| БрМЭЦМі: |
БОЮФРДздcnblogsЃЌЮФеТЭЈЙ§ГЃМћЗжРрФЃаЭгыЫуЗЈЃЌKNNЗжРрЫуЗЈдРэМАгІгУЃЌЦгЫиБДвЖЫЙЗжРрЫуЗЈдРэЃЌОіВпЪїЃЈDecision
TreeЃЉЗжРрЫуЗЈдРэМАгІгУЕШЯрЙиЗНУцЯъЯИНщЩмЁЃ
|
|
ГЃМћЗжРрФЃаЭгыЫуЗЈ ОрРыХаБ№ЗЈЃЌМДзюНќСкЫуЗЈKNNЃЛ БДвЖЫЙЗжРрЦїЃЛ ЯпадХаБ№ЗЈЃЌМДТпМЛиЙщЫуЗЈЃЛ ОіВпЪїЃЛ жЇГжЯђСПЛњЃЛ ЩёОЭјТчЃЛ
1. KNNЗжРрЫуЗЈдРэМАгІгУ
1.1 KNNИХЪі KзюНќСкЃЈk-Nearest NeighborЃЌKNNЃЉЗжРрЫуЗЈЪЧзюМђЕЅЕФЛњЦїбЇЯАЫуЗЈЁЃ
KNNЫуЗЈЕФжИЕМЫМЯыЪЧЁАНќжьепГрЃЌНќФЋепКкЁБЃЌгЩФуЕФСкОгРДЭЦЖЯФуЕФРраЭЁЃ
БОжЪЩЯЃЌKNNЫуЗЈОЭЪЧгУОрРыРДКтСПбљБОжЎМфЕФЯрЫЦЖШЁЃ
1.2 ЫуЗЈЭМЪО ДгбЕСЗМЏжаевЕНКЭаТЪ§ОнзюНгНќЕФkЬѕМЧТМЃЌШЛКѓИљОнЖрЪ§РрРДОіЖЈаТЪ§ОнРрБ№ ЫуЗЈЩцМА3ИіжївЊвђЫи 1) бЕСЗЪ§ОнМЏ 2) ОрРыЛђЯрЫЦЖШЕФМЦЫуКтСП 3) kЕФДѓаЁ

ЫуЗЈУшЪі 1) вбжЊСНРрЁАЯШбщЁБЪ§ОнЃЌЗжБ№ЪЧРЖЗНПщКЭКьШ§НЧЃЌЫћУЧЗжВМдквЛИіЖўЮЌПеМфжаЃЛ 2) гавЛИіЮДжЊРрБ№ЕФЪ§Он(ТЬЕу)ЃЌашвЊХаЖЯЫќЪЧЪєгкЁАРЖЗНПщЁБЛЙЪЧЁАКьШ§НЧЁБРрЃЛ 3) ПМВьРыТЬЕузюНќЕФ3Иі(ЛђkИі)Ъ§ОнЕуЕФРрБ№ЃЌеМЖрЪ§ЕФРрБ№МДЮЊТЬЕуХаЖЈРрБ№ЃЛ
1.3 ЫуЗЈвЊЕу
1.3.1 МЦЫуВНжш МЦЫуВНжшШчЯТЃК
1) ЫуОрРыЃКИјЖЈВтЪдЖдЯѓЃЌМЦЫуЫќгыбЕСЗМЏжаЕФУПИіЖдЯѓЕФОрРыЃЛ
2) евСкОгЃКШІЖЈОрРызюНќЕФkИібЕСЗЖдЯѓЃЌзїЮЊВтЪдЖдЯѓЕФНќСкЃЛ
3) зіЗжРрЃКИљОнетkИіНќСкЙщЪєЕФжївЊРрБ№ЃЌРДЖдВтЪдЖдЯѓЗжРрЃЛ
1.3.2 ЯрЫЦЖШЕФКтСП ОрРыдННќгІИУвтЮЖзХетСНИіЕуЪєгквЛИіЗжРрЕФПЩФмаддНДѓЃЌЕЋЃЌОрРыВЛФмДњБэвЛЧаЃЌгааЉЪ§ОнЕФЯрЫЦЖШКтСПВЂВЛЪЪКЯгУОрРыЃЛ ЯрЫЦЖШКтСПЗНЗЈЃКАќРЈХЗЪНОрРыЁЂМаНЧгрЯвЕШЁЃ ЃЈМђЕЅгІгУжаЃЌвЛАуЪЙгУХЗЪНОрРыЃЌЕЋЖдгкЮФБОЗжРрРДЫЕЃЌЪЙгУгрЯвРДМЦЫуЯрЫЦЖШОЭБШХЗЪНОрРыИќКЯЪЪЃЉ
1.3.3 РрБ№ЕФХаЖЈ МђЕЅЭЖЦБЗЈЃКЩйЪ§ЗўДгЖрЪ§ЃЌНќСкжаФФИіРрБ№ЕФЕузюЖрОЭЗжЮЊИУРр МгШЈЭЖЦБЗЈЃКИљОнОрРыЕФдЖНќЃЌЖдНќСкЕФЭЖЦБНјааМгШЈЃЌОрРыдННќдђШЈжидНДѓЃЈШЈжиЮЊОрРыЦНЗНЕФЕЙЪ§ЃЉ
1.4 ЫуЗЈВЛзужЎДІ
1. бљБОВЛЦНКтШнвзЕМжТНсЙћДэЮѓ
ШчвЛИіРрЕФбљБОШнСПКмДѓЃЌЖјЦфЫћРрбљБОШнСПКмаЁЪБЃЌгаПЩФмЕМжТЕБЪфШывЛИіаТбљБОЪБЃЌИУбљБОЕФKИіСкОгжаДѓШнСПРрЕФбљБОеМЖрЪ§ЁЃ ИФЩЦЗНЗЈЃКЖдДЫПЩвдВЩгУШЈжЕЕФЗНЗЈЃЈКЭИУбљБООрРыаЁЕФСкОгШЈжЕДѓЃЉРДИФНјЁЃ 2. МЦЫуСПНЯДѓ
вђЮЊЖдУПвЛИіД§ЗжРрЕФЮФБОЖМвЊМЦЫуЫќЕНШЋЬхвбжЊбљБОЕФОрРыЃЌВХФмЧѓЕУЫќЕФKИізюНќСкЕуЁЃ ИФЩЦЗНЗЈЃКЪЕЯжЖдвбжЊбљБОЕуНјааМєМЃЌЪТЯШШЅГ§ЖдЗжРрзїгУВЛДѓЕФбљБОЁЃ зЂЃКИУЗНЗЈБШНЯЪЪгУгкбљБОШнСПБШНЯДѓЕФРргђЕФРргђЕФЗжРрЃЌЖјФЧаЉбљБОШнСПНЯаЁЕФРргђВЩгУетжжЫуЗЈБШНЯШнвзВњЩњЮѓЗжЁЃ
1.5 KNNЗжРрЫуЗЈPythonЪЕеНЁЊЁЊKNNМђЕЅЪ§ОнЗжРрЪЕМљ 1.5.1 ашЧѓ МЦЫуЕиРэЮЛжУЕФЯрЫЦЖШ
гавдЯТЯШбщЪ§ОнЃЌЪЙгУKNNЫуЗЈЖдЮДжЊРрБ№Ъ§ОнЗжРр
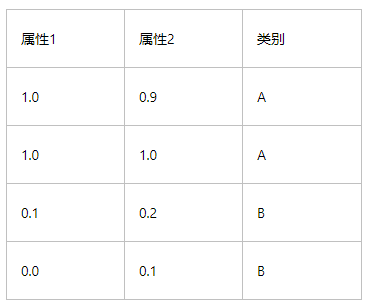
ЮДжЊРрБ№Ъ§Он
1.5.2 PythonЪЕЯж
ЪзЯШЃЌЮвУЧаТНЈвЛИіKNN.pyНХБОЮФМўЃЌЮФМўРяУцАќКЌСНИіКЏЪ§ЃЌвЛИігУРДЩњГЩаЁЪ§ОнМЏЃЌвЛИіЪЕЯжKNNЗжРрЫуЗЈЁЃДњТыШчЯТЃК
##########################
# KNN: k Nearest Neighbors
#ЪфШыЃКnewInput: (1xN)ЕФД§ЗжРрЯђСП
# dataSet: (NxM)ЕФбЕСЗЪ§ОнМЏ
# labels: бЕСЗЪ§ОнМЏЕФРрБ№БъЧЉЯђСП
# k: НќСкЪ§
# ЪфГіЃКПЩФмадзюДѓЕФЗжРрБъЧЉ
##########################
from numpy import
import operator
#ДДНЈвЛИіЪ§ОнМЏЃЌАќКЌ2ИіРрБ№ЙВ4ИібљБО
def createDataSet():
# ЩњГЩвЛИіОиеѓЃЌУПааБэЪОвЛИібљБО
group = array([[1.0,0.9],[1.0,1.0],[0.1,0.2],[0.0,0.1]])
# 4ИібљБОЗжБ№ЫљЪєЕФРрБ№
labels = ['A', 'A', 'B', 'B']
return group, labels
# KNNЗжРрЫуЗЈКЏЪ§ЖЈвх
def KNNClassify(newInput, dataSet, labels, k)ЃК
numSamples = dataSet.shape[0] #shape[0]БэЪОааЪ§
