| БрМЭЦМі: |
БОЮФРДздгкМђЪщЃЌБОЮФжївЊНщЩмСЫЖдYOLOдРэНјааФПБъМьВтЃЌвдМАyolov2ЭјТчНсЙЙЮЊШЋОэЛ§ЭјТчFCNЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
|
|
1 YOLO
ДДаТЕуЃК ЖЫЕНЖЫбЕСЗМАЭЦЖЯ + ИФИяЧјгђНЈвщПђЪНФПБъМьВтПђМм + ЪЕЪБФПБъМьВт
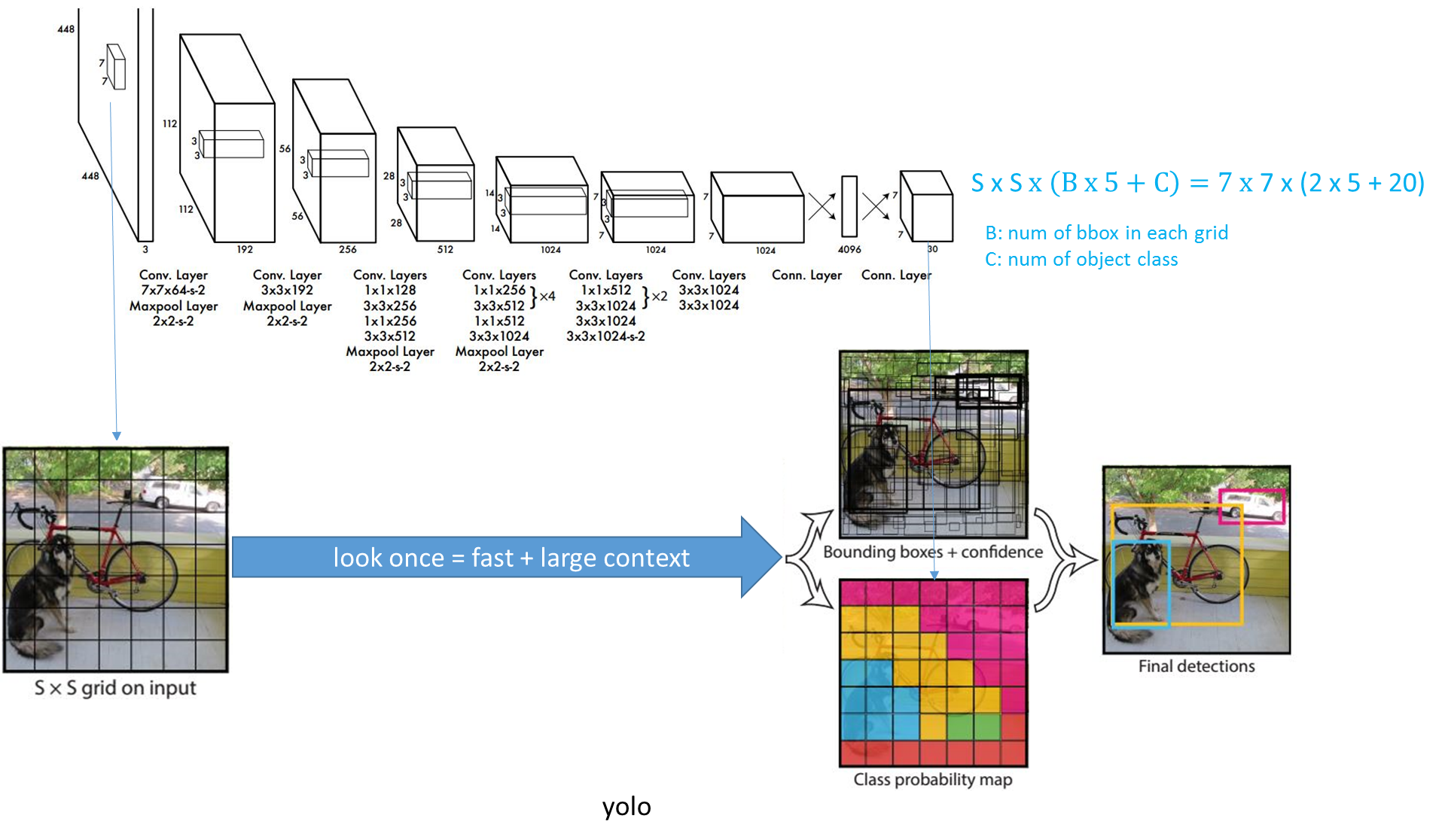
1.1 ДДаТЕу
(1) ИФИяСЫЧјгђНЈвщПђЪНМьВтПђМм: RCNNЯЕСаОљашвЊЩњГЩНЈвщПђЃЌдкНЈвщПђЩЯНјааЗжРргыЛиЙщЃЌЕЋНЈвщПђжЎМфгажиЕўЃЌетЛсДјРДКмЖржиИДЙЄзїЁЃYOLOНЋШЋЭМЛЎЗжЮЊSXSЕФИёзгЃЌУПИіИёзгИКд№жааФдкИУИёзгЕФФПБъМьВтЃЌВЩгУвЛДЮаддЄВтЫљгаИёзгЫљКЌФПБъЕФbboxЁЂЖЈЮЛжУаХЖШвдМАЫљгаРрБ№ИХТЪЯђСПРДНЋЮЪЬтвЛДЮадНтОі(one-shot)ЁЃ
1.2 InferenceЙ§ГЬ
YOLOЭјТчНсЙЙгЩ24ИіОэЛ§Вугы2ИіШЋСЌНгВуЙЙГЩЃЌЭјТчШыПкЮЊ448x448(v2ЮЊ416x416)ЃЌЭМЦЌНјШыЭјТчЯШОЙ§resizeЃЌЭјТчЕФЪфГіНсЙћЮЊвЛИіеХСПЃЌЮЌЖШЮЊЃК
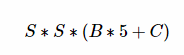
ЦфжаЃЌSЮЊЛЎЗжЭјИёЪ§ЃЌBЮЊУПИіЭјИёИКд№ФПБъИіЪ§ЃЌCЮЊРрБ№ИіЪ§ЁЃИУБэДяЪНКЌвхЮЊЃК
(1) УПИіаЁИёЛсЖдгІBИіБпНчПђЃЌБпНчПђЕФПэИпЗЖЮЇЮЊШЋЭМЃЌБэЪОвдИУаЁИёЮЊжааФбАевЮяЬхЕФБпНчПђЮЛжУЁЃ
