| БрМЭЦМі: |
БОЮФРДздгкМђЪщЃЌБОЮФжївЊНщЩмШЫЙЄЩёОЭјТчШыУХжЊЪЖЕФзмНсЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
|
|
ЮвУЧДгЯТУцЫФЕуШЯЪЖШЫЙЄЩёОЭјТчЃЈANN: Artificial Neutral
NetworkЃЉЃКЩёОдЊНсЙЙЁЂЩёОдЊЕФМЄЛюКЏЪ§ЁЂЩёОЭјТчЭиЦЫНсЙЙЁЂЩёОЭјТчбЁдёШЈжЕКЭбЇЯАЫуЗЈЁЃ
1. ЩёОдЊЃК
ЮвУЧЯШРДПДвЛзщЖдБШЭМОЭФмСЫНтЪЧдѕбљДгЩњЮяЩёОдЊНЈФЃЮЊШЫЙЄЩёОдЊЁЃ

ШЫЙЄЩёОдЊНЈФЃЙ§ГЬ
ЯТУцЗжБ№НВЪі:
ЩњЮяЩёОдЊЕФзщГЩАќРЈЯИАћЬхЁЂЪїЭЛЁЂжсЭЛЁЂЭЛДЅЁЃЪїЭЛПЩвдПДзїЪфШыЖЫЃЌНгЪеДгЦфЫћЯИАћДЋЕнЙ§РДЕФЕчаХКХЃЛжсЭЛПЩвдПДзїЪфГіЖЫЃЌДЋЕнЕчКЩИјЦфЫћЯИАћЃЛЭЛДЅПЩвдПДзїI/OНгПкЃЌСЌНгЩёОдЊЃЌЕЅИіЩёОдЊПЩвдКЭЩЯЧЇИіЩёОдЊСЌНгЁЃЯИАћЬхФкгаФЄЕчЮЛЃЌДгЭтНчДЋЕнЙ§РДЕФЕчСїЪЙФЄЕчЮЛЗЂЩњБфЛЏЃЌВЂЧвВЛЖЯРлМгЃЌЕБФЄЕчЮЛЩ§ИпЕНГЌЙ§вЛИіуажЕЪБЃЌЩёОдЊБЛМЄЛюЃЌВњЩњвЛИіТіГхЃЌДЋЕнЕНЯТвЛИіЩёОдЊЁЃ
ЮЊСЫИќаЮЯѓРэНтЩёОдЊДЋЕнаХКХЙ§ГЬЃЌАбвЛИіЩёОдЊБШзївЛИіЫЎЭАЁЃЫЎЭАЯТВрСЌзХЖрИљЫЎЙмЃЈЪїЭЛЃЉЃЌЫЎЙмМШПЩвдАбЭАРяЕФЫЎХХГіШЅЃЈвжжЦадЃЉЃЌгжПЩвдНЋЦфЫћЫЎЭАЕФЫЎЪфНјРДЃЈаЫЗмадЃЉЃЌЫЎЙмЕФДжЯИВЛЭЌЃЌЖдЭАжаЫЎЕФгАЯьГЬЖШВЛЭЌЃЈШЈжиЃЉЃЌЫЎЙмЖдЫЎЭАЫЎЮЛЃЈФЄЕчЮЛЃЉЕФИФБфОЭЪЧЫЎЭАФкЫЎЮЛЕФИФБфЃЌЕБЭАжаЫЎДяЕНвЛЖЈИпЖШЪБЃЌОЭФмЭЈЙ§СэвЛЬѕЙмЕРЃЈжсЭЛЃЉХХГіШЅЁЃ
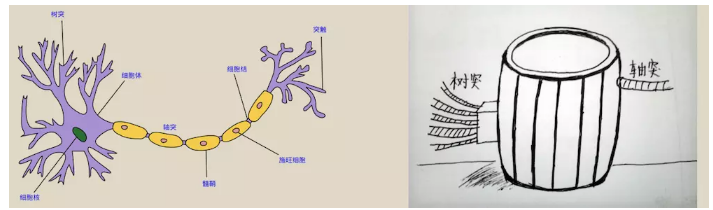
ЩёОдЊЪЧЖрЪфШыЕЅЪфГіЕФаХЯЂДІРэЕЅдЊЃЌОпгаПеМфећКЯадКЭуажЕадЃЌЪфШыЗжЮЊаЫЗмадЪфШыКЭвжжЦадЪфШыЁЃ
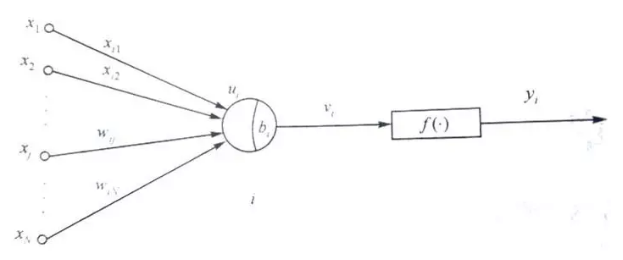
АДееетИідРэЃЌПЦбЇМвЬсГіСЫM-PФЃаЭЃЈШЁздСНИіЬсГіепЕФаеУћЪззжФИЃЉЃЌM-PФЃаЭЪЧЖдЩњЮяЩёОдЊЕФНЈФЃЃЌзїЮЊШЫЙЄЩёОЭјТчжаЕФвЛИіЩёОдЊЁЃ
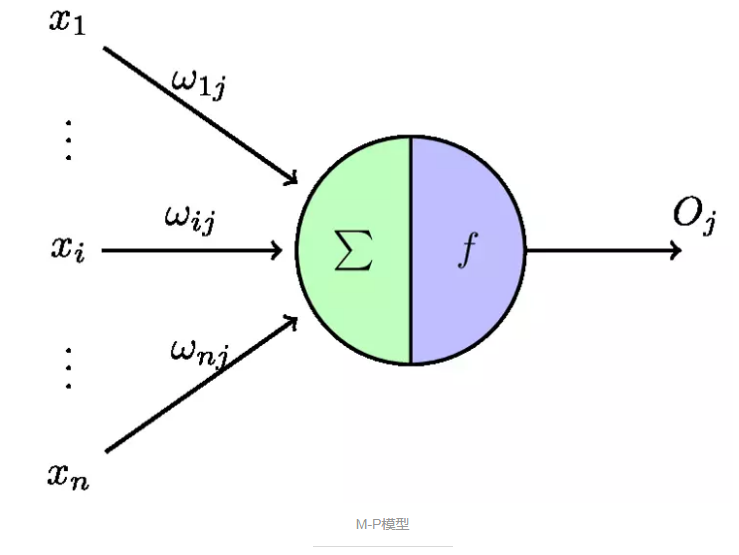
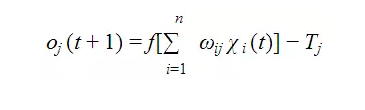
гЩMPФЃаЭЕФЪОвтЭМЃЌЮвУЧПЩвдПДЕНгыЩњЮяЩёОдЊЕФЯрЫЦжЎДІЃЌx_iБэЪОЖрИіЪфШыЃЌW_ijБэЪОУПИіЪфШыЕФШЈжЕЃЌЦфе§ИКФЃФтСЫЩњЮяЩёОдЊжаЭЛГіЕФаЫЗмКЭвжжЦЃЛsigmaБэЪОНЋШЋВПЪфШыаХКХНјааРлМгећКЯЃЌfЮЊМЄЛюКЏЪ§ЃЌOЮЊЪфГіЁЃЯТЭМПЩвдПДЕНЩњЮяЩёОдЊКЭMPФЃаЭЕФРрБШЃК

ЭљКѓЕЎЩњЕФИїжжЩёОдЊФЃаЭЖМЪЧгЩMPФЃаЭбнБфЙ§РДЁЃ
2. МЄЛюКЏЪ§
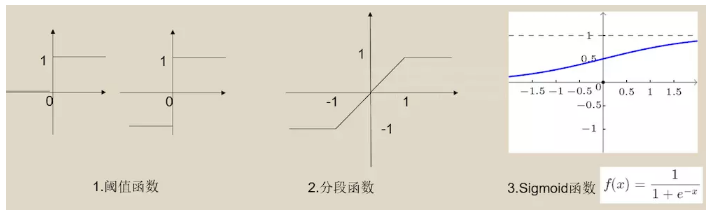
