| БрМЭЦМі: |
БОЮФРДздгкcsdnЃЌЮФеТжївЊНщЩмСЫМЏГЩбЇЯАЕФМИжжЗНЗЈКЭЦфЯргІЕФгІгУЕШЯрЙиФкШн
ЁЃ |
|
МЏГЩбЇЯАжївЊЗжЮЊ baggingЃЌ boosting КЭ stackingЗНЗЈЁЃБОЮФжївЊЪЧНщЩмstackingЗНЗЈМАЦфгІгУЁЃЕЋЪЧдкзмНсжЎЧАЛЙЪЧЯШЛиЙЫвЛЯТМЬГабЇЯАЁЃ
етВПЗжжївЊзЊздЭјТчЁЃ
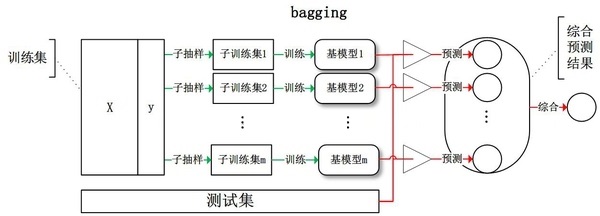
1. BaggingЗНЗЈЃК
ИјЖЈвЛИіДѓаЁЮЊnЕФбЕСЗМЏ DЃЌBaggingЫуЗЈДгжаОљдШЁЂгаЗХЛиЕибЁГі mИіДѓаЁЮЊ n' ЕФзгМЏDiЃЌзїЮЊаТЕФбЕСЗМЏЁЃдкет
mИібЕСЗМЏЩЯЪЙгУЗжРрЁЂЛиЙщЕШЫуЗЈЃЌдђПЩЕУЕН mИіФЃаЭЃЌдйЭЈЙ§ШЁЦНОљжЕЁЂШЁЖрЪ§ЦБЕШЗНЗЈзлКЯВњЩњдЄВтНсЙћЃЌМДПЩЕУЕНBaggingЕФНсЙћЁЃ
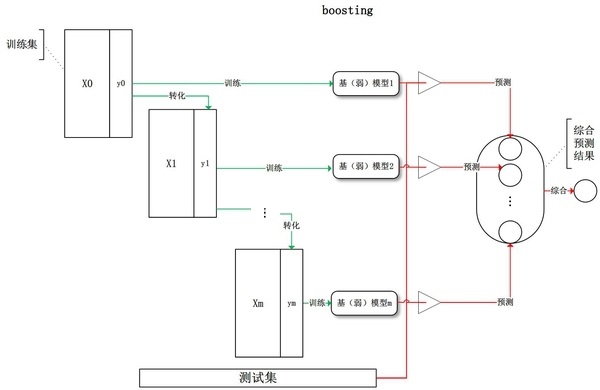
2. Boosting ЗНЗЈ
МгШыЕФЙ§ГЬжаЃЌЭЈГЃИљОнЫќУЧЕФЩЯвЛТжЕФЗжРрзМШЗТЪИјгшВЛЭЌЕФШЈжиЁЃМгКЭШѕбЇЯАепжЎКѓЃЌЪ§ОнЭЈГЃЛсБЛжиаТМгШЈЃЌРДЧПЛЏЖджЎЧАЗжРрДэЮѓЪ§ОнЕуЕФЗжРрЃЌЦфжавЛИіОЕфЕФЬсЩ§ЫуЗЈР§згЪЧAdaBoostЁЃ
3. Stacking ЗНЗЈЃК
НЋбЕСЗКУЕФЫљгаЛљФЃаЭЖдећИібЕСЗМЏНјаадЄВтЃЌЕкjИіЛљФЃаЭЖдЕкiИібЕСЗбљБОЕФдЄВтжЕНЋзїЮЊаТЕФбЕСЗМЏжаЕкiИібљБОЕФЕкjИіЬиеїжЕЃЌзюКѓЛљгкаТЕФбЕСЗМЏНјаабЕСЗЁЃЭЌРэЃЌдЄВтЕФЙ§ГЬвВвЊЯШОЙ§ЫљгаЛљФЃаЭЕФдЄВтаЮГЩаТЕФВтЪдМЏЃЌзюКѓдйЖдВтЪдМЏНјаадЄВтЃК
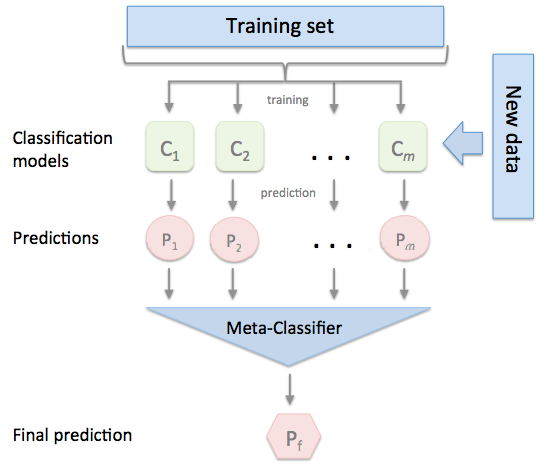
ЯТУцЮвУЧНщЩмвЛПюЙІФмЧПДѓЕФstackingРћЦїЃЌmlxtendПтЃЌЫќПЩвдКмПьЕиЭъГЩЖдsklearnФЃаЭЕиstackingЁЃ
жївЊгавдЯТМИжжЪЙгУЗНЗЈАЩЃК
I. зюЛљБОЕФЪЙгУЗНЗЈЃЌМДЪЙгУЧАУцЗжРрЦїВњЩњЕФЬиеїЪфГізїЮЊзюКѓзмЕФmeta-classifierЕФЪфШыЪ§Он
from sklearn
import datasets
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
import numpy as np
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingClassifier(classifiers=[clf1, clf2,
clf3],
meta_classifier=lr)
print('3-fold cross validation:\n')
for clf, label in zip([clf1, clf2, clf3, sclf],
['KNN',
'Random Forest',
'Naive Bayes',
'StackingClassifier']):
scores = model_selection.cross_val_score(clf,
X, y,
cv=3, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label)) |
