| БрМЭЦМі: |
БОЮФРДздjianshuЃЌБОЮФЪЙгУЛњЦїбЇЯАШыУХОЕфР§згЬЉЬЙФсПЫКХГЫПЭЩњДцдЄВтРДЪЕМЪВйзїЃЌНЋЖдгІЕФЫуЗЈгІгУдкИјГіЕФЪ§ОнМЏЩЯНјаадЄВтЕФЯъЯИЙ§ГЬЁЃ |
|
ЫцзХШЫЙЄжЧФмЕФаЫЦ№ЃЌдНРДдНЖрЕФЛњЦїбЇЯААЎКУепМгШыСЫбЇЯАЕФааСаЃЌЕЋЪЧДѓЖрЪ§ЛњЦїГѕбЇепдкШыГЁЪБУдТЗСЫЃЌвђЮЊЫћУЧЯнШыСЫКкКазгЕФЗНЪНЃЌЪЙгУЫћУЧВЛУїАзЕФПЦбЇМЦЫуПтКЭЫуЗЈЁЃ
БОЮФИљОнзїепзюНќвЛИідТЕФбЇЯАаФЕУЃЌНсКЯвЛаЉЪщЩЯОЕфЕФбЇЯААИР§ЃЌзмНсвЛЯТвЛИідТЙІСІаЁАзЖдЛњЦїбЇЯАЕФШЯЪЖЁЃЯЃЭћФмдкЪЕМЪбЇЯАжаИјФуДјРДЦєЗЂЃЌзЃФњКУдЫЃЁ
Ъ§ОнПЦбЇ VS ЫцЛњ
вЛИіБШНЯОЕфЮЪЬтЃКдЄВтЖўдЊЪТМўЕФНсЙћЁЃ ЛЛОфЛАЫЕЃЌОЭЪЧЫќВЛЪЧЗЂЩњОЭЪЧУЛгаЗЂЩњЁЃ
Р§ШчЃЌФугЎСЫЛђепУЛгагЎЃЌФуЭЈЙ§СЫПМЪдЛђепУЛгаЭЈЙ§ПМЪдЃЌФуБЛНгЪмЛђепВЛБЛНгЪмЕШЁЃ ГЃМћЕФвЕЮёГЁОАОЭЪЧгУЛЇСїЪЇЛђСєДцЃЌСэЯжЪЕАИР§ЪЧвНСЦЪТМўЕФЫРЭіТЪЛђЩњДцТЪЗжЮіЁЃЖўдЊЪТМўВњЩњСЫвЛИігаШЄЕФЯжЯѓЃЌвђЮЊЮвУЧЭГМЦжЊЕРЃЌЫцЛњВТВтгІИУДяЕН50ЃЅЕФзМШЗТЪЃЌЖјВЛашвЊДДНЈвЛИіЕЅвЛЕФЫуЗЈЛђБраДвЛааДњТыЁЃетЦЊЮФеТЃЌЮвЪЙгУЛњЦїбЇЯАШыУХОЕфР§згTitanicЃКMachine
Learning from DisasteЃЈЬЉЬЙФсПЫКХГЫПЭЩњДцдЄВтЃЉРДЪЕМЪВйзїЃЌНЋЖдгІЕФЫуЗЈгІгУдкИјГіЕФЪ§ОнМЏЩЯНјаадЄВтЁЃ
Ъ§ОнЙЄзїЕФЛљБОСїГЬ
ЖЈвхЮЪЬт: ЮвУЧЪзЯШашвЊНтОіЕФЪЧЮвУЧНЋУцСйвЛИіЪВУДЮЪЬтЃЌашвЊЮвУЧзіЪВУДЃЌЫзЛАЫЕЕФФЅЕЖВЛЮѓПГВёЙЄЃЌЪзЯШПДЧхЖдЪжЪЧЫВХФмгаЕФЗХЪИЁЃ
ЪеМЏЪ§Он: ИљОнШЗЖЈЕФЪ§ОнЗжЮіЖдЯѓЃЌГщЯѓГідкЪ§ОнЗжЮіжаЫљашвЊЕФЬиеїаХЯЂЃЌШЛКѓбЁдёКЯЪЪЕФаХЯЂЪеМЏЗНЗЈЃЌНЋЪеМЏЕНЕФаХЯЂДцШыЪ§ОнПтЁЃЖдгкКЃСПЪ§ОнЃЌбЁдёвЛИіКЯЪЪЕФЪ§ОнДцДЂКЭЙмРэЕФЪ§ОнВжПтЪЧжСЙиживЊЕФЁЃ
зМБИЯћЗбЪ§Он: АбВЛЭЌРДдДЁЂИёЪНЁЂЬиЕуаджЪЕФЪ§ОндкТпМЩЯЛђЮяРэЩЯгаЛњЕиМЏжаЃЌДгЖјЮЊЦѓвЕЬсЙЉШЋУцЕФЪ§ОнЙВЯэЁЃШчЙћжДааЖрЪ§ЕФЪ§ОнЭкОђЫуЗЈЃЌМДЪЙЪЧдкЩйСПЪ§ОнЩЯвВашвЊКмГЄЕФЪБМфЃЌЖјзіЩЬвЕдЫгЊЪ§ОнЭкОђЪБЪ§ОнСПЭљЭљЗЧГЃДѓЁЃЪ§ОнЙцдМММЪѕПЩвдгУРДЕУЕНЪ§ОнМЏЕФЙцдМБэЪОЃЌЫќаЁЕУЖрЃЌЕЋШдШЛНгНќгкБЃГждЪ§ОнЕФЭъећадЃЌВЂЧвЙцдМКѓжДааЪ§ОнЭкОђНсЙћгыЙцдМЧАжДааНсЙћЯрЭЌЛђМИКѕЯрЭЌЁЃдкЪ§ОнПтжаЕФЪ§ОнгавЛаЉЪЧВЛЭъећЕФЃЈгааЉИааЫШЄЕФЪєадШБЩйЪєаджЕЃЉЁЂКЌдыЩљЕФЃЈАќКЌДэЮѓЕФЪєаджЕЃЉЃЌВЂЧвЪЧВЛвЛжТЕФЃЈЭЌбљЕФаХЯЂВЛЭЌЕФБэЪОЗНЪНЃЉЃЌвђДЫашвЊНјааЪ§ОнЧхРэЃЌНЋЭъећЁЂе§ШЗЁЂвЛжТЕФЪ§ОнаХЯЂДцШыЪ§ОнВжПтжаЁЃВЛШЛЃЌЭкОђЕФНсЙћЛсВюЧПШЫвтЁЃЭЈЙ§ЦНЛЌОлМЏЁЂЪ§ОнИХЛЏЁЂЙцЗЖЛЏЕШЗНЪННЋЪ§ОнзЊЛЛГЩЪЪгУгкЪ§ОнЭкОђЕФаЮЪНЁЃЖдгкгааЉЪЕЪ§аЭЪ§ОнЃЌЭЈЙ§ИХФюЗжВуКЭЪ§ОнЕФРыЩЂЛЏРДзЊЛЛЪ§ОнвВЪЧживЊЕФвЛВНЁЃ
ЬНЫїадЗжЮі: ИљОнЪ§ОнВжПтжаЕФЪ§ОнаХЯЂЃЌбЁдёКЯЪЪЕФЗжЮіЙЄОпЃЌгІгУЭГМЦЗНЗЈЁЂЪТР§ЭЦРэЁЂОіВпЪїЁЂЙцдђЭЦРэЁЂФЃК§МЏЃЌЩѕжСЩёОЭјТчЁЂвХДЋЫуЗЈЕФЗНЗЈДІРэаХЯЂЃЌЕУГігагУЕФЗжЮіаХЯЂЁЃ
Ъ§ОнНЈФЃ: ЯёУшЪіадКЭЭЦТладЭГМЦЪ§ОнвЛбљЃЌЪ§ОнНЈФЃПЩвдзмНсЪ§ОнЛђдЄВтЮДРДЕФНсЙћЁЃ
ФњЕФЪ§ОнМЏКЭдЄЦкНсЙћНЋОіЖЈПЩЙЉЪЙгУЕФЫуЗЈЁЃ живЊЕФЪЧвЊМЧзЁЃЌЫуЗЈЪЧЙЄОпЃЌЖјВЛЪЧФЇеШЁЃ ФуШдШЛБиаыЪЧжЊЕРШчКЮЮЊЙЄзїбЁдёе§ШЗЕФЙЄОпЕФЙЄНГЁЃ
вЛИіБШгїОЭЪЧвЊЧѓгаШЫИјФувЛАбЗЩРћЦжЬъаыЕЖЃЌЫћУЧИјФувЛАбТнЫПЕЖЛђепвЛАбДИзгЁЃ ГфЦфСПЃЌЫќЯдЪОЭъШЋШБЗІСЫНтЁЃ
зюдуИтЕФЪЧЃЌетЪЙЕУЯюФПВЛПЩФмЭъГЩЁЃ Ъ§ОнНЈФЃвВЪЧШчДЫЁЃ ДэЮѓЕФФЃаЭПЩФмЕМжТзюВюЕФБэЯжЃЌЩѕжСЛсЕМжТДэЮѓЕФНсТлЁЃ
ФЃаЭбщжЄКЭФЃаЭЪЙгУ: гУбЕСЗЪ§ОнЖдФЃаЭНјаабЕСЗжЎКѓЃЌОЭПЩвдгУгкдЄВтЪ§ОнЁЃ
ЛАВЛЖрЫЕЃЌЯТУцЮвУЧе§ЪННјШые§ЬтЁЃ
ЕквЛВНЃКЮЪЬтУшЪі
етИіЯюФПРяЃЌЮвУЧашвЊзіЕФЪЧЩшМЦвЛИіЫуЗЈРДдЄВтЬЉЬЙФсПЫКХГЫПЭЕФЩњДцНсЙћЁЃ
ЯюФП ИХРР:
ЬЉЬЙФсПЫКХЕФГСУЛЪЧРњЪЗЩЯзюГєУћебзХЕФКЃФбЪТЙЪжЎвЛЁЃ 1912Фъ4дТ15ШеЃЌдкЪзКНЦкМфЃЌЬЉЬЙФсПЫКХзВЩЯвЛзљБљЩНКѓГСУЛЃЌ2224УћГЫПЭКЭЛњзщШЫдБжага1502ШЫгіФбЁЃ
етвЛЫЪШЫЬ§ЮХЕФБЏОче№КГСЫЙњМЪЩчЛсЃЌВЂЕМжТСЫИќКУЕФДЌВААВШЋЬѕР§ЁЃ
ГСДЌЕМжТЩњУќЫ№ЪЇЕФдвђжЎвЛЪЧГЫПЭКЭДЌдБУЛгазуЙЛЕФОШЩњЭЇЁЃ ЫфШЛавДцЯТРДЕФдЫЦјгавЛаЉвђЫиЃЌЕЋвЛаЉШЫБШЦфЫћШЫИќгаПЩФмЩњДцЃЌБШШчИОХЎЃЌЖљЭЏКЭЩЯВуНзМЖЁЃ
дкетИіЬєеНжаЃЌЮвУЧвЊЧѓФуЭъГЩЖдЪВУДбљЕФШЫПЩФмЩњДцЕФЗжЮіЁЃ ЬиБ№ЪЧЃЌЮвУЧвЊЧѓФудЫгУЛњЦїбЇЯАЕФЙЄОпРДдЄВтФФаЉГЫПЭдкджФбжаЛсавДцЁЃ
ЖЭСЖММФм
ЖўЗжРр
Python ЛљДЁ
ЕкЖўВН: ЪеМЏЪ§Он
Ъ§ОнМЏЧыЕНСЌНгДІЯТди Titanic: Machine Learning
from Disaster
ЕкШ§ВН: НЈФЃдЄВт
етвЛВННЋЖдЪ§ОнНјааЧхЯДЁЂећРэЃЌДІРэПежЕЕШвЛЯЕСаВйзїЁЃ
3.1 ЯЕЭГЛЗОГ
import sys
print("Python version: {}". format(sys.version))