МЄЛюКЏЪ§ПЩвдПДзїТЫВЈЦїЃЌНгЪеЭтНчИїжжИїбљЕФаХКХЃЌЭЈЙ§ЕїећКЏЪ§ЃЌЪфГіЦкЭћжЕЁЃANNЭЈГЃВЩгУШ§РрМЄЛюКЏЪ§:уажЕКЏЪ§ЁЂЗжЖЮКЏЪ§ЁЂЫЋМЋадСЌајКЏЪ§ЃЈsigmoidЃЌtanhЃЉЃК
3. бЇЯАЫуЗЈ
ЩёОЭјТчЕФбЇЯАвВГЦЮЊбЕСЗЃЌЭЈЙ§ЩёОЭјТчЫљдкЛЗОГЕФДЬМЄзїгУЕїећЩёОЭјТчЕФздгЩВЮЪ§ЃЈШчСЌНгШЈжЕЃЉЃЌЪЙЩёОЭјТчвдвЛжжаТЕФЗНЪНЖдЭтВПЛЗОГзіГіЗДгІЕФвЛИіЙ§ГЬЁЃУПИіЩёОЭјТчЖМгавЛИіМЄЛюКЏЪ§y=f(x)ЃЌбЕСЗЙ§ГЬОЭЪЧЭЈЙ§ИјЖЈЕФКЃСПxЪ§ОнКЭyЪ§ОнЃЌФтКЯГіМЄЛюКЏЪ§fЁЃбЇЯАЙ§ГЬЗжЮЊгаЕМЪІбЇЯАКЭЮоЕМЪІбЇЯАЃЌгаЕМЪІбЇЯАЪЧИјЖЈЦкЭћЪфГіЃЌЭЈЙ§ЖдШЈжЕЕФЕїећЪЙЪЕМЪЪфГіБЦНќЦкЭћЪфГіЃЛЮоЕМЪІбЇЯАИјЖЈБэЪОЗНЗЈжЪСПЕФВтСПГпЖШЃЌИљОнИУГпЖШРДгХЛЏВЮЪ§ЁЃГЃМћЕФгаHebbбЇЯАЁЂОРДэбЇЯАЁЂЛљгкМЧвфбЇЯАЁЂЫцЛњбЇЯАЁЂОКељбЇЯАЁЃ
HebbбЇЯАЃК
ЃЈЬљЙЋЪНВЛЗНБуЃЌжЛМђЪідРэЃЉетЪЧзюдчЬсГіЕФбЇЯАЗНЗЈЃЌдРэЪЧШчЙћЭЛДЅЃЈСЌНгЃЉСНБпЕФСНИіЩёОдЊБЛЭЌЪБЃЈЭЌВНЃЉМЄЛюЃЌдђИУЭЛДЅЕФФмСПЃЈШЈжиЃЉОЭбЁдёаддіМгЃЛШчЙћБЛвьВНМЄЛюЃЌдђИУЭЛГіФмСПМѕШѕЛђЯћГ§ЁЃ
ОРДэбЇЯАЃК
