| БрМЭЦМі: |
БОЮФРДздгкВЉПЭдАЃЌБОЮФжївЊЪЙгУЛњЦїбЇЯАЫуЗЈРДНЋИіЬхЛњЦїбЇЯАЦїЕФНсЙћНсКЯдквЛЦ№ЃЌетИіЗНЗЈОЭЪЧStackingЃЌЯЃЭћЖдФњЕФбЇЯАгаЫљАяжњЁЃ
|
|
МЏГЩбЇЯА
Ensemble learning жаЮФУћНазіМЏГЩбЇЯАЃЌЫќВЂВЛЪЧвЛИіЕЅЖРЕФЛњЦїбЇЯАЫуЗЈЃЌЖјЪЧНЋКмЖрЕФЛњЦїбЇЯАЫуЗЈНсКЯдквЛЦ№ЃЌЮвУЧАбзщГЩМЏГЩбЇЯАЕФЫуЗЈНазіЁАИіЬхбЇЯАЦїЁБЁЃдкМЏГЩбЇЯАЦїЕБжаЃЌИіЬхбЇЯАЦїЖМЯрЭЌЃЌФЧУДетаЉИіЬхбЇЯАЦїПЩвдНазіЁАЛљбЇЯАЦїЁБЁЃ
ИіЬхбЇЯАЦїзщКЯдквЛЦ№аЮГЩЕФМЏГЩбЇЯАЃЌГЃГЃФмЙЛЪЙЕУЗКЛЏадФмЬсИпЃЌетЖдгкЁАШѕбЇЯАЦїЁБЕФЬсИпгШЮЊУїЯдЁЃШѕбЇЯАЦїжИЕФЪЧБШЫцЛњВТЯывЊКУвЛаЉЕФбЇЯАЦїЁЃ
дкНјааМЏГЩбЇЯАЕФЪБКђЃЌЮвУЧЯЃЭћЮвУЧЕФЛљбЇЯАЦїгІИУЪЧКУЖјВЛЭЌЃЌетИіЫМЯыдкКѓУцОГЃЬхЯжЁЃ ЁАКУЁБОЭЪЧЫЕЃЌФуЕФЛљбЇЯАЦїВЛФмЬЋВюЃЌЁАВЛЭЌЁБОЭЪЧИїИібЇЯАЦїОЁСПгаВювьЁЃ
МЏГЩбЇЯАгаСНИіЗжРрЃЌвЛИіЪЧИіЬхбЇЯАЦїДцдкЧПвРРЕЙиЯЕЁЂБиаыДЎааЩњГЩЕФађСаЛЏЗНЗЈЃЌвдBoostingЮЊДњБэЁЃСэЭтвЛжжЪЧИіЬхбЇЯАЦїВЛДцдкЧПвРРЕЙиЯЕЁЂПЩЭЌЪБЩњГЩЕФВЂааЛЏЗНЗЈЃЌвдBaggingКЭЫцЛњЩСжЃЈRandom
ForestЃЉЮЊДњБэЁЃ
Stacking ЕФЛљБОЫМЯы
НЋИіЬхбЇЯАЦїНсКЯдквЛЦ№ЕФЪБКђЪЙгУЕФЗНЗЈНазіНсКЯВпТдЁЃЖдгкЗжРрЮЪЬтЃЌЮвУЧПЩвдЪЙгУЭЖЦБЗЈРДбЁдёЪфГізюЖрЕФРрЁЃЖдгкЛиЙщЮЪЬтЃЌЮвУЧПЩвдНЋЗжРрЦїЪфГіЕФНсЙћЧѓЦНОљжЕЁЃ
ЩЯУцЫЕЕФЭЖЦБЗЈКЭЦНОљЗЈЖМЪЧКмгааЇЕФНсКЯВпТдЃЌЛЙгавЛжжНсКЯВпТдЪЧЪЙгУСэЭтвЛИіЛњЦїбЇЯАЫуЗЈРДНЋИіЬхЛњЦїбЇЯАЦїЕФНсЙћНсКЯдквЛЦ№ЃЌетИіЗНЗЈОЭЪЧStackingЁЃ
дкstackingЗНЗЈжаЃЌЮвУЧАбИіЬхбЇЯАЦїНазіГѕМЖбЇЯАЦїЃЌгУгкНсКЯЕФбЇЯАЦїНазіДЮМЖбЇЯАЦїЛђдЊбЇЯАЦїЃЈmeta-learnerЃЉЃЌДЮМЖбЇЯАЦїгУгкбЕСЗЕФЪ§ОнНазіДЮМЖбЕСЗМЏЁЃДЮМЖбЕСЗМЏЪЧдкбЕСЗМЏЩЯгУГѕМЖбЇЯАЦїЕУЕНЕФЁЃ
ЮвУЧЬљвЛеХжмжОЛЊРЯЪІЁЖЛњЦїбЇЯАЁЗвЛеХЭМРДЫЕвЛЯТstackingбЇЯАЫуЗЈЁЃ

Й§ГЬ1-3 ЪЧбЕСЗГіРДИіЬхбЇЯАЦїЃЌвВОЭЪЧГѕМЖбЇЯАЦїЁЃ
Й§ГЬ5-9ЪЧ ЪЙгУбЕСЗГіРДЕФИіЬхбЇЯАЦїРДЕУдЄВтЕФНсЙћЃЌетИідЄВтЕФНсЙћЕБзіДЮМЖбЇЯАЦїЕФбЕСЗМЏЁЃ
Й§ГЬ11 ЪЧгУГѕМЖбЇЯАЦїдЄВтЕФНсЙћбЕСЗГіДЮМЖбЇЯАЦїЃЌЕУЕНЮвУЧзюКѓбЕСЗЕФФЃаЭЁЃ
