАбетУДЖрЕФжЊЪЖОЙ§здМКЕФДѓФдЫМПМЁЃбЕСЗГіСЫвЛИіФЃаЭЁЃаЮГЩСЫетЦЊЮФЕЕЁЃФмЙЛ
ЫЕетвВЪЧвЛжжЛњЦїбЇЯАЕФЙ§ГЬАЩ(аІ)ЁЃ
зїепЫљдкЕФаавЕЛсНгДЅЕНДѓСПЕФЪ§ОнЃЌвђДЫЖдгкЪ§ОнЕФДІРэКЭЗжЮіЪЧбАГЃЗЧГЃживЊЕФЙЄзїЃЌЛњЦїбЇЯАПЮГЬЕФЫМЯыКЭРэФюЖдгкзїепШеГЃЕФЙЄзїжИв§зїгУМЋДѓЃЌМИ
КѕЕМжТСЫзїепЖдгкЪ§ОнМлжЕЕФгжвЛДЮШЯЪЖЁЃЯыЯыАыФъЧАЃЌзїепЛЙЖдЛњЦїбЇЯАЫЦЖЎЗЧЖЎЁЃШчНёвВФмЙЛЫуЪЧвЛИіЛњЦїбЇЯАЕФExpertСЫ(аІ)ЁЃЕЋзїепЪМжеОѕЕУЃЌЛњЦї
бЇЯАЕФеце§гІгУВЛЪЧЭЈЙ§ИХФюЛђепЫМЯыЕФЗНЪНЁЃЖјЪЧЭЈЙ§ЪЕМљЁЃНіНігаЕБАбЛњЦїбЇЯАММЪѕеце§гІгУЪБЃЌВХПЩЫуЪЧЖдЛњЦїбЇЯАЕФРэНтНјШыСЫвЛИіВуДЮЁЃе§ЫљЮНдйЁАбєДКАз
бЉЁБЕФММЪѕЃЌвВБиаыТфЕНЁАЯТРяАЭШЫЁБЕФГЁОАЯТдЫгУЁЃблЯТгавЛжжЗчЦјЃЌЙњФкЭтбаОПЛњЦїбЇЯАЕФФГаЉбЇепЁЃгавЛжжИпЙѓЕФБЦИёЁЃОѕЕУздМКЕФбаОПЪЧЦеЭЈШЫЮоЗЈРэНт
ЕФЃЌПЩЪЧетжжРэФюЪЧИљБОДэЮѓЕФЁЃУЛгадкеце§ЪЕМЪЕФЕиЗНЗЂЛгзїгУЃЌЦОЪВУДжЄУїФуЕФбаОПгаЫљМлжЕФиЃПзїепОѕЕУБиаыНЋИпДѓЩЯЕФММЪѕгУдкИФБфЦеЭЈШЫЕФЩњЛюЩЯЃЌВХ
ФмЗЂЛгЦфИљБОЕФМлжЕЁЃ
вЛаЉМђЕЅЕФГЁОАЃЌЧЁЧЁЪЧЪЕМљЛњЦїбЇЯАММЪѕЕФзюКУЕиЗНЁЃ |