## step1ЃКМЦЫуОрРы
# tile(A, reps)ЃКЙЙдьвЛИіОиеѓЃЌЭЈЙ§AжиИДrepsДЮЕУЕН
# the following copy numSamples rows for dataSet
diff = tile(newInput, (numSamples, 1)) -dataSet
#АДдЊЫиЧѓВюжЕ
squareDiff = diff ** 2 #НЋВюжЕЦНЗН
squareDist = sum(squaredDiff, axis = 1) # АДааРлМг
##step2ЃКЖдОрРыХХађ
# argsort() ЗЕЛиХХађКѓЕФЫїв§жЕ
sortedDistIndices = argsort(distance)
classCount = {} # define a dictionary (can be
append element)
for i in xrange(k):
##step 3: бЁдёkИізюНќСк
voteLabel = labels[sortedDistIndices[i]]
## step 4:МЦЫуkИізюНќСкжаИїРрБ№ГіЯжЕФДЮЪ§
# when the key voteLabel is not in dictionary
classCountЃЌget()
# will return 0
classCount[voteLabel] = classCount.get(voteLabel,
0) + 1
##step 5ЃКЗЕЛиГіЯжДЮЪ§зюЖрЕФРрБ№БъЧЉ
maxCount = 0
for key, value in classCount.items():
if value > maxCount:
maxCount = value
maxIndex = key
return maxIndex |
ШЛКѓЕїгУЫуЗЈНјааВтЪд
import KNN
from numpy import *
#ЩњГЩЪ§ОнМЏКЭРрБ№БъЧЉ
dataSet,labels = KNN.createDataSet()
#ЖЈвхвЛИіЮДжЊРрБ№ЕФЪ§Он
testX = array([1.2, 1.0])
k=3
#ЕїгУЗжРрКЏЪ§ЖдЮДжЊЪ§ОнЗжРр
outputLabel = KNN.KNNClassify(testX, dataSet,
labels, 3)
print "Your input is:", testX, "
and classified to class:", outputLabel
testX = array([0.1, 0.3])
outputLabel = KNN.KNNClassify(testX,dataSet,
labels, 3)
print "Your input is:", testX, "and
classified to class:", outputLabel |
етЪБКђЛсЪфГіЃК
Your input is:
[1.2 1.0] and classified to class: A
Your input is: [0.1 0.3] and classified to class:
B |
2. ЦгЫиБДвЖЫЙЗжРрЫуЗЈдРэ 2.1 ИХЪі БДвЖЫЙЗжРрЫуЗЈЪБвЛДѓРрЗжРрЫуЗЈЕФзмГЦЁЃБДвЖЫЙЗжРрЫуЗЈвдбљБОПЩФмЪєгкФГРрЕФИХТЪРДзїЮЊЗжРрвРОнЁЃЦгЫиБДвЖЫЙЗжРрЫуЗЈЪББДвЖЫЙЗжРрЫуЗЈжазюМђЕЅЕФвЛжжЁЃ
зЂЃКЦгЫиЕФвтЫМЪБЬѕМўИХТЪЖРСЂад
2.2 ЫуЗЈЫМЯы ЦгЫиБДвЖЫЙЕФЫМЯыЪЧетбљЕФЃКШчЙћвЛИіЪТЮядквЛаЉЪєадЬѕМўЗЂЩњЕФЧщПіЯТЃЌЪТЮяЪєгкAЕФИХТЪ>ЪєгкBЕФИХТЪЃЌдђХаЖЈЪТЮяЪєгкAЁЃ
ЭЈЫзРДЫЕБШШчЃЌдкФГЬѕДѓНжЩЯЃЌга100ШЫЃЌЦфжага50ИіУРЙњШЫЃЌ50ИіЗЧжоШЫЃЌПДЕНвЛИіНВгЂгяЕФКкШЫЃЌФЧУДЮвУЧЪЧдѕУДШЅХаЖЯЫћРДздФФРяЃП
ЬсШЁЬиеїЃК
ЗєЩЋЃККкЃЌгябдЃКгЂгя
ЯШбщжЊЪЖЃК
P(КкЩЋ|ЗЧжоШЫ) = 0.8
P(НВгЂгя|ЗЧжоШЫ)=0.1
P(КкЩЋ|УРЙњШЫ)= 0.2
P(НВгЂгя|УРЙњШЫ)=0.9
вЊХаЖЯЕФИХТЪЪЧЃК
P(ЗЧжоШЫ|(НВгЂгяЃЌКкЩЋ) )
P(УРЙњШЫ|(НВгЂгяЃЌКкЩЋ) )
ЫМПМЙ§ГЬЃК

P(ЗЧжоШЫ|(НВгЂгяЃЌКкЩЋ) ) ЕФ Зжзг= 0.1 * 0.8 *0.5 =0.04
P(УРЙњШЫ|(НВгЂгяЃЌКкЩЋ) ) ЕФ Зжзг= 0.9 *0.2 * 0.5 = 0.09
ДгЖјБШНЯетСНИіИХТЪЕФДѓаЁОЭЕШМлгкБШНЯетСНИіЗжзгЕФжЕЃЌПЩвдЕУГіНсТлЃЌДЫШЫгІИУЪЧЃКУРЙњШЫЁЃ
ЦфдЬКЌЕФЪ§бЇдРэШчЯТЃК
p(A|xy)=p(Axy)/p(xy) =p(Axy)/p(x)p(y) =p(A)/p(x)*p(A)/p(y)*
p(xy)/p(xy)= p(A|x)p(A|y)
ЦгЫиБДвЖЫЙЗжРрЦї
НВСЫЩЯУцЕФаЁЙЪЪТЃЌЮвУЧРДЦгЫиБДвЖЫЙЗжРрЦїЕФБэЪОаЮЪНЃК
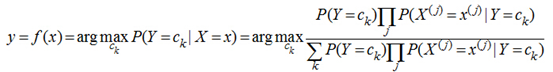
ЕБЬиеїЮЊЮЊxЪБЃЌМЦЫуЫљгаРрБ№ЕФЬѕМўИХТЪЃЌбЁШЁЬѕМўИХТЪзюДѓЕФРрБ№зїЮЊД§ЗжРрЕФРрБ№ЁЃгЩгкЩЯЙЋЪНЕФЗжФИЖдУПИіРрБ№ЖМЪЧвЛбљЕФЃЌвђДЫМЦЫуЪБПЩвдВЛПМТЧЗжФИЃЌМД
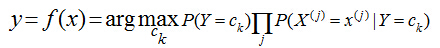
ЦгЫиБДвЖЫЙЕФЦгЫиЬхЯждкЦфЖдИїИіЬѕМўЕФЖРСЂадМйЩшЩЯЃЌМгЩЯЖРСЂМйЩшКѓЃЌДѓДѓМѕЩйСЫВЮЪ§МйЩшПеМфЁЃЁЁЁЁ
2.3 ЫуЗЈвЊЕу 2.3.1 ЫуЗЈВНжш 1. ЗжНтИїРрЯШбщбљБОЪ§ОнжаЕФЬиеїЃЛ
2. МЦЫуИїРрЪ§ОнжаЃЌИїЬиеїЕФЬѕМўИХТЪЃЛ(БШШчЃКЬиеї1ГіЯжЕФЧщПіЯТЃЌЪєгкAРрЕФИХТЪp(A|Ьиеї1)ЃЌЪєгкBРрЕФИХТЪp(B|Ьиеї1)ЃЌЪєгкCРрЕФИХТЪp(C|Ьиеї1)......)