ШчЙћЯывЊдЄВтвЛИіЪ§ОнЕФЪфГіЃЌжЛашвЊАбетЬѕЪ§ОнгУГѕМЖбЇЯАЦїдЄВтЃЌШЛКѓНЋдЄВтКѓЕФНсЙћгУДЮМЖбЇЯАЦїдЄВтБуПЩЁЃ
StackingЕФЪЕЯж
зюЯШЯыЕНЕФЗНЗЈЪЧетбљЕФЃЌ
1ЃКгУЪ§ОнМЏDРДбЕСЗh1,h2,h3...ЃЌ
2ЃКгУетаЉбЕСЗГіРДЕФГѕМЖбЇЯАЦїдкЪ§ОнМЏDЩЯУцНјаадЄВтЕУЕНДЮМЖбЕСЗМЏЁЃ
3ЃКгУДЮМЖбЕСЗМЏРДбЕСЗДЮМЖбЇЯАЦїЁЃ
ЕЋЪЧетбљЕФЪЕЯжЪЧгаКмДѓЕФШБЯнЕФЁЃдкдЪМЪ§ОнМЏDЩЯУцбЕСЗЕФФЃаЭЃЌШЛКѓгУетаЉФЃаЭдйDЩЯУцдйНјаадЄВтЕУЕНЕФДЮМЖбЕСЗМЏПЯЖЈЪЧЗЧГЃКУЕФЁЃЛсГіЯжЙ§ФтКЯЕФЯжЯѓЁЃ
ФЧУДЃЌЮвУЧЛЛвЛжжзіЗЈЃЌЮвУЧгУНЛВцбщжЄЕФЫМЯыРДЪЕЯжstackingЕФФЃаЭЃЌДгетРяФУРДвЛеХЭМ
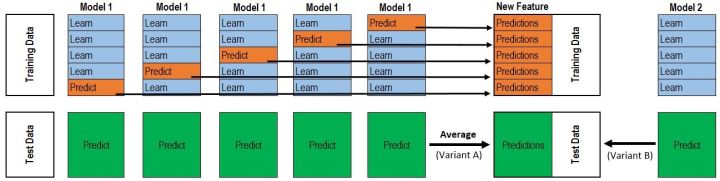
ДЮМЖбЕСЗМЏЕФЙЙГЩВЛЪЧжБНггЩФЃаЭдкбЕСЗМЏDЩЯУцдЄВтЕУЕНЃЌЖјЪЧЪЙгУНЛВцбщжЄЕФЗНЗЈЃЌНЋбЕСЗМЏDЗжЮЊkЗнЃЌЖдгкУПвЛЗнЃЌгУЪЃгрЪ§ОнМЏбЕСЗФЃаЭЃЌШЛКѓдЄВтГіетвЛЗнЕФНсЙћЁЃжиИДЩЯУцВНжшЃЌжБЕНУПвЛЗнЖМдЄВтГіРДЁЃетбљОЭВЛЛсГіЯжЩЯУцЕФЙ§ФтКЯетжжЧщПіЁЃВЂЧвдкЙЙдьДЮМЖбЕСЗМЏЕФЙ§ГЬЕБжаЃЌЫГБуАбВтЪдМЏЕФДЮМЖЪ§ОнвВИјЙЙдьГіРДСЫЁЃ
ЖдгкЮвУЧЫљгаЕФГѕМЖбЕСЗЦїЃЌЖМвЊжиИДЩЯУцЕФВНжшЃЌВХЙЙдьГіРДзюжеЕФДЮМЖбЕСЗМЏКЭДЮМЖВтЪдМЏЁЃ
ЙЙдьstackingЗНЗЈ
ЮвУЧаДвЛИіstackingЗНЗЈЃЌЯТУцЪЧЫќЕФЪЕЯжДњТыЃК
import numpy
as np
from sklearn.model_selection import KFold
def get_stacking(clf, x_train, y_train, x_test,
n_folds=10):
"""
етИіКЏЪ§ЪЧstackingЕФКЫаФЃЌЪЙгУНЛВцбщжЄЕФЗНЗЈЕУЕНДЮМЖбЕСЗМЏ
x_train, y_train, x_test ЕФжЕгІИУЮЊnumpyРяУцЕФЪ§зщРраЭ numpy.ndarray
.
ШчЙћЪфШыЮЊpandasЕФDataFrameРраЭдђЛсАбБЈДэ"""
train_num, test_num = x_train.shape[0], x_test.shape[0]
second_level_train_set = np.zeros((train_num,))
second_level_test_set = np.zeros((test_num,))
test_nfolds_sets = np.zeros((test_num, n_folds))
kf = KFold(n_splits=n_folds)
for i,(train_index, test_index) in enumerate(kf.split(x_train)):
