| 编辑推荐: |
本文来自于csdn,本文是主要介绍了神经网络应用在分类问题中效果,以及神经网络结构及算法,希望对您的学习有所帮助。
|
|
1.什么是神经网络
1.1 基本结构
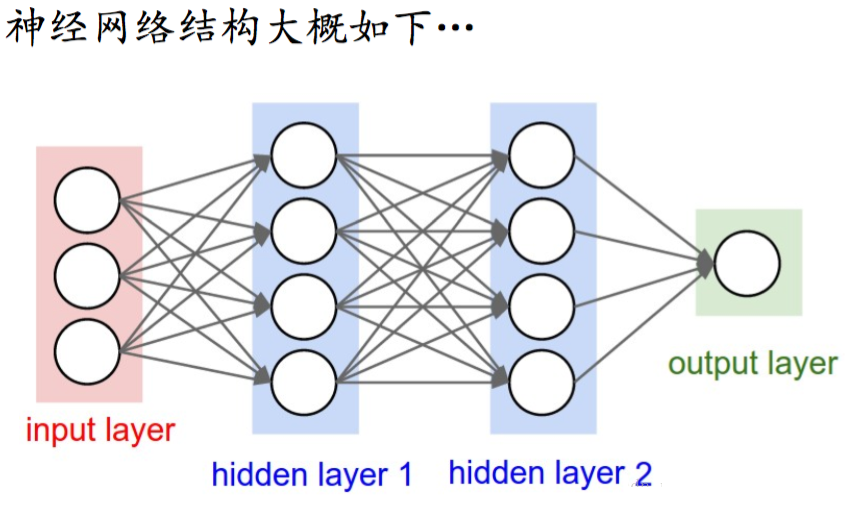
说明:
通常一个神经网络由一个input layer,多个hidden layer和一个output layer构成。
图中圆圈可以视为一个神经元(又可以称为感知器)
设计神经网络的重要工作是设计hidden layer,及神经元之间的权重
添加少量隐层获得浅层神经网络SNN;隐层很多时就是深层神经网络DNN
如果你觉得这篇文章看起来稍微还有些吃力,或者想要系统地学习人工智能,那么推荐你去看床长人工智能教程。非常棒的大神之作。教程不仅通俗易懂,而且很风趣幽默。点击这里可以查看教程。
1.2 从逻辑回归到神经元
LinearRegression模型:
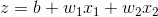
sigmoid函数:
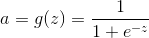
LR可以理解为如下结构:
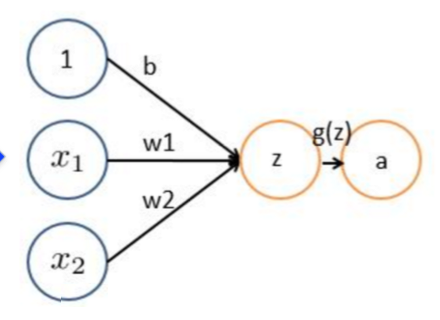
所以逻辑回归是一个单层感知器(没有隐层)结构。
2 为什么需要神经网络
首先,神经网络应用在分类问题中效果很好。? 工业界中分类问题居多。