3. ЗжНтД§ЗжРрЪ§ОнжаЕФЬиеї(Ьиеї1ЁЂЬиеї2ЁЂЬиеї3ЁЂЬиеї4......)
4. МЦЫуИїЬиеїЕФИїЬѕМўИХТЪЕФГЫЛ§ЃЌШчЯТЫљЪОЃК
ХаЖЯЮЊAРрЕФИХТЪЃКp(A|Ьиеї1) * p(A|Ьиеї2) * p(A|Ьиеї3) * p(A|Ьиеї4)......
ХаЖЯЮЊBРрЕФИХТЪЃКp(B|Ьиеї1) * p(B|Ьиеї2) * p(B|Ьиеї3) * p(B|Ьиеї4)......
ХаЖЯЮЊCРрЕФИХТЪЃКp(C|Ьиеї1) * p(C|Ьиеї2) * p(C|Ьиеї3) * p(C|Ьиеї4)......
......
5. НсЙћжаЕФзюДѓжЕОЭЪЧИУбљБОЫљЪєЕФРрБ№
2.3.2 ЫуЗЈгІгУОйР§
ДѓжкЕуЦРЁЂЬдБІЕШЕчЩЬЩЯЖМЛсгаДѓСПЕФгУЛЇЦРТлЃЌБШШчЃК
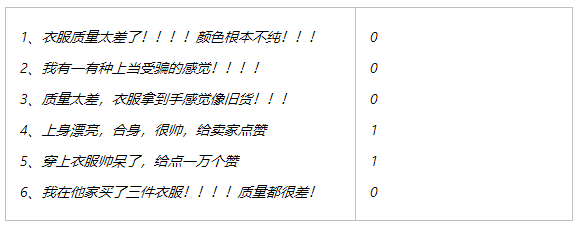
Цфжа1/2/3/6ЪЧВюЦРЃЌ4/5ЪЧКУЦР
ЯждкашвЊЪЙгУЦгЫиБДвЖЫЙЗжРрЫуЗЈРДздЖЏЗжРрЦфЫћЕФЦРТлЃЌБШШчЃК

2.3.3 ЫуЗЈгІгУСїГЬ 1. ЗжНтГіЯШбщЪ§ОнжаЕФИїЬиеї
(МДЗжДЪЃЌБШШчЁАвТЗўЁБЃЌЁАжЪСПЬЋВюЁБЃЌЁАВюЁБЃЌЁАВЛДПЁБЃЌЁАЫЇЁБЃЌЁАЦЏССЁБЃЌЁАдоЁБ ......)
2. МЦЫуИїРрБ№ЃЈКУЦРЁЂВюЦРЃЉжаЃЌИїЬиеїЕФЬѕМўИХТЪ
(БШШч p(ЁАвТЗўЁБ | ВюЦР)ЁЂp(ЁАвТЗўЁБ | КУЦР)ЁЂp(ЁАВюЁБ|КУЦР)ЁЂp(ЁАВюЁБ| ВюЦР)
......)
3. МЦЫуРрБ№ИХТЪ
p(КУЦР|(c1,c2,c5,c8))ЕФЗжзг=p(c1|КУЦР) * p(c2|КУЦР) * p(c3|КУЦР)
*......p(КУЦР)
p(ВюЦР|(c1,c2,c5,c8))ЕФЗжзг=p(c1|ВюЦР) * p(c2|ВюЦР) * p(c3|ВюЦР)
*......p(ВюЦР)

4. ЯдШЛp(ВюЦР)ЕФНсЙћжЕИќДѓЃЌвђДЫaБЛХаБ№ЮЊ"ВюЦР"
2.4 ЦгЫиБДвЖЫЙЗжРрЫуЗЈАИР§ 2.4.1 ашЧѓ РћгУДѓСПгЪМўЯШбщЪ§ОнЃЌЪЙгУЦгЫиБДвЖЫЙЗжРрЫуЗЈРДздЖЏЪЖБ№РЌЛјгЪМў
2.4.2 pythonЪЕЯж
#Й§ТЫРЌЛјгЪМў
def textParse(bigString): #е§дђБэДяЪННјааЮФБОНтЮі
import re
listOfTokens = re.split(r'\W*', bigString)
return [tok.lower() for tok in listOfTokens if
len(tok) > 2]
def spamTest()
docList = []; classList = []; fullText = []
for i in range(1,26): #ЕМШыВЂНтЮіЮФБОЮФМў
wordList = textParse(open('email/spam/%d.txt'%i).read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(1)
wordList = textParse(open('email/ham/%d.txt'%i).read())
docList.append(wordList)
fullText.extend(wordList)
classList.append(0)
vocabList = createVocabList(docList)
trainingSet = range(50);testSet = []
for i in range(10): #ЫцЛњЙЙНЈбЕСЗМЏ
randIndex = int(random.uniform(0, len(trainingSet)))
testSet.append(trainingSet[randIndex]) #ЫцЛњЬєбЁвЛИіЮФЕЕЫїв§КХЗХШыВтЪдМЏ
del(trainingSet[randIndex]) #НЋИУЮФЕЕЫїв§КХДгбЕСЗМЏжаЬоГ§
trainMat = []; trainClasses = []
for docIndex in trainingSet:
trainMat.append(setOfWords2Vec(vocabList, docList[docIndex]))
trainClasses.append(classList[docIndex])
p0V,p1V,pSpam = trainNBO(array(trainMat), array(trainClasses))
errorCount = 0
for docIndex in testSet: #ЖдВтЪдМЏНјааЗжРр
wordVector = setOfWords2Vec(vocabList, docList[docIndex])
if classifyNB(array(wordVector), p0V,p1V !=
classList[docIndex]:
errorCount +=1
print 'the error rate is:', float(errorCount)/len(testSet) |
3. logisticТпМЛиЙщЗжРрЫуЗЈМАгІгУ 3.1 ИХЪі LineageТпМЛиЙщЪЧвЛжжМђЕЅЖјгжаЇЙћВЛДэЕФЗжРрЫуЗЈЁЃ