x_tra, y_tra = x_train[train_index], y_train[train_index]
x_tst, y_tst = x_train[test_index], y_train[test_index]
clf.fit(x_tra, y_tra)
second_level_train_set[test_index] = clf.predict(x_tst)
test_nfolds_sets[:,i] = clf.predict(x_test)
second_level_test_set[:] = test_nfolds_sets.mean(axis=1)
return second_level_train_set, second_level_test_set
#ЮвУЧетРяЪЙгУ5ИіЗжРрЫуЗЈЃЌЮЊСЫЬхЯжstackingЕФЫМЯыЃЌОЭВЛМгВЮЪ§СЫ
from sklearn.ensemble import (RandomForestClassifier,
AdaBoostClassifier,
GradientBoostingClassifier, ExtraTreesClassifier)
from sklearn.svm import SVC
rf_model = RandomForestClassifier()
adb_model = AdaBoostClassifier()
gdbc_model = GradientBoostingClassifier()
et_model = ExtraTreesClassifier()
svc_model = SVC()
#дкетРяЮвУЧЪЙгУtrain_test_splitРДШЫЮЊЕФжЦдьвЛаЉЪ§Он
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
train_x, test_x, train_y, test_y = train_test_split(iris.data,
iris.target, test_size=0.2)
train_sets = []
test_sets = []
for clf in [rf_model, adb_model, gdbc_model,
et_model, svc_model]:
train_set, test_set = get_stacking(clf, train_x,
train_y, test_x)
train_sets.append(train_set)
test_sets.append(test_set)
meta_train = np.concatenate([result_set.reshape(-1,1)
for result_set in train_sets], axis=1)
meta_test = np.concatenate([y_test_set.reshape(-1,1)
for y_test_set in test_sets], axis=1)
#ЪЙгУОіВпЪїзїЮЊЮвУЧЕФДЮМЖЗжРрЦї
from sklearn.tree import DecisionTreeClassifier
dt_model = DecisionTreeClassifier()
dt_model.fit(meta_train, train_y)
df_predict = dt_model.predict(meta_test)
print(df_predict) |
ЪфГіНсЙћШчЯТ(вђЮЊЪЧЫцЛњЛЎЗжЕФЃЌЫљвдУПДЮдЫааНсЙћПЩФмВЛвЛбљ)ЃК
| [1 0 1 1 1 2
1 2 2 2 0 0 1 2 2 1 0 2 1 0 0 1 1 0 0 2 0 2 1
