| БрМЭЦМі: |
БОЮФРДздгкМђЪщЃЌБОЮФжївЊЖдYOLOзіМђЕЅНщЩмЃЌОЙ§ЭМЯёЗжРрбЕСЗЕФЧА20ВуЭјТчМгЩЯКѓУцЕФЭјТчВуНјааМьВтШЮЮёЕФбЕСЗЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
|
|
YOLOЃЈYou Only Look OnceЃЉТлЮФНќаЉФъЃЌR-CNNЕШЛљгкЩюЖШбЇЯАФПБъМьВтЗНЗЈЃЌДѓДѓЬсИпСЫМьВтОЋЖШКЭМьВтЫйЖШЁЃ
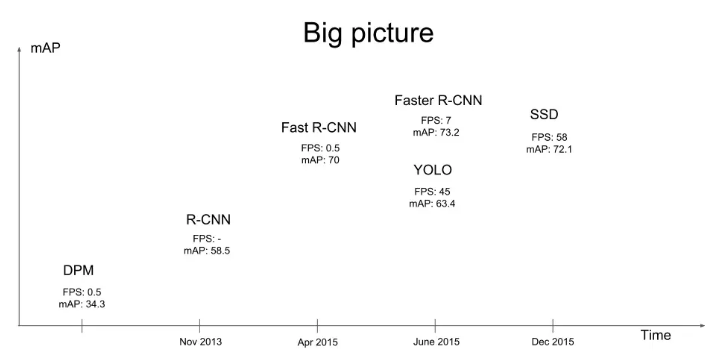
Р§ШчдкPascal VOCЪ§ОнМЏЩЯFaster R-CNNЕФmAPДяЕНСЫ73.2ЁЃЖјYOLOКЭSSDдкДяЕННЯИпЕФМьВтОЋЖШЕФЭЌЪБЃЌМьВтЫйЖШЖМдк40FPSвдЩЯЁЃ
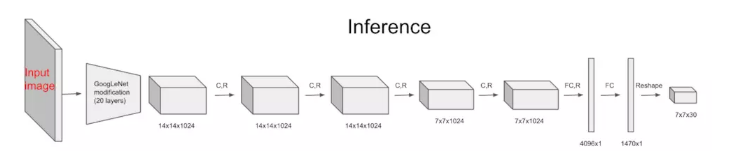
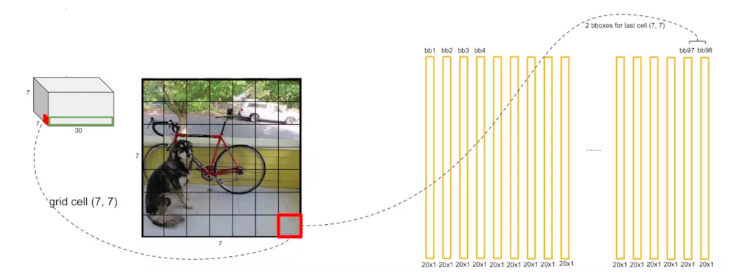
ећИіYOLOЕФЭјТчНсЙЙШчЭМЃЌЧАУц20ВуЪЙгУСЫИФНјЕФGoogleNetЃЌЕУЕН14ЁС14ЁС1024ЕФtensorЃЌНгЯТРДОЙ§4ИіОэЛ§ВуЗжБ№Нјаа3ЁС3ЕФОэЛ§ВйзїКЭ1ЁС1ЕФНЕЮЌВйзїЃЌзюКѓОЙ§СНИіШЋСЌНгВуКѓЪфГіЮЊ7ЁС7ЁС30ЕФtensorЁЃМьВтФПБъОЭФмДг7ЁС7ЁС30ЕФtensorжаЕУЕНЁЃ
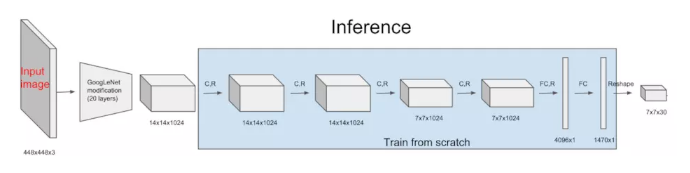
зїепЪзЯШШЁГіЧАУцЕФ20ВуЭјТчЃЌСэЭтдйМгЩЯвЛИіaverage-poolingВуКЭвЛИіШЋСЌНгВуЃЌдкImageNetбЕСЗМЏЩЯНјааЭМЯёЗжРрШЮЮёЕФгћбЕСЗЃЌtop-5ДяЕН88%ЕФзМШЗЖШЁЃШЛКѓНЋОЙ§ЭМЯёЗжРрбЕСЗЕФЧА20ВуЭјТчМгЩЯКѓУцЕФЭјТчВуНјааМьВтШЮЮёЕФбЕСЗЁЃ7ЁС7ЁС30
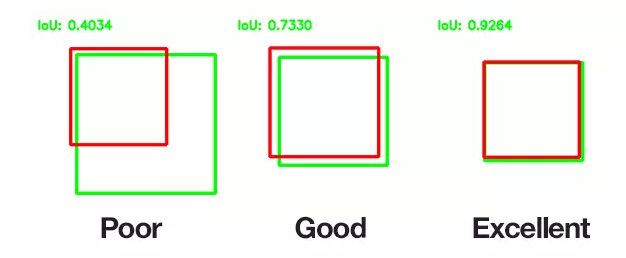