МЦЫуЪЕМЪЪфГіКЭЦкЭћЪфГіЕФЮѓВюЃЌдйЗЕЛиЮѓВюЃЌаоИФШЈжЕЁЃдРэМђЕЅЃЌгУЕНзюЖрЃЌзюаЁЬнЖШЯТНЕЗЈЃЈLMSзюаЁОљЗНЮѓВюЫуЗЈЃЉОЭЪЧетжжЗНЗЈЁЃ
ЛљгкМЧвфЕФбЇЯАЃК
жївЊгУгкФЃЪНЗжРрЃЌдкЛљгкМЧвфЕФбЇЯАжаЃЌЙ§ШЅЕФбЇЯАНсЙћБЛДцДЂдквЛИіДѓЕФДцДЂЦїжаЃЌЕБЪфШывЛИіаТЕФВтЪдЯђСПЪБЃЌбЇЯАЙ§ГЬОЭЪЧАбаТЯђСПЙщЕНвбДцДЂЕФФГИіРржаЁЃЫуЗЈАќРЈСНВПЗжЃКвЛЪЧгУгкЖЈвхВтЪдЯђСПОжВПСьгђЕФБъзМЃЛЖўЪЧдкОжВПСьгђбЕСЗбљБОЕФбЇЯАЙцдђЁЃГЃгУзюНќСкЙцдђЁЃ
ЫцЛњбЇЯАЫуЗЈЃК
вВНаBolzmannбЇЯАЙцдђЃЌИљОнзюДѓЫЦШЛЙцдђЃЌЭЈЙ§ЕїећШЈжЕЃЌзюаЁЛЏЫЦШЛКЏЪ§ЛђЦфЖдЪ§ЁЃ
ФЃФтЭЫЛ№ЫуЗЈЪЧДгЮяРэКЭЛЏбЇЭЫЛ№Й§ГЬРрЭЦЙ§РДЃЌЪЧЁАЖдЮяЬхМгЮТКѓдйРфШДЕФДІРэЙ§ГЬЁБЕФЪ§бЇНЈФЃЁЃећИіЙ§ГЬЗжЮЊСНВНЃКЪзЯШдкИпЮТЯТНјааЫбЫїЃЌДЫЪБИїзДЬЌГіЯжИХТЪЯрВюВЛДѓЃЌПЩвдКмПьНјШыЁАШШЦНКтзДЬЌЁБЃЌетЪБНјааЕФЪЧЁАДжЫбЫїЁБЃЌвВОЭЪЧДѓжТевЕНЯЕЭГЕФЕЭФмЧјЧјгђЃЛЫцзХЮТЖШНЕЕЭЃЌИїзДЬЌГіЯжЕФИХТЪВюОрж№НЅБЛРЉДѓЃЌЫбЫїОЋЖШВЛЖЯЬсИпЃЌетОЭПЩвддНРДдНзМШЗЕиевЕНЭјТчФмСПКЏЪ§ЕФШЋОжзюаЁЕуЁЃ
ОКељбЇЯАЃК
ЩёОЭјТчЕФЪфГіЩёОдЊжЎМфЯрЛЅОКељЃЌдкШЮвЛЪБМфжЛФмгавЛИіЪфГіЩёОдЊЪЧЛюадЕФЁЃ