LR或者linear SVM更适用线性分割。如果数据非线性可分(现实生活中多是非线性的),LR通常需要靠特征工程做特征映射,增加高斯项或者组合项;SVM需要选择核。
而增加高斯项、组合项会产生很多没有用的维度,增加计算量。GBDT可以使用弱的线性分类器组合成强分类器,但维度很高时效果可能并不好。
2.1 非线性可分怎么办
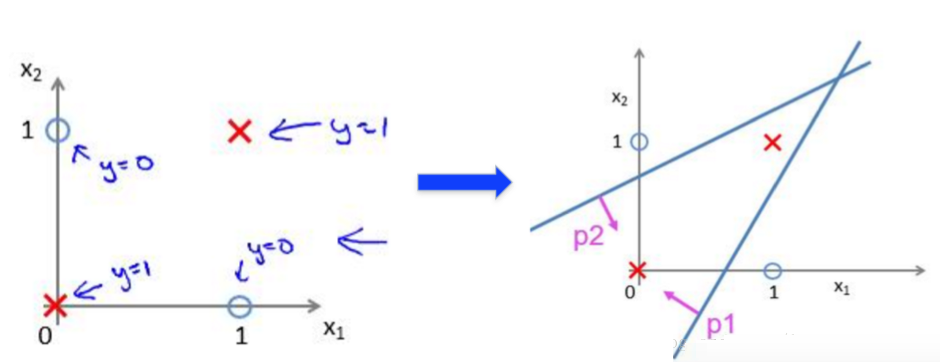
如下图非线性可分
从逻辑回归看,单层感知器只能解决线性问题。要解决非线性问题,需要引入多层感知器(加入隐层)。
这时使用两个线性分类器,再求逻辑与就可以达到分类的效果。? 注意,最开始的两个线性分类器都是部分正确的分类器
2.2 神经元完成逻辑与
前面说可以使用两个线性分类器的逻辑与可以完成上例的非线性分割。暂时不管两个线性分类器,现在先使用神经元(感知器)达到逻辑与的效果
假设 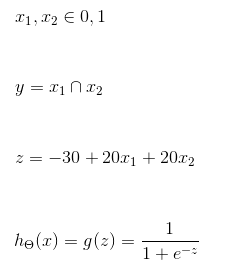
这样,g(z)完成逻辑与: 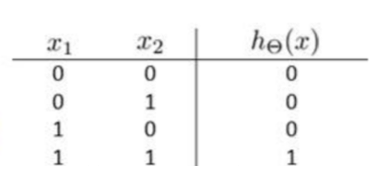
调整z的参数,可以实现逻辑或等操作
2.3 流程图
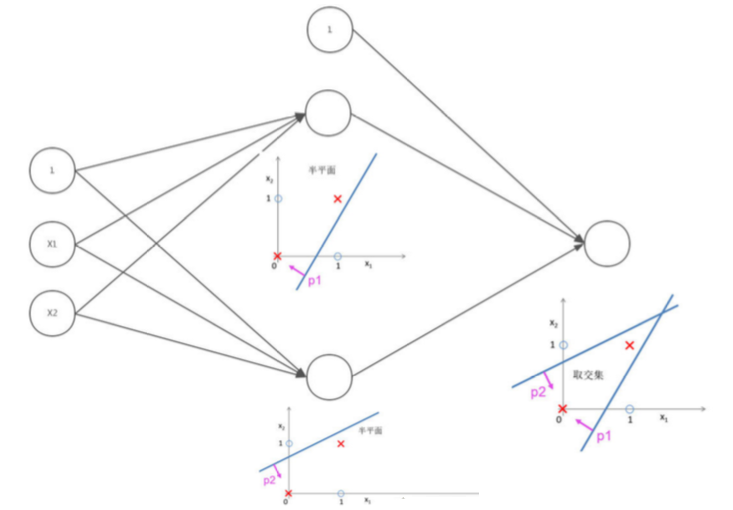
可以看到,先有imput layer生产两个线性分类器,在通过两个线性分类器的权重组合构成逻辑与,完成非线性分类。
注意,训练两个线性分类器需要imput的权重,逻辑与又需要两个线性分类器的权重。
2.4 效果
对线性分类器的逻辑与和逻辑或的组合可以完美的对平面样本进行分类