II. СэвЛжжЪЙгУЕквЛВуЛљБОЗжРрЦїВњЩњЕФРрБ№ИХТЪжЕзїЮЊmeta-classfierЕФЪфШыЃЌетжжЧщПіЯТашвЊНЋStackingClassifierЕФВЮЪ§ЩшжУЮЊ
use_probas=TrueЁЃШчЙћНЋВЮЪ§ЩшжУЮЊ average_probas=TrueЃЌФЧУДетаЉЛљЗжРрЦїЖдУПвЛИіРрБ№ВњЩњЕФИХТЪжЕЛсБЛЦНОљЃЌЗёдђЛсЦДНгЁЃ
Р§ШчгаСНИіЛљЗжРрЦїВњЩњЕФИХТЪЪфГіЮЊЃК
classifier 1: [0.2, 0.5, 0.3]
classifier 2: [0.3, 0.4, 0.4]
1) average = True :
ВњЩњЕФmeta-feature ЮЊЃК[0.25, 0.45, 0.35]
2) average = False:
ВњЩњЕФmeta-featureЮЊЃК[0.2, 0.5, 0.3, 0.3, 0.4, 0.4]
from sklearn
import datasets
iris = datasets.load_iris()
X, y = iris.data[:, 1:3], iris.target
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from mlxtend.classifier import StackingClassifier
import numpy as np
clf1 = KNeighborsClassifier(n_neighbors=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
lr = LogisticRegression()
sclf = StackingClassifier(classifiers=[clf1, clf2,
clf3],
use_probas=True,
average_probas=False,
meta_classifier=lr)
print('3-fold cross validation:\n')
for clf, label in zip([clf1, clf2, clf3, sclf],
['KNN',
'Random Forest',
'Naive Bayes',
'StackingClassifier']):
scores = model_selection.cross_val_score(clf,
X, y,
cv=3, scoring='accuracy')
print("Accuracy: %0.2f (+/- %0.2f) [%s]"
% (scores.mean(), scores.std(), label)) |
III. СэЭтвЛжжЗНЗЈЪЧЖдбЕСЗЛљжаЕФЬиеїЮЌЖШНјааВйзїЕФЃЌетДЮВЛЪЧИјУПвЛИіЛљЗжРрЦїШЋВПЕФЬиеїЃЌЖјЪЧИјВЛЭЌЕФЛљЗжРрЦїЗжВЛЭЌЕФЬиеїЃЌМДБШШчЛљЗжРрЦї1бЕСЗЧААыВПЗжЬиеїЃЌЛљЗжРрЦї2бЕСЗКѓАыВПЗжЬиеїЃЈПЩвдЭЈЙ§sklearn
ЕФpipelines ЪЕЯжЃЉЁЃзюжеЭЈЙ§StackingClassifierзщКЯЦ№РДЁЃ
from sklearn.datasets
import load_iris
from mlxtend.classifier import StackingClassifier
from mlxtend.feature_selection import ColumnSelector
from sklearn.pipeline import make_pipeline
from sklearn.linear_model import LogisticRegression