import pandas as pd
print("pandas version: {}". format(pd.__version__))
import matplotlib
print("matplotlib version: {}". format(matplotlib.__version__))
import numpy as np
print("NumPy version: {}". format(np.__version__))
import scipy as sp
print("SciPy version: {}". format(sp.__version__))
import IPython
from IPython import display
print("IPython version: {}". format(IPython.__version__))
import sklearn
print("scikit-learn version: {}". format(sklearn.__version__))
import random
import time
import warnings
warnings.filterwarnings('ignore') |
Python version: 2.7.10 (default, Oct 23 2015, 19:19:21)
[GCC 4.2.1 Compatible Apple LLVM 7.0.0 (clang-700.0.59.5)]
pandas version: 0.21.1
matplotlib version: 2.1.1
NumPy version: 1.13.3
SciPy version: 1.0.0
IPython version: 5.5.0
scikit-learn version: 0.19.1
3.11 МгдиЛњЦїбЇЯАПт
етРяжївЊЪЙгУpythonЕФscikit-learn Ъ§ОнЛњЦїбЇЯАПтРДНјааНЈФЃвдМАmatplotlibЁЂseabornЭМаЮПтРДНјааПЩЪгЛЏВйзїЁЃ
from sklearn
import svm, tree, linear_model, neighbors, naive_bayes,
ensemble, discriminant_analysis, gaussian_process
from xgboost import XGBClassifier
from sklearn.preprocessing import OneHotEncoder,
LabelEncoder
from sklearn import feature_selection
from sklearn import model_selection
from sklearn import metrics
#ПЩЪгЛЏ
import matplotlib as mpl
import matplotlib.pyplot as plt
import matplotlib.pylab as pylab
import seaborn as sns
from pandas.tools.plotting import scatter_matrix
%matplotlib inline
mpl.style.use('ggplot')
sns.set_style('white')
pylab.rcParams['figure.figsize'] = 12,8 |
3.2 Ъ§ОнЙлВь
етЪЧЮвУЧУцЯђЪ§ОнЕФЕквЛВНЃЌдкзіНјааЪ§ОнНЈФЃЗжЮіжЎЧАЃЌЮвУЧЪзЯШЕУЙлВьЪ§ОнГЄЪВУДбљЃЌОпгаЪВУДбљЕФЬиЕуЃЌЖдФУЕНЪжЕФЪ§ОнЮвУЧЕФФПБъЪЧвЊзіЪВУДЕШНјааГѕВНШЯЪЖЃЌЮвУЧЯШЕМШыЪ§ОнНјааЙлВьЁЃ