ЪВУДЪЧЛиЙщЃКБШШчЫЕЮвУЧгаСНРрЪ§ОнЃЌИїга50ИіЕузщГЩЃЌЕБЮвУЧАбетаЉЕуЛГіРДЃЌЛсгавЛЬѕЯпЧјЗжетСНзщЪ§ОнЃЌЮвУЧФтКЯГіетИіЧњЯпЃЈвђЮЊКмгаПЩФмЪЧЗЧЯпадЕФЃЉЃЌОЭЪЧЛиЙщЁЃЮвУЧЭЈЙ§ДѓСПЕФЪ§ОневГіетЬѕЯпЃЌВЂФтКЯГіетЬѕЯпЕФБэДяЪНЃЌдйгааТЪ§ОнЃЌЮвУЧОЭвдетЬѕЯпЮЊЧјЗжРДЪЕЯжЗжРрЁЃ
ЯТЭМЪЧвЛИіЪ§ОнМЏЕФСНзщЪ§ОнЃЌжаМфгавЛЬѕЧјЗжСНзщЪ§ОнЕФЯпЁЃ
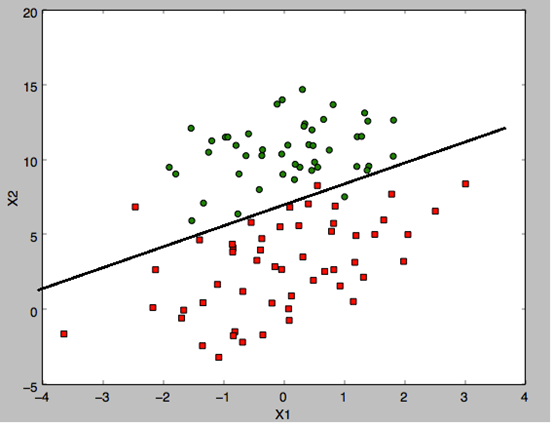
ЯдШЛЃЌжЛгаетжжЯпадПЩЗжЕФЪ§ОнЗжВМВХЪЪКЯгУЯпадТпМЛиЙщ
3.2 ЫуЗЈЫМЯы LineageЛиЙщЗжРрЫуЗЈОЭЪЧНЋЯпадЛиЙщгІгУдкЗжРрГЁОАжа
дкИУГЁОАжаЃЌМЦЫуНсЙћЪЧвЊЕУЕНЖдбљБОЪ§ОнЕФЗжРрБъЧЉЃЌЖјВЛЪЧЕУЕНФЧЬѕЛиЙщжБЯп
3.2.1 ЫуЗЈЭМЪО
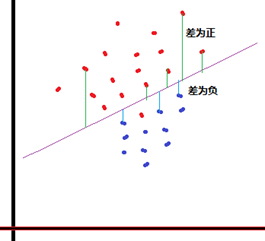
1) ЫуЗЈФПБъ()ЃП
ДѓАзЛАЃКМЦЫуИїЕуЕФyжЕЕНФтКЯЯпЕФДЙжБОрРыЃЌШчЙћОрРы>0ЃЌЗжЮЊРрAЃЛОрРы<0ЃЌЗжЮЊРрBЁЃ
2) ШчКЮЕУЕНФтКЯЯпФиЃП
ДѓАзЛАЃКжЛФмЯШМйЩшЃЌвђЮЊЯпЛђУцЕФКЏЪ§ЖМПЩвдБэДяГЩy(ФтКЯ)=w1 * x1 + w2 * x2 +
w3 * x3 + ... ЃЌЦфжаЕФwЪЧД§ЖЈВЮЪ§ЃЌЖјxЪЧЪ§ОнЕФИїЮЌЖШЬиеїжЕЃЌвђЖјЩЯЪіЮЪЬтОЭБфГЩСЫбљБОy(x)
- y(ФтКЯ) > 0? AЃКB
3) ШчКЮЧѓНтГівЛЬззюгХЕФwВЮЪ§Фи?
ЛљБОЫМТЗЃКДњШыЁБЯШбщЪ§ОнЁАРДФцЭЦЧѓНтЃЌЕЋеыЖдВЛЕШЪНЧѓНтВЮЪ§МЋЦфРЇФбЃЌЭЈгУЕФНтОіЗНЗЈЃЌНЋЖдВЛЕШЪНЕФЧѓНтзівЛИізЊЛЛЃКa.НЋЁБбљБОy(x)
- y(ФтКЯ)ЁАЕФВюжЕбЙЫѕЕНвЛИі0~1ЕФаЁЧјМфЃЛb.ШЛКѓДњШыДѓСПЕФбљБОЬиеїжЕЃЌДгЖјЕУЕНвЛЯЕСаЕФЪфГіНсЙћЃЛc.дйНЋетаЉЪфГіНсЙћИњбљБОЕФЯШбщРрБ№БШНЯЃЌВЂИљОнБШНЯЧщПіРДЕїећФтКЯЯпЕФВЮЪ§жЕЃЌДгЖјЪЧФтКЯЯпЕФВЮЪ§БЦНќзюгХЁЃДгЖјНЋЮЪЬтзЊЛЏЮЊБЦНќЧѓНтЕФЕфаЭЪ§бЇЮЪЬтЁЃ
3.2.2 sigmoidКЏЪ§ ЩЯЪіЫуЗЈЫМТЗжаЃЌЭЈГЃЪЙгУsigmoidКЏЪ§зїЮЊзЊЛЛКЏЪ§
КЏЪ§БэДяЪНЃК
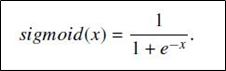
зЂЃКДЫДІЕФxЪЧЯђСП
КЏЪ§ЧњЯпЃК
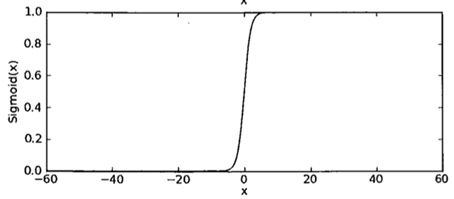
жЎЫљвдЪЙгУsigmoidКЏЪ§ЃЌОЭЪЧШУбљАхЕуОЙ§дЫЫуКѓЕУЕНЕФНсЙћЯожЦдк0~1жЎМфЃЌбЙЫѕЪ§ОнЕФОоЗље№ЕДЃЌДгЖјЗНБуЕУЕНбљБОЕуЕФЗжРрБъЧЉ(ЗжРрвдsigmoidКЏЪ§ЕФМЦЫуНсЙћЪЧЗёДѓгк0.5ЮЊвРОн)
3.3 ЫуЗЈЪЕЯжЗжЮі 1.3.1 ЪЕЯжЫМТЗ ЫуЗЈЫМЯыЕФЪ§бЇБэЪі АбЪ§ОнМЏЕФЬиеїжЕЩшЮЊx1ЃЌx2ЃЌx3......ЃЌЧѓГіЫќУЧЕФЛиЙщЯЕЪ§wjЃЌЩшz=w1 * x1 +
w2 * x2......ЃЌШЛКѓНЋzжЕДњШыsigmoidКЏЪ§ВЂХаЖЯНсЙћЃЌМДПЩЕУЕНЗжРрБъЧЉ
ЮЪЬтдкгкШчКЮЕУЕНвЛзщКЯЪЪЕФВЮЪ§wjЃП
ЭЈЙ§НтЮіЕФЭООЖКмФбЧѓНтЃЌЖјЭЈЙ§ЕќДњЕФЗНЗЈПЩвдБШНЯБуНнЕиевЕНзюгХНтЁЃМђЕЅРДЫЕЃЌОЭЪЧВЛЖЯгУбљБОЬиеїжЕДњШыЫуЪНЃЌМЦЫуГіНсЙћКѓИњЦфЪЕМЪБъЧЉНјааБШНЯЃЌИљОнВюжЕРДаое§ВЮЪ§ЃЌШЛКѓдйДњШыаТЕФбљБОжЕМЦЫуЃЌбЛЗЭљИДЃЌжБЕНЮоашаое§ЛђвбЕНДядЄЩшЕФЕќДњДЮЪ§ЁЃ
зЂЃКДЫЙ§ГЬгУЬнЖШЩЯЩ§РДЪЕЯжЁЃ
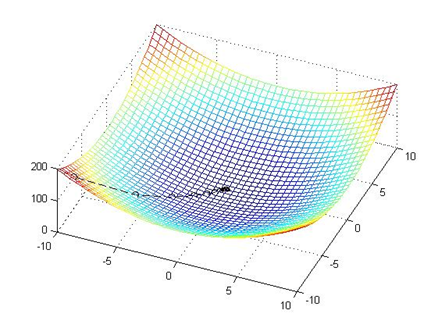
1.3.2 ЬнЖШЩЯЩ§ЫуЗЈ ЬнЖШЩЯЩ§ЪЧжИевЕНКЏЪ§діГЄЕФЗНЯђЁЃдкОпЬхЪЕЯжЕФЙ§ГЬжаЃЌВЛЭЃЕиЕќДњдЫЫужБЕНwЕФжЕМИКѕВЛдйБфЛЏЮЊжЙЁЃ
ШчЭМЫљЪОЃК

3.4 LineageТпМЛиЙщЗжРрPythonЪЕеН 3.4.1 ашЧѓ ЖдИјЖЈЕФЯШбщЪ§ОнМЏЃЌЪЙгУlogisticЛиЙщЫуЗЈЖдаТЪ§ОнЗжРр
3.4.2 pythonЪЕЯж
3.4.2.1 ЖЈвхsigmoidКЏЪ§
def loadDataSet():
dataMat = []; labelMat = []
fr = open('d:/testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat, labelMat