tensorЕФНтЪЭЃКЦфЪЕетРяЕФ7ЁС7ВЂВЛЪЧНЋЪфШыЭМЯёЛЎЗжЮЊ7ЁС7ЕФЭјИёЃЌЪЕМЪЩЯжИОЙ§ЖрИіОэЛ§ВуДІРэЙ§КѓЕФЬиеїmapЪЧ7ЁС7ДѓаЁЕФЃЌЖјЧвЦфжаЕФУПИіcellЪЧЛЅЯргажиЕўЕФЃЌЕЋЪЧЮЊСЫБугкжБЙлРэНтЃЌжБНгНЋдЪМЭМЯёгУ7ЁС7ЕФЭјИёНјааЛЎЗжЁЃПЩвдПДЕНУПИіcellЯђСПЕФЧА5ЮЌЗжБ№ДњБэСЫвЛИіМьВтПђЕФxзјБъЃЌyзјБъЃЌПэЖШКЭИпЖШЃЌМьВтПђжагаФПБъЮяЬхЕФжУаХЖШЃЈP(Object)
IOUЃЉЁЃ
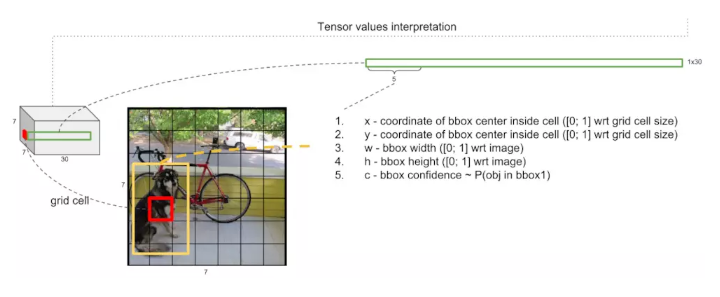
дкТлЮФжаУПИіcellгаСНИіМьВтПђЃЌ6ЕН10ЮЌЯђСПДњБэСЫСэЭтвЛИіМьВтПђЕФxзјБъЃЌyзјБъЃЌПэЖШКЭИпЖШЃЌМьВтПђжагаФПБъЮяЬхЕФжУаХЖШЁЃ
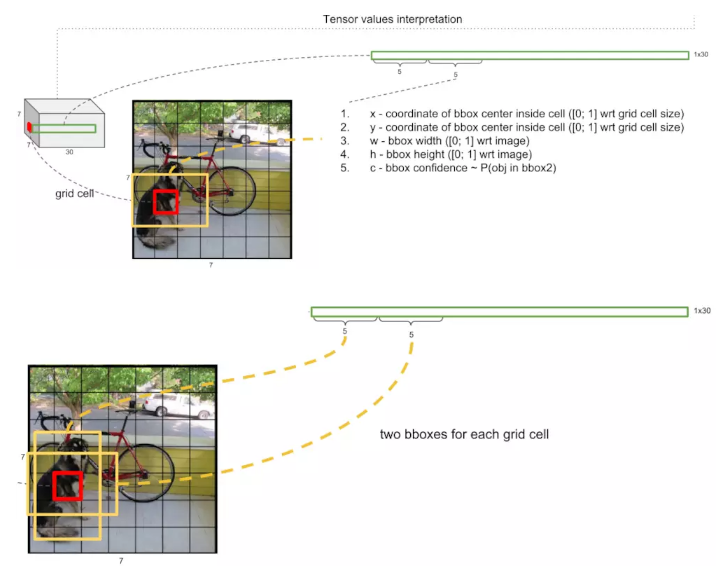
cellЛЙЪЃЯТ20ЮЌЯђСПЃЌДњБэетИіcellжаЕФЮяЬхЪєгк20ИіРрБ№ЕФИХТЪжЕЁЃНЋcellСНИіМьВтПђЕФжУаХЖШЗжБ№ГЫвд20РрБ№ЕФИХТЪжЕЁЃ