data_raw = pd.read_csv('./Titanic/input/train.csv')
data_val = pd.read_csv('./Titanic/input/test.csv')
data1 = data_raw.copy(deep = True)
data_cleaner = [data1, data_val]
print (data_raw.info())
data_raw.sample(10)
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
PassengerId 891 non-null int64
Survived 891 non-null int64
Pclass 891 non-null int64
Name 891 non-null object
Sex 891 non-null object
Age 714 non-null float64
SibSp 891 non-null int64
Parch 891 non-null int64
Ticket 891 non-null object
Fare 891 non-null float64
Cabin 204 non-null object
Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.6+ KB |
3.3 Ъ§Онаое§ЁЂПежЕДІРэЁЂаТНЈЬиеїЁЂЪ§ОнзЊЛЛ
етвЛВНЮвУЧашвЊНјааЩЯЪіЫФВНДѓжТВйзїЃЌашвЊетбљзіЕФдвђЗжБ№ЮЊЃК
** аое§ЧхЯД**ЃКДгЩЯУцЕФдЪМЪ§ОнЭГМЦаХЯЂРяПЩвдПДЕНЃЌЦфжагаКмЖрДэЮѓЛђепВЛКЯРэЕФЪ§ОнЃЌБШШчAgeЁЂCabinФЧСНСаОЭгаКмЖрШБЪЇжЕЃЌЛЙгаШчЙћЪ§ОнжагавЛаЉЦцвьжЕЃЌБШШчгавЛИіГЫПЭИіФъСфЬиБ№ДѓЃЌПЩФмЮЊ300ЖрЩѕжСИќДѓЃЌетбљЕФЪ§ОнДцдкОЭПЩФмЛсИјЮвУЧЕФФЃаЭдьГЩИЩШХЃЌЮвУЧбЁдёШЅаоИДетбљЕФвЛаЉЪ§ОнЃЌЪЧвђЮЊЮвУЧЛсШЯЮЊЪ§ОнаоИДжЎКѓЖдЮвУЧФЃаЭЕФОЋШЗадДјРДвЛЖЈЕФЬсЩ§ЃЌШЛЖјЪТЪЕвВШБЪЇЛсЪЧетбљЁЃ
ПежЕДІРэЃК дкCabinЃЌAge ЕШзжЖЮЃЌКЌгавЛаЉПежЕЃЌетаЉЪ§ОнПЩФмЪЧвђЮЊУЛЗЈЪеМЏЕНГЫПЭЕФФГаЉаХЯЂЕМжТЃЌетаЉМЧТМЕФДІРэЗНЪНЭЈГЃБШНЯжБЙлЕФгаСНжжЗНЗЈЃЌвЛИізюМђЕЅЕФОЭЪЧжБНгАбКЌгаПежЕЕФМЧТМЩОЕєЃЌСэЭтвЛИіЪЧАДФГжжЙцдђЖдШБЪЇЕФжЕНјааЬюГфЁЃЕквЛжжЗНЗЈЭЈГЃВЛЪЧКмЭЦМіЕФЃЌвђЮЊетбљЕФЛАЛсЫ№ЪЇКмЖрбЕСЗЪ§ОнЃЌгаЪБзжЖЮЕФШБЪЇвВдкФГжжГЬЖШЩЯЬсЙЉСЫвЛЖЈЕФаХЯЂЃЌЖјЧвЕБбЕСЗЪ§ОнжаДѓСПМЧТМКЌгаПежЕЕФЧщПіЯТАбетаЉМЧТМЩОГ§ЛсЕМжТЮвУЧЕФбЕСЗЪ§ОнВЛзуЖјв§ЗЂФЃаЭОЋЖШДяВЛЕНдЄЦкЕФаЇЙћЁЃШчЙћЪЧЬюГфМЧТМЕФЛАЗНЗЈгаКмЖрЃЌБШНЯГЃМћЕФгаОљжЕЃЌжаЮЛЪ§ЕШЬюГфЗНЪНЁЃ
аТНЈЬиеї: ЮвУЧПЩвдРћгУЯжгаЕФвЛаЉЬиеїВњЩњвЛаЉИќЖрЕФЬиеїЁЃ
Ъ§ОнзЊЛЛЃКДгдЪМЪ§ОнЩЯПДЃЌгаКмЖрзжЗћРрЬиеїЃЌЭЈГЃЮвУЧдкНЋЪ§ОнЪфШыФЃаЭЕФЪБКђИќЯЃЭћЪЧгУЪ§жЕаЭЕФЬиеїЃЌдкЩЯЪіЪ§ОнМЏжаЮвУЧНЋгУЗжРрБъЧЉРДзЊЛЛЦфжавЛаЉЬиеїЁЃ
3.4 ЧхРэЪ§Он
for dataset
in data_cleaner:
dataset['Age'].fillna(dataset['Age'].median(),
inplace = True)
dataset['Embarked'].fillna(dataset['Embarked'].mode()[0],
inplace = True)
dataset['Fare'].fillna(dataset['Fare'].median(),
inplace = True)
drop_column = ['PassengerId','Cabin', 'Ticket']
data1.drop(drop_column, axis=1, inplace = True)
print(data1.isnull().sum())
print("-"*10)
print(data_val.isnull().sum())
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Fare 0
Embarked 0
dtype: int64
----------
PassengerId 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 327
Embarked 0
dtype: int64 |
#бЕСЗЪ§ОнДІРэ
for dataset in data_cleaner:
dataset['FamilySize'] = dataset ['SibSp'] + dataset['Parch']
+ 1
dataset['IsAlone'] = 1
dataset['IsAlone'].loc[dataset['FamilySize'] >
1] = 0
dataset['Title'] = dataset['Name'].str.split(",
", expand=True)[1].str.split(".",
expand=True)[0]
dataset['FareBin'] = pd.qcut(dataset['Fare'],
4)
dataset['AgeBin'] = pd.cut(dataset['Age'].astype(int),
5)
stat_min = 10
title_names = (data1['Title'].value_counts() <
stat_min)
data1['Title'] = data1['Title'].apply(lambda x:
'Misc' if title_names.loc[x] == True else x)
print(data1['Title'].value_counts())
print("-"*10)
#дйПДвЛЯТЮвУЧЕФЪ§Он
data1.info()
data_val.info()
data1.sample(10) |
3.5 ИёЪНзЊЛЛ
етРяЮвУЧЛсАбЯрЙиЬиеїзЊЛЛГЩРрБ№БъЧЉЃЌШЛКѓАбЗжРрЪ§ОнзЊЛЛРГЩЖрСаЬиеїЪ§ОнЁЃ
label = LabelEncoder()
for dataset in data_cleaner:
dataset['Sex_Code'] = label.fit_transform(dataset['Sex'])
dataset['Embarked_Code'] = label.fit_transform(dataset['Embarked'])
dataset['Title_Code'] = label.fit_transform(dataset['Title'])
dataset['AgeBin_Code'] = label.fit_transform(dataset['AgeBin'])
dataset['FareBin_Code'] = label.fit_transform(dataset['FareBin'])
Target = ['Survived']