def sigmoid(inX):
return 1.0/(1+exp(-inX)) |
3.4.2.2 ЗЕЛиЛиЙщЯЕЪ§
ЖдгІгкУПИіЬиеїжЕЃЌforбЛЗЪЕЯжСЫЕнЙщЬнЖШЩЯЩ§ЫуЗЈЁЃ
def gradAscent(dataMatln,
classLabels):
dataMatrix = mat(dataMatln) # НЋЯШбщЪ§ОнМЏзЊЛЛЮЊNumPyОиеѓ
labelMat = mat(classLabels).transpose() #НЋЯШбщЪ§ОнЕФРрБъЧЉзЊЛЛЮЊNumPyОиеѓ
m,n = shape(dataMatrix)
alpha = 0.001 #ЩшжУБЦНќВНГЄЕїећЯЕЪ§
maxCycles = 500 #ЩшжУзюДѓЕќДњДЮЪ§ЮЊ500
weights = ones((n,1)) #weightsМДЮЊашвЊЕќДњЧѓНтЕФВЮЪ§ЯђСП
for k in range(maxCycles): #heavy on matrix
operations
h = sigmoid(dataMatrix * weights) #ДњШыбљБОЯђСПЧѓЕУЁАбљБОyЁБ
sigmoidзЊЛЛжЕ
error = (labelMat - h) #ЧѓВю
weights = weights + alpha * dataMatrix.transpose()
* error #ИљОнВюжЕЕїећВЮЪ§ЯђСП
return weights |
ЮвУЧЕФЪ§ОнМЏгаСНИіЬиеїжЕЗжБ№ЪЧx1,x2ЁЃдкДњТыжагждіЩшСЫx0БфСПЁЃ
НсЙћЃЌЗЕЛиСЫЬиеїжЕЕФЛиЙщЯЕЪ§ЃК
[[4.12414349]
[0.48007329]
[-0.6168482]]
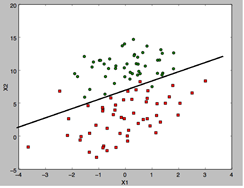
ЮвУЧЕУГіx1КЭx2ЕФЙиЯЕ(Щшx0 = 1)ЃЌ0=4.12414349+0.48007329*x1
- 0.6168482*x2
3.4.2.3 ЯпадФтКЯЯп ЛГіx1гыx2ЕФЙиЯЕЭМЁЊЁЊЯпадФтКЯЯп
4.ОіВпЪїЃЈDecision TreeЃЉЗжРрЫуЗЈдРэМАгІгУ 4.1 ИХЪі ОіВпЪїЁЊЁЊЪЧвЛжжБЛЙуЗКЪЙгУЕФЗжРрЫуЗЈЁЃЯрБШБДвЖЫЙЫуЗЈЃЌОіВпЪїЕФгХЪЦдкгкЙЙдьЙ§ГЬВЛашвЊШЮКЮСьгђжЊЪЖЛђВЮЪ§ЩшжУЁЃдкЪЕМЪгІгУжаЃЌЖдгкЬНВтЪНЕФжЊЪЖЗЂЯжЃЌОіВпЪїИќМгЪЪгУЁЃ
ОіВпЪїЭЈГЃгаШ§ИіВНжшЃКЬиеїбЁдёЁЂОіВпЪїЕФЩњГЩЁЂОіВпЪїЕФаоМєЁЃ
4.2 ЫуЗЈЫМЯы ЭЈЫзРДЫЕЃЌОіВпЪїЗжРрЕФЫМЯыРрЫЦгкевЖдЯѓЁЃЯжЯыЯѓвЛИіХЎКЂЕФФИЧзвЊИјетИіХЎКЂНщЩмФаХѓгбЃЌгкЪЧгаСЫЯТУцЕФЖдЛАЃК
ХЎЖљЃКЖрДѓФъМЭСЫЃП ФИЧзЃК26 ХЎЖљЃКГЄЕФЫЇВЛЫЇЃП ФИЧзЃКЭІЫЇЕФЁЃ ХЎЖљЃКЪеШыИпВЛЃП ФИЧзЃКВЛЫуКмИпЃЌжаЕШЧщПіЁЃ ХЎЖљЃКЪЧЙЋЮёдБТ№ЃП ФИЧзЃКЪЧЃЌЙЋЮёдБЃЌдкЫАЮёОжЩЯАрФиЁЃ ХЎЖљЃКФЧКУЃЌЮвШЅМћМћЁЃ
етИіХЎКЂЕФОіВпЙ§ГЬОЭЪЧЕфаЭЕФЗжРрЪїОіВпЁЃЪЕжЪЃКЭЈЙ§ФъСфЁЂГЄЯрЁЂЪеШыКЭЪЧЗёЙЋЮёдБНЋФаШЫЗжЮЊСНИіРрБ№ЃКМћКЭВЛМћ
МйЩшетИіХЎКЂЖдФаШЫЕФвЊЧѓЪЧЃК30ЫъвдЯТЁЂГЄЯржаЕШвдЩЯВЂЧвЪЧИпЪеШыепЛђжаЕШвдЩЯЪеШыЕФЙЋЮёдБЃЌФЧУДетИіПЩвдгУЯТЭМБэЪОХЎКЂЕФОіВпТпМЁЃ
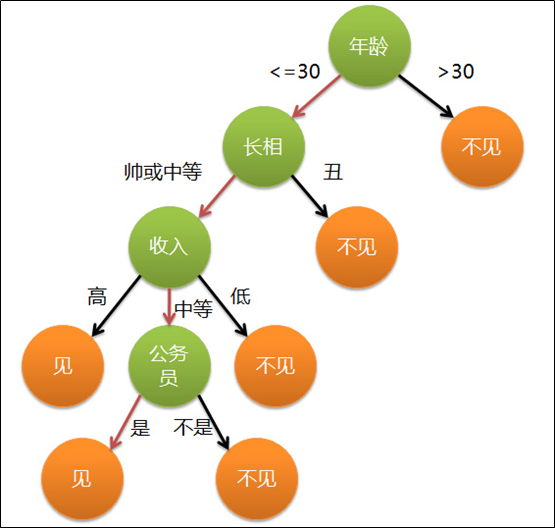
ЩЯЭМЭъећБэДяСЫетИіХЎКЂОіЖЈЪЧЗёМћвЛИідМЛсЖдЯѓЕФВпТдЃЌЦфжаЃК
ТЬЩЋНкЕуБэЪОХаЖЯЬѕМў ГШЩЋНкЕуБэЪООіВпНсЙћ М§ЭЗБэЪОдквЛИіХаЖЯЬѕМўдкВЛЭЌЧщПіЯТЕФОіВпТЗОЖ ЭМжаКьЩЋМ§ЭЗБэЪОСЫЩЯУцР§згжаХЎКЂЕФОіВпЙ§ГЬЁЃетЗљЭМЛљБОПЩвдЫуЪЧвЛПХОіВпЪїЃЌЫЕЫќЁБЛљБОПЩвдЫуЁАЪЧвђЮЊЭМжаЕФХаЖЈЬѕМўУЛгаСПЛЏЃЌШчЪеШыИпжаЕЭЕШЕШЃЌЛЙВЛФмЫуЪЧбЯИёвтвхЩЯЕФОіВпЪїЃЌШчЙћНЋЫљгаЬѕМўСПЛЏЃЌдђОЭБфГЩеце§ЕФОіВпЪїСЫЁЃ
ОіВпЪїЗжРрЫуЗЈЕФЙиМќОЭЪЧИљОнЁБЯШбщЪ§ОнЁАЙЙдьвЛПУзюМбЕФОіВпЪїЃЌгУвддЄВтЮДжЊЪ§ОнЕФРрБ№
ОіВпЪїЃКЪЧвЛИіЪїНсЙЙ(ПЩвдЪЧЖўВцЪїЛђЗЧЖўВцЪї)ЁЃЦфУПИіЗЧвЖНкЕуБэЪОвЛИіЬиеїЪєадЩЯЕФВтЪдЃЌУПИіЗжжЇДњБэетИіЬиеїЪєаддкФГИіжЕгђЩЯЕФЪфГіЃЌЖјУПИівЖНкЕуДцЗХвЛИіРрБ№ЁЃЪЙгУОіВпЪїНјааОіВпЕФЙ§ГЬОЭЪЧДгИљНкЕуПЊЪМЃЌВтЪдД§ЗжРрЯюжаЯргІЕФЬиеїЪєадЃЌВЂАДееЦфжЕбЁдёЪфГіЗжжЇЃЌжБЕНЕНДявЖзгНкЕуЃЌНЋвЖзгНкЕуДцЗХЕФРрБ№зїЮЊОіВпНсЙћЁЃ