2] |
ЙЙдьstackingРр
ЪТЪЕЩЯЛЙПЩвдЙЙдьвЛИіstackingЕФРрЃЌЫќгЕгаfitКЭpredictЗНЗЈ
from sklearn.model_selection
import KFold
from sklearn.base import BaseEstimator, RegressorMixin,
TransformerMixin, clone
import numpy as np
#ЖдгкЗжРрЮЪЬтПЩвдЪЙгУ ClassifierMixin
class StackingAveragedModels(BaseEstimator,
RegressorMixin, TransformerMixin):
def __init__(self, base_models, meta_model,
n_folds=5):
self.base_models = base_models
self.meta_model = meta_model
self.n_folds = n_folds
# ЮвУЧНЋдРДЕФФЃаЭcloneГіРДЃЌВЂЧвНјааЪЕЯжfitЙІФм
def fit(self, X, y):
self.base_models_ = [list() for x in self.base_models]
self.meta_model_ = clone(self.meta_model)
kfold = KFold(n_splits=self.n_folds, shuffle=True,
random_state=156)
#ЖдгкУПИіФЃаЭЃЌЪЙгУНЛВцбщжЄЕФЗНЗЈРДбЕСЗГѕМЖбЇЯАЦїЃЌВЂЧвЕУЕНДЮМЖбЕСЗМЏ
out_of_fold_predictions = np.zeros((X.shape[0],
len(self.base_models)))
for i, model in enumerate(self.base_models):
for train_index, holdout_index in kfold.split(X,
y):
self.base_models_[i].append(instance)
instance = clone(model)
instance.fit(X[train_index], y[train_index])
y_pred = instance.predict(X[holdout_index])
out_of_fold_predictions[holdout_index, i] =
y_pred
# ЪЙгУДЮМЖбЕСЗМЏРДбЕСЗДЮМЖбЇЯАЦї
self.meta_model_.fit(out_of_fold_predictions,
y)
return self
#дкЩЯУцЕФfitЗНЗЈЕБжаЃЌЮвУЧвбОНЋЮвУЧбЕСЗГіРДЕФГѕМЖбЇЯАЦїКЭДЮМЖбЇЯАЦїБЃДцЯТРДСЫ
#predictЕФЪБКђжЛашвЊгУетаЉбЇЯАЦїЙЙдьЮвУЧЕФДЮМЖдЄВтЪ§ОнМЏВЂЧвНјаадЄВтОЭПЩвдСЫ
def predict(self, X):
meta_features = np.column_stack([
np.column_stack([model.predict(X) for model
in base_models]).mean(axis=1)
for base_models in self.base_models_ ])
return self.meta_model_.predict(meta_features)
|
|