(2) УПИіБпНчПђЖдгІвЛИіЗжжЕЃЌДњБэИУДІЪЧЗёгаЮяЬхМАЖЈЮЛзМШЗЖШЃК
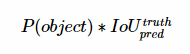
(3) УПИіаЁИёЛсЖдгІCИіИХТЪжЕЃЌевГізюДѓИХТЪЖдгІЕФРрБ№P(Class|object)P(Class|object)ЃЌВЂШЯЮЊаЁИёжаАќКЌИУЮяЬхЛђепИУЮяЬхЕФвЛВПЗжЁЃ
1.3 ЗжИёЫМЯыЪЕЯжЗНЗЈ
вЛжБРЇЛѓЕФЮЪЬтЪЧЃКЗжИёЫМЯыдкДњТыЪЕЯжжаОПОЙШчКЮЬхЯжЕФФиЃП
дкyolov1ЕФyolo.cfgЮФМўжаЃК
[net]
batch=1
subdivisions=1
height=448
width=448
channels=3
momentum=0.9
decay=0.0005
saturation=1.5
exposure=1.5
hue=.1
conv24 ЁЃЁЃЁЃ
[local]
size=3
stride=1
pad=1
filters=256
activation=leaky
[dropout]
probability=.5
[connected]
output= 1715
activation=linear
[detection]
classes=20
coords=4
rescore=1
side=7
num=3
softmax=0
sqrt=1
jitter=.2
object_scale=1
noobject_scale=.5
class_scale=1
coord_scale=5 |
зюКѓвЛИіШЋСЌНгВуЪфГіЬиеїИіЪ§ЮЊ1715ЃЌЖјdetctionВуНЋИУ1715ЕФЬиеїЯђСПећИіЮЊвЛИіЃЌside?side?((coodrds+rescore)?num+classes)side?side?((coodrds+rescore)?num+classes)ЕФеХСПЁЃЦфжаЃЌside?sideside?sideМДЮЊдЭМжаS?SS?SЕФаЁИёЁЃЮЊЪВУДsideЮЛжУЕФЪфГіЛсЖдгІЕНдЭМжааЁИёЕФЮЛжУФиЃПвђЮЊбЕСЗЙ§ГЬжаЛсЪЙгУЖдгІЮЛжУЕФGTМрЖНЭјТчЪеСВЃЌВтЪдЙ§ГЬжаУПИіаЁИёздШЛЖдгІдЭМаЁИёЩЯФПБъЕФМьВтЁЃ