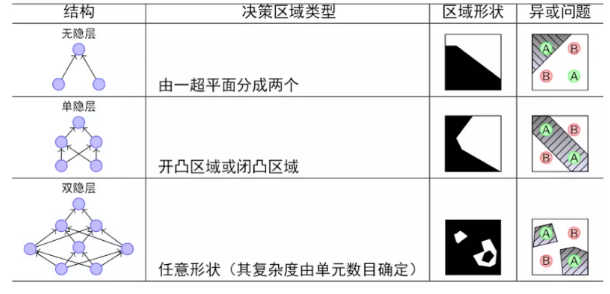
4. ЩёОЭјТчЭиЦЫНсЙЙ
ГЃМћЕФЭиЦЫНсЙЙгаЕЅВуЧАЯђЭјТчЁЂЖрВуЧАЯђЭјТчЁЂЗДРЁЭјТчЃЌЫцЛњЩёОЭјТчЁЂОКељЩёОЭјТчЁЃ
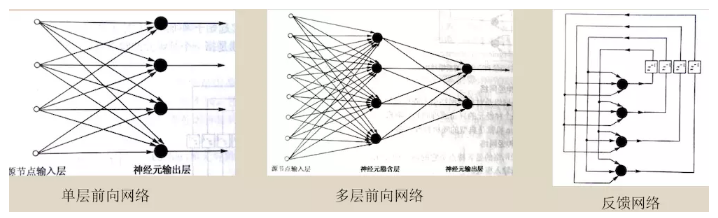
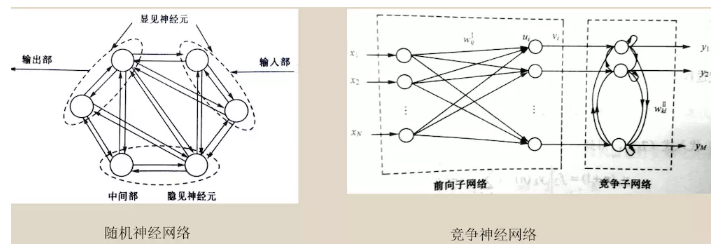
5. ЩёОЭјТчЕФЗЂеЙЕЅВуИажЊЦїЃК
1958ФъЬсГіЃЌгыMPФЃаЭВЛЭЌДІдкгкШЈжЕПЩБфЃЌетбљОЭПЩвдНјаабЇЯАЁЃЫќАќКЌвЛИіЯпадРлМгЦїКЭЖўжЕуажЕдЊМўЃЈМЄЛюКЏЪ§ЪЧуажЕКЏЪ§ЃЉЃЌЛЙАќРЈЭтВПЦЋВюbЁЃЕЅВуИажЊЦїБЛЩшМЦгУРДЖдЪфШыНјааЖўЗжРрЃЌЕБИажЊЦїЪфГі+1ЪБЃЌЪфШыЮЊвЛРрЃЛЕБЪфГіЮЊ-1ЪБЃЌЪфШыЮЊСэвЛРрЁЃжЎКѓЛЙгагІгУLMSЫуЗЈЕФЕЅВуИажЊЦїЁЃ
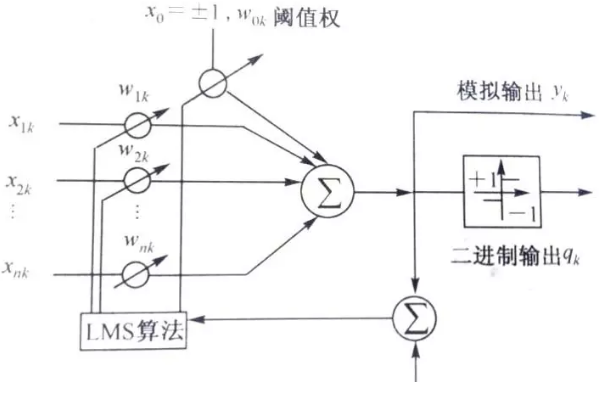
ЕЅВуИажЊЦїЕФШБЯнЪЧжЛФмЖдЯпадЮЪЬтЗжРрЁЃШчЯТЭМЃЌзѓБпФмгУвЛИљЯпЗжПЊЃЌЕЋгвБпШДВЛФмЁЃ
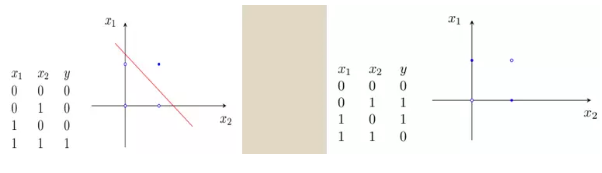
ИУШБЯнРДздМЄЛюКЏЪ§ЁЃИФНјЫМТЗОЭЪЧаоИФМЄЛюКЏЪ§ЃЈАбЗжРрЯпБфГЩЧњЯпЃЌШчЭждВЯпЃЉЁЂдіМгЩёОЭјТчВуЪ§ЃЈШУСНЬѕжБЯпЛђЖрЬѕжБЯпРДЗжРрЃЉЁЃжїСїзіЗЈЪЧдіМгВуЪ§ЃЌгкЪЧгаСЫЖрВуИажЊЦїЁЃ
ЖрВуИажЊЦїЃК