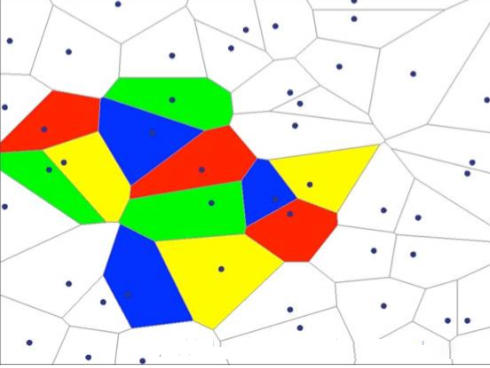
隐层决定了最终的分类效果
由上图可以看出,随着隐层层数的增多,凸域将可以形成任意的形状,因此可以解决任何复杂的分类问题。实际上,Kolmogorov理论指出:双隐层感知器就足以解决任何复杂的分类问题。
3 神经网络表达力与过拟合
理论上,单隐层神经网络可以逼近任何连续函数(只要隐层的神经元个数足够)
虽然从数学上看多隐层和单隐层表达能力一致,但多隐层的神经网络比单隐层神经网络工程效果好很多
对于一些分类数据(比如CTR预估),3层神经网络效果优于2层神经网络,但如果把层数不断增加(4,5,6层),对最后的结果的帮助没有那么大的跳变
图像数据比较特殊,是一种深层的结构化数据,深层次的卷积神经网络能更充分和准确的把这些层级信息表达出来
提升隐层数量或者隐层神经元个数,神经网络的“容量”会变大,空间表达能力会变强
过多的隐层和神经元结点会带来过拟合问题
不要试图降低神经网络参数量来减缓过拟合,用正则化或者dropout
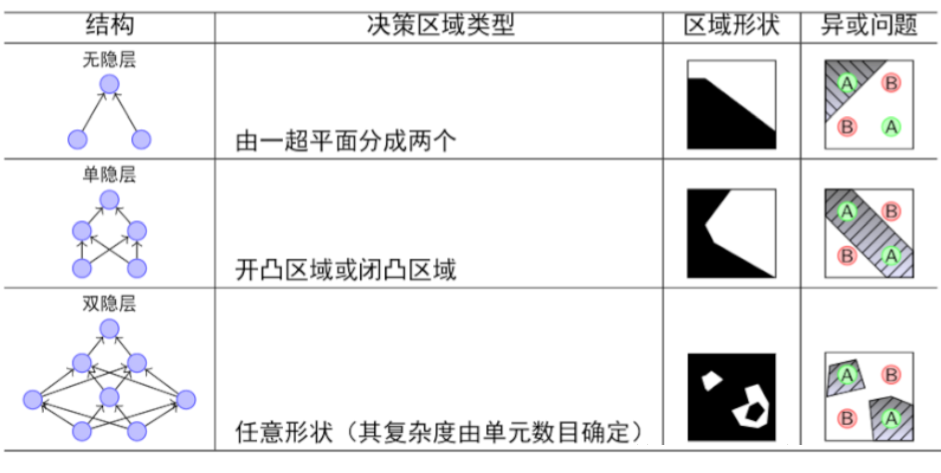
4 神经网络结构
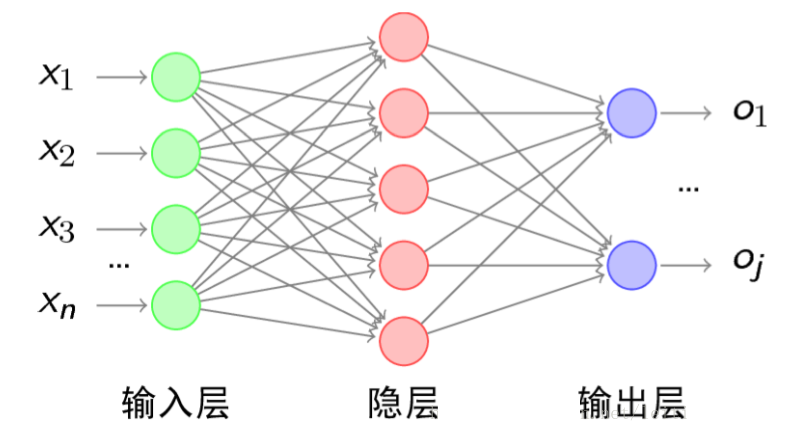
4.1 网络结构
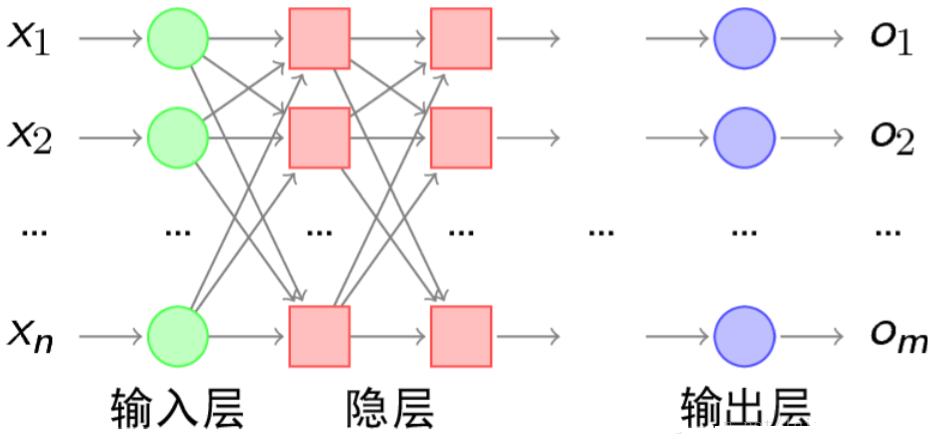
n个输入;输出m个概率
4.2 传递函数/激活函数
前面每一层输入经过线性变换wx+b后还用到了sigmoid函数,在神经网络的结构中被称为传递函数或者激活函数。??