4.3 ОіВпЪїЙЙдь 4.3.1 ОіВпЪїЙЙдьбљР§
МйШчгавдЯТХаЖЯЦЛЙћКУЛЕЕФЪ§ОнбљБОЃК

бљБОжага2ИіЪєадЃЌA0БэЪОЪЧЗёКьЦЛЙћЁЃA1БэЪОЪЧЗёДѓгкЦЛЙћЁЃМйШчвЊИљОнетИіЪ§ОнбљБОЙЙНЈвЛПУздЖЏХаЖЯЦЛЙћКУЛЕЕФОіВпЪїЁЃгЩгкБОР§жаЕФЪ§ОнжЛга2ИіЪєадЃЌвђДЫЃЌЮвУЧПЩвдЧюОйЫљгаПЩФмЙЙдьГіРДЕФОіВпЪїЃЌОЭ2ПЮЪїЃЌШчЯТЭМЫљЪОЃК
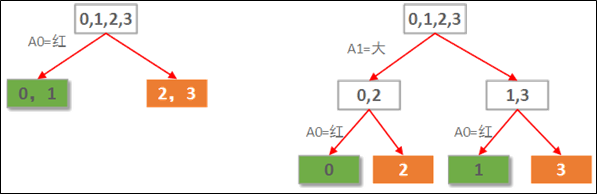
ЯдШЛзѓБпЯШЪЙгУA0(КьЩЋ)зіЛЎЗжвРОнЕФОіВпЪївЊгХгкгвБпгУA1(ДѓаЁ)зіЛЎЗжвРОнЕФОіВпЪїЁЃЕБШЛетЪЧжБОѕЕФШЯжЊЁЃЖјжБОѕЯдШЛВЛЪЪКЯзЊЛЏГЩГЬађЕФЪЕЯжЃЌЫљвдашвЊгавЛжжЖЈСПЕФПМВьРДЦРМлетСНПУЪїЕФадФмКУЛЕЁЃ
ОіВпЪїЕФЦРМлЫљгУЕФЖЈСППМВьЗНЗЈЮЊМЦЫуУПжжЛЎЗжЧщПіЕФаХЯЂьидівцЃКШчЙћОЙ§ФГИібЁЖЈЕФЪєадНјааЪ§ОнЛЎЗжКѓЕФаХЯЂьиЯТНЕзюЖрЃЌдђетИіЛЎЗжЪєадЪЧзюгХбЁдёЁЃ
4.3.2 ЪєадЛЎЗжбЁдё(МДЙЙдьОіВпЪї)ЕФвРОн ьиЃКаХЯЂТлЕФЕьЛљШЫЯуХЉЖЈвхЕФгУРДаХЯЂСПЕФЕЅЮЛЁЃМђЕЅРДЫЕЃЌьиОЭЪЧЁАЮоађЃЌЛьТвЁБЕФГЬЖШЁЃ
ЙЋЪНЃКH(X)=- ІВ pi * logpi, i=1,2, ... , nЃЌpiЮЊвЛИіЬиеїЕФИХТЪ
ЭЈЙ§МЦЫуРДРэНтЃК
1ЁЂдЪМбљБОЪ§ОнЕФьиЃК
бљР§змЪ§ЃК4 КУЦЛЙћЃК2 ЛЕЦЛЙћЃК2
ьиЃК-(1/2 * log(1/2) + 1/2 * log(1/2)) =1
аХЯЂьиЮЊ1БэЪОЕБЧАДІгкзюЛьТвЃЌзюЮоађЕФзДЬЌ
2ЁЂСНПХОіВпЪїЕФЛЎЗжНсЙћьидівцМЦЫу
Ъї1ЯШбЁA0зїЛЎЗжЃЌИїзгНкЕуаХЯЂьиМЦЫуШчЯТЃК 0,1вЖзгНкЕуга2Иіе§Р§ЃЌ0ИіИКР§ЁЃаХЯЂьиЮЊЃКe1 = -(2/2 * log(2/2) + 0/2
* log(0/2)) =0ЁЃ
2,3вЖзгНкЕуга0Иіе§Р§ЃЌ2ИіИКР§ЁЃаХЯЂьиЮЊЃКe2 = -(0/2 * log(0/2) + 2/2
* log(2/2)) =0ЁЃ
вђДЫбЁдёA0ЛЎЗжКѓЕФаХЯЂьиЮЊУПИізгНкЕуЕФаХЯЂьиЫљеМБШжиЕФМгШЈКЭЃКE = e1 * 2/4 + e2
* 2/4 = 0ЁЃ
бЁдёA0зіЛЎЗжЕФаХЯЂьидівцG(SЃЌA0) = S - E = 1 - 0 =1ЁЃ
ЪТЪЕЩЯЃЌОіВпЪївЖзгНкЕуБэЪОвбОЖМЪєгкЯрЭЌРрБ№ЃЌвђДЫаХЯЂьивЛЖЈЮЊ0ЁЃ
Ъї2ЯШбЁA1зїЛЎЗжЃЌИїзгНкЕуаХЯЂьиМЦЫуШчЯТЃК 0,2згНкЕуга1Иіе§Р§ЃЌ1ИіИКР§ЁЃаХЯЂьиЮЊЃКe1 = -(1/2 * log(1/2) + 1/2
* log(1/2)) = 1ЁЃ
1,3згНкЕуга1Иіе§Р§ЃЌ1ИіИКР§ЁЃаХЯЂьиЮЊЃКe2 = -(1/2 * log(1/2) + 1/2
* log(1/2)) = 1ЁЃ
вђДЫбЁдёA1ЛЎЗжКѓЕФаХЯЂьиЮЊУПИізгНкЕуЕФаХЯЂьиЫљеМБШжиЕФМгШЈКЭЃКE = e1 * 2/4 + e2
* 2/4 = 1ЁЃвВОЭЪЧЫЕЗжСЫИњУЛЗжвЛбљЃЁ
бЁдёA1зіЛЎЗжЕФаХЯЂьидівцG(SЃЌA1) = S - E = 1 - 1 = 0ЁЃ
вђДЫЃЌУПДЮЛЎЗжжЎЧАЃЌЮвУЧжЛашвЊМЦЫуГіаХЯЂьидівцзюДѓЕФФЧжжЛЎЗжМДПЩЁЃ
4.4 ЫуЗЈвЊЕу 4.4.1 жИЕМЫМЯы ОЙ§ОіВпЪєадЕФЛЎЗжКѓЃЌЪ§ОнЕФЮоађЖШдНРДдНЕЭЃЌвВОЭЪЧаХЯЂьидНРДдНаЁ
4.4.2 ЫуЗЈЪЕЯж ЪсРэГіЪ§ОнжаЕФЪєадЃЌБШНЯАДееФГЬиЖЈЪєадЛЎЗжКѓЕФЪ§ОнЕФаХЯЂьидівцЃЌбЁдёаХЯЂьидівцзюДѓЕФФЧИіЪєадзїЮЊЕквЛЛЎЗжвРОнЃЌШЛКѓМЬајбЁдёЕкЖўЪєадЃЌвдДЫРрЭЦЁЃ
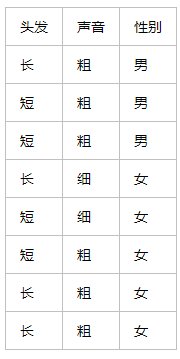
4.5 ОіВпЪїЗжРрЫуЗЈPythonЪЕеН 4.5.1 АИР§ашЧѓ ЮвУЧЕФШЮЮёОЭЪЧбЕСЗвЛИіОіВпЪїЗжРрЦїЃЌЪфШыЩэИпКЭЬхжиЃЌЗжРрЦїФмИјГіетИіШЫЪЧХжзгЛЙЪЧЪнзгЁЃ
ЫљгУЕФбЕСЗЪ§ОнШчЯТЃЌетИіЪ§ОнвЛЙВга8ИібљБОЃЌУПИібљБОга2ИіЪєадЃЌЗжБ№ЮЊЭЗЗЂКЭЩљвєЃЌЕкШ§СаЮЊадБ№БъЧЉЃЌБэЪОЁАФаЁБЛђЁАХЎЁБЁЃИУЪ§ОнБЃДцдк1.txtжаЁЃ