дкЪфШыВуКЭЪфГіВужЎМфдіМгвўКЌВуЃЈвђЮЊВЛФмдкбЕСЗбљБОжаЙлВьЕНЫќУЧЕФжЕЃЌЫљвдНавўКЌВуЃЉЁЃ
ЖрВуИажЊЦїЗжРрФмСІШчЯТЃК
ЫцзХвўВуВуЪ§ЕФдіЖрЃЌЭЙгђНЋПЩвдаЮГЩШЮвтЕФаЮзДЃЌвђДЫПЩвдНтОіШЮКЮИДдгЕФЗжРрЮЪЬтЁЃKolmogorovРэТлжИГіЃКЫЋвўВуИажЊЦїОЭзувдНтОіШЮКЮИДдгЕФЗжРрЮЪЬтЁЃЕЋВуЪ§ЕФдіЖрДјРДвўКЌВуЕФШЈжЕбЕСЗЮЪЬтЃЌЖдгкИївўВуЕФНкЕуРДЫЕЃЌЫќУЧВЂВЛДцдкЦкЭћЪфГіЃЌЫљвдвВЮоЗЈЭЈЙ§ИажЊЦїЕФбЇЯАЙцдђРДбЕСЗЖрВуИажЊЦїЁЃ1966ФъЃЌMiniskyКЭPapertдкЫћУЧЕФЁЖИажЊЦїЁЗвЛЪщжаЬсГіСЫЩЯЪіЕФИажЊЦїЕФбаОПЦПОБЃЌжИГіРэТлЩЯЛЙВЛФмжЄУїНЋИажЊЦїФЃаЭРЉеЙЕНЖрВуЭјТчЪЧгавтвхЕФЁЃШЫЙЄЩёОЭјТчНјШыЕЭЙШЦкЁЃжБЕНГіЯжЮѓВюЗДЯђДЋВЅЫуЗЈЃЈBPЃКErrorBack
PropagationЃЉЃЌНтОіСЫЖрВуИажЊЦїЕФбЇЯАЮЪЬтЁЃ
BPЩёОЭјТчЃКBPЩёОЭјТчДцдкСНЬѕаХКХЯпЃЌЙЄзїаХКХе§ЯђДЋВЅЃЌЮѓВюаХКХЗДЯђДЋВЅЁЃЗДЯђДЋВЅЙ§ГЬжаЃЌж№ВуаоИФСЌНгШЈжЕЁЃBPЫуЗЈПЩвдПДзїLMSЫуЗЈЕФРлМгАцЃЌвђЮЊЖдгкЪфГіВуЕФЕЅИіЩёОдЊЃЌЦфбЇЯАЫуЗЈЮЊLMSЫуЗЈЁЃ
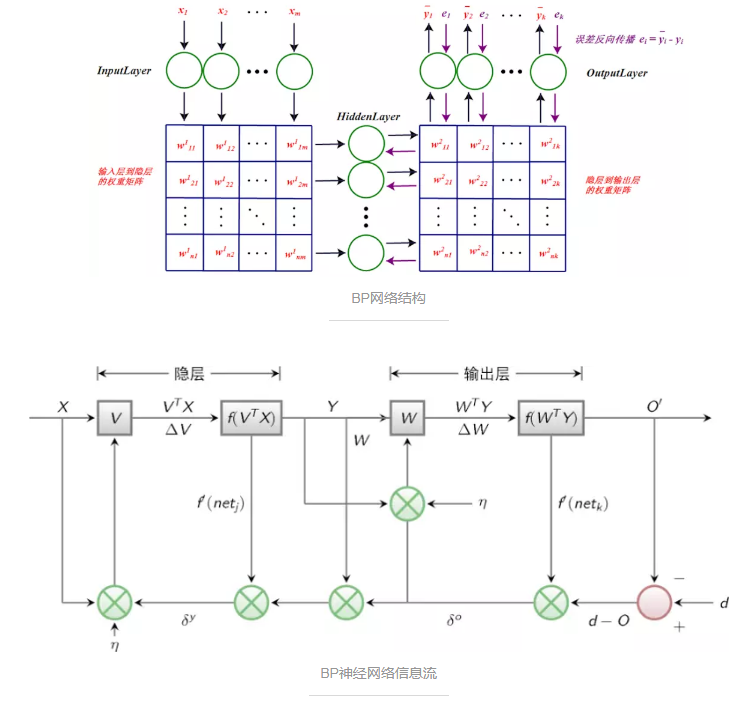