data1_x = ['Sex','Pclass', 'Embarked', 'Title','SibSp',
'Parch', 'Age', 'Fare', 'FamilySize', 'IsAlone']
data1_x_calc = ['Sex_Code','Pclass', 'Embarked_Code',
'Title_Code','SibSp', 'Parch', 'Age', 'Fare']
data1_xy = Target + data1_x
#print('Original X Y: ', data1_xy, '\n')
data1_x_bin = ['Sex_Code','Pclass', 'Embarked_Code',
'Title_Code', 'FamilySize', 'AgeBin_Code', 'FareBin_Code']
data1_xy_bin = Target + data1_x_bin
#print('Bin X Y: ', data1_xy_bin, '\n')
data1_dummy = pd.get_dummies(data1[data1_x])
data1_x_dummy = data1_dummy.columns.tolist()
data1_xy_dummy = Target + data1_x_dummy
#print('Dummy X Y: ', data1_xy_dummy, '\n')
data1_dummy.head() |

ОЙ§ЩЯЪіДІРэжЎКѓЃЌЮвУЧЕФбЕСЗЪ§ОнвЊБШдЪМЪ§ОнећЦыЙцЗЖСЫКмЖрЁЃ
3.6 В№ЗжбЕСЗЪ§ОнКЭВтЪдЪ§Он
ЮЊСЫЗРжЙЮвУЧЕФФЃаЭЗЂЩњЙ§ФтКЯЛђепЧЗФтКЯжЎРрЮЪЬтЃЈОпЬхЖЈвхздааАйЖШЃЉЃЌЮвУЧашвЊНЋЪ§ОнНјааВ№ЗжЃЌгУвЛВПЗжЪ§ОнНјаабЕСЗЃЌШЛКѓгУЪЃгрЕФЪ§ОнНјаазМШЗадбщжЄЃЌетжжвВЪЧМрЖНбЇЯАФЃаЭЬигаЕФЃЌетРяЮвУЧгУsklearn
ПтРяЯжгаЕФКЏЪ§НјааВ№ЗжЃЌЭЈГЃбЕСЗМЏКЭВтЪдМЏЕФЛЎЗжБШР§ЮЊ75/25
#split the data
set
train1_x, test1_x, train1_y, test1_y = model_selection.train_test_split(data1[data1_x_calc],
data1[Target], random_state = 0)
train1_x_bin, test1_x_bin, train1_y_bin, test1_y_bin
= model_selection.train_test_split(data1[data1_x_bin],
data1[Target] , random_state = 0)
train1_x_dummy, test1_x_dummy, train1_y_dummy,
test1_y_dummy = model_selection.train_test_split
(data1_dummy[data1_x_dummy], data1[Target], random_state
= 0)
print("Data1 Shape: {}".format(data1.shape))
print("Train1 Shape: {}".format(train1_x.shape))
print("Test1 Shape: {}".format(test1_x.shape))
train1_x_bin.head() |
Data1 Shape: (891, 19)
Train1 Shape: (668, 8)
Test1 Shape: (223, 8)
3.7 ПЩЪгЛЏЪ§ОнНјааЭГМЦЙлВт