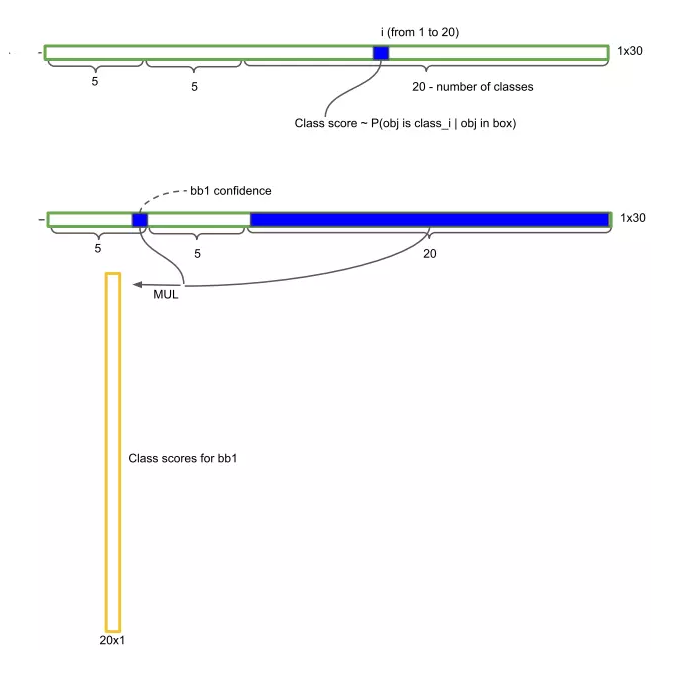
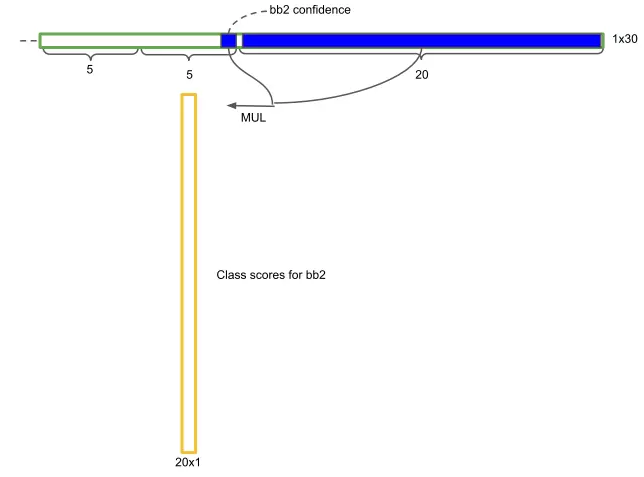
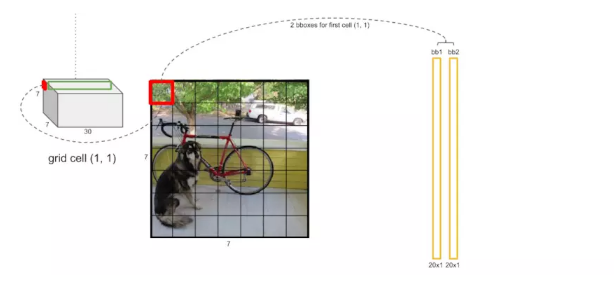
зюКѓЕУЕНСЫ7ЁС7ЁС2=98ИіМьВтПђЕФ20ИіРрБ№ЕФИХТЪжЕЁЃ
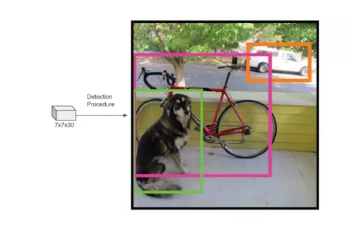
НгЯТРДвЊДгКђбЁЕФМьВтПђжаевГізюКѓЕФФПБъПђЃК
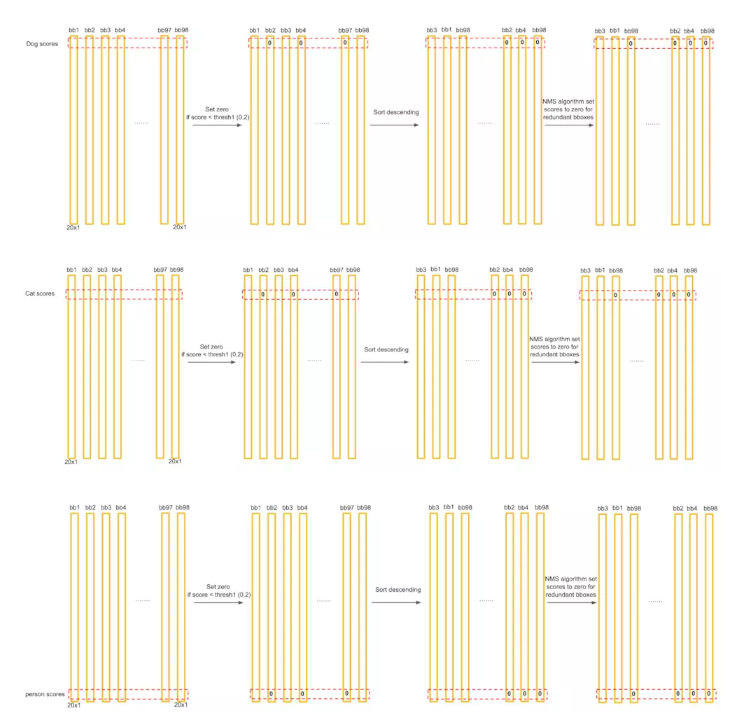
ЖдУПИіРрБ№ЃЌНјаауажЕБШНЯЁЂНЕађХХСаЁЂЖдгажиЕўЕФКђбЁПђЪЙгУЗЧМЋДѓжЕвжжЦЃЈNMSЃЉВйзїЁЃ
зюКѓКђбЁПђЕФзюжеЗжЪ§ЕУЕНзюжеЕФРрБ№КЭЗжЪ§ЃК
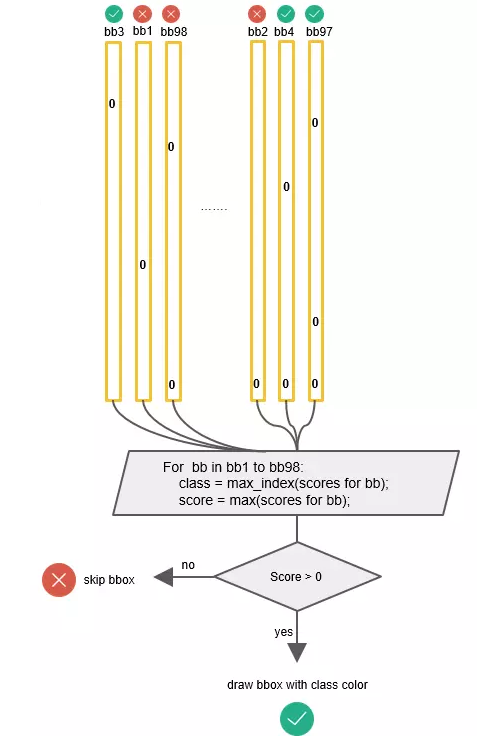
БъГіМьВтПђЃК

ЙигкЗЧМЋДѓжЕвжжЦЃЈNMSЃЉЃК