дЄВтДІРэЙ§ГЬЪ§ОнЕФЙщвЛЛЏ
дкбЕСЗyoloЧАашвЊЯШзМБИЪ§ОнЃЌЦфжага
вЛВНЮЊЃК
жагаИіconvertКЏЪ§
def convert(size,
box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h) |
GTБпНчПђзЊЛЛЮЊ(xc, yc, w, h)ЕФБэЪОЗНЪНЃЌwc, yc, w, hБЛЙщвЛЛЏЕН0~1жЎМфЁЃ
дйПДЫ№ЪЇКЏЪ§
1.4 YOLOШБЕу
1) ЖдаЁЮяЬхМАСкНќЬиеїМьВтаЇЙћВюЃКЕБвЛИіаЁИёжаГіЯжЖргкСНИіаЁЮяЬхЛђепвЛИіаЁИёжаГіЯжЖрИіВЛЭЌЮяЬхЪБаЇЙћЧЗМбЁЃдвђЃКBБэЪОУПИіаЁИёдЄВтБпНчПђЪ§ЃЌЖјYOLOФЌШЯЭЌИёзгРяЫљгаБпНчПђЮЊЭЌжжРрЮяЬхЁЃ
(2) ЭМЦЌНјШыЭјТчЧАЛсЯШНјааresizeЮЊ448 x 448ЃЌНЕЕЭМьВтЫйЖШ(it takes about
10ms in 25ms)ЃЌШчЙћжБНгбЕСЗЖдгІГпДчЛсгаМгЫйПеМфЁЃ
(3) ЛљДЁЭјТчМЦЫуСПНЯДѓЃЌyolov2ЪЙгУdarknet-19НјааМгЫйЁЃ
1.5 ЪЕбщНсТл
(1) ЫйЖШИќПь(ЪЕЪБ)ЃКyolo(24 convs) -> 45 fpsЃЌfast_yolo(9
convs) -> 150 fps
(2) ШЋЭМЮЊЗЖЮЇНјааМьВт(ЖјЗЧдкНЈвщПђФкМьВт)ЃЌДјРДИќДѓЕФcontextаХЯЂЃЌЪЙЕУЯрЖдгкFast-RCNNЮѓМьТЪИќЕЭЃЌЕЋЖЈЮЛОЋЖШЧЗМбЁЃ
1.6 YOLOЫ№ЪЇКЏЪ§