ЃЈВЛФмЬљЙЋЪНВЛКУНтЪЭАЁ -_-!ЃЉsigmaЪЧЮѓВюаХКХЃЌyitaЪЧбЇЯАТЪЃЌnetЪЧЪфШыжЎКЭЃЌVЪЧЪфШыВуЕНвўКЌВуЕФШЈжиОиеѓЃЌWЪЧвўКЌВуЕНЪфГіВуЕФШЈжиОиеѓЁЃ
жЎКѓЛЙгаМИжжОЖЯђЛљЭјТчЃЈRBFЃКRadial Basis FunctionЃЉЃК
RBFЩёОЭјТчЪєгкЖрВуЧАЯђЩёОЭјТчЃЌЫќЪЧвЛжжШ§ВуЧАЯђЭјТчЁЃЪфШыВугЩаХКХдДНкЕузщГЩЃЛЕкЖўВуЮЊвўКЌВуЃЌвўЕЅдЊИіЪ§гЩЫљУшЪіЕФЮЪЬтЖјЖЈЃЌвўЕЅдЊЕФБфЛЛКЏЪ§ЪЧЖджааФЕуОЖЯђЖдГЦЧвЫЅМѕЕФЗЧИКЗЧЯпадКЏЪ§ЃЛЕкШ§ВуЮЊЪфГіВуЁЃЦфЛљБОЫМЯыЪЧЃКгУОЖЯђЛљКЏЪ§зїЮЊвўЕЅдЊЕФЁАЛљЁБЃЌЙЙГЩвўКЌВуПеМфЃЌвўКЌВуЖдЪфШыЪИСПНјааБфЛЛЃЌНЋЕЭЮЌЕФФЃЪНЪфШыЪ§ОнБфЛЛЕНИпЮЌПеМфФкЃЌЪЙЕУдкЕЭЮЌПеМфФкЕФЯпадВЛПЩЗжЮЪЬтдкИпЮЌПеМфФкЯпадПЩЗжЁЃRBFЭјТчЗжЮЊе§ЙцЛЏЭјТчКЭЙувхЭјТчЁЃЧјБ№дкгквўКЌВуЕФИіЪ§ЁЃЛљКЏЪ§вЛАубЁгУИёСжКЏЪ§ЁЃ
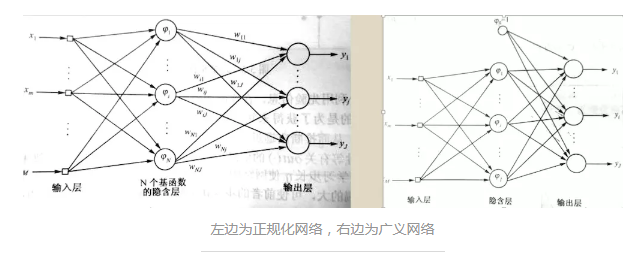
зѓБпЮЊе§ЙцЛЏЭјТчЃЌгвБпЮЊЙувхЭјТчRBFвЊбЇЯАЕФЫуЗЈгаШ§ИіЃКЛљКЏЪ§ЕФжааФЁЂЛљКЏЪ§ЕФЗНВюЁЂШЈжЕЁЃбЇЯАжааФвЊгУЕНОлРрЫуЗЈЃЌГЃгУK-ОљжЕОлРрЫуЗЈЁЃШЗЖЈжааФКѓЃЌПЩвдгУЪ§бЇЙЋЪНЧѓГіЗНВюЁЃбЇЯАШЈжЕПЩвдгУLMSЫуЗЈЁЃ