4.5.2 ФЃаЭЗжЮі ОіВпЪїЖдгкЁАЪЧЗЧЁБЕФЖўжЕТпМЕФЗжжІЯрЕБздШЛЁЃ
БОР§ОіВпЪїЕФШЮЮёЪЧевЕНЭЗЗЂЁЂЩљвєНЋЦфбљБОСНСНЗжРрЃЌздЖЅЯђЯТЙЙНЈОіВпЪїЁЃ
дкетРяЃЌЮвУЧСаГіСНжжЗНАИЃК
ЂйЯШИљОнЭЗЗЂХаЖЯЃЌШєХаЖЯВЛГіЃЌдйИљОнЩљвєХаЖЯЃЌгкЪЧЛСЫвЛЗљЭМЃЌШчЯТЃК
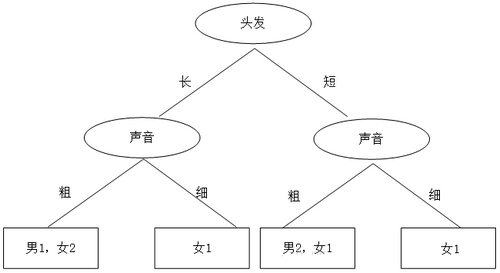
гкЪЧЃЌвЛИіМђЕЅЁЂжБЙлЕФОіВпЪїОЭетУДГіРДСЫЁЃЭЗЗЂГЄЁЂЩљвєДжОЭЪЧФаЩњЃЛЭЗЗЂГЄЁЂЩљвєЯИОЭЪЧХЎЩњЃЛЭЗЗЂЖЬЁЂЩљвєДжЪЧФаЩњЃЛЭЗЗЂЖЬЁЂЩљвєЯИЪЧХЎЩњЁЃ
Ђк ЯШИљОнЩљвєХаЖЯЃЌШЛКѓдйИљОнЭЗЗЂРДХаЖЯЃЌОіВпЪїШчЯТЃК
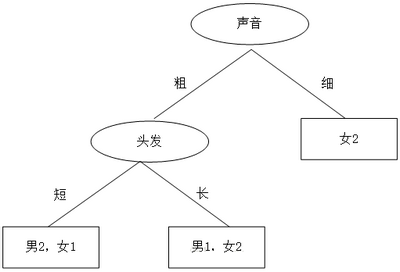
ФЧУДЮЪЬтРДСЫЃКЗНАИЂйКЭЗНАИЂкФФИіЕФОіВпЪїКУаЉЃПМЦЫуЛњзіОіВпЪїЕФЪБКђЃЌУцЖдЖрИіЬиеїЃЌИУШчКЮбЁФФИіЬиеїЮЊзюМбЖрЕУЛЎЗжЬиеїЃП
ЛЎЗжЪ§ОнМЏЕФДѓддђЪЧЃКНЋЮоађЕФЪ§ОнБфЕУИќМггаађЁЃ
ЮвУЧПЩвдЪЙгУЖржжЗНЗЈЛЎЗжЪ§ОнМЏЃЌЕЋЪЧУПжжЗНЗЈЖМгаИїздЕФгХШБЕуЁЃгкЪЧЮвУЧетУДЯыЃЌШчЙћЮвУЧФмВтСПЪ§ОнЕФИДдгЖШЃЌЖдБШАДВЛЭЌЬиеїЗжРрКѓЕФЪ§ОнИДдгЖШЃЌШєАДФГвЛЬиеїЗжРрКѓИДдгЖШМѕЩйЕФИќЖрЃЌФЧУДетИіЬиеїМДЮЊзюМбЗжРрЬиеїЁЃЮЊДЫЃЌClaude
ShannonЖЈвхСЫьиКЭаХЯЂдівцЃЌгУьиРДБэЪОаХЯЂЕФИДдгЖШЃЌьидНДѓЃЌдђаХЯЂдНИДдгЁЃаХЯЂдівцБэЪОСНИіаХЯЂьиЕФВюжЕЁЃ
ЪзЯШМЦЫуЮДЗжРрЧАЕФьиЃЌзмЙВга8ЮЛЭЌбЇЃЌФаЩњ3ЮЛЃЌХЎЩњ5ЮЛ
ьиЃЈзмЃЉ= -3/8*log2(3/8)-5/8*log2(5/8)=0.9544
НгзХЗжБ№МЦЫуЗНАИЂйКЭЗНАИЂкЗжРрКѓаХЯЂьиЁЃ
ЗНАИЂйЪзЯШАДЭЗЗЂЗжРрЃЌЗжРрКѓЕФНсЙћЮЊЃКГЄЭЗЗЂжага1Фа3ХЎЁЃЖЬЭЗЗЂжага2Фа2ХЎЁЃ
ьиЃЈГЄЗЂЃЉ= -1/4*log2(1/4)-3/4*log2(3/4)=0.8113
ьиЃЈЖЬЗЂЃЉ= -2/4*log2(2/4)-2/4*log2(2/4)=1
ьиЃЈЗНАИЂйЃЉ= 4/8*0.8113+4/8*1=0.9057 ЃЈ4/8ЮЊГЄЭЗЗЂга4ШЫЃЌЖЬЭЗЗЂга4ШЫЃЉ
аХЯЂдівцЃЈЗНАИЂйЃЉ= ьиЃЈзмЃЉ- ьиЃЈЗНАИЂйЃЉ= 0.9544 - 0.9057 = 0.0487
ЭЌРэЃЌАДЗНАИЂкЕФЗНЗЈЃЌЪзЯШАДЩљвєЬиеїРДЗжЃЌЗжРрКѓЕФНсЙћЮЊЃКЩљвєДжжага3Фа3ХЎЁЃЩљвєЯИжага0Фа2ХЎЁЃ
ьиЃЈЩљвєДжЃЉ= -3/6*log2(3/6)-3/6*log2(3/6)=1
ьиЃЈЩљвєЯИЃЉ= -2/2*log2(2/2)=0
ьиЃЈЗНАИЂкЃЉ= 6/8*1+2/8*0=0.75 ЃЈ6/8ЮЊЩљвєДжга6ШЫЃЌ2/8ЮЊЩљвєЯИга2ШЫЃЉ
аХЯЂдівцЃЈЗНАИЂкЃЉ= ьиЃЈзмЃЉ- ьиЃЈЗНАИЂкЃЉ= 0.9544 - 0.75 = 0.2087
АДееЗНАИЂкЕФЗНЗЈЃЌЯШАДЩљвєЬиеїЗжРрЃЌаХЯЂдівцИќДѓЃЌЧјЗжбљБОЕФФмСІИќЧПЃЌИќОпгаДњБэадЁЃ
вдЩЯОЭЪЧОіВпЪїID3ЫуЗЈЕФКЫаФЫМЯыЁЃ
4.5.3 pythonЪЕЯжID3ЫуЗЈ
from math import
log
import operator
def calcShannonEnt(dataSet): # МЦЫуЪ§ОнЕФьи(entropy)
numEntries=len(dataSet) # Ъ§ОнЬѕЪ§
labelCounts={}
for featVec in dataSet:
currentLabel=featVec[-1] # УПааЪ§ОнЕФзюКѓвЛИізжЃЈРрБ№ЃЉ
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel]=0
labelCounts[currentLabel]+=1 # ЭГМЦгаЖрЩйИіРрвдМАУПИіРрЕФЪ§СП
shannonEnt=0
for key in labelCounts:
prob=float(labelCounts[key])/numEntries # МЦЫуЕЅИіРрЕФьижЕ
shannonEnt-=prob*log(prob,2) # РлМгУПИіРрЕФьижЕ
return shannonEnt
def createDataSet1(): # ДДдьЪОР§Ъ§Он
dataSet = [['ГЄ', 'Дж', 'Фа'],
['ЖЬ', 'Дж', 'Фа'],
['ЖЬ', 'Дж', 'Фа'],
['ГЄ', 'ЯИ', 'ХЎ'],
['ЖЬ', 'ЯИ', 'ХЎ'],
['ЖЬ', 'Дж', 'ХЎ'],
['ГЄ', 'Дж', 'ХЎ'],