YoloЫ№ЪЇКЏЪ§ЕФРэНтбЇЯАгкЧБЗќдкДњТыжа
** Loss = ІЫcoordІЫcoord * зјБъдЄВтЮѓВю(1) + КЌobjectЕФbox confidenceдЄВтЮѓВю
(2)+ ІЫnoobjІЫnoobj* ВЛКЌobjectЕФbox confidenceдЄВтЮѓВю(3)
+ УПИіИёзгжаРрБ№дЄВтЮѓВю(4) **

(1) ећИіЫ№ЪЇКЏЪ§еыЖдБпНчПђЫ№ЪЇ(ЭМжа1, 2, 3ВПЗж)гыИёзг(4ВПЗж)жїЬхНјааЬжТлЁЃ
(2) ВПЗж1ЮЊБпНчПђЮЛжУгыДѓаЁЕФЫ№ЪЇКЏЪ§ЃЌЪНжаЖдПэИпЖМНјааПЊИљЪЧЮЊСЫЪЙгУДѓаЁВюБ№БШНЯДѓЕФБпНчПђВюБ№МѕаЁЁЃР§ШчЃЌвЛИіЭЌбљНЋвЛИі100x100ЕФФПБъгывЛИі10x10ЕФФПБъЖМдЄВтДѓСЫ10ИіЯёЫиЃЌдЄВтПђЮЊ110
x 110гы20 x 20ЁЃЯдШЛЕквЛжжЧщПіЮвУЧЛЙПЩвдЪЇЕРНгЪмЃЌЕЋЕкЖўжжЧщПіЯрЕБгкАбБпНчПђдЄВтДѓСЫвЛБЖЃЌЕЋШчЙћВЛЪЙгУИљКХКЏЪ§ЃЌФЧУДЫ№ЪЇЯрЭЌЃЌЖМЮЊ200ЁЃЕЋАбПэИпЖМдіМгИљКХЪБЃК
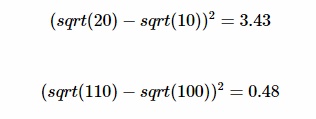
ЯдШЛЃЌЖдаЁПђдЄВтЦЋВю10ИіЯёЫиДјРДСЫИќИпЕФЫ№ЪЇЁЃЭЈЙ§діМгИљКХЃЌЪЙЕУдЄВтЯрЭЌЦЋВюгыИќаЁЕФПђВњЩњИќДѓЕФЫ№ЪЇЁЃЕЋИљОнYOLOv2ЕФЪЕбщжЄУїЃЌЛЙгаИќКУЕФЗНЗЈНтОіетИіЮЪЬтЁЃ
(3) ШєгаЮяЬхТфШыБпНчПђжаЃЌдђМЦЫудЄВтБпНчПђКЌгаЮяЬхЕФжУаХЖШCiCiКЭецЪЕЮяЬхгыБпНчПђIoUCi?Ci^ЕФЫ№ЪЇЃЌЮвУЧЯЃЭћСНВюжЕдНаЁЫ№ЪЇдНЕЭЁЃ