iris = load_iris()
X = iris.data
y = iris.target
pipe1 = make_pipeline(ColumnSelector(cols=(0,
2)),
LogisticRegression())
pipe2 = make_pipeline(ColumnSelector(cols=(1,
2, 3)),
LogisticRegression())
sclf = StackingClassifier(classifiers=[pipe1,
pipe2],
meta_classifier=LogisticRegression())
sclf.fit(X, y) |
StackingClassifier ЪЙгУAPIМАВЮЪ§НтЮіЃК
StackingClassifier(classifiers, meta_classifier, use_probas=False,
average_probas=False, verbose=0, use_features_in_secondary=False)
ВЮЪ§ЃК
classifiers : ЛљЗжРрЦїЃЌЪ§зщаЮЪНЃЌ[cl1, cl2, cl3]. УПИіЛљЗжРрЦїЕФЪєадБЛДцДЂдкРрЪєад
self.clfs_.
meta_classifier : ФПБъЗжРрЦїЃЌМДНЋЧАУцЗжРрЦїКЯЦ№РДЕФЗжРрЦї
use_probas : bool (default: False) ЃЌШчЙћЩшжУЮЊTrueЃЌ ФЧУДФПБъЗжРрЦїЕФЪфШыОЭЪЧЧАУцЗжРрЪфГіЕФРрБ№ИХТЪжЕЖјВЛЪЧРрБ№БъЧЉ
average_probas : bool (default: False)ЃЌгУРДЩшжУЩЯвЛИіВЮЪ§ЕБЪЙгУИХТЪжЕЪфГіЕФЪБКђЪЧЗёЪЙгУЦНОљжЕЁЃ
verbose : int, optional (default=0)ЁЃгУРДПижЦЪЙгУЙ§ГЬжаЕФШежОЪфГіЃЌЕБ
verbose = 0ЪБЃЌЪВУДвВВЛЪфГіЃЌ verbose = 1ЃЌЪфГіЛиЙщЦїЕФађКХКЭУћзжЁЃverbose
= 2ЃЌЪфГіЯъЯИЕФВЮЪ§аХЯЂЁЃverbose > 2, здЖЏНЋverboseЩшжУЮЊаЁгк2ЕФЃЌverbose
-2.
use_features_in_secondary : bool (default: False).
ШчЙћЩшжУЮЊTrueЃЌФЧУДзюжеЕФФПБъЗжРрЦїОЭБЛЛљЗжРрЦїВњЩњЕФЪ§ОнКЭзюГѕЕФЪ§ОнМЏЭЌЪБбЕСЗЁЃШчЙћЩшжУЮЊFalseЃЌзюжеЕФЗжРрЦїжЛЛсЪЙгУЛљЗжРрЦїВњЩњЕФЪ§ОнбЕСЗЁЃ
ЪєадЃК
clfs_ : УПИіЛљЗжРрЦїЕФЪєадЃЌlist, shape ЮЊ [n_classifiers]ЁЃ
meta_clf_ : зюжеФПБъЗжРрЦїЕФЪєад
ЗНЗЈЃК
fit(X, y)
fit_transform(X, y=None, fit_params)
get_params(deep=True)ЃЌШчЙћЪЧЪЙгУsklearnЕФGridSearchЗНЗЈЃЌФЧУДЗЕЛиЗжРрЦїЕФИїЯюВЮЪ§ЁЃ
predict(X)
predict_proba(X)
score(X, y, sample_weight=None)ЃЌ ЖдгкИјЖЈЪ§ОнМЏКЭИјЖЈlabelЃЌЗЕЛиЦРМлaccuracy
set_params(params)ЃЌЩшжУЗжРрЦїЕФВЮЪ§ЃЌparamsЕФЩшжУЗНЗЈКЭsklearnЕФИёЪНвЛбљ |