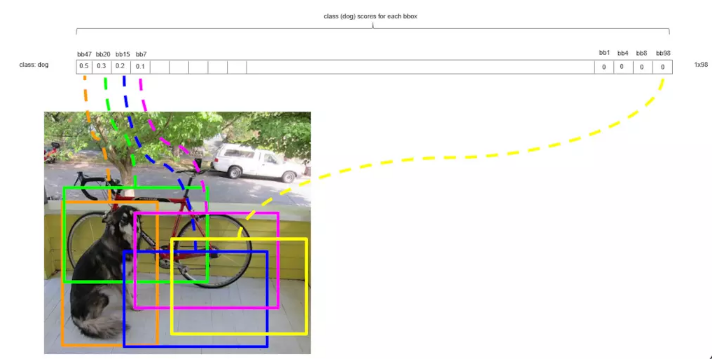
гУbbox_maxДњБэЗжЪ§зюДѓЕФКђбЁПђЃЌНЋЦфгыЦфЫћКђбЁПђbbox_curНјааБШНЯЃЌШчЙћIoUЃЈbbox_maxЃЌbbox_curЃЉ>0.5ЃЌНЋКђбЁПђbbox_curЕФЗжЪ§жУЮЊ0ЁЃЕквЛТжбЛЗКѓЃЌгЩгкГШЩЋПђЃЈbbox_maxЃЉКЭТЬЩЋПђЕФжиЕўЖШДѓгк0.5ЃЌЫљвдНЋТЬЩЋКђбЁПђЕФЗжЪ§жУ0ЁЃ
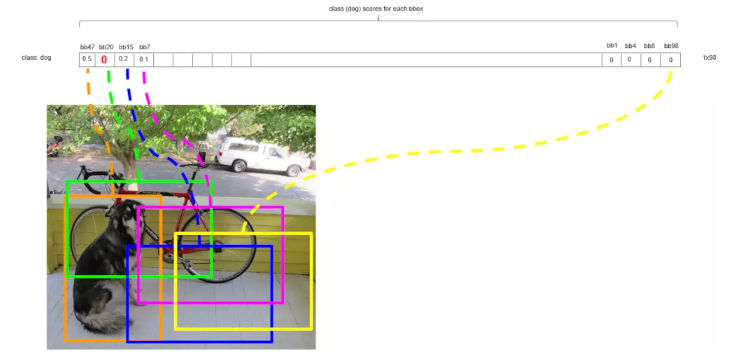
ЕкЖўТжбЛЗЃЌНЋЪЃЯТЕФЕкЖўДѓЗжЪ§ЕФКђбЁПђЩшЮЊbbox_maxЃЈЭМжаЕФРЖЩЋПђЃЉ
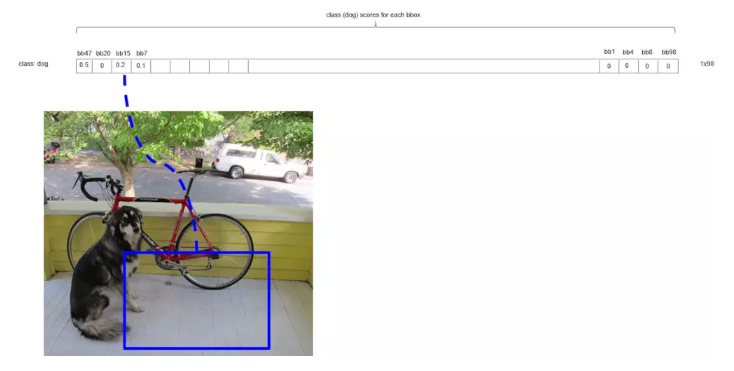
ЭЌбљЕФЕРРэЃЌгЩгкРЖЩЋПђЃЈbbox_maxЃЉКЭЗлЩЋПђЕФжиЕўЖШДѓгк0.5ЃЌЫљвдНЋЗлЩЋКђбЁПђЕФЗжЪ§жУ0ЁЃ
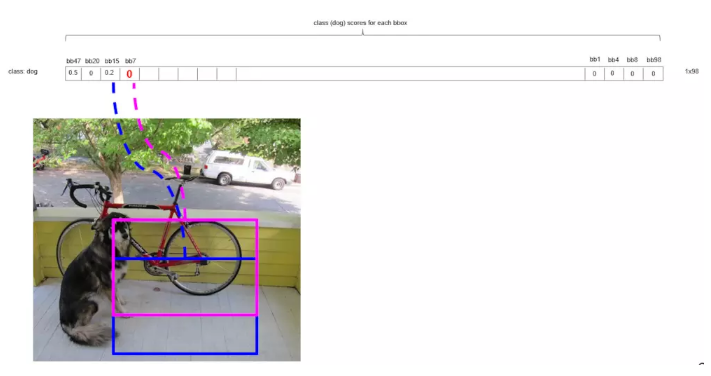