(4) ШєУЛгаШЮКЮЮяЬхжааФТфШыБпНчПђжаЃЌдђCi?Ci^ЮЊ0ЃЌДЫЪБЮвУЧЯЃЭћдЄВтКЌгаЮяЬхЕФжУаХЖШCiCiдНаЁдНКУЁЃШЛЖјЃЌДѓВПЗжБпНчПђЖМУЛгаЮяЬхЃЌЛ§ЩйГЩЖрЃЌдьГЩlossЕФЕк3ВПЗжгыЕк4ВПЗжЕФВЛЦНКтЃЌвђДЫЃЌзїВХдкlossЕФШ§ВПЗждіМгШЈжиІЫnobj=0.5ІЫnobj=0.5
ЁЃ
(5) ЖдгкУПИіИёзгЖјбдЃЌзїепЩшМЦжЛФмАќКЌЭЌжжЮяЬхЁЃШєИёзгжаАќКЌЮяЬхЃЌЮвУЧЯЃЭћЯЃЭћдЄВте§ШЗЕФРрБ№ЕФИХТЪдННгНќгк1дНКУЃЌЖјДэЮѓРрБ№ЕФИХТЪдННгНќгк0дНКУЁЃlossЕк4ВПЗжжаЃЌШєpi(c)?pi(c)^жаcЮЊе§ШЗРрБ№ЃЌдђжЕЮЊ1ЃЌШєЗЧе§ШЗРрБ№ЃЌдђжЕЮЊ0ЁЃ
ВЮПМвыЮФ
2 YOLOv2
yolov1ЛљДЁЩЯЕФбгајЃЌаТЕФЛљДЁЭјТчЃЌЖрГпЖШбЕСЗЃЌШЋОэЛ§ЭјТчЃЌFaster-RCNNЕФanchorЛњжЦЃЌИќЖрЕФбЕСЗММЧЩЕШЕШИФНјЪЙЕУyolov2ЫйЖШгыОЋЖШЖМДѓЗљЬсЩ§ЃЌИФНјаЇЙћШчЯТЭМЃК
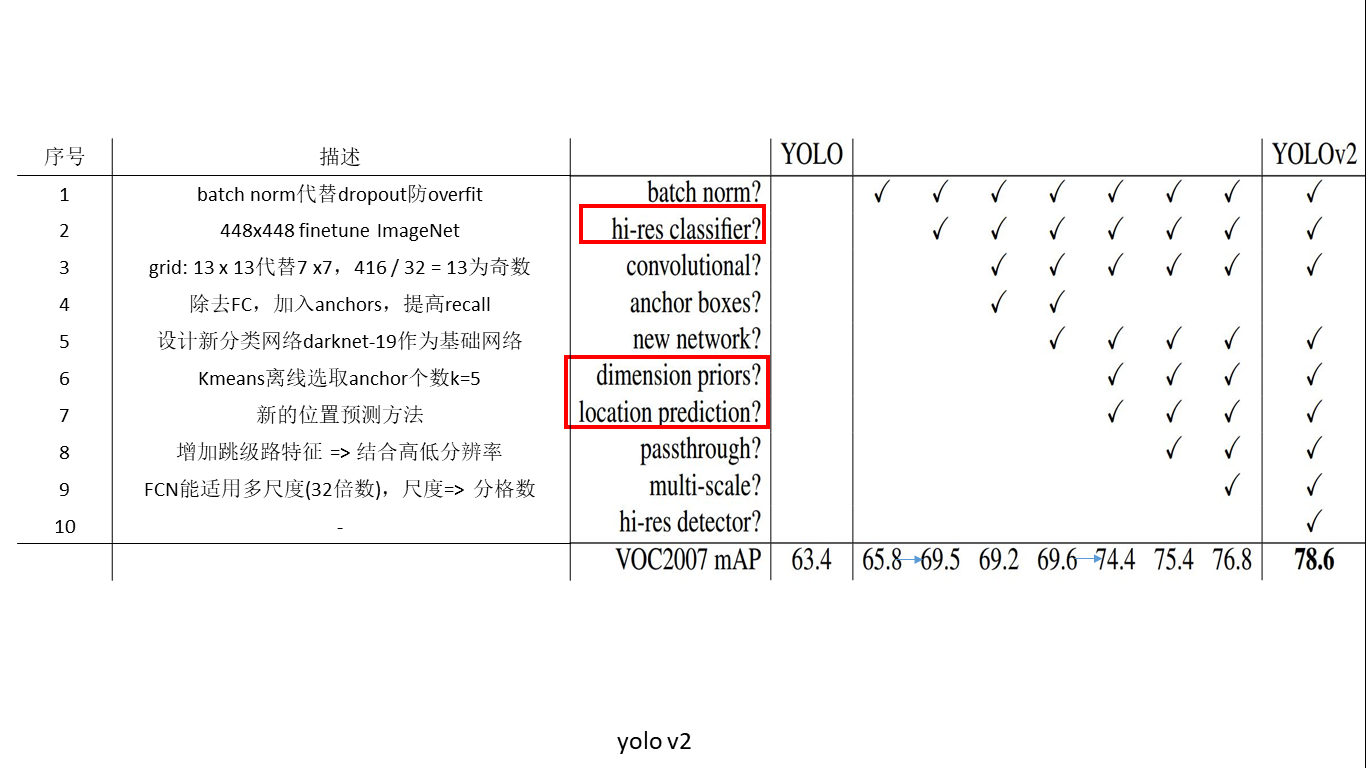
2.1 BatchNorm
BatchnormЪЧ2015ФъвдКѓЦеБщБШНЯСїааЕФбЕСЗММЧЩЃЌдкУПвЛВужЎКѓМгШыBNВуПЩвдНЋећИіbatchЪ§ОнЙщвЛЛЏЕНОљжЕЮЊ0ЃЌЗНВюЮЊ1ЕФПеМфжаЃЌМДНЋЫљгаВуЪ§ОнЙцЗЖЛЏЃЌЗРжЙЬнЖШЯћЪЇгыЬнЖШБЌеЈЃЌШчЃК
МгШыBNВубЕСЗжЎКѓаЇЙћОЭЪЧЭјТчЪеСВИќПьЃЌВЂЧваЇЙћИќКУЁЃYOLOv2дкМгШыBNВужЎКѓmAPЩЯЩ§2%ЁЃ
ЙигкBNзїгУ
2.2 дЄбЕСЗГпДч