除了sigmoid,还有tanh、relu等别的激活函数。激活函数使线性的结果非线性化。
4.2.1 为什么需要传递函数
简单理解上,如果不加激活函数,无论多少层隐层,最终的结果还是原始输入的线性变化,这样一层隐层就可以达到结果,就没有多层感知器的意义了。所以每个隐层都会配一个激活函数,提供非线性变化。
4.2.2 介绍两种激活函数
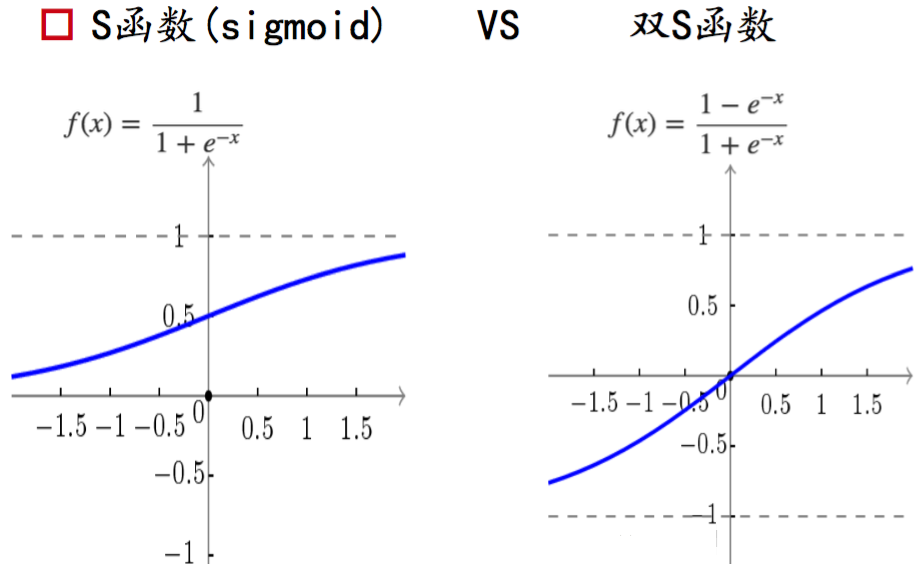
双S函数又被称为tanh函数
5 BP算法
5.1 网络结构
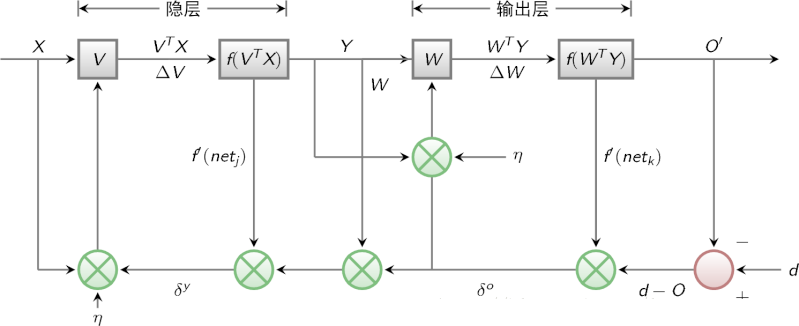
1. 正向传播求损失,反向传播回传误差
2. 根据误差信号修正每层的权重
3. f是激活函数;f(netj)是隐层的输出; f(netk)是输出层的输出O; d是target
5.2 如何反向传播
以三层感知器为例:
结合BP网络结构,误差由输出展开至输入的过程如下:

有了误差E,通过求偏导就可以求得最优的权重。(不要忘记学习率)

BP算法属于δ学习规则类,这类算法常被称为误差的梯度下降算法。 这类算法要求变换函数可导(sigmoid是满足的)
5.3 举例
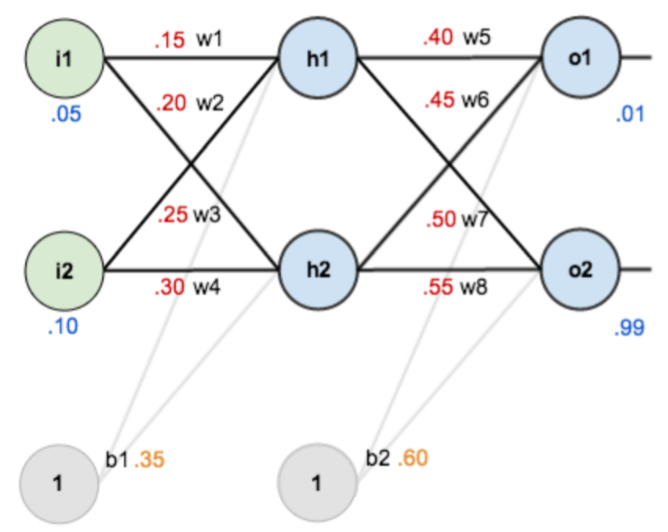
图中元素:
两个输入;
隐层: b1, w1, w2, w3, w4 (都有初始值)
输出层:b2, w5, w6, w7, w8(赋了初始值)
5.3.1 前向运算? 计算误差 
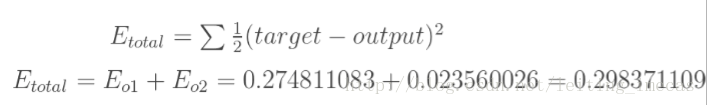
则误差:

参数更新:

求误差对w1的偏导
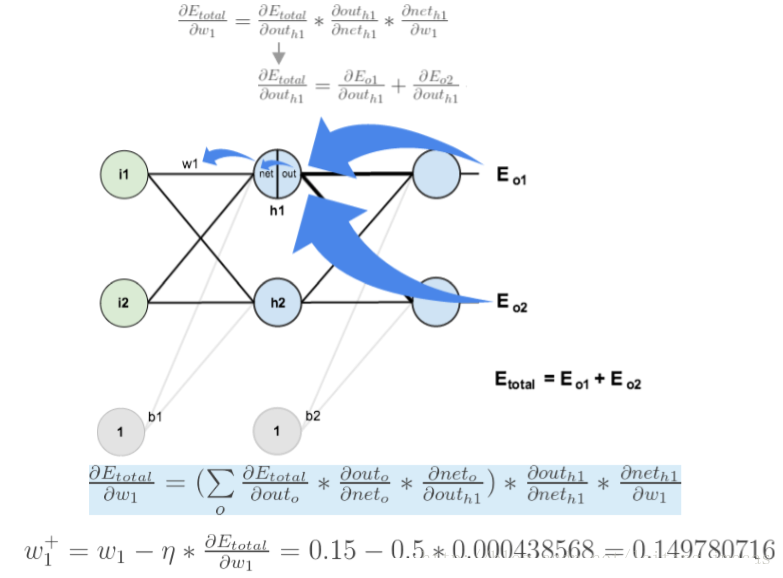
5.3.2 反向传播
求误差对w5的偏导过程 参数更新: 求误差对w1的偏导 注意,w1对两个输出的误差都有影响
通过以上过程可以更新所有权重,就可以再次迭代更新了,直到满足条件。
|