RBFЭјТчгыBPЭјТчБШНЯЃКRBFФмЙЛБЦНќШЮвтЗЧЯпадКЏЪ§ЁЃBPЭјТчЪЧЖдЗЧЯпадгГЩфЕФШЋОжБЦНќЃЌЖјRBFЭјТчЪЙгУОжВПжИЪ§ЫЅМѕЕФЗЧЯпадКЏЪ§НјааОжВПБЦНќЁЃвЊДяЕНЯрЭЌЕФОЋЖШЃЌRBFЭјТчЫљашвЊЕФВЮЪ§БШBPЭјТчвЊЩйЕУЖрЁЃжЇГжЯђСПЛњЃЈSVMЃКSupport
Vector MachineЃЉ:
жЎЧАЕФBPЩёОЭјТчДцдкЕФМИИіЮЪЬтЃК
1ЁЂBPЫуЗЈЪЧгУЬнЖШЗЈЕМГіЕФЃЌвђДЫгХЛЏЙ§ГЬПЩФмЯнШыОжВПМЋжЕЁЃ
2ЁЂBPЫуЗЈЕФФПБъКЏЪ§ЪЧОбщЗчЯеЃЌЫќжЛФмБЃжЄЗжРрЮѓВюЖдгкгаЯоИібљБОЪЧМЋаЁЃЌЮоЗЈБЃжЄЖдЫљгаПЩФмЕФЕуДяЕНМЋаЁЁЃ
3ЁЂЩёОЭјТчНсЙЙЕФЩшМЦЃЈШчвўНкЕуЪ§ФПЕФбЁдёЃЉвРРЕЩшМЦепЕФЯШбщжЊЪЖЃЌШБЗІвЛжжгаРэТлвРОнЕФбЯИёЩшМЦГЬађЁЃ
гкЪЧгаСЫжЇГжЯђСПЛњЃК
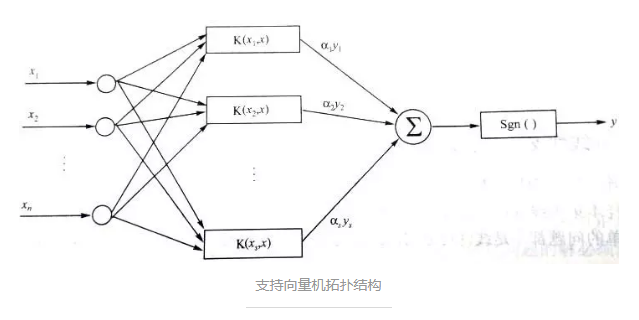
жЇГжЯђСПЛњЭиЦЫНсЙЙЦфЫћ:
ЛЙгаHopfieldЩёОЭјТчЁЂЫцЛњЩёОЭјТчBoltzmannЛњЁЂHammingОКељЩёОЭјТчЕШЁЃ
ЫцзХМЦЫуЛњгВМўМЦЫуФмСІдНРДдНЧПЃЌгУРДбЕСЗЕФЪ§ОндНРДдНЖрЃЌЩёОЭјТчБфЕУдНРДдНИДдгЁЃдкШЫЙЄжЧФмСьгђГЃЬ§ЕНDNNЃЈЩюЖШЩёОЭјТчЃЉЁЂCNNЃЈОэЛ§ЩёОЭјТчЃЉЁЂRNNЃЈЕнЙщЩёОЭјТчЃЉЁЃЦфжаЃЌDNNЪЧзмГЦЃЌжИВуЪ§ЗЧГЃЖрЕФЭјТчЃЌЭЈГЃгаЖўЪЎМИВуЃЌОпЬхПЩвдЪЧCNNЛђRNNЕШЭјТчНсЙЙЁЃ
|