yolov1вВдкImage-NetдЄбЕСЗФЃаЭЩЯНјааfine-tuneЃЌЕЋЪЧдЄбЕСЗЪБЭјТчШыПкЮЊ224
x 224ЃЌЖјfine-tuneЪБЮЊ448 x 448ЃЌетЛсДјРДдЄбЕСЗЭјТчгыЪЕМЪбЕСЗЭјТчЪЖБ№ЭМЯёГпДчЕФВЛМцШнЁЃyolov2жБНгЪЙгУ448
x 448ЕФЭјТчШыПкНјаадЄбЕСЗЃЌШЛКѓдкМьВтШЮЮёЩЯНјаабЕСЗЃЌаЇЙћЕУЕН3.7%ЕФЬсЩ§ЁЃ
2.3 ИќЯИЭјТчЛЎЗж
yolov2ЮЊСЫЬсЩ§аЁЮяЬхМьВтаЇЙћЃЌМѕЩйЭјТчжаpoolingВуЪ§ФПЃЌЪЙзюжеЬиеїЭМГпДчИќДѓЃЌШчЪфШыЮЊ416
x 416ЃЌдђЪфГіЮЊ13 x 13 x 125ЃЌЦфжа13 x 13ЮЊзюжеЬиеїЭМЃЌМДдЭМЗжИёЕФИіЪ§ЃЌ125ЮЊУПИіИёзгжаЕФБпНчПђЙЙГЩ(5
x (classes + 5))ЁЃашвЊзЂвтЕФЪЧЃЌЬиеїЭМГпДчШЁОігкдЭМГпДчЃЌЕЋЬиеїЭМГпДчБиаыЮЊЦцЪ§ЃЌвдДЫБЃДцжаМфгавЛИіЮЛжУФмПДЕНдЭМжааФДІЕФФПБъЁЃ
2.4 ШЋОэЛ§ЭјТч
ЮЊСЫЪЙЭјТчФмЙЛНгЪмЖржжГпДчЕФЪфШыЭМЯёЃЌyolov2Г§ШЅСЫv1ЭјТчНсЙЙжаЕФШЋСЌВуЃЌвђЮЊШЋСЌНгВуБиаывЊЧѓЪфШыЪфГіЙЬЖЈГЄЖШЬиеїЯђСПЁЃНЋећИіЭјТчБфГЩвЛИіШЋОэЛ§ЭјТчЃЌФмЙЛЖдЖржжГпДчЪфШыНјааМьВтЁЃЭЌЪБЃЌШЋОэЛ§ЭјТчЯрЖдгкШЋСЌНгВуФмЙЛИќКУЕФБЃСєФПБъЕФПеМфЮЛжУаХЯЂЁЃ
2.5 аТЛљДЁЭјТч
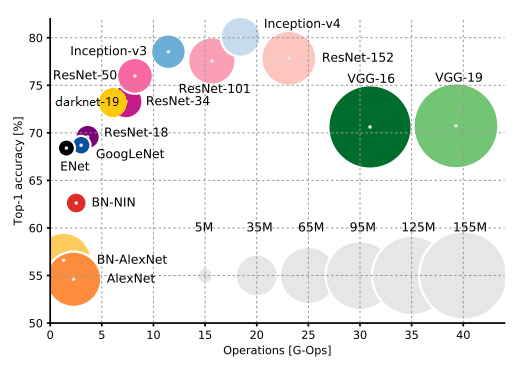