ЪЙгУЗЧМЋДѓжЕвжжЦбЛЗНсЪјКѓЃЌКмЖрЧщПіЯТЃЌЖМжЛгаЩйЪ§ЕФМИИіКђбЁПђДѓгк0ЁЃЙигкIntersect over
Union (IoU)
ЙигкYolo v2КѓРДзїепЖдYOLOНјааСЫИФНјЃЌЙЋВМСЫYOLO v2ЃЌТлЮФдкОЋЖШЃЈ73.4 mAP
on Pascal vocЃЉКЭЫйЖШСНИіЗНУцЖМгаЬсИпЃЌВЂЧвЬсГіСЫФмЙЛМьВт9000РрЮяЬхЕФЗНЗЈЁЃОпЬхИФНјЕФЕиЗНгаЃКдіМгСЫbatch
normalizationдкImageNetЩЯЕФдЄбЕСЗЪЙгУ224ЁС224КЭ448x448СНжжГпДчЕФЭМЯёЁЃгУFaster-RCNNРрЫЦЕФanchor
boxes ЃЌДњЬц7ЁС7grid-cellЁЃгУkmeansЗНЗЈЕУЕНboxаЮзДЃЌДњЬцШЫЙЄбЁдёboxаЮзДЁЃдкImageNetКЭMS-COCOЪ§ОнМЏЩЯНјаабЕСЗЁЃЬсГіСЫФмЙЛдкЗжРрЪ§ОнМЏЩЯбЕСЗМьВтШЮЮёЕФЗНЗЈЁЃЪЙгУWordTreeНсКЯЖржжВЛЭЌБъЧЉЕФЪ§ОнЁЃ
|