дкЮвУЧАбЪ§ОнЧхРэЭъГЩжЎКѓЃЌЮвУЧПЩвдЭЈЙ§ПЩЪгЛЏЙЄОпНЋЮвУЧЕФФПБъСаКЭИїЬиеїЪєадЕФЙиЯЕДђгЁГіРДПДПДЯрЛЅЙиЯЕЃЌетбљвдБуЮвУЧЖдЪжжаЕФЪ§ОнгаИіИќжБЙлЕФИаОѕЁЃ
ЯТУцЮвУЧжЛОйМИИіР§згЃЌЦфЫћЕФЬиеїЙиЯЕПЩвдееР§ДђгЁГіРДЁЃ
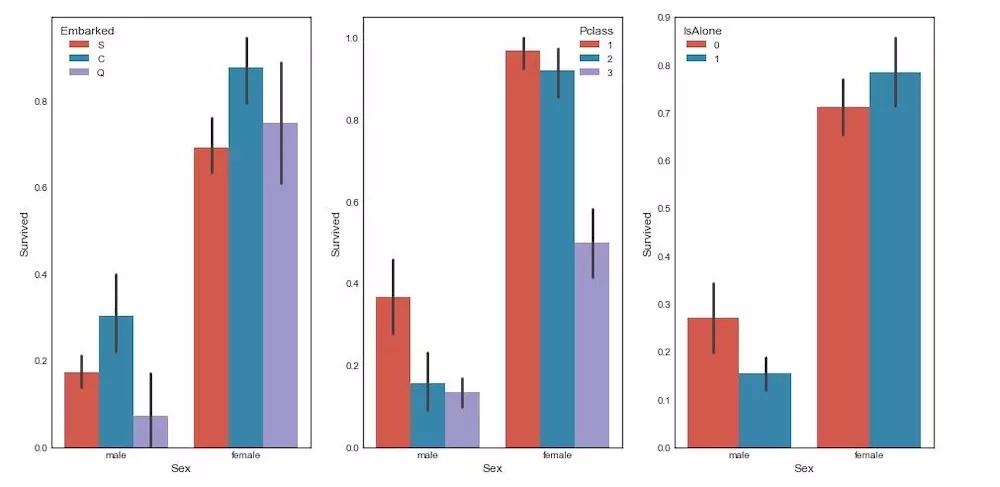
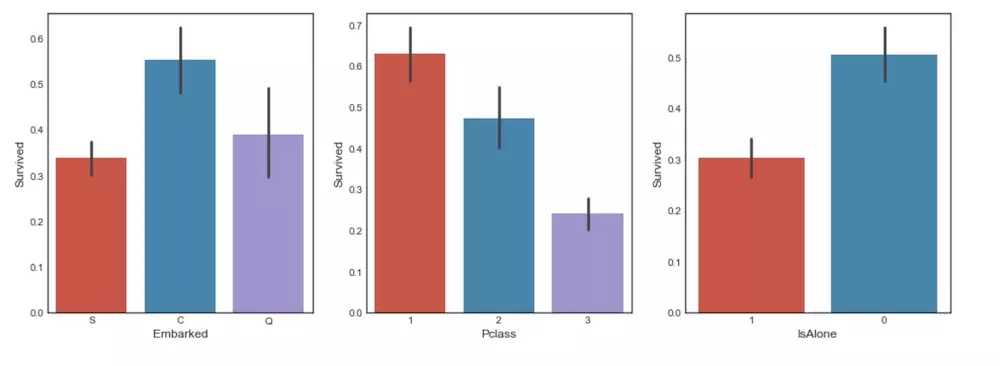
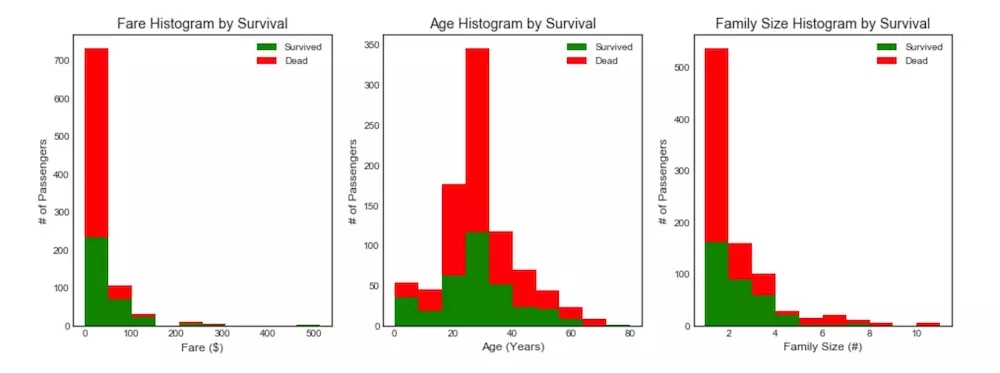
data1ећРэКѓЕФЪ§ОнаЗНВюОиеѓШШСІЭМ
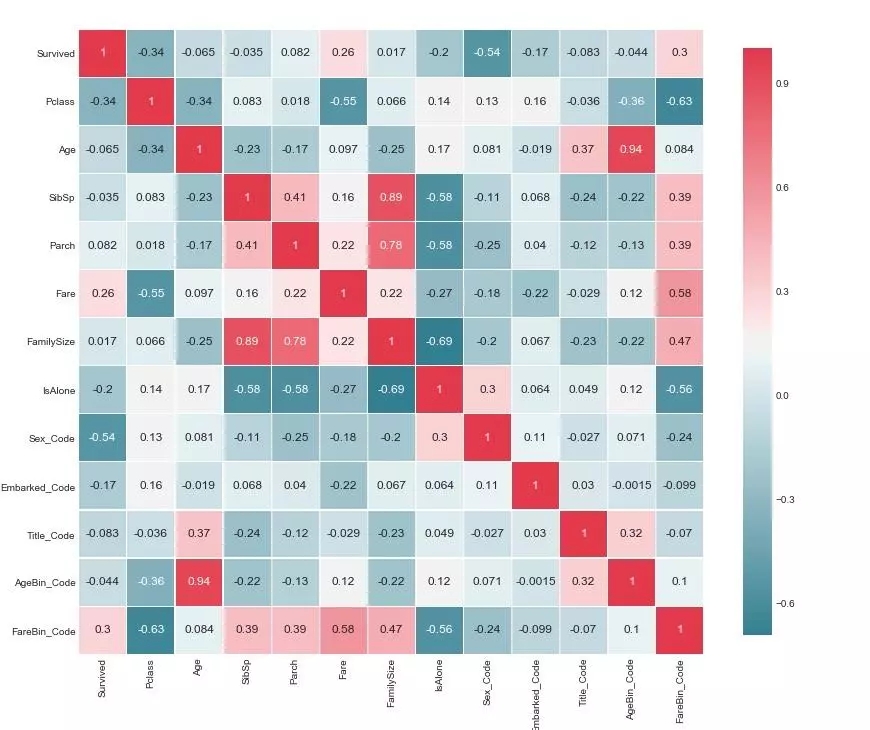
3.7 НЈФЃЗжЮі
дкОЙ§ЩЯЪіВНжшЖдФЃаЭЪ§ОнНјааДІРэжЎКѓЃЌЪ§ОнвбОЛљБОПЩгУЃЌЭЌЪБЭЈЙ§ПЩЪгЛЏЪжЖЮЖдЪ§ОнНјаадЄРРЖдећЬхЕФЗжВМгаИіДѓжТАбЮеЃЌНгЯТРДЕФЙЄзїОЭЪЧНЈСЂФЃаЭЃЌетвЛВНЭЈГЃашвЊвЛаЉМЦЫуЛњЁЂЪ§бЇЁЂЩЬвЕЗжЮіЕШЗНУцЕФжЊЪЖЃЌЪєгкЖрбЇПЦЕФвЛИіНЛВцЃЌВЛЙ§авПїгаКмЖрЯжГЩЕФЙЄОпАќвбОАяЮвУЧЗтзАКУСЫКмЖрЫуЗЈЃЌвђДЫЮвУЧжЛашвЊМИааДњТыЩѕжСОЭФмНЋФЃаЭНЈСЂГіРДЁЃЭЈГЃЛњЦїбЇЯАПЩДѓжТЗжЮЊЃКМрЖНбЇЯАЁЂЗЧМрЖНбЇЯАЁЂЧПЛЏбЇЯАЃЌетРяЮвУЧЕФЮЪЬтНЋЙщНсЮЊМрЖНбЇЯАЮЪЬтЁЃШЛЖјЖдгкЭЌвЛИіЪ§ОнЃЌЮвУЧгаКмЖрЫуЗЈФЃаЭПЩвдбЁдёЃЌОпЬхЪВУДбљЕФФЃаЭЪЪКЯЪдбщЕФЪ§ОнЃЌетИіЕУИљОнгУЛЇЕФЪ§ОнЬиеїРДОіЖЈЃЌЬєбЁФЃаЭЕФЙ§ГЬвВЪЧвЛИіОбщвЊЧѓКмИпЕФВНжшЁЃетРяЮвУЧЬєГівЛаЉКмГЃМћЕФЫуЗЈЖМбЕСЗвЛЯТШЛКѓБШНЯдЄВтЕФНсЙћЃЌЯъЯИЕФЫуЗЈЪЙгУЧыВЮМћЖдгІЕФscikit-learnЮФЕЕЁЃ
MLA = [
ensemble.AdaBoostClassifier(),
ensemble.BaggingClassifier(),
ensemble.ExtraTreesClassifier(),
ensemble.GradientBoostingClassifier(),
ensemble.RandomForestClassifier(),
gaussian_process.GaussianProcessClassifier(),
linear_model.LogisticRegressionCV(),
linear_model.PassiveAggressiveClassifier(),
linear_model.RidgeClassifierCV(),
linear_model.SGDClassifier(),
linear_model.Perceptron(),
#ЦгЫиБДвЖЫЙ
naive_bayes.BernoulliNB(),
naive_bayes.GaussianNB(),
neighbors.KNeighborsClassifier(),
#жЇГжЯђСПЛњ
svm.SVC(probability=True),
svm.NuSVC(probability=True),
svm.LinearSVC(),
#ОіВпЪї
tree.DecisionTreeClassifier(),
tree.ExtraTreeClassifier(),
discriminant_analysis.LinearDiscriminantAnalysis(),
discriminant_analysis.QuadraticDiscriminantAnalysis(),
XGBClassifier()