ЯТЭМЮЊВЛЭЌЛљДЁЭјТчНсЙЙзіЗжРрШЮЮёЫљЖдОЭЕФМЦЫуСПЃЌКсзјБъЮЊзівЛДЮЧАЯђЗжРрШЮЮёЫљашвЊЕФВйзїЪ§ФПЁЃПЩвдПДГізїепЫљЪЙгУЕФdarknet-19зїЮЊЛљДЁдЄбЕСЗЭјТч(ЙВ19ИіОэЛ§Ву)ЃЌФмдкБЃГжИпОЋЖШЕФЧщПіЯТПьЫйдЫЫуЁЃЖјSSDЪЙгУЕФVGG-16зїЮЊЛљДЁЭјТчЃЌVGG-16ЫфШЛОЋЖШгыdarknet-19ЯрЕБЃЌЕЋдЫЫуЫйЖШТ§ЁЃЙигкdarknet-19ЛљДЁЭјТчЫйЖШ
2.6 anchorЛњжЦ
yolov2ЮЊСЫЬсИпОЋЖШгыейЛиТЪЃЌЪЙгУFaster-RCNNжаЕФanchorЛњжЦЁЃвдЯТЮЊЮвЖдanchorЛњжЦЪЙгУЕФРэНтЃКдкУПИіЭјИёЩшжУkИіВЮПМanchorЃЌбЕСЗвдGT
anchorзїЮЊЛљзММЦЫуЗжРргыЛиЙщЫ№ЪЇЁЃВтЪдЪБжБНгдкУПИіИёзгЩЯдЄВтkИіanchor boxЃЌУПИіanchor
boxЮЊЯрЖдгкВЮПМanchorЕФoffsetгыw,hЕФrefineЁЃетбљАбдРДУПИіИёзгжаБпНчПђЮЛжУЕФШЋЭМЛиЙщ(yolov1)зЊЛЛЮЊЖдВЮПМanchorЮЛжУЕФОЋао(yolov2)ЁЃ
жСгкУПИіИёзгжаЩшжУЖрЩйИіanchor(МДkЕШгкМИ)ЃЌзїепЪЙгУСЫk-meansЫуЗЈРыЯпЖдvocМАcocoЪ§ОнМЏжаФПБъЕФаЮзДМАГпЖШНјааСЫМЦЫуЁЃЗЂЯжЕБk
= 5ЪБВЂЧвбЁШЁЙЬЖЈ5БШР§жЕЕФЪБЃЌanchorsаЮзДМАГпЖШзюНгНќvocгыcocoжаФПБъЕФаЮзДЃЌВЂЧвkвВВЛФмЬЋДѓЃЌЗёдђФЃаЭЬЋИДдгЃЌМЦЫуСПКмДѓЁЃ
2.7 аТБпНчПђдЄВтЗНЪН
етВПЗжУЛгаПДЬЋЖЎЃЌЯШеМИіПгЃЌЕШвдКѓУїАзСЫдйРДВЙЃЌИаОѕгІИУЪЧдкУжВЙДѓаЁБпНчПђЛиЙщЮѓВюЫ№ЪЇЕФЮЪЬтАЩЁЃетРяЗЂЯжгаЦЊВЉЮФЖдетВПЗжНВЕУЭІзаЯИЕФЁЃ