['ГЄ', 'Дж', 'ХЎ']]
labels = ['ЭЗЗЂ', 'Щљвє'] # СНИіЬиеї
return dataSet, labels
def splitDataSet(dataSet, axis, value): # АДФГИіЬиеїЗжРрКѓЕФЪ§Он
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet): # бЁдёзюгХЕФЗжРрЬиеї
numFeatures = len(dataSet[0]) - 1
print(numFeatures)
baseEntropy = calcShannonEnt(dataSet) # дЪМЕФьи
bestInfoGain = 0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
# АДЬиеїЗжРрКѓЕФьи
infoGain = baseEntropy - newEntropy # дЪМьигыАДЬиеїЗжРрКѓЕФьиЕФВюжЕ
if (infoGain > bestInfoGain): # ШєАДФГЬиеїЛЎЗжКѓЃЌьижЕМѕЩйЕФзюДѓЃЌдђДЮЬиеїЮЊзюгХЗжРрЬиеї
bestInfoGain = infoGain
bestFeature = i
return bestFeature
def majorityCnt(classList): # АДЗжРрКѓРрБ№Ъ§СПХХађЃЌБШШчЃКзюКѓЗжРрЮЊ2Фа1ХЎЃЌдђХаЖЈЮЊФаЃК
classCount={}
for vote in classList:
if vote not in classCount.keys():
classCount[vote]=0
classCount[vote]+=1
sortedClassCount = sorted(classCount.items(),
key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet, labels):
classList = [example[-1] for example in dataSet]
# РрБ№ЃКФаЛђХЎ
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
# бЁдёзюгХЬиеї
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}} # ЗжРрНсЙћвдзжЕфаЮЪНБЃДц
del(labels[bestFeat])
featValues = [example[bestFeat] for example
in dataSet]
#print(featValues)
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet,
bestFeat, value), subLabels)
return myTree
if __name__ == '__main__':
dataSet, labels = createDataSet1() # ДДдьЪОР§Ъ§Он
print(createTree(dataSet, labels)) # ЪфГіОіВпЪїФЃаЭНсЙћ |
етЪБКђЛсЪфГі
| {'Щљвє': {'ЯИ': 'ХЎ',
'Дж': {'ЭЗЗЂ': {'ГЄ': 'ХЎ', 'ЖЬ': 'Фа'}}}} |
4.5.4 ОіВпЪїЕФБЃДц вЛПУОіВпЪїЕФбЇЯАбЕСЗЪЧЗЧГЃКФЗбдЫЫуЪБМфЕФЃЌвђДЫЃЌОіВпЪїбЕСЗГіРДКѓЃЌПЩНјааБЃДцЃЌвдБудкдЄВтаТЕФЪ§ОнЪБжЛашвЊжБНгМгдибЕСЗКУЕФОіВпЪїМДПЩ
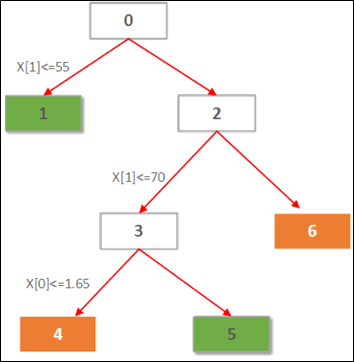
БОАИР§ЕФДњТыжавбОАбОіВпЪїЕФНсЙЙаДШыСЫtree.dotжаЁЃДђПЊИУЮФМўЃЌКмШнвзЛГіОіВпЪїЃЌЛЙПЩвдПДЕНОіВпЪїЕФИќЖрЗжРраХЯЂЁЃ
БОР§ЕФtree.dotШчЯТЫљЪОЃК
digraph Tree
{
[label="X[1] <= 55.0000\nentropy = 0.954434002925\nsamples
= 8", shape="box"] ;
[label="entropy = 0.0000\nsamples = 2\nvalue
= [ 2. 0.]", shape="box"] ;
-> 1 ;
[label="X[1] <= 70.0000\nentropy = 0.650022421648\nsamples
= 6", shape="box"] ;
-> 2 ;
[label="X[0] <= 1.6500\nentropy = 0.918295834054\nsamples
= 3", shape="box"] ;
-> 3 ;
[label="entropy = 0.0000\nsamples = 2\nvalue
= [ 0. 2.]", shape="box"] ;
-> 4 ;
[label="entropy = 0.0000\nsamples = 1\nvalue
= [ 1. 0.]", shape="box"] ;
-> 5 ;
[label="entropy = 0.0000\nsamples = 3\nvalue
= [ 0. 3.]", shape="box"] ;
-> 6 ;
} |
ИљОнетИіаХЯЂЃЌОіВпЪїгІИУГЄЕФШчЯТетИібљзгЃК
|