]
#бЕСЗМЏВ№Зж
cv_split = model_selection.ShuffleSplit(n_splits
= 10, test_size = .3, train_size = .6, random_state
= 0 )
#ДДНЈЖдБШНсЙћМЏ
MLA_columns = ['MLA Name', 'MLA Parameters','MLA
Train Accuracy Mean', 'MLA Test Accuracy Mean',
'MLA Test Accuracy 3*STD' ,'MLA Time']
MLA_compare = pd.DataFrame(columns = MLA_columns)
MLA_predict = data1[Target]
row_index = 0
for alg in MLA:
#ЩшжУВЮЪ§
MLA_name = alg.__class__.__name__
MLA_compare.loc[row_index, 'MLA Name'] = MLA_name
MLA_compare.loc[row_index, 'MLA Parameters']
= str(alg.get_params())
#НЛВцбщжЄ
cv_results = model_selection.cross_validate(alg,
data1[data1_x_bin], data1[Target], cv = cv_split)
MLA_compare.loc[row_index, 'MLA Time'] = cv_results['fit_time'].mean()
MLA_compare.loc[row_index, 'MLA Train Accuracy
Mean'] = cv_results['train_score'].mean()
MLA_compare.loc[row_index, 'MLA Test Accuracy
Mean'] = cv_results['test_score'].mean()
MLA_compare.loc[row_index, 'MLA Test Accuracy
3*STD'] = cv_results['test_score'].std()*3
alg.fit(data1[data1_x_bin], data1[Target])
MLA_predict[MLA_name] = alg.predict(data1[data1_x_bin])
row_index+=1
MLA_compare.sort_values(by = ['MLA Test Accuracy
Mean'], ascending = False, inplace = True)
MLA_compare |
дЫааНсЙћЃК
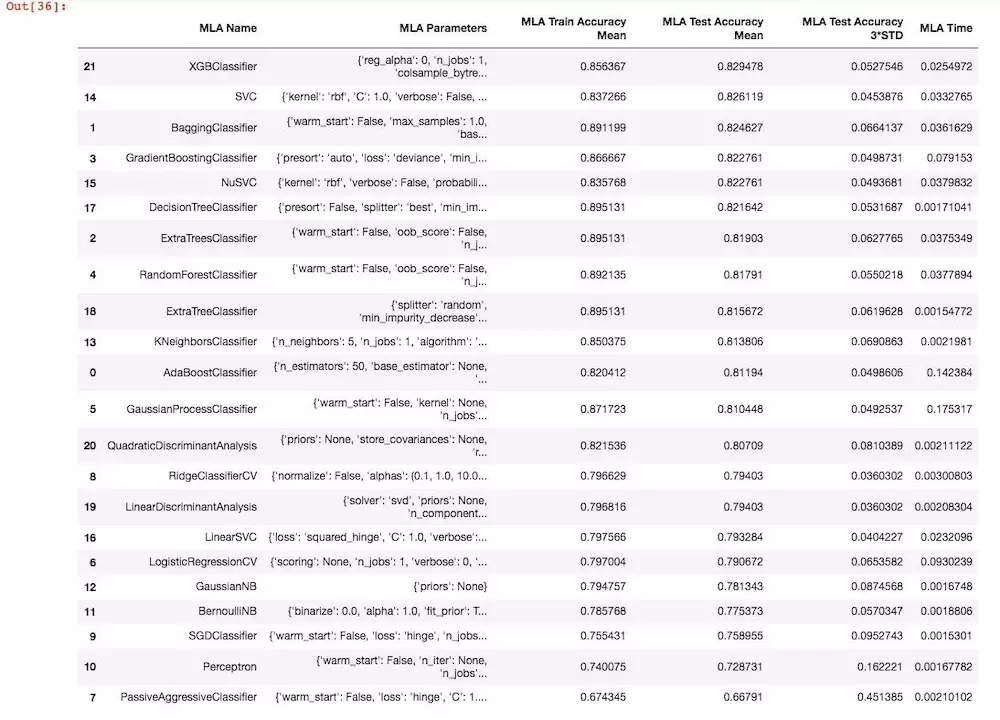
ећЬхЩЯПДЃЌXGBClassifier ЕФЪЕМЪдЄВтОЋЖШзюИпЃЌЖјЦфжагаМИИіЫуЗЈФЃаЭдкбЕСЗЪ§ОнМЏЩЯДяЕНСЫ0.895131ЕФзюИпОЋЖШЃЌЕЋЪЧдкВтЪдЪ§ОнМЏКЯЩЯЕФБэЯжБШXGBClassifier
ЗжРрЦїВюСЫЩдЮЂвЛЕуЕуЁЃ
3.8 аЁНсЗжЮі
ОЙ§ГѕВНЕФЪ§ОнДІРэЁЂЗжЮіЃЌЮвУЧЕФФЃаЭНЋдЄВте§ШЗЖШДгЫцЛњЕФ0.5ЬсИпЕНСЫ82%ЃЌетвбОЪЧвЛИіЗЧГЃДѓЕФНјВНСЫЃЌШЛЖјЮвУЧПЩФмЛсЯыЃЌЛЙгаУЛгаЪВУДЗНЗЈЖдЮвУЧЕФФЃаЭОЋЖШИќНјвЛВНЬсИпЃПетИіД№АИЪЧПЯЖЈЕФЃЌВЛЙ§етРядлУЧОЭднЪБВЛНщЩмСЫЃЌЛЙУЛбЇЕНЁЃЁЃЁЃЮћЮћЁЃетОЭЪЧзюНќбЇЯАЕФвЛаЉЛљБОЕФЛњЦїбЇЯАЗНУцЯрЙиЕФжЊЪЖСЫЃЌвдКѓЛЙЕУОГЃЯђДѓХЃУЧбЇЯАЃЁ
|