2.8 ВаВюВуШкКЯЕЭМЖЬиеї
ЮЊСЫЪЙгУЭјТчФмЙЛИќКУМьВтаЁЮяЬхЃЌзїепЪЙгУСЫresnetЬјМЖВуНсЙЙЃЌЭјТчФЉЖЫЕФИпМЖЬиеїВугыЧАвЛВуЛђепЧАМИВуЕФЕЭМЖЯИСЃЖШЬиеїНсКЯЦ№РДЃЌдіМгЭјТчЖдаЁЮяЬхЕФМьВтаЇЙћЃЌЪЙгУИУЗНЗЈФмЙЛНЋmAPЬсИп1%ЁЃ
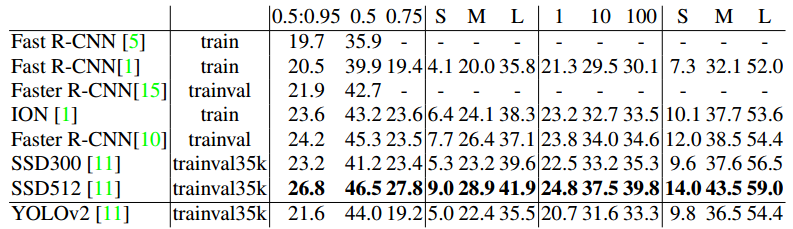
ЭЌбљЃЌдкSSDМьВтЦїЩЯвВПЩвдПДГіЪЙгУЯИСЃЖШЬиеї(ЕЭМЖЬиеї)НЋНјаааЁЮяЬхМьВтЕФЫМЯыЃЌЕЋЪЧВЛЭЌЕФЪЧSSDжБНгдкЖрИіЕЭМЖЬиеїЭМЩЯНјааФПБъМьВтЃЌвђДЫЃЌSSDЖдгкаЁФПБъМьВтаЇЙћвЊгХгкYOLOv2ЃЌетЕуПЩвдcocoВтЪдМЏЩЯПДГіЃЌвђЮЊcocoЩЯаЁЮяЬхБШНЯЖрЃЌЕЋyolov2дкcocoЩЯвЊУїЯдбЗЩЋгкssdЃЌЕЋдкБШНЯМђЕЅЕФМьВтЪ§ОнМЏvocЩЯгХгкssdЁЃ
2.9 ЖрГпДчбЕСЗ
yolov2ЭјТчНсЙЙЮЊШЋОэЛ§ЭјТчFCNЃЌПЩвдЪЪгкВЛЭЌГпДчЭМЦЌзїЮЊЪфШыЃЌЕЋвЊТњзуФЃаЭдкВтЪдЪБФмЙЛЖдЖрГпЖШЪфШыЭМЯёЖМгаКмКУаЇЙћЃЌзїепбЕСЗЙ§ГЬжаУП10ИіepochЖМЛсЖдЭјТчНјаааТЕФЪфШыГпДчЕФбЕСЗЁЃашвЊзЂвтЕФЪЧЃЌвђЮЊШЋОэЛ§ЭјТчзмЙВЖдЪфШыЭМЯёНјааСЫ5ДЮЯТВЩбљ(ВНГЄЮЊ2ЕФОэЛ§ЛђепГиЛЏВу)ЃЌ
ЫљвдзюжеЬиеїЭМЮЊдЭМЕФ1/32ЁЃЫљвддкбЕСЗЛђепВтЪдЪБЃЌЭјТчЪфШыБиаыЮЊ32ЕФЮЛЪ§ЁЃВЂЧвзюжеЬиеїЭМГпДчМДЮЊдЭМЛЎЗжЭјТчЕФЗНЪНЁЃ
|









